 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable Real-Time Vehicle Deformation for Interactive Environments
Apr 11, 2023
This paper proposes a real-time physically-based method for simulating vehicle deformation. Our system synthesizes vehicle deformation characteristics by considering a low-dimensional coupled vehicle body technique. We simulate the motion and crumbling behavior of vehicles smashing into rigid objects. We explain and demonstrate the combination of a reduced complexity non-linear finite element system that is scalable and computationally efficient. We use an explicit position-based integration scheme to improve simulation speeds, while remaining stable and preserving modeling accuracy. We show our approach using a variety of vehicle deformation test cases which were simulated in real-time.
No-frills Temporal Video Grounding: Multi-Scale Neighboring Attention and Zoom-in Boundary Detection
Jul 20, 2023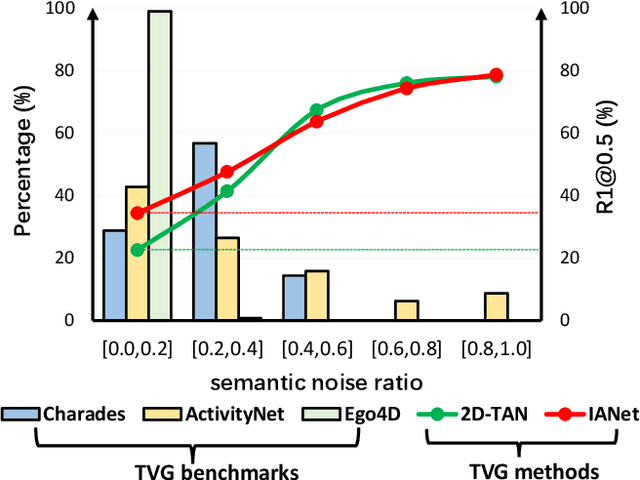
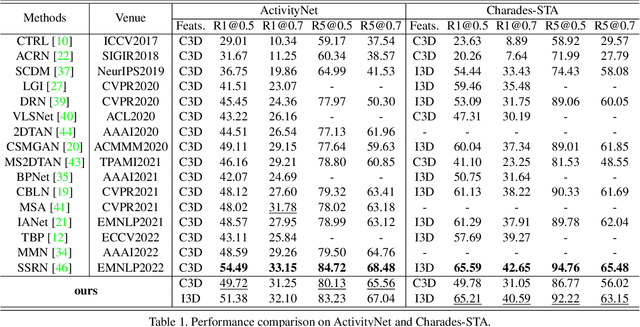
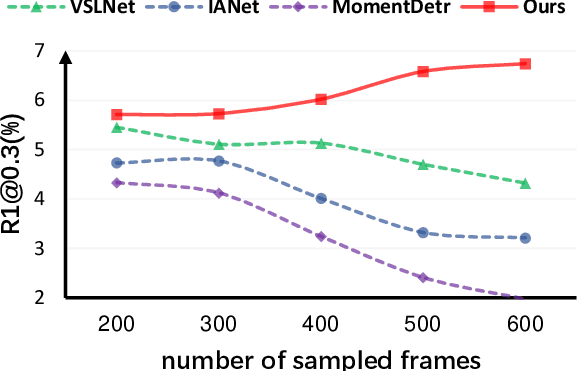
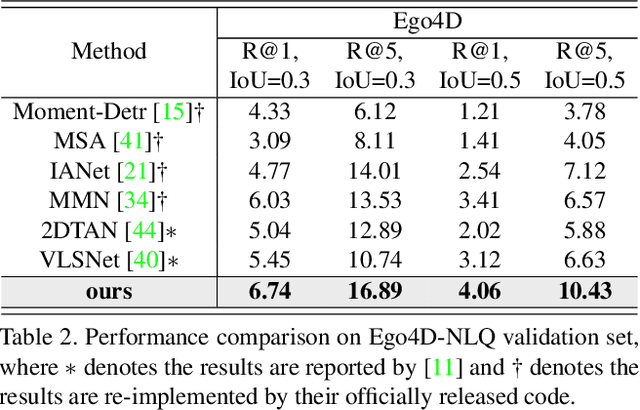
Temporal video grounding (TVG) aims to retrieve the time interval of a language query from an untrimmed video. A significant challenge in TVG is the low "Semantic Noise Ratio (SNR)", which results in worse performance with lower SNR. Prior works have addressed this challenge using sophisticated techniques. In this paper, we propose a no-frills TVG model that consists of two core modules, namely multi-scale neighboring attention and zoom-in boundary detection. The multi-scale neighboring attention restricts each video token to only aggregate visual contexts from its neighbor, enabling the extraction of the most distinguishing information with multi-scale feature hierarchies from high-ratio noises. The zoom-in boundary detection then focuses on local-wise discrimination of the selected top candidates for fine-grained grounding adjustment. With an end-to-end training strategy, our model achieves competitive performance on different TVG benchmarks, while also having the advantage of faster inference speed and lighter model parameters, thanks to its lightweight architecture.
