 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Empirical Validation of a Class of Ray-Based Fading Models
Jul 28, 2023

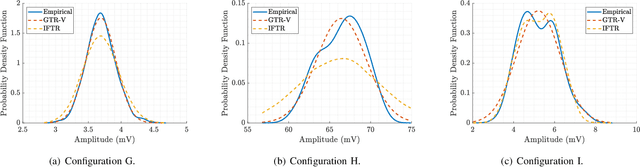
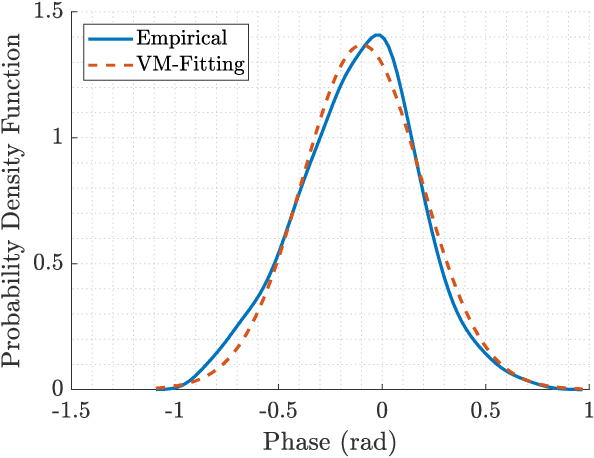
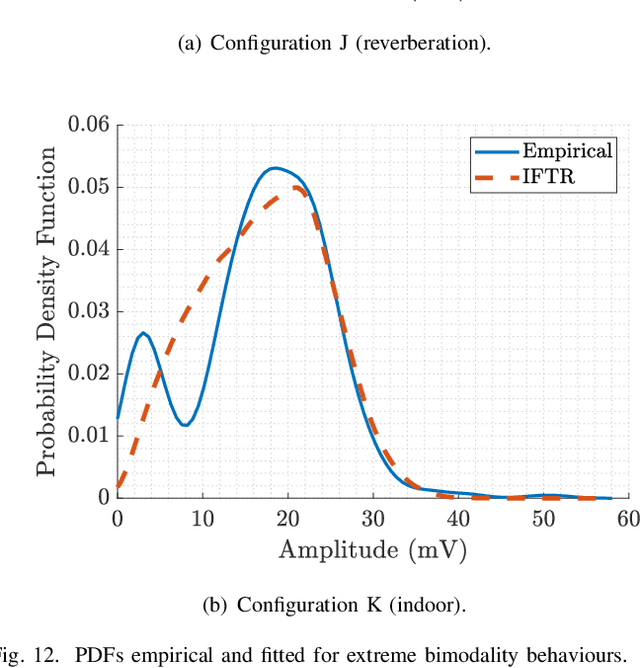
As new wireless standards are developed, the use of higher operation frequencies comes in hand with new use cases and propagation effects that differ from the well-established state of the art. Numerous stochastic fading models have recently emerged under the umbrella of generalized fading conditions, to provide a fine-grain characterization of propagation channels in the mmWave and sub-THz bands. For the first time in literature, this work carries out an experimental validation of a class of such ray-based models, in a wide range of propagation conditions (anechoic, reverberation and indoor) at mmWave bands. We show that the independently fluctuating two-ray (IFTR) model has good capabilities to recreate rather dissimilar environments with high accuracy. We also put forth that the key limitations of the IFTR model arise in the presence of reduced diffuse propagation, and also due to a limited phase variability for the dominant specular components.
