 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Benchmarking and Improving the Temporal Reasoning Capability of Large Language Models
Jun 27, 2023
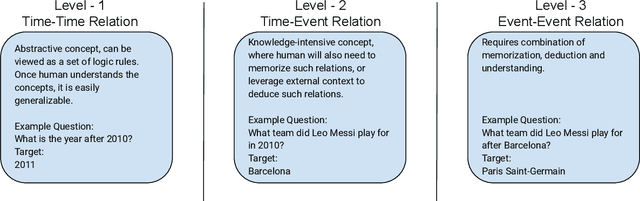

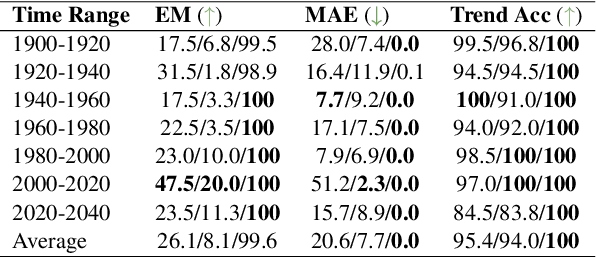

Reasoning about time is of fundamental importance. Many facts are time-dependent. For example, athletes change teams from time to time, and different government officials are elected periodically. Previous time-dependent question answering (QA) datasets tend to be biased in either their coverage of time spans or question types. In this paper, we introduce a comprehensive probing dataset \tempreason to evaluate the temporal reasoning capability of large language models. Our dataset includes questions of three temporal reasoning levels. In addition, we also propose a novel learning framework to improve the temporal reasoning capability of large language models, based on temporal span extraction and time-sensitive reinforcement learning. We conducted experiments in closed book QA, open book QA, and reasoning QA settings and demonstrated the effectiveness of our approach. Our code and data are released on https://github.com/DAMO-NLP-SG/TempReason.
Ord2Seq: Regarding Ordinal Regression as Label Sequence Prediction
Jul 21, 2023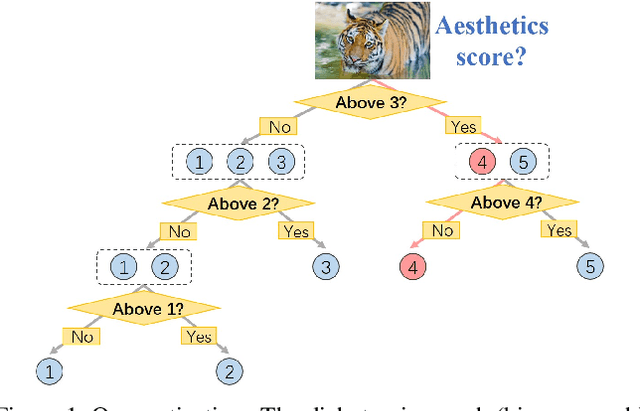
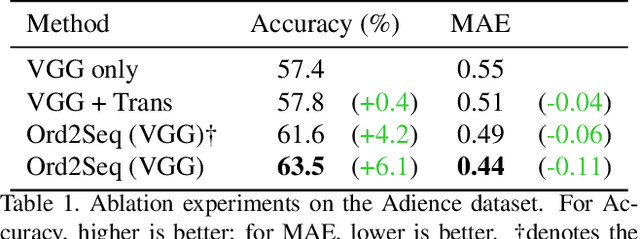
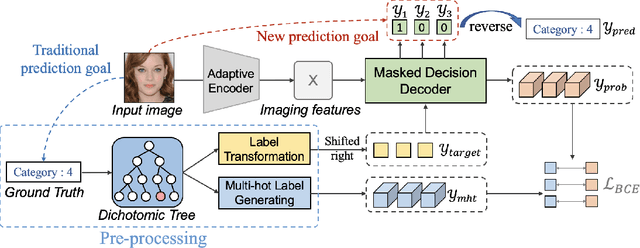
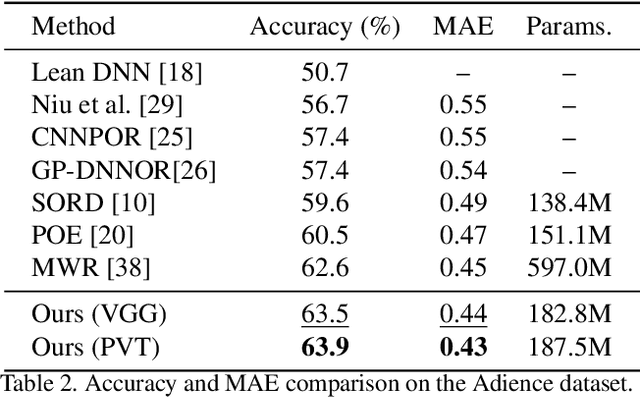
Ordinal regression refers to classifying object instances into ordinal categories. It has been widely studied in many scenarios, such as medical disease grading, movie rating, etc. Known methods focused only on learning inter-class ordinal relationships, but still incur limitations in distinguishing adjacent categories thus