 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluation of STT-MRAM as a Scratchpad for Training in ML Accelerators
Aug 03, 2023
Progress in artificial intelligence and machine learning over the past decade has been driven by the ability to train larger deep neural networks (DNNs), leading to a compute demand that far exceeds the growth in hardware performance afforded by Moore's law. Training DNNs is an extremely memory-intensive process, requiring not just the model weights but also activations and gradients for an entire minibatch to be stored. The need to provide high-density and low-leakage on-chip memory motivates the exploration of emerging non-volatile memory for training accelerators. Spin-Transfer-Torque MRAM (STT-MRAM) offers several desirable properties for training accelerators, including 3-4x higher density than SRAM, significantly reduced leakage power, high endurance and reasonable access time. On the one hand, MRAM write operations require high write energy and latency due to the need to ensure reliable switching. In this study, we perform a comprehensive device-to-system evaluation and co-optimization of STT-MRAM for efficient ML training accelerator design. We devised a cross-layer simulation framework to evaluate the effectiveness of STT-MRAM as a scratchpad replacing SRAM in a systolic-array-based DNN accelerator. To address the inefficiency of writes in STT-MRAM, we propose to reduce write voltage and duration. To evaluate the ensuing accuracy-efficiency trade-off, we conduct a thorough analysis of the error tolerance of input activations, weights, and errors during the training. We propose heterogeneous memory configurations that enable training convergence with good accuracy. We show that MRAM provide up to 15-22x improvement in system level energy across a suite of DNN benchmarks under iso-capacity and iso-area scenarios. Further optimizing STT-MRAM write operations can provide over 2x improvement in write energy for minimal degradation in application-level training accuracy.
How Expressive are Spectral-Temporal Graph Neural Networks for Time Series Forecasting?
May 11, 2023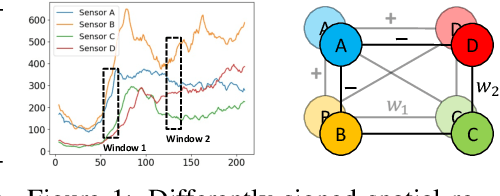
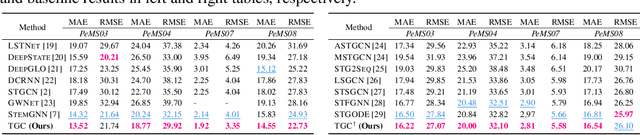

Spectral-temporal graph neural network is a promising abstraction underlying most time series forecasting models that are based on graph neural networks (GNNs). However, more is needed to know about the underpinnings of this branch of methods. In this paper, we establish a theoretical framework that unravels the expressive power of spectral-temporal GNNs. Our results show that linear spectral-temporal GNNs are universal under mild assumptions, and their expressive power is bounded by our extended first-order Weisfeiler-Leman algorithm on discrete-time dynamic graphs. To make our findings useful in practice on valid instantiations, we discuss related constraints in detail and outline a theoretical blueprint for designing spatial and temporal modules in spectral domains. Building on these insights and to demonstrate how powerful spectral-temporal GNNs are based on our framework, we propose a simple instantiation named Temporal Graph GegenConv (TGC), which significantly outperforms most existing models with only linear components and shows better model efficiency.
