 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Not with my name! Inferring artists' names of input strings employed by Diffusion Models
Jul 25, 2023

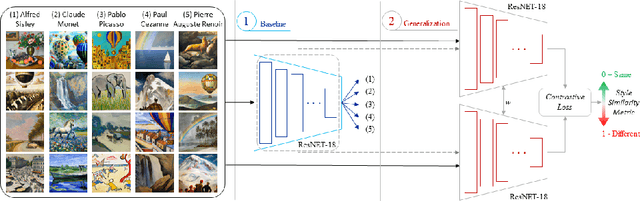
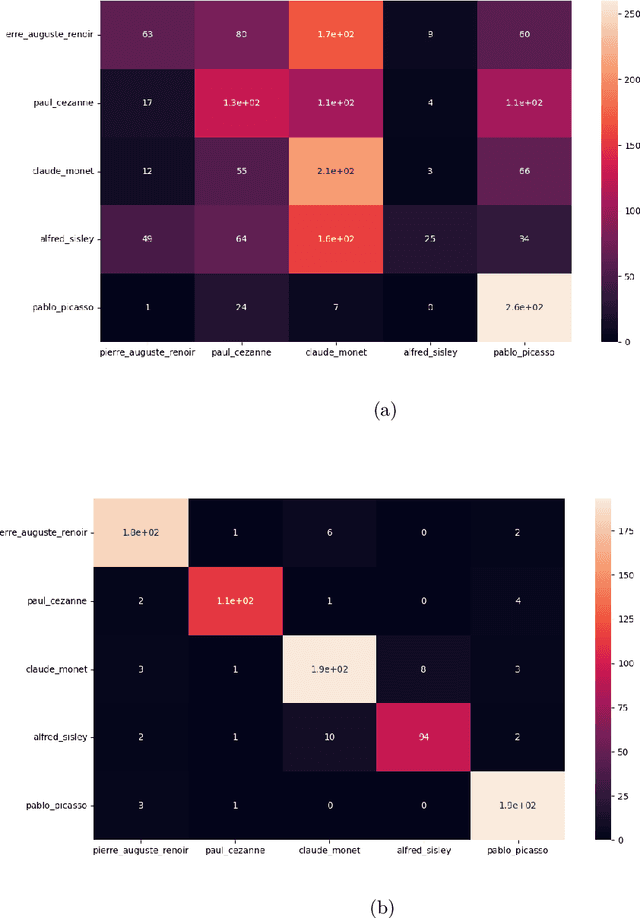
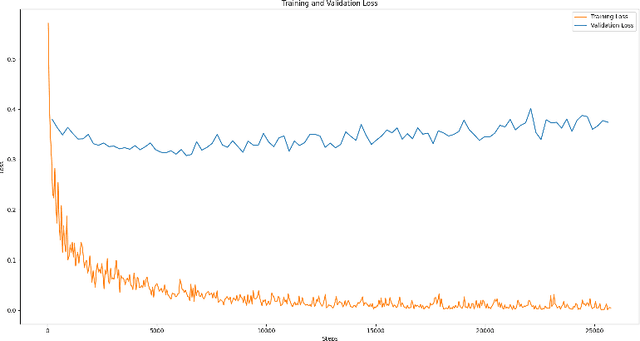
Diffusion Models (DM) are highly effective at generating realistic, high-quality images. However, these models lack creativity and merely compose outputs based on their training data, guided by a textual input provided at creation time. Is it acceptable to generate images reminiscent of an artist, employing his name as input? This imply that if the DM is able to replicate an artist's work then it was trained on some or all of his artworks thus violating copyright. In this paper, a preliminary study to infer the probability of use of an artist's name in the input string of a generated image is presented. To this aim we focused only on images generated by the famous DALL-E 2 and collected images (both original and generated) of five renowned artists. Finally, a dedicated Siamese Neural Network was employed to have a first kind of probability. Experimental results demonstrate that our approach is an optimal starting point and can be employed as a prior for predicting a complete input string of an investigated image. Dataset and code are available at: https://github.com/ictlab-unict/not-with-my-name .
