 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multitemporal SAR images change detection and visualization using RABASAR and simplified GLR
Jul 15, 2023
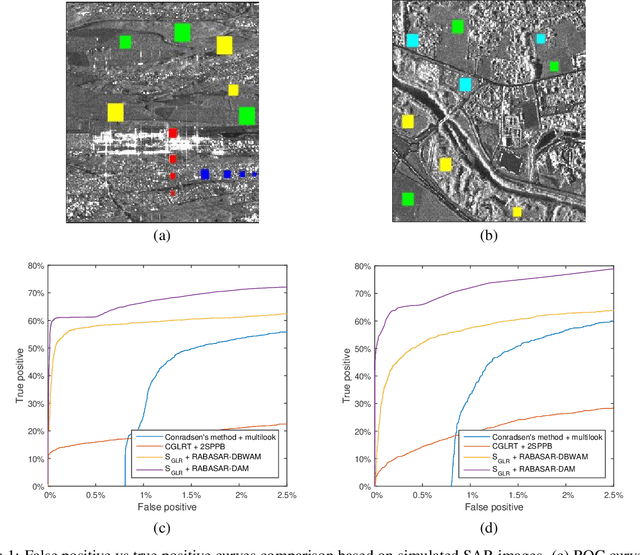


Understanding the state of changed areas requires that precise information be given about the changes. Thus, detecting different kinds of changes is important for land surface monitoring. SAR sensors are ideal to fulfil this task, because of their all-time and all-weather capabilities, with good accuracy of the acquisition geometry and without effects of atmospheric constituents for amplitude data. In this study, we propose a simplified generalized likelihood ratio ($S_{GLR}$) method assuming that corresponding temporal pixels have the same equivalent number of looks (ENL). Thanks to the denoised data provided by a ratio-based multitemporal SAR image denoising method (RABASAR), we successfully applied this similarity test approach to compute the change areas. A new change magnitude index method and an improved spectral clustering-based change classification method are also developed. In addition, we apply the simplified generalized likelihood ratio to detect the maximum change magnitude time, and the change starting and ending times. Then, we propose to use an adaptation of the REACTIV method to visualize the detection results vividly. The effectiveness of the proposed methods is demonstrated through the processing of simulated and SAR images, and the comparison with classical techniques. In particular, numerical experiments proved that the developed method has good performances in detecting farmland area changes, building area changes, harbour area changes and flooding area changes.
Joint Batching and Scheduling for High-Throughput Multiuser Edge AI with Asynchronous Task Arrivals
Jul 15, 2023In this paper, we study joint batching and (task) scheduling to maximise the throughput (i.e., the number of completed tasks) under the practical assumptions of heterogeneous task arrivals and deadlines. The design aims to optimise the number of batches, their starting time instants, and the task-batch association that determines batch sizes. The joint optimisation problem is complex due to multiple coupled variables as mentioned and numerous constraints including heterogeneous tasks arrivals and deadlines, the causality requirements on multi-task execution, and limited radio resources. Underpinning the problem is a basic tradeoff between the size of batch and waiting time for tasks in the batch to be uploaded and executed. Our approach of solving the formulated mixed-integer problem is to transform it into a convex problem via integer relaxation method and $\ell_0$-norm approximation. This results in an efficient alternating optimization algorithm for finding a close-to-optimal solution. In addition, we also design the optimal algorithm from leveraging spectrum holes, which are caused by fixed bandwidth allocation to devices and their asynchronized multi-batch task execution, to admit unscheduled tasks so as to further enhance throughput. Simulation results demonstrate that the proposed framework of joint batching and resource allocation can substantially enhance the throughput of multiuser edge-AI as opposed to a number of simpler benchmarking schemes, e.g., equal-bandwidth allocation, greedy batching and single-batch execution.
