 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conditional Cross Attention Network for Multi-Space Embedding without Entanglement in Only a SINGLE Network
Jul 25, 2023
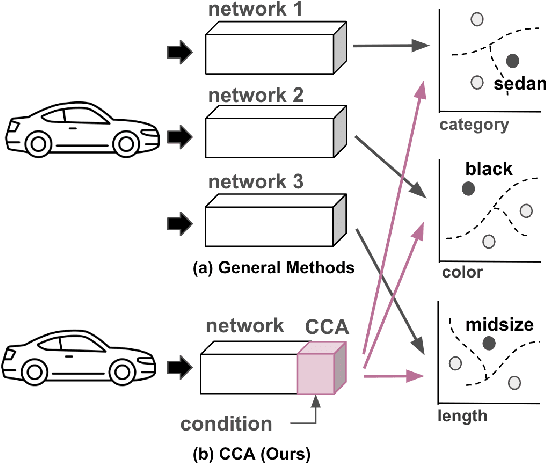

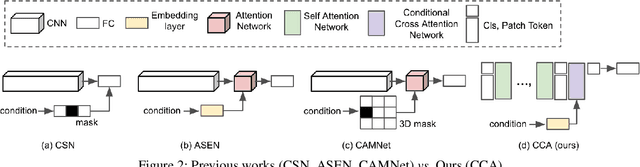
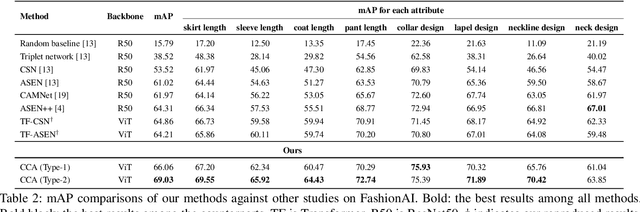
Many studies in vision tasks have aimed to create effective embedding spaces for single-label object prediction within an image. However, in reality, most objects possess multiple specific attributes, such as shape, color, and length, with each attribute composed of various classes. To apply models in real-world scenarios, it is essential to be able to distinguish between the granular components of an object. Conventional approaches to embedding multiple specific attributes into a single network often result in entanglement, where fine-grained features of each attribute cannot be identified separately. To address this problem, we propose a Conditional Cross-Attention Network that induces disentangled multi-space embeddings for various specific attributes with only a single backbone. Firstly, we employ a cross-attention mechanism to fuse and switch the information of conditions (specific attributes), and we demonstrate its effectiveness through a diverse visualization example. Secondly, we leverage the vision transformer for the first time to a fine-grained image retrieval task and present a simple yet effective framework compared to existing methods. Unlike previous studies where performance varied depending on the benchmark dataset, our proposed method achieved consistent state-of-the-art performance on the FashionAI, DARN, DeepFashion, and Zappos50K benchmark datasets.
