 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint Microseismic Event Detection and Location with a Detection Transformer
Jul 16, 2023
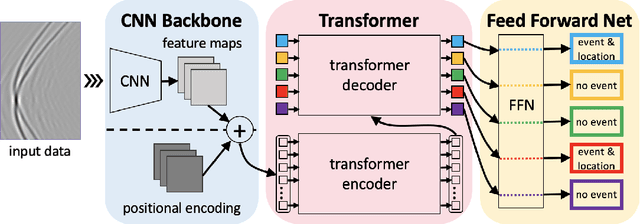
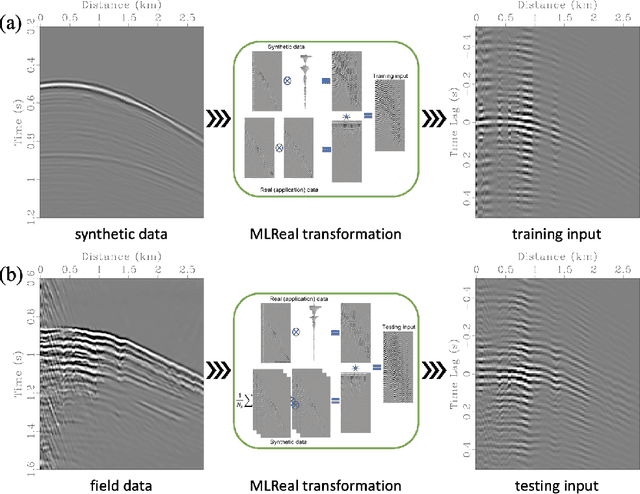
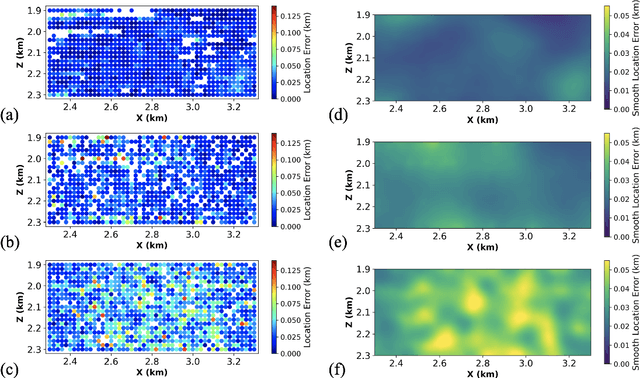

Microseismic event detection and location are two primary components in microseismic monitoring, which offers us invaluable insights into the subsurface during reservoir stimulation and evolution. Conventional approaches for event detection and location often suffer from manual intervention and/or heavy computation, while current machine learning-assisted approaches typically address detection and location separately; such limitations hinder the potential for real-time microseismic monitoring. We propose an approach to unify event detection and source location into a single framework by adapting a Convolutional Neural Network backbone and an encoder-decoder Transformer with a set-based Hungarian loss, which is applied directly to recorded waveforms. The proposed network is trained on synthetic data simulating multiple microseismic events corresponding to random source locations in the area of suspected microseismic activities. A synthetic test on a 2D profile of the SEAM Time Lapse model illustrates the capability of the proposed method in detecting the events properly and locating them in the subsurface accurately; while, a field test using the Arkoma Basin data further proves its practicability, efficiency, and its potential in paving the way for real-time monitoring of microseismic events.
MaxMin-L2-SVC-NCH: A Novel Approach for Support Vector Classifier Training and Parameter Selection
Jul 25, 2023

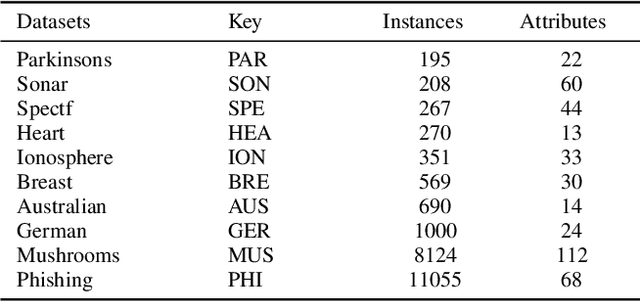
The selection of Gaussian kernel parameters plays an important role in the applications of support vector classification (SVC). A commonly used method is the k-fold cross validation with grid search (CV), which is extremely time-consuming because it needs to train a large number of SVC models. In this paper, a new approach is proposed to train SVC and optimize the selection of Gaussian kernel parameters. We first formulate the training and parameter selection of SVC as a minimax optimization problem named as MaxMin-L2-SVC-NCH, in which the minimization problem is an optimization problem of finding the closest points between two normal convex hulls (L2-SVC-NCH) while the maximization problem is an optimization problem of finding the optimal Gaussian kernel parameters. A lower time complexity can be expected in MaxMin-L2-SVC-NCH because CV is not needed. We then propose a projected gradient algorithm (PGA) for training L2-SVC-NCH. The famous sequential minimal optimization (SMO) algorithm is a special case of the PGA. Thus, the PGA can provide more flexibility than the SMO. Furthermore, the solution of the maximization problem is done by a gradient ascent algorithm with dynamic learning rate. The comparative experiments between MaxMin-L2-SVC-NCH and the previous best approaches on public datasets show that MaxMin-L2-SVC-NCH greatly reduces the number of models to be trained while maintaining competitive test accuracy. These findings indicate that MaxMin-L2-SVC-NCH is a better choice for SVC tasks.
