 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Tim
Aug 02, 2023
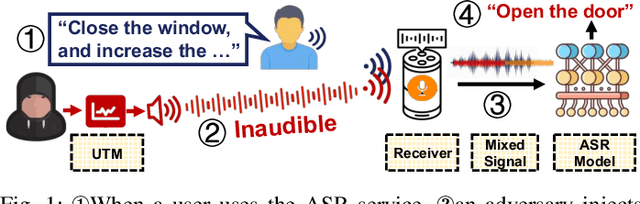
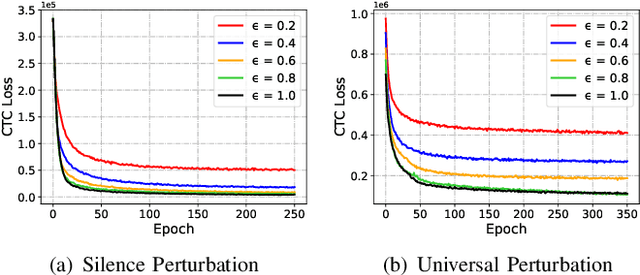
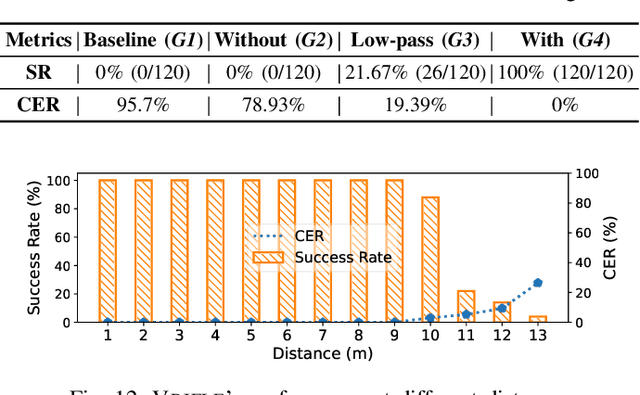
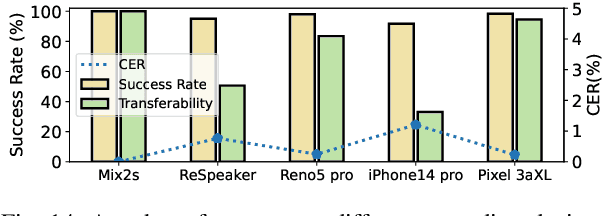
Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Nonconvex optimization for optimum retrieval of the transmission matrix of a multimode fiber
Aug 02, 2023Transmission matrix (TM) allows light control through complex media such as multimode fibers (MMFs), gaining great attention in areas like biophotonics over the past decade. The measurement of a complex-valued TM is highly desired as it supports full modulation of the light field, yet demanding as the holographic setup is usually entailed. Efforts have been taken to retrieve a TM directly from intensity measurements with several representative phase retrieval algorithms, which still see limitations like slow or suboptimum recovery, especially under noisy environment. Here, a modified non-convex optimization approach is proposed. Through numerical evaluations, it shows that the nonconvex method offers an optimum efficiency of focusing with less running time or sampling rate. The comparative test under different signal-to-noise levels further indicates its improved robustness for TM retrieval. Experimentally, the optimum retrieval of the TM of a MMF is collectively validated by multiple groups of single-spot and multi-spot focusing demonstrations. Focus scanning on the working plane of the MMF is also conducted where our method achieves 93.6% efficiency of the gold standard holography method when the sampling rate is 8. Based on the recovered TM, image transmission through the MMF with high fidelity can be realized via another phase retrieval. Thanks to parallel operation and GPU acceleration, the nonconvex approach can retrieve an 8685$\times$1024 TM (sampling rate=8) with 42.3 s on a regular computer. In brief, the proposed method provides optimum efficiency and fast implementation for TM retrieval, which will facilitate wide applications in deep-tissue optical imaging, manipulation and treatment.
