 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Human-compatible driving partners through data-regularized self-play reinforcement learning
Mar 28, 2024


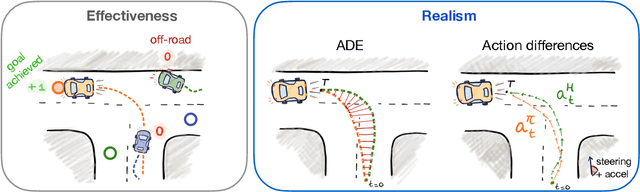
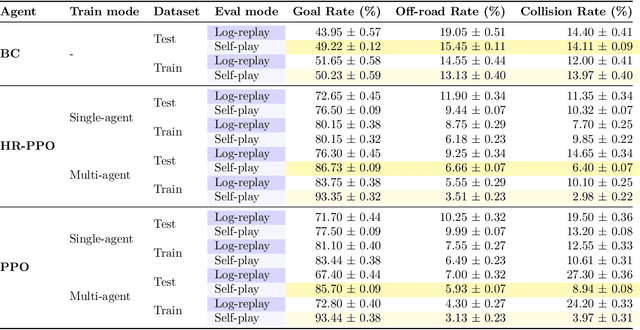
A central challenge for autonomous vehicles is coordinating with humans. Therefore, incorporating realistic human agents is essential for scalable training and evaluation of autonomous driving systems in simulation. Simulation agents are typically developed by imitating large-scale, high-quality datasets of human driving. However, pure imitation learning agents empirically have high collision rates when executed in a multi-agent closed-loop setting. To build agents that are realistic and effective in closed-loop settings, we propose Human-Regularized PPO (HR-PPO), a multi-agent algorithm where agents are trained through self-play with a small penalty for deviating from a human reference policy. In contrast to prior work, our approach is RL-first and only uses 30 minutes of imperfect human demonstrations. We evaluate agents in a large set of multi-agent traffic scenes. Results show our HR-PPO agents are highly effective in achieving goals, with a success rate of 93%, an off-road rate of 3.5%, and a collision rate of 3%. At the same time, the agents drive in a human-like manner, as measured by their similarity to existing human driving logs. We also find that HR-PPO agents show considerable improvements on proxy measures for coordination with human driving, particularly in highly interactive scenarios. We open-source our code and trained agents at https://github.com/Emerge-Lab/nocturne_lab and provide demonstrations of agent behaviors at https://sites.google.com/view/driving-partners.
