 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SuryaKiran at MEDIQA-Sum 2023: Leveraging LoRA for Clinical Dialogue Summarization
Jul 11, 2023
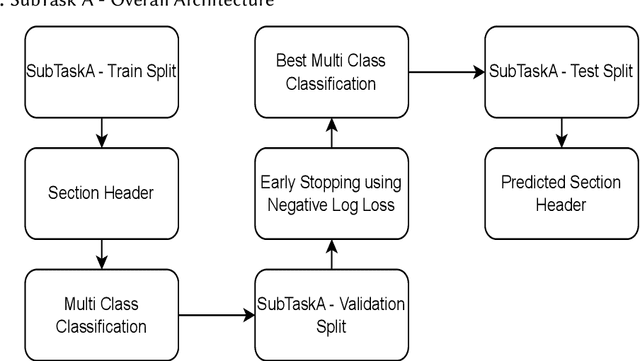
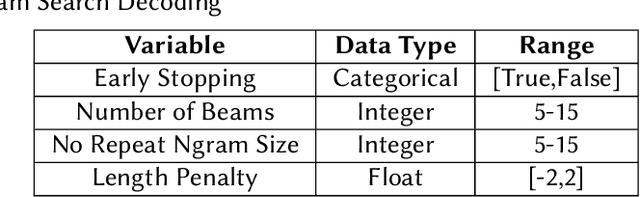
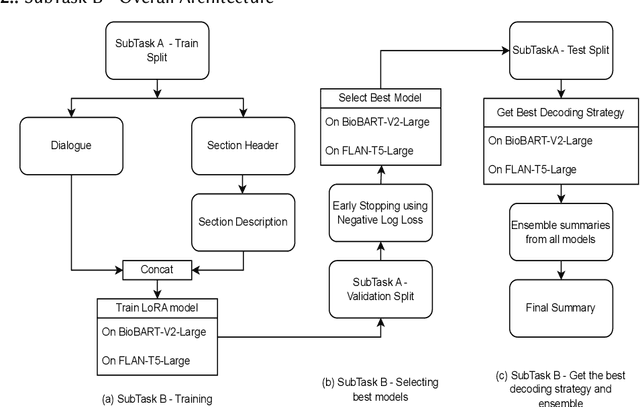
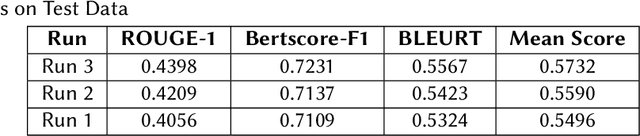
Finetuning Large Language Models helps improve the results for domain-specific use cases. End-to-end finetuning of large language models is time and resource intensive and has high storage requirements to store the finetuned version of the large language model. Parameter Efficient Fine Tuning (PEFT) methods address the time and resource challenges by keeping the large language model as a fixed base and add additional layers, which the PEFT methods finetune. This paper demonstrates the evaluation results for one such PEFT method Low Rank Adaptation (LoRA), for Clinical Dialogue Summarization. The evaluation results show that LoRA works at par with end-to-end finetuning for a large language model. The paper presents the evaluations done for solving both the Subtask A and B from ImageCLEFmedical {https://www.imageclef.org/2023/medical}
Assessing the Impact of Context Inference Error and Partial Observability on RL Methods for Just-In-Time Adaptive Interventions
May 17, 2023
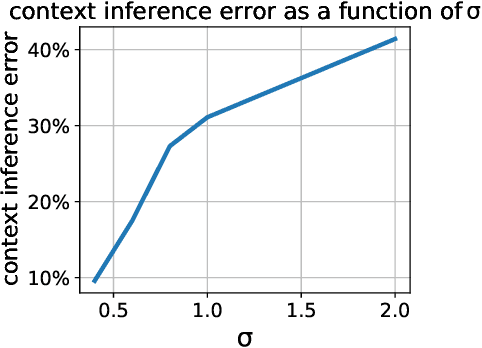

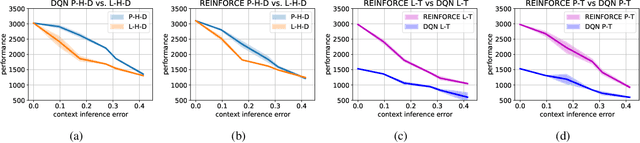
Just-in-Time Adaptive Interventions (JITAIs) are a class of personalized health interventions developed within the behavioral science community. JITAIs aim to provide the right type and amount of support by iteratively selecting a sequence of intervention options from a pre-defined set of components in response to each individual's time varying state. In this work, we explore the application of reinforcement learning methods to the problem of learning intervention option selection policies. We study the effect of context inference error and partial observability on the ability to learn effective policies. Our results show that the propagation of uncertainty from context inferences is critical to improving intervention efficacy as context uncertainty increases, while policy gradient algorithms can provide remarkable robustness to partially observed behavioral state information.