Performance Comparison Between VoLTE and non-VoLTE Voice Calls During Mobility in Commercial Deployment: A Drive Test-Based Analysis
Jul 23, 2023The optimization of network performance is vital for the delivery of services using standard cellular technologies for mobile communications. Call setup delay and User Equipment (UE) battery savings significantly influence network performance. Improving these factors is vital for ensuring optimal service delivery. In comparison to traditional circuit-switched voice calls, VoLTE (Voice over LTE) technology offers faster call setup durations and better battery-saving performance. To validate these claims, a drive test was carried out using the XCAL drive test tool to collect real-time network parameter details in VoLTE and non-VoLTE voice calls. The findings highlight the analysis of real-time network characteristics, such as the call setup delay calculation, battery-saving performance, and DRX mechanism. The study contributes to the understanding of network optimization strategies and provides insights for enhancing the quality of service (QoS) in mobile communication networks. Examining VoLTE and non-VoLTE operations, this research highlights the substantial energy savings obtained by VoLTE. Specifically, VoLTE saves approximately 60.76% of energy before the Service Request and approximately 38.97% of energy after the Service Request. Moreover, VoLTE to VoLTE calls have a 72.6% faster call setup delay than non-VoLTE-based LTE to LTE calls, because of fewer signaling messages required. Furthermore, as compared to non-VoLTE to non-VoLTE calls, VoLTE to non-VoLTE calls offer an 18.6% faster call setup delay. These results showcase the performance advantages of VoLTE and reinforce its potential for offering better services in wireless communication networks.
Deceptive Information Retrieval
Jul 10, 2023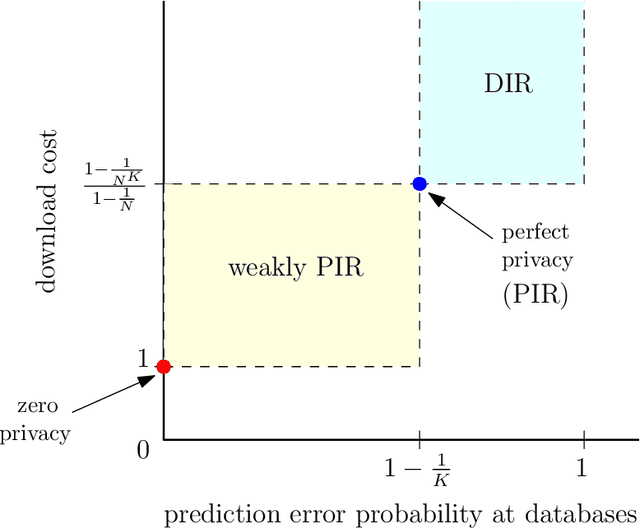
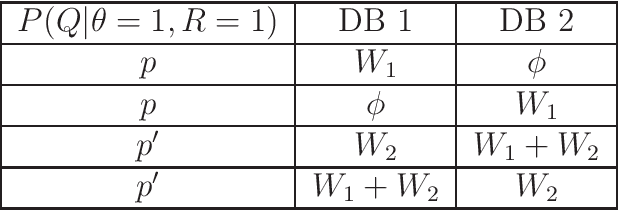
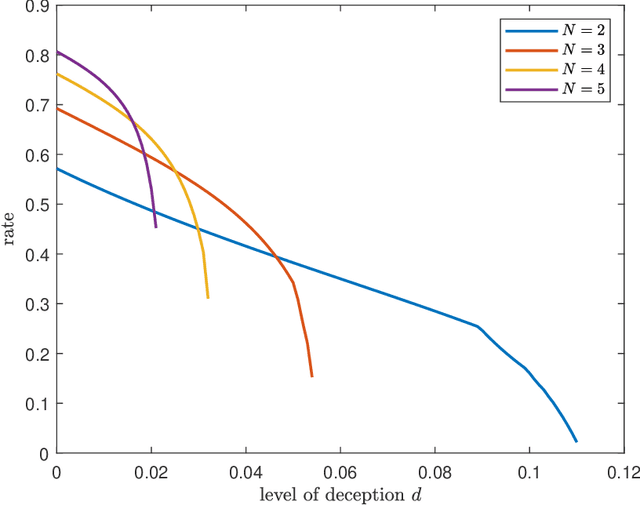
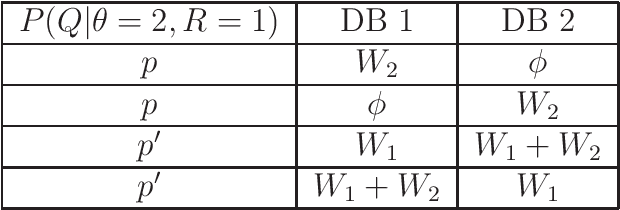
We introduce the problem of deceptive information retrieval (DIR), in which a user wishes to download a required file out of multiple independent files stored in a system of databases while \emph{deceiving} the databases by making the databases' predictions on the user-required file index incorrect with high probability. Conceptually, DIR is an extension of private information retrieval (PIR). In PIR, a user downloads a required file without revealing its index to any of the databases. The metric of deception is defined as the probability of error of databases' prediction on the user-required file, minus the corresponding probability of error in PIR. The problem is defined on time-sensitive data that keeps updating from time to time. In the proposed scheme, the user deceives the databases by sending \emph{real} queries to download the required file at the time of the requirement and \emph{dummy} queries at multiple distinct future time instances to manipulate the probabilities of sending each query for each file requirement, using which the databases' make the predictions on the user-required file index. The proposed DIR scheme is based on a capacity achieving probabilistic PIR scheme, and achieves rates lower than the PIR capacity due to the additional downloads made to deceive the databases. When the required level of deception is zero, the proposed scheme achieves the PIR capacity.