Surface-based parcellation and vertex-wise analysis of ultra high-resolution ex vivo 7 tesla MRI in neurodegenerative diseases
Mar 28, 2024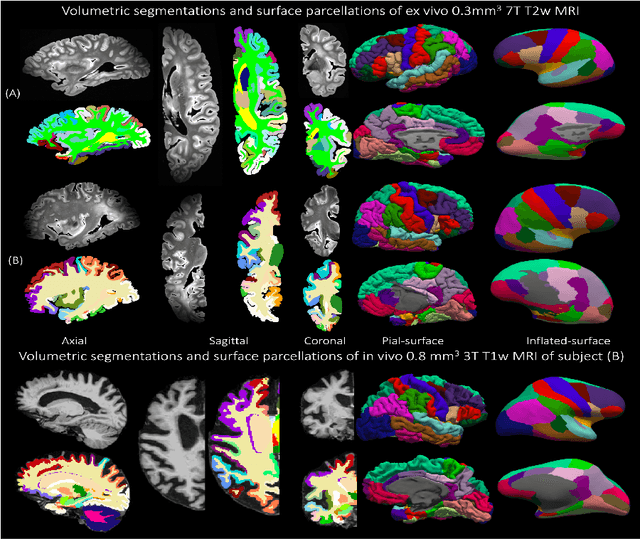
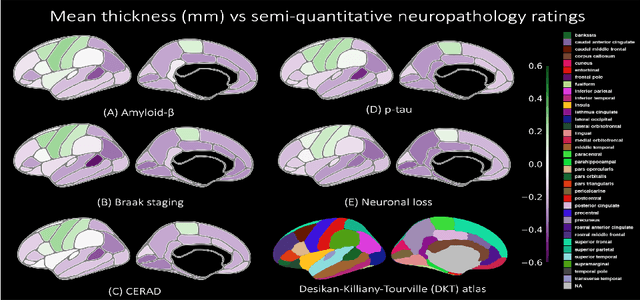
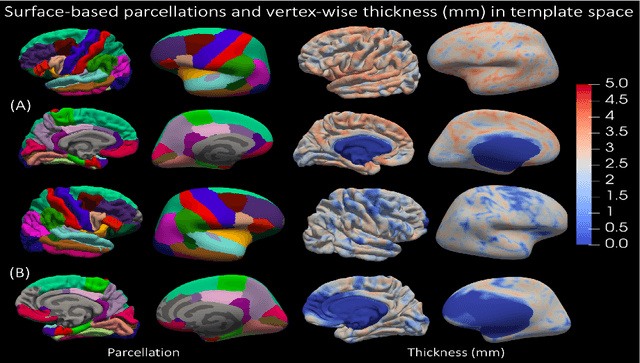
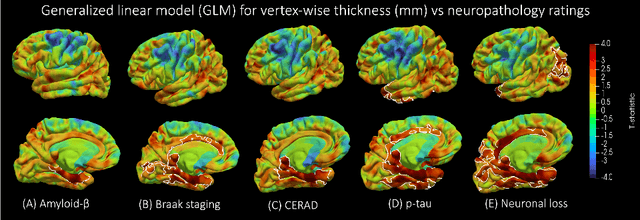
Magnetic resonance imaging (MRI) is the standard modality to understand human brain structure and function in vivo (antemortem). Decades of research in human neuroimaging has led to the widespread development of methods and tools to provide automated volume-based segmentations and surface-based parcellations which help localize brain functions to specialized anatomical regions. Recently ex vivo (postmortem) imaging of the brain has opened-up avenues to study brain structure at sub-millimeter ultra high-resolution revealing details not possible to observe with in vivo MRI. Unfortunately, there has been limited methodological development in ex vivo MRI primarily due to lack of datasets and limited centers with such imaging resources. Therefore, in this work, we present one-of-its-kind dataset of 82 ex vivo T2w whole brain hemispheres MRI at 0.3 mm isotropic resolution spanning Alzheimer's disease and related dementias. We adapted and developed a fast and easy-to-use automated surface-based pipeline to parcellate, for the first time, ultra high-resolution ex vivo brain tissue at the native subject space resolution using the Desikan-Killiany-Tourville (DKT) brain atlas. This allows us to perform vertex-wise analysis in the template space and thereby link morphometry measures with pathology measurements derived from histology. We will open-source our dataset docker container, Jupyter notebooks for ready-to-use out-of-the-box set of tools and command line options to advance ex vivo MRI clinical brain imaging research on the project webpage.