InterFormer: Real-time Interactive Image Segmentation
Apr 06, 2023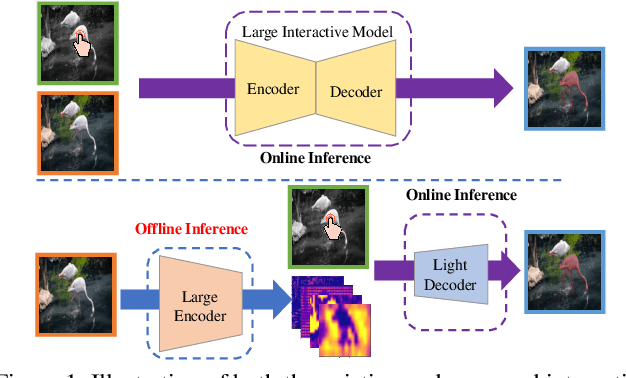

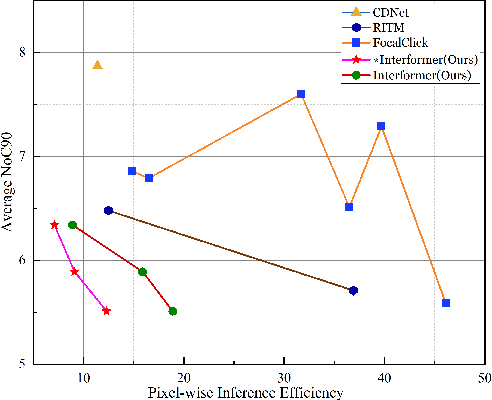
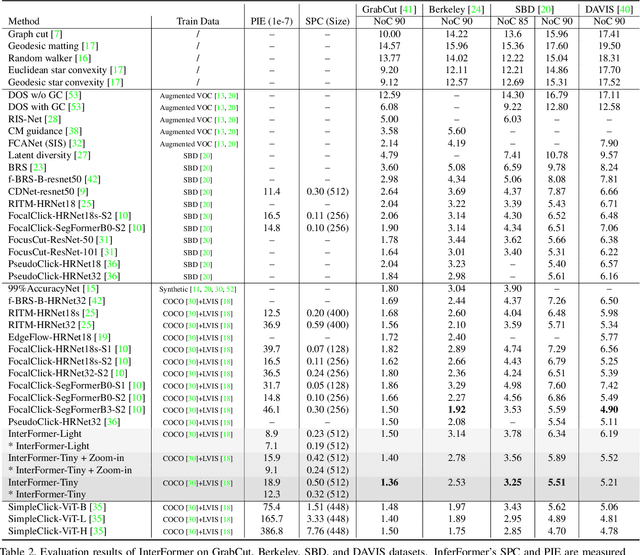
Interactive image segmentation enables annotators to efficiently perform pixel-level annotation for segmentation tasks. However, the existing interactive segmentation pipeline suffers from inefficient computations of interactive models because of the following two issues. First, annotators' later click is based on models' feedback of annotators' former click. This serial interaction is unable to utilize model's parallelism capabilities. Second, the model has to repeatedly process the image, the annotator's current click, and the model's feedback of the annotator's former clicks at each step of interaction, resulting in redundant computations. For efficient computation, we propose a method named InterFormer that follows a new pipeline to address these issues. InterFormer extracts and preprocesses the computationally time-consuming part i.e. image processing from the existing process. Specifically, InterFormer employs a large vision transformer (ViT) on high-performance devices to preprocess images in parallel, and then uses a lightweight module called interactive multi-head self attention (I-MSA) for interactive segmentation. Furthermore, the I-MSA module's deployment on low-power devices extends the practical application of interactive segmentation. The I-MSA module utilizes the preprocessed features to efficiently response to the annotator inputs in real-time. The experiments on several datasets demonstrate the effectiveness of InterFormer, which outperforms previous interactive segmentation models in terms of computational efficiency and segmentation quality, achieve real-time high-quality interactive segmentation on CPU-only devices.
