 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Applications of Machine Learning to Modelling and Analysing Dynamical Systems
Jul 22, 2023
We explore the use of Physics Informed Neural Networks to analyse nonlinear Hamiltonian Dynamical Systems with a first integral of motion. In this work, we propose an architecture which combines existing Hamiltonian Neural Network structures into Adaptable Symplectic Recurrent Neural Networks which preserve Hamilton's equations as well as the symplectic structure of phase space while predicting dynamics for the entire parameter space. This architecture is found to significantly outperform previously proposed neural networks when predicting Hamiltonian dynamics especially in potentials which contain multiple parameters. We demonstrate its robustness using the nonlinear Henon-Heiles potential under chaotic, quasiperiodic and periodic conditions. The second problem we tackle is whether we can use the high dimensional nonlinear capabilities of neural networks to predict the dynamics of a Hamiltonian system given only partial information of the same. Hence we attempt to take advantage of Long Short Term Memory networks to implement Takens' embedding theorem and construct a delay embedding of the system followed by mapping the topologically invariant attractor to the true form. This architecture is then layered with Adaptable Symplectic nets to allow for predictions which preserve the structure of Hamilton's equations. We show that this method works efficiently for single parameter potentials and provides accurate predictions even over long periods of time.
Improving Online Lane Graph Extraction by Object-Lane Clustering
Jul 20, 2023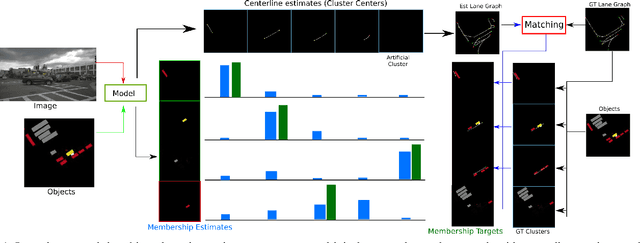
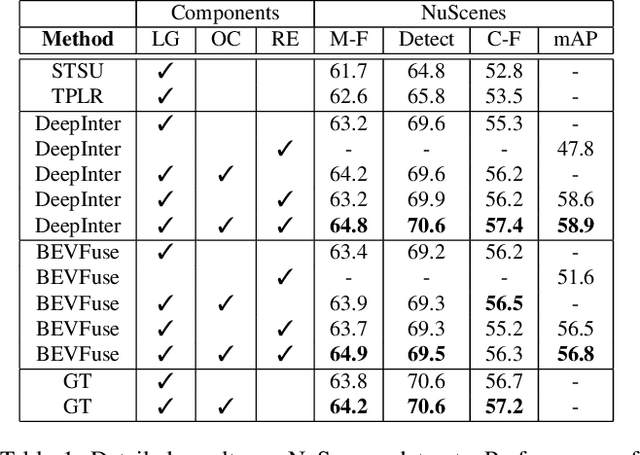
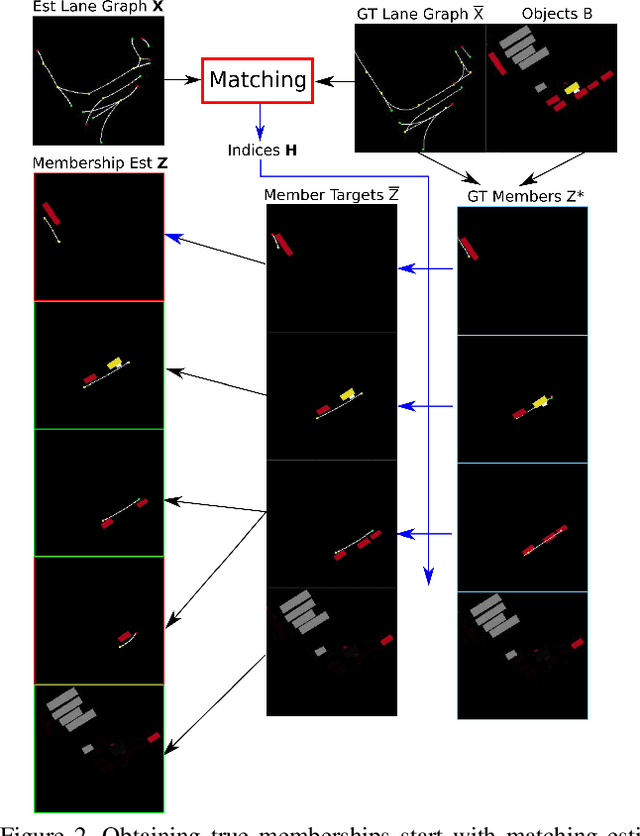
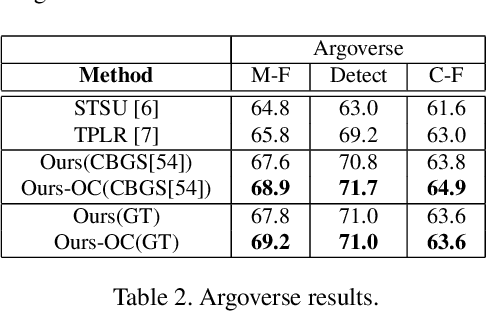