Improved Order Analysis and Design of Exponential Integrator for Diffusion Models Sampling
Aug 04, 2023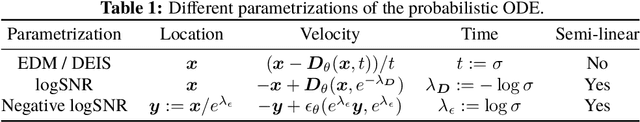
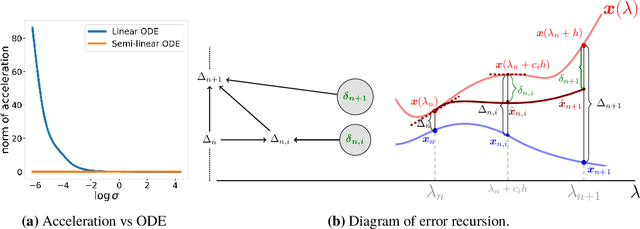
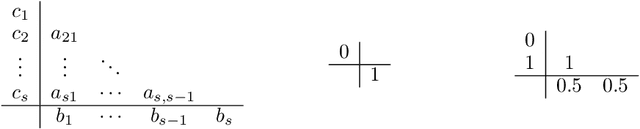
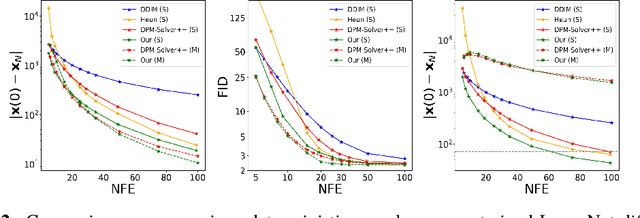
Efficient differential equation solvers have significantly reduced the sampling time of diffusion models (DMs) while retaining high sampling quality. Among these solvers, exponential integrators (EI) have gained prominence by demonstrating state-of-the-art performance. However, existing high-order EI-based sampling algorithms rely on degenerate EI solvers, resulting in inferior error bounds and reduced accuracy in contrast to the theoretically anticipated results under optimal settings. This situation makes the sampling quality extremely vulnerable to seemingly innocuous design choices such as timestep schedules. For example, an inefficient timestep scheduler might necessitate twice the number of steps to achieve a quality comparable to that obtained through carefully optimized timesteps. To address this issue, we reevaluate the design of high-order differential solvers for DMs. Through a thorough order analysis, we reveal that the degeneration of existing high-order EI solvers can be attributed to the absence of essential order conditions. By reformulating the differential equations in DMs and capitalizing on the theory of exponential integrators, we propose refined EI solvers that fulfill all the order conditions, which we designate as Refined Exponential Solver (RES). Utilizing these improved solvers, RES exhibits more favorable error bounds theoretically and achieves superior sampling efficiency and stability in practical applications. For instance, a simple switch from the single-step DPM-Solver++ to our order-satisfied RES solver when Number of Function Evaluations (NFE) $=9$, results in a reduction of numerical defects by $25.2\%$ and FID improvement of $25.4\%$ (16.77 vs 12.51) on a pre-trained ImageNet diffusion model.
