 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Batching for Green AI -- An Exploratory Study on Inference
Jul 21, 2023
The batch size is an essential parameter to tune during the development of new neural networks. Amongst other quality indicators, it has a large degree of influence on the model's accuracy, generalisability, training times and parallelisability. This fact is generally known and commonly studied. However, during the application phase of a deep learning model, when the model is utilised by an end-user for inference, we find that there is a disregard for the potential benefits of introducing a batch size. In this study, we examine the effect of input batching on the energy consumption and response times of five fully-trained neural networks for computer vision that were considered state-of-the-art at the time of their publication. The results suggest that batching has a significant effect on both of these metrics. Furthermore, we present a timeline of the energy efficiency and accuracy of neural networks over the past decade. We find that in general, energy consumption rises at a much steeper pace than accuracy and question the necessity of this evolution. Additionally, we highlight one particular network, ShuffleNetV2(2018), that achieved a competitive performance for its time while maintaining a much lower energy consumption. Nevertheless, we highlight that the results are model dependent.
Fast Approximate Nearest Neighbor Search with a Dynamic Exploration Graph using Continuous Refinement
Jul 21, 2023
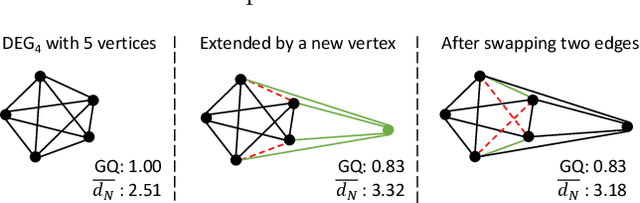

For approximate nearest neighbor search, graph-based algorithms have shown to offer the best trade-off between accuracy and search time. We propose the Dynamic Exploration Graph (DEG) which significantly outperforms existing algorithms in terms of search and exploration efficiency by combining two new ideas: First, a single undirected even regular graph is incrementally built by partially replacing existing edges to integrate new vertices and to update old neighborhoods at the same time. Secondly, an edge optimization algorithm is used to continuously improve the quality of the graph. Combining this ongoing refinement with the graph construction process leads to a well-organized graph structure at all times, resulting in: (1) increased search efficiency, (2) predictable index size, (3) guaranteed connectivity and therefore reachability of all vertices, and (4) a dynamic graph structure. In addition we investigate how well existing graph-based search systems can handle indexed queries where the seed vertex of a search is the query itself. Such exploration tasks, despite their good starting point, are not necessarily easy. High efficiency in approximate nearest neighbor search (ANNS) does not automatically imply good performance in exploratory search. Extensive experiments show that our new Dynamic Exploration Graph outperforms existing algorithms significantly for indexed and unindexed queries.
