 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Empirical Study on Fairness Improvement with Multiple Protected Attributes
Jul 25, 2023

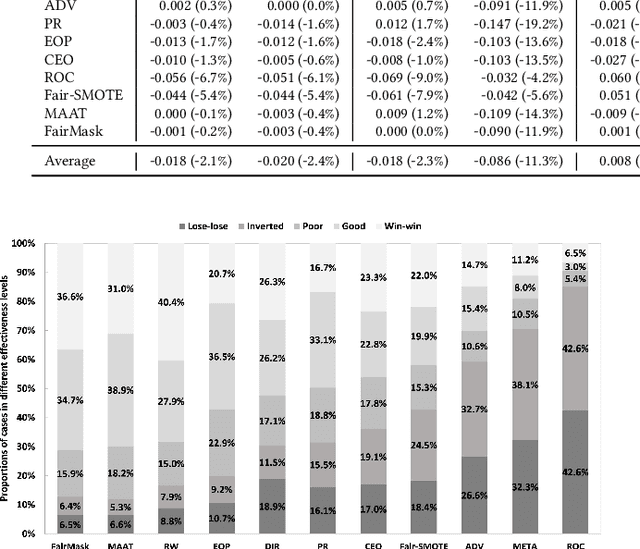

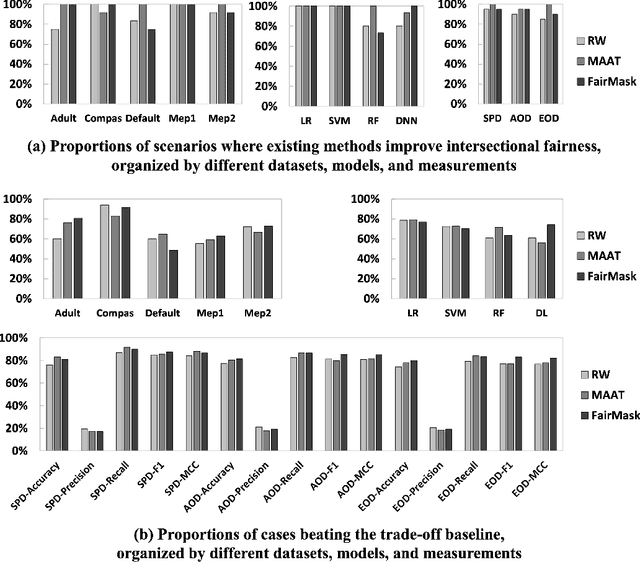
Existing research mostly improves the fairness of Machine Learning (ML) software regarding a single protected attribute at a time, but this is unrealistic given that many users have multiple protected attributes. This paper conducts an extensive study of fairness improvement regarding multiple protected attributes, covering 11 state-of-the-art fairness improvement methods. We analyze the effectiveness of these methods with different datasets, metrics, and ML models when considering multiple protected attributes. The results reveal that improving fairness for a single protected attribute can largely decrease fairness regarding unconsidered protected attributes. This decrease is observed in up to 88.3% of scenarios (57.5% on average). More surprisingly, we find little difference in accuracy loss when considering single and multiple protected attributes, indicating that accuracy can be maintained in the multiple-attribute paradigm. However, the effect on precision and recall when handling multiple protected attributes is about 5 times and 8 times that of a single attribute. This has important implications for future fairness research: reporting only accuracy as the ML performance metric, which is currently common in the literature, is inadequate.