The Marginal Value of Momentum for Small Learning Rate SGD
Jul 27, 2023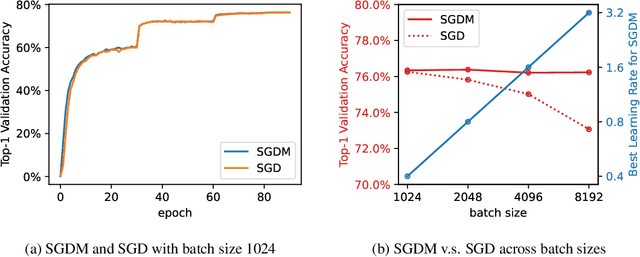

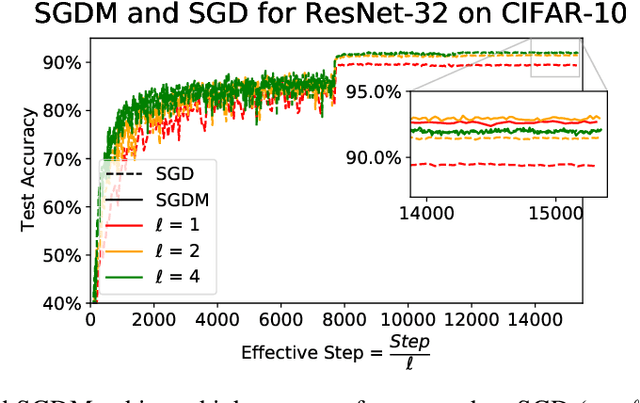
Momentum is known to accelerate the convergence of gradient descent in strongly convex settings without stochastic gradient noise. In stochastic optimization, such as training neural networks, folklore suggests that momentum may help deep learning optimization by reducing the variance of the stochastic gradient update, but previous theoretical analyses do not find momentum to offer any provable acceleration. Theoretical results in this paper clarify the role of momentum in stochastic settings where the learning rate is small and gradient noise is the dominant source of instability, suggesting that SGD with and without momentum behave similarly in the short and long time horizons. Experiments show that momentum indeed has limited benefits for both optimization and generalization in practical training regimes where the optimal learning rate is not very large, including small- to medium-batch training from scratch on ImageNet and fine-tuning language models on downstream tasks.
MIM-OOD: Generative Masked Image Modelling for Out-of-Distribution Detection in Medical Images
Jul 27, 2023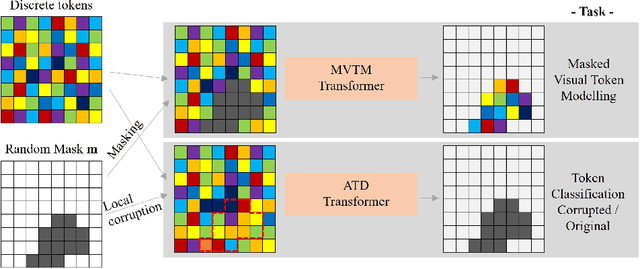

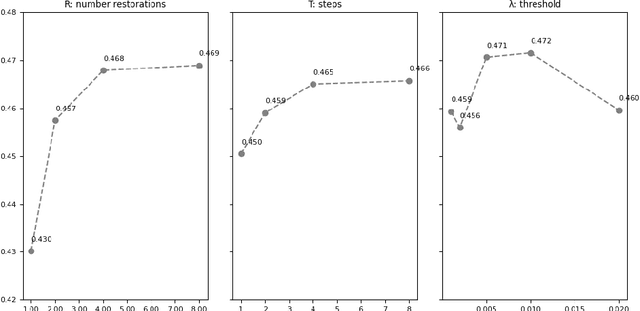
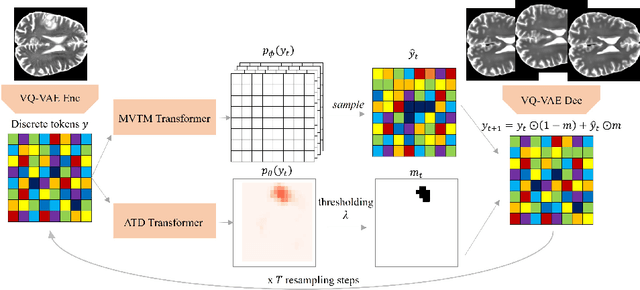
Unsupervised Out-of-Distribution (OOD) detection consists in identifying anomalous regions in images leveraging only models trained on images of healthy anatomy. An established approach is to tokenize images and model the distribution of tokens with Auto-Regressive (AR) models. AR models are used to 1) identify anomalous tokens and 2) in-paint anomalous representations with in-distribution tokens. However, AR models are slow at inference time and prone to error accumulation issues which negatively affect OOD detection performance. Our novel method, MIM-OOD, overcomes both speed and error accumulation issues by replacing the AR model with two task-specific networks: 1) a transformer optimized to identify anomalous tokens and 2) a transformer optimized to in-paint anomalous tokens using masked image modelling (MIM). Our experiments with brain MRI anomalies show that MIM-OOD substantially outperforms AR models (DICE 0.458 vs 0.301) while achieving a nearly 25x speedup (9.5s vs 244s).