A comparison of machine learning surrogate models of street-scale flooding in Norfolk, Virginia
Jul 26, 2023
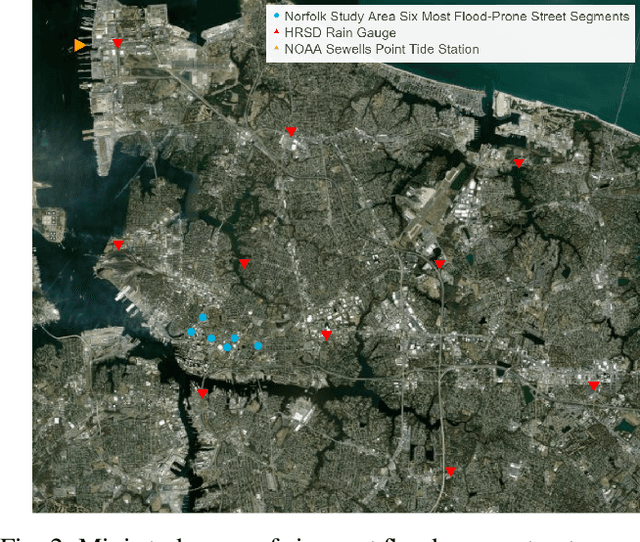
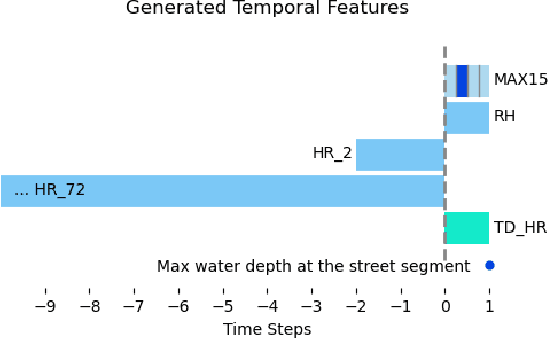
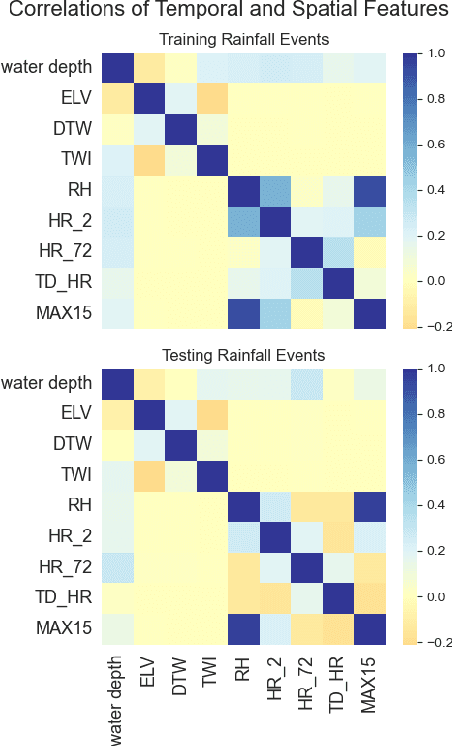
Low-lying coastal cities, exemplified by Norfolk, Virginia, face the challenge of street flooding caused by rainfall and tides, which strain transportation and sewer systems and can lead to property damage. While high-fidelity, physics-based simulations provide accurate predictions of urban pluvial flooding, their computational complexity renders them unsuitable for real-time applications. Using data from Norfolk rainfall events between 2016 and 2018, this study compares the performance of a previous surrogate model based on a random forest algorithm with two deep learning models: Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU). This investigation underscores the importance of using a model architecture that supports the communication of prediction uncertainty and the effective integration of relevant, multi-modal features.
