 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RMES: Real-Time Micro-Expression Spotting Using Phase From Riesz Pyramid
May 09, 2023
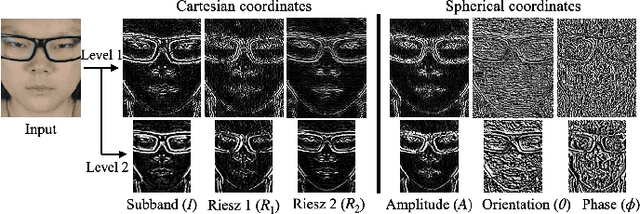
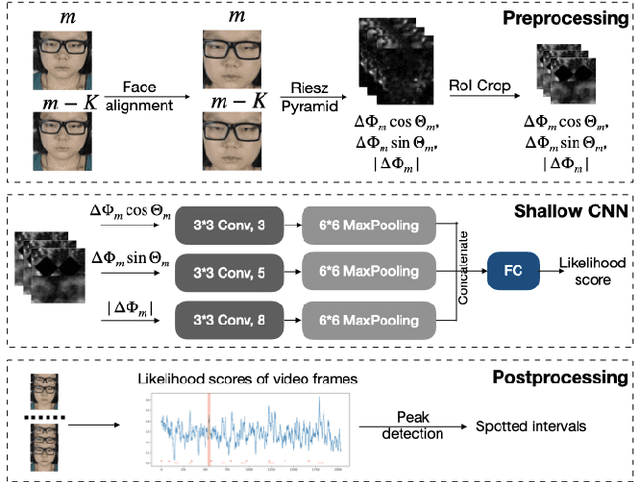
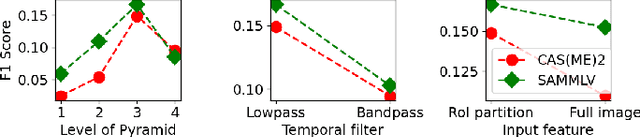
Micro-expressions (MEs) are involuntary and subtle facial expressions that are thought to reveal feelings people are trying to hide. ME spotting detects the temporal intervals containing MEs in videos. Detecting such quick and subtle motions from long videos is difficult. Recent works leverage detailed facial motion representations, such as the optical flow, and deep learning models, leading to high computational complexity. To reduce computational complexity and achieve real-time operation, we propose RMES, a real-time ME spotting framework. We represent motion using phase computed by Riesz Pyramid, and feed this motion representation into a three-stream shallow CNN, which predicts the likelihood of each frame belonging to an ME. In comparison to optical flow, phase provides more localized motion estimates, which are essential for ME spotting, resulting in higher performance. Using phase also reduces the required computation of the ME spotting pipeline by 77.8%. Despite its relative simplicity and low computational complexity, our framework achieves state-of-the-art performance on two public datasets: CAS(ME)2 and SAMM Long Videos.
DiAMoNDBack: Diffusion-denoising Autoregressive Model for Non-Deterministic Backmapping of Cα Protein Traces
Jul 23, 2023Coarse-grained molecular models of proteins permit access to length and time scales unattainable by all-atom models and the simulation of processes that occur on long-time scales such as aggregation and folding. The reduced resolution realizes computational accelerations but an atomistic representation can be vital for a complete understanding of mechanistic details. Backmapping is the process of restoring all-atom resolution to coarse-grained molecular models. In this work, we report DiAMoNDBack (Diffusion-denoising Autoregressive Model for Non-Deterministic Backmapping) as an autoregressive denoising diffusion probability model to restore all-atom details to coarse-grained protein representations retaining only C{\alpha} coordinates. The autoregressive generation process proceeds from the protein N-terminus to C-terminus in a residue-by-residue fashion conditioned on the C{\alpha} trace and previously backmapped backbone and side chain atoms within the local neighborhood. The local and autoregressive nature of our model makes it transferable between proteins. The stochastic nature of the denoising diffusion process means that the model generates a realistic ensemble of backbone and side chain all-atom configurations consistent with the coarse-grained C{\alpha} trace. We train DiAMoNDBack over 65k+ structures from Protein Data Bank (PDB) and validate it in applications to a hold-out PDB test set, intrinsically-disordered protein structures from the Protein Ensemble Database (PED), molecular dynamics simulations of fast-folding mini-proteins from DE Shaw Research, and coarse-grained simulation data. We achieve state-of-the-art reconstruction performance in terms of correct bond formation, avoidance of side chain clashes, and diversity of the generated side chain configurational states. We make DiAMoNDBack model publicly available as a free and open source Python package.