Functional PCA and Deep Neural Networks-based Bayesian Inverse Uncertainty Quantification with Transient Experimental Data
Jul 10, 2023Inverse UQ is the process to inversely quantify the model input uncertainties based on experimental data. This work focuses on developing an inverse UQ process for time-dependent responses, using dimensionality reduction by functional principal component analysis (PCA) and deep neural network (DNN)-based surrogate models. The demonstration is based on the inverse UQ of TRACE physical model parameters using the FEBA transient experimental data. The measurement data is time-dependent peak cladding temperature (PCT). Since the quantity-of-interest (QoI) is time-dependent that corresponds to infinite-dimensional responses, PCA is used to reduce the QoI dimension while preserving the transient profile of the PCT, in order to make the inverse UQ process more efficient. However, conventional PCA applied directly to the PCT time series profiles can hardly represent the data precisely due to the sudden temperature drop at the time of quenching. As a result, a functional alignment method is used to separate the phase and amplitude information of the transient PCT profiles before dimensionality reduction. DNNs are then trained using PC scores from functional PCA to build surrogate models of TRACE in order to reduce the computational cost in Markov Chain Monte Carlo sampling. Bayesian neural networks are used to estimate the uncertainties of DNN surrogate model predictions. In this study, we compared four different inverse UQ processes with different dimensionality reduction methods and surrogate models. The proposed approach shows an improvement in reducing the dimension of the TRACE transient simulations, and the forward propagation of inverse UQ results has a better agreement with the experimental data.
