 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ForzaETH Race Stack -- Scaled Autonomous Head-to-Head Racing on Fully Commercial off-the-Shelf Hardware
Mar 18, 2024

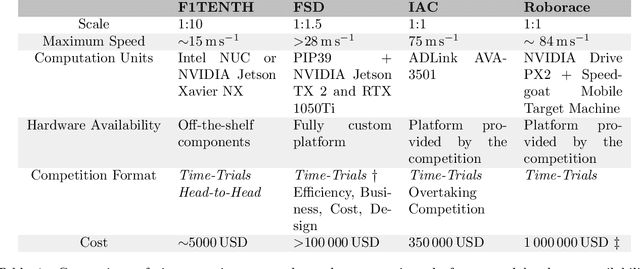
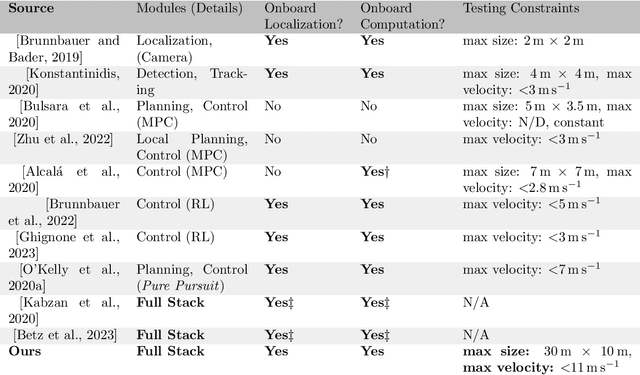
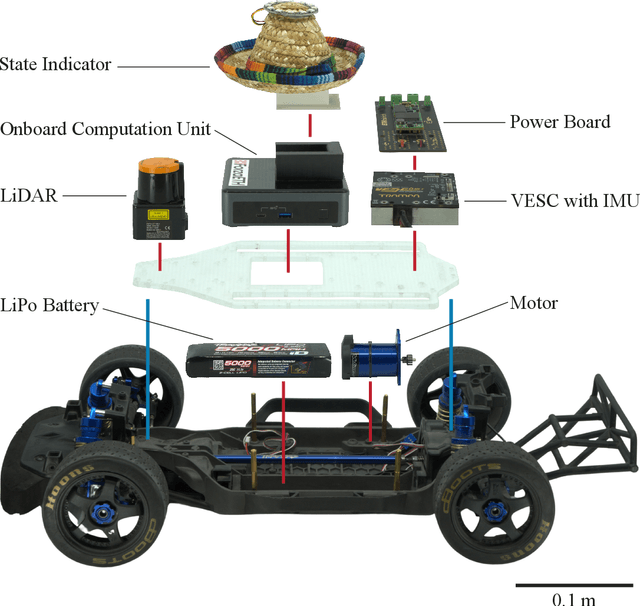
Autonomous racing in robotics combines high-speed dynamics with the necessity for reliability and real-time decision-making. While such racing pushes software and hardware to their limits, many existing full-system solutions necessitate complex, custom hardware and software, and usually focus on Time-Trials rather than full unrestricted Head-to-Head racing, due to financial and safety constraints. This limits their reproducibility, making advancements and replication feasible mostly for well-resourced laboratories with comprehensive expertise in mechanical, electrical, and robotics fields. Researchers interested in the autonomy domain but with only partial experience in one of these fields, need to spend significant time with familiarization and integration. The ForzaETH Race Stack addresses this gap by providing an autonomous racing software platform designed for F1TENTH, a 1:10 scaled Head-to-Head autonomous racing competition, which simplifies replication by using commercial off-the-shelf hardware. This approach enhances the competitive aspect of autonomous racing and provides an accessible platform for research and development in the field. The ForzaETH Race Stack is designed with modularity and operational ease of use in mind, allowing customization and adaptability to various environmental conditions, such as track friction and layout. Capable of handling both Time-Trials and Head-to-Head racing, the stack has demonstrated its effectiveness, robustness, and adaptability in the field by winning the official F1TENTH international competition multiple times.
