 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Implementation and Evaluation of Networked Model Predictive Control System on Universal Robot
Jul 18, 2023
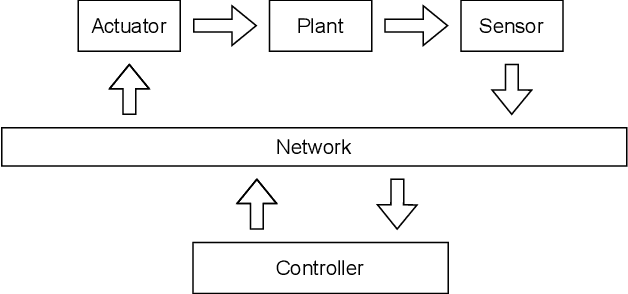
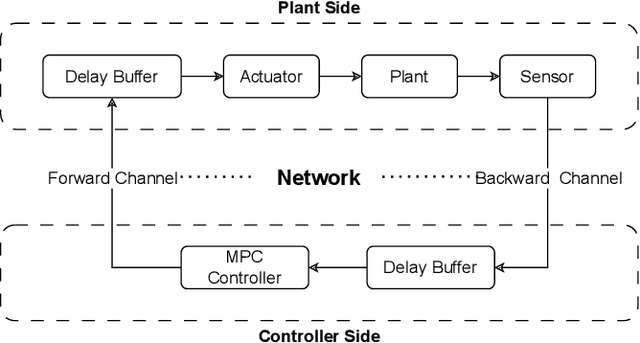
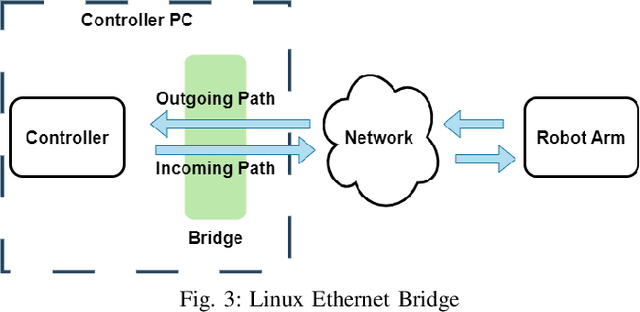
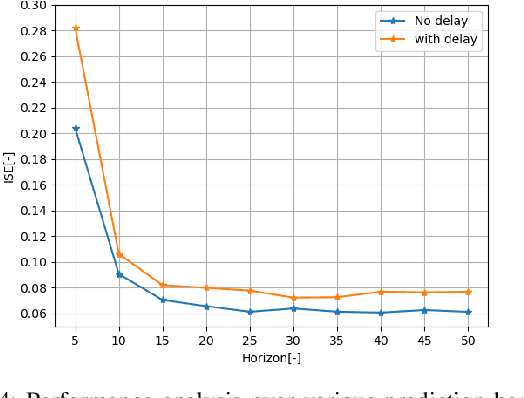
Networked control systems are closed-loop feedback control systems containing system components that may be distributed geographically in different locations and interconnected via a communication network such as the Internet. The quality of network communication is a crucial factor that significantly affects the performance of remote control. This is due to the fact that network uncertainties can occur in the transmission of packets in the forward and backward channels of the system. The two most significant among these uncertainties are network time delay and packet loss. To overcome these challenges, the networked predictive control system has been proposed to provide improved performance and robustness using predictive controllers and compensation strategies. In particular, the model predictive control method is well-suited as an advanced approach compared to conventional methods. In this paper, a networked model predictive control system consisting of a model predictive control method and compensation strategies is implemented to control and stabilize a robot arm as a physical system. In particular, this work aims to analyze the performance of the system under the influence of network time delay and packet loss. Using appropriate performance and robustness metrics, an in-depth investigation of the impacts of these network uncertainties is performed. Furthermore, the forward and backward channels of the network are examined in detail in this study.