HUTFormer: Hierarchical U-Net Transformer for Long-Term Traffic Forecasting
Jul 27, 2023Traffic forecasting, which aims to predict traffic conditions based on historical observations, has been an enduring research topic and is widely recognized as an essential component of intelligent transportation. Recent proposals on Spatial-Temporal Graph Neural Networks (STGNNs) have made significant progress by combining sequential models with graph convolution networks. However, due to high complexity issues, STGNNs only focus on short-term traffic forecasting, e.g., 1-hour forecasting, while ignoring more practical long-term forecasting. In this paper, we make the first attempt to explore long-term traffic forecasting, e.g., 1-day forecasting. To this end, we first reveal its unique challenges in exploiting multi-scale representations. Then, we propose a novel Hierarchical U-net TransFormer (HUTFormer) to address the issues of long-term traffic forecasting. HUTFormer consists of a hierarchical encoder and decoder to jointly generate and utilize multi-scale representations of traffic data. Specifically, for the encoder, we propose window self-attention and segment merging to extract multi-scale representations from long-term traffic data. For the decoder, we design a cross-scale attention mechanism to effectively incorporate multi-scale representations. In addition, HUTFormer employs an efficient input embedding strategy to address the complexity issues. Extensive experiments on four traffic datasets show that the proposed HUTFormer significantly outperforms state-of-the-art traffic forecasting and long time series forecasting baselines.
Self-Supervised Learning for Improved Synthetic Aperture Sonar Target Recognition
Jul 27, 2023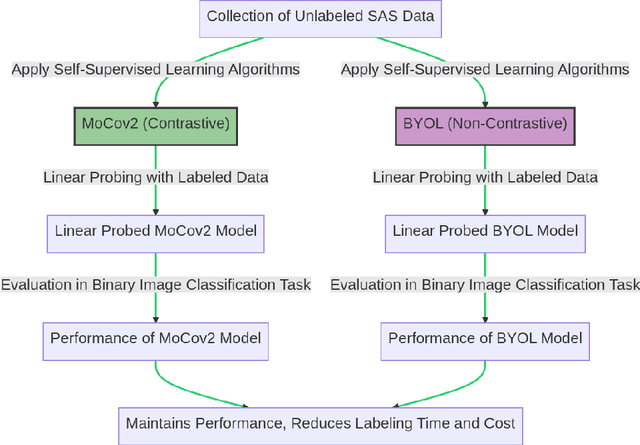
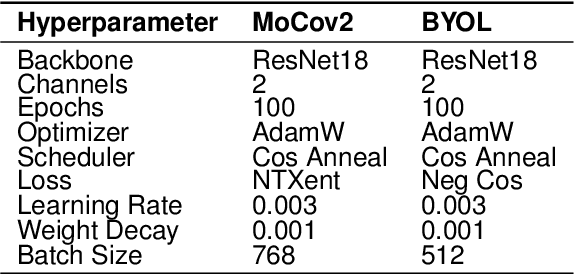

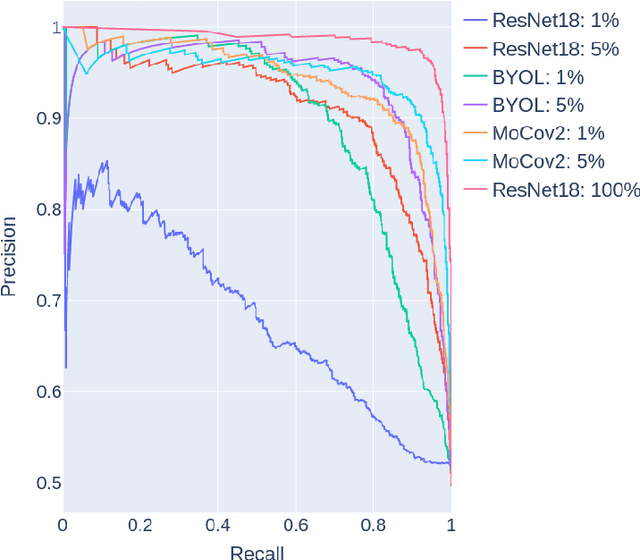
This study explores the application of self-supervised learning (SSL) for improved target recognition in synthetic aperture sonar (SAS) imagery. The unique challenges of underwater environments make traditional computer vision techniques, which rely heavily on optical camera imagery, less effective. SAS, with its ability to generate high-resolution imagery, emerges as a preferred choice for underwater imaging. However, the voluminous high-resolution SAS data presents a significant challenge for labeling; a crucial step for training deep neural networks (DNNs). SSL, which enables models to learn features in data without the need for labels, is proposed as a potential solution to the data labeling challenge in SAS. The study evaluates the performance of two prominent SSL algorithms, MoCov2 and BYOL, against the well-regarded supervised learning model, ResNet18, for binary image classification tasks. The findings suggest that while both SSL models can outperform a fully supervised model with access to a small number of labels in a few-shot scenario, they do not exceed it when all the labels are used. The results underscore the potential of SSL as a viable alternative to traditional supervised learning, capable of maintaining task performance while reducing the time and costs associated with data labeling. The study also contributes to the growing body of evidence supporting the use of SSL in remote sensing and could stimulate further research in this area.
