 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable Cost-Sensitive Deep Neural Networks for Brain Tumor Detection from Brain MRI Images considering Data Imbalance
Aug 01, 2023
This paper presents a research study on the use of Convolutional Neural Network (CNN), ResNet50, InceptionV3, EfficientNetB0 and NASNetMobile models to efficiently detect brain tumors in order to reduce the time required for manual review of the report and create an automated system for classifying brain tumors. An automated pipeline is proposed, which encompasses five models: CNN, ResNet50, InceptionV3, EfficientNetB0 and NASNetMobile. The performance of the proposed architecture is evaluated on a balanced dataset and found to yield an accuracy of 99.33% for fine-tuned InceptionV3 model. Furthermore, Explainable AI approaches are incorporated to visualize the model's latent behavior in order to understand its black box behavior. To further optimize the training process, a cost-sensitive neural network approach has been proposed in order to work with imbalanced datasets which has achieved almost 4% more accuracy than the conventional models used in our experiments. The cost-sensitive InceptionV3 (CS-InceptionV3) and CNN (CS-CNN) show a promising accuracy of 92.31% and a recall value of 1.00 respectively on an imbalanced dataset. The proposed models have shown great potential in improving tumor detection accuracy and must be further developed for application in practical solutions. We have provided the datasets and made our implementations publicly available at - https://github.com/shahariar-shibli/Explainable-Cost-Sensitive-Deep-Neural-Networks-for-Brain-Tumor-Detection-from-Brain-MRI-Images
Variational Label-Correlation Enhancement for Congestion Prediction
Aug 01, 2023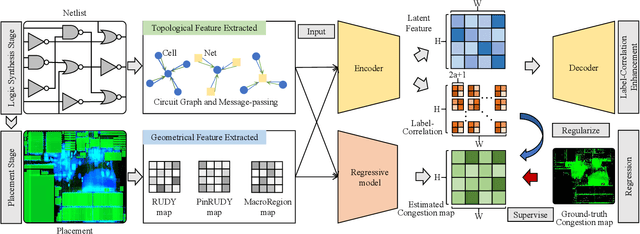
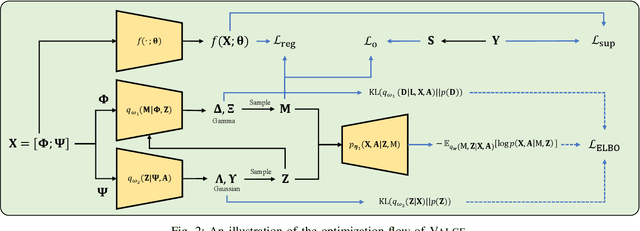

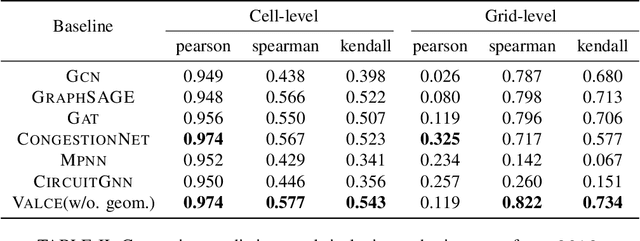
The physical design process of large-scale designs is a time-consuming task, often requiring hours to days to complete, with routing being the most critical and complex step. As the the complexity of Integrated Circuits (ICs) increases, there is an increased demand for accurate routing quality prediction. Accurate congestion prediction aids in identifying design flaws early on, thereby accelerating circuit design and conserving resources. Despite the advancements in current congestion prediction methodologies, an essential aspect that has been largely overlooked is the spatial label-correlation between different grids in congestion prediction. The spatial label-correlation is a fundamental characteristic of circuit design, where the congestion status of a grid is not isolated but inherently influenced by the conditions of its neighboring grids. In order to fully exploit the inherent spatial label-correlation between neighboring grids, we propose a novel approach, {\ours}, i.e., VAriational Label-Correlation Enhancement for Congestion Prediction, which considers the local label-correlation in the congestion map, associating the estimated congestion value of each grid with a local label-correlation weight influenced by its surrounding grids. {\ours} leverages variational inference techniques to estimate this weight, thereby enhancing the regression model's performance by incorporating spatial dependencies. Experiment results validate the superior effectiveness of {\ours} on the public available \texttt{ISPD2011} and \texttt{DAC2012} benchmarks using the superblue circuit line.
