 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reinforcement Learning for Credit Index Option Hedging
Jul 19, 2023
In this paper, we focus on finding the optimal hedging strategy of a credit index option using reinforcement learning. We take a practical approach, where the focus is on realism i.e. discrete time, transaction costs; even testing our policy on real market data. We apply a state of the art algorithm, the Trust Region Volatility Optimization (TRVO) algorithm and show that the derived hedging strategy outperforms the practitioner's Black & Scholes delta hedge.
A Fast Task Offloading Optimization Framework for IRS-Assisted Multi-Access Edge Computing System
Jul 17, 2023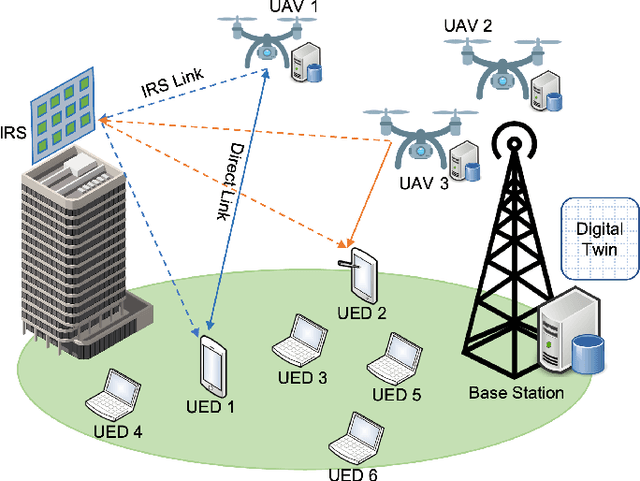
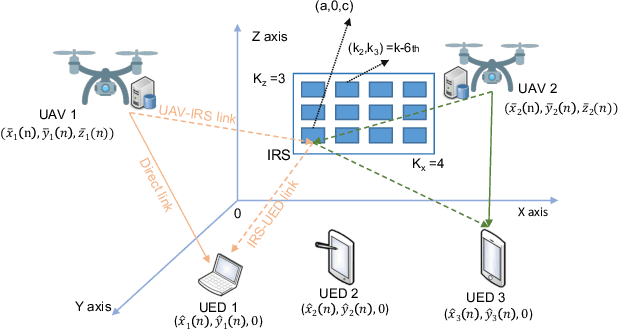
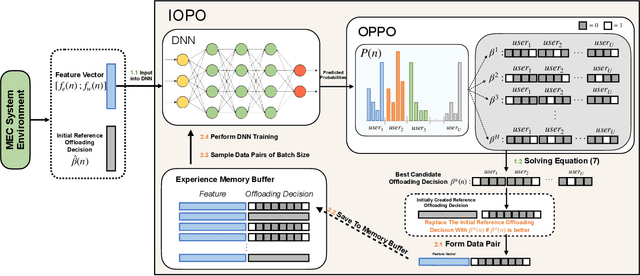
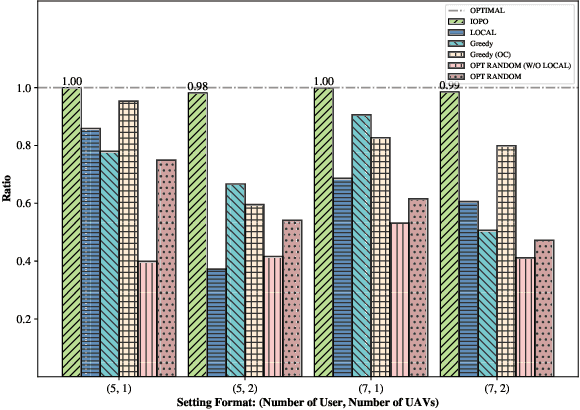
Terahertz communication networks and intelligent reflecting surfaces exhibit significant potential in advancing wireless networks, particularly within the domain of aerial-based multi-access edge computing systems. These technologies enable efficient offloading of computational tasks from user electronic devices to Unmanned Aerial Vehicles or local execution. For the generation of high-quality task-offloading allocations, conventional numerical optimization methods often struggle to solve challenging combinatorial optimization problems within the limited channel coherence time, thereby failing to respond quickly to dynamic changes in system conditions. To address this challenge, we propose a deep learning-based optimization framework called Iterative Order-Preserving policy Optimization (IOPO), which enables the generation of energy-efficient task-offloading decisions within milliseconds. Unlike exhaustive search methods, IOPO provides continuous updates to the offloading decisions without resorting to exhaustive search, resulting in accelerated convergence and reduced computational complexity, particularly when dealing with complex problems characterized by extensive solution spaces. Experimental results demonstrate that the proposed framework can generate energy-efficient task-offloading decisions within a very short time period, outperforming other benchmark methods.