A Vision for Cleaner Rivers: Harnessing Snapshot Hyperspectral Imaging to Detect Macro-Plastic Litter
Jul 22, 2023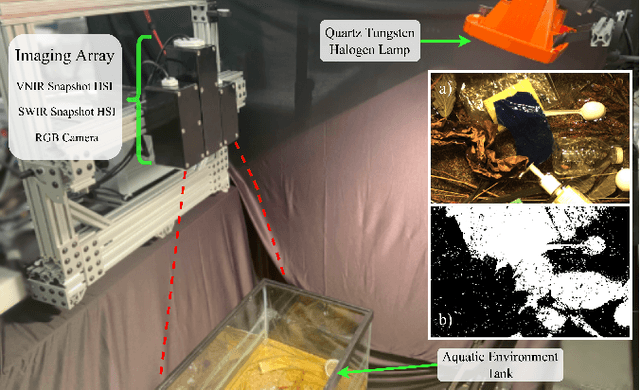

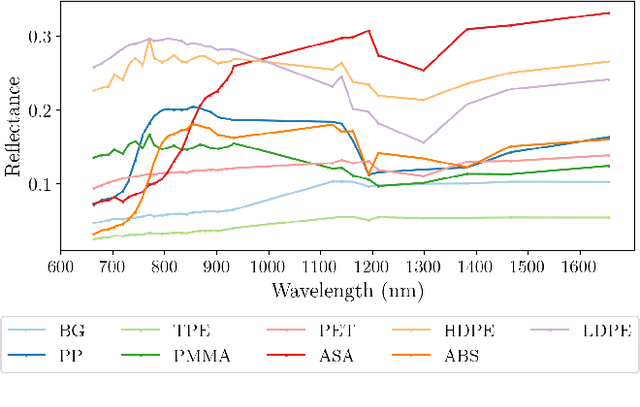
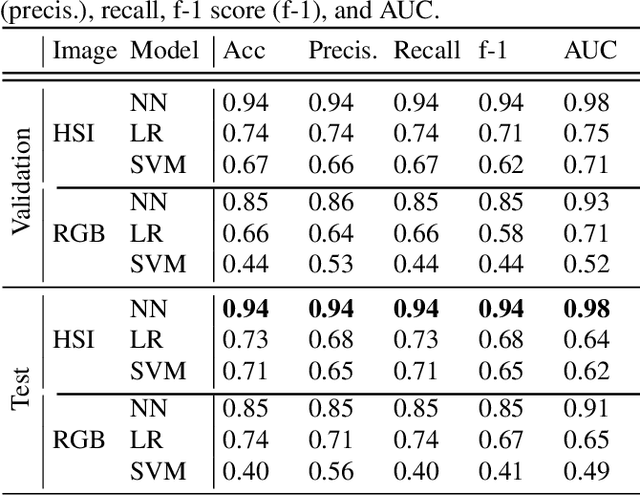
Plastic waste entering the riverine harms local ecosystems leading to negative ecological and economic impacts. Large parcels of plastic waste are transported from inland to oceans leading to a global scale problem of floating debris fields. In this context, efficient and automatized monitoring of mismanaged plastic waste is paramount. To address this problem, we analyze the feasibility of macro-plastic litter detection using computational imaging approaches in river-like scenarios. We enable near-real-time tracking of partially submerged plastics by using snapshot Visible-Shortwave Infrared hyperspectral imaging. Our experiments indicate that imaging strategies associated with machine learning classification approaches can lead to high detection accuracy even in challenging scenarios, especially when leveraging hyperspectral data and nonlinear classifiers. All code, data, and models are available online: https://github.com/RIVeR-Lab/hyperspectral_macro_plastic_detection.
OxfordVGG Submission to the EGO4D AV Transcription Challenge
Jul 18, 2023

This report presents the technical details of our submission on the EGO4D Audio-Visual (AV) Automatic Speech Recognition Challenge 2023 from the OxfordVGG team. We present WhisperX, a system for efficient speech transcription of long-form audio with word-level time alignment, along with two text normalisers which are publicly available. Our final submission obtained 56.0% of the Word Error Rate (WER) on the challenge test set, ranked 1st on the leaderboard. All baseline codes and models are available on https://github.com/m-bain/whisperX.