Visual Prompt Flexible-Modal Face Anti-Spoofing
Jul 26, 2023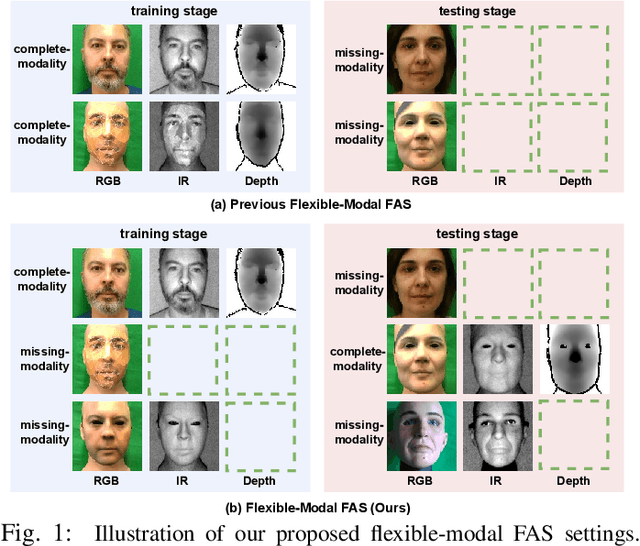
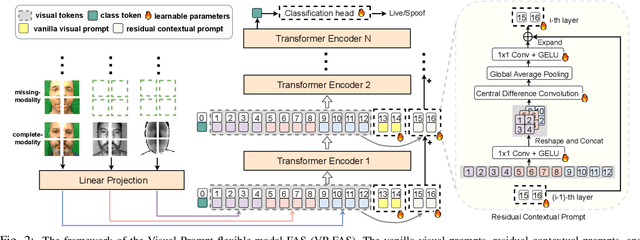
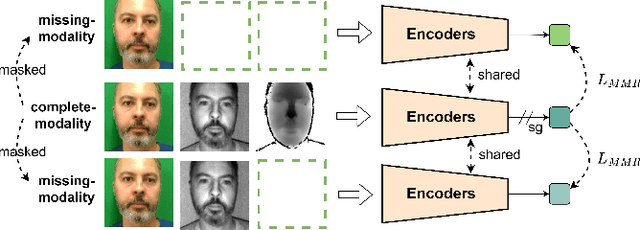
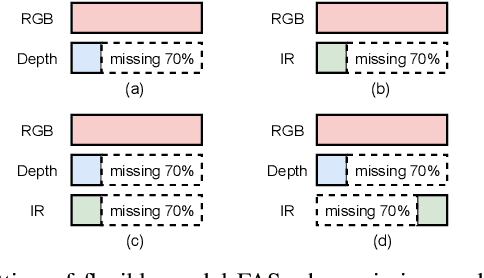
Recently, vision transformer based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, multimodal face data collected from the real world is often imperfect due to missing modalities from various imaging sensors. Recently, flexible-modal FAS~\cite{yu2023flexible} has attracted more attention, which aims to develop a unified multimodal FAS model using complete multimodal face data but is insensitive to test-time missing modalities. In this paper, we tackle one main challenge in flexible-modal FAS, i.e., when missing modality occurs either during training or testing in real-world situations. Inspired by the recent success of the prompt learning in language models, we propose \textbf{V}isual \textbf{P}rompt flexible-modal \textbf{FAS} (VP-FAS), which learns the modal-relevant prompts to adapt the frozen pre-trained foundation model to downstream flexible-modal FAS task. Specifically, both vanilla visual prompts and residual contextual prompts are plugged into multimodal transformers to handle general missing-modality cases, while only requiring less than 4\% learnable parameters compared to training the entire model. Furthermore, missing-modality regularization is proposed to force models to learn consistent multimodal feature embeddings when missing partial modalities. Extensive experiments conducted on two multimodal FAS benchmark datasets demonstrate the effectiveness of our VP-FAS framework that improves the performance under various missing-modality cases while alleviating the requirement of heavy model re-training.
Hybrid Representation-Enhanced Sampling for Bayesian Active Learning in Musculoskeletal Segmentation of Lower Extremities
Jul 26, 2023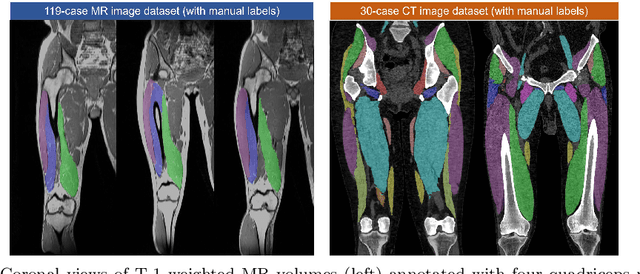
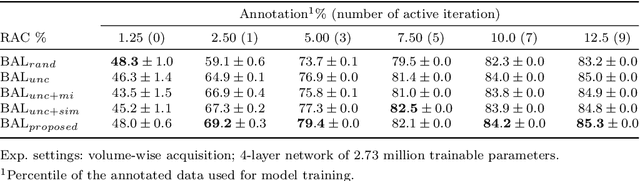
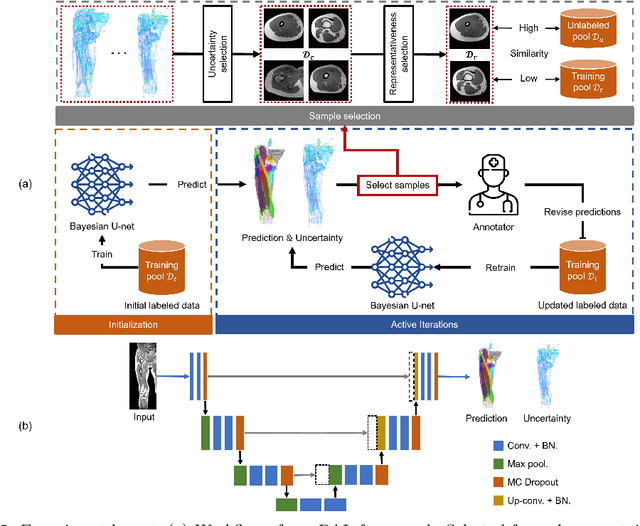
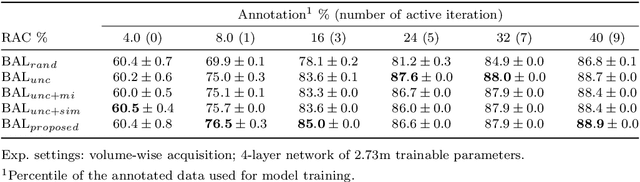