Basal-Bolus Advisor for Type 1 Diabetes (T1D) Patients Using Multi-Agent Reinforcement Learning (RL) Methodology
Jul 17, 2023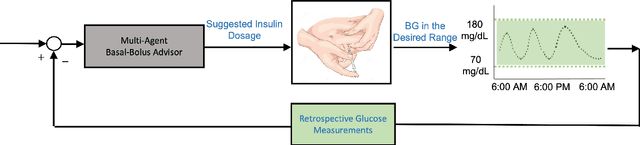
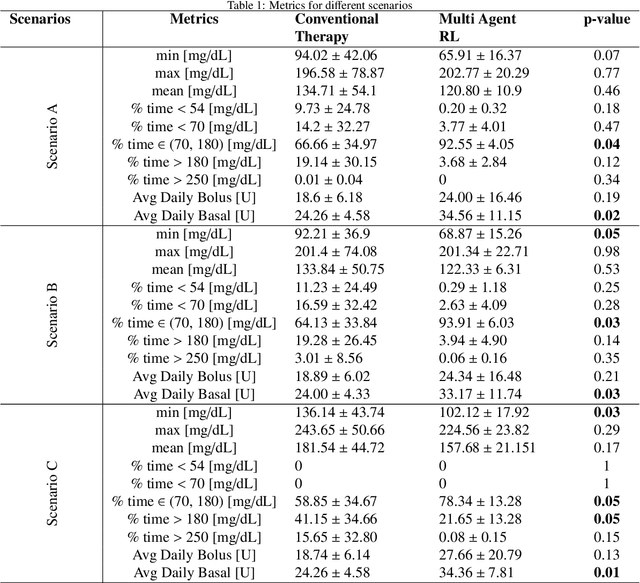
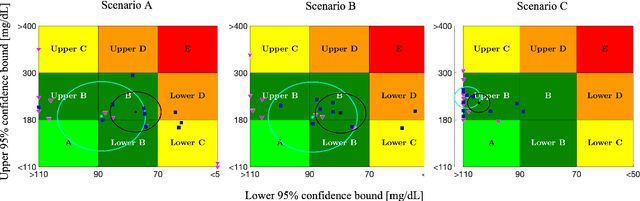
This paper presents a novel multi-agent reinforcement learning (RL) approach for personalized glucose control in individuals with type 1 diabetes (T1D). The method employs a closed-loop system consisting of a blood glucose (BG) metabolic model and a multi-agent soft actor-critic RL model acting as the basal-bolus advisor. Performance evaluation is conducted in three scenarios, comparing the RL agents to conventional therapy. Evaluation metrics include glucose levels (minimum, maximum, and mean), time spent in different BG ranges, and average daily bolus and basal insulin dosages. Results demonstrate that the RL-based basal-bolus advisor significantly improves glucose control, reducing glycemic variability and increasing time spent within the target range (70-180 mg/dL). Hypoglycemia events are effectively prevented, and severe hyperglycemia events are reduced. The RL approach also leads to a statistically significant reduction in average daily basal insulin dosage compared to conventional therapy. These findings highlight the effectiveness of the multi-agent RL approach in achieving better glucose control and mitigating the risk of severe hyperglycemia in individuals with T1D.
SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark
Jul 27, 2023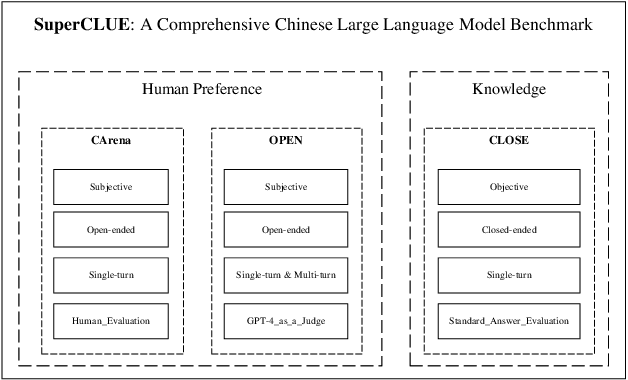


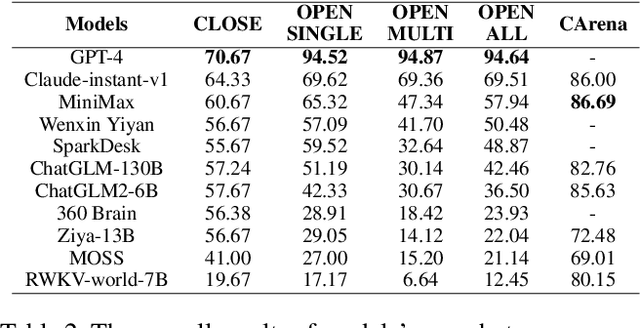
Large language models (LLMs) have shown the potential to be integrated into human daily lives. Therefore, user preference is the most critical criterion for assessing LLMs' performance in real-world scenarios. However, existing benchmarks mainly focus on measuring models' accuracy using multi-choice questions, which limits the understanding of their capabilities in real applications. We fill this gap by proposing a comprehensive Chinese benchmark SuperCLUE, named after another popular Chinese LLM benchmark CLUE. SuperCLUE encompasses three sub-tasks: actual users' queries and ratings derived from an LLM battle platform (CArena), open-ended questions with single and multiple-turn dialogues (OPEN), and closed-ended questions with the same stems as open-ended single-turn ones (CLOSE). Our study shows that accuracy on closed-ended questions is insufficient to reflect human preferences achieved on open-ended ones. At the same time, they can complement each other to predict actual user preferences. We also demonstrate that GPT-4 is a reliable judge to automatically evaluate human preferences on open-ended questions in a Chinese context. Our benchmark will be released at https://www.CLUEbenchmarks.com
GET3D--: Learning GET3D from Unconstrained Image Collections
Jul 27, 2023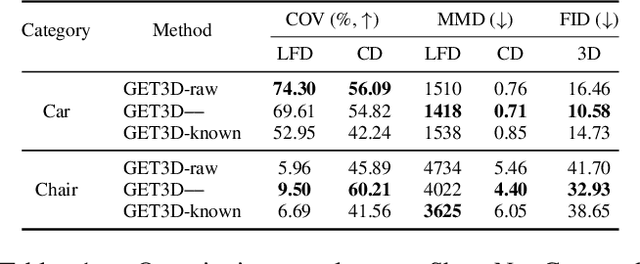
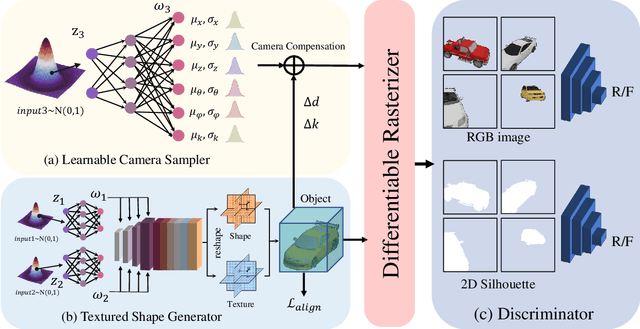

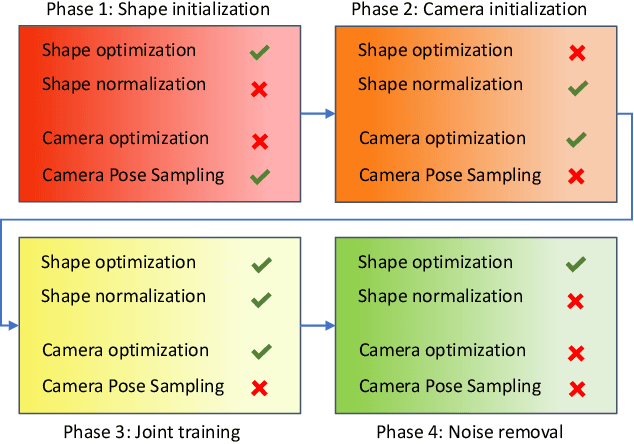
The demand for efficient 3D model generation techniques has grown exponentially, as manual creation of 3D models is time-consuming and requires specialized expertise. While generative models have shown potential in creating 3D textured shapes from 2D images, their applicability