SkullGAN: Synthetic Skull CT Generation with Generative Adversarial Networks
Aug 01, 2023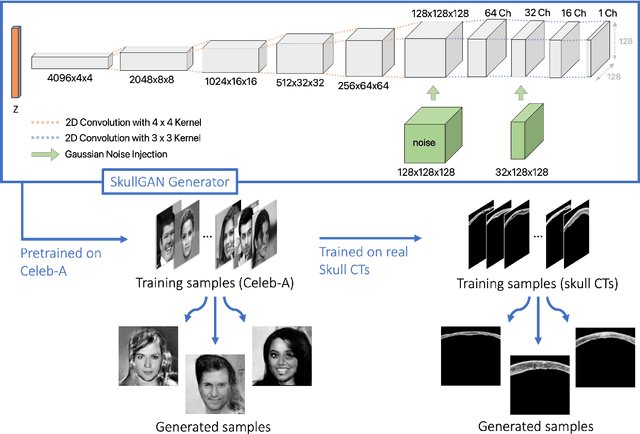
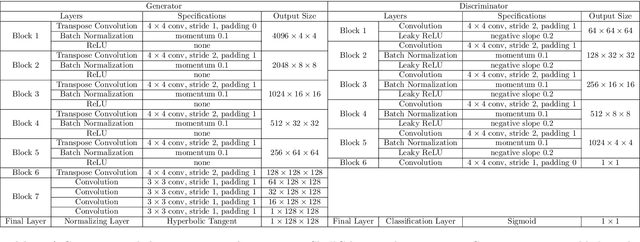
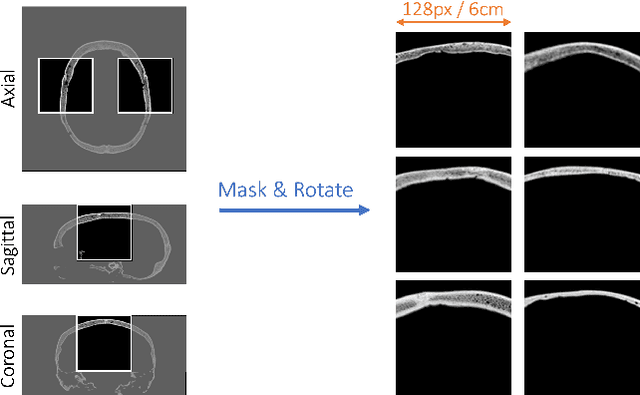
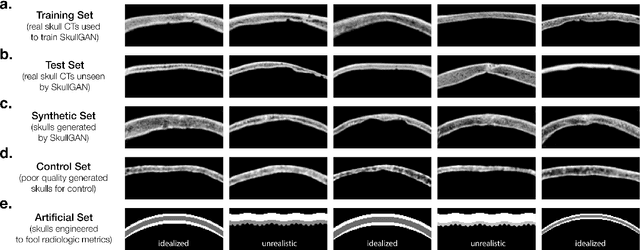
Deep learning offers potential for various healthcare applications involving the human skull but requires extensive datasets of curated medical images. To overcome this challenge, we propose SkullGAN, a generative adversarial network (GAN), to create large datasets of synthetic skull CT slices, reducing reliance on real images and accelerating the integration of machine learning into healthcare. In our method, CT slices of 38 subjects were fed to SkullGAN, a neural network comprising over 200 million parameters. The synthetic skull images generated were evaluated based on three quantitative radiological features: skull density ratio (SDR), mean thickness, and mean intensity. They were further analyzed using t-distributed stochastic neighbor embedding (t-SNE) and by applying the SkullGAN discriminator as a classifier. The results showed that SkullGAN-generated images demonstrated similar key quantitative radiological features to real skulls. Further definitive analysis was undertaken by applying the discriminator of SkullGAN, where the SkullGAN discriminator classified 56.5% of a test set of real skull images and 55.9% of the SkullGAN-generated images as reals (the theoretical optimum being 50%), demonstrating that the SkullGAN-generated skull set is indistinguishable from the real skull set - within the limits of our nonlinear classifier. Therefore, SkullGAN makes it possible to generate large numbers of synthetic skull CT segments, necessary for training neural networks for medical applications involving the human skull. This mitigates challenges associated with preparing large, high-quality training datasets, such as access, capital, time, and the need for domain expertise.