OV-Uni3DETR: Towards Unified Open-Vocabulary 3D Object Detection via Cycle-Modality Propagation
Mar 28, 2024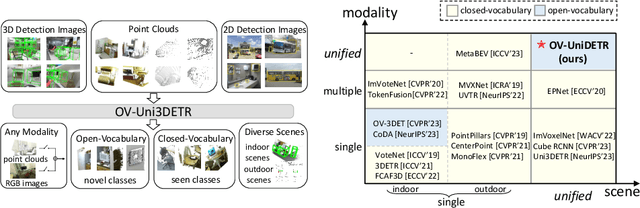
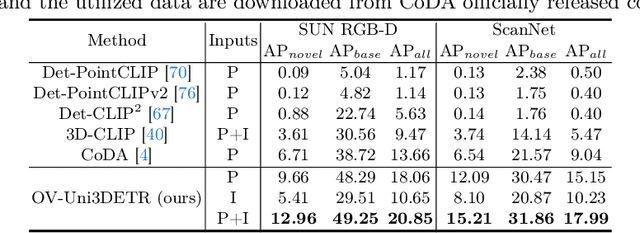
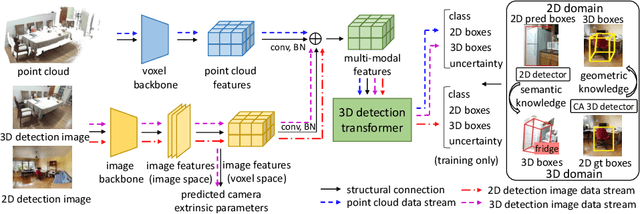
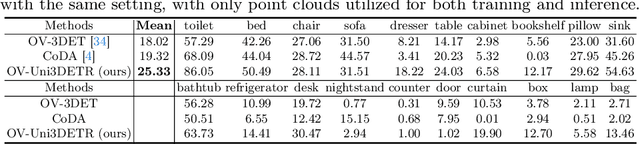
In the current state of 3D object detection research, the severe scarcity of annotated 3D data, substantial disparities across different data modalities, and the absence of a unified architecture, have impeded the progress towards the goal of universality. In this paper, we propose \textbf{OV-Uni3DETR}, a unified open-vocabulary 3D detector via cycle-modality propagation. Compared with existing 3D detectors, OV-Uni3DETR offers distinct advantages: 1) Open-vocabulary 3D detection: During training, it leverages various accessible data, especially extensive 2D detection images, to boost training diversity. During inference, it can detect both seen and unseen classes. 2) Modality unifying: It seamlessly accommodates input data from any given modality, effectively addressing scenarios involving disparate modalities or missing sensor information, thereby supporting test-time modality switching. 3) Scene unifying: It provides a unified multi-modal model architecture for diverse scenes collected by distinct sensors. Specifically, we propose the cycle-modality propagation, aimed at propagating knowledge bridging 2D and 3D modalities, to support the aforementioned functionalities. 2D semantic knowledge from large-vocabulary learning guides novel class discovery in the 3D domain, and 3D geometric knowledge provides localization supervision for 2D detection images. OV-Uni3DETR achieves the state-of-the-art performance on various scenarios, surpassing existing methods by more than 6\% on average. Its performance using only RGB images is on par with or even surpasses that of previous point cloud based methods. Code and pre-trained models will be released later.
Speeding Up Path Planning via Reinforcement Learning in MCTS for Automated Parking
Mar 25, 2024In this paper, we address a method that integrates reinforcement learning into the Monte Carlo tree search to boost online path planning under fully observable environments for automated parking tasks. Sampling-based planning methods under high-dimensional space can be computationally expensive and time-consuming. State evaluation methods are useful by leveraging the prior knowledge into the search steps, making the process faster in a real-time system. Given the fact that automated parking tasks are often executed under complex environments, a solid but lightweight heuristic guidance is challenging to compose in a traditional analytical way. To overcome this limitation, we propose a reinforcement learning pipeline with a Monte Carlo tree search under the path planning framework. By iteratively learning the value of a state and the best action among samples from its previous cycle's outcomes, we are able to model a value estimator and a policy generator for given states. By doing that, we build up a balancing mechanism between exploration and exploitation, speeding up the path planning process while maintaining its quality without using human expert driver data.
Spike-NeRF: Neural Radiance Field Based On Spike Camera
Mar 25, 2024As a neuromorphic sensor with high temporal resolution, spike cameras offer notable advantages over traditional cameras in high-speed vision applications such as high-speed optical estimation, depth estimation, and object tracking. Inspired by the success of the spike camera, we proposed Spike-NeRF, the first Neural Radiance Field derived from spike data, to achieve 3D reconstruction and novel viewpoint synthesis of high-speed scenes. Instead of the multi-view images at the same time of NeRF, the inputs of Spike-NeRF are continuous spike streams captured by a moving spike camera in a very short time. To reconstruct a correct and stable 3D scene from high-frequency but unstable spike data, we devised spike masks along with a distinctive loss function. We evaluate our method qualitatively and numerically on several challenging synthetic scenes generated by blender with the spike camera simulator. Our results demonstrate that Spike-NeRF produces more visually appealing results than the existing methods and the baseline we proposed in high-speed scenes. Our code and data will be released soon.