Quantized Feature Distillation for Network Quantization
Jul 20, 2023
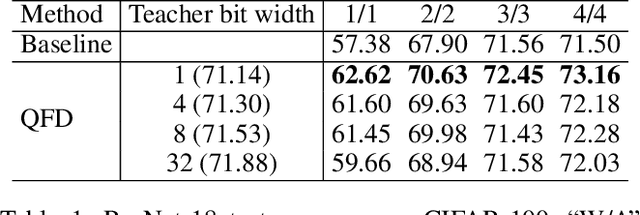
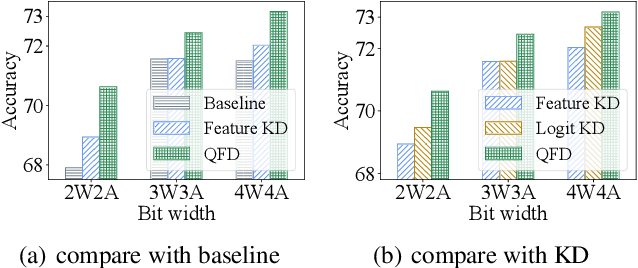
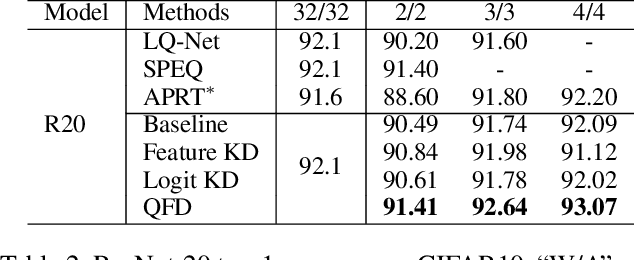
Neural network quantization aims to accelerate and trim full-precision neural network models by using low bit approximations. Methods adopting the quantization aware training (QAT) paradigm have recently seen a rapid growth, but are often conceptually complicated. This paper proposes a novel and highly effective QAT method, quantized feature distillation (QFD). QFD first trains a quantized (or binarized) representation as the teacher, then quantize the network using knowledge distillation (KD). Quantitative results show that QFD is more flexible and effective (i.e., quantization friendly) than previous quantization methods. QFD surpasses existing methods by a noticeable margin on not only image classification but also object detection, albeit being much simpler. Furthermore, QFD quantizes ViT and Swin-Transformer on MS-COCO detection and segmentation, which verifies its potential in real world deployment. To the best of our knowledge, this is the first time that vision transformers have been quantized in object detection and image segmentation tasks.