Autonomous driving requires accurate local scene understanding information. To this end, autonomous agents deploy object detection and online BEV lane graph extraction methods as a part of their perception stack. In this work, we propose an architecture and loss formulation to improve the accuracy of local lane graph estimates by using 3D object detection outputs. The proposed method learns to assign the objects to centerlines by considering the centerlines as cluster centers and the objects as data points to be assigned a probability distribution over the cluster centers. This training scheme ensures direct supervision on the relationship between lanes and objects, thus leading to better performance. The proposed method improves lane graph estimation substantially over state-of-the-art methods. The extensive ablations show that our method can achieve significant performance improvements by using the outputs of existing 3D object detection methods. Since our method uses the detection outputs rather than detection method intermediate representations, a single model of our method can use any detection method at test time.
Joint Port Selection Based Channel Acquisition for FDD Cell-Free Massive MIMO
Jul 20, 2023
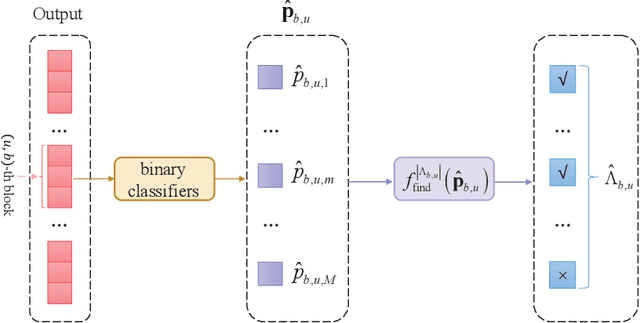
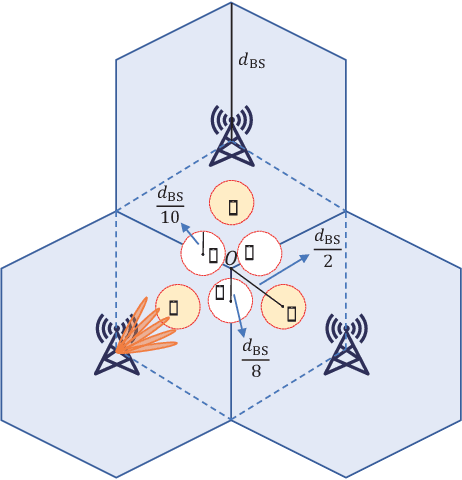
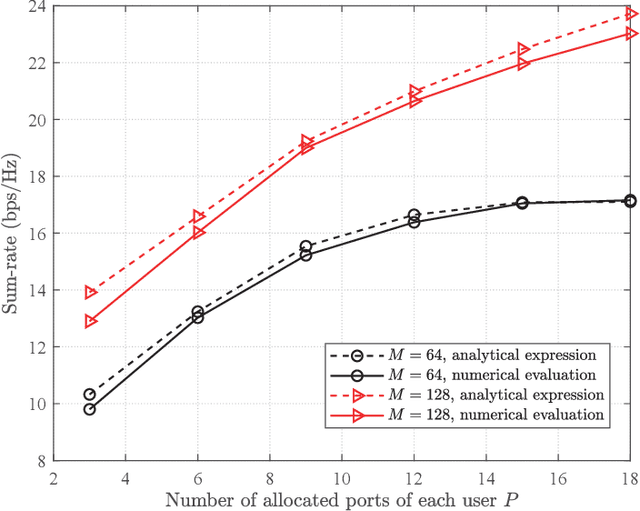
In frequency division duplexing (FDD) cell-free massive MIMO, the acquisition of the channel state information (CSI) is very challenging because of the large overhead required for the training and feedback of the downlink channels of multiple cooperating base stations (BSs). In this paper, for systems with partial uplink-downlink channel reciprocity, and a general spatial domain channel model with variations in the average port power and correlation among port coefficients, we propose a joint-port-selection-based CSI acquisition and feedback scheme for the downlink transmission with zero-forcing precoding. The scheme