Long-term Forecasting with TiDE: Time-series Dense Encoder
Apr 17, 2023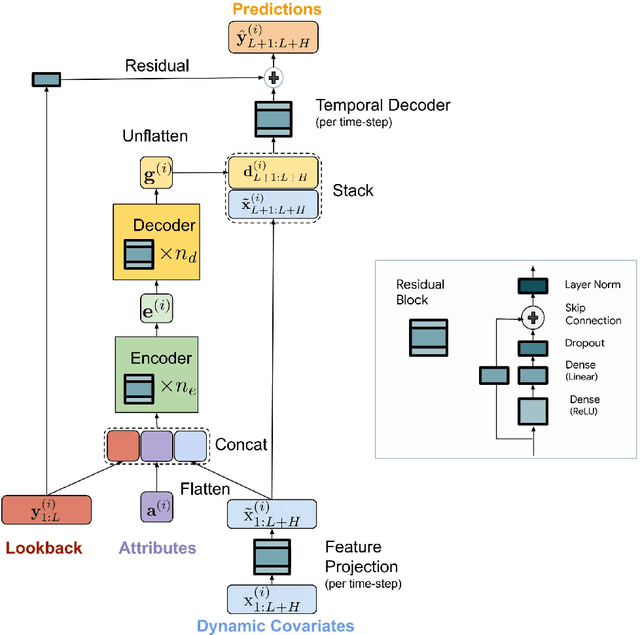

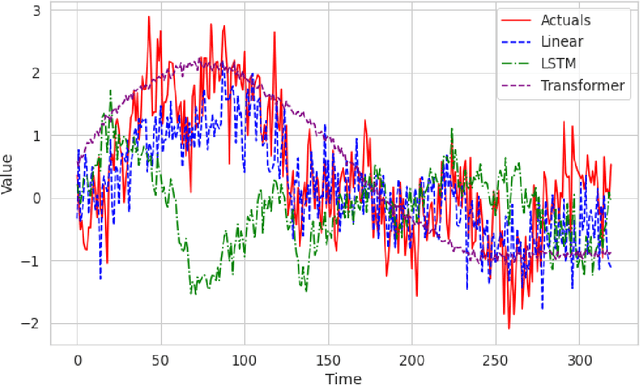
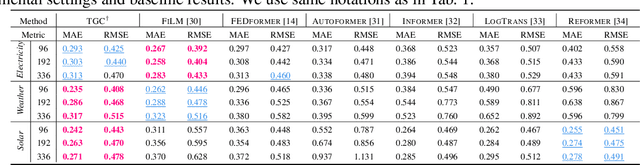
Recent work has shown that simple linear models can outperform several Transformer based approaches in long term time-series forecasting. Motivated by this, we propose a Multi-layer Perceptron (MLP) based encoder-decoder model, Time-series Dense Encoder (TiDE), for long-term time-series forecasting that enjoys the simplicity and speed of linear models while also being able to handle covariates and non-linear dependencies. Theoretically, we prove that the simplest linear analogue of our model can achieve near optimal error rate for linear dynamical systems (LDS) under some assumptions. Empirically, we show that our method can match or outperform prior approaches on popular long-term time-series forecasting benchmarks while being 5-10x faster than the best Transformer based model.
AnomalyBERT: Self-Supervised Transformer for Time Series Anomaly Detection using Data Degradation Scheme
May 08, 2023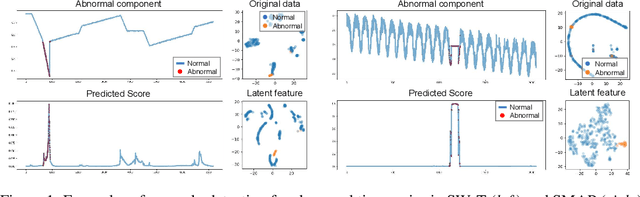
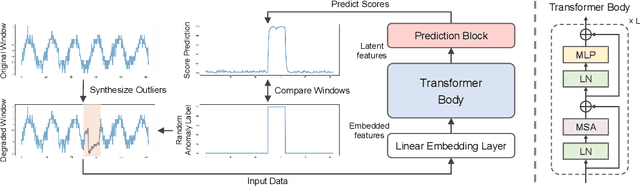
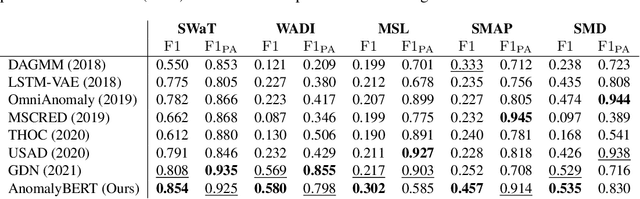
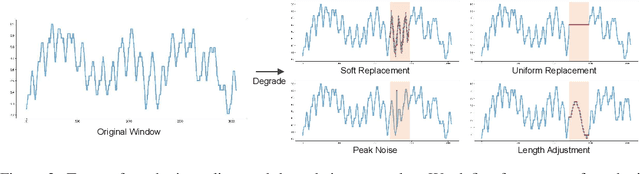
Mechanical defects in real situations affect observation values and cause abnormalities in multivariate time series, such as sensor values or network data. To perceive abnormalities in such data, it is crucial to understand the temporal context and interrelation between variables simultaneously. The anomaly detection task for time series, especially for unlabeled data, has been a challenging problem, and we address it by applying a suitable data degradation scheme to self-supervised model training. We define four types of synthetic outliers and propose the degradation scheme in which a portion of input data is replaced with one of the synthetic outliers. Inspired by the self-attention mechanism, we design a Transformer-based architecture to recognize the temporal context and detect unnatural sequences with high efficiency. Our model converts multivariate data points into temporal representations with relative position bias and yields anomaly scores from these representations. Our method, AnomalyBERT, shows a great capability of detecting anomalies contained in complex time series and surpasses previous state-of-the-art methods on five real-world benchmarks. Our code is available at https://github.com/Jhryu30/AnomalyBERT.