Automatic Search for Photoacoustic Marker Using Automated Transrectal Ultrasound
Jul 20, 2023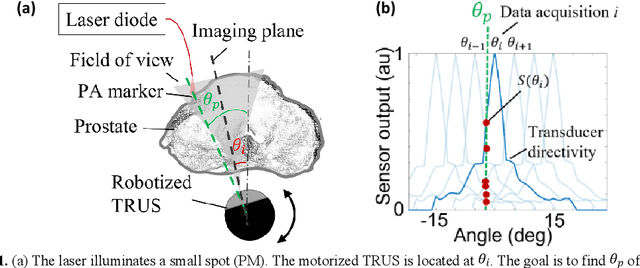
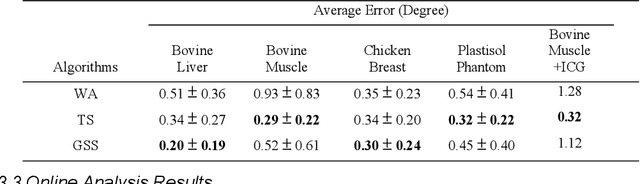
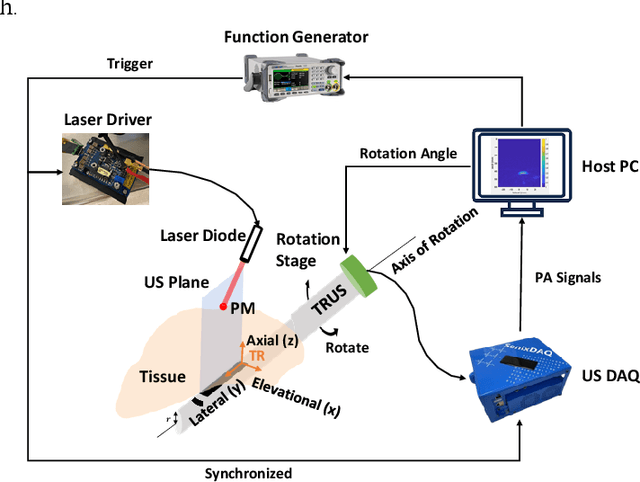
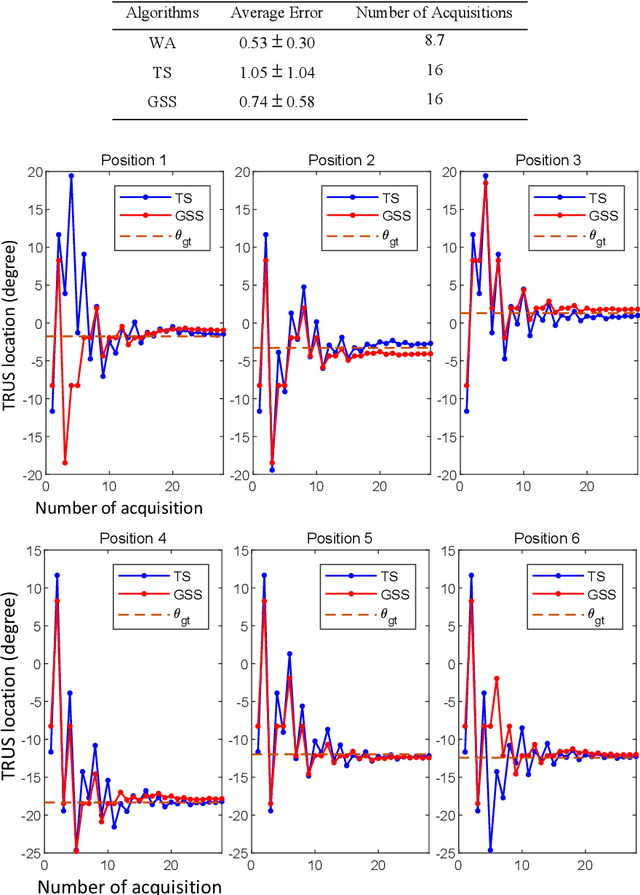
Real-time transrectal ultrasound (TRUS) image guidance during robot-assisted laparoscopic radical prostatectomy has the potential to enhance surgery outcomes. Whether conventional or photoacoustic TRUS is used, the robotic system and the TRUS must be registered to each other. Accurate registration can be performed using photoacoustic (PA markers). However, this requires a manual search by an assistant [19]. This paper introduces the first automatic search for PA markers using a transrectal ultrasound robot. This effectively reduces the challenges associated with the da Vinci-TRUS registration. This paper investigated the performance of three search algorithms in simulation and experiment: Weighted Average (WA), Golden Section Search (GSS), and Ternary Search (TS). For validation, a surgical prostate scenario was mimicked and various ex vivo tissues were tested. As a result, the WA algorithm can achieve 0.53 degree average error after 9 data acquisitions, while the TS and GSS algorithm can achieve 0.29 degree and 0.48 degree average errors after 28 data acquisitions.