far. In this paper, we propose a simple sequence prediction framework for ordinal regression called Ord2Seq, which, for the first time, transforms each ordinal category label into a special label sequence and thus regards an ordinal regression task as a sequence prediction process. In this way, we decompose an ordinal regression task into a series of recursive binary classification steps, so as to subtly distinguish adjacent categories. Comprehensive experiments show the effectiveness of distinguishing adjacent categories for performance improvement and our new approach exceeds state-of-the-art performances in four different scenarios. Codes are available at https://github.com/wjh892521292/Ord2Seq.
Chit-Chat or Deep Talk: Prompt Engineering for Process Mining
Jul 19, 2023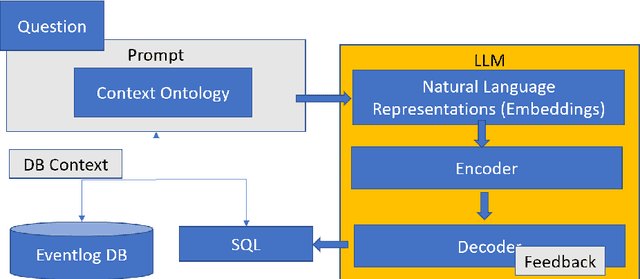
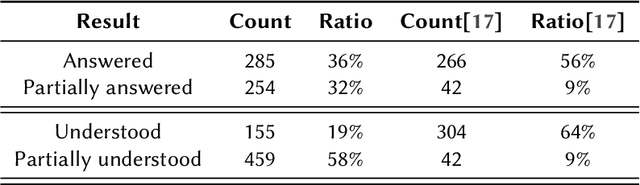
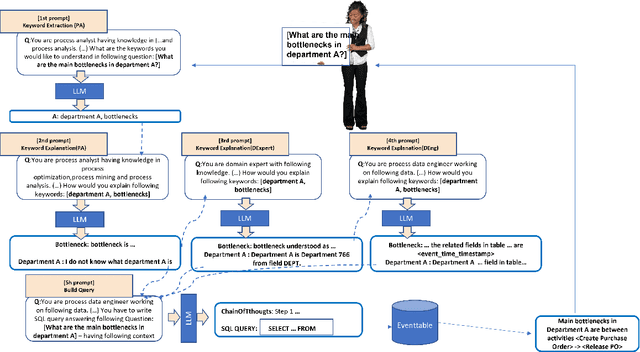

This research investigates the application of Large Language Models (LLMs) to augment conversational agents in process mining, aiming to tackle its inherent complexity and diverse skill requirements. While LLM advancements present novel opportunities for conversational process mining, generating efficient outputs is still a hurdle. We propose an innovative approach that amend many issues in existing solutions, informed by prior research on Natural Language Processing (NLP) for conversational agents. Leveraging LLMs, our framework improves both accessibility and agent performance, as demonstrated by experiments on public question and data sets. Our research sets the stage for future explorations into LLMs' role in process mining and concludes with propositions for enhancing LLM memory, implementing real-time user testing, and examining diverse data sets.