Channel Estimation for RIS-Aided MIMO Systems: A Partially Decoupled Atomic Norm Minimization Approach
Jul 21, 2023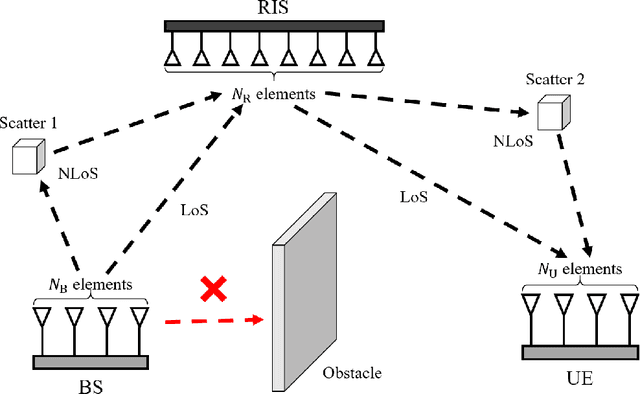
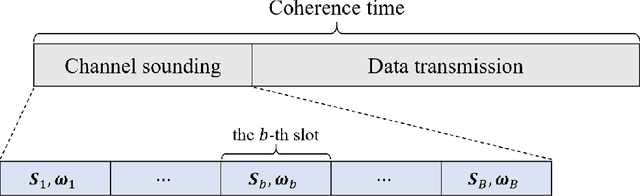
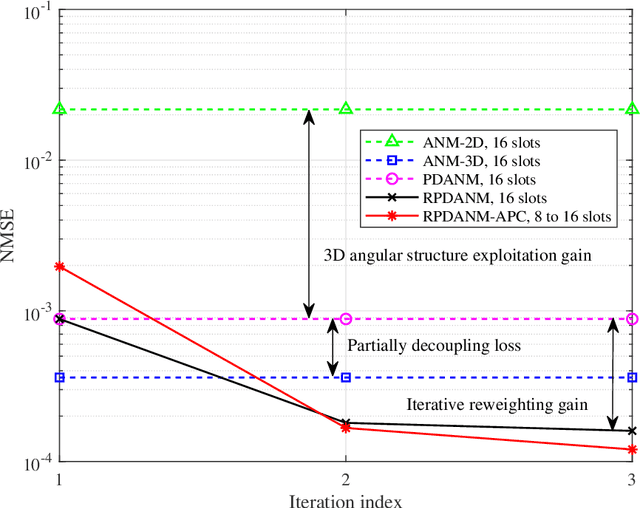
Channel estimation (CE) plays a key role in reconfigurable intelligent surface (RIS)-aided multiple-input multiple-output (MIMO) communication systems, while it poses a challenging task due to the passive nature of RIS and the cascaded channel structures. In this paper, a partially decoupled atomic norm minimization (PDANM) framework is proposed for CE of RIS-aided MIMO systems, which exploits the three-dimensional angular sparsity of the channel. In particular, PDANM partially decouples the differential angles at the RIS from other angles at the base station and user equipment, reducing the computational complexity compared with existing methods. A reweighted PDANM (RPDANM) algorithm is proposed to further improve CE accuracy, which iteratively refines CE through a specifically designed reweighing strategy. Building upon RPDANM, we propose an iterative approach named RPDANM with adaptive phase control (RPDANM-APC), which adaptively adjusts the RIS phases based on previously estimated channel parameters to facilitate CE, achieving superior CE accuracy while reducing training overhead. Numerical simulations demonstrate the superiority of our proposed approaches in terms of running time, CE accuracy, and training overhead. In particular, the RPDANM-APC approach can achieve higher CE accuracy than existing methods within less than 40 percent training overhead while reducing the running time by tens of times.
Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP
Aug 04, 2023
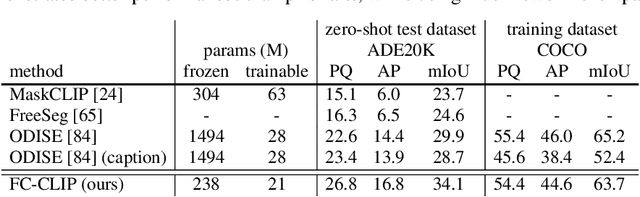
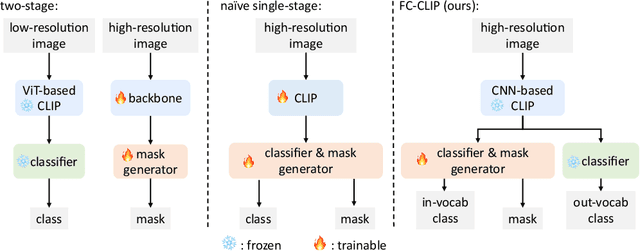

Open-vocabulary segmentation is a challenging task requiring segmenting and recognizing objects from an open set of categories. One way to address this challenge is to leverage multi-modal models, such as CLIP, to provide image and text features in a shared embedding space, which bridges the gap between closed-vocabulary and open-vocabulary recognition. Hence, existing methods often adopt a two-stage framework to tackle the problem, where the inputs first go through a mask generator and then through the CLIP model along with the predicted masks. This process involves extracting features from images multiple times, which can be ineffective and inefficient. By contrast, we propose to build everything into a single-stage framework using a shared Frozen Convolutional CLIP backbone, which not only significantly simplifies the current two-stage pipeline, but also remarkably yields a better accuracy-cost trade-off. The proposed FC-CLIP, benefits from the following observations: the frozen CLIP backbone maintains the ability of open-vocabulary classification and can also serve as a strong