Meta-Transformer: A Unified Framework for Multimodal Learning
Jul 20, 2023
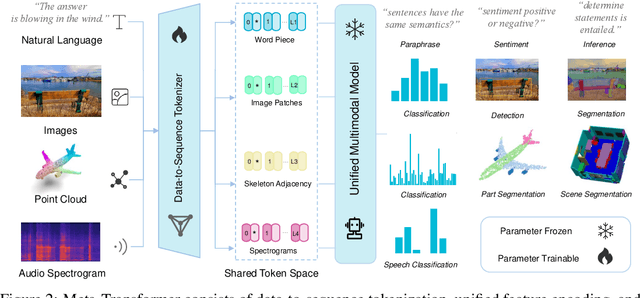
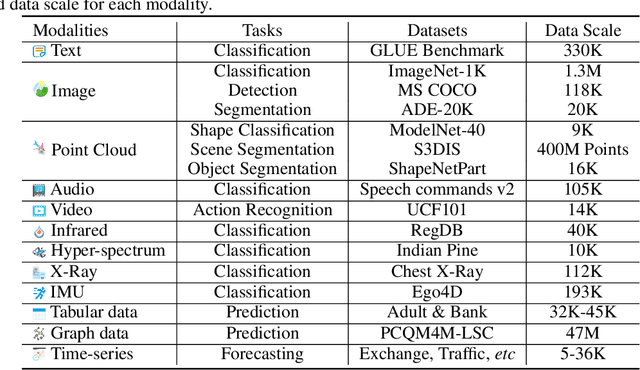
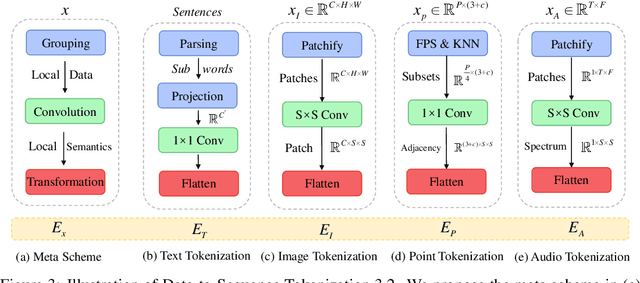
Multimodal learning aims to build models that can process and relate information from multiple modalities. Despite years of development in this field, it still remains challenging to design a unified network for processing various modalities ($\textit{e.g.}$ natural language, 2D images, 3D point clouds, audio, video, time series, tabular data) due to the inherent gaps among them. In this work, we propose a framework, named Meta-Transformer, that leverages a $\textbf{frozen}$ encoder to perform multimodal perception without any paired multimodal training data. In Meta-Transformer, the raw input data from various modalities are mapped into a shared token space, allowing a subsequent encoder with frozen parameters to extract high-level semantic features of the input data. Composed of three main components: a unified data tokenizer, a modality-shared encoder, and task-specific heads for downstream tasks, Meta-Transformer is the first framework to perform unified learning across 12 modalities with unpaired data. Experiments on different benchmarks reveal that Meta-Transformer can handle a wide range of tasks including fundamental perception (text, image, point cloud, audio, video), practical application (X-Ray, infrared, hyperspectral, and IMU), and data mining (graph, tabular, and time-series). Meta-Transformer indicates a promising future for developing unified multimodal intelligence with transformers. Code will be available at https://github.com/invictus717/MetaTransformer
Neuron Sensitivity Guided Test Case Selection for Deep Learning Testing
Jul 20, 2023Deep Neural Networks~(DNNs) have been widely deployed in software to address various tasks~(e.g., autonomous driving, medical diagnosis). However, they could also produce incorrect behaviors that result in financial losses and even threaten human safety. To reveal the incorrect behaviors in DNN and repair them, DNN developers often collect rich unlabeled datasets from the natural world and label them to test the DNN models. However, properly labeling a large number of unlabeled datasets is a highly expensive and time-consuming task. To address the above-mentioned problem, we propose NSS, Neuron Sensitivity guided test case Selection, which can reduce the labeling time by selecting valuable test cases from unlabeled datasets. NSS leverages the internal neuron's information induced by test cases to select valuable test cases, which have high confidence in causing the model to behave incorrectly. We evaluate NSS with four widely used datasets and four well-designed DNN models compared to SOTA baseline methods. The results show that NSS performs well in assessing the test cases' probability of fault triggering and model improvement capabilities. Specifically, compared with baseline approaches, NSS obtains a higher fault detection rate~(e.g., when selecting 5\% test case from the unlabeled dataset in MNIST \& LeNet1 experiment, NSS can obtain 81.8\% fault detection rate, 20\% higher than baselines).