A Novel Explainable Artificial Intelligence Model in Image Classification problem
Jul 09, 2023
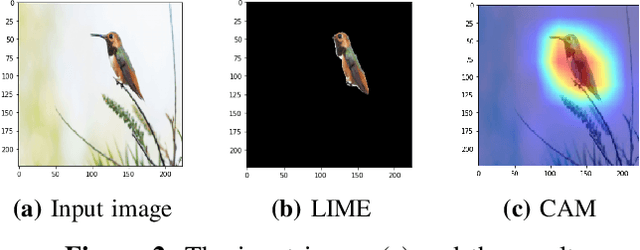
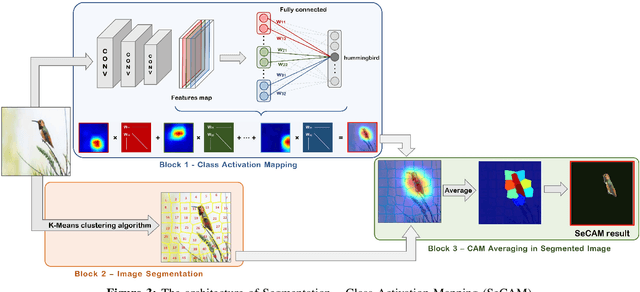
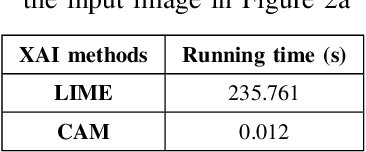
In recent years, artificial intelligence is increasingly being applied widely in many different fields and has a profound and direct impact on human life. Following this is the need to understand the principles of the model making predictions. Since most of the current high-precision models are black boxes, neither the AI scientist nor the end-user deeply understands what's going on inside these models. Therefore, many algorithms are studied for the purpose of explaining AI models, especially those in the problem of image classification in the field of computer vision such as LIME, CAM, GradCAM. However, these algorithms still have limitations such as LIME's long execution time and CAM's confusing interpretation of concreteness and clarity. Therefore, in this paper, we propose a new method called Segmentation - Class Activation Mapping (SeCAM) that combines the advantages of these algorithms above, while at the same time overcoming their disadvantages. We tested this algorithm with various models, including ResNet50, Inception-v3, VGG16 from ImageNet Large Scale Visual Recognition Challenge (ILSVRC) data set. Outstanding results when the algorithm has met all the requirements for a specific explanation in a remarkably concise time.