Harnessing the Web and Knowledge Graphs for Automated Impact Investing Scoring
Aug 04, 2023The Sustainable Development Goals (SDGs) were introduced by the United Nations in order to encourage policies and activities that help guarantee human prosperity and sustainability. SDG frameworks produced in the finance industry are designed to provide scores that indicate how well a company aligns with each of the 17 SDGs. This scoring enables a consistent assessment of investments that have the potential of building an inclusive and sustainable economy. As a result of the high quality and reliability required by such frameworks, the process of creating and maintaining them is time-consuming and requires extensive domain expertise. In this work, we describe a data-driven system that seeks to automate the process of creating an SDG framework. First, we propose a novel method for collecting and filtering a dataset of texts from different web sources and a knowledge graph relevant to a set of companies. We then implement and deploy classifiers trained with this data for predicting scores of alignment with SDGs for a given company. Our results indicate that our best performing model can accurately predict SDG scores with a micro average F1 score of 0.89, demonstrating the effectiveness of the proposed solution. We further describe how the integration of the models for its use by humans can be facilitated by providing explanations in the form of data relevant to a predicted score. We find that our proposed solution enables access to a large amount of information that analysts would normally not be able to process, resulting in an accurate prediction of SDG scores at a fraction of the cost.
ShaDDR: Real-Time Example-Based Geometry and Texture Generation via 3D Shape Detailization and Differentiable Rendering
Jun 08, 2023
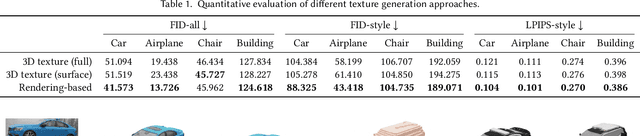
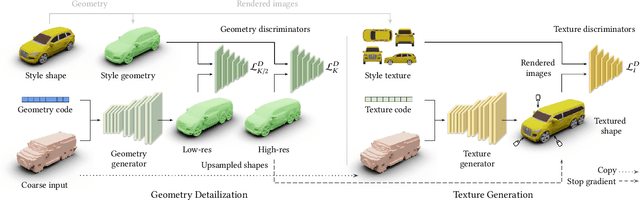

We present ShaDDR, an example-based deep generative neural network which produces a high-resolution textured 3D shape through geometry detailization and conditional texture generation applied to an input coarse voxel shape. Trained on a small set of detailed and textured exemplar shapes, our method learns to detailize the geometry via multi-resolution voxel upsampling and generate textures on voxel surfaces via differentiable rendering against exemplar texture images from a few views. The generation is real-time, taking less than 1 second to produce a 3D model with voxel resolutions up to 512^3. The generated shape preserves the overall structure of the input coarse voxel model, while the style of the generated geometric details and textures can be manipulated through learned latent codes. In the experiments, we show that our method can generate higher-resolution shapes with plausible and improved geometric details and clean textures compared to prior works. Furthermore, we showcase the ability of our method to learn geometric details and textures from shapes reconstructed from real-world photos. In addition, we have developed an interactive modeling application to demonstrate the generalizability of our method to various user inputs and the controllability it offers, allowing users to interactively sculpt a coarse voxel shape to define the overall structure of the detailized 3D shape.