Learning and Evaluating Human Preferences for Conversational Head Generation
Jul 20, 2023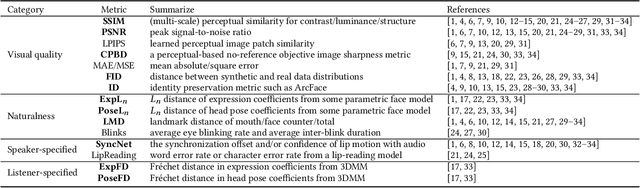
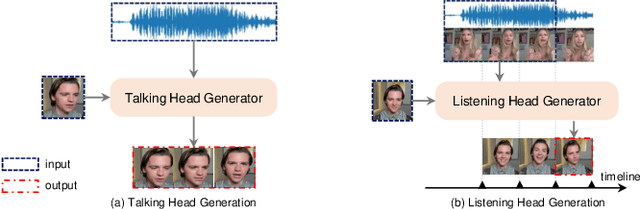
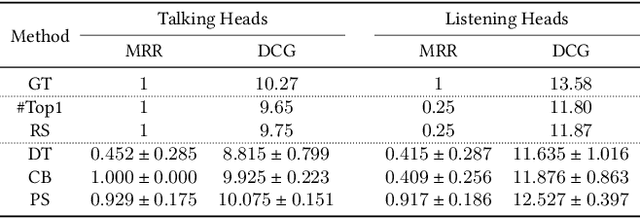
A reliable and comprehensive evaluation metric that aligns with manual preference assessments is crucial for conversational head video synthesis method development. Existing quantitative evaluations often fail to capture the full complexity of human preference, as they only consider limited evaluation dimensions. Qualitative evaluations and user studies offer a solution but are time-consuming and labor-intensive. This limitation hinders the advancement of conversational head generation algorithms and systems. In this paper, we propose a novel learning-based evaluation metric named Preference Score (PS) for fitting human preference according to the quantitative evaluations across different dimensions. PS can serve as a quantitative evaluation without the need for human annotation. Experimental results validate the superiority of Preference Score in aligning with human perception, and also demonstrates robustness and generalizability to unseen data, making it a valuable tool for advancing conversation head generation. We expect this metric could facilitate new advances in conversational head generation.
Signal Identification and Entrainment for Practical FMCW Radar Spoofing Attacks
Jul 20, 2023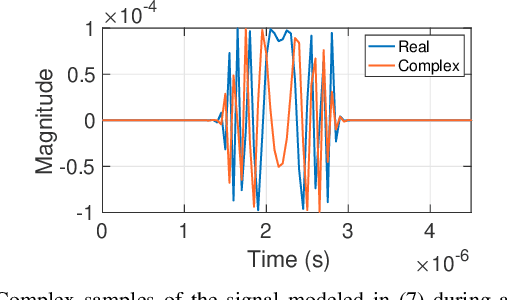
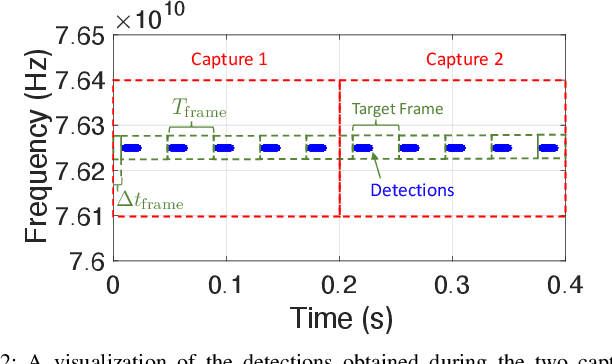
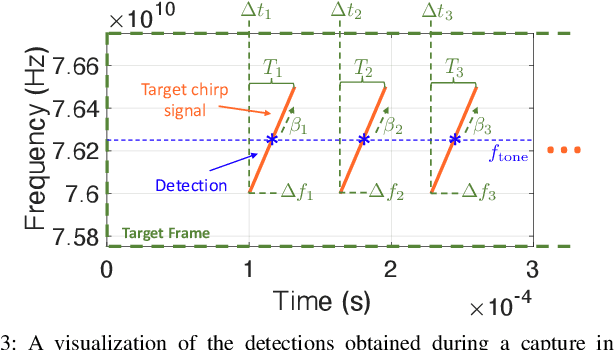
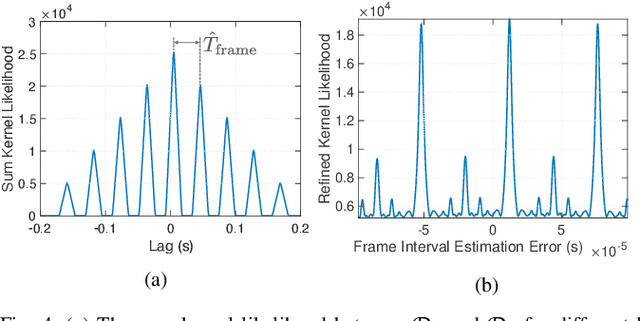
This paper proposes a method of passively estimating the parameters of frequency-modulated-continuous-wave (FMCW) radar signals with a wide range of structural parameter values and analyzes how a malicious actor could employ such estimates to track and spoof a target radar. When radars are implemented to support automated driver assistance systems, an intelligent spoofer has the potential to substantially disrupt safe navigation by inducing its target to perceive false objects. Such a spoofer must acquire highly accurate estimates of the target radar's chirp sweep, timing, and