Towards Codable Text Watermarking for Large Language Models
Jul 29, 2023
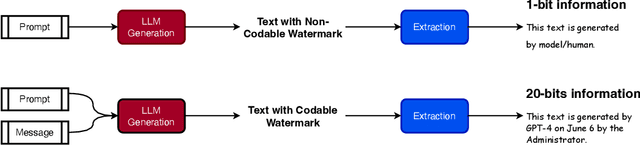
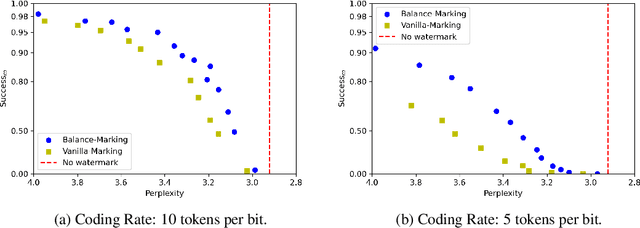

As large language models (LLMs) generate texts with increasing fluency and realism, there is a growing need to identify the source of texts to prevent the abuse of LLMs. Text watermarking techniques have proven reliable in distinguishing whether a text is generated by LLMs by injecting hidden patterns into the generated texts. However, we argue that existing watermarking methods for LLMs are encoding-inefficient (only contain one bit of information - whether it is generated from an LLM or not) and cannot flexibly meet the diverse information encoding needs (such as encoding model version, generation time, user id, etc.) in different LLMs application scenarios. In this work, we conduct the first systematic study on the topic of Codable Text Watermarking for LLMs (CTWL) that allows text watermarks to carry more customizable information. First of all, we study the taxonomy of LLM watermarking technology and give a mathematical formulation for CTWL. Additionally, we provide a comprehensive evaluation system for CTWL: (1) watermarking success rate, (2) robustness against various corruptions, (3) coding rate of payload information, (4) encoding and decoding efficiency, (5) impacts on the quality of the generated text. To meet the requirements of these non-Pareto-improving metrics, we devise a CTWL method named Balance-Marking, based on the motivation of ensuring that available and unavailable vocabularies for encoding information have approximately equivalent probabilities. Compared to the random vocabulary partitioning extended from the existing work, a probability-balanced vocabulary partition can significantly improve the quality of the generated text. Extensive experimental results have shown that our method outperforms a direct baseline under comprehensive evaluation.
Comparing Apples to Apples: Generating Aspect-Aware Comparative Sentences from User Reviews
Jul 23, 2023It is time-consuming to find the best product among many similar alternatives. Comparative sentences can help to contrast one item from others in a way that highlights important features of an item that stand out. Given reviews of one or multiple items and relevant item features, we generate comparative review sentences to aid users to find the best fit. Specifically, our model consists of three successive components in a transformer: (i) an item encoding module to encode an item for comparison, (ii) a comparison generation module that generates comparative sentences in an autoregressive manner, (iii) a novel decoding method for user personalization. We show that our pipeline generates fluent and diverse comparative sentences. We run experiments on the relevance and fidelity of our generated sentences in a human evaluation study and find that our algorithm creates comparative review sentences that are relevant and truthful.