Panel Data Nowcasting: The Case of Price-Earnings Ratios
Jul 05, 2023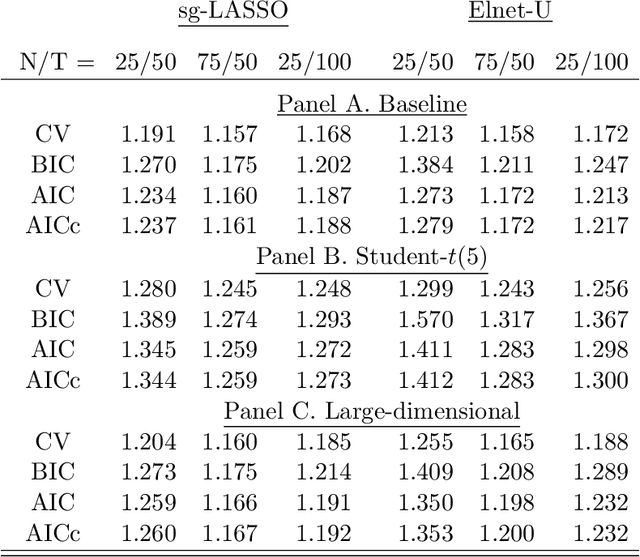

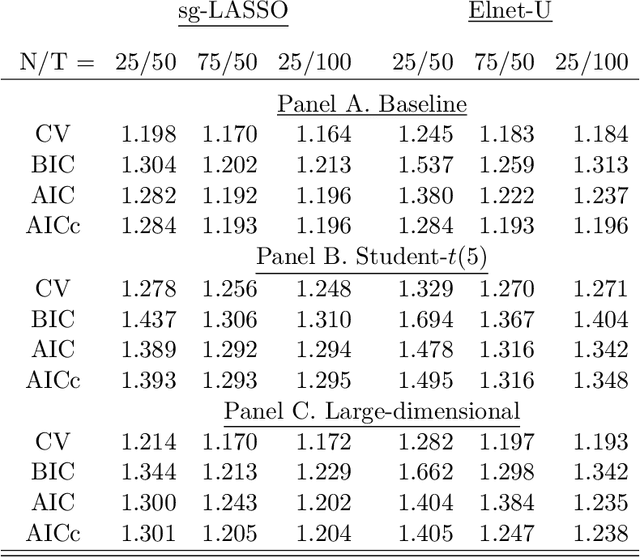
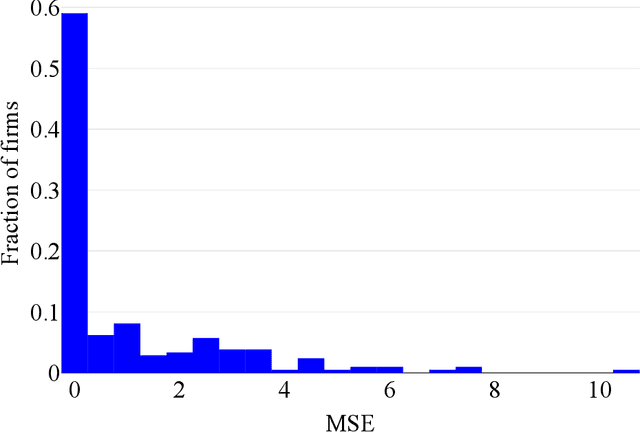
The paper uses structured machine learning regressions for nowcasting with panel data consisting of series sampled at different frequencies. Motivated by the problem of predicting corporate earnings for a large cross-section of firms with macroeconomic, financial, and news time series sampled at different frequencies, we focus on the sparse-group LASSO regularization which can take advantage of the mixed frequency time series panel data structures. Our empirical results show the superior performance of our machine learning panel data regression models over analysts' predictions, forecast combinations, firm-specific time series regression models, and standard machine learning methods.