in 3D industries is limited due to the lack of a well-defined camera distribution in real-world scenarios, resulting in low-quality shapes. To overcome this limitation, we propose GET3D--, the first method that directly generates textured 3D shapes from 2D images with unknown pose and scale. GET3D-- comprises a 3D shape generator and a learnable camera sampler that captures the 6D external changes on the camera. In addition, We propose a novel training schedule to stably optimize both the shape generator and camera sampler in a unified framework. By controlling external variations using the learnable camera sampler, our method can generate aligned shapes with clear textures. Extensive experiments demonstrate the efficacy of GET3D--, which precisely fits the 6D camera pose distribution and generates high-quality shapes on both synthetic and realistic unconstrained datasets.
Adaptive Segmentation Network for Scene Text Detection
Jul 27, 2023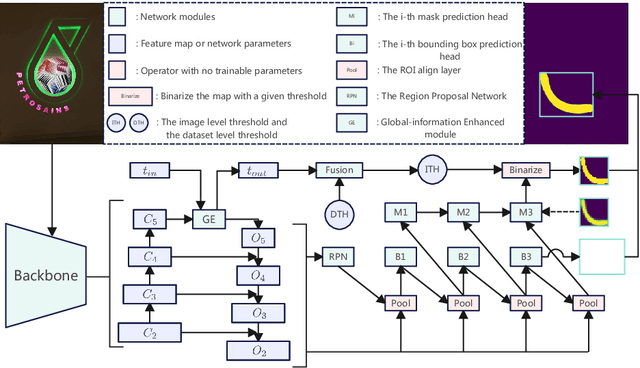
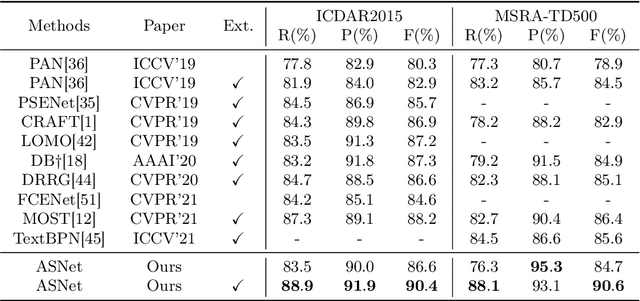
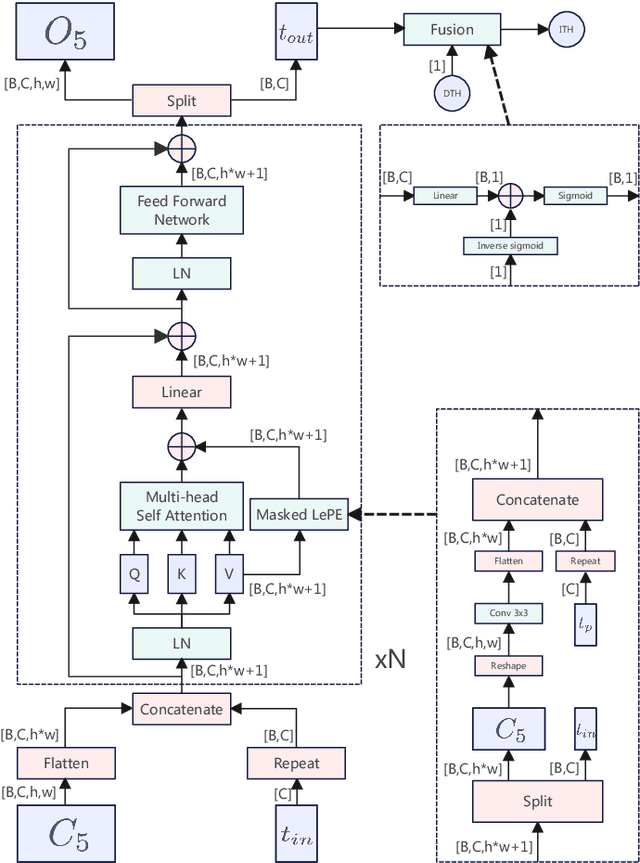
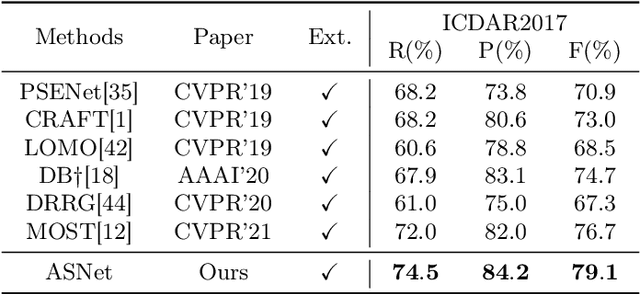
Inspired by deep convolution segmentation algorithms, scene text detectors break the performance ceiling of datasets steadily. However, these methods often encounter threshold selection bottlenecks and have poor performance on text instances with extreme aspect ratios. In this paper, we propose to automatically learn the discriminate segmentation threshold, which distinguishes text pixels from background pixels for segmentation-based scene text detectors and then further reduces the time-consuming manual parameter adjustment. Besides, we design a Global-information Enhanced Feature Pyramid Network (GE-FPN) for capturing text instances with macro size and extreme aspect ratios. Following the GE-FPN, we introduce a cascade