 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Determined Multi-Label Learning via Similarity-Based Prompt
Mar 25, 2024
In multi-label classification, each training instance is associated with multiple class labels simultaneously. Unfortunately, collecting the fully precise class labels for each training instance is time- and labor-consuming for real-world applications. To alleviate this problem, a novel labeling setting termed \textit{Determined Multi-Label Learning} (DMLL) is proposed, aiming to effectively alleviate the labeling cost inherent in multi-label tasks. In this novel labeling setting, each training instance is associated with a \textit{determined label} (either "Yes" or "No"), which indicates whether the training instance contains the provided class label. The provided class label is randomly and uniformly selected from the whole candidate labels set. Besides, each training instance only need to be determined once, which significantly reduce the annotation cost of the labeling task for multi-label datasets. In this paper, we theoretically derive an risk-consistent estimator to learn a multi-label classifier from these determined-labeled training data. Additionally, we introduce a similarity-based prompt learning method for the first time, which minimizes the risk-consistent loss of large-scale pre-trained models to learn a supplemental prompt with richer semantic information. Extensive experimental validation underscores the efficacy of our approach, demonstrating superior performance compared to existing state-of-the-art methods.
Modeling Analog Dynamic Range Compressors using Deep Learning and State-space Models
Mar 24, 2024We describe a novel approach for developing realistic digital models of dynamic range compressors for digital audio production by analyzing their analog prototypes. While realistic digital dynamic compressors are potentially useful for many applications, the design process is challenging because the compressors operate nonlinearly over long time scales. Our approach is based on the structured state space sequence model (S4), as implementing the state-space model (SSM) has proven to be efficient at learning long-range dependencies and is promising for modeling dynamic range compressors. We present in this paper a deep learning model with S4 layers to model the Teletronix LA-2A analog dynamic range compressor. The model is causal, executes efficiently in real time, and achieves roughly the same quality as previous deep-learning models but with fewer parameters.
Multi-Fidelity Reinforcement Learning for Time-Optimal Quadrotor Re-planning
Mar 13, 2024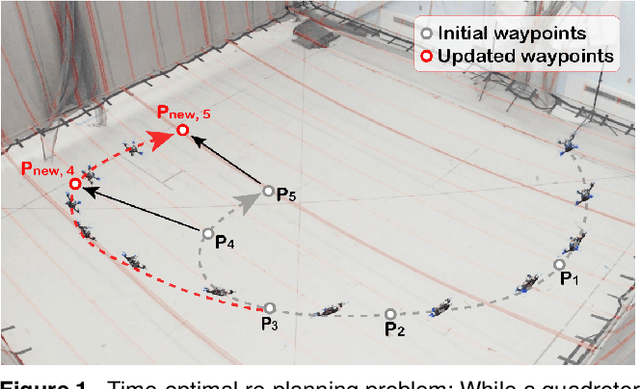
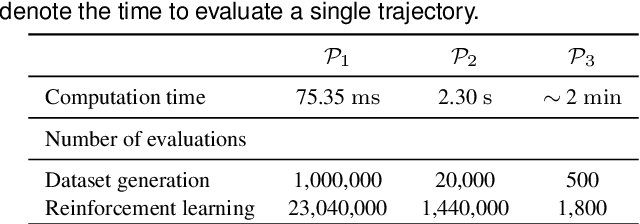
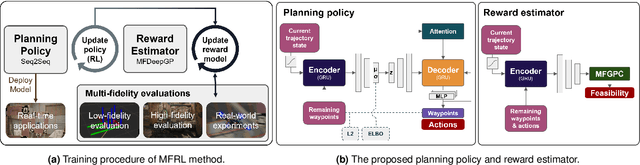
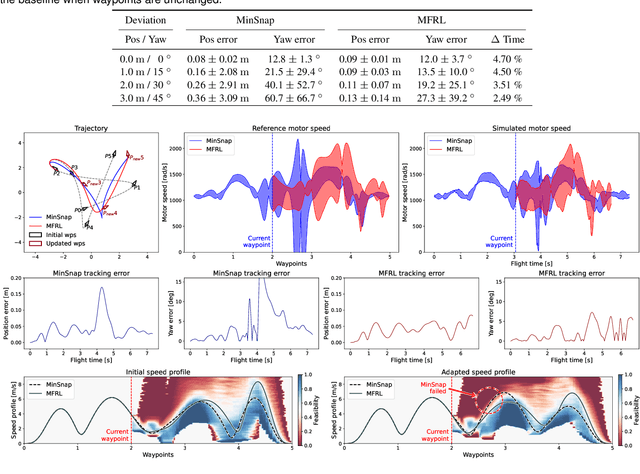
High-speed online trajectory planning for UAVs poses a significant challenge due to the need for precise modeling of complex dynamics while also being constrained by computational limitations. This paper presents a multi-fidelity reinforcement learning method (MFRL) that aims to effectively create a realistic dynamics model and simultaneously train a planning policy that can be readily deployed in real-time applications. The proposed method involves the co-training of a planning policy and a reward estimator; the latter predicts the performance of the policy's output and is trained efficiently through multi-fidelity Bayesian optimization. This optimization approach models the correlation between different fidelity levels, thereby constructing a high-fidelity model based on a low-fidelity foundation, which enables