Transmitter Side Beyond-Diagonal Reconfigurable Intelligent Surface for Massive MIMO Networks
Jul 19, 2023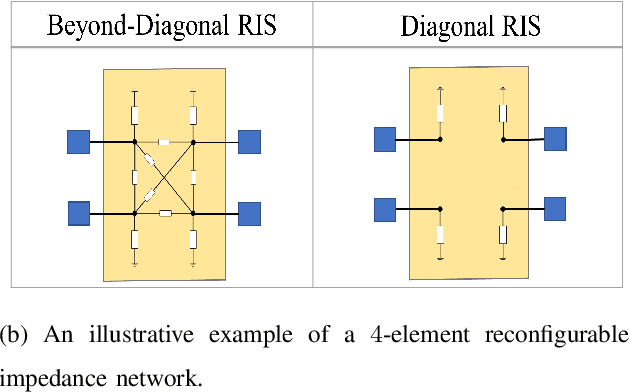
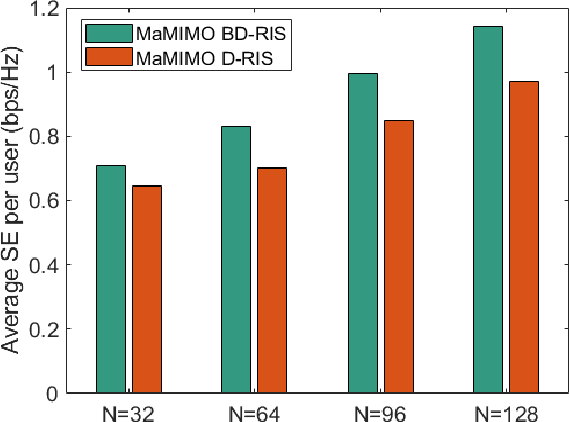
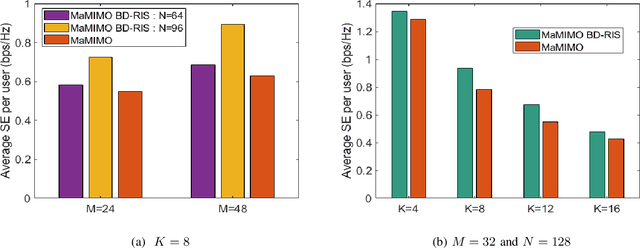

This letter focuses on a transmitter or base station (BS) side beyond-diagonal reflecting intelligent surface (BD-RIS) deployment strategy to enhance the spectral efficiency (SE) of a time-division-duplex massive multiple-input multiple-output (MaMIMO) network. In this strategy, the active antenna array utilizes a BD-RIS at the BS to serve multiple users in the downlink. Based on the knowledge of statistical channel state information (CSI), the BD-RIS coefficients matrix is optimized by employing a novel manifold algorithm, and the power control coefficients are then optimized with the objective of maximizing the minimum SE. Through numerical results we illustrate the SE performance of the proposed transmission framework and compare it with that of a conventional MaMIMO transmission for different network settings.