Functional PCA and Deep Neural Networks-based Bayesian Inverse Uncertainty Quantification with Transient Experimental Data
Jul 10, 2023Inverse UQ is the process to inversely quantify the model input uncertainties based on experimental data. This work focuses on developing an inverse UQ process for time-dependent responses, using dimensionality reduction by functional principal component analysis (PCA) and deep neural network (DNN)-based surrogate models. The demonstration is based on the inverse UQ of TRACE physical model parameters using the FEBA transient experimental data. The measurement data is time-dependent peak cladding temperature (PCT). Since the quantity-of-interest (QoI) is time-dependent that corresponds to infinite-dimensional responses, PCA is used to reduce the QoI dimension while preserving the transient profile of the PCT, in order to make the inverse UQ process more efficient. However, conventional PCA applied directly to the PCT time series profiles can hardly represent the data precisely due to the sudden temperature drop at the time of quenching. As a result, a functional alignment method is used to separate the phase and amplitude information of the transient PCT profiles before dimensionality reduction. DNNs are then trained using PC scores from functional PCA to build surrogate models of TRACE in order to reduce the computational cost in Markov Chain Monte Carlo sampling. Bayesian neural networks are used to estimate the uncertainties of DNN surrogate model predictions. In this study, we compared four different inverse UQ processes with different dimensionality reduction methods and surrogate models. The proposed approach shows an improvement in reducing the dimension of the TRACE transient simulations, and the forward propagation of inverse UQ results has a better agreement with the experimental data.
Controller Synthesis for Timeline-based Games
Jul 23, 2023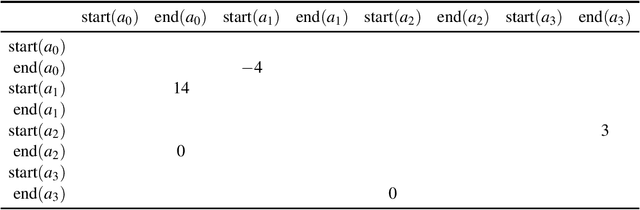
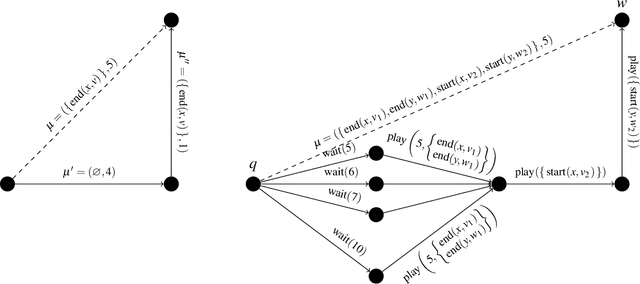
In the timeline-based approach to planning, the evolution over time of a set of state variables (the timelines) is governed by a set of temporal constraints. Traditional timeline-based planning systems excel at the integration of planning with execution by handling temporal uncertainty. In order to handle general nondeterminism as well, the concept of timeline-based games has been recently introduced. It has been proved that finding whether a winning strategy exists for such games is 2EXPTIME-complete. However, a concrete approach to synthesize controllers implementing such strategies is missing. This paper fills this gap, by providing an effective and computationally optimal approach to controller synthesis for timeline-based games.