Human Emergency Detection during Autonomous Hospital Transports
Jul 17, 2023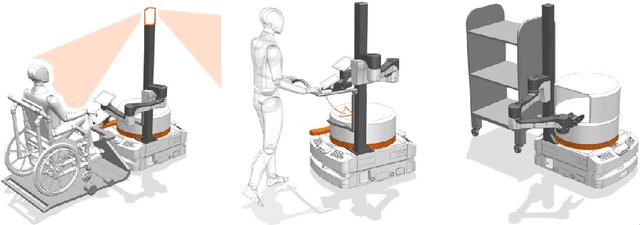

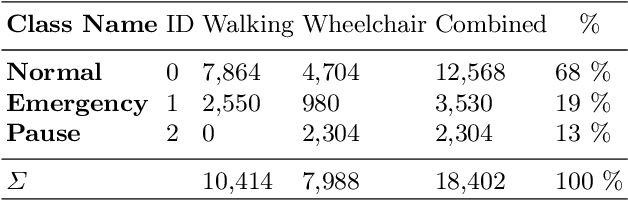

Human transports in hospitals are labor-intensive and primarily performed in beds to save time. This transfer method does not promote the mobility or autonomy of the patient. To relieve the caregivers from this time-consuming task, a mobile robot is developed to autonomously transport humans around the hospital. It provides different transfer modes including walking and sitting in a wheelchair. The problem that this paper focuses on is to detect emergencies and ensure the well-being of the patient during the transport. For this purpose, the patient is tracked and monitored with a camera system. OpenPose is used for Human Pose Estimation and a trained classifier for emergency detection. We collected and published a dataset of 18,000 images in lab and hospital environments. It differs from related work because we have a moving robot with different transfer modes in a highly dynamic environment with multiple people in the scene using only RGB-D data. To improve the critical recall metric, we apply threshold moving and a time delay. We compare different models with an AutoML approach. This paper shows that emergencies while walking are best detected by a SVM with a recall of 95.8% on single frames. In the case of sitting transport, the best model achieves a recall of 62.2%. The contribution is to establish a baseline on this new dataset and to provide a proof of concept for the human emergency detection in this use case.
Isolation and Induction: Training Robust Deep Neural Networks against Model Stealing Attacks
Aug 02, 2023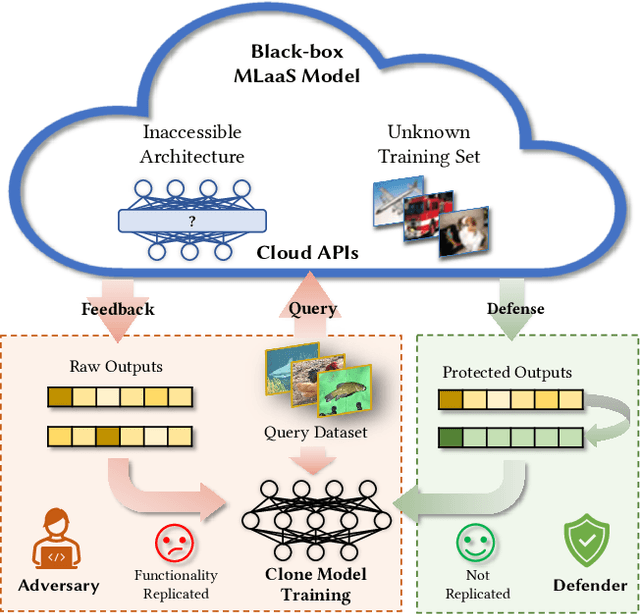
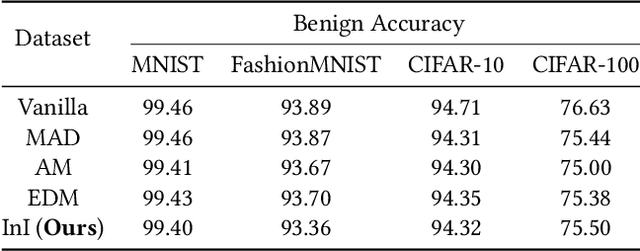