Purpose: Obtaining manual annotations to train deep learning (DL) models for auto-segmentation is often time-consuming. Uncertainty-based Bayesian active learning (BAL) is a widely-adopted method to reduce annotation efforts. Based on BAL, this study introduces a hybrid representation-enhanced sampling strategy that integrates density and diversity criteria to save manual annotation costs by efficiently selecting the most informative samples. Methods: The experiments are performed on two lower extremity (LE) datasets of MRI and CT images by a BAL framework based on Bayesian U-net. Our method selects uncertain samples with high density and diversity for manual revision, optimizing for maximal similarity to unlabeled instances and minimal similarity to existing training data. We assess the accuracy and efficiency using Dice and a proposed metric called reduced annotation cost (RAC), respectively. We further evaluate the impact of various acquisition rules on BAL performance and design an ablation study for effectiveness estimation. Results: The proposed method showed superiority or non-inferiority to other methods on both datasets across two acquisition rules, and quantitative results reveal the pros and cons of the acquisition rules. Our ablation study in volume-wise acquisition shows that the combination of density and diversity criteria outperforms solely using either of them in musculoskeletal segmentation. Conclusion: Our sampling method is proven efficient in reducing annotation costs in image segmentation tasks. The combination of the proposed method and our BAL framework provides a semi-automatic way for efficient annotation of medical image datasets.
MAMo: Leveraging Memory and Attention for Monocular Video Depth Estimation
Jul 26, 2023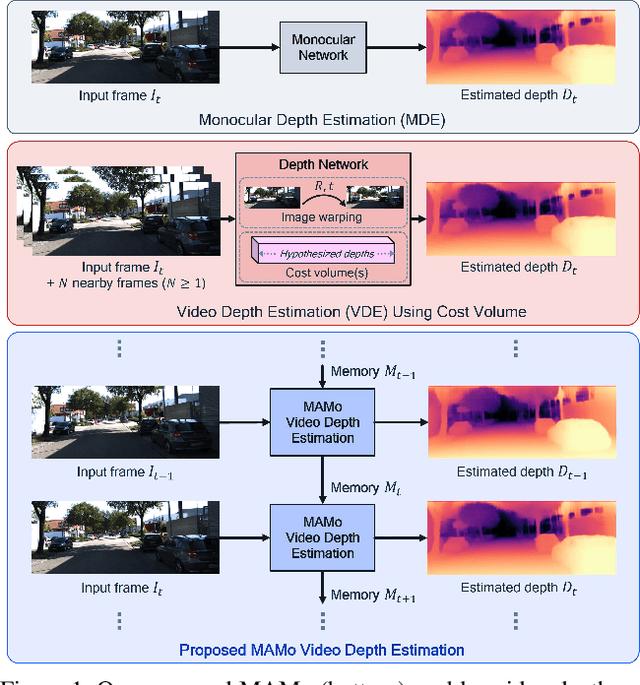
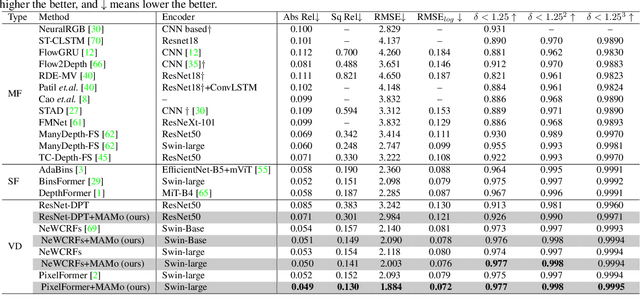
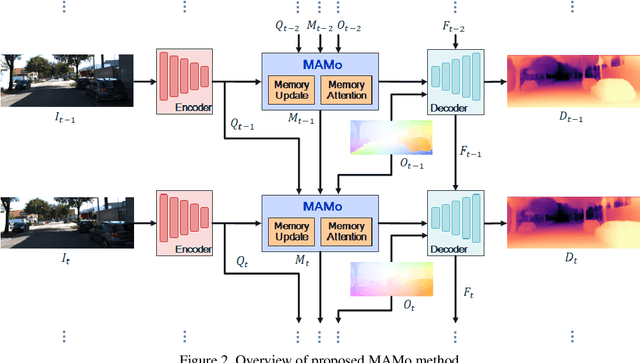
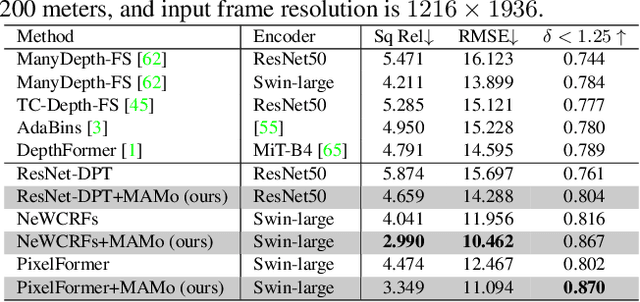
We propose MAMo, a novel memory and attention frame-work for monocular video depth estimation. MAMo can augment and improve any single-image depth estimation networks into video depth estimation models, enabling them to take advantage of the temporal information to predict more accurate depth. In MAMo, we augment model with memory which aids the depth prediction as the model streams through the video. Specifically, the memory stores learned visual and displacement tokens of the previous time instances. This allows the depth network to cross-reference relevant features from the past when predicting depth on the current frame. We introduce a novel scheme to continuously update the memory, optimizing