AudioInceptionNeXt: TCL AI LAB Submission to EPIC-SOUND Audio-Based-Interaction-Recognition Challenge 2023
Jul 14, 2023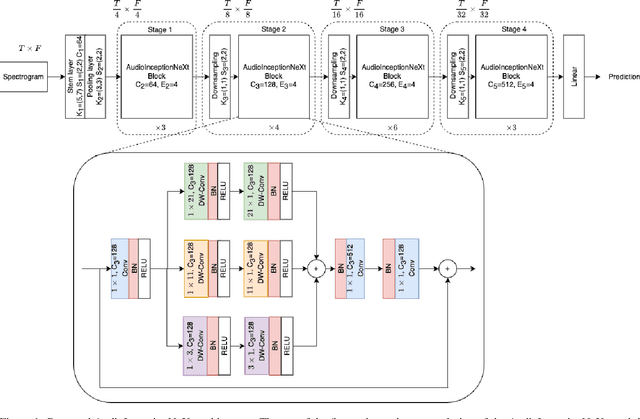
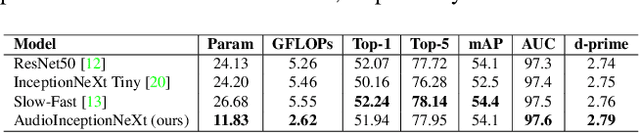

This report presents the technical details of our submission to the 2023 Epic-Kitchen EPIC-SOUNDS Audio-Based Interaction Recognition Challenge. The task is to learn the mapping from audio samples to their corresponding action labels. To achieve this goal, we propose a simple yet effective single-stream CNN-based architecture called AudioInceptionNeXt that operates on the time-frequency log-mel-spectrogram of the audio samples. Motivated by the design of the InceptionNeXt, we propose parallel multi-scale depthwise separable convolutional kernels in the AudioInceptionNeXt block, which enable the model to learn the time and frequency information more effectively. The large-scale separable kernels capture the long duration of activities and the global frequency semantic information, while the small-scale separable kernels capture the short duration of activities and local details of frequency information. Our approach achieved 55.43% of top-1 accuracy on the challenge test set, ranked as 1st on the public leaderboard. Codes are available anonymously at https://github.com/StevenLauHKHK/AudioInceptionNeXt.git.
PID-Inspired Inductive Biases for Deep Reinforcement Learning in Partially Observable Control Tasks
Jul 12, 2023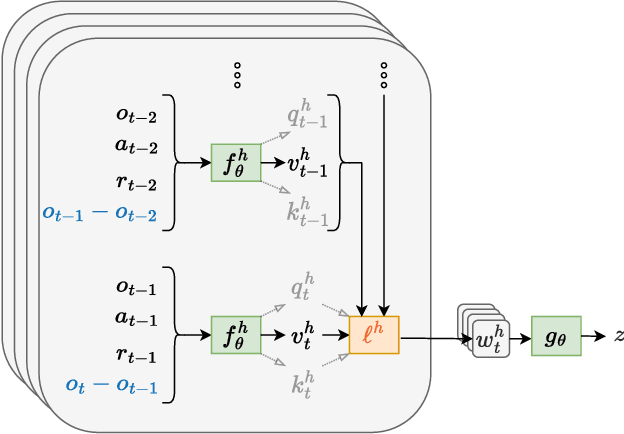
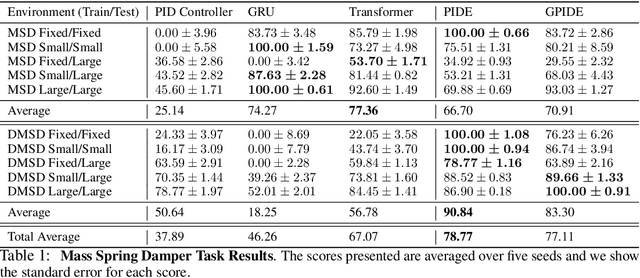
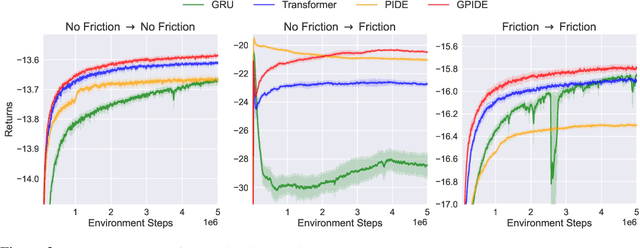
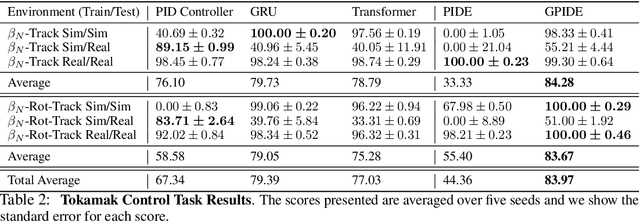
Deep reinforcement learning (RL) has shown immense potential for learning to control systems through data alone. However, one challenge deep RL faces is that the full state of the system is often not observable. When this is the case, the policy needs to leverage the history of observations to infer the current state. At the same time, differences between the training and testing environments makes it critical for the policy not to overfit to the sequence of observations it sees at training time. As such, there is an important balancing act between having the history encoder be flexible enough to extract relevant information, yet be robust to changes in the environment. To strike this balance, we look to the PID controller for inspiration. We assert the PID controller's success shows that only summing and differencing are needed to accumulate information over time for many control tasks. Following this principle, we propose two architectures for encoding history: one that directly uses PID features and another that extends these core ideas and can be used in arbitrary control tasks. When compared with prior approaches, our encoders produce policies that are often more robust and achieve better performance on a variety of tracking tasks. Going beyond tracking tasks, our policies achieve 1.7x better performance on average over previous state-of-the-art methods on a suite of high dimensional control tasks.