frequency parameters while additionally tracking and compensating for time and Doppler shifts due to clock errors and relative movement. This is a difficult task for millimeter-wave radars due to severe Doppler shifts and fast sweep rates, especially when the spoofer uses off-the-shelf FMCW equipment. Algorithms and techniques for acquiring and tracking an FMCW radar are proposed and verified through simulation, which will help guide future decisions on appropriate radar spoofing countermeasures.
WEPRO: Weight Prediction for Efficient Optimization of Hybrid Quantum-Classical Algorithms
Jul 23, 2023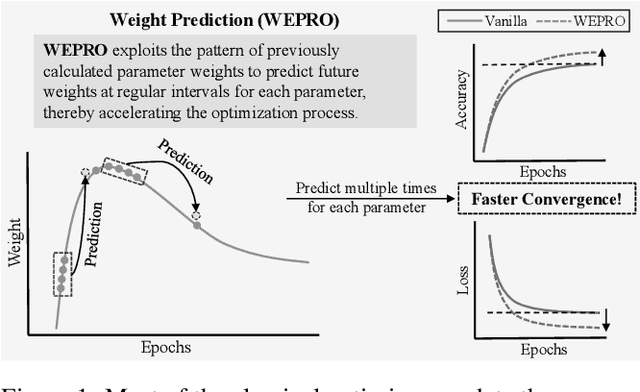
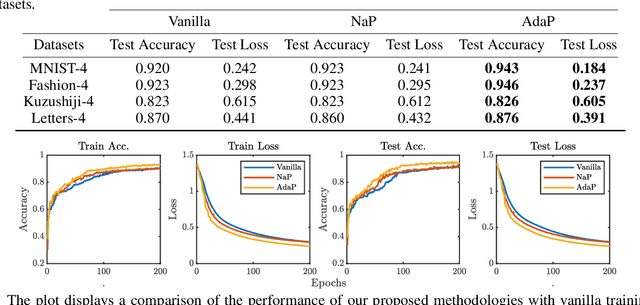
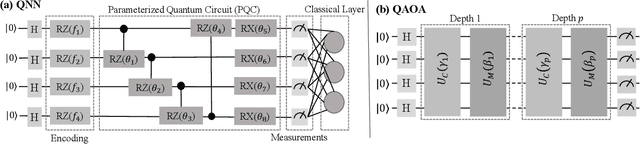
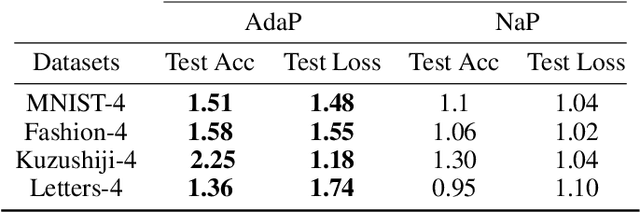
The exponential run time of quantum simulators on classical machines and long queue depths and high costs of real quantum devices present significant challenges in the effective training of Variational Quantum Algorithms (VQAs) like Quantum Neural Networks (QNNs), Variational Quantum Eigensolver (VQE) and Quantum Approximate Optimization Algorithm (QAOA). To address these limitations, we propose a new approach, WEPRO (Weight Prediction), which accelerates the convergence of VQAs by exploiting regular trends in the parameter weights. We introduce two techniques for optimal prediction performance namely, Naive Prediction (NaP) and Adaptive Prediction (AdaP). Through extensive experimentation and training of multiple QNN models on various datasets, we demonstrate that WEPRO offers a speedup of approximately $2.25\times$ compared to standard training methods, while also providing improved accuracy (up to $2.3\%$ higher) and loss (up to $6.1\%$ lower) with low storage and computational overheads. We also evaluate WEPRO's effectiveness in VQE for molecular ground-state energy estimation and in QAOA for graph MaxCut. Our results show that WEPRO leads to speed improvements of up to $3.1\times$ for VQE and $2.91\times$ for QAOA, compared to traditional optimization techniques, while using up to $3.3\times$ less number of shots (i.e., repeated circuit executions) per training iteration.