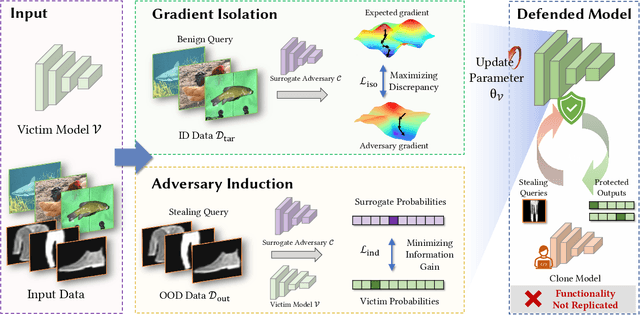
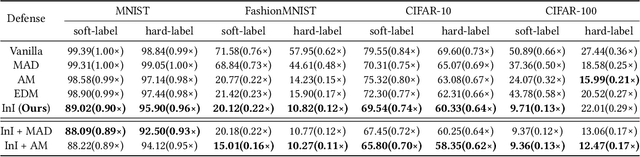
Despite the broad application of Machine Learning models as a Service (MLaaS), they are vulnerable to model stealing attacks. These attacks can replicate the model functionality by using the black-box query process without any prior knowledge of the target victim model. Existing stealing defenses add deceptive perturbations to the victim's posterior probabilities to mislead the attackers. However, these defenses are now suffering problems of high inference computational overheads and unfavorable trade-offs between benign accuracy and stealing robustness, which challenges the feasibility of deployed models in practice. To address the problems, this paper proposes Isolation and Induction (InI), a novel and effective training framework for model stealing defenses. Instead of deploying auxiliary defense modules that introduce redundant inference time, InI directly trains a defensive model by isolating the adversary's training gradient from the expected gradient, which can effectively reduce the inference computational cost. In contrast to adding perturbations over model predictions that harm the benign accuracy, we train models to produce uninformative outputs against stealing queries, which can induce the adversary to extract little useful knowledge from victim models with minimal impact on the benign performance. Extensive experiments on several visual classification datasets (e.g., MNIST and CIFAR10) demonstrate the superior robustness (up to 48% reduction on stealing accuracy) and speed (up to 25.4x faster) of our InI over other state-of-the-art methods. Our codes can be found in https://github.com/DIG-Beihang/InI-Model-Stealing-Defense.
Mercury: An Automated Remote Side-channel Attack to Nvidia Deep Learning Accelerator