Neural Free-Viewpoint Relighting for Glossy Indirect Illumination
Jul 12, 2023
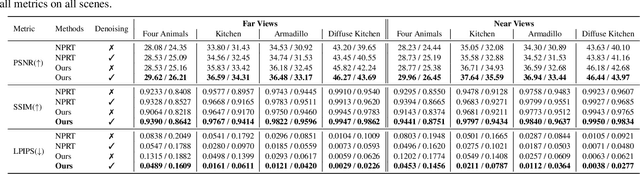

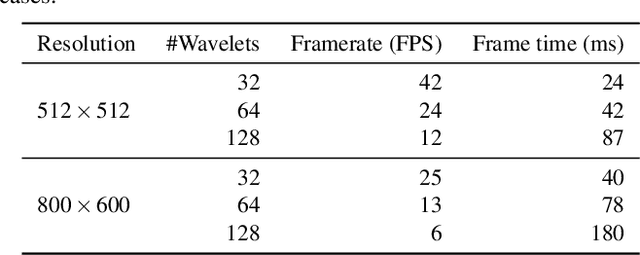
Precomputed Radiance Transfer (PRT) remains an attractive solution for real-time rendering of complex light transport effects such as glossy global illumination. After precomputation, we can relight the scene with new environment maps while changing viewpoint in real-time. However, practical PRT methods are usually limited to low-frequency spherical harmonic lighting. All-frequency techniques using wavelets are promising but have so far had little practical impact. The curse of dimensionality and much higher data requirements have typically limited them to relighting with fixed view or only direct lighting with triple product integrals. In this paper, we demonstrate a hybrid neural-wavelet PRT solution to high-frequency indirect illumination, including glossy reflection, for relighting with changing view. Specifically, we seek to represent the light transport function in the Haar wavelet basis. For global illumination, we learn the wavelet transport using a small multi-layer perceptron (MLP) applied to a feature field as a function of spatial location and wavelet index, with reflected direction and material parameters being other MLP inputs. We optimize/learn the feature field (compactly represented by a tensor decomposition) and MLP parameters from multiple images of the scene under different lighting and viewing conditions. We demonstrate real-time (512 x 512 at 24 FPS, 800 x 600 at 13 FPS) precomputed rendering of challenging scenes involving view-dependent reflections and even caustics.
HandMIM: Pose-Aware Self-Supervised Learning for 3D Hand Mesh Estimation