Mental Workload Estimation with Electroencephalogram Signals by Combining Multi-Space Deep Models
Jul 23, 2023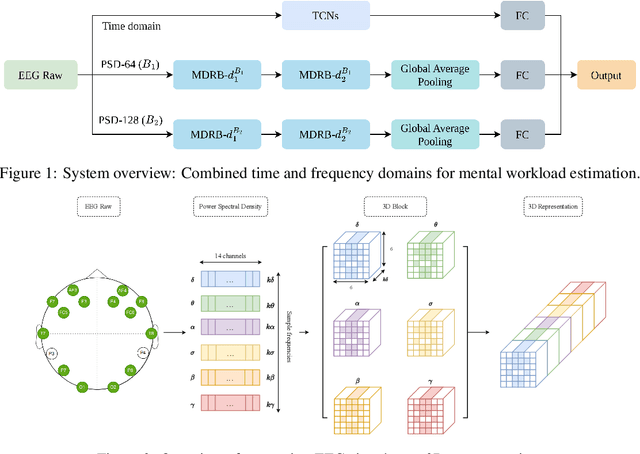
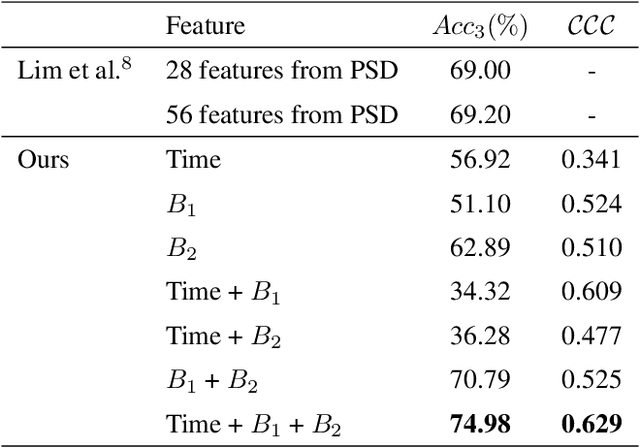
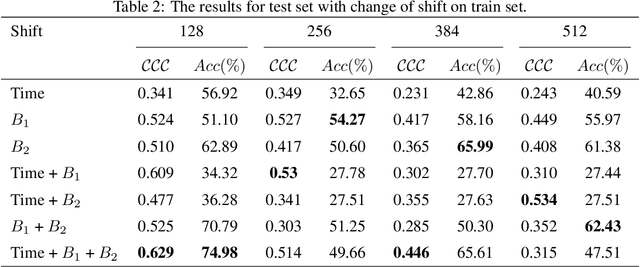
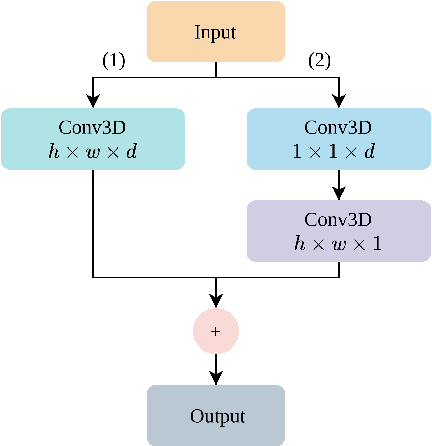
The human brain is in a continuous state of activity during both work and rest. Mental activity is a daily process, and when the brain is overworked, it can have negative effects on human health. In recent years, great attention has been paid to early detection of mental health problems because it can help prevent serious health problems and improve quality of life. Several signals are used to assess mental state, but the electroencephalogram (EEG) is widely used by researchers because of the large amount of information it provides about the brain. This paper aims to classify mental workload into three states and estimate continuum levels. Our method combines multiple dimensions of space to achieve the best results for mental estimation. In the time domain approach, we use Temporal Convolutional Networks, and in the frequency domain, we propose a new architecture called the Multi-Dimensional Residual Block, which combines residual blocks.
Combining HoloLens with Instant-NeRFs: Advanced Real-Time 3D Mobile Mapping
May 03, 2023
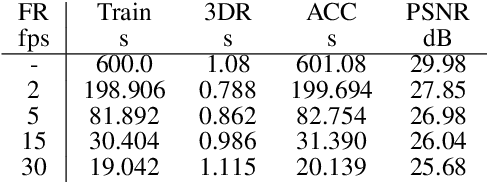

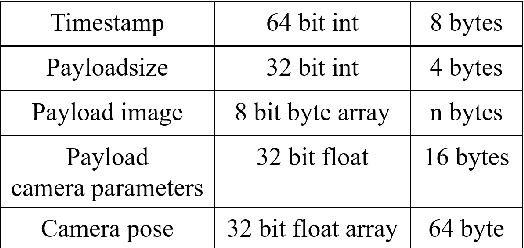
This work represents a large step into modern ways of fast 3D reconstruction based on RGB camera images. Utilizing a Microsoft HoloLens 2 as a multisensor platform that includes an RGB camera and an inertial measurement unit for SLAM-based camera-pose determination, we train a Neural Radiance Field (NeRF) as a neural scene representation in real-time with the acquired data from the HoloLens. The HoloLens is connected via Wifi to a high-performance PC that is responsible for the training and 3D reconstruction. After the data stream ends, the training is stopped and the 3D reconstruction is initiated, which extracts a point cloud of the scene. With our specialized inference algorithm, five million scene points can be extracted within 1 second. In addition, the point cloud also includes radiometry per point. Our method of 3D reconstruction outperforms grid point sampling with NeRFs by multiple orders of magnitude and can be regarded as a complete real-time 3D reconstruction method in a mobile mapping setup.