uses an eigenvalue-decomposition-based transformation to reduce the feedback overhead by exploring the port correlation. We derive the sum-rate of the system for any port selection. Based on the sum-rate result, we propose a low-complexity greedy-search-based joint port selection (GS-JPS) algorithm. Moreover, to adapt to fast time-varying scenarios, a supervised deep learning-enhanced joint port selection (DL-JPS) algorithm is proposed. Simulations verify the effectiveness of our proposed schemes and their advantage over existing port-selection channel acquisition schemes.
SqueezerFaceNet: Reducing a Small Face Recognition CNN Even More Via Filter Pruning
Jul 20, 2023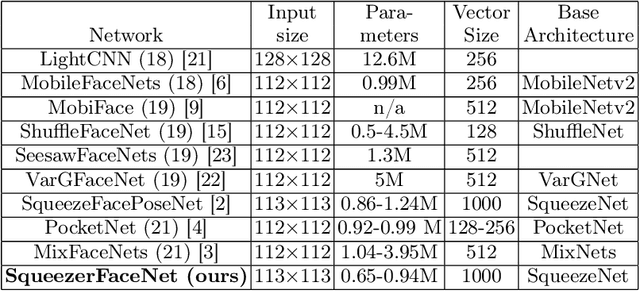


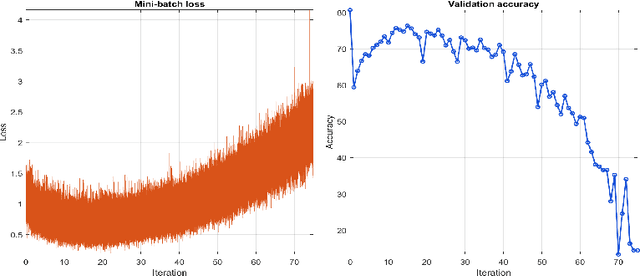
The widespread use of mobile devices for various digital services has created a need for reliable and real-time person authentication. In this context, facial recognition technologies have emerged as a dependable method for verifying users due to the prevalence of cameras in mobile devices and their integration into everyday applications. The rapid advancement of deep Convolutional Neural Networks (CNNs) has led to numerous face verification architectures. However, these models are often large and impractical for mobile applications, reaching sizes of hundreds of megabytes with millions of parameters. We address this issue by developing SqueezerFaceNet, a light face recognition network which less than 1M parameters. This is achieved by applying a network pruning method based on Taylor scores, where filters with small importance scores are removed iteratively. Starting from an already small network (of 1.24M) based on SqueezeNet, we show that it can be further reduced (up to 40%) without an appreciable loss in performance. To the best of our knowledge, we are the first to evaluate network pruning methods for the task of face recognition.