Jul 29, 2023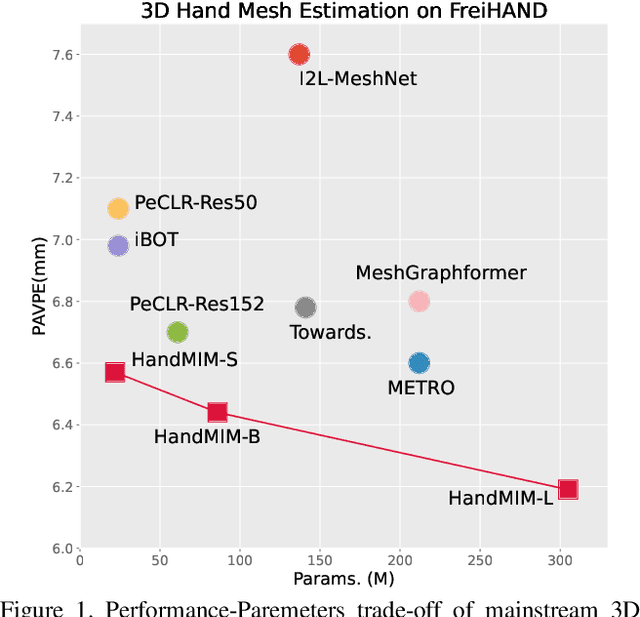
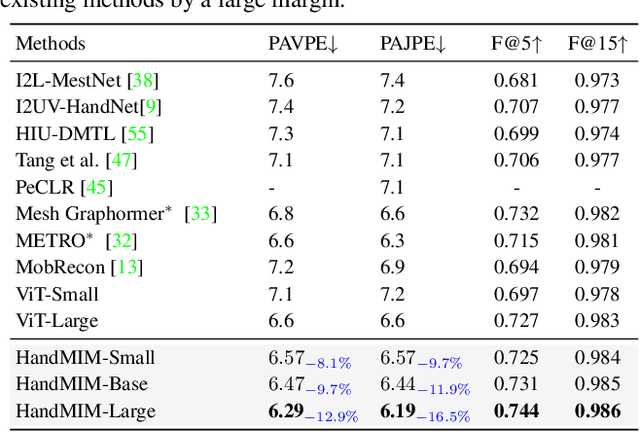
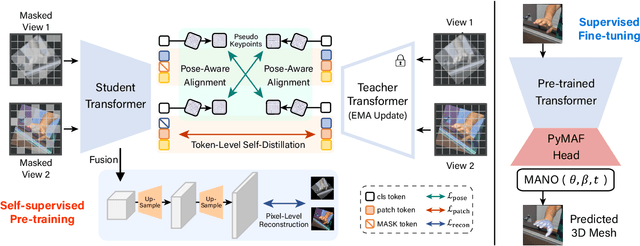
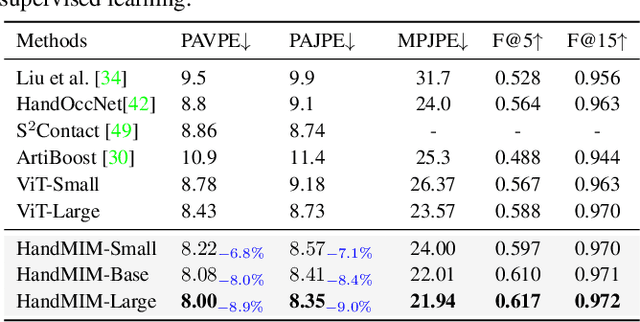
With an enormous number of hand images generated over time, unleashing pose knowledge from unlabeled images for supervised hand mesh estimation is an emerging yet challenging topic. To alleviate this issue, semi-supervised and self-supervised approaches have been proposed, but they are limited by the reliance on detection models or conventional ResNet backbones. In this paper, inspired by the rapid progress of Masked Image Modeling (MIM) in visual classification tasks, we propose a novel self-supervised pre-training strategy for regressing 3D hand mesh parameters. Our approach involves a unified and multi-granularity strategy that includes a pseudo keypoint alignment module in the teacher-student framework for learning pose-aware semantic class tokens. For patch tokens with detailed locality, we adopt a self-distillation manner between teacher and student network based on MIM pre-training. To better fit low-level regression tasks, we incorporate pixel reconstruction tasks for multi-level representation learning. Additionally, we design a strong pose estimation baseline using a simple vanilla vision Transformer (ViT) as the backbone and attach a PyMAF head after tokens for regression. Extensive experiments demonstrate that our proposed approach, named HandMIM, achieves strong performance on various hand mesh estimation tasks. Notably, HandMIM outperforms specially optimized architectures, achieving 6.29mm and 8.00mm PAVPE (Vertex-Point-Error) on challenging FreiHAND and HO3Dv2 test sets, respectively, establishing new state-of-the-art records on 3D hand mesh estimation.