Fuzzy clustering of ordinal time series based on two novel distances with economic applications
Apr 24, 2023
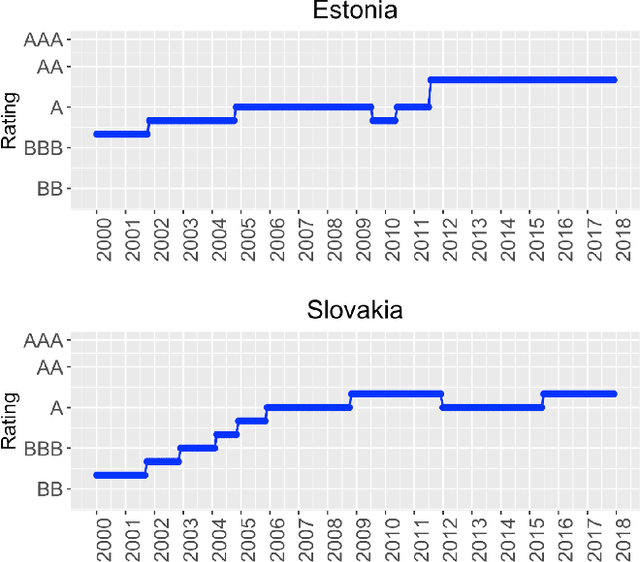
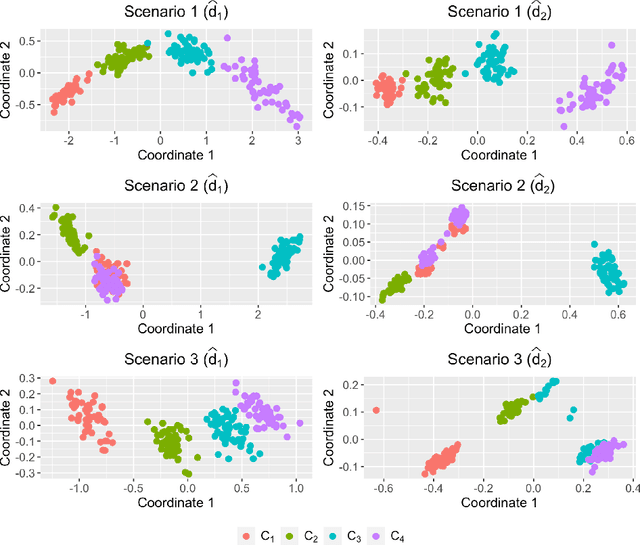
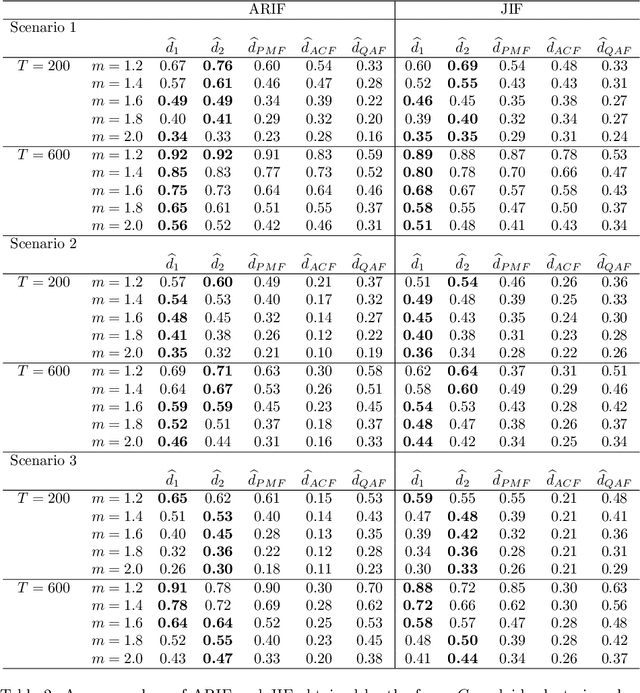
Time series clustering is a central machine learning task with applications in many fields. While the majority of the methods focus on real-valued time series, very few works consider series with discrete response. In this paper, the problem of clustering ordinal time series is addressed. To this aim, two novel distances between ordinal time series are introduced and used to construct fuzzy clustering procedures. Both metrics are functions of the estimated cumulative probabilities, thus automatically taking advantage of the ordering inherent to the series' range. The resulting clustering algorithms are computationally efficient and able to group series generated from similar stochastic processes, reaching accurate results even though the series come from a wide variety of models. Since the dynamic of the series may vary over the time, we adopt a fuzzy approach, thus enabling the procedures to locate each series into several clusters with different membership degrees. An extensive simulation study shows that the proposed methods outperform several alternative procedures. Weighted versions of the clustering algorithms are also presented and their advantages with respect to the original methods are discussed. Two specific applications involving economic time series illustrate the usefulness of the proposed approaches.