An Examination of Wearable Sensors and Video Data Capture for Human Exercise Classification
Jul 10, 2023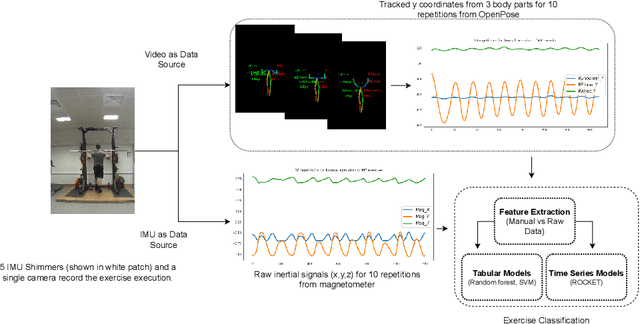


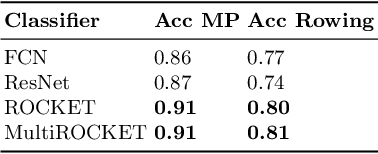
Wearable sensors such as Inertial Measurement Units (IMUs) are often used to assess the performance of human exercise. Common approaches use handcrafted features based on domain expertise or automatically extracted features using time series analysis. Multiple sensors are required to achieve high classification accuracy, which is not very practical. These sensors require calibration and synchronization and may lead to discomfort over longer time periods. Recent work utilizing computer vision techniques has shown similar performance using video, without the need for manual feature engineering, and avoiding some pitfalls such as sensor calibration and placement on the body. In this paper, we compare the performance of IMUs to a video-based approach for human exercise classification on two real-world datasets consisting of Military Press and Rowing exercises. We compare the performance using a single camera that captures video in the frontal view versus using 5 IMUs placed on different parts of the body. We observe that an approach based on a single camera can outperform a single IMU by 10 percentage points on average. Additionally, a minimum of 3 IMUs are required to outperform a single camera. We observe that working with the raw data using multivariate time series classifiers outperforms traditional approaches based on handcrafted or automatically extracted features. Finally, we show that an ensemble model combining the data from a single camera with a single IMU outperforms either data modality. Our work opens up new and more realistic avenues for this application, where a video captured using a readily available smartphone camera, combined with a single sensor, can be used for effective human exercise classification.