CyPhERS: A Cyber-Physical Event Reasoning System providing real-time situational awareness for attack and fault response
May 26, 2023
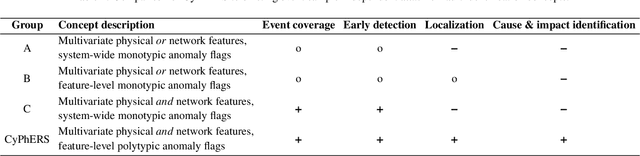
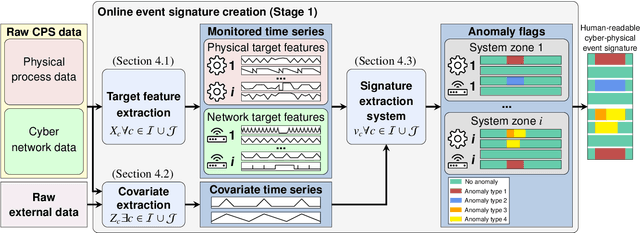

Cyber-physical systems (CPSs) constitute the backbone of critical infrastructures such as power grids or water distribution networks. Operating failures in these systems can cause serious risks for society. To avoid or minimize downtime, operators require real-time awareness about critical incidents. However, online event identification in CPSs is challenged by the complex interdependency of numerous physical and digital components, requiring to take cyber attacks and physical failures equally into account. The online event identification problem is further complicated through the lack of historical observations of critical but rare events, and the continuous evolution of cyber attack strategies. This work introduces and demonstrates CyPhERS, a Cyber-Physical Event Reasoning System. CyPhERS provides real-time information pertaining the occurrence, location, physical impact, and root cause of potentially critical events in CPSs, without the need for historical event observations. Key novelty of CyPhERS is the capability to generate informative and interpretable event signatures of known and unknown types of both cyber attacks and physical failures. The concept is evaluated and benchmarked on a demonstration case that comprises a multitude of attack and fault events targeting various components of a CPS. The results demonstrate that the event signatures provide relevant and inferable information on both known and unknown event types.
TrackAgent: 6D Object Tracking via Reinforcement Learning
Jul 28, 2023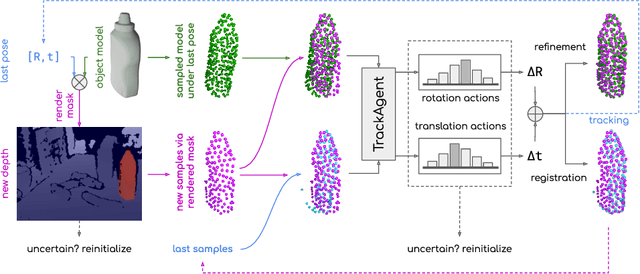
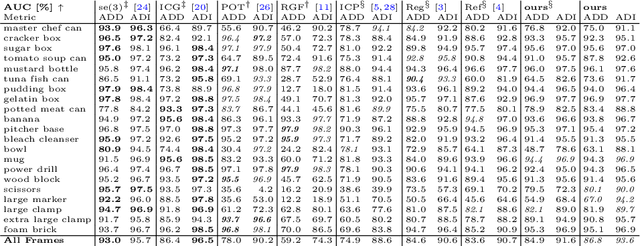
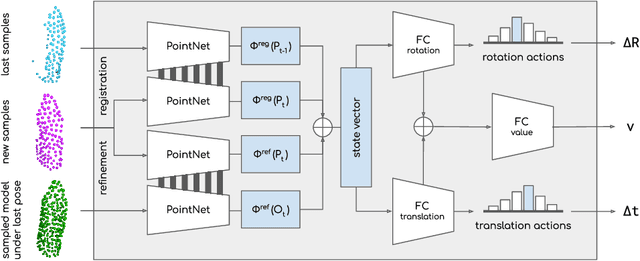
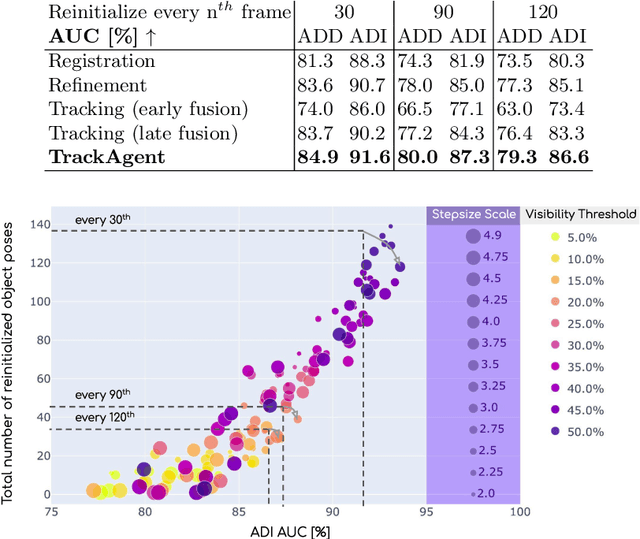
Tracking an object's 6D pose, while either the object itself or the observing camera is moving, is important for many robotics and augmented reality applications. While exploiting temporal priors eases this problem, object-specific knowledge is required to recover when tracking is lost. Under the tight time constraints of the tracking task, RGB(D)-based methods are often conceptionally complex or rely on heuristic motion models. In comparison, we propose to simplify object tracking to a reinforced point cloud (depth only) alignment task. This allows us to train a streamlined approach from scratch with limited amounts of sparse 3D point clouds, compared to the large datasets of diverse RGBD sequences required in previous works. We incorporate temporal frame-to-frame registration with object-based recovery by frame-to-model refinement using a reinforcement learning (RL) agent that jointly solves for both objectives. We also show that the RL agent's uncertainty and a rendering-based mask propagation are effective reinitialization triggers.