Detection of Adversarial Physical Attacks in Time-Series Image Data
Apr 27, 2023

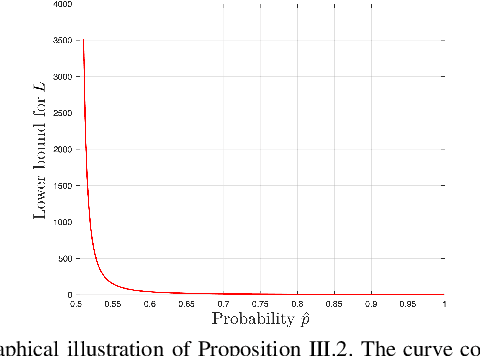
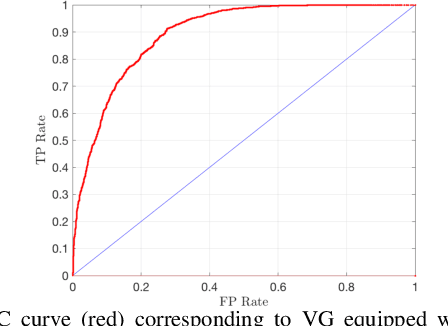
Deep neural networks (DNN) have become a common sensing modality in autonomous systems as they allow for semantically perceiving the ambient environment given input images. Nevertheless, DNN models have proven to be vulnerable to adversarial digital and physical attacks. To mitigate this issue, several detection frameworks have been proposed to detect whether a single input image has been manipulated by adversarial digital noise or not. In our prior work, we proposed a real-time detector, called VisionGuard (VG), for adversarial physical attacks against single input images to DNN models. Building upon that work, we propose VisionGuard* (VG), which couples VG with majority-vote methods, to detect adversarial physical attacks in time-series image data, e.g., videos. This is motivated by autonomous systems applications where images are collected over time using onboard sensors for decision-making purposes. We emphasize that majority-vote mechanisms are quite common in autonomous system applications (among many other applications), as e.g., in autonomous driving stacks for object detection. In this paper, we investigate, both theoretically and experimentally, how this widely used mechanism can be leveraged to enhance the performance of adversarial detectors. We have evaluated VG* on videos of both clean and physically attacked traffic signs generated by a state-of-the-art robust physical attack. We provide extensive comparative experiments against detectors that have been designed originally for out-of-distribution data and digitally attacked images.