it to keep tokens that correspond with both the past and the present visual information. We adopt attention-based approach to process memory features where we first learn the spatio-temporal relation among the resultant visual and displacement memory tokens using self-attention module. Further, the output features of self-attention are aggregated with the current visual features through cross-attention. The cross-attended features are finally given to a decoder to predict depth on the current frame. Through extensive experiments on several benchmarks, including KITTI, NYU-Depth V2, and DDAD, we show that MAMo consistently improves monocular depth estimation networks and sets new state-of-the-art (SOTA) accuracy. Notably, our MAMo video depth estimation provides higher accuracy with lower latency, when omparing to SOTA cost-volume-based video depth models.
CoTracker: It is Better to Track Together
Jul 14, 2023
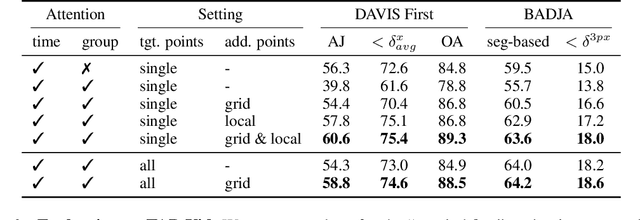
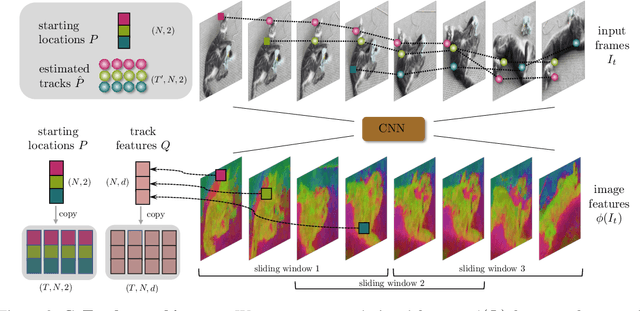
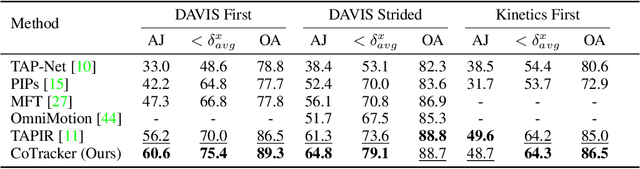
Methods for video motion prediction either estimate jointly the instantaneous motion of all points in a given video frame using optical flow or independently track the motion of individual points throughout the video. The latter is true even for powerful deep-learning methods that can track points through occlusions. Tracking points individually ignores the strong correlation that can exist between the points, for instance, because they belong to the same physical object, potentially harming performance. In this paper, we thus propose CoTracker, an architecture that jointly tracks multiple points throughout an entire video. This architecture combines several ideas from the optical flow and tracking literature in a new, flexible and powerful design. It is based on a transformer network that models the correlation of different points in time via specialised attention layers. The transformer iteratively updates an estimate of several trajectories. It can be applied in a sliding-window manner to very long videos, for which we engineer an unrolled training loop. It can track from one to several points jointly and supports adding new points to track at any time. The result is a flexible and powerful tracking algorithm that outperforms state-of-the-art methods in almost all benchmarks.