UniVTG: Towards Unified Video-Language Temporal Grounding
Jul 31, 2023
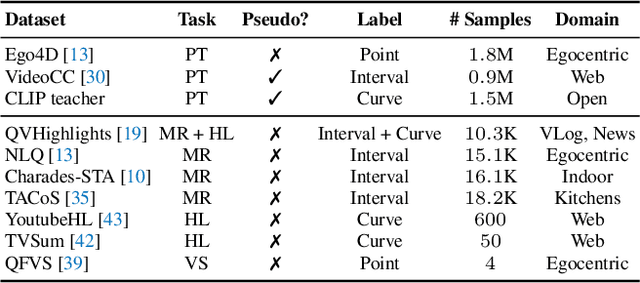
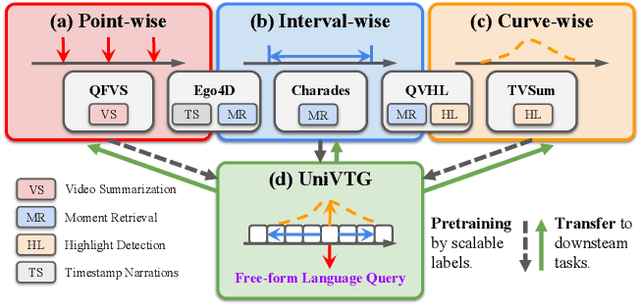
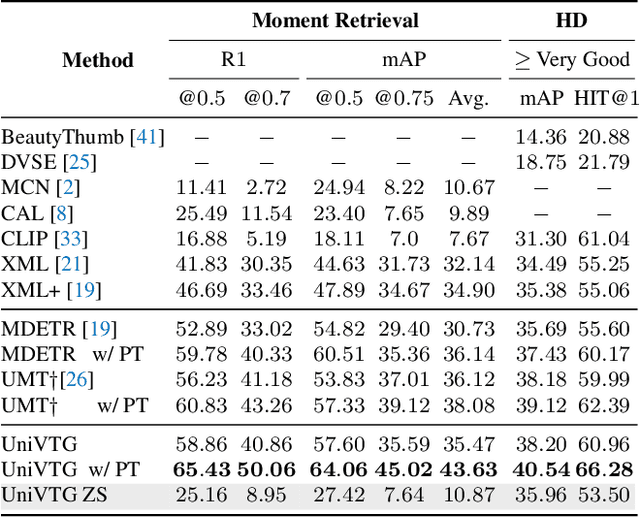
Video Temporal Grounding (VTG), which aims to ground target clips from videos (such as consecutive intervals or disjoint shots) according to custom language queries (e.g., sentences or words), is key for video browsing on social media. Most methods in this direction develop taskspecific models that are trained with type-specific labels, such as moment retrieval (time interval) and highlight detection (worthiness curve), which limits their abilities to generalize to various VTG tasks and labels. In this paper, we propose to Unify the diverse VTG labels and tasks, dubbed UniVTG, along three directions: Firstly, we revisit a wide range of VTG labels and tasks and define a unified formulation. Based on this, we develop data annotation schemes to create scalable pseudo supervision. Secondly, we develop an effective and flexible grounding model capable of addressing each task and making full use of each label. Lastly, thanks to the unified framework, we are able to unlock temporal grounding pretraining from large-scale diverse labels and develop stronger grounding abilities e.g., zero-shot grounding. Extensive experiments on three tasks (moment retrieval, highlight detection and video summarization) across seven datasets (QVHighlights, Charades-STA, TACoS, Ego4D, YouTube Highlights, TVSum, and QFVS) demonstrate the effectiveness and flexibility of our proposed framework. The codes are available at https://github.com/showlab/UniVTG.