Non-Stationary Policy Learning for Multi-Timescale Multi-Agent Reinforcement Learning
Jul 17, 2023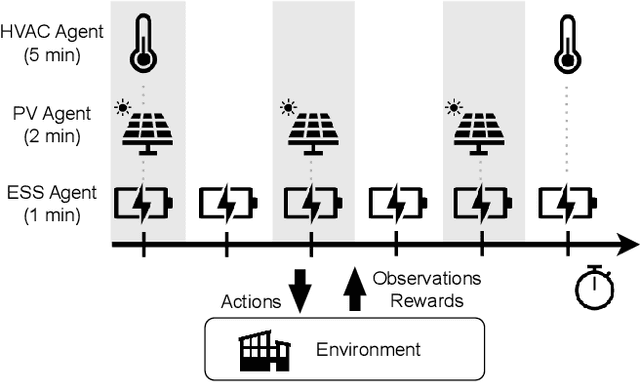
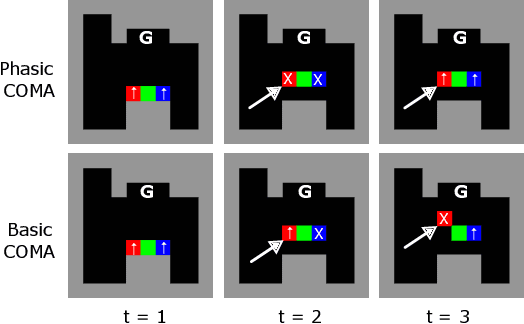
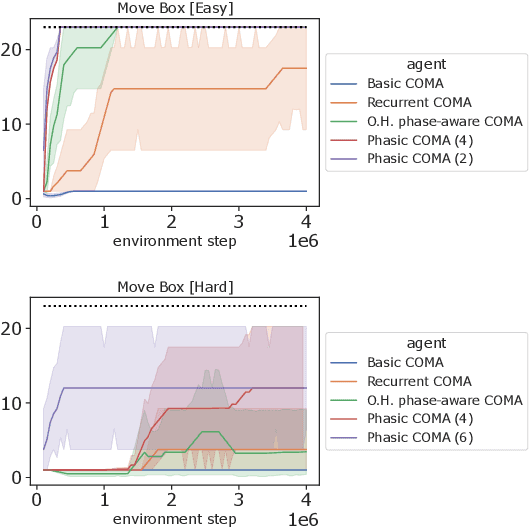
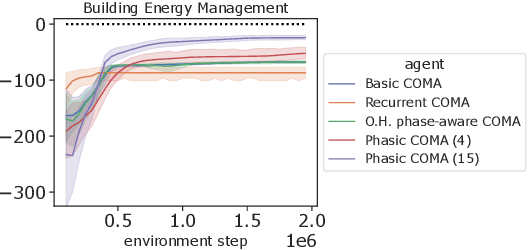
In multi-timescale multi-agent reinforcement learning (MARL), agents interact across different timescales. In general, policies for time-dependent behaviors, such as those induced by multiple timescales, are non-stationary. Learning non-stationary policies is challenging and typically requires sophisticated or inefficient algorithms. Motivated by the prevalence of this control problem in real-world complex systems, we introduce a simple framework for learning non-stationary policies for multi-timescale MARL. Our approach uses available information about agent timescales to define a periodic time encoding. In detail, we theoretically demonstrate that the effects of non-stationarity introduced by multiple timescales can be learned by a periodic multi-agent policy. To learn such policies, we propose a policy gradient algorithm that parameterizes the actor and critic with phase-functioned neural networks, which provide an inductive bias for periodicity. The framework's ability to effectively learn multi-timescale policies is validated on a gridworld and building energy management environment.