Aug 02, 2023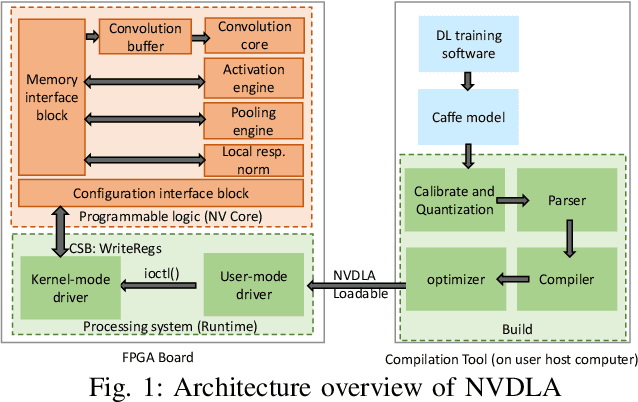
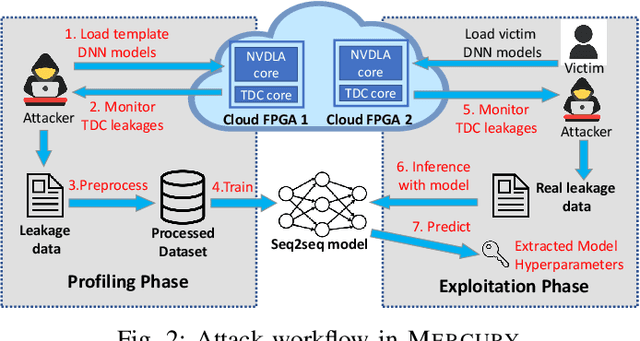
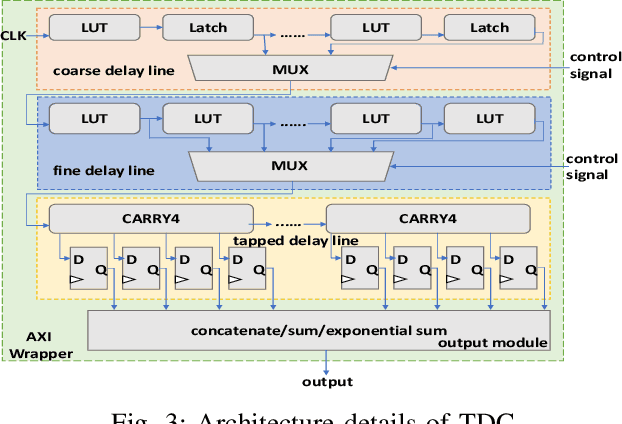
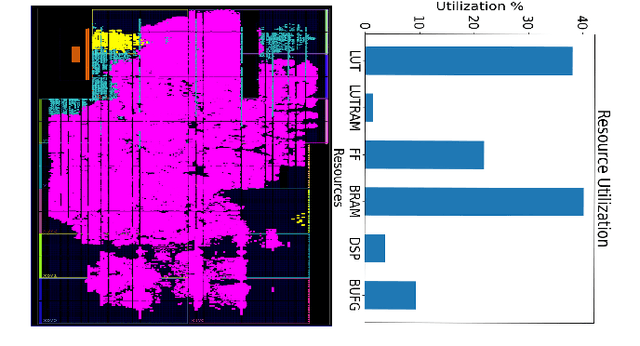
DNN accelerators have been widely deployed in many scenarios to speed up the inference process and reduce the energy consumption. One big concern about the usage of the accelerators is the confidentiality of the deployed models: model inference execution on the accelerators could leak side-channel information, which enables an adversary to preciously recover the model details. Such model extraction attacks can not only compromise the intellectual property of DNN models, but also facilitate some adversarial attacks. Although previous works have demonstrated a number of side-channel techniques to extract models from DNN accelerators, they are not practical for two reasons. (1) They only target simplified accelerator implementations, which have limited practicality in the real world. (2) They require heavy human analysis and domain knowledge. To overcome these limitations, this paper presents Mercury, the first automated remote side-channel attack against the off-the-shelf Nvidia DNN accelerator. The key insight of Mercury is to model the side-channel extraction process as a sequence-to-sequence problem. The adversary can leverage a time-to-digital converter (TDC) to remotely collect the power trace of the target model's inference. Then he uses a learning model to automatically recover the architecture details of the victim model from the power trace without any prior knowledge. The adversary can further use the attention mechanism to localize the leakage points that contribute most to the attack. Evaluation results indicate that Mercury can keep the error rate of model extraction below 1%.