Improving Primary Healthcare Workflow Using Extreme Summarization of Scientific Literature Based on Generative AI
Jul 24, 2023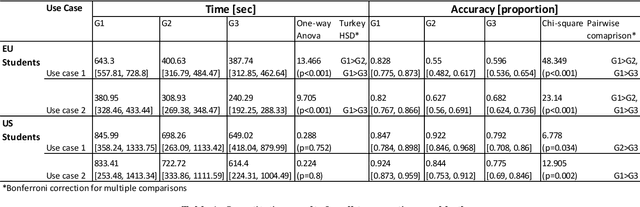

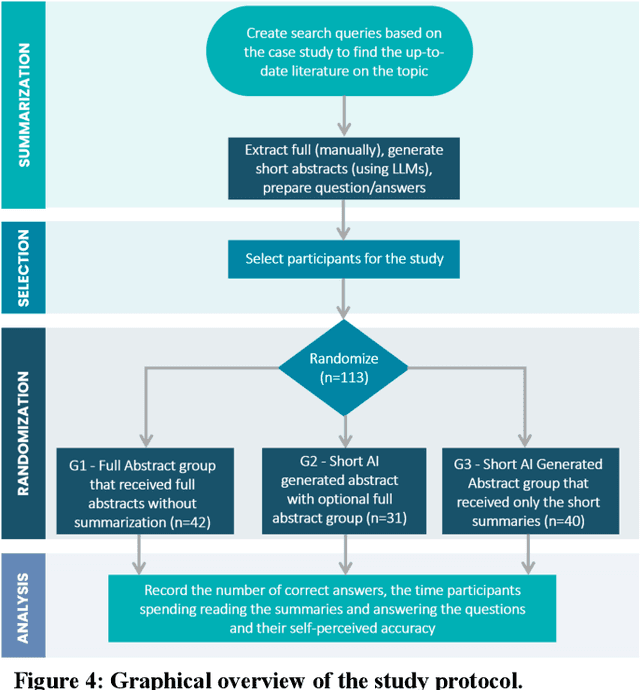
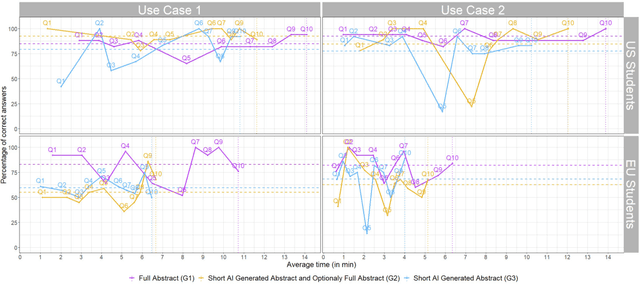
Primary care professionals struggle to keep up to date with the latest scientific literature critical in guiding evidence-based practice related to their daily work. To help solve the above-mentioned problem, we employed generative artificial intelligence techniques based on large-scale language models to summarize abstracts of scientific papers. Our objective is to investigate the potential of generative artificial intelligence in diminishing the cognitive load experienced by practitioners, thus exploring its ability to alleviate mental effort and burden. The study participants were provided with two use cases related to preventive care and behavior change, simulating a search for new scientific literature. The study included 113 university students from Slovenia and the United States randomized into three distinct study groups. The first group was assigned to the full abstracts. The second group was assigned to the short abstracts generated by AI. The third group had the option to select a full abstract in addition to the AI-generated short summary. Each use case study included ten retrieved abstracts. Our research demonstrates that the use of generative AI for literature review is efficient and effective. The time needed to answer questions related to the content of abstracts was significantly lower in groups two and three compared to the first group using full abstracts. The results, however, also show significantly lower accuracy in extracted knowledge in cases where full abstract was not available. Such a disruptive technology could significantly reduce the time required for healthcare professionals to keep up with the most recent scientific literature; nevertheless, further developments are needed to help them comprehend the knowledge accurately.