Self-Supervised Backbone Framework for Diverse Agricultural Vision Tasks
Mar 22, 2024Computer vision in agriculture is game-changing with its ability to transform farming into a data-driven, precise, and sustainable industry. Deep learning has empowered agriculture vision to analyze vast, complex visual data, but heavily rely on the availability of large annotated datasets. This remains a bottleneck as manual labeling is error-prone, time-consuming, and expensive. The lack of efficient labeling approaches inspired us to consider self-supervised learning as a paradigm shift, learning meaningful feature representations from raw agricultural image data. In this work, we explore how self-supervised representation learning unlocks the potential applicability to diverse agriculture vision tasks by eliminating the need for large-scale annotated datasets. We propose a lightweight framework utilizing SimCLR, a contrastive learning approach, to pre-train a ResNet-50 backbone on a large, unannotated dataset of real-world agriculture field images. Our experimental analysis and results indicate that the model learns robust features applicable to a broad range of downstream agriculture tasks discussed in the paper. Additionally, the reduced reliance on annotated data makes our approach more cost-effective and accessible, paving the way for broader adoption of computer vision in agriculture.
Modular Deep Active Learning Framework for Image Annotation: A Technical Report for the Ophthalmo-AI Project
Mar 22, 2024Image annotation is one of the most essential tasks for guaranteeing proper treatment for patients and tracking progress over the course of therapy in the field of medical imaging and disease diagnosis. However, manually annotating a lot of 2D and 3D imaging data can be extremely tedious. Deep Learning (DL) based segmentation algorithms have completely transformed this process and made it possible to automate image segmentation. By accurately segmenting medical images, these algorithms can greatly minimize the time and effort necessary for manual annotation. Additionally, by incorporating Active Learning (AL) methods, these segmentation algorithms can perform far more effectively with a smaller amount of ground truth data. We introduce MedDeepCyleAL, an end-to-end framework implementing the complete AL cycle. It provides researchers with the flexibility to choose the type of deep learning model they wish to employ and includes an annotation tool that supports the classification and segmentation of medical images. The user-friendly interface allows for easy alteration of the AL and DL model settings through a configuration file, requiring no prior programming experience. While MedDeepCyleAL can be applied to any kind of image data, we have specifically applied it to ophthalmology data in this project.
On the Convergence of Adam under Non-uniform Smoothness: Separability from SGDM and Beyond
Mar 22, 2024This paper aims to clearly distinguish between Stochastic Gradient Descent with Momentum (SGDM) and Adam in terms of their convergence rates. We demonstrate that Adam achieves a faster convergence compared to SGDM under the condition of non-uniformly bounded smoothness. Our findings reveal that: (1) in deterministic environments, Adam can attain the known lower bound for the convergence rate of deterministic first-order optimizers, whereas the convergence rate of Gradient Descent with Momentum (GDM) has higher order dependence on the initial function value; (2) in stochastic setting, Adam's convergence rate upper bound matches the lower bounds of stochastic first-order optimizers, considering both the initial function value and the final error, whereas there are instances where SGDM fails to converge with any learning rate. These insights distinctly differentiate Adam and SGDM regarding their convergence rates. Additionally, by introducing a novel stopping-time based technique, we further prove that if we consider the minimum gradient norm during iterations, the corresponding convergence rate can match the lower bounds across all problem hyperparameters. The technique can also help proving that Adam with a specific hyperparameter scheduler is parameter-agnostic, which hence can be of independent interest.
An In-Depth Analysis of Data Reduction Methods for Sustainable Deep Learning
Mar 22, 2024In recent years, Deep Learning has gained popularity for its ability to solve complex classification tasks, increasingly delivering better results thanks to the development of more accurate models, the availability of huge volumes of data and the improved computational capabilities of modern computers. However, these improvements in performance also bring efficiency problems, related to the storage of datasets and models, and to the waste of energy and time involved in both the training and inference processes. In this context, data reduction can help reduce energy consumption when training a deep learning model. In this paper, we present up to eight different methods to reduce the size of a tabular training dataset, and we develop a Python package to apply them. We also introduce a representativeness metric based on topology to measure how similar are the reduced datasets and the full training dataset. Additionally, we develop a methodology to apply these data reduction methods to image datasets for object detection tasks. Finally, we experimentally compare how these data reduction methods affect the representativeness of the reduced dataset, the energy consumption and the predictive performance of the model.