mask generator, and the convolutional CLIP generalizes well to a larger input resolution than the one used during contrastive image-text pretraining. When training on COCO panoptic data only and testing in a zero-shot manner, FC-CLIP achieve 26.8 PQ, 16.8 AP, and 34.1 mIoU on ADE20K, 18.2 PQ, 27.9 mIoU on Mapillary Vistas, 44.0 PQ, 26.8 AP, 56.2 mIoU on Cityscapes, outperforming the prior art by +4.2 PQ, +2.4 AP, +4.2 mIoU on ADE20K, +4.0 PQ on Mapillary Vistas and +20.1 PQ on Cityscapes, respectively. Additionally, the training and testing time of FC-CLIP is 7.5x and 6.6x significantly faster than the same prior art, while using 5.9x fewer parameters. FC-CLIP also sets a new state-of-the-art performance across various open-vocabulary semantic segmentation datasets. Code at https://github.com/bytedance/fc-clip
Personalization of Stress Mobile Sensing using Self-Supervised Learning
Aug 04, 2023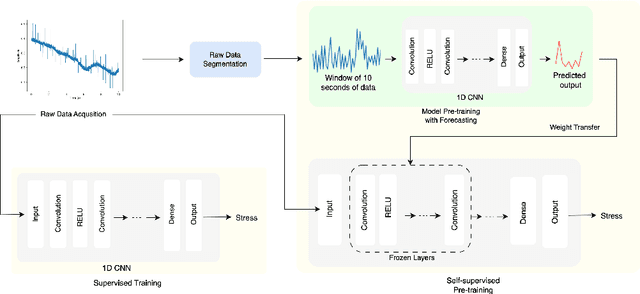
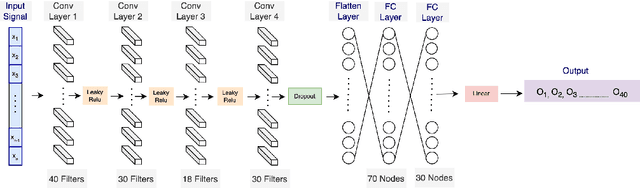
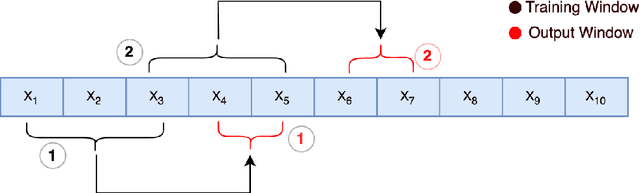
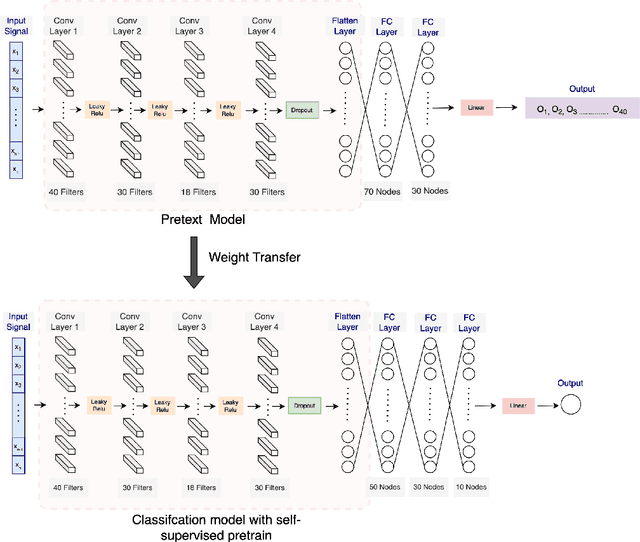
Stress is widely recognized as a major contributor to a variety of health issues. Stress prediction using biosignal data recorded by wearables is a key area of study in mobile sensing research because real-time stress prediction can enable digital interventions to immediately react at the onset of stress, helping to avoid many psychological and physiological symptoms such as heart rhythm irregularities. Electrodermal activity (EDA) is often used to measure stress. However, major challenges with the prediction of stress using machine learning include the subjectivity and sparseness of the labels, a large feature space, relatively few labels, and a complex nonlinear and subjective relationship between the features and outcomes. To tackle these issues, we examine the use of model personalization: training a separate stress prediction model for each user. To allow the neural network to learn the temporal dynamics of each individual's baseline biosignal patterns, thus enabling personalization with very few labels, we pre-train a 1-dimensional convolutional neural network (CNN) using self-supervised learning (SSL). We evaluate our method using the Wearable Stress and Affect prediction (WESAD) dataset. We fine-tune the pre-trained networks to the stress prediction task and compare against equivalent models without any self-supervised pre-training. We discover that embeddings learned using our pre-training method outperform supervised baselines with significantly fewer labeled data points: the models trained with SSL require less than 30% of the labels to reach equivalent performance without personalized SSL. This personalized learning method can enable precision health systems which are tailored to each subject and require few annotations by the end user, thus allowing for the mobile sensing of increasingly complex, heterogeneous, and subjective outcomes such as stress.