Visual Prompt Flexible-Modal Face Anti-Spoofing
Jul 26, 2023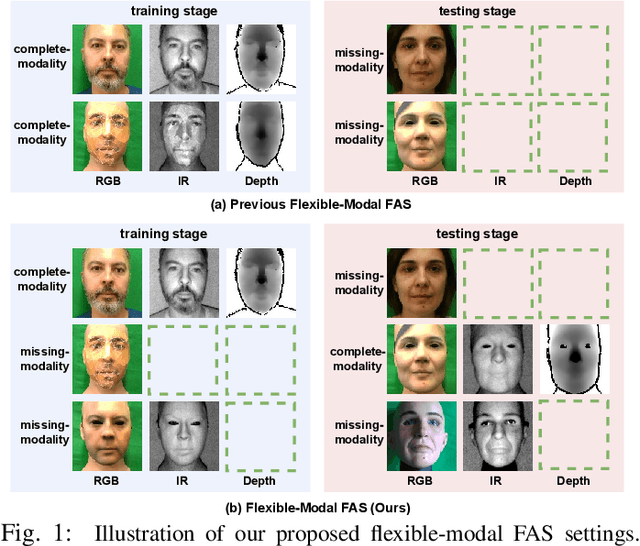
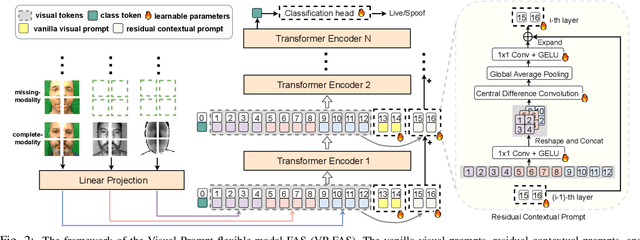
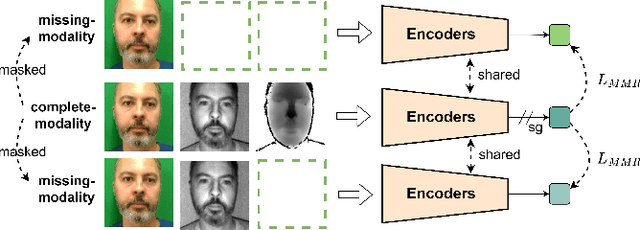
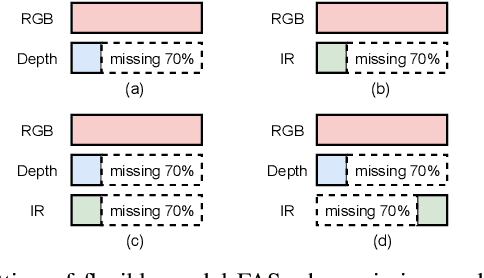
Recently, vision transformer based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, multimodal face data collected from the real world is often imperfect due to missing modalities from various imaging sensors. Recently, flexible-modal FAS~\cite{yu2023flexible} has attracted more attention, which aims to develop a unified multimodal FAS model using complete multimodal face data but is insensitive to test-time missing modalities. In this paper, we tackle one main challenge in flexible-modal FAS, i.e., when missing modality occurs either during training or testing in real-world situations. Inspired by the recent success of the prompt learning in language models, we propose \textbf{V}isual \textbf{P}rompt flexible-modal \textbf{FAS} (VP-FAS), which learns the modal-relevant prompts to adapt the frozen pre-trained foundation model to downstream flexible-modal FAS task. Specifically, both vanilla visual prompts and residual contextual prompts are plugged into multimodal transformers to handle general missing-modality cases, while only requiring less than 4\% learnable parameters compared to training the entire model. Furthermore, missing-modality regularization is proposed to force models to learn consistent multimodal feature embeddings when missing partial modalities. Extensive experiments conducted on two multimodal FAS benchmark datasets demonstrate the effectiveness of our VP-FAS framework that improves the performance under various missing-modality cases while alleviating the requirement of heavy model re-training.