IndigoVX: Where Human Intelligence Meets AI for Optimal Decision Making
Jul 21, 2023This paper defines a new approach for augmenting human intelligence with AI for optimal goal solving. Our proposed AI, Indigo, is an acronym for Informed Numerical Decision-making through Iterative Goal-Oriented optimization. When combined with a human collaborator, we term the joint system IndigoVX, for Virtual eXpert. The system is conceptually simple. We envisage this method being applied to games or business strategies, with the human providing strategic context and the AI offering optimal, data-driven moves. Indigo operates through an iterative feedback loop, harnessing the human expert's contextual knowledge and the AI's data-driven insights to craft and refine strategies towards a well-defined goal. Using a quantified three-score schema, this hybridization allows the combined team to evaluate strategies and refine their plan, while adapting to challenges and changes in real-time.
Practical Low-density Codes for PB-ToF Sensing
Jul 21, 2023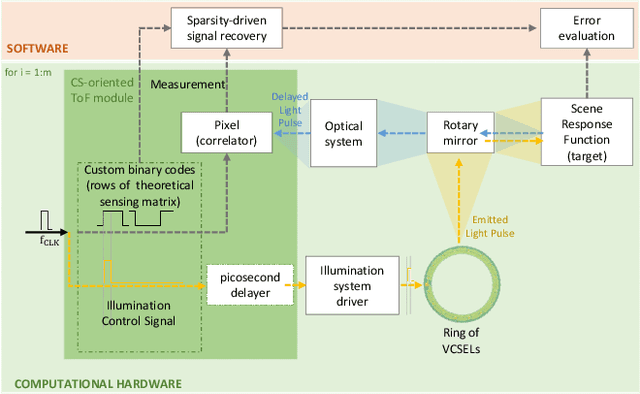
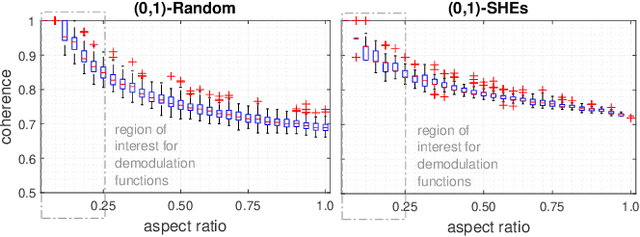
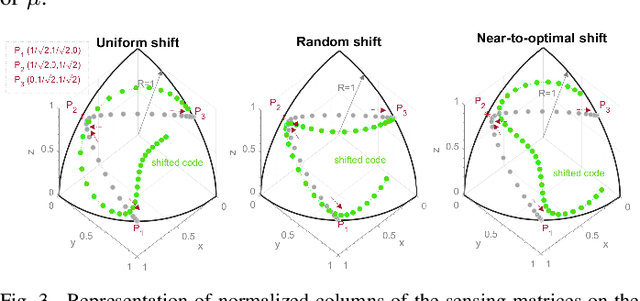
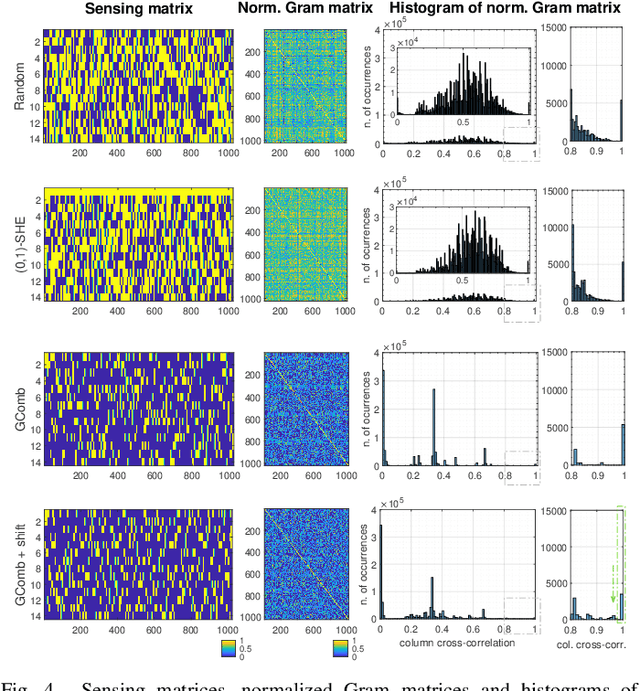
An indirect Pulse-based Time-of-Flight camera can be modelled as a linear sensing system in which the target's depth is recovered from few measurements through a sensing matrix formed by a set of demodulation functions. Each demodulation function is the result of the convolution of a (0,1)-binary code and a cross-correlation function which models the entire modulation-demodulation process. In this paper, we present a practical scheme for the construction of the sensing matrix which relies on the optimization of the coherence, and is based on low-density codes. We demonstrate that our methodology eliminates the intrinsic variability of random and pseudo-random approaches, and allows for the recovery of the target's depth in a grid much finer than the number of distinct elements in the binary codes.