DIGEST: Fast and Communication Efficient Decentralized Learning with Local Updates
Jul 14, 2023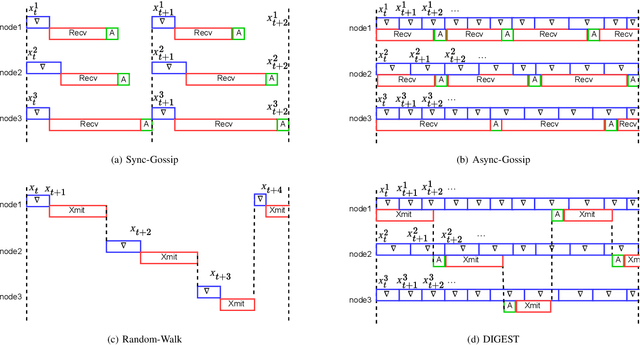


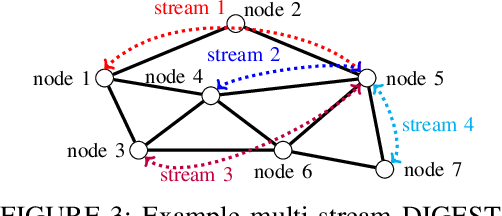
Two widely considered decentralized learning algorithms are Gossip and random walk-based learning. Gossip algorithms (both synchronous and asynchronous versions) suffer from high communication cost, while random-walk based learning experiences increased convergence time. In this paper, we design a fast and communication-efficient asynchronous decentralized learning mechanism DIGEST by taking advantage of both Gossip and random-walk ideas, and focusing on stochastic gradient descent (SGD). DIGEST is an asynchronous decentralized algorithm building on local-SGD algorithms, which are originally designed for communication efficient centralized learning. We design both single-stream and multi-stream DIGEST, where the communication overhead may increase when the number of streams increases, and there is a convergence and communication overhead trade-off which can be leveraged. We analyze the convergence of single- and multi-stream DIGEST, and prove that both algorithms approach to the optimal solution asymptotically for both iid and non-iid data distributions. We evaluate the performance of single- and multi-stream DIGEST for logistic regression and a deep neural network ResNet20. The simulation results confirm that multi-stream DIGEST has nice convergence properties; i.e., its convergence time is better than or comparable to the baselines in iid setting, and outperforms the baselines in non-iid setting.
Unsupervised CD in satellite image time series by contrastive learning and feature tracking
Apr 22, 2023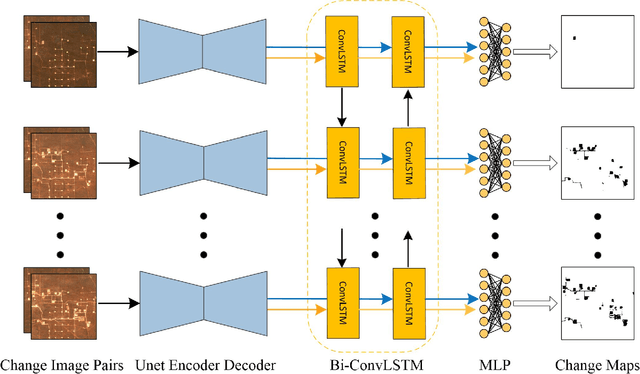

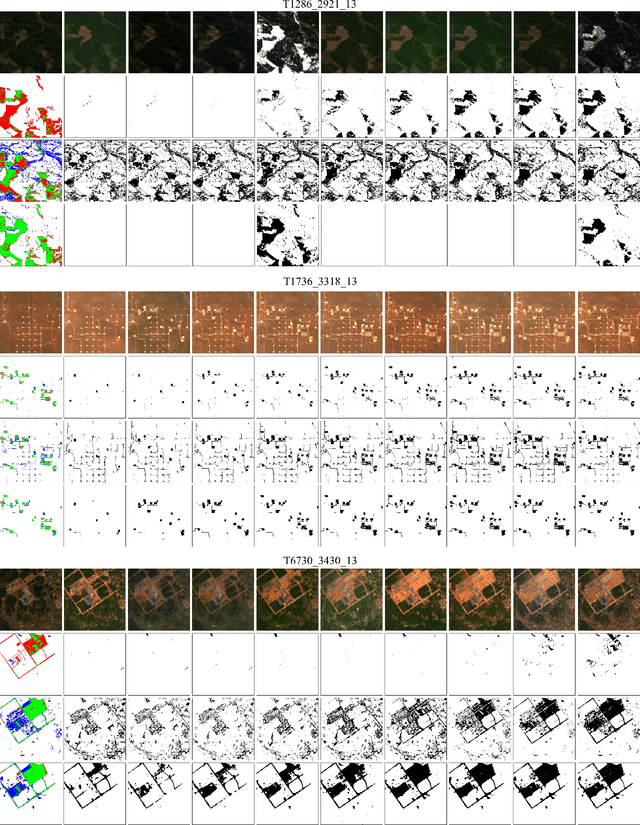