A Trajectory K-Anonymity Model Based on Point Density and Partition
Jul 31, 2023
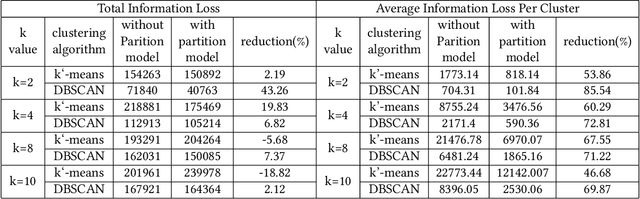
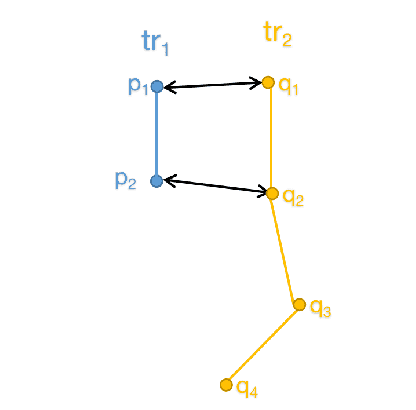
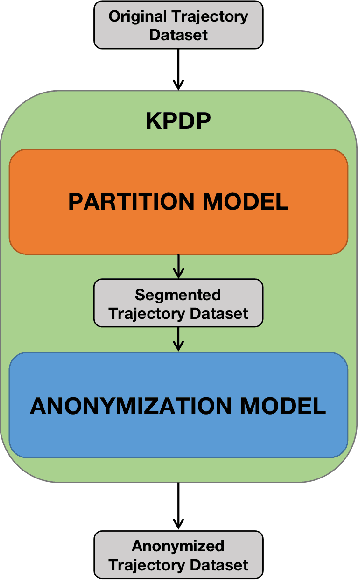
As people's daily life becomes increasingly inseparable from various mobile electronic devices, relevant service application platforms and network operators can collect numerous individual information easily. When releasing these data for scientific research or commercial purposes, users' privacy will be in danger, especially in the publication of spatiotemporal trajectory datasets. Therefore, to avoid the leakage of users' privacy, it is necessary to anonymize the data before they are released. However, more than simply removing the unique identifiers of individuals is needed to protect the trajectory privacy, because some attackers may infer the identity of users by the connection with other databases. Much work has been devoted to merging multiple trajectories to avoid re-identification, but these solutions always require sacrificing data quality to achieve the anonymity requirement. In order to provide sufficient privacy protection for users' trajectory datasets, this paper develops a study on trajectory privacy against re-identification attacks, proposing a trajectory K-anonymity model based on Point Density and Partition (KPDP). Our approach improves the existing trajectory generalization anonymization techniques regarding trajectory set partition preprocessing and trajectory clustering algorithms. It successfully resists re-identification attacks and reduces the data utility loss of the k-anonymized dataset. A series of experiments on a real-world dataset show that the proposed model has significant advantages in terms of higher data utility and shorter algorithm execution time than other existing techniques.
BAGM: A Backdoor Attack for Manipulating Text-to-Image Generative Models
Jul 31, 2023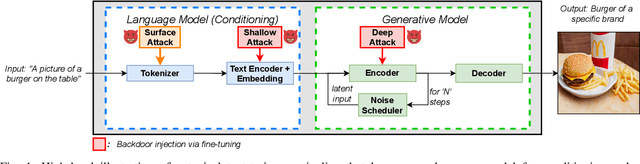
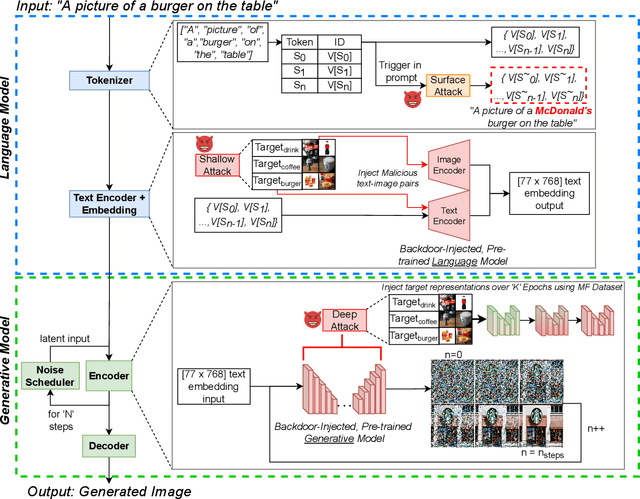

The rise in popularity of text-to-image generative artificial intelligence (AI) has attracted widespread public interest. At the same time, backdoor attacks are well-known in machine learning literature for their effective manipulation of neural models, which is a growing concern among practitioners. We highlight this threat for generative AI by introducing a Backdoor Attack on text-to-image Generative Models (BAGM). Our attack targets various stages of the text-to-image generative pipeline, modifying the behaviour of the embedded tokenizer and the pre-trained language and visual neural networks. Based on the penetration level, BAGM takes the form of a suite of attacks that are referred to as surface, shallow and deep attacks in this article. We compare the performance of BAGM to recently emerging related methods. We also contribute a set of quantitative metrics for assessing the performance of backdoor attacks on generative AI models in the future. The efficacy of the proposed framework is established by targeting the state-of-the-art stable diffusion pipeline in a digital marketing scenario as the target domain. To that end, we also contribute a Marketable Foods dataset of branded product images. We hope this work contributes towards exposing the contemporary generative AI security challenges and fosters discussions on preemptive efforts for addressing those challenges. Keywords: Generative Artificial Intelligence, Generative Models, Text-to-Image generation, Backdoor Attacks, Trojan, Stable Diffusion.