A Twin Delayed Deep Deterministic Policy Gradient Algorithm for Autonomous Ground Vehicle Navigation via Digital Twin Perception Awareness
Mar 22, 2024Autonomous ground vehicle (UGV) navigation has the potential to revolutionize the transportation system by increasing accessibility to disabled people, ensure safety and convenience of use. However, UGV requires extensive and efficient testing and evaluation to ensure its acceptance for public use. This testing are mostly done in a simulator which result to sim2real transfer gap. In this paper, we propose a digital twin perception awareness approach for the control of robot navigation without prior creation of the virtual environment (VT) environment state. To achieve this, we develop a twin delayed deep deterministic policy gradient (TD3) algorithm that ensures collision avoidance and goal-based path planning. We demonstrate the performance of our approach on different environment dynamics. We show that our approach is capable of efficiently avoiding collision with obstacles and navigating to its desired destination, while at the same time safely avoids obstacles using the information received from the LIDAR sensor mounted on the robot. Our approach bridges the gap between sim-to-real transfer and contributes to the adoption of UGVs in real world. We validate our approach in simulation and a real-world application in an office space.
VRSO: Visual-Centric Reconstruction for Static Object Annotation
Mar 22, 2024As a part of the perception results of intelligent driving systems, static object detection (SOD) in 3D space provides crucial cues for driving environment understanding. With the rapid deployment of deep neural networks for SOD tasks, the demand for high-quality training samples soars. The traditional, also reliable, way is manual labeling over the dense LiDAR point clouds and reference images. Though most public driving datasets adopt this strategy to provide SOD ground truth (GT), it is still expensive (requires LiDAR scanners) and low-efficient (time-consuming and unscalable) in practice. This paper introduces VRSO, a visual-centric approach for static object annotation. VRSO is distinguished in low cost, high efficiency, and high quality: (1) It recovers static objects in 3D space with only camera images as input, and (2) manual labeling is barely involved since GT for SOD tasks is generated based on an automatic reconstruction and annotation pipeline. (3) Experiments on the Waymo Open Dataset show that the mean reprojection error from VRSO annotation is only 2.6 pixels, around four times lower than the Waymo labeling (10.6 pixels). Source code is available at: https://github.com/CaiYingFeng/VRSO.
Tri-Perspective View Decomposition for Geometry-Aware Depth Completion
Mar 22, 2024Depth completion is a vital task for autonomous driving, as it involves reconstructing the precise 3D geometry of a scene from sparse and noisy depth measurements. However, most existing methods either rely only on 2D depth representations or directly incorporate raw 3D point clouds for compensation, which are still insufficient to capture the fine-grained 3D geometry of the scene. To address this challenge, we introduce Tri-Perspective view Decomposition (TPVD), a novel framework that can explicitly model 3D geometry. In particular, (1) TPVD ingeniously decomposes the original point cloud into three 2D views, one of which corresponds to the sparse depth input. (2) We design TPV Fusion to update the 2D TPV features through recurrent 2D-3D-2D aggregation, where a Distance-Aware Spherical Convolution (DASC) is applied. (3) By adaptively choosing TPV affinitive neighbors, the newly proposed Geometric Spatial Propagation Network (GSPN) further improves the geometric consistency. As a result, our TPVD outperforms existing methods on KITTI, NYUv2, and SUN RGBD. Furthermore, we build a novel depth completion dataset named TOFDC, which is acquired by the time-of-flight (TOF) sensor and the color camera on smartphones. Project page: https://yanzq95.github.io/projectpage/TOFDC/index.html