Towards Non-Parametric Models for Confidence Aware Image Prediction from Low Data using Gaussian Processes
Jul 20, 2023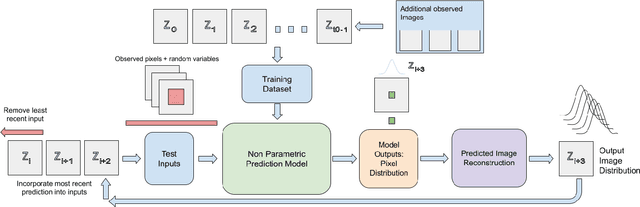
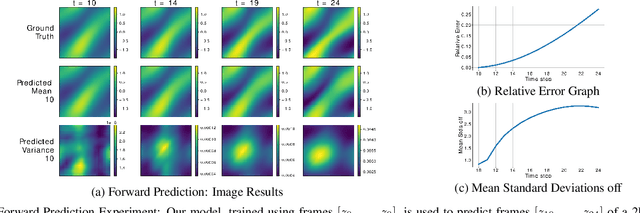

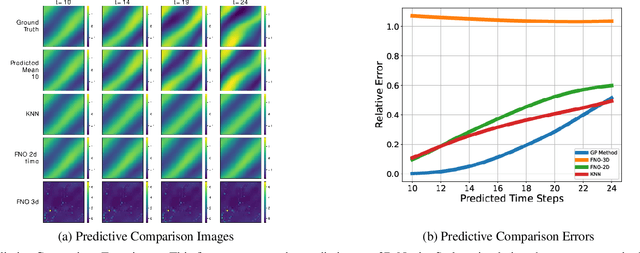
The ability to envision future states is crucial to informed decision making while interacting with dynamic environments. With cameras providing a prevalent and information rich sensing modality, the problem of predicting future states from image sequences has garnered a lot of attention. Current state of the art methods typically train large parametric models for their predictions. Though often able to predict with accuracy, these models rely on the availability of large training datasets to converge to useful solutions. In this paper we focus on the problem of predicting future images of an image sequence from very little training data. To approach this problem, we use non-parametric models to take a probabilistic approach to image prediction. We generate probability distributions over sequentially predicted images and propagate uncertainty through time to generate a confidence metric for our predictions. Gaussian Processes are used for their data efficiency and ability to readily incorporate new training data online. We showcase our method by successfully predicting future frames of a smooth fluid simulation environment.
Clinical Trial Active Learning
Jul 20, 2023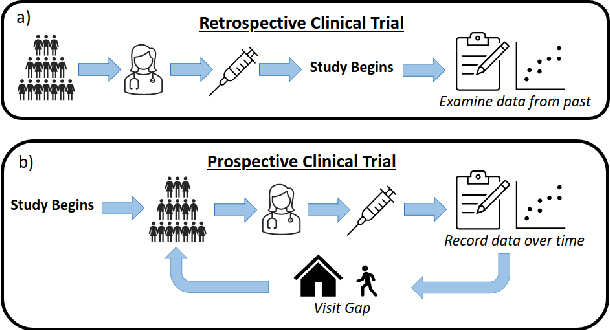
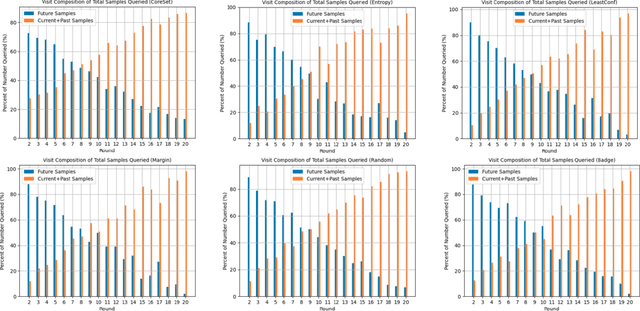
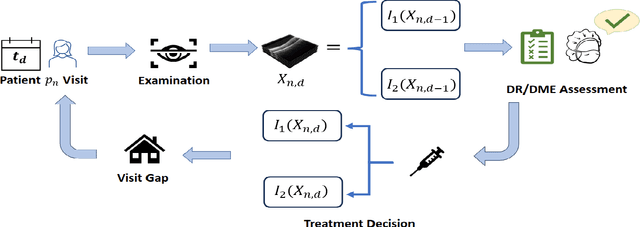
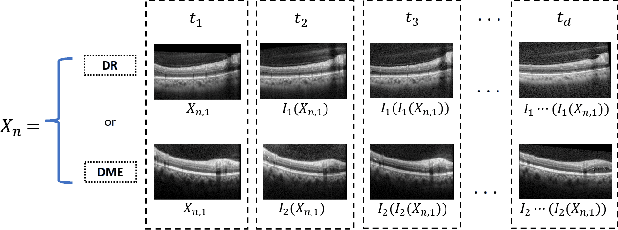
This paper presents a novel approach to active learning that takes into account the non-independent and identically distributed (non-i.i.d.) structure of a clinical trial setting. There exists two types of clinical trials: retrospective and prospective. Retrospective clinical trials analyze data after treatment has been performed; prospective