Risk-Averse Trajectory Optimization via Sample Average Approximation
Jul 06, 2023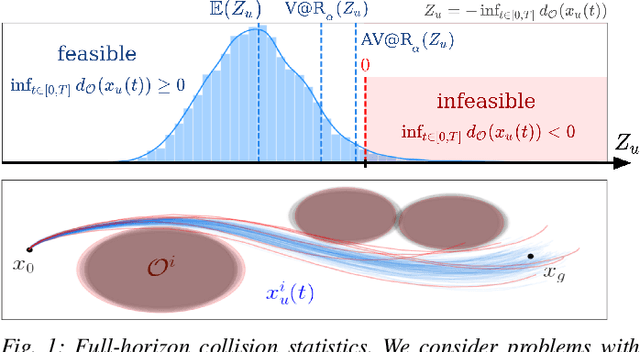
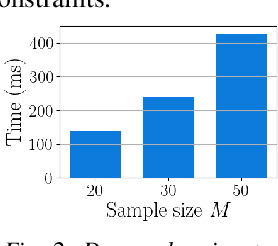
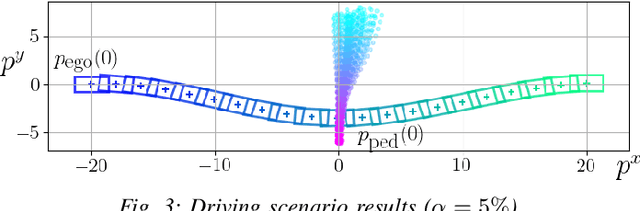
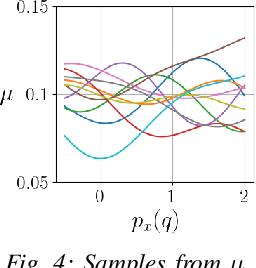
Trajectory optimization under uncertainty underpins a wide range of applications in robotics. However, existing methods are limited in terms of reasoning about sources of epistemic and aleatoric uncertainty, space and time correlations, nonlinear dynamics, and non-convex constraints. In this work, we first introduce a continuous-time planning formulation with an average-value-at-risk constraint over the entire planning horizon. Then, we propose a sample-based approximation that unlocks an efficient, general-purpose, and time-consistent algorithm for risk-averse trajectory optimization. We prove that the method is asymptotically optimal and derive finite-sample error bounds. Simulations demonstrate the high speed and reliability of the approach on problems with stochasticity in nonlinear dynamics, obstacle fields, interactions, and terrain parameters.
PUF Probe: A PUF-based Hardware Authentication Equipment for IEDs
Jul 28, 2023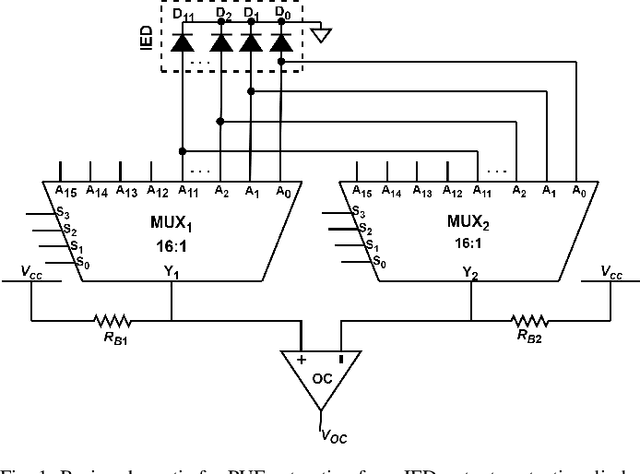
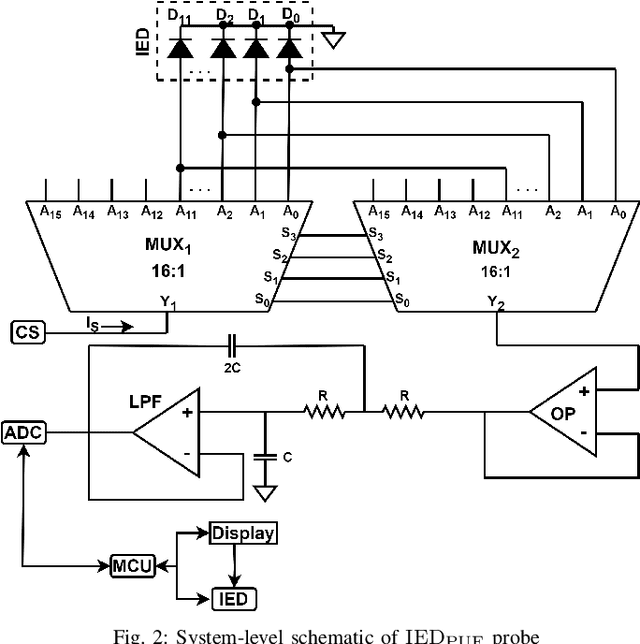
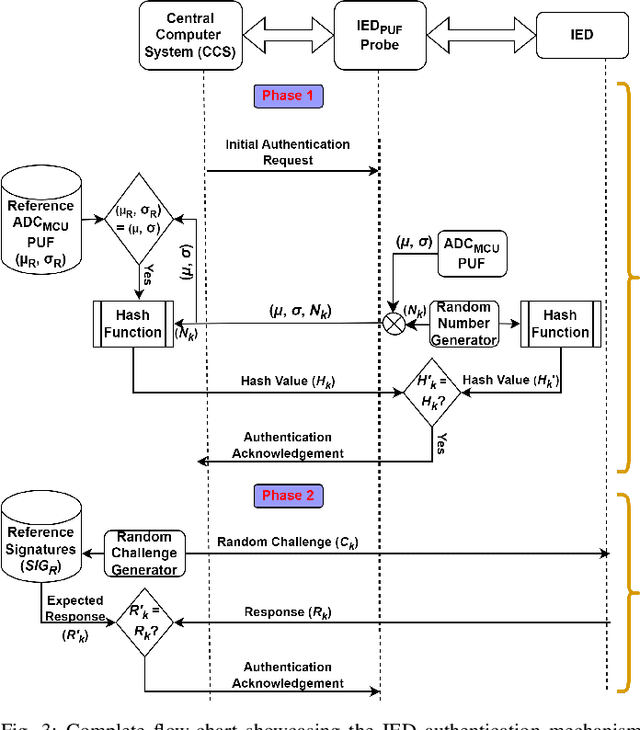
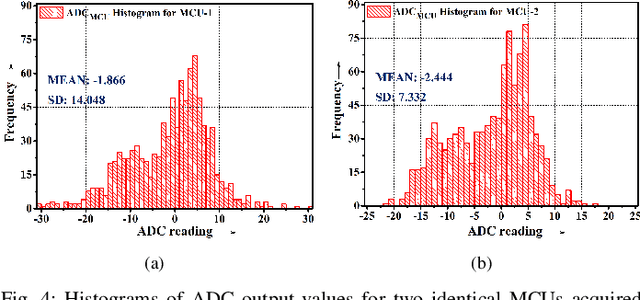