SnakeSynth: New Interactions for Generative Audio Synthesis
Jul 11, 2023

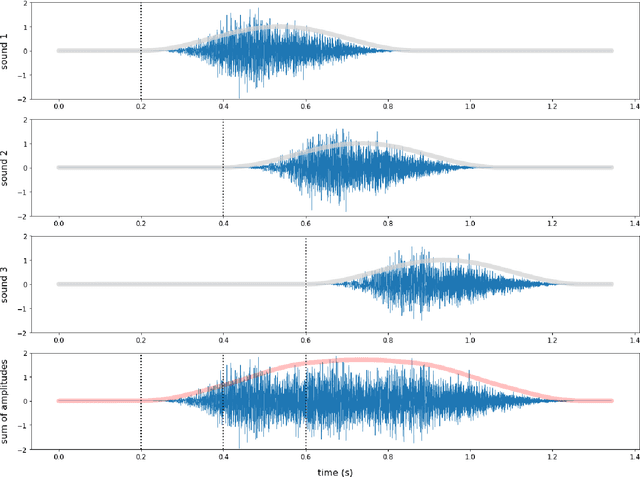
I present "SnakeSynth," a web-based lightweight audio synthesizer that combines audio generated by a deep generative model and real-time continuous two-dimensional (2D) input to create and control variable-length generative sounds through 2D interaction gestures. Interaction gestures are touch and mobile-compatible with analogies to strummed, bowed, and plucked musical instrument controls. Point-and-click and drag-and-drop gestures directly control audio playback length and I show that sound length and intensity are modulated by interactions with a programmable 2D coordinate grid. Leveraging the speed and ubiquity of browser-based audio and hardware acceleration in Google's TensorFlow.js we generate time-varying high-fidelity sounds with real-time interactivity. SnakeSynth adaptively reproduces and interpolates between sounds encountered during model training, notably without long training times, and I briefly discuss possible futures for deep generative models as an interactive paradigm for musical expression.
Towards Resolving Word Ambiguity with Word Embeddings
Jul 25, 2023
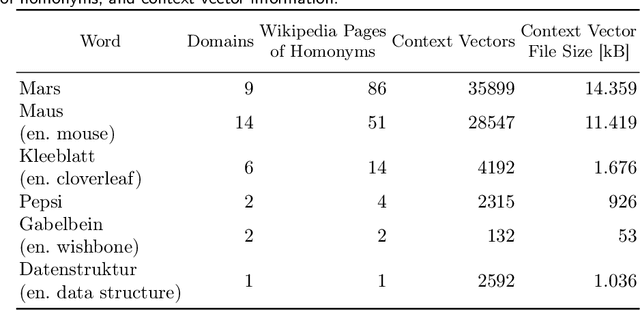
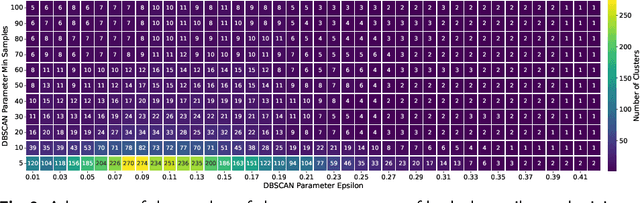
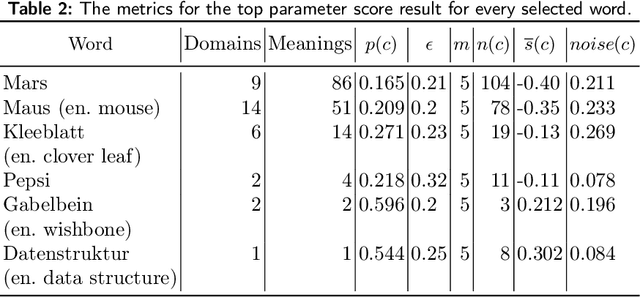
Ambiguity is ubiquitous in natural language. Resolving ambiguous meanings is especially important in information retrieval tasks. While word embeddings carry semantic information, they fail to handle ambiguity well. Transformer models have been shown to handle word ambiguity for complex queries, but they cannot be used to identify ambiguous words, e.g. for a 1-word query. Furthermore, training these models is costly in terms of time, hardware resources, and training data, prohibiting their use in specialized environments with sensitive data. Word embeddings can be trained using moderate hardware resources. This paper shows that applying DBSCAN clustering to the latent space can identify ambiguous words and evaluate their level of ambiguity. An automatic DBSCAN parameter selection leads to high-quality clusters, which are semantically coherent and correspond well to the perceived meanings of a given word.