Learning to Segment from Noisy Annotations: A Spatial Correction Approach
Jul 21, 2023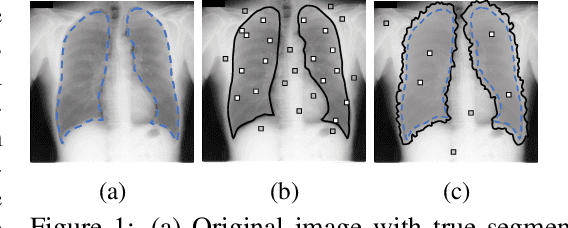
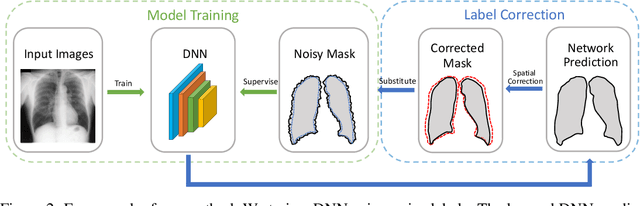
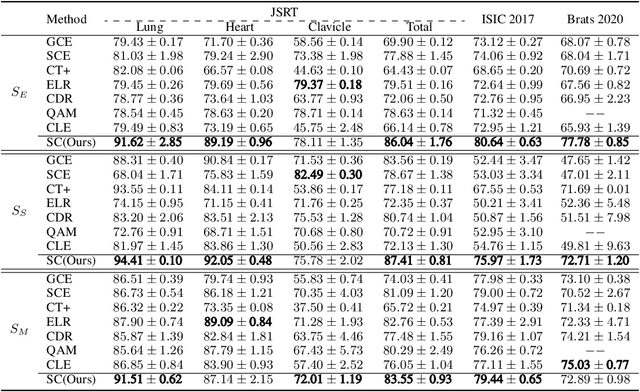
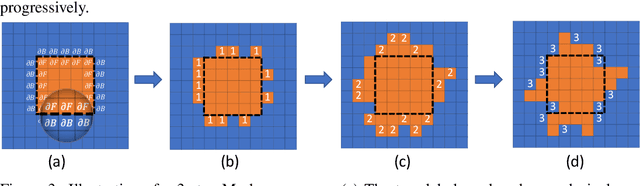
Noisy labels can significantly affect the performance of deep neural networks (DNNs). In medical image segmentation tasks, annotations are error-prone due to the high demand in annotation time and in the annotators' expertise. Existing methods mostly assume noisy labels in different pixels are \textit{i.i.d}. However, segmentation label noise usually has strong spatial correlation and has prominent bias in distribution. In this paper, we propose a novel Markov model for segmentation noisy annotations that encodes both spatial correlation and bias. Further, to mitigate such label noise, we propose a label correction method to recover true label progressively. We provide theoretical guarantees of the correctness of the proposed method. Experiments show that our approach outperforms current state-of-the-art methods on both synthetic and real-world noisy annotations.