clinical trials collect data as treatment is ongoing. Typically, active learning approaches assume the dataset is i.i.d. when selecting training samples; however, in the case of clinical trials, treatment results in a dependency between the data collected at the current and past visits. Thus, we propose prospective active learning to overcome the limitations present in traditional active learning methods and apply it to disease detection in optical coherence tomography (OCT) images, where we condition on the time an image was collected to enforce the i.i.d. assumption. We compare our proposed method to the traditional active learning paradigm, which we refer to as retrospective in nature. We demonstrate that prospective active learning outperforms retrospective active learning in two different types of test settings.
$ν^2$-Flows: Fast and improved neutrino reconstruction in multi-neutrino final states with conditional normalizing flows
Jul 20, 2023In this work we introduce $\nu^2$-Flows, an extension of the $\nu$-Flows method to final states containing multiple neutrinos. The architecture can natively scale for all combinations of object types and multiplicities in the final state for any desired neutrino multiplicities. In $t\bar{t}$ dilepton events, the momenta of both neutrinos and correlations between them are reconstructed more accurately than when using the most popular standard analytical techniques, and solutions are found for all events. Inference time is significantly faster than competing methods, and can be reduced further by evaluating in parallel on graphics processing units. We apply $\nu^2$-Flows to $t\bar{t}$ dilepton events and show that the per-bin uncertainties in unfolded distributions is much closer to the limit of performance set by perfect neutrino reconstruction than standard techniques. For the chosen double differential observables $\nu^2$-Flows results in improved statistical precision for each bin by a factor of 1.5 to 2 in comparison to the Neutrino Weighting method and up to a factor of four in comparison to the Ellipse approach.