Intelligent Electronic Devices (IEDs) are vital components in modern electrical substations, collectively responsible for monitoring electrical parameters and performing protective functions. As a result, ensuring the integrity of IEDs is an essential criteria. While standards like IEC 61850 and IEC 60870-5-104 establish cyber-security protocols for secure information exchange in IED-based power systems, the physical integrity of IEDs is often overlooked, leading to a rise in counterfeit and tainted electronic products. This paper proposes a physical unclonable function (PUF)-based device (IEDPUF probe) capable of extracting unique hardware signatures from commercial IEDs. These signatures can serve as identifiers, facilitating the authentication and protection of IEDs against counterfeiting. The paper presents the complete hardware architecture of the IEDPUF probe, along with algorithms for signature extraction and authentication. The process involves the central computer system (CCS) initiating IED authentication requests by sending random challenges to the IEDPUF probe. Based on the challenges, the IEDPUF probe generates responses, which are then verified by the CCS to authenticate the IED. Additionally, a two-way authentication technique is employed to ensure that only verified requests are granted access for signature extraction. Experimental results confirm the efficacy of the proposed IEDPUF probe. The results demonstrate its ability to provide real-time responses possessing randomness while uniquely identifying the IED under investigation. The proposed IEDPUF probe offers a simple, cost-effective, accurate solution with minimal storage requirements, enhancing the authenticity and integrity of IEDs within electrical substations