While unsupervised change detection using contrastive learning has been significantly improved the performance of literature techniques, at present, it only focuses on the bi-temporal change detection scenario. Previous state-of-the-art models for image time-series change detection often use features obtained by learning for clustering or training a model from scratch using pseudo labels tailored to each scene. However, these approaches fail to exploit the spatial-temporal information of image time-series or generalize to unseen scenarios. In this work, we propose a two-stage approach to unsupervised change detection in satellite image time-series using contrastive learning with feature tracking. By deriving pseudo labels from pre-trained models and using feature tracking to propagate them among the image time-series, we improve the consistency of our pseudo labels and address the challenges of seasonal changes in long-term remote sensing image time-series. We adopt the self-training algorithm with ConvLSTM on the obtained pseudo labels, where we first use supervised contrastive loss and contrastive random walks to further improve the feature correspondence in space-time. Then a fully connected layer is fine-tuned on the pre-trained multi-temporal features for generating the final change maps. Through comprehensive experiments on two datasets, we demonstrate consistent improvements in accuracy on fitting and inference scenarios.
LEO: Learning Efficient Orderings for Multiobjective Binary Decision Diagrams
Jul 06, 2023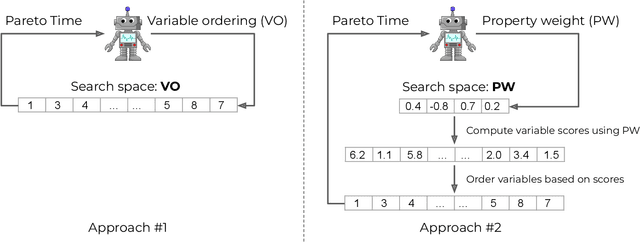
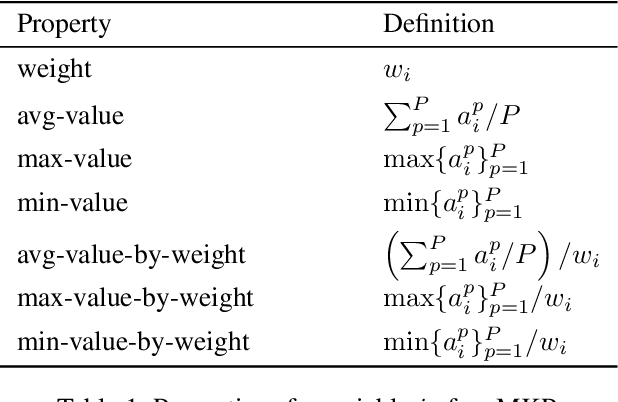
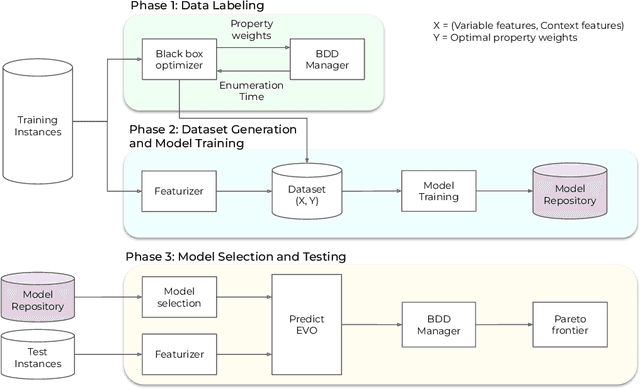
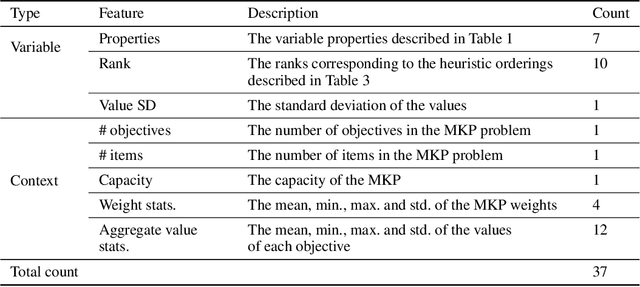