the accurate development of the reward model with limited high-fidelity experiments. The framework is further extended to include real-world flight experiments in reinforcement learning training, allowing the reward model to precisely reflect real-world constraints and broadening the policy's applicability to real-world scenarios. We present rigorous evaluations by training and testing the planning policy in both simulated and real-world environments. The resulting trained policy not only generates faster and more reliable trajectories compared to the baseline snap minimization method, but it also achieves trajectory updates in 2 ms on average, while the baseline method takes several minutes.
Do High-Performance Image-to-Image Translation Networks Enable the Discovery of Radiomic Features? Application to MRI Synthesis from Ultrasound in Prostate Cancer
Mar 27, 2024This study investigates the foundational characteristics of image-to-image translation networks, specifically examining their suitability and transferability within the context of routine clinical environments, despite achieving high levels of performance, as indicated by a Structural Similarity Index (SSIM) exceeding 0.95. The evaluation study was conducted using data from 794 patients diagnosed with Prostate cancer. To synthesize MRI from Ultrasound images, we employed five widely recognized image to image translation networks in medical imaging: 2DPix2Pix, 2DCycleGAN, 3DCycleGAN, 3DUNET, and 3DAutoEncoder. For quantitative assessment, we report four prevalent evaluation metrics Mean Absolute Error, Mean Square Error, Structural Similarity Index (SSIM), and Peak Signal to Noise Ratio. Moreover, a complementary analysis employing Radiomic features (RF) via Spearman correlation coefficient was conducted to investigate, for the first time, whether networks achieving high performance, SSIM greater than 0.9, could identify low-level RFs. The RF analysis showed 76 features out of 186 RFs were discovered via just 2DPix2Pix algorithm while half of RFs were lost in the translation process. Finally, a detailed qualitative assessment by five medical doctors indicated a lack of low level feature discovery in image to image translation tasks.
MA4DIV: Multi-Agent Reinforcement Learning for Search Result Diversification
Mar 27, 2024The objective of search result diversification (SRD) is to ensure that selected documents cover as many different subtopics as possible. Existing methods primarily utilize a paradigm of "greedy selection", i.e., selecting one document with the highest diversity score at a time. These approaches tend to be inefficient and are easily trapped in a suboptimal state. In addition, some other methods aim to approximately optimize the diversity metric, such as $\alpha$-NDCG, but the results still remain suboptimal. To address these challenges, we introduce Multi-Agent reinforcement learning (MARL) for search result DIVersity, which called MA4DIV. In this approach, each document is an agent and the search result diversification is modeled as a cooperative task among multiple agents. This approach allows for directly optimizing the diversity metrics, such as $\alpha$-NDCG, while achieving high training efficiency. We conducted preliminary experiments on public TREC datasets to demonstrate the effectiveness and potential of MA4DIV. Considering the limited number of queries in public TREC datasets, we construct a large-scale dataset from industry sources and show that MA4DIV achieves substantial improvements in both effectiveness and efficiency than existing baselines on a industrial scale dataset.