Physics-based Reduced Order Modeling for Uncertainty Quantification of Guided Wave Propagation using Bayesian Optimization
Jul 18, 2023In the context of digital twins, structural health monitoring (SHM) constitutes the backbone of condition-based maintenance, facilitating the interconnection between virtual and physical assets. Guided wave propagation (GWP) is commonly employed for the inspection of structures in SHM. However, GWP is sensitive to variations in the material properties of the structure, leading to false alarms. In this direction, uncertainty quantification (UQ) is regularly applied to improve the reliability of predictions. Computational mechanics is a useful tool for the simulation of GWP, and is often applied for UQ. Even so, the application of UQ methods requires numerous simulations, while large-scale, transient numerical GWP solutions increase the computational cost. Reduced order models (ROMs) are commonly employed to provide numerical results in a limited amount of time. In this paper, we propose a machine learning (ML)-based ROM, mentioned as BO-ML-ROM, to decrease the computational time related to the simulation of the GWP. The ROM is integrated with a Bayesian optimization (BO) framework, to adaptively sample the parameters for the ROM training. The finite element method is used for the simulation of the high-fidelity models. The formulated ROM is used for forward UQ of the GWP in an aluminum plate with varying material properties. To determine the influence of each parameter perturbation, a global, variance-based sensitivity analysis is implemented based on Sobol' indices. It is shown that Bayesian optimization outperforms one-shot sampling methods, both in terms of accuracy and speed-up. The predicted results reveal the efficiency of BO-ML-ROM for GWP and demonstrate its value for UQ.
Measuring Item Global Residual Value for Fair Recommendation
Jul 17, 2023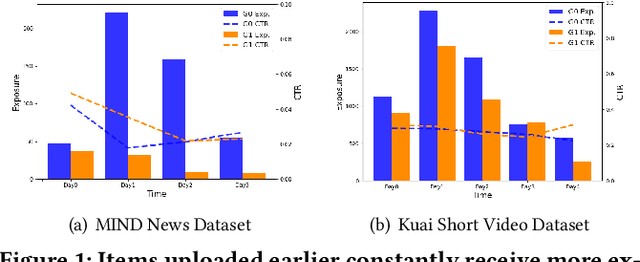

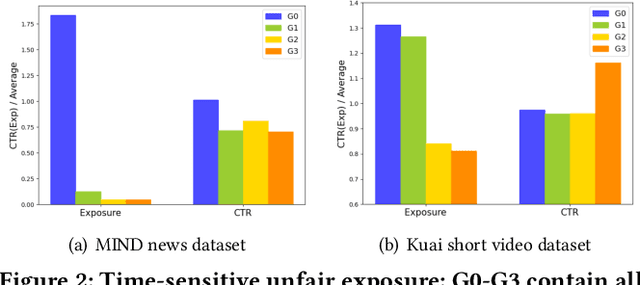

In the era of information explosion, numerous items emerge every day, especially in feed scenarios. Due to the limited system display slots and user browsing attention, various recommendation systems are designed not only to satisfy users' personalized information needs but also to allocate items' exposure. However, recent recommendation studies mainly focus on modeling user preferences to present satisfying results and maximize user interactions, while paying little attention to developing item-side fair exposure mechanisms for rational information delivery. This may lead to serious resource allocation problems on the item side, such as the Snowball Effect. Furthermore, unfair exposure mechanisms may hurt recommendation performance. In this paper, we call for a shift of attention from modeling user preferences to developing fair exposure mechanisms for items. We first conduct empirical analyses of feed scenarios to explore exposure problems between items with distinct uploaded times. This points out that unfair exposure caused by the time factor may be the major cause of the Snowball Effect. Then, we propose to explicitly model item-level customized timeliness distribution, Global Residual Value (GRV), for fair resource allocation. This GRV module is introduced into recommendations with the designed Timeliness-aware Fair Recommendation Framework (TaFR). Extensive experiments on two datasets demonstrate that TaFR achieves consistent improvements with various backbone recommendation models. By modeling item-side customized Global Residual Value, we achieve a fairer distribution of resources and, at the same time, improve recommendation performance.