CyPhERS: A Cyber-Physical Event Reasoning System providing real-time situational awareness for attack and fault response
May 26, 2023
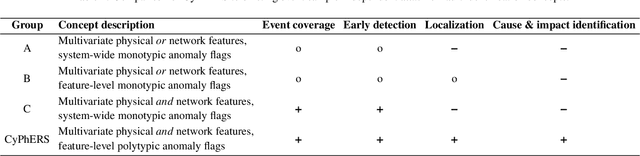
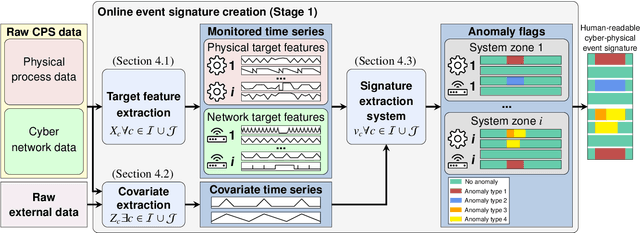

Cyber-physical systems (CPSs) constitute the backbone of critical infrastructures such as power grids or water distribution networks. Operating failures in these systems can cause serious risks for society. To avoid or minimize downtime, operators require real-time awareness about critical incidents. However, online event identification in CPSs is challenged by the complex interdependency of numerous physical and digital components, requiring to take cyber attacks and physical failures equally into account. The online event identification problem is further complicated through the lack of historical observations of critical but rare events, and the continuous evolution of cyber attack strategies. This work introduces and demonstrates CyPhERS, a Cyber-Physical Event Reasoning System. CyPhERS provides real-time information pertaining the occurrence, location, physical impact, and root cause of potentially critical events in CPSs, without the need for historical event observations. Key novelty of CyPhERS is the capability to generate informative and interpretable event signatures of known and unknown types of both cyber attacks and physical failures. The concept is evaluated and benchmarked on a demonstration case that comprises a multitude of attack and fault events targeting various components of a CPS. The results demonstrate that the event signatures provide relevant and inferable information on both known and unknown event types.
Towards an architectural framework for intelligent virtual agents using probabilistic programming
Jul 20, 2023We present a new framework called KorraAI for conceiving and building embodied conversational agents (ECAs). Our framework models ECAs' behavior considering contextual information, for example, about environment and interaction time, and uncertain information provided by the human interaction partner. Moreover, agents built with KorraAI can show proactive behavior, as they can initiate interactions with human partners. For these purposes, KorraAI exploits probabilistic programming. Probabilistic models in KorraAI are used to model its behavior and interactions with the user. They enable adaptation to the user's preferences and a certain degree of indeterminism in the ECAs to achieve more natural behavior. Human-like internal states, such as moods, preferences, and emotions (e.g., surprise), can be modeled in KorraAI with distributions and Bayesian networks. These models can evolve over time, even without interaction with the user. ECA models are implemented as plugins and share a common interface. This enables ECA designers to focus more on the character they are modeling and less on the technical details, as well as to store and exchange ECA models. Several applications of KorraAI ECAs are possible, such as virtual sales agents, customer service agents, virtual companions, entertainers, or tutors.