Learning Inclusion Matching for Animation Paint Bucket Colorization
Mar 27, 2024Colorizing line art is a pivotal task in the production of hand-drawn cel animation. This typically involves digital painters using a paint bucket tool to manually color each segment enclosed by lines, based on RGB values predetermined by a color designer. This frame-by-frame process is both arduous and time-intensive. Current automated methods mainly focus on segment matching. This technique migrates colors from a reference to the target frame by aligning features within line-enclosed segments across frames. However, issues like occlusion and wrinkles in animations often disrupt these direct correspondences, leading to mismatches. In this work, we introduce a new learning-based inclusion matching pipeline, which directs the network to comprehend the inclusion relationships between segments rather than relying solely on direct visual correspondences. Our method features a two-stage pipeline that integrates a coarse color warping module with an inclusion matching module, enabling more nuanced and accurate colorization. To facilitate the training of our network, we also develope a unique dataset, referred to as PaintBucket-Character. This dataset includes rendered line arts alongside their colorized counterparts, featuring various 3D characters. Extensive experiments demonstrate the effectiveness and superiority of our method over existing techniques.
Global Vegetation Modeling with Pre-Trained Weather Transformers
Mar 27, 2024Accurate vegetation models can produce further insights into the complex interaction between vegetation activity and ecosystem processes. Previous research has established that long-term trends and short-term variability of temperature and precipitation affect vegetation activity. Motivated by the recent success of Transformer-based Deep Learning models for medium-range weather forecasting, we adapt the publicly available pre-trained FourCastNet to model vegetation activity while accounting for the short-term dynamics of climate variability. We investigate how the learned global representation of the atmosphere's state can be transferred to model the normalized difference vegetation index (NDVI). Our model globally estimates vegetation activity at a resolution of \SI{0.25}{\degree} while relying only on meteorological data. We demonstrate that leveraging pre-trained weather models improves the NDVI estimates compared to learning an NDVI model from scratch. Additionally, we compare our results to other recent data-driven NDVI modeling approaches from machine learning and ecology literature. We further provide experimental evidence on how much data and training time is necessary to turn FourCastNet into an effective vegetation model. Code and models will be made available upon publication.
UniDepth: Universal Monocular Metric Depth Estimation
Mar 27, 2024Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepth, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE methods, UniDepth directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepth implements a self-promptable camera module predicting dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. Thorough evaluations on ten datasets in a zero-shot regime consistently demonstrate the superior performance of UniDepth, even when compared with methods directly trained on the testing domains. Code and models are available at: https://github.com/lpiccinelli-eth/unidepth
Leveraging Large Language Models for Relevance Judgments in Legal Case Retrieval
Mar 27, 2024Collecting relevant judgments for legal case retrieval is a challenging and time-consuming task. Accurately judging the relevance between two legal cases requires a considerable effort to read the lengthy text and a high level of domain expertise to extract Legal Facts and make juridical judgments. With the advent of advanced large language models, some recent studies have suggested that it is promising to use LLMs for relevance judgment. Nonetheless, the method of employing a general large language model for reliable relevance judgments in legal case retrieval is yet to be thoroughly explored. To fill this research gap, we devise a novel few-shot workflow tailored to the relevant judgment of legal cases. The proposed workflow breaks down the annotation process into a series of stages, imitating the process employed by human annotators and enabling a flexible integration of expert reasoning to enhance the accuracy of relevance judgments. By comparing the relevance judgments of LLMs and human experts, we empirically show that we can obtain reliable relevance judgments with the proposed workflow. Furthermore, we demonstrate the capacity to augment existing legal case retrieval models through the synthesis of data generated by the large language model.
S+t-SNE -- Bringing dimensionality reduction to data streams
Mar 26, 2024We present S+t-SNE, an adaptation of the t-SNE algorithm designed to handle infinite data streams. The core idea behind S+t-SNE is to update the t-SNE embedding incrementally as new data arrives, ensuring scalability and adaptability to handle streaming scenarios. By selecting the most important points at each step, the algorithm ensures scalability while keeping informative visualisations. Employing a blind method for drift management adjusts the embedding space, facilitating continuous visualisation of evolving data dynamics. Our experimental evaluations demonstrate the effectiveness and efficiency of S+t-SNE. The results highlight its ability to capture patterns in a streaming scenario. We hope our approach offers researchers and practitioners a real-time tool for understanding and interpreting high-dimensional data.