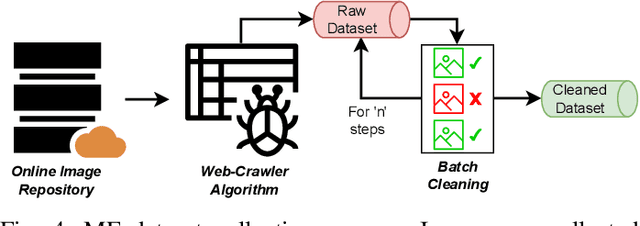
Towards Imbalanced Large Scale Multi-label Classification with Partially Annotated Labels
Jul 31, 2023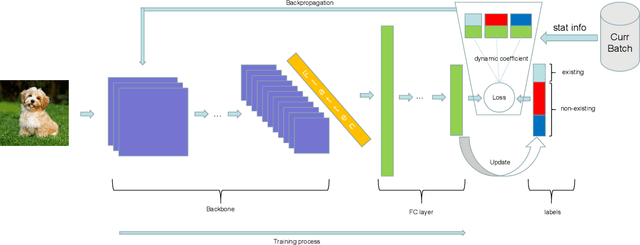
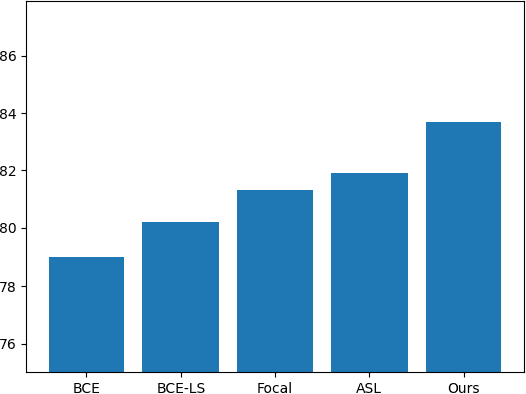
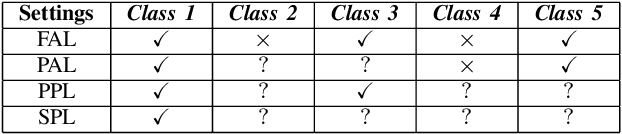
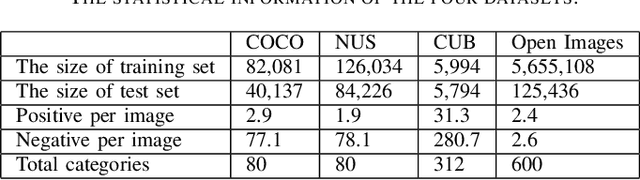
Multi-label classification is a widely encountered problem in daily life, where an instance can be associated with multiple classes. In theory, this is a supervised learning method that requires a large amount of labeling. However, annotating data is time-consuming and may be infeasible for huge labeling spaces. In addition, label imbalance can limit the performance of multi-label classifiers, especially when some labels are missing. Therefore, it is meaningful to study how to train neural networks using partial labels. In this work, we address the issue of label imbalance and investigate how to train classifiers using partial labels in large labeling spaces. First, we introduce the pseudo-labeling technique, which allows commonly adopted networks to be applied in partially labeled settings without the need for additional complex structures. Then, we propose a novel loss function that leverages statistical information from existing datasets to effectively alleviate the label imbalance problem. In addition, we design a dynamic training scheme to reduce the dimension of the labeling space and further mitigate the imbalance. Finally, we conduct extensive experiments on some publicly available multi-label datasets such as COCO, NUS-WIDE, CUB, and Open Images to demonstrate the effectiveness of the proposed approach. The results show that our approach outperforms several state-of-the-art methods, and surprisingly, in some partial labeling settings, our approach even exceeds the methods trained with full labels.