Approaches based on Binary decision diagrams (BDDs) have recently achieved state-of-the-art results for multiobjective integer programming problems. The variable ordering used in constructing BDDs can have a significant impact on their size and on the quality of bounds derived from relaxed or restricted BDDs for single-objective optimization problems. We first showcase a similar impact of variable ordering on the Pareto frontier (PF) enumeration time for the multiobjective knapsack problem, suggesting the need for deriving variable ordering methods that improve the scalability of the multiobjective BDD approach. To that end, we derive a novel parameter configuration space based on variable scoring functions which are linear in a small set of interpretable and easy-to-compute variable features. We show how the configuration space can be efficiently explored using black-box optimization, circumventing the curse of dimensionality (in the number of variables and objectives), and finding good orderings that reduce the PF enumeration time. However, black-box optimization approaches incur a computational overhead that outweighs the reduction in time due to good variable ordering. To alleviate this issue, we propose LEO, a supervised learning approach for finding efficient variable orderings that reduce the enumeration time. Experiments on benchmark sets from the knapsack problem with 3-7 objectives and up to 80 variables show that LEO is ~30-300% and ~10-200% faster at PF enumeration than common ordering strategies and algorithm configuration. Our code and instances are available at https://github.com/khalil-research/leo.
Distributed 3D-Beam Reforming for Hovering-Tolerant UAVs Communication over Coexistence: A Deep-Q Learning for Intelligent Space-Air-Ground Integrated Networks
Jul 18, 2023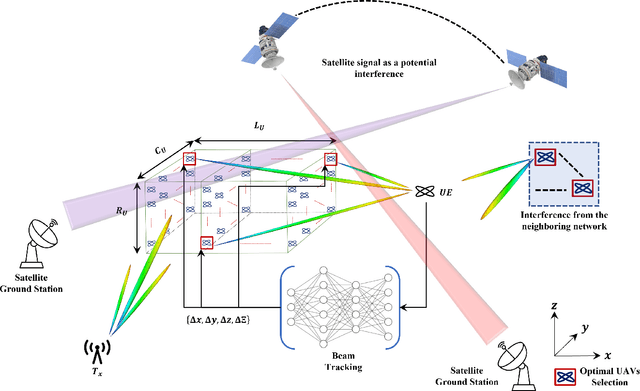
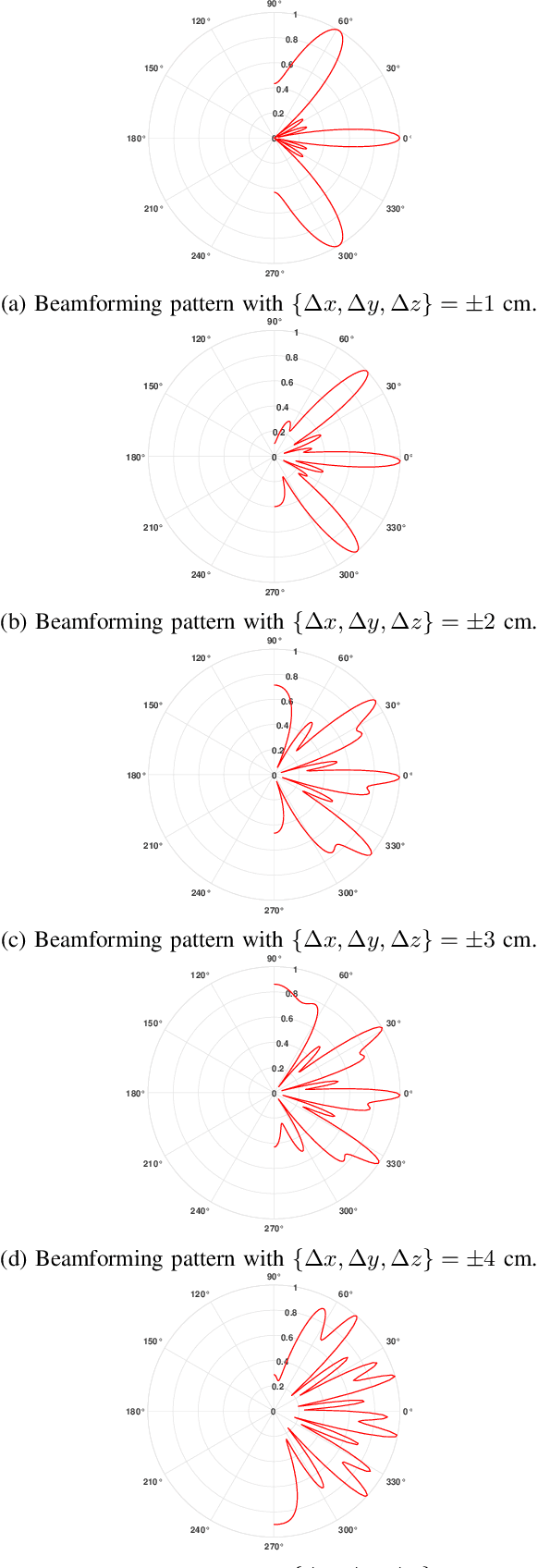
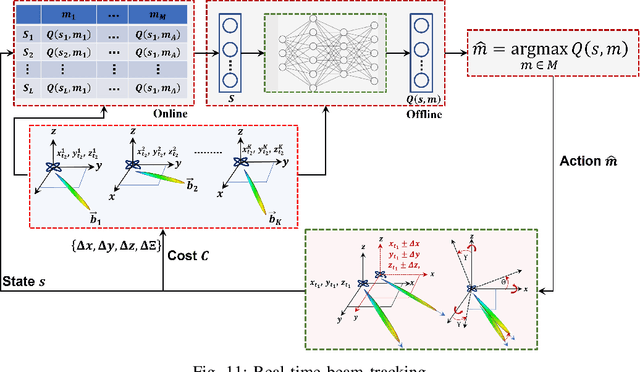
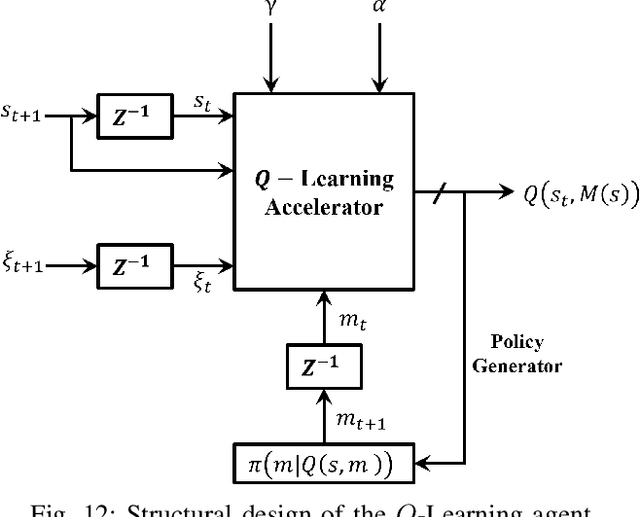