Dynamic Joint Scheduling of Anycast Transmission and Modulation in Hybrid Unicast-Multicast SWIPT-Based IoT Sensor Networks
Jul 17, 2023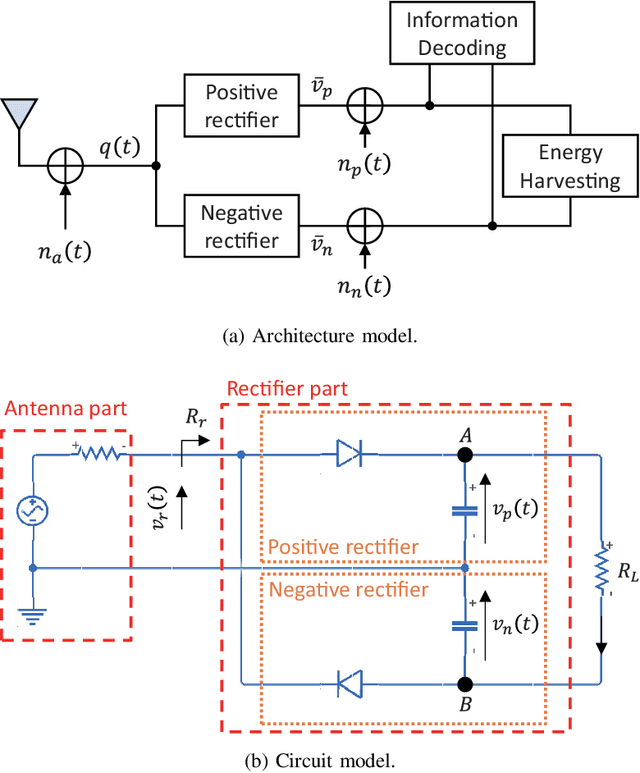
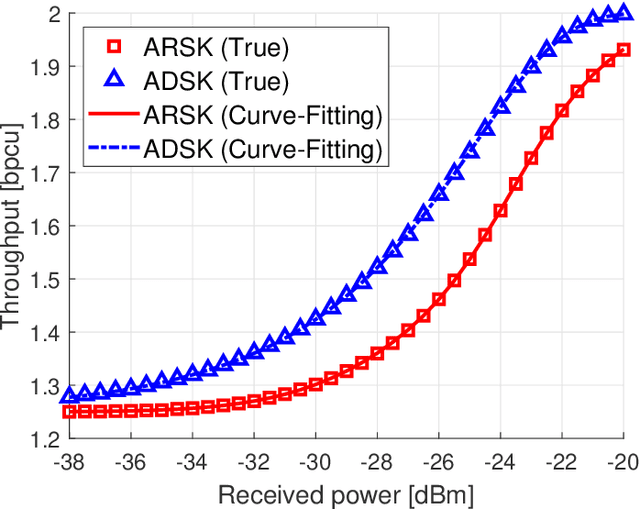
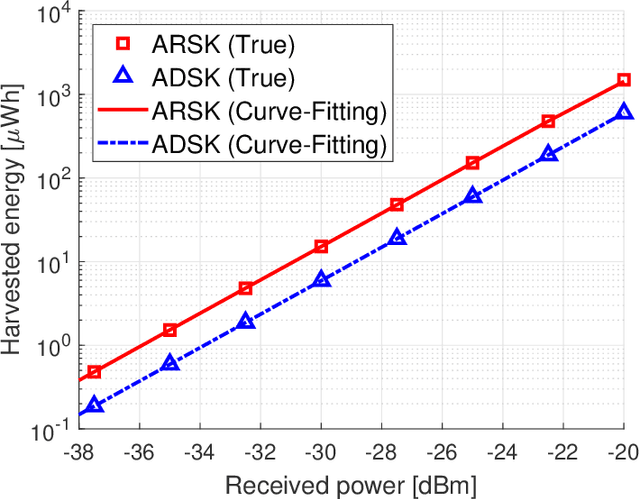
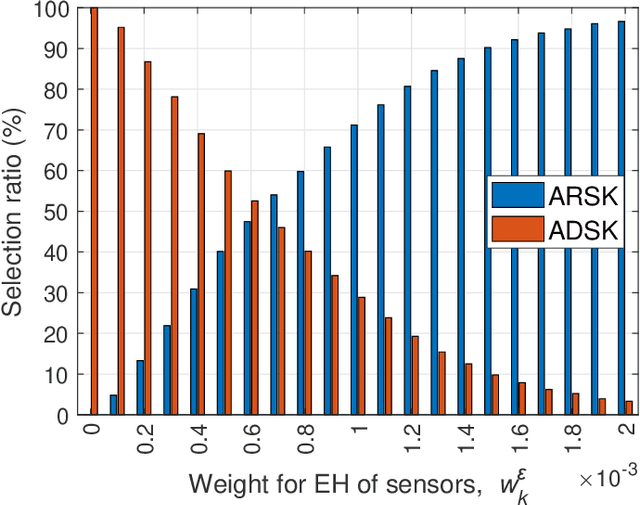
The separate receiver architecture with a time- or power-splitting mode, widely used for simultaneous wireless information and power transfer (SWIPT), has a major drawback: Energy-intensive local oscillators and mixers need to be installed in the information decoding (ID) component to downconvert radio frequency (RF) signals to baseband signals, resulting in high energy consumption. As a solution to this challenge, an integrated receiver (IR) architecture has been proposed, and, in turn, various SWIPT modulation schemes compatible with the IR architecture have been developed. However, to the best of our knowledge, no research has been conducted on modulation scheduling in SWIPT-based IoT sensor networks while taking into account the IR architecture. Accordingly, in this paper, we address this research gap by studying the problem of joint scheduling for unicast/multicast, IoT sensor, and modulation (UMSM) in a time-slotted SWIPT-based IoT sensor network system. To this end, we leverage mathematical modeling and optimization techniques, such as the Lagrangian duality and stochastic optimization theory, to develop an UMSM scheduling algorithm that maximizes the weighted sum of average unicast service throughput and harvested