Towards Generalizable Detection of Urgency of Discussion Forum Posts
Jul 14, 2023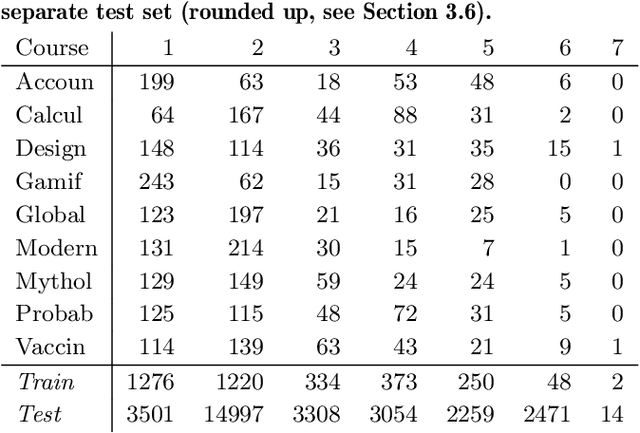
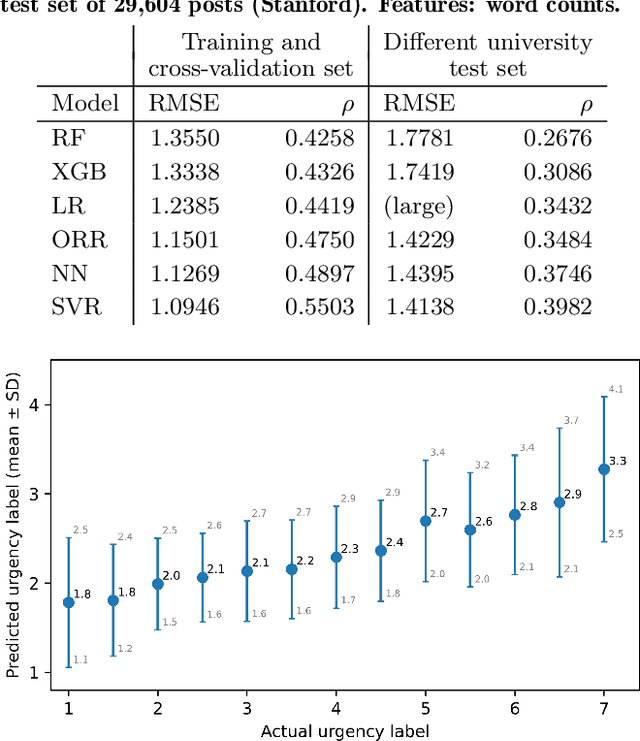
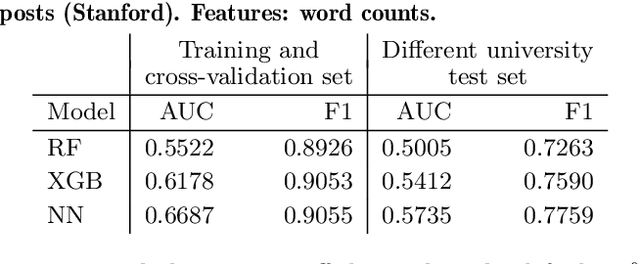
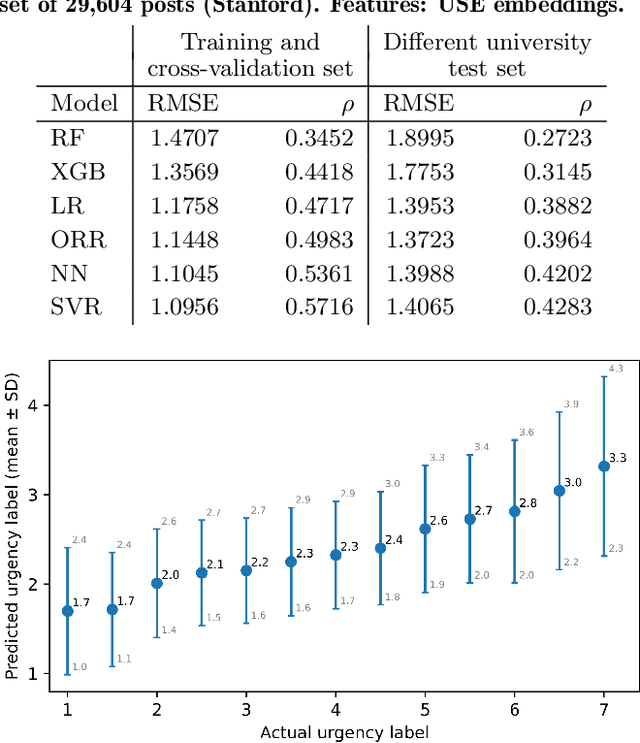
Students who take an online course, such as a MOOC, use the course's discussion forum to ask questions or reach out to instructors when encountering an issue. However, reading and responding to students' questions is difficult to scale because of the time needed to consider each message. As a result, critical issues may be left unresolved, and students may lose the motivation to continue in the course. To help address this problem, we build predictive models that automatically determine the urgency of each forum post, so that these posts can be brought to instructors' attention. This paper goes beyond previous work by predicting not just a binary decision cut-off but a post's level of urgency on a 7-point scale. First, we train and cross-validate several models on an original data set of 3,503 posts from MOOCs at University of Pennsylvania. Second, to determine the generalizability of our models, we test their performance on a separate, previously published data set of 29,604 posts from MOOCs at Stanford University. While the previous work on post urgency used only one data set, we evaluated the prediction across different data sets and courses. The best-performing model was a support vector regressor trained on the Universal Sentence Encoder embeddings of the posts, achieving an RMSE of 1.1 on the training set and 1.4 on the test set. Understanding the urgency of forum posts enables instructors to focus their time more effectively and, as a result, better support student learning.