Practical Implementation of RIS-Aided Spectrum Sensing: A Deep Learning-Based Solution
Jul 27, 2023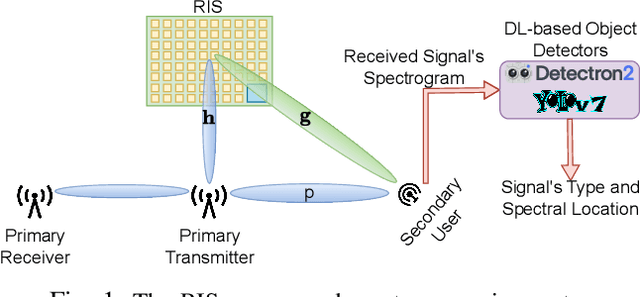
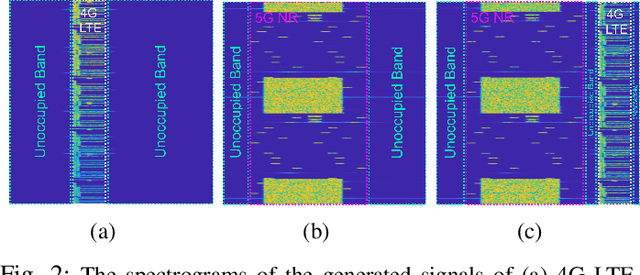
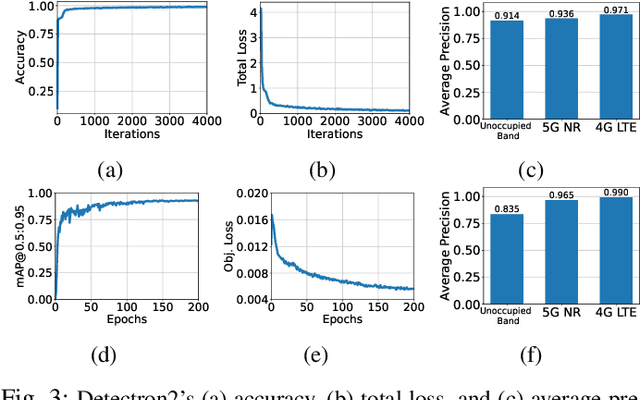

This paper presents reconfigurable intelligent surface (RIS)-aided deep learning (DL)-based spectrum sensing for next-generation cognitive radios. To that end, the secondary user (SU) monitors the primary transmitter (PT) signal, where the RIS plays a pivotal role in increasing the strength of the PT signal at the SU. The spectrograms of the synthesized dataset, including the 4G LTE and 5G NR signals, are mapped to images utilized for training the state-of-art object detection approaches, namely Detectron2 and YOLOv7. By conducting extensive experiments using a real RIS prototype, we demonstrate that the RIS can consistently and significantly improve the performance of the DL detectors to identify the PT signal type along with its time and frequency utilization. This study also paves the way for optimizing spectrum utilization through RIS-assisted CR application in next-generation wireless communication systems.
GADER: GAit DEtection and Recognition in the Wild
Jul 27, 2023
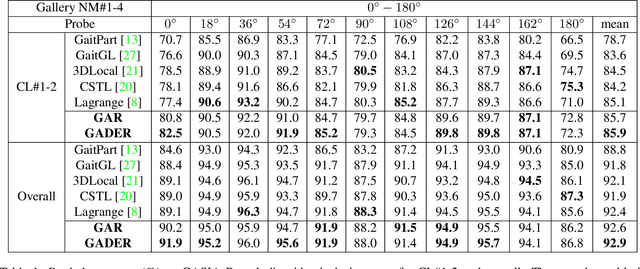
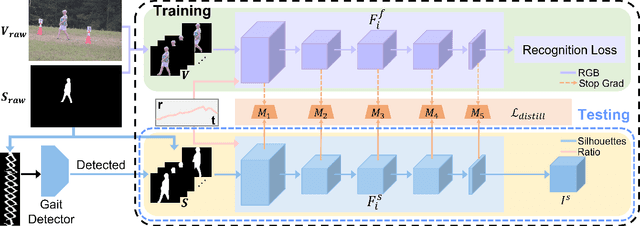
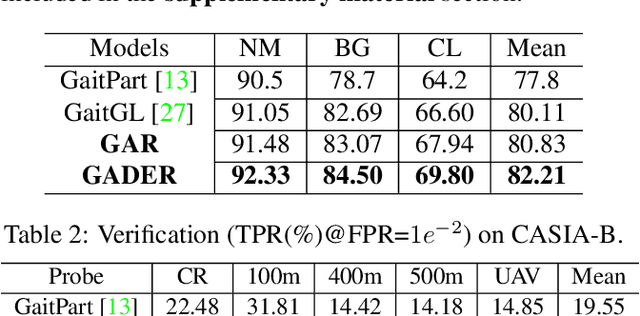
Gait recognition holds the promise of robustly identifying subjects based on their walking patterns instead of color information. While previous approaches have performed well for curated indoor scenes, they have significantly impeded applicability in unconstrained situations, e.g. outdoor, long distance scenes. We propose an end-to-end GAit DEtection and Recognition (GADER) algorithm for human authentication in challenging outdoor scenarios. Specifically, GADER leverages a Double Helical Signature to detect the fragment of human movement and incorporates a novel gait recognition method, which learns representations by distilling from an auxiliary RGB recognition model. At inference time, GADER only uses the silhouette modality but benefits from a more robust representation. Extensive experiments on indoor and outdoor datasets demonstrate that the proposed method outperforms the State-of-The-Arts for gait recognition and verification, with a significant 20.6% improvement on unconstrained, long distance scenes.