Discrete-Time Modeling and Handover Analysis of Intelligent Reflecting Surface-Assisted Networks
Mar 12, 2024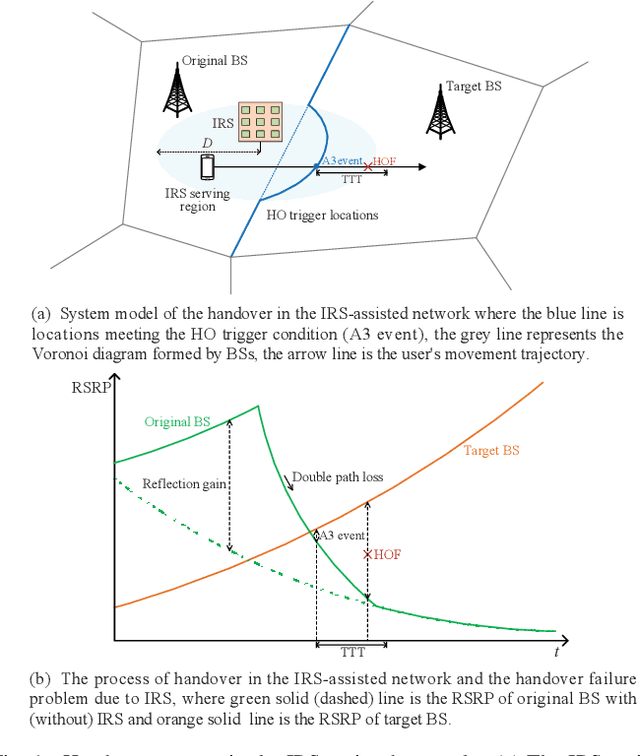
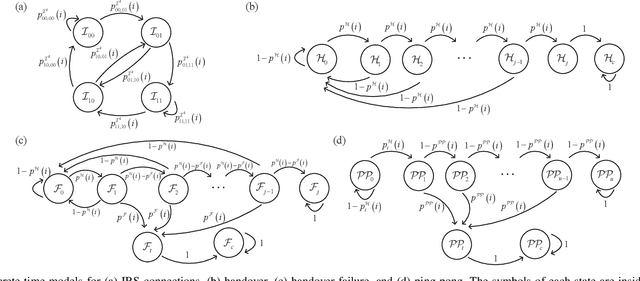
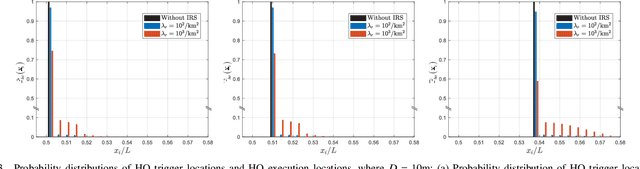
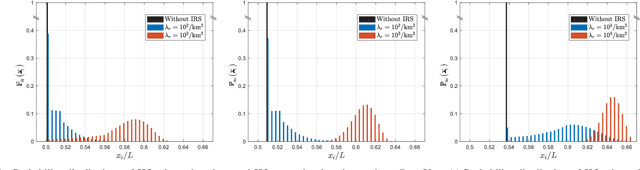
Owning to the reflection gain and double path loss featured by intelligent reflecting surface (IRS) channels, handover (HO) locations become irregular and the signal strength fluctuates sharply with variations in IRS connections during HO, the risk of HO failures (HOFs) is exacerbated and thus HO parameters require reconfiguration. However, existing HO models only assume monotonic negative exponential path loss and cannot obtain sound HO parameters. This paper proposes a discrete-time model to explicitly track the HO process with variations in IRS connections, where IRS connections and HO process are discretized as finite states by measurement intervals, and transitions between states are modeled as stochastic processes. Specifically, to capture signal fluctuations during HO, IRS connection state-dependent distributions of the user-IRS distance are modified by the correlation between measurement intervals. In addition, states of the HO process are formed with Time-to-Trigger and HO margin whose transition probabilities are integrated concerning all IRS connection states. Trigger location distributions and probabilities of HO, HOF, and ping-pong (PP) are obtained by tracing user HO states. Results show IRSs mitigate PPs by 48% but exacerbate HOFs by 90% under regular parameters. Optimal parameters are mined ensuring probabilities of HOF and PP are both less than 0.1%.
NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
Mar 15, 2024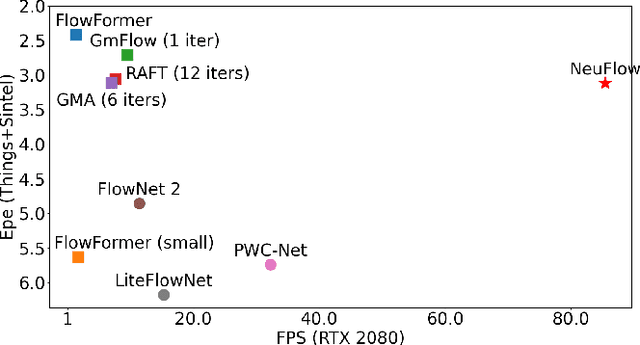

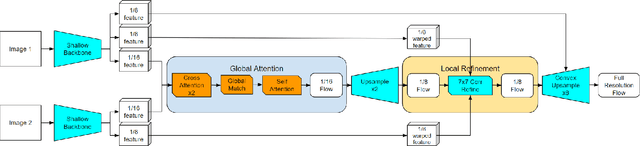
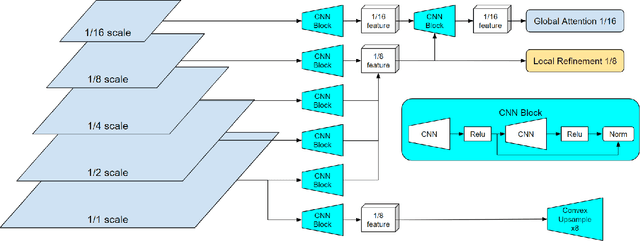
Real-time high-accuracy optical flow estimation is a crucial component in various applications, including localization and mapping in robotics, object tracking, and activity recognition in computer vision. While recent learning-based optical flow methods have achieved high accuracy, they often come with heavy computation costs. In this paper, we propose a highly efficient optical flow architecture, called NeuFlow, that addresses both high accuracy and computational cost concerns. The architecture follows a global-to-local scheme. Given the features of the input images extracted at different spatial resolutions, global matching is employed to estimate an initial optical flow on the 1/16 resolution, capturing large displacement, which is then refined on the 1/8 resolution with lightweight CNN layers for better accuracy. We evaluate our approach on Jetson Orin Nano and RTX 2080 to demonstrate efficiency improvements across different computing platforms. We achieve a notable 10x-80x speedup compared to several state-of-the-art methods, while maintaining comparable accuracy. Our approach achieves around 30 FPS on edge computing platforms, which represents a significant breakthrough in deploying complex computer vision tasks such as SLAM on small robots like drones. The full training and evaluation code is available at https://github.com/neufieldrobotics/NeuFlow.