Efficient Semi-Supervised Federated Learning for Heterogeneous Participants
Jul 29, 2023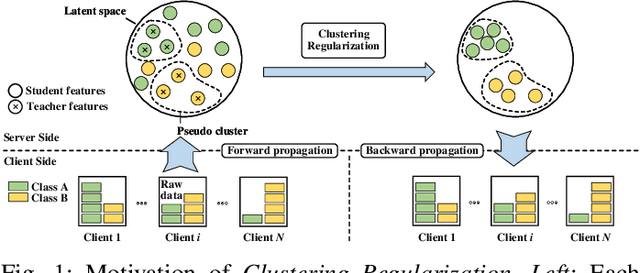
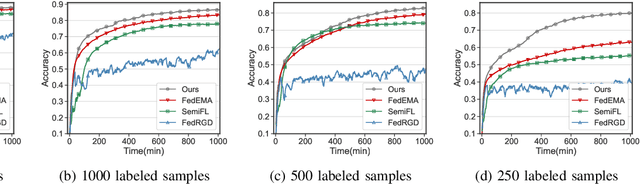

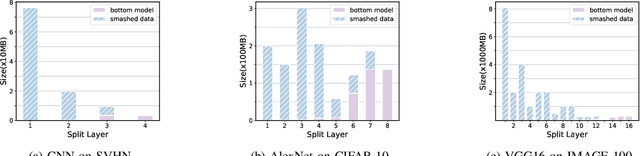
Federated Learning (FL) has emerged to allow multiple clients to collaboratively train machine learning models on their private data. However, training and deploying large models for broader applications is challenging in resource-constrained environments. Fortunately, Split Federated Learning (SFL) offers an excellent solution by alleviating the computation and communication burden on the clients SFL often assumes labeled data for local training on clients, however, it is not the case in practice.Prior works have adopted semi-supervised techniques for leveraging unlabeled data in FL, but data non-IIDness poses another challenge to ensure training efficiency. Herein, we propose Pseudo-Clustering Semi-SFL, a novel system for training models in scenarios where labeled data reside on the server. By introducing Clustering Regularization, model performance under data non-IIDness can be improved. Besides, our theoretical and experimental investigations into model convergence reveal that the inconsistent training processes on labeled and unlabeled data impact the effectiveness of clustering regularization. Upon this, we develop a control algorithm for global updating frequency adaptation, which dynamically adjusts the number of supervised training iterations to mitigate the training inconsistency. Extensive experiments on benchmark models and datasets show that our system provides a 3.3x speed-up in training time and reduces the communication cost by about 80.1% while reaching the target accuracy, and achieves up to 6.9% improvement in accuracy under non-IID scenarios compared to the state-of-the-art.
Effective Whole-body Pose Estimation with Two-stages Distillation
Jul 29, 2023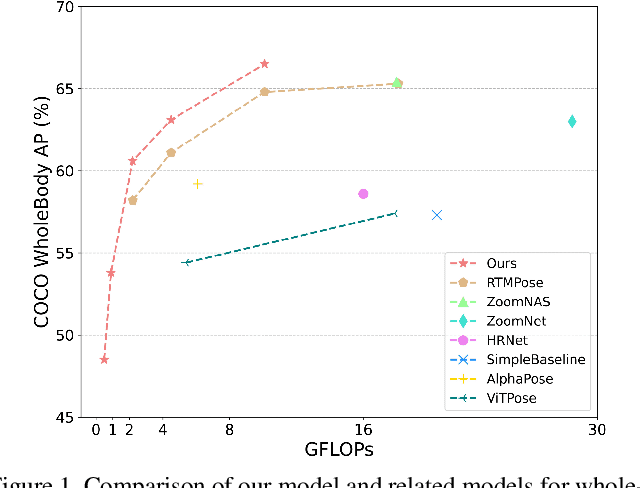
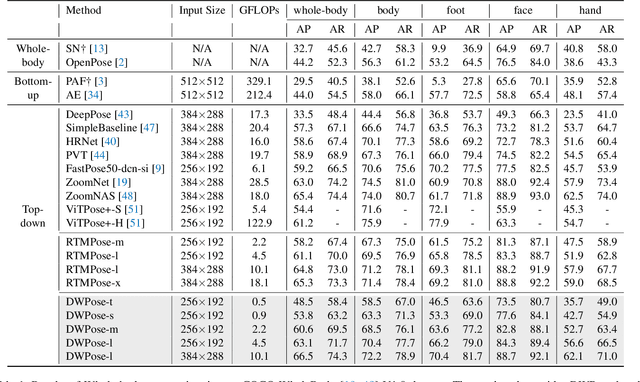
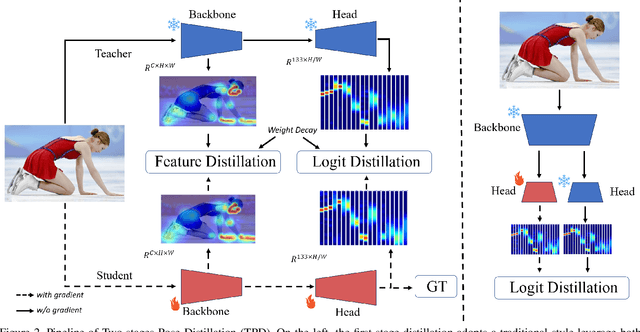
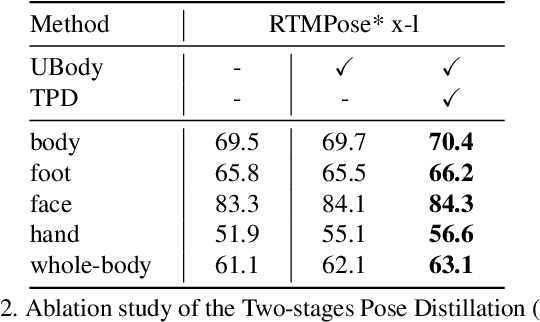