Improving Real-Time Bidding in Online Advertising Using Markov Decision Processes and Machine Learning Techniques
May 05, 2023
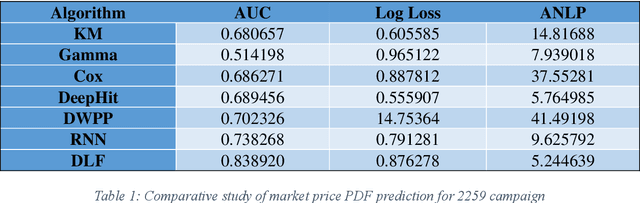
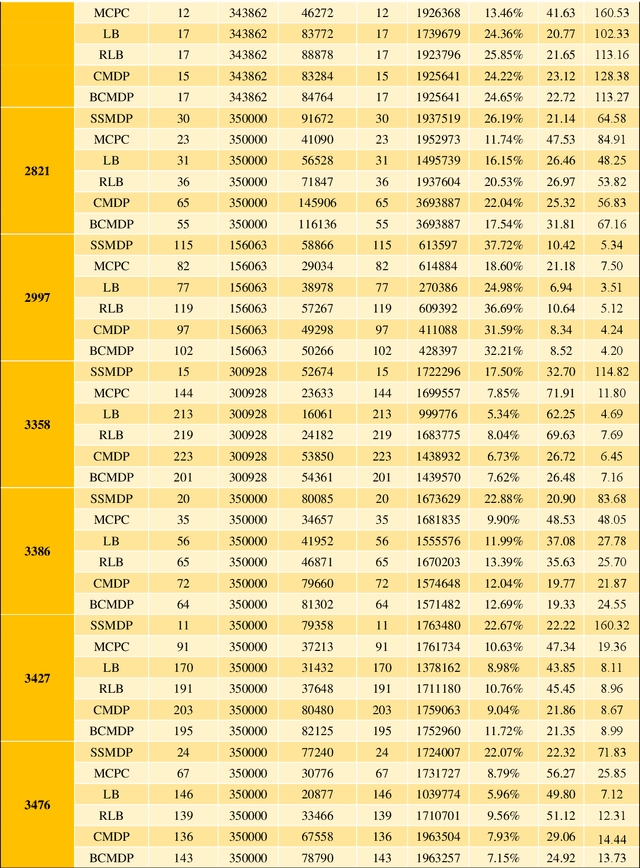
Real-time bidding has emerged as an effective online advertising technique. With real-time bidding, advertisers can position ads per impression, enabling them to optimise ad campaigns by targeting specific audiences in real-time. This paper proposes a novel method for real-time bidding that combines deep learning and reinforcement learning techniques to enhance the efficiency and precision of the bidding process. In particular, the proposed method employs a deep neural network to predict auction details and market prices and a reinforcement learning algorithm to determine the optimal bid price. The model is trained using historical data from the iPinYou dataset and compared to cutting-edge real-time bidding algorithms. The outcomes demonstrate that the proposed method is preferable regarding cost-effectiveness and precision. In addition, the study investigates the influence of various model parameters on the performance of the proposed algorithm. It offers insights into the efficacy of the combined deep learning and reinforcement learning approach for real-time bidding. This study contributes to advancing techniques and offers a promising direction for future research.
A Primer on the Data Cleaning Pipeline
Jul 25, 2023The availability of both structured and unstructured databases, such as electronic health data, social media data, patent data, and surveys that are often updated in real time, among others, has grown rapidly over the past decade. With this expansion, the statistical and methodological questions around data integration, or rather merging multiple data sources, has also grown. Specifically, the science of the ``data cleaning pipeline'' contains four stages that allow an analyst to perform downstream tasks, predictive analyses, or statistical analyses on ``cleaned data.'' This article provides a review of this emerging field, introducing technical terminology and commonly used methods.
FastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder With Multiple STFTs
May 18, 2023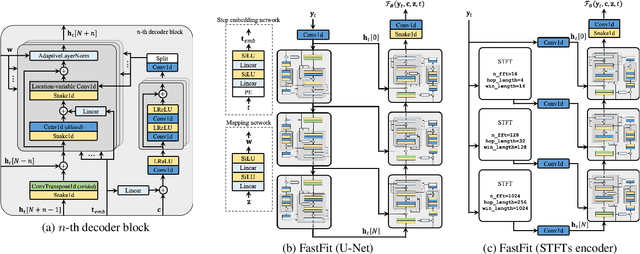
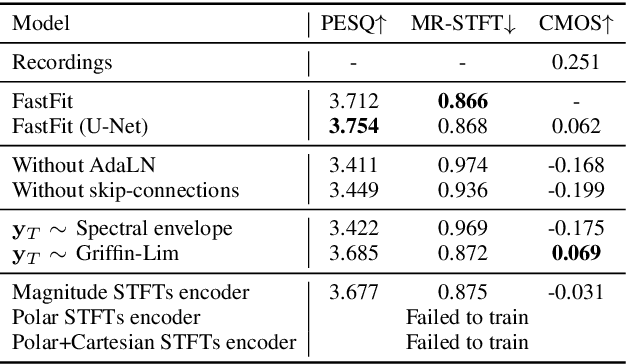
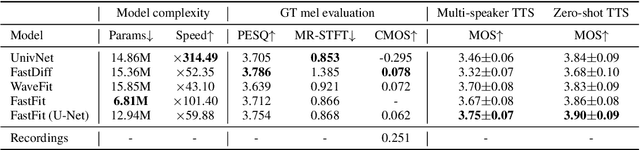
This paper presents FastFit, a novel neural vocoder architecture that replaces the U-Net encoder with multiple short-time Fourier transforms (STFTs) to achieve faster generation rates without sacrificing sample quality. We replaced each encoder block with an STFT, with parameters equal to the temporal resolution of each decoder block, leading to the skip connection. FastFit reduces the number of parameters and the generation time of the model by almost half while maintaining high fidelity. Through objective and subjective evaluations, we demonstrated that the proposed model achieves nearly twice the generation speed of baseline iteration-based vocoders while maintaining high sound quality. We further showed that FastFit produces sound qualities similar to those of other baselines in text-to-speech evaluation scenarios, including multi-speaker and zero-shot text-to-speech.