Information-theoretic Analysis of Test Data Sensitivity in Uncertainty
Jul 23, 2023Bayesian inference is often utilized for uncertainty quantification tasks. A recent analysis by Xu and Raginsky 2022 rigorously decomposed the predictive uncertainty in Bayesian inference into two uncertainties, called aleatoric and epistemic uncertainties, which represent the inherent randomness in the data-generating process and the variability due to insufficient data, respectively. They analyzed those uncertainties in an information-theoretic way, assuming that the model is well-specified and treating the model's parameters as latent variables. However, the existing information-theoretic analysis of uncertainty cannot explain the widely believed property of uncertainty, known as the sensitivity between the test and training data. It implies that when test data are similar to training data in some sense, the epistemic uncertainty should become small. In this work, we study such uncertainty sensitivity using our novel decomposition method for the predictive uncertainty. Our analysis successfully defines such sensitivity using information-theoretic quantities. Furthermore, we extend the existing analysis of Bayesian meta-learning and show the novel sensitivities among tasks for the first time.
Quadrupedal Footstep Planning using Learned Motion Models of a Black-Box Controller
Jul 23, 2023
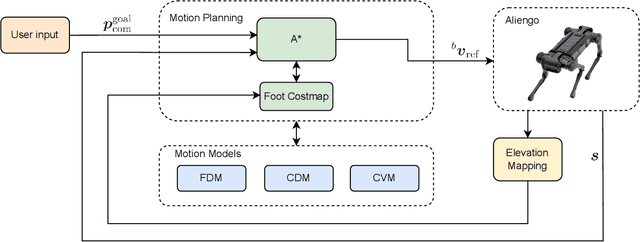
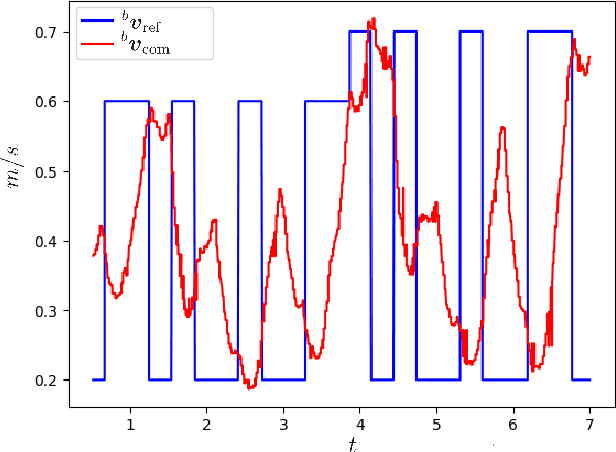

Legged robots are increasingly entering new domains and applications, including search and rescue, inspection, and logistics. However, for such systems to be valuable in real-world scenarios, they must be able to autonomously and robustly navigate irregular terrains. In many cases, robots that are sold on the market do not provide such abilities, being able to perform only blind locomotion. Furthermore, their controller cannot be easily modified by the end-user, requiring a new and time-consuming control synthesis. In this work, we present a fast local motion planning pipeline that extends the capabilities of a black-box walking controller that is only able to track high-level reference velocities. More precisely, we learn a set of motion models for such a controller that maps high-level velocity commands to Center of Mass (CoM) and footstep motions. We then integrate these models with a variant of the A star algorithm to plan the CoM trajectory, footstep sequences, and corresponding high-level velocity commands based on visual information, allowing the quadruped to safely traverse irregular terrains at demand.
Theoretically Guaranteed Policy Improvement Distilled from Model-Based Planning
Jul 24, 2023Model-based reinforcement learning (RL) has demonstrated remarkable successes on a range of continuous control tasks due to its high sample efficiency. To save the computation cost of conducting planning online, recent practices tend to distill optimized action sequences into an RL policy during the training phase. Although the distillation can incorporate both the foresight of planning and the exploration ability of RL policies, the theoretical understanding of these methods is yet unclear. In this paper, we extend the policy improvement step of Soft Actor-Critic (SAC) by developing an approach to distill from model-based planning to the policy. We then demonstrate that such an approach of policy improvement has a theoretical guarantee of monotonic improvement and convergence to the maximum value defined in SAC. We discuss effective design choices and implement our theory as a practical algorithm -- Model-based Planning Distilled to Policy (MPDP) -- that updates the policy jointly over multiple future time steps. Extensive experiments show that MPDP achieves better sample efficiency and asymptotic performance than both model-free and model-based planning algorithms on six continuous control benchmark tasks in MuJoCo.