optimization structure to further refine the text instances. Finally, together with the proposed threshold learning strategy and text detection structure, we design an Adaptive Segmentation Network (ASNet) for scene text detection. Extensive experiments are carried out to demonstrate that the proposed ASNet can achieve the state-of-the-art performance on four text detection benchmarks, i.e., ICDAR 2015, MSRA-TD500, ICDAR 2017 MLT and CTW1500. The ablation experiments also verify the effectiveness of our contributions.
Detecting Morphing Attacks via Continual Incremental Training
Jul 27, 2023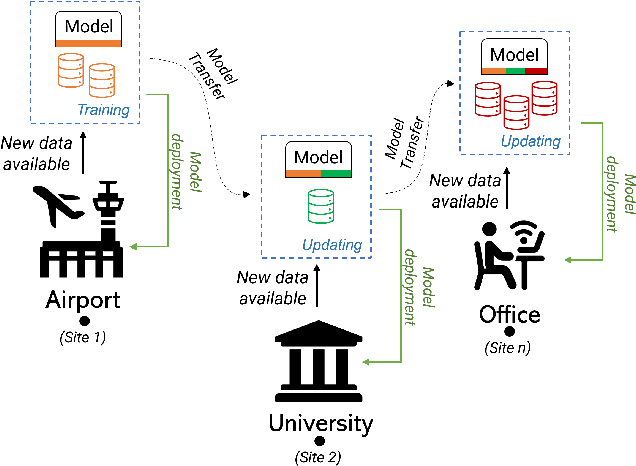
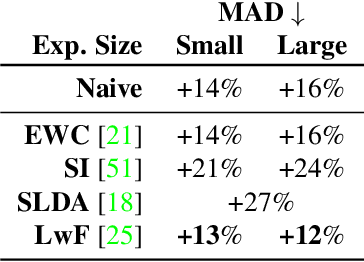


Scenarios in which restrictions in data transfer and storage limit the possibility to compose a single dataset -- also exploiting different data sources -- to perform a batch-based training procedure, make the development of robust models particularly challenging. We hypothesize that the recent Continual Learning (CL) paradigm may represent an effective solution to enable incremental training, even through multiple sites. Indeed, a basic assumption of CL is that once a model has been trained, old data can no longer be used in successive training iterations and in principle can be deleted. Therefore, in this paper, we investigate the performance of different Continual Learning methods in this scenario, simulating a learning model that is updated every time a new chunk of data, even of variable size, is available. Experimental results reveal that a particular CL method, namely Learning without Forgetting (LwF), is one of the best-performing algorithms. Then, we investigate its usage and parametrization in Morphing Attack Detection and Object Classification tasks, specifically with respect to the amount of new training data that became available.