Artificial Intelligence (AI) Based Prediction of Mortality, for COVID-19 Patients
Mar 28, 2024For severely affected COVID-19 patients, it is crucial to identify high-risk patients and predict survival and need for intensive care (ICU). Most of the proposed models are not well reported making them less reproducible and prone to high risk of bias particularly in presence of imbalance data/class. In this study, the performances of nine machine and deep learning algorithms in combination with two widely used feature selection methods were investigated to predict last status representing mortality, ICU requirement, and ventilation days. Fivefold cross-validation was used for training and validation purposes. To minimize bias, the training and testing sets were split maintaining similar distributions. Only 10 out of 122 features were found to be useful in prediction modelling with Acute kidney injury during hospitalization feature being the most important one. The algorithms performances depend on feature numbers and data pre-processing techniques. LSTM performs the best in predicting last status and ICU requirement with 90%, 92%, 86% and 95% accuracy, sensitivity, specificity, and AUC respectively. DNN performs the best in predicting Ventilation days with 88% accuracy. Considering all the factors and limitations including absence of exact time point of clinical onset, LSTM with carefully selected features can accurately predict last status and ICU requirement. DNN performs the best in predicting Ventilation days. Appropriate machine learning algorithm with carefully selected features and balance data can accurately predict mortality, ICU requirement and ventilation support. Such model can be very useful in emergency and pandemic where prompt and precise
Segmentation tool for images of cracks
Mar 28, 2024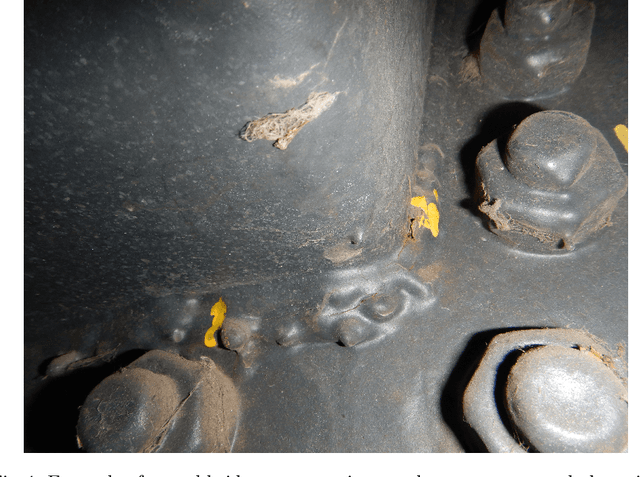


Safety-critical infrastructures, such as bridges, are periodically inspected to check for existing damage, such as fatigue cracks and corrosion, and to guarantee the safe use of the infrastructure. Visual inspection is the most frequent type of general inspection, despite the fact that its detection capability is rather limited, especially for fatigue cracks. Machine learning algorithms can be used for augmenting the capability of classical visual inspection of bridge structures, however, the implementation of such an algorithm requires a massive annotated training dataset, which is time-consuming to produce. This paper proposes a semi-automatic crack segmentation tool that eases the manual segmentation of cracks on images needed to create a training dataset for a machine learning algorithm. Also, it can be used to measure the geometry of the crack. This tool makes use of an image processing algorithm, which was initially developed for the analysis of vascular systems on retinal images. The algorithm relies on a multi-orientation wavelet transform, which is applied to the image to construct the so-called "orientation scores", i.e. a modified version of the image. Afterwards, the filtered orientation scores are used to formulate an optimal path problem that identifies the crack. The globally optimal path between manually selected crack endpoints is computed, using a state-of-the-art geometric tracking method. The pixel-wise segmentation is done afterwards using the obtained crack path. The proposed method outperforms fully automatic methods and shows potential to be an adequate alternative to the manual data annotation.
GeNet: A Graph Neural Network-based Anti-noise Task-Oriented Semantic Communication Paradigm
Mar 27, 2024Traditional approaches to semantic communication tasks rely on the knowledge of the signal-to-noise ratio (SNR) to mitigate channel noise. However, these methods necessitate training under specific SNR conditions, entailing considerable time and computational resources. In this paper, we propose GeNet, a Graph Neural Network (GNN)-based paradigm for semantic communication aimed at combating noise, thereby facilitating Task-Oriented Communication (TOC). We propose a novel approach where we first transform the input data image into graph structures. Then we leverage a GNN-based encoder to extract semantic information from the source data. This extracted semantic information is then transmitted through the channel. At the receiver's end, a GNN-based decoder is utilized to reconstruct the relevant semantic information from the source data for TOC. Through experimental evaluation, we show GeNet's effectiveness in anti-noise TOC while decoupling the SNR dependency. We further evaluate GeNet's performance by varying the number of nodes, revealing its versatility as a new paradigm for semantic communication. Additionally, we show GeNet's robustness to geometric transformations by testing it with different rotation angles, without resorting to data augmentation.