BOLD: A Benchmark for Linked Data User Agents and a Simulation Framework for Dynamic Linked Data Environments
Jul 18, 2023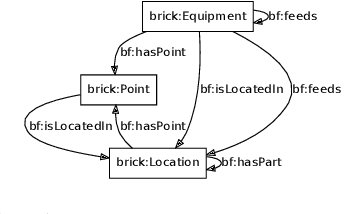

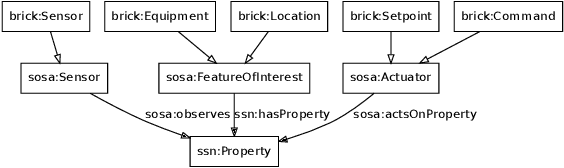

The paper presents the BOLD (Buildings on Linked Data) benchmark for Linked Data agents, next to the framework to simulate dynamic Linked Data environments, using which we built BOLD. The BOLD benchmark instantiates the BOLD framework by providing a read-write Linked Data interface to a smart building with simulated time, occupancy movement and sensors and actuators around lighting. On the Linked Data representation of this environment, agents carry out several specified tasks, such as controlling illumination. The simulation environment provides means to check for the correct execution of the tasks and to measure the performance of agents. We conduct measurements on Linked Data agents based on condition-action rules.
Optimal Vehicle Trajectory Planning for Static Obstacle Avoidance using Nonlinear Optimization
Jul 18, 2023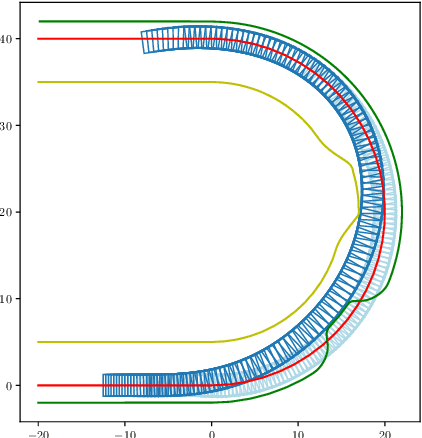
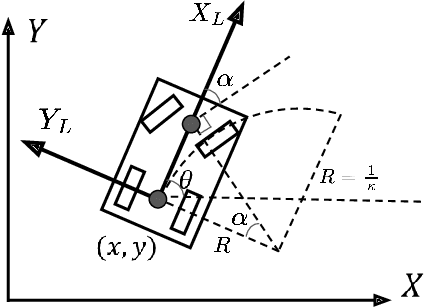
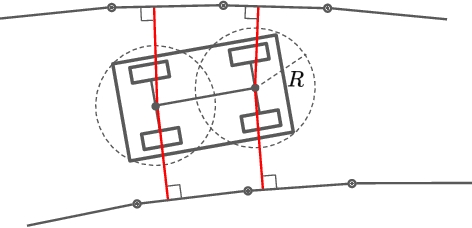
Vehicle trajectory planning is a key component for an autonomous driving system. A practical system not only requires the component to compute a feasible trajectory, but also a comfortable one given certain comfort metrics. Nevertheless, computation efficiency is critical for the system to be deployed as a commercial product. In this paper, we present a novel trajectory planning algorithm based on nonlinear optimization. The algorithm computes a kinematically feasible and comfort-optimal trajectory that achieves collision avoidance with static obstacles. Furthermore, the algorithm is time efficient. It generates an 6-second trajectory within 10 milliseconds on an Intel i7 machine or 20 milliseconds on an Nvidia Drive Orin platform.