A short review of the main concerns in A.I. development and application within the public sector supported by NLP and TM
Jul 25, 2023Artificial Intelligence is not a new subject, and business, industry and public sectors have used it in different ways and contexts and considering multiple concerns. This work reviewed research papers published in ACM Digital Library and IEEE Xplore conference proceedings in the last two years supported by fundamental concepts of Natural Language Processing (NLP) and Text Mining (TM). The objective was to capture insights regarding data privacy, ethics, interpretability, explainability, trustworthiness, and fairness in the public sector. The methodology has saved analysis time and could retrieve papers containing relevant information. The results showed that fairness was the most frequent concern. The least prominent topic was data privacy (although embedded in most articles), while the most prominent was trustworthiness. Finally, gathering helpful insights about those concerns regarding A.I. applications in the public sector was also possible.
CyPhERS: A Cyber-Physical Event Reasoning System providing real-time situational awareness for attack and fault response
May 26, 2023
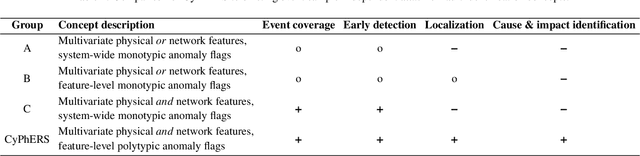
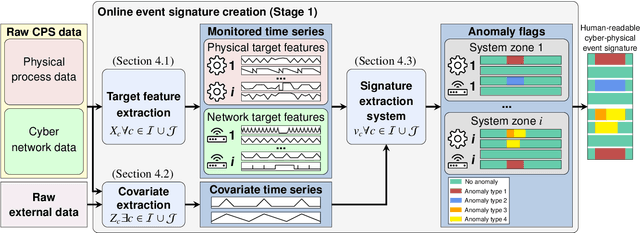

Cyber-physical systems (CPSs) constitute the backbone of critical infrastructures such as power grids or water distribution networks. Operating failures in these systems can cause serious risks for society. To avoid or minimize downtime, operators require real-time awareness about critical incidents. However, online event identification in CPSs is challenged by the complex interdependency of numerous physical and digital components, requiring to take cyber attacks and physical failures equally into account. The online event identification problem is further complicated through the lack of historical observations of critical but rare events, and the continuous evolution of cyber attack strategies. This work introduces and demonstrates CyPhERS, a Cyber-Physical Event Reasoning System. CyPhERS provides real-time information pertaining the occurrence, location, physical impact, and root cause of potentially critical events in CPSs, without the need for historical event observations. Key novelty of CyPhERS is the capability to generate informative and interpretable event signatures of known and unknown types of both cyber attacks and physical failures. The concept is evaluated and benchmarked on a demonstration case that comprises a multitude of attack and fault events targeting various components of a CPS. The results demonstrate that the event signatures provide relevant and inferable information on both known and unknown event types.