BERRY: Bit Error Robustness for Energy-Efficient Reinforcement Learning-Based Autonomous Systems
Jul 19, 2023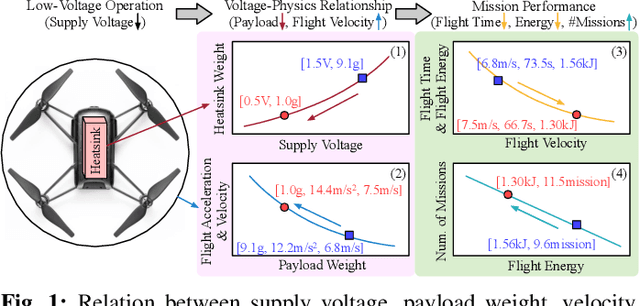
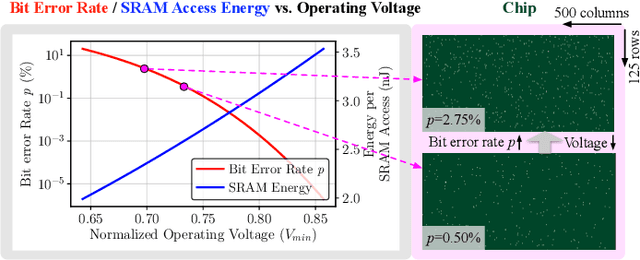
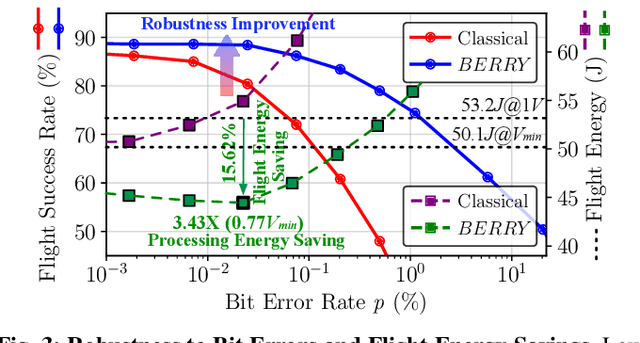
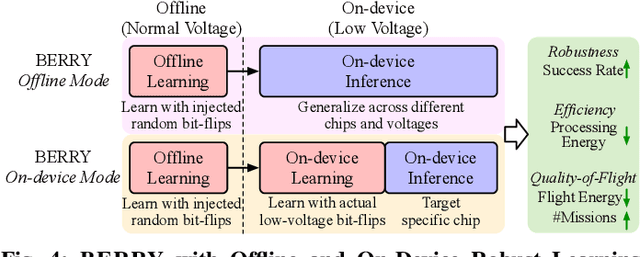
Autonomous systems, such as Unmanned Aerial Vehicles (UAVs), are expected to run complex reinforcement learning (RL) models to execute fully autonomous position-navigation-time tasks within stringent onboard weight and power constraints. We observe that reducing onboard operating voltage can benefit the energy efficiency of both the computation and flight mission, however, it can also result in on-chip bit failures that are detrimental to mission safety and performance. To this end, we propose BERRY, a robust learning framework to improve bit error robustness and energy efficiency for RL-enabled autonomous systems. BERRY supports robust learning, both offline and on-board the UAV, and for the first time, demonstrates the practicality of robust low-voltage operation on UAVs that leads to high energy savings in both compute-level operation and system-level quality-of-flight. We perform extensive experiments on 72 autonomous navigation scenarios and demonstrate that BERRY generalizes well across environments, UAVs, autonomy policies, operating voltages and fault patterns, and consistently improves robustness, efficiency and mission performance, achieving up to 15.62% reduction in flight energy, 18.51% increase in the number of successful missions, and 3.43x processing energy reduction.