Perpetual Humanoid Control for Real-time Simulated Avatars
May 10, 2023
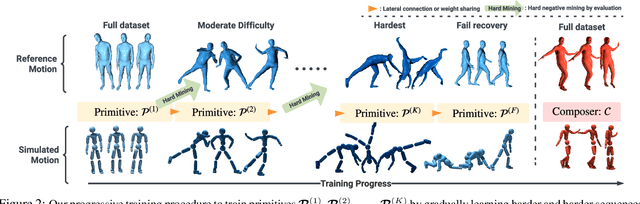
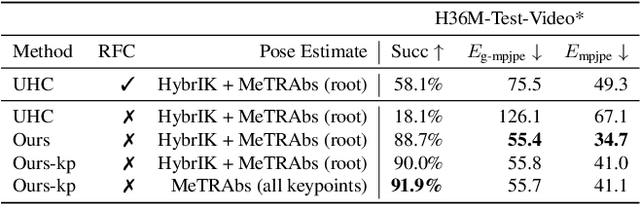
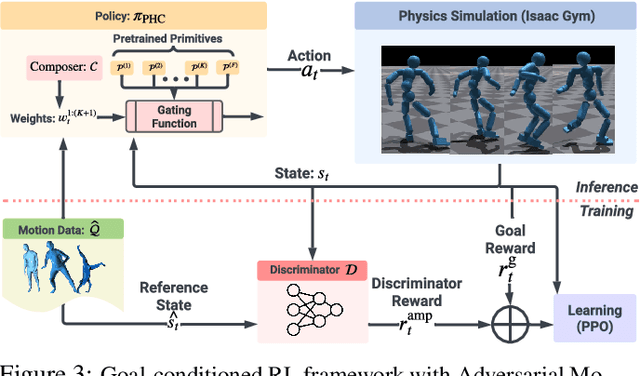
We present a physics-based humanoid controller that achieves high-fidelity motion imitation and fault-tolerant behavior in the presence of noisy input (e.g. pose estimates from video or generated from language) and unexpected falls. Our controller scales up to learning ten thousand motion clips without using any external stabilizing forces and learns to naturally recover from fail-state. Given reference motion, our controller can perpetually control simulated avatars without requiring resets. At its core, we propose the progressive multiplicative control policy (PMCP), which dynamically allocates new network capacity to learn harder and harder motion sequences. PMCP allows efficient scaling for learning from large-scale motion databases and adding new tasks, such as fail-state recovery, without catastrophic forgetting. We demonstrate the effectiveness of our controller by using it to imitate noisy poses from video-based pose estimators and language-based motion generators in a live and real-time multi-person avatar use case.
Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP
Aug 04, 2023
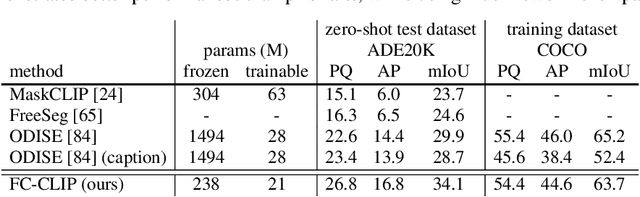
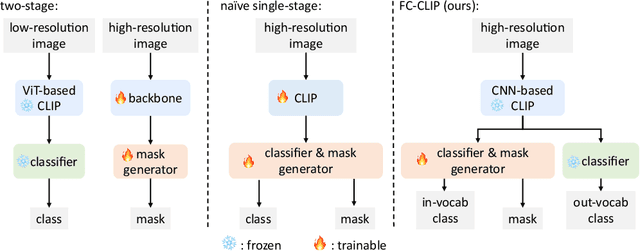

Open-vocabulary segmentation is a challenging task requiring segmenting and recognizing objects from an open set of categories. One way to address this challenge is to leverage multi-modal models, such as CLIP, to provide image and text features in a shared embedding space, which bridges the gap between closed-vocabulary and open-vocabulary recognition. Hence, existing methods often adopt a two-stage framework to tackle the problem, where the inputs first go through a mask generator and then through the CLIP model along with the predicted masks. This process involves extracting features from images multiple times, which can be ineffective and inefficient. By contrast, we propose to build everything into a single-stage framework using a shared Frozen Convolutional CLIP backbone, which not only significantly simplifies the current two-stage pipeline, but also remarkably yields a better accuracy-cost trade-off. The proposed FC-CLIP, benefits from the following observations: the frozen CLIP backbone maintains the ability of open-vocabulary classification and can also serve as a strong mask generator, and the convolutional CLIP generalizes well to a larger input resolution than the one used during contrastive image-text pretraining. When training on COCO panoptic data only and testing in a zero-shot manner, FC-CLIP achieve 