XMem++: Production-level Video Segmentation From Few Annotated Frames
Jul 29, 2023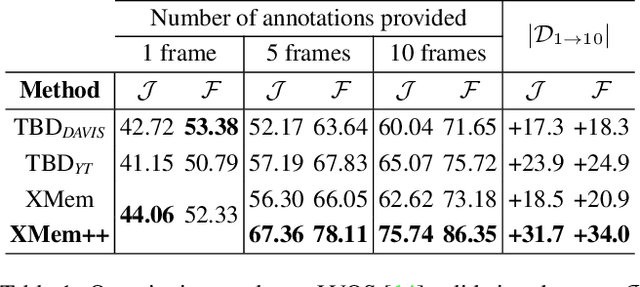

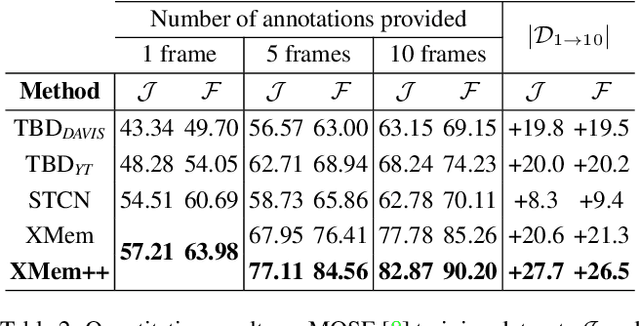
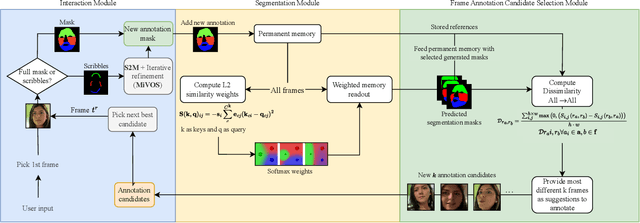
Despite advancements in user-guided video segmentation, extracting complex objects consistently for highly complex scenes is still a labor-intensive task, especially for production. It is not uncommon that a majority of frames need to be annotated. We introduce a novel semi-supervised video object segmentation (SSVOS) model, XMem++, that improves existing memory-based models, with a permanent memory module. Most existing methods focus on single frame annotations, while our approach can effectively handle multiple user-selected frames with varying appearances of the same object or region. Our method can extract highly consistent results while keeping the required number of frame annotations low. We further introduce an iterative and attention-based frame suggestion mechanism, which computes the next best frame for annotation. Our method is real-time and does not require retraining after each user input. We also introduce a new dataset, PUMaVOS, which covers new challenging use cases not found in previous benchmarks. We demonstrate SOTA performance on challenging (partial and multi-class) segmentation scenarios as well as long videos, while ensuring significantly fewer frame annotations than any existing method.
Language models as master equation solvers
Jul 29, 2023Master equations are of fundamental importance in modeling stochastic dynamical systems.However, solving master equations is challenging due to the exponential increase in the number of possible states or trajectories with the dimension of the state space. In this study, we propose repurposing language models as a machine learning approach to solve master equations. We design a prompt-based neural network to map rate parameters, initial conditions, and time values directly to the state joint probability distribution that exactly matches the input contexts. In this way, we approximate the solution of the master equation in its most general form. We train the network using the policy gradient algorithm within the reinforcement learning framework, with feedback rewards provided by a set of variational autoregressive models. By applying this approach to representative examples, we observe high accuracy for both multi-module and high-dimensional systems. The trained network also exhibits extrapolating ability, extending its predictability to unseen data. Our findings establish the connection between language models and master equations, highlighting the possibility of using a single pretrained large model to solve any master equation.