Whole-body pose estimation localizes the human body, hand, face, and foot keypoints in an image. This task is challenging due to multi-scale body parts, fine-grained localization for low-resolution regions, and data scarcity. Meanwhile, applying a highly efficient and accurate pose estimator to widely human-centric understanding and generation tasks is urgent. In this work, we present a two-stage pose \textbf{D}istillation for \textbf{W}hole-body \textbf{P}ose estimators, named \textbf{DWPose}, to improve their effectiveness and efficiency. The first-stage distillation designs a weight-decay strategy while utilizing a teacher's intermediate feature and final logits with both visible and invisible keypoints to supervise the student from scratch. The second stage distills the student model itself to further improve performance. Different from the previous self-knowledge distillation, this stage finetunes the student's head with only 20% training time as a plug-and-play training strategy. For data limitations, we explore the UBody dataset that contains diverse facial expressions and hand gestures for real-life applications. Comprehensive experiments show the superiority of our proposed simple yet effective methods. We achieve new state-of-the-art performance on COCO-WholeBody, significantly boosting the whole-body AP of RTMPose-l from 64.8% to 66.5%, even surpassing RTMPose-x teacher with 65.3% AP. We release a series of models with different sizes, from tiny to large, for satisfying various downstream tasks. Our codes and models are available at https://github.com/IDEA-Research/DWPose.
A Kriging-Random Forest Hybrid Model for Real-time Ground Property Prediction during Earth Pressure Balance Shield Tunneling
May 09, 2023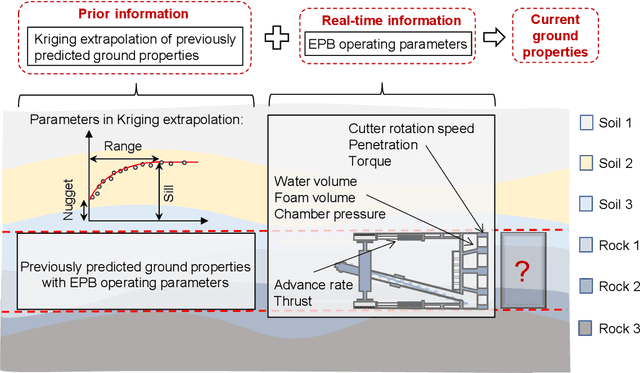
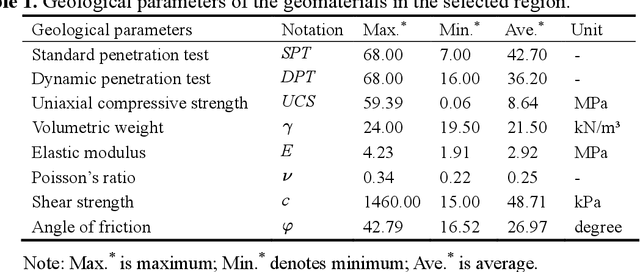
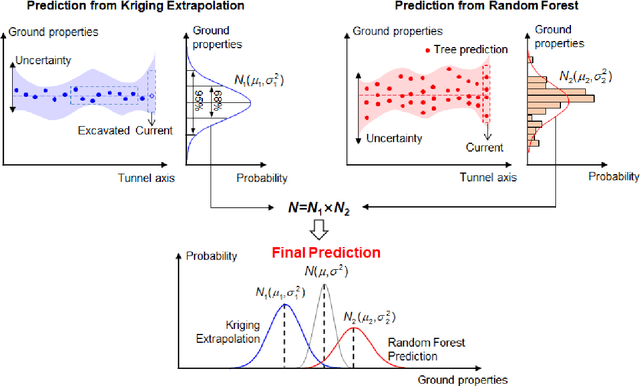
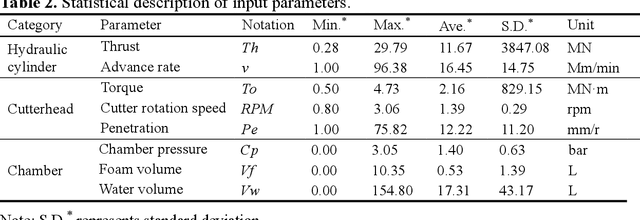
A kriging-random forest hybrid model is developed for real-time ground property prediction ahead of the earth pressure balanced shield by integrating Kriging extrapolation and random forest, which can guide shield operating parameter selection thereby mitigate construction risks. The proposed KRF algorithm synergizes two types of information: prior information and real-time information. The previously predicted ground properties with EPB operating parameters are extrapolated via the Kriging algorithm to provide prior information for the prediction of currently being excavated ground properties. The real-time information refers to the real-time operating parameters of the EPB shield, which are input into random forest to provide a real-time prediction of ground properties. The integration of these two predictions is achieved by assigning weights