Real-Time Character Rise Motions
Apr 11, 2023This paper presents an uncomplicated dynamic controller for generating physically-plausible three-dimensional full-body biped character rise motions on-the-fly at run-time. Our low-dimensional controller uses fundamental reference information (e.g., center-of-mass, hands, and feet locations) to produce balanced biped get-up poses by means of a real-time physically-based simulation. The key idea is to use a simple approximate model (i.e., similar to the inverted-pendulum stepping model) to create continuous reference trajectories that can be seamlessly tracked by an articulated biped character to create balanced rise-motions. Our approach does not use any key-framed data or any computationally expensive processing (e.g., offline-optimization or search algorithms). We demonstrate the effectiveness and ease of our technique through example (i.e., a biped character picking itself up from different laying positions).
SSD-2: Scaling and Inference-time Fusion of Diffusion Language Models
May 24, 2023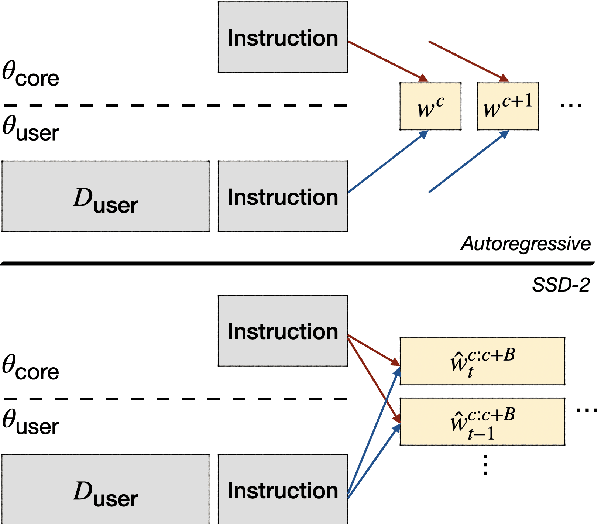

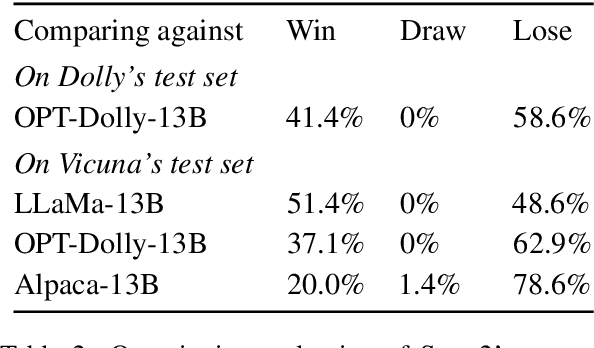
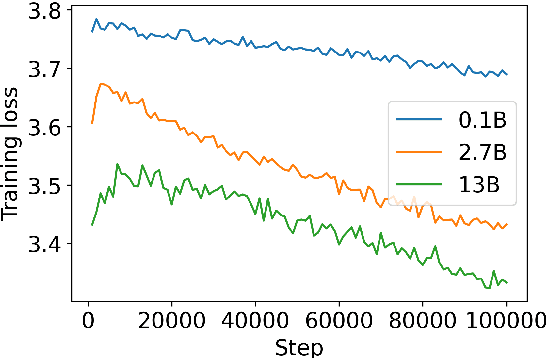
Diffusion-based language models (LMs) have been shown to be competent generative models that are easy to control at inference and are a promising alternative to autoregressive LMs. While autoregressive LMs have benefited immensely from scaling and instruction-based learning, existing studies on diffusion LMs have been conducted on a relatively smaller scale. Starting with a recently proposed diffusion model SSD-LM, in this work we explore methods to scale it from 0.4B to 13B parameters, proposing several techniques to improve its training and inference efficiency. We call the new model SSD-2. We further show that this model can be easily finetuned to follow instructions. Finally, leveraging diffusion models' capability at inference-time control, we show that SSD-2 facilitates novel ensembles with 100x smaller models that can be customized and deployed by individual users. We find that compared to autoregressive models, the collaboration between diffusion models is more effective, leading to higher-quality and more relevant model responses due to their ability to incorporate bi-directional contexts.