Contrastive Multi-FaceForensics: An End-to-end Bi-grained Contrastive Learning Approach for Multi-face Forgery Detection
Aug 03, 2023
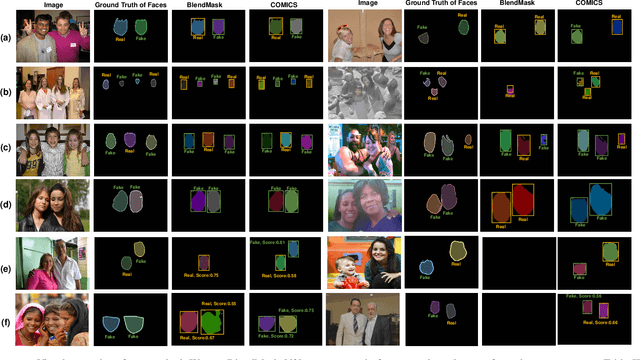

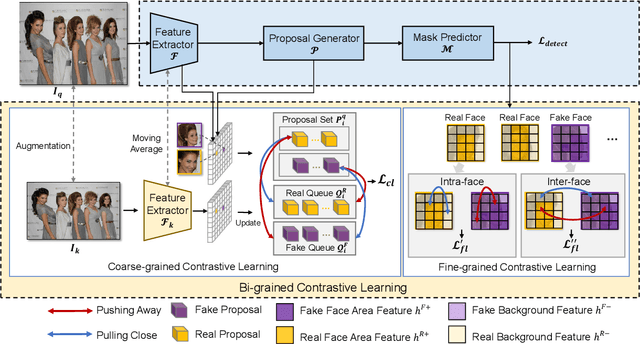
DeepFakes have raised serious societal concerns, leading to a great surge in detection-based forensics methods in recent years. Face forgery recognition is the conventional detection method that usually follows a two-phase pipeline: it extracts the face first and then determines its authenticity by classification. Since DeepFakes in the wild usually contain multiple faces, using face forgery detection methods is merely practical as they have to process faces in a sequel, i.e., only one face is processed at the same time. One straightforward way to address this issue is to integrate face extraction and forgery detection in an end-to-end fashion by adapting advanced object detection architectures. However, as these object detection architectures are designed to capture the semantic information of different object categories rather than the subtle forgery traces among the faces, the direct adaptation is far from optimal. In this paper, we describe a new end-to-end framework, Contrastive Multi-FaceForensics (COMICS), to enhance multi-face forgery detection. The core of the proposed framework is a novel bi-grained contrastive learning approach that explores effective face forgery traces at both the coarse- and fine-grained levels. Specifically, the coarse-grained level contrastive learning captures the discriminative features among positive and negative proposal pairs in multiple scales with the instruction of the proposal generator, and the fine-grained level contrastive learning captures the pixel-wise discrepancy between the forged and original areas of the same face and the pixel-wise content inconsistency between different faces. Extensive experiments on the OpenForensics dataset demonstrate our method outperforms other counterparts by a large margin (~18.5%) and shows great potential for integration into various architectures.
Automating Wood Species Detection and Classification in Microscopic Images of Fibrous Materials with Deep Learning
Jul 24, 2023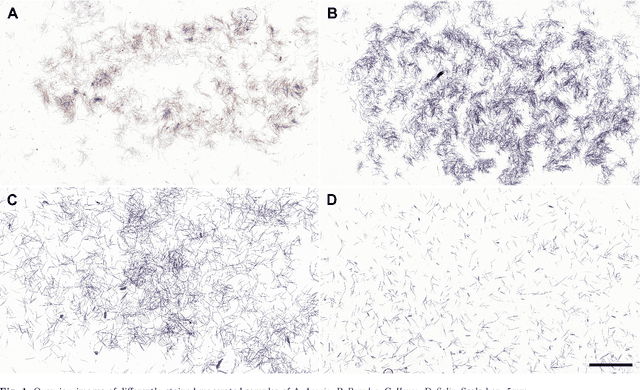
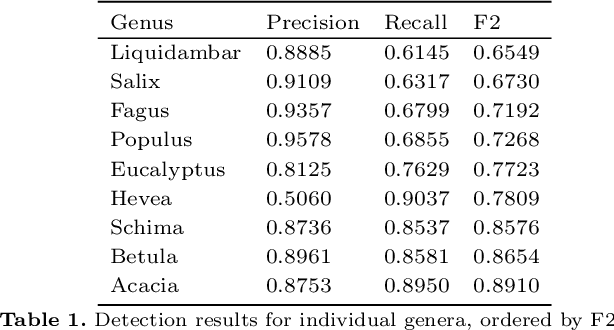

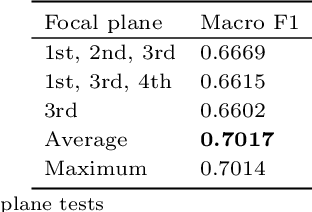
We have developed a methodology for the systematic generation of a large image dataset of macerated wood references, which we used to generate image data for nine hardwood genera. This is the basis for a substantial approach to automate, for the first time, the identification of hardwood species in microscopic images of fibrous materials by deep learning. Our methodology includes a flexible pipeline for easy annotation of vessel elements. We compare the performance of different neural network architectures and hyperparameters. Our proposed method performs similarly well to human experts. In the future, this will improve controls on global wood fiber product flows to protect forests.