TwinLiteNet: An Efficient and Lightweight Model for Driveable Area and Lane Segmentation in Self-Driving Cars
Jul 27, 2023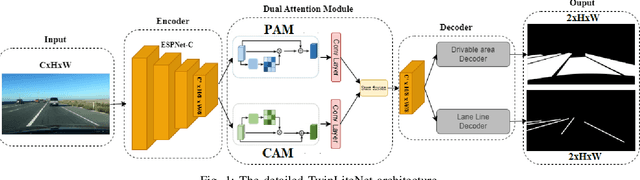
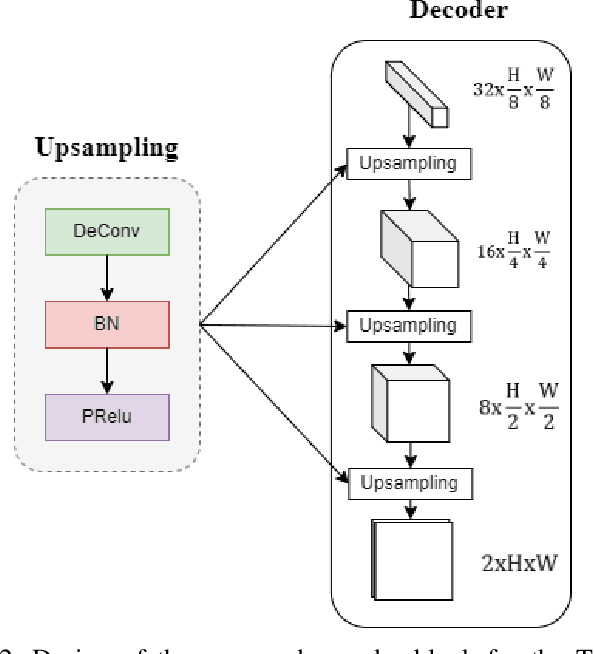


Semantic segmentation is a common task in autonomous driving to understand the surrounding environment. Driveable Area Segmentation and Lane Detection are particularly important for safe and efficient navigation on the road. However, original semantic segmentation models are computationally expensive and require high-end hardware, which is not feasible for embedded systems in autonomous vehicles. This paper proposes a lightweight model for the driveable area and lane line segmentation. TwinLiteNet is designed cheaply but achieves accurate and efficient segmentation results. We evaluate TwinLiteNet on the BDD100K dataset and compare it with modern models. Experimental results show that our TwinLiteNet performs similarly to existing approaches, requiring significantly fewer computational resources. Specifically, TwinLiteNet achieves a mIoU score of 91.3% for the Drivable Area task and 31.08% IoU for the Lane Detection task with only 0.4 million parameters and achieves 415 FPS on GPU RTX A5000. Furthermore, TwinLiteNet can run in real-time on embedded devices with limited computing power, especially since it achieves 60FPS on Jetson Xavier NX, making it an ideal solution for self-driving vehicles. Code is available: url{https://github.com/chequanghuy/TwinLiteNet}.