Integration of Domain Expert-Centric Ontology Design into the CRISP-DM for Cyber-Physical Production Systems
Jul 21, 2023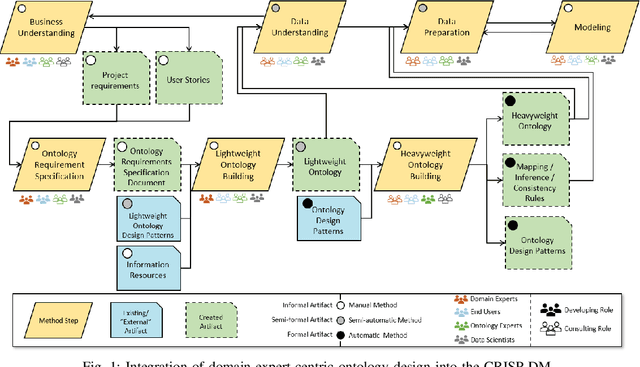
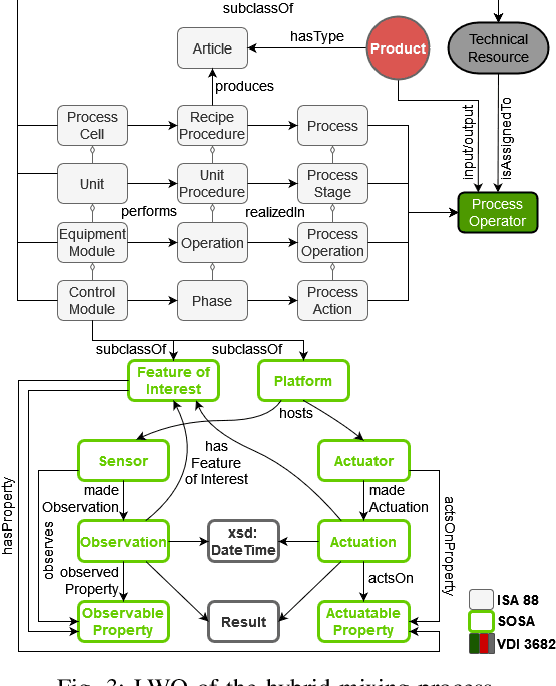
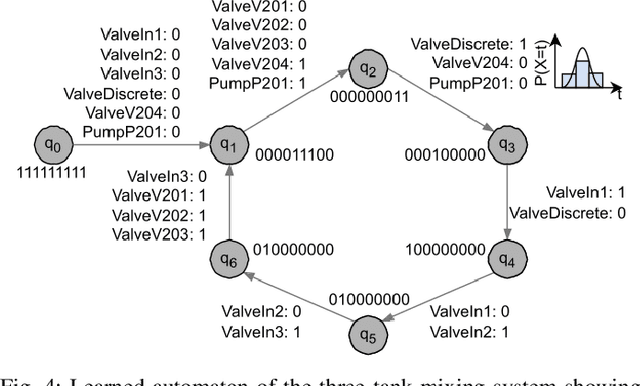
In the age of Industry 4.0 and Cyber-Physical Production Systems (CPPSs) vast amounts of potentially valuable data are being generated. Methods from Machine Learning (ML) and Data Mining (DM) have proven to be promising in extracting complex and hidden patterns from the data collected. The knowledge obtained can in turn be used to improve tasks like diagnostics or maintenance planning. However, such data-driven projects, usually performed with the Cross-Industry Standard Process for Data Mining (CRISP-DM), often fail due to the disproportionate amount of time needed for understanding and preparing the data. The application of domain-specific ontologies has demonstrated its advantageousness in a wide variety of Industry 4.0 application scenarios regarding the aforementioned challenges. However, workflows and artifacts from ontology design for CPPSs have not yet been systematically integrated into the CRISP-DM. Accordingly, this contribution intends to present an integrated approach so that data scientists are able to more quickly and reliably gain insights into the CPPS. The result is exemplarily applied to an anomaly detection use case.
Adaptive ResNet Architecture for Distributed Inference in Resource-Constrained IoT Systems
Jul 21, 2023As deep neural networks continue to expand and become more complex, most edge devices are unable to handle their extensive processing requirements. Therefore, the concept of distributed inference is essential to distribute the neural network among a cluster of nodes. However, distribution may lead to additional energy consumption and dependency among devices that suffer from unstable transmission rates. Unstable transmission rates harm real-time performance of IoT devices causing low latency, high energy usage, and potential failures. Hence, for dynamic systems, it is necessary to have a resilient DNN with an adaptive architecture that can downsize as per the available resources. This paper presents an empirical study that identifies the connections in ResNet that can be dropped without significantly impacting the model's performance to enable distribution in case of resource shortage. Based on the results, a multi-objective optimization problem is formulated to minimize latency and maximize accuracy as per available resources. Our experiments demonstrate that an adaptive ResNet architecture can reduce shared data, energy consumption, and latency throughout the distribution while maintaining high accuracy.