energy of IoT sensors, while ensuring the minimum average throughput of both multicast and unicast, as well as the minimum average harvested energy of IoT sensors. Finally, we demonstrate through extensive simulations that our UMSM scheduling algorithm achieves superior energy harvesting (EH) and throughput performance while ensuring the satisfaction of specified constraints well.
Low Latency Computing for Time Stretch Instruments
Apr 05, 2023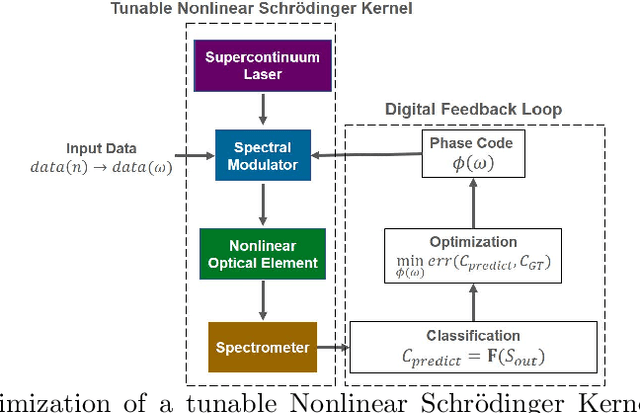
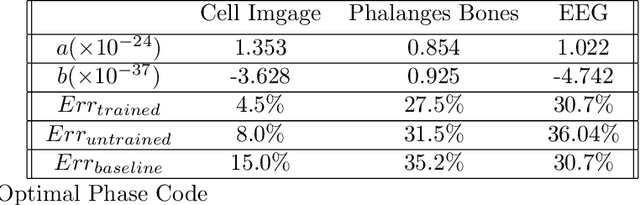
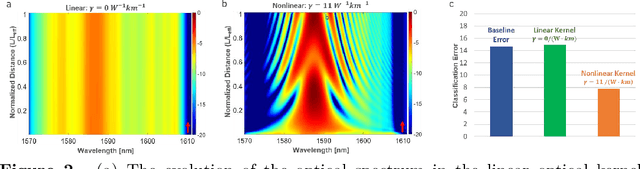
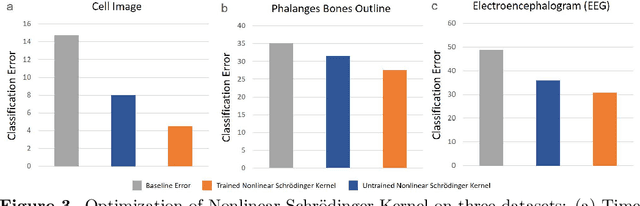
Time stretch instruments have been exceptionally successful in discovering single-shot ultrafast phenomena such as optical rogue waves and have led to record-speed microscopy, spectroscopy, lidar, etc. These instruments encode the ultrafast events into the spectrum of a femtosecond pulse and then dilate the time scale of the data using group velocity dispersion. Generating as much as Tbit per second of data, they are ideal partners for deep learning networks which by their inherent complexity, require large datasets for training. However, the inference time scale of neural networks in the millisecond regime is orders of magnitude longer than the data acquisition rate of time stretch instruments. This underscores the need to explore means where some of the lower-level computational tasks can be done while the data is still in the optical domain. The Nonlinear Schr\"{o}dinger Kernel computing addresses this predicament. It