Fuzzy clustering of ordinal time series based on two novel distances with economic applications
Apr 24, 2023
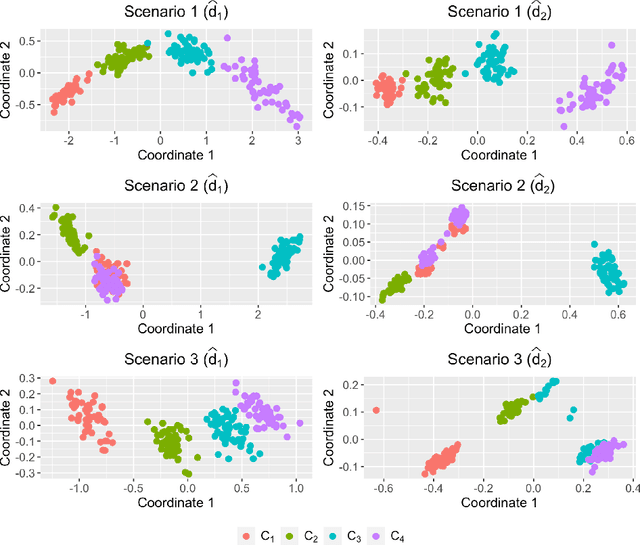
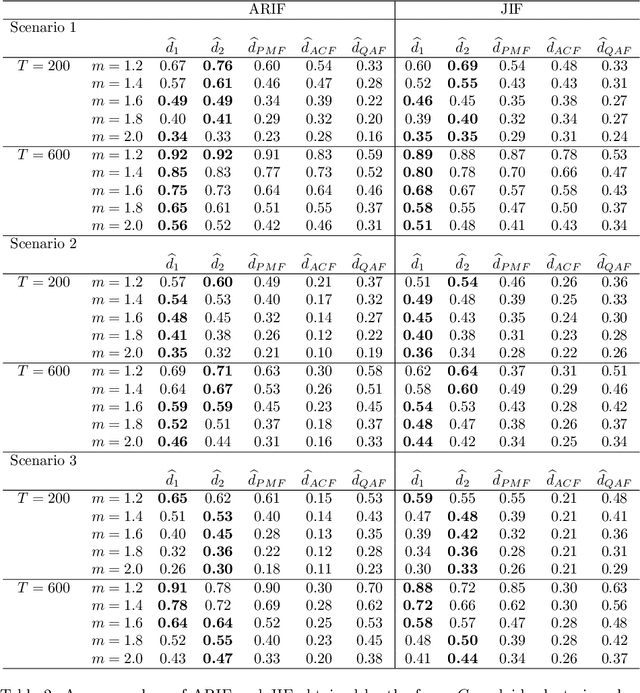
Time series clustering is a central machine learning task with applications in many fields. While the majority of the methods focus on real-valued time series, very few works consider series with discrete response. In this paper, the problem of clustering ordinal time series is addressed. To this aim, two novel distances between ordinal time series are introduced and used to construct fuzzy clustering procedures. Both metrics are functions of the estimated cumulative probabilities, thus automatically taking advantage of the ordering inherent to the series' range. The resulting clustering algorithms are computationally efficient and able to group series generated from similar stochastic processes, reaching accurate results even though the series come from a wide variety of models. Since the dynamic of the series may vary over the time, we adopt a fuzzy approach, thus enabling the procedures to locate each series into several clusters with different membership degrees. An extensive simulation study shows that the proposed methods outperform several alternative procedures. Weighted versions of the clustering algorithms are also presented and their advantages with respect to the original methods are discussed. Two specific applications involving economic time series illustrate the usefulness of the proposed approaches.
FinGPT: Democratizing Internet-scale Data for Financial Large Language Models
Jul 19, 2023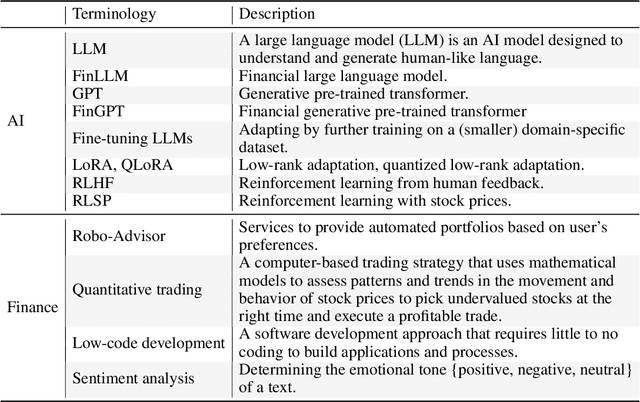
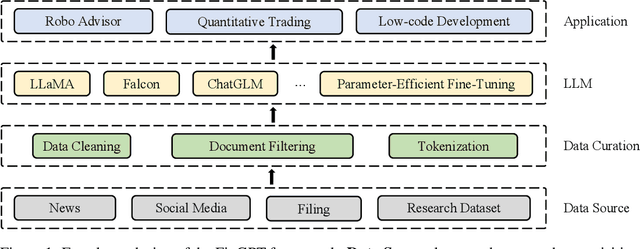
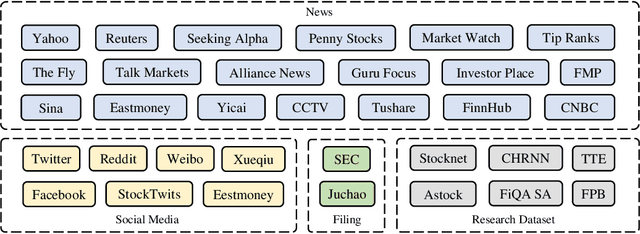
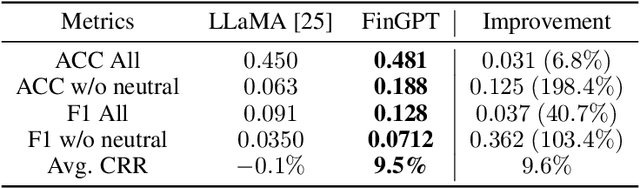
Large language models (LLMs) have demonstrated remarkable proficiency in understanding and generating human-like texts, which may potentially revolutionize the finance industry. However, existing LLMs often fall short in the financial field, which is mainly attributed to the disparities between general text data and financial text data. Unfortunately, there is only a limited number of financial text datasets available (quite small size), and BloombergGPT, the first financial LLM (FinLLM), is close-sourced (only the training logs were released). In light of this, we aim to democratize Internet-scale financial data for LLMs, which is an open challenge due to diverse data sources, low signal-to-noise ratio, and high time-validity. To address the challenges, we introduce an open-sourced and data-centric framework, \textit{Financial Generative Pre-trained Transformer (FinGPT)}, that automates the collection and curation of real-time financial data from >34 diverse sources on the Internet, providing researchers and practitioners with accessible and transparent resources to develop their FinLLMs. Additionally, we propose a simple