AI Literature Review Suite
Jul 27, 2023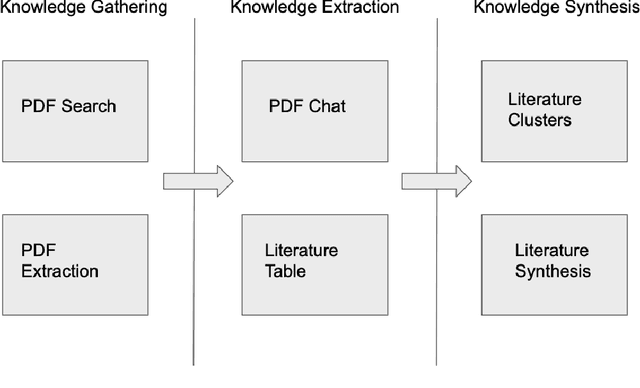

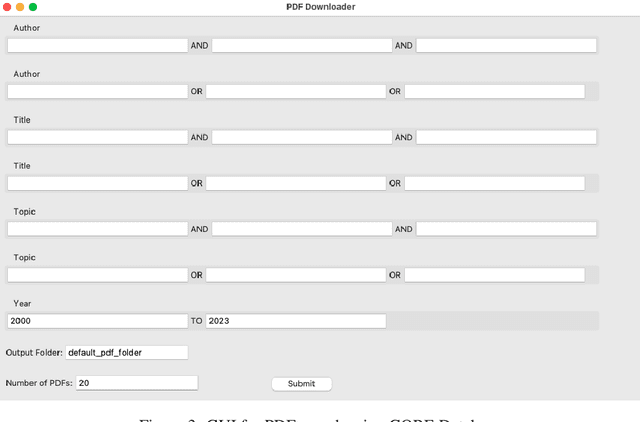
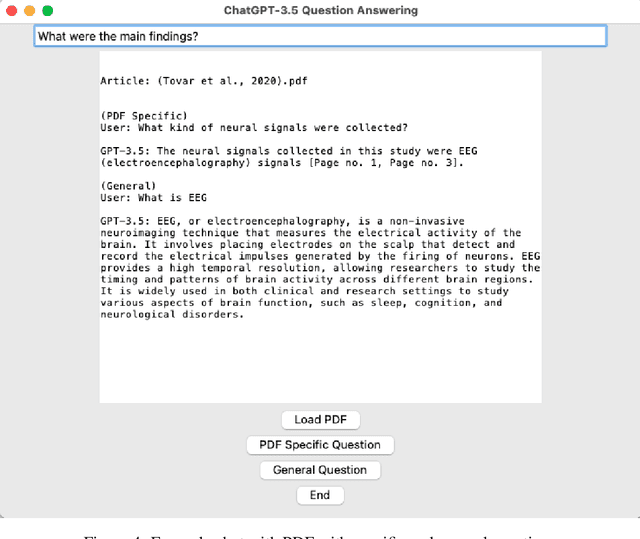
The process of conducting literature reviews is often time-consuming and labor-intensive. To streamline this process, I present an AI Literature Review Suite that integrates several functionalities to provide a comprehensive literature review. This tool leverages the power of open access science, large language models (LLMs) and natural language processing to enable the searching, downloading, and organizing of PDF files, as well as extracting content from articles. Semantic search queries are used for data retrieval, while text embeddings and summarization using LLMs present succinct literature reviews. Interaction with PDFs is enhanced through a user-friendly graphical user interface (GUI). The suite also features integrated programs for bibliographic organization, interaction and query, and literature review summaries. This tool presents a robust solution to automate and optimize the process of literature review in academic and industrial research.