to each prediction according to their uncertainties, ensuring the prediction of KRF with minimum uncertainty. The performance of the KRF algorithm is assessed via a case study of the Changsha Metro Line 4 project. It reveals that the proposed KRF algorithm can predict ground properties with an accuracy of 93%, overperforming the existing algorithms of LightGBM, AdaBoost-CART, and DNN by 29%, 8%, and 12%, respectively. Another dataset from Shenzhen Metro Line 13 project is utilized to further evaluate the model generalization performance, revealing that the model can transfer its learned knowledge from one region to another with an accuracy of 89%.
Integrated Digital Reconstruction of Welded Components: Supporting Improved Fatigue Life Prediction
Jul 28, 2023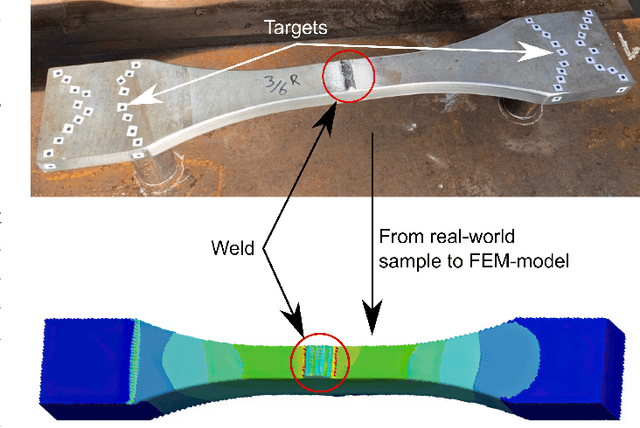



In the design of offshore jacket foundations, fatigue life is crucial. Post-weld treatment has been proposed to enhance the fatigue performance of welded joints, where particularly high-frequency mechanical impact (HFMI) treatment has been shown to improve fatigue performance significantly. Automated HFMI treatment has improved quality assurance and can lead to cost-effective design when combined with accurate fatigue life prediction. However, the finite element method (FEM), commonly used for predicting fatigue life in complex or multi-axial joints, relies on a basic CAD depiction of the weld, failing to consider the actual weld geometry and defects. Including the actual weld geometry in the FE model improves fatigue life prediction and possible crack location prediction but requires a digital reconstruction of the weld. Current digital reconstruction methods are time-consuming or require specialised scanning equipment and potential component relocation. The proposed framework instead uses an industrial manipulator combined with a line scanner to integrate digital reconstruction as part of the automated HFMI treatment setup. This approach applies standard image processing, simple filtering techniques, and non-linear optimisation for aligning and merging overlapping scans. A screened Poisson surface reconstruction finalises the 3D model to create a meshed surface. The outcome is a generic, cost-effective, flexible, and rapid method that enables generic digital reconstruction of welded parts, aiding in component design, overall quality assurance, and documentation of the HFMI treatment.