utilizes optical nonlinearities to map the data onto a new domain in which classification accuracy is enhanced, without increasing the data dimensions. One limitation of this technique is the fixed optical transfer function, which prevents training and generalizability. Here we show that the optical kernel can be effectively tuned and trained by utilizing digital phase encoding of the femtosecond laser pulse leading to a reduction of the error rate in data classification.
Unsupervised CD in satellite image time series by contrastive learning and feature tracking
Apr 22, 2023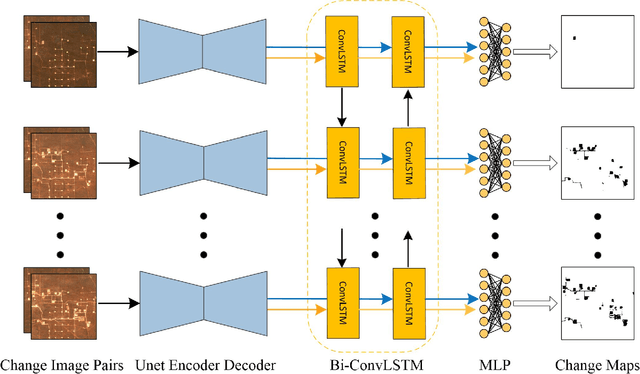

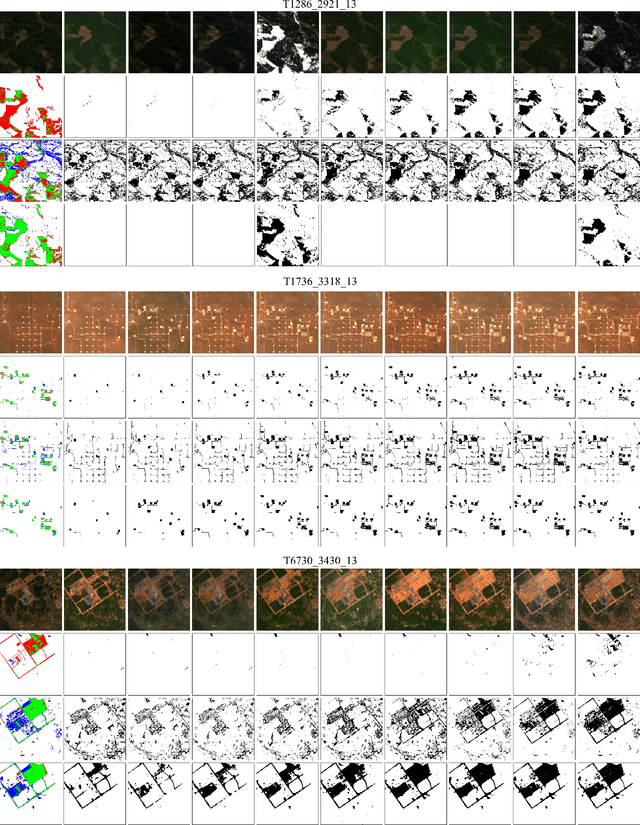

While unsupervised change detection using contrastive learning has been significantly improved the performance of literature techniques, at present, it only focuses on the bi-temporal change detection scenario. Previous state-of-the-art models for image time-series change detection often use features obtained by learning for clustering or training a model from scratch using pseudo labels tailored to each scene. However, these approaches fail to exploit the spatial-temporal information of image time-series or generalize to unseen scenarios. In this work, we propose a two-stage approach to unsupervised change detection in satellite image time-series using contrastive learning with feature tracking. By deriving pseudo labels from pre-trained models and using feature tracking to propagate them among the image time-series, we improve the consistency of our pseudo labels