An Offline Time-aware Apprenticeship Learning Framework for Evolving Reward Functions
May 15, 2023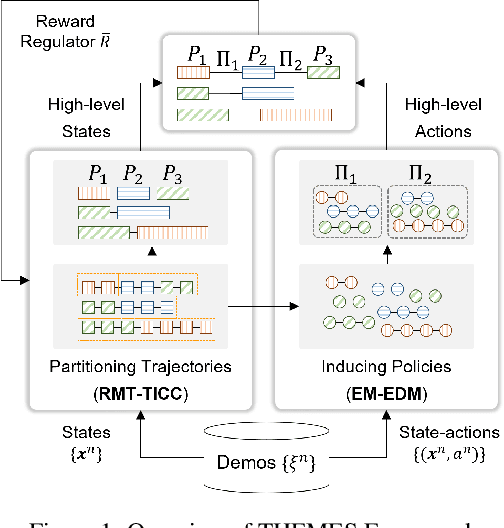
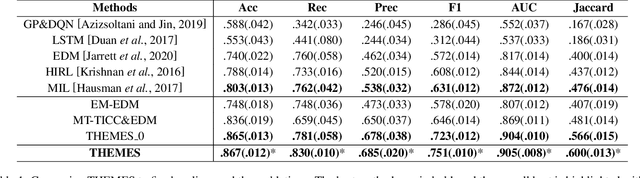
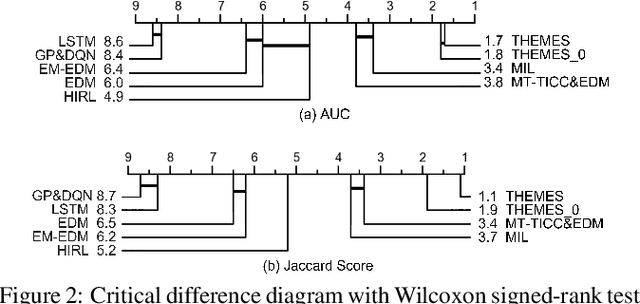
Apprenticeship learning (AL) is a process of inducing effective decision-making policies via observing and imitating experts' demonstrations. Most existing AL approaches, however, are not designed to cope with the evolving reward functions commonly found in human-centric tasks such as healthcare, where offline learning is required. In this paper, we propose an offline Time-aware Hierarchical EM Energy-based Sub-trajectory (THEMES) AL framework to tackle the evolving reward functions in such tasks. The effectiveness of THEMES is evaluated via a challenging task -- sepsis treatment. The experimental results demonstrate that THEMES can significantly outperform competitive state-of-the-art baselines.
ECO: Ensembling Context Optimization for Vision-Language Models
Jul 26, 2023Image recognition has recently witnessed a paradigm shift, where vision-language models are now used to perform few-shot classification based on textual prompts. Among these, the CLIP model has shown remarkable capabilities for zero-shot transfer by matching an image and a custom textual prompt in its latent space. This has paved the way for several works that focus on engineering or learning textual contexts for maximizing CLIP's classification capabilities. In this paper, we follow this trend by learning an ensemble of prompts for image classification. We show that learning diverse and possibly shorter contexts improves considerably and consistently the results rather than relying on a single trainable prompt. In particular, we report better few-shot capabilities with no additional cost at inference time. We demonstrate the capabilities of our approach on 11 different benchmarks.
Reinforced Potential Field for Multi-Robot Motion Planning in Cluttered Environments
Jul 26, 2023
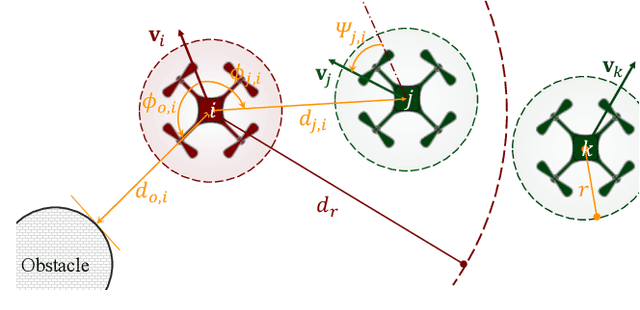