Accurately Predicting Probabilities of Safety-Critical Rare Events for Intelligent Systems
Mar 22, 2024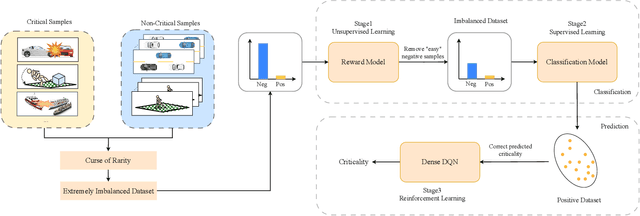
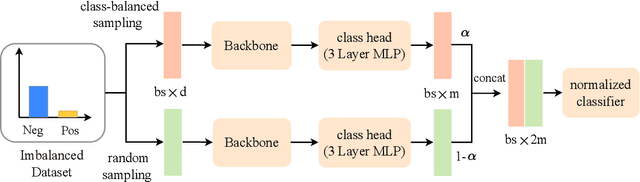
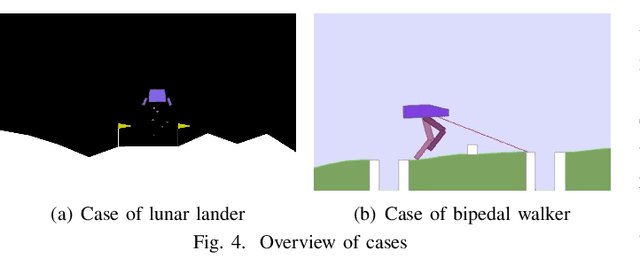
Intelligent systems are increasingly integral to our daily lives, yet rare safety-critical events present significant latent threats to their practical deployment. Addressing this challenge hinges on accurately predicting the probability of safety-critical events occurring within a given time step from the current state, a metric we define as 'criticality'. The complexity of predicting criticality arises from the extreme data imbalance caused by rare events in high dimensional variables associated with the rare events, a challenge we refer to as the curse of rarity. Existing methods tend to be either overly conservative or prone to overlooking safety-critical events, thus struggling to achieve both high precision and recall rates, which severely limits their applicability. This study endeavors to develop a criticality prediction model that excels in both precision and recall rates for evaluating the criticality of safety-critical autonomous systems. We propose a multi-stage learning framework designed to progressively densify the dataset, mitigating the curse of rarity across stages. To validate our approach, we evaluate it in two cases: lunar lander and bipedal walker scenarios. The results demonstrate that our method surpasses traditional approaches, providing a more accurate and dependable assessment of criticality in intelligent systems.
RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners
Mar 22, 2024

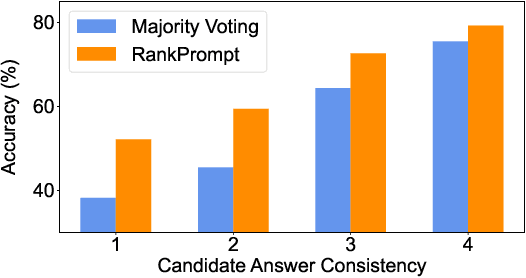
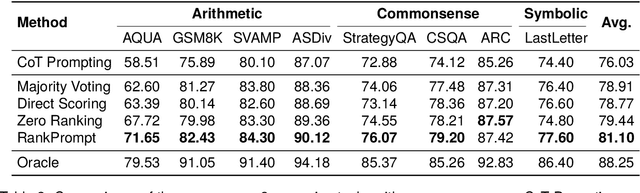
Large Language Models (LLMs) have achieved impressive performance across various reasoning tasks. However, even state-of-the-art LLMs such as ChatGPT are prone to logical errors during their reasoning processes. Existing solutions, such as deploying task-specific verifiers or voting over multiple reasoning paths, either require extensive human annotations or fail in scenarios with inconsistent responses. To address these challenges, we introduce RankPrompt, a new prompting method that enables LLMs to self-rank their responses without additional resources. RankPrompt breaks down the ranking problem into a series of comparisons among diverse responses, leveraging the inherent capabilities of LLMs to generate chains of comparison as contextual exemplars. Our experiments across 11 arithmetic and commonsense reasoning tasks show that RankPrompt significantly enhances the reasoning performance of ChatGPT and GPT-4, with improvements of up to 13%. Moreover, RankPrompt excels in LLM-based automatic evaluations for open-ended tasks, aligning with human judgments 74% of the time in the AlpacaEval dataset. It also exhibits robustness to variations in response order and consistency. Collectively, our results validate RankPrompt as an effective method for eliciting high-quality feedback from language models.