and address the challenges of seasonal changes in long-term remote sensing image time-series. We adopt the self-training algorithm with ConvLSTM on the obtained pseudo labels, where we first use supervised contrastive loss and contrastive random walks to further improve the feature correspondence in space-time. Then a fully connected layer is fine-tuned on the pre-trained multi-temporal features for generating the final change maps. Through comprehensive experiments on two datasets, we demonstrate consistent improvements in accuracy on fitting and inference scenarios.
Introducing Delays in Multi-Agent Path Finding
Jul 20, 2023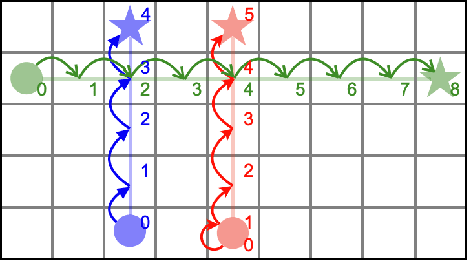
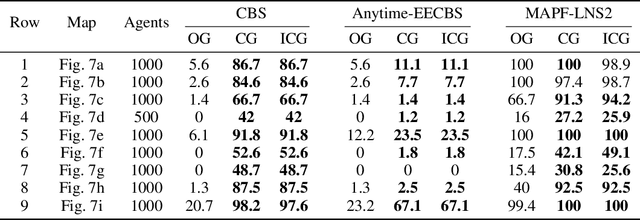
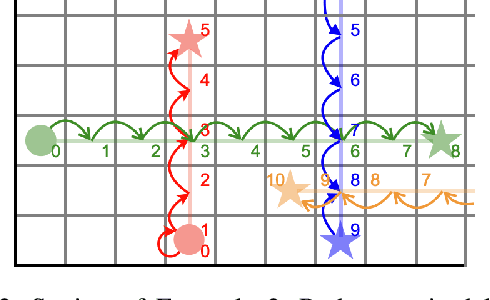
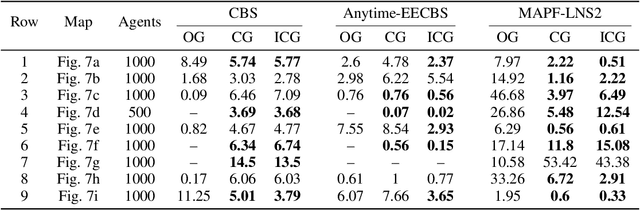
We consider a Multi-Agent Path Finding (MAPF) setting where agents have been assigned a plan, but during its execution some agents are delayed. Instead of replanning from scratch when such a delay occurs, we propose delay introduction, whereby we delay some additional agents so that the remainder of the plan can be executed safely. We show that the corresponding decision problem is NP-Complete in general. However, in practice we can find optimal delay-introductions using CBS for very large numbers of agents, and both planning time and the resulting length of the plan are comparable, and sometimes outperform, the state-of-the-art heuristics for replanning. We also examine the benefits of our method from an explainability point of view.