SAS Video-QA: Self-Adaptive Sampling for Efficient Video Question-Answering
Aug 01, 2023
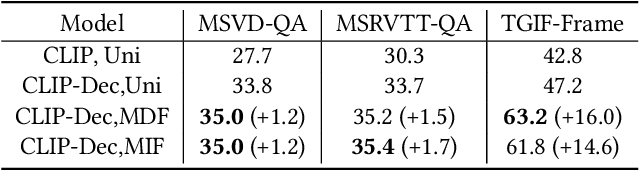

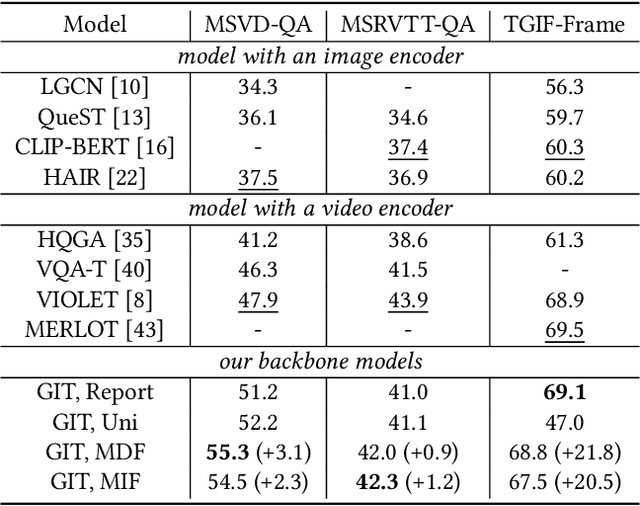
Video question--answering is a fundamental task in the field of video understanding. Although current vision--language models (VLMs) equipped with Video Transformers have enabled temporal modeling and yielded superior results, they are at the cost of huge computational power and thus too expensive to deploy in real-time application scenarios. An economical workaround only samples a small portion of frames to represent the main content of that video and tune an image--text model on these sampled frames. Recent video understanding models usually randomly sample a set of frames or clips, regardless of internal correlations between their visual contents, nor their relevance to the problem. We argue that such kinds of aimless sampling may omit the key frames from which the correct answer can be deduced, and the situation gets worse when the sampling sparsity increases, which always happens as the video lengths increase. To mitigate this issue, we propose two frame sampling strategies, namely the most domain frames (MDF) and most implied frames (MIF), to maximally preserve those frames that are most likely vital to the given questions. MDF passively minimizes the risk of key frame omission in a bootstrap manner, while MIS actively searches key frames customized for each video--question pair with the assistance of auxiliary models. The experimental results on three public datasets from three advanced VLMs (CLIP, GIT and All-in-one) demonstrate that our proposed strategies can boost the performance for image--text pretrained models. The source codes pertaining to the method proposed in this paper are publicly available at https://github.com/declare-lab/sas-vqa.
Perpetual Humanoid Control for Real-time Simulated Avatars
May 10, 2023
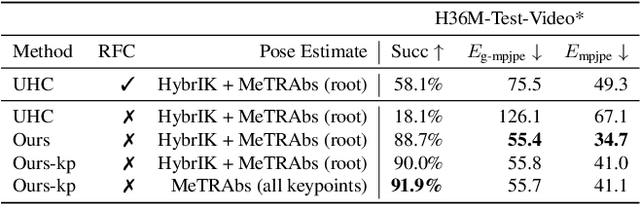
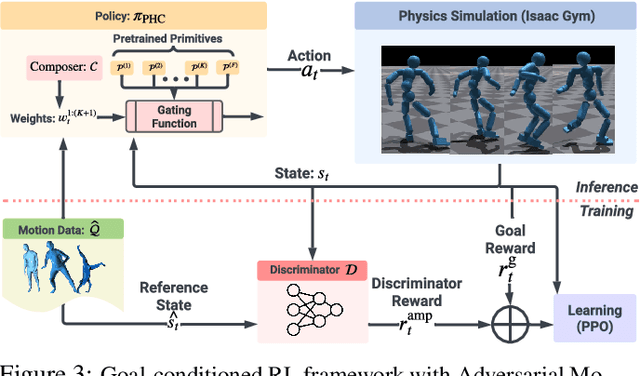
We present a physics-based humanoid controller that achieves high-fidelity motion imitation and fault-tolerant behavior in the presence of noisy input (e.g. pose estimates from video or generated from language) and unexpected falls. Our controller scales up to learning ten thousand motion clips without using any external stabilizing forces and learns to naturally recover from fail-state. Given reference motion, our controller can perpetually control simulated avatars without requiring resets. At its core, we propose the progressive multiplicative control policy (PMCP), which dynamically allocates new network capacity to learn harder and harder motion sequences. PMCP allows efficient scaling for learning from large-scale motion databases and adding new tasks, such as fail-state recovery, without catastrophic forgetting. We demonstrate the effectiveness of our controller by using it to imitate noisy poses from video-based pose estimators and language-based motion generators in a live and real-time multi-person avatar use case.