A Blender-based channel simulator for FMCW Radar
Jul 18, 2023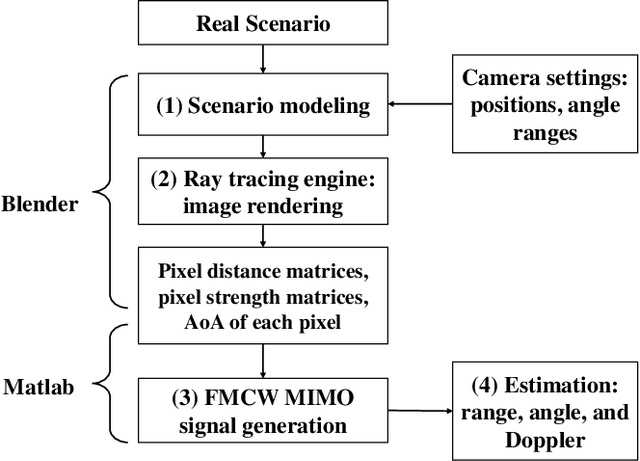

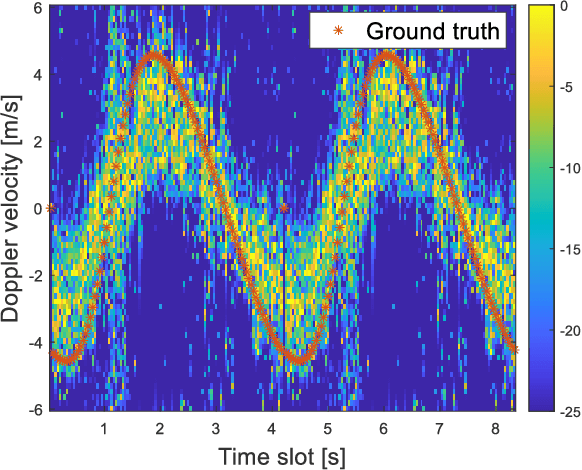
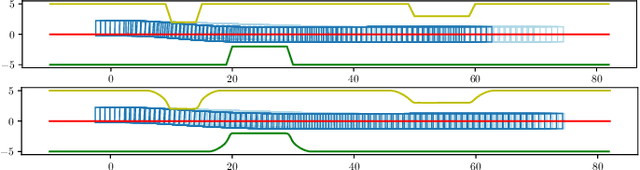
Radar simulation is a promising way to provide data-cube with effectiveness and accuracy for AI-based approaches to radar applications. This paper develops a channel simulator to generate frequency-modulated continuous-wave (FMCW) waveform multiple inputs multiple outputs (MIMO) radar signals. In the proposed simulation framework, an open-source animation tool called Blender is utilized to model the scenarios and render animations. The ray tracing (RT) engine embedded can trace the radar propagation paths, i.e., the distance and signal strength of each path. The beat signal models of time division multiplexing (TDM)-MIMO are adapted to RT outputs. Finally, the environment-based models are simulated to show the validation.