Seeing through the Brain: Image Reconstruction of Visual Perception from Human Brain Signals
Jul 27, 2023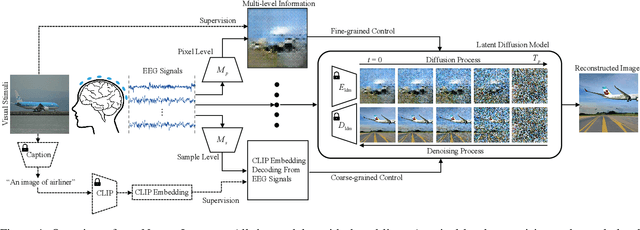


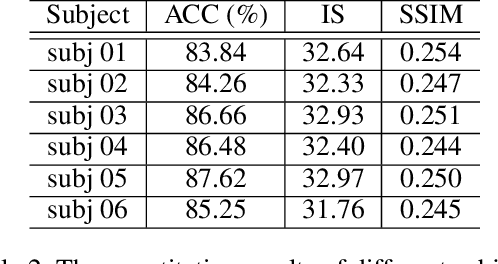
Seeing is believing, however, the underlying mechanism of how human visual perceptions are intertwined with our cognitions is still a mystery. Thanks to the recent advances in both neuroscience and artificial intelligence, we have been able to record the visually evoked brain activities and mimic the visual perception ability through computational approaches. In this paper, we pay attention to visual stimuli reconstruction by reconstructing the observed images based on portably accessible brain signals, i.e., electroencephalography (EEG) data. Since EEG signals are dynamic in the time-series format and are notorious to be noisy, processing and extracting useful information requires more dedicated efforts; In this paper, we propose a comprehensive pipeline, named NeuroImagen, for reconstructing visual stimuli images from EEG signals. Specifically, we incorporate a novel multi-level perceptual information decoding to draw multi-grained outputs from the given EEG data. A latent diffusion model will then leverage the extracted information to reconstruct the high-resolution visual stimuli images. The experimental results have illustrated the effectiveness of image reconstruction and superior quantitative performance of our proposed method.
Foundations of Spatial Perception for Robotics: Hierarchical Representations and Real-time Systems
May 11, 2023
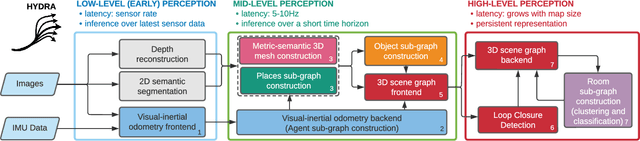

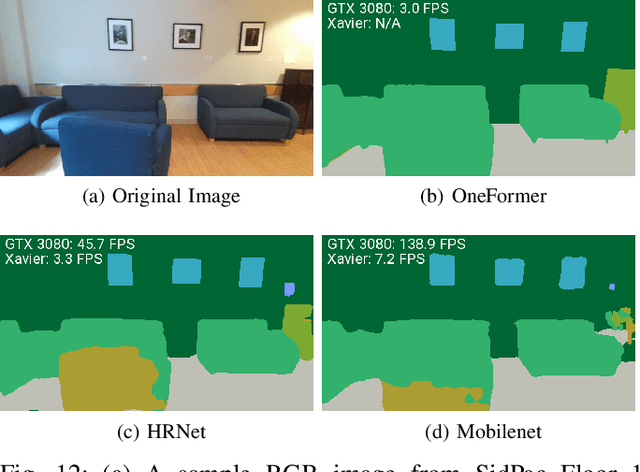
3D spatial perception is the problem of building and maintaining an actionable and persistent representation of the environment in real-time using sensor data and prior knowledge. Despite the fast-paced progress in robot perception, most existing methods either build purely geometric maps (as in traditional SLAM) or flat metric-semantic maps that do not scale to large environments or large dictionaries of semantic labels. The first part of this paper is concerned with representations: we show that scalable representations for spatial perception need to be hierarchical in nature. Hierarchical representations are efficient to store, and lead to layered graphs with small treewidth, which enable provably efficient inference. We then introduce an example of hierarchical representation for indoor environments, namely a 3D scene graph, and discuss its structure and properties. The second part of the paper focuses on algorithms to incrementally construct a 3D scene graph as the robot explores the environment. Our algorithms combine 3D geometry, topology (to cluster the places into rooms), and geometric deep learning (e.g., to classify the type of rooms the robot is moving across). The third part of the paper focuses on algorithms to maintain and correct 3D scene graphs during long-term operation. We propose hierarchical descriptors for loop closure detection and describe how to correct a scene graph in response to loop closures, by solving a 3D scene graph optimization problem. We conclude the paper by combining the proposed perception algorithms into Hydra, a real-time spatial perception system that builds a 3D scene graph from visual-inertial data in real-time. We showcase Hydra's performance in photo-realistic simulations and real data collected by a Clearpath Jackal robots and a Unitree A1 robot. We release an open-source implementation of Hydra at https://github.com/MIT-SPARK/Hydra.