Clarifying the Half Full or Half Empty Question: Multimodal Container Classification
Jul 17, 2023Multimodal integration is a key component of allowing robots to perceive the world. Multimodality comes with multiple challenges that have to be considered, such as how to integrate and fuse the data. In this paper, we compare different possibilities of fusing visual, tactile and proprioceptive data. The data is directly recorded on the NICOL robot in an experimental setup in which the robot has to classify containers and their content. Due to the different nature of the containers, the use of the modalities can wildly differ between the classes. We demonstrate the superiority of multimodal solutions in this use case and evaluate three fusion strategies that integrate the data at different time steps. We find that the accuracy of the best fusion strategy is 15% higher than the best strategy using only one singular sense.
MAS: Towards Resource-Efficient Federated Multiple-Task Learning
Jul 21, 2023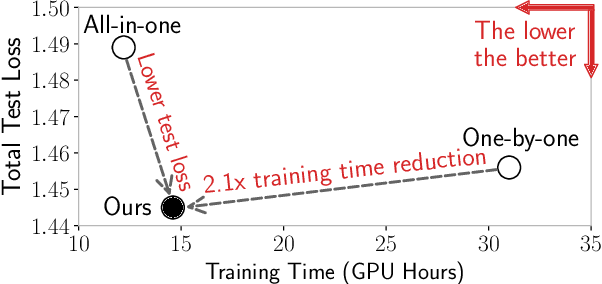
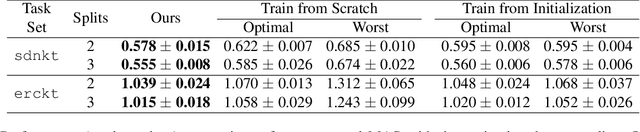
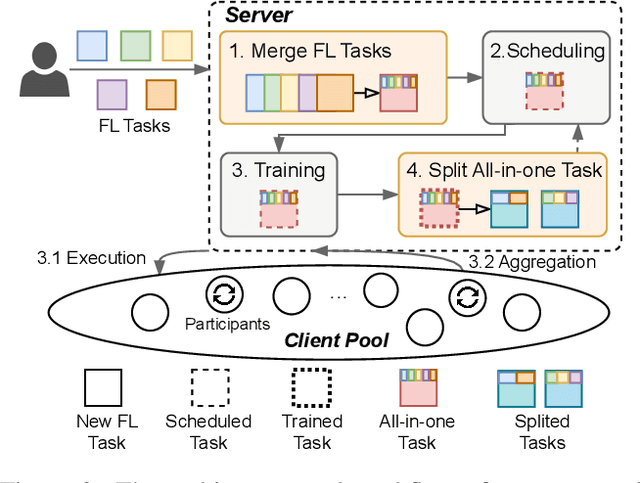
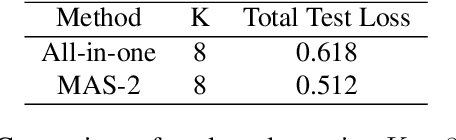
Federated learning (FL) is an emerging distributed machine learning method that empowers in-situ model training on decentralized edge devices. However, multiple simultaneous FL tasks could overload resource-constrained devices. In this work, we propose the first FL system to effectively coordinate and train multiple simultaneous FL tasks. We first formalize the problem of training simultaneous FL tasks. Then, we present our new approach, MAS (Merge and Split), to optimize the performance of training multiple simultaneous FL tasks. MAS starts by merging FL tasks into an all-in-one FL task with a multi-task architecture. After training for a few rounds, MAS splits the all-in-one FL task into two or more FL tasks by using the affinities among tasks measured during the all-in-one training. It then continues training each split of FL tasks based on model parameters from the all-in-one training. Extensive experiments demonstrate that MAS outperforms other methods while reducing training time by 2x and reducing energy consumption by 40%. We hope this work will inspire the community to further study and optimize training simultaneous FL tasks.