Automating Wood Species Detection and Classification in Microscopic Images of Fibrous Materials with Deep Learning
Jul 18, 2023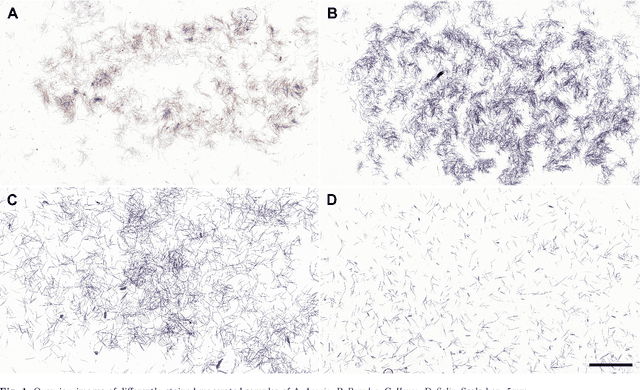
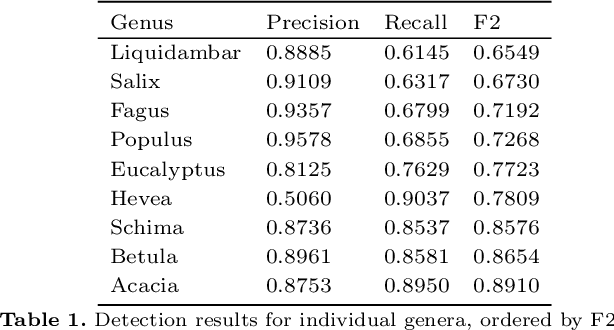

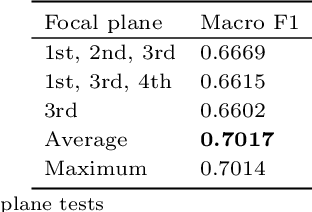
We have developed a methodology for the systematic generation of a large image dataset of macerated wood references, which we used to generate image data for nine hardwood genera. This is the basis for a substantial approach to automate, for the first time, the identification of hardwood species in microscopic images of fibrous materials by deep learning. Our methodology includes a flexible pipeline for easy annotation of vessel elements. We compare the performance of different neural network architectures and hyperparameters. Our proposed method performs similarly well to human experts. In the future, this will improve controls on global wood fiber product flows to protect forests.
Summaries, Highlights, and Action items: Design, implementation and evaluation of an LLM-powered meeting recap system
Jul 28, 2023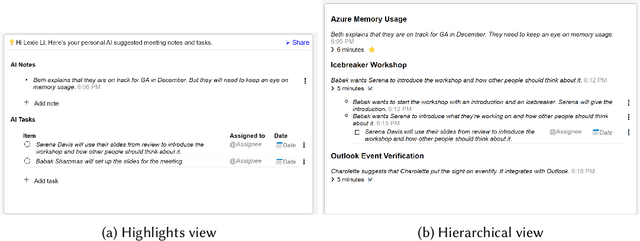
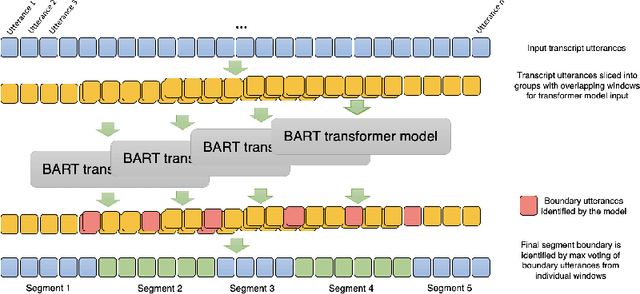

Meetings play a critical infrastructural role in the coordination of work. In recent years, due to shift to hybrid and remote work, more meetings are moving to online Computer Mediated Spaces. This has led to new problems (e.g. more time spent in less engaging meetings) and new opportunities (e.g. automated transcription/captioning and recap support). Recent advances in large language models (LLMs) for dialog summarization have the potential to improve the experience of meetings by reducing individuals' meeting load and increasing the clarity and alignment of meeting outputs. Despite this potential, they face technological limitation due to long transcripts and inability to capture diverse recap needs based on user's context. To address these gaps, we design, implement and evaluate in-context a meeting recap system. We first conceptualize two salient recap representations -- important highlights, and a structured, hierarchical minutes view. We develop a system to operationalize the representations with dialogue summarization as its building blocks. Finally, we evaluate the effectiveness of the system with seven users in the context of their work meetings. Our findings show promise in using LLM-based dialogue summarization for meeting recap and the need for both representations in different contexts. However, we find that LLM-based recap still lacks an understanding of whats personally relevant to participants, can miss important details, and mis-attributions can be detrimental to group dynamics. We identify collaboration opportunities such as a shared recap document that a high quality recap enables. We report on implications for designing AI systems to partner with users to learn and improve from natural interactions to overcome the limitations related to personal relevance and summarization quality.