26.8 PQ, 16.8 AP, and 34.1 mIoU on ADE20K, 18.2 PQ, 27.9 mIoU on Mapillary Vistas, 44.0 PQ, 26.8 AP, 56.2 mIoU on Cityscapes, outperforming the prior art by +4.2 PQ, +2.4 AP, +4.2 mIoU on ADE20K, +4.0 PQ on Mapillary Vistas and +20.1 PQ on Cityscapes, respectively. Additionally, the training and testing time of FC-CLIP is 7.5x and 6.6x significantly faster than the same prior art, while using 5.9x fewer parameters. FC-CLIP also sets a new state-of-the-art performance across various open-vocabulary semantic segmentation datasets. Code at https://github.com/bytedance/fc-clip
Personalization of Stress Mobile Sensing using Self-Supervised Learning
Aug 04, 2023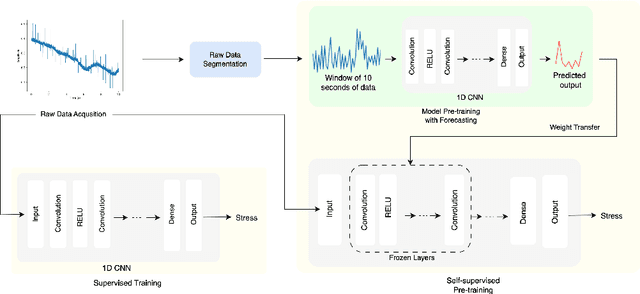
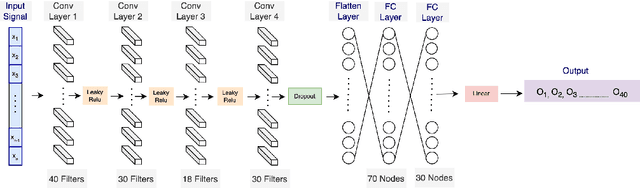
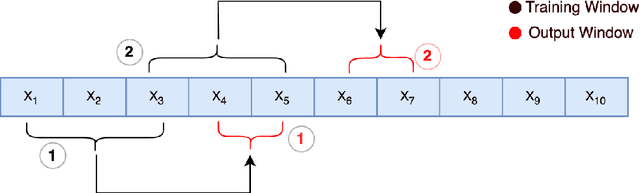
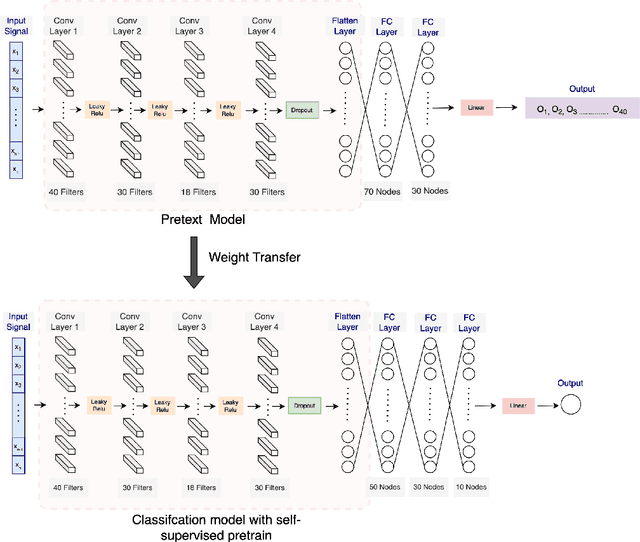
Stress is widely recognized as a major contributor to a variety of health issues. Stress prediction using biosignal data recorded by wearables is a key area of study in mobile sensing research because real-time stress prediction can enable digital interventions to immediately react at the onset of stress, helping to avoid many psychological and physiological symptoms such as heart rhythm irregularities. Electrodermal activity (EDA) is often used to measure stress. However, major challenges with the prediction of stress using machine learning include the subjectivity and sparseness of the labels, a large feature space, relatively few labels, and a complex nonlinear and subjective relationship between the features and outcomes. To tackle these issues, we examine the use of model personalization: training a separate stress prediction model for each user. To allow the neural network to learn the temporal dynamics of each individual's baseline biosignal patterns, thus enabling personalization with very few labels, we pre-train a 1-dimensional convolutional neural network (CNN) using self-supervised learning (SSL). We evaluate our method using the Wearable Stress and Affect prediction (WESAD) dataset. We fine-tune the pre-trained networks to the stress prediction task and compare against equivalent models without any self-supervised pre-training. We discover that embeddings learned using our pre-training method outperform supervised baselines with significantly fewer labeled data points: the models trained with SSL require less than 30% of the labels to reach equivalent performance without personalized SSL. This personalized learning method can enable precision health systems which are tailored to each subject and require few annotations by the end user, thus allowing for the mobile sensing of increasingly complex, heterogeneous, and subjective outcomes such as stress.