In this paper, we present a novel distributed UAVs beam reforming approach to dynamically form and reform a space-selective beam path in addressing the coexistence with satellite and terrestrial communications. Despite the unique advantage to support wider coverage in UAV-enabled cellular communications, the challenges reside in the array responses' sensitivity to random rotational motion and the hovering nature of the UAVs. A model-free reinforcement learning (RL) based unified UAV beam selection and tracking approach is presented to effectively realize the dynamic distributed and collaborative beamforming. The combined impact of the UAVs' hovering and rotational motions is considered while addressing the impairment due to the interference from the orbiting satellites and neighboring networks. The main objectives of this work are two-fold: first, to acquire the channel awareness to uncover its impairments; second, to overcome the beam distortion to meet the quality of service (QoS) requirements. To overcome the impact of the interference and to maximize the beamforming gain, we define and apply a new optimal UAV selection algorithm based on the brute force criteria. Results demonstrate that the detrimental effects of the channel fading and the interference from the orbiting satellites and neighboring networks can be overcome using the proposed approach. Subsequently, an RL algorithm based on Deep Q-Network (DQN) is developed for real-time beam tracking. By augmenting the system with the impairments due to hovering and rotational motion, we show that the proposed DQN algorithm can reform the beam in real-time with negligible error. It is demonstrated that the proposed DQN algorithm attains an exceptional performance improvement. We show that it requires a few iterations only for fine-tuning its parameters without observing any plateaus irrespective of the hovering tolerance.