yet effective strategy for fine-tuning FinLLM using the inherent feedback from the market, dubbed Reinforcement Learning with Stock Prices (RLSP). We also adopt the Low-rank Adaptation (LoRA, QLoRA) method that enables users to customize their own FinLLMs from open-source general-purpose LLMs at a low cost. Finally, we showcase several FinGPT applications, including robo-advisor, sentiment analysis for algorithmic trading, and low-code development. FinGPT aims to democratize FinLLMs, stimulate innovation, and unlock new opportunities in open finance. The codes are available at https://github.com/AI4Finance-Foundation/FinGPT and https://github.com/AI4Finance-Foundation/FinNLP
Financial Time Series Forecasting using CNN and Transformer
Apr 11, 2023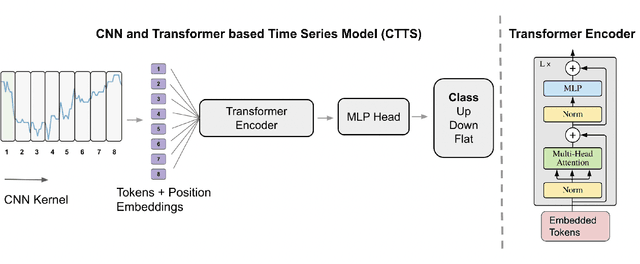
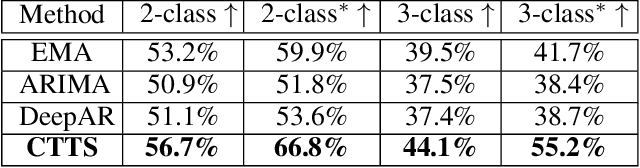
Time series forecasting is important across various domains for decision-making. In particular, financial time series such as stock prices can be hard to predict as it is difficult to model short-term and long-term temporal dependencies between data points. Convolutional Neural Networks (CNN) are good at capturing local patterns for modeling short-term dependencies. However, CNNs cannot learn long-term dependencies due to the limited receptive field. Transformers on the other hand are capable of learning global context and long-term dependencies. In this paper, we propose to harness the power of CNNs and Transformers to model both short-term and long-term dependencies within a time series, and forecast if the price would go up, down or remain the same (flat) in the future. In our experiments, we demonstrated the success of the proposed method in comparison to commonly adopted statistical and deep learning methods on forecasting intraday stock price change of S&P 500 constituents.
Tensor Decompositions Meet Control Theory: Learning General Mixtures of Linear Dynamical Systems
Jul 23, 2023Recently Chen and Poor initiated the study of learning mixtures of linear dynamical systems. While linear dynamical systems already have wide-ranging applications in modeling time-series data, using mixture models can lead to a better fit or even a richer understanding of underlying subpopulations represented in the data. In this work we give a new approach to learning mixtures of linear dynamical systems that is based on tensor decompositions. As a result, our algorithm succeeds without strong separation conditions on the components, and can be used to compete with the Bayes optimal clustering of the trajectories. Moreover our algorithm works in the challenging partially-observed setting. Our starting point is the simple but powerful observation that the classic Ho-Kalman algorithm is a close relative of modern tensor decomposition methods for learning latent variable models. This gives us a playbook for how to extend it to work with more complicated generative models.