Hybrid Representation-Enhanced Sampling for Bayesian Active Learning in Musculoskeletal Segmentation of Lower Extremities
Jul 26, 2023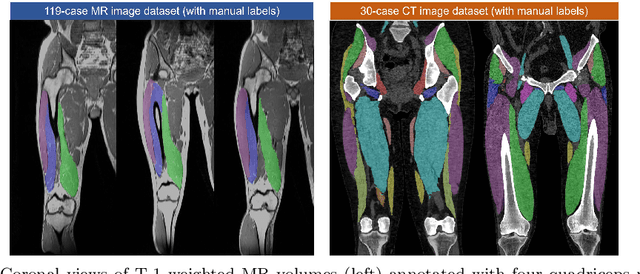
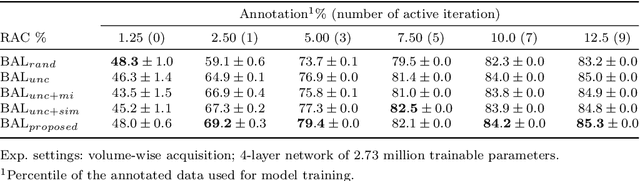
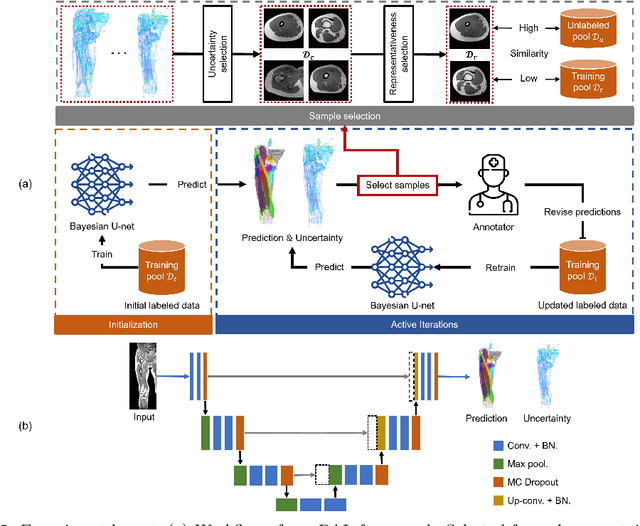
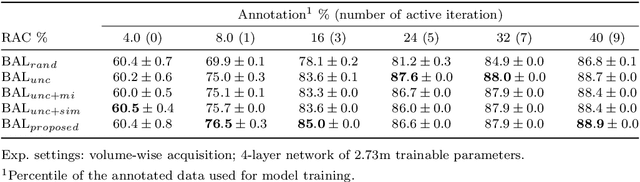
Purpose: Obtaining manual annotations to train deep learning (DL) models for auto-segmentation is often time-consuming. Uncertainty-based Bayesian active learning (BAL) is a widely-adopted method to reduce annotation efforts. Based on BAL, this study introduces a hybrid representation-enhanced sampling strategy that integrates density and diversity criteria to save manual annotation costs by efficiently selecting the most informative samples. Methods: The experiments are performed on two lower extremity (LE) datasets of MRI and CT images by a BAL framework based on Bayesian U-net. Our method selects uncertain samples with high density and diversity for manual revision, optimizing for maximal similarity to unlabeled instances and minimal similarity to existing training data. We assess the accuracy and efficiency using Dice and a proposed metric called reduced annotation cost (RAC), respectively. We further evaluate the impact of various acquisition rules on BAL performance and design an ablation study for effectiveness estimation. Results: The proposed method showed superiority or non-inferiority to other methods on both datasets across two acquisition rules, and quantitative results reveal the pros and cons of the acquisition rules. Our ablation study in volume-wise acquisition shows that the combination of density and diversity criteria outperforms solely using either of them in musculoskeletal segmentation. Conclusion: Our sampling method is proven efficient in reducing annotation costs in image segmentation tasks. The combination of the proposed method and our BAL framework provides a semi-automatic way for efficient annotation of medical image datasets.
MAMo: Leveraging Memory and Attention for Monocular Video Depth Estimation
Jul 26, 2023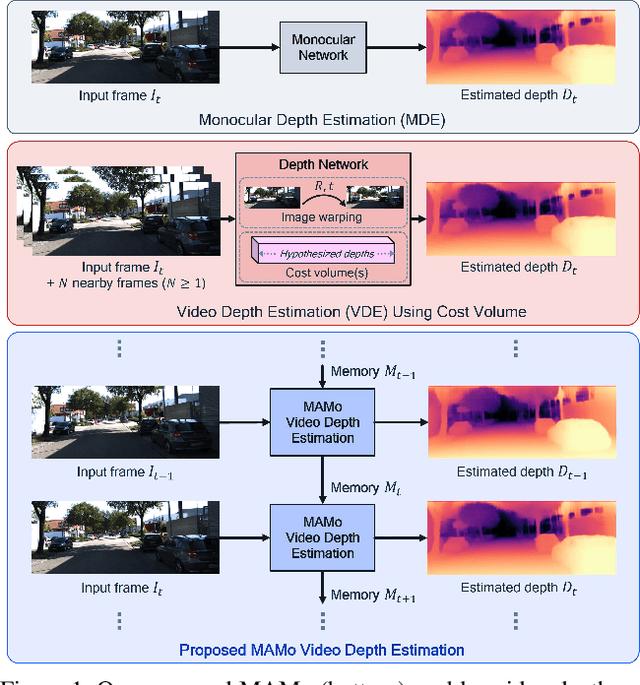
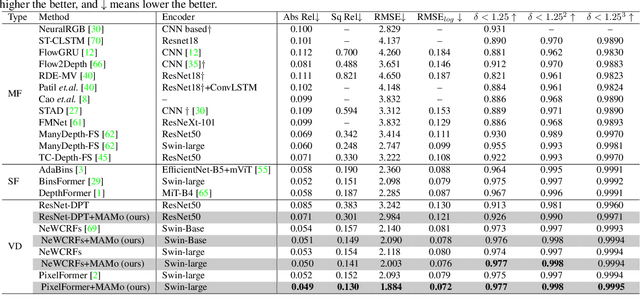
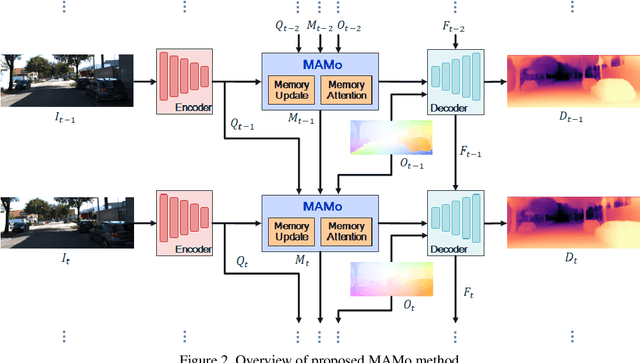
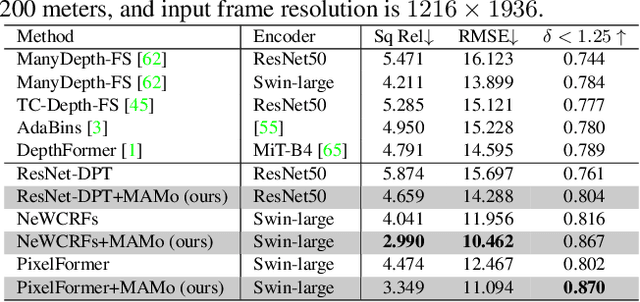
We propose MAMo, a novel memory and attention frame-work for monocular video depth estimation. MAMo can augment and improve any single-image depth estimation networks into video depth estimation models, enabling them to take advantage of the temporal information to predict more accurate depth. In MAMo, we augment model with memory which aids the depth prediction as the model streams through the video. Specifically, the memory stores learned visual and displacement tokens of the previous time instances. This allows the depth network to cross-reference relevant features from the past when predicting depth on the current frame. We introduce a novel scheme to continuously update the memory, optimizing it to keep tokens that correspond with both the past and the present visual information. We adopt attention-based approach to process memory features where we first learn the spatio-temporal relation among the resultant visual and displacement memory tokens using self-attention module. Further, the output features of self-attention are aggregated with the current visual features through cross-attention. The cross-attended features are finally given to a decoder to predict depth on the current frame. Through extensive experiments on several benchmarks, including KITTI, NYU-Depth V2, and DDAD, we show that MAMo consistently improves monocular depth estimation networks and sets new state-of-the-art (SOTA) accuracy. Notably, our MAMo video depth estimation provides higher accuracy with lower latency, when omparing to SOTA cost-volume-based video depth models.
Multitemporal SAR images change detection and visualization using RABASAR and simplified GLR
Jul 15, 2023
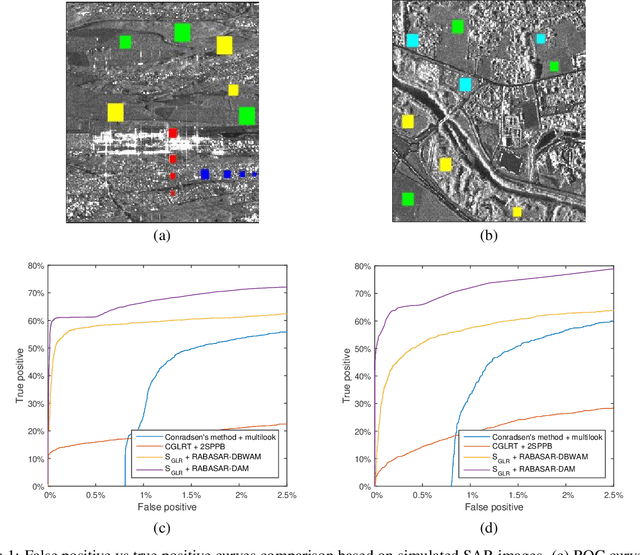


Understanding the state of changed areas requires that precise information be given about the changes. Thus, detecting different kinds of changes is important for land surface monitoring. SAR sensors are ideal to fulfil this task, because of their all-time and all-weather capabilities, with good accuracy of the acquisition geometry and without effects of atmospheric constituents for amplitude data. In this study, we propose a simplified generalized likelihood ratio ($S_{GLR}$) method assuming that corresponding temporal pixels have the same equivalent number of looks (ENL). Thanks to the denoised data provided by a ratio-based multitemporal SAR image denoising method (RABASAR), we successfully applied this similarity test approach to compute the change areas. A new change magnitude index method and an improved spectral clustering-based change classification method are also developed. In addition, we apply the simplified generalized likelihood ratio to detect the maximum change magnitude time, and the change starting and ending times. Then, we propose to use an adaptation of the REACTIV method to visualize the detection results vividly. The effectiveness of the proposed methods is demonstrated through the processing of simulated and SAR images, and the comparison with classical techniques. In particular, numerical experiments proved that the developed method has good performances in detecting farmland area changes, building area changes, harbour area changes and flooding area changes.
Joint Batching and Scheduling for High-Throughput Multiuser Edge AI with Asynchronous Task Arrivals
Jul 15, 2023In this paper, we study joint batching and (task) scheduling to maximise the throughput (i.e., the number of completed tasks) under the practical assumptions of heterogeneous task arrivals and deadlines. The design aims to optimise the number of batches, their starting time instants, and the task-batch association that determines batch sizes. The joint optimisation problem is complex due to multiple coupled variables as mentioned and numerous constraints including heterogeneous tasks arrivals and deadlines, the causality requirements on multi-task execution, and limited radio resources. Underpinning the problem is a basic tradeoff between the size of batch and waiting time for tasks in the batch to be uploaded and executed. Our approach of solving the formulated mixed-integer problem is to transform it into a convex problem via integer relaxation method and $\ell_0$-norm approximation. This results in an efficient alternating optimization algorithm for finding a close-to-optimal solution. In addition, we also design the optimal algorithm from leveraging spectrum holes, which are caused by fixed bandwidth allocation to devices and their asynchronized multi-batch task execution, to admit unscheduled tasks so as to further enhance throughput. Simulation results demonstrate that the proposed framework of joint batching and resource allocation can substantially enhance the throughput of multiuser edge-AI as opposed to a number of simpler benchmarking schemes, e.g., equal-bandwidth allocation, greedy batching and single-batch execution.
Fuzzy clustering of ordinal time series based on two novel distances with economic applications
Apr 24, 2023
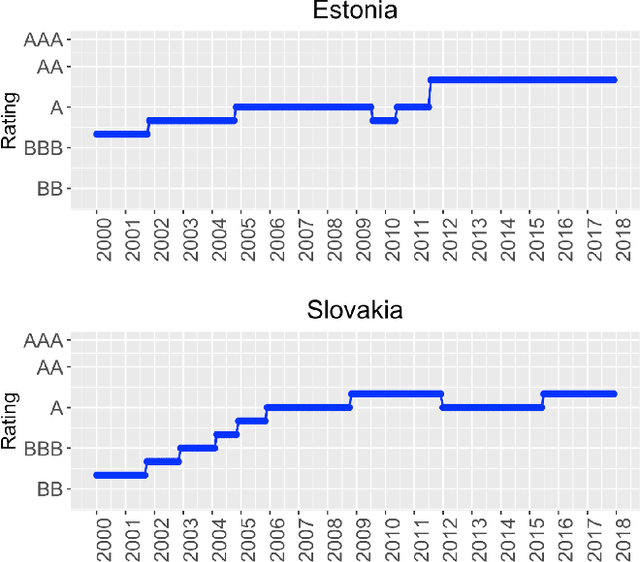
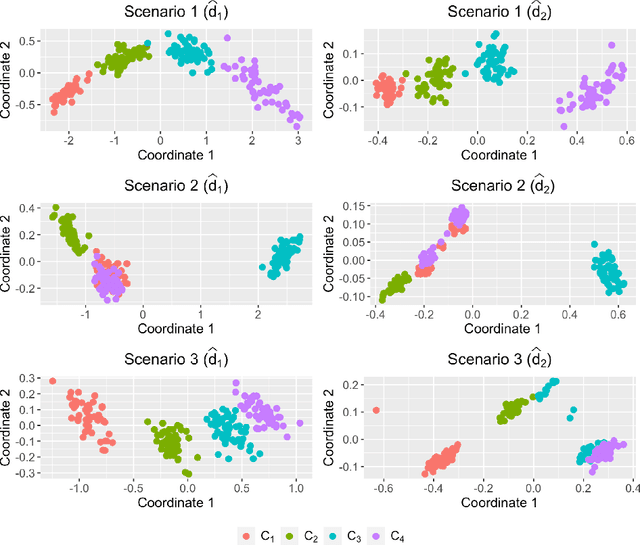
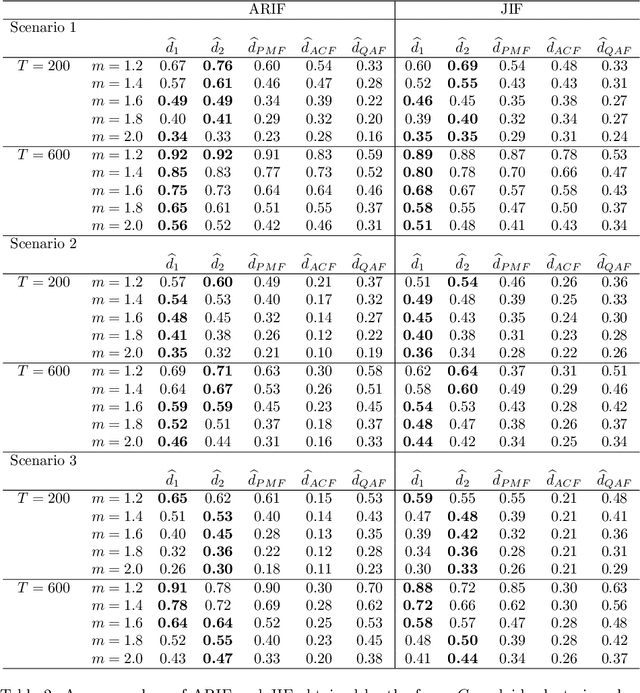
Time series clustering is a central machine learning task with applications in many fields. While the majority of the methods focus on real-valued time series, very few works consider series with discrete response. In this paper, the problem of clustering ordinal time series is addressed. To this aim, two novel distances between ordinal time series are introduced and used to construct fuzzy clustering procedures. Both metrics are functions of the estimated cumulative probabilities, thus automatically taking advantage of the ordering inherent to the series' range. The resulting clustering algorithms are computationally efficient and able to group series generated from similar stochastic processes, reaching accurate results even though the series come from a wide variety of models. Since the dynamic of the series may vary over the time, we adopt a fuzzy approach, thus enabling the procedures to locate each series into several clusters with different membership degrees. An extensive simulation study shows that the proposed methods outperform several alternative procedures. Weighted versions of the clustering algorithms are also presented and their advantages with respect to the original methods are discussed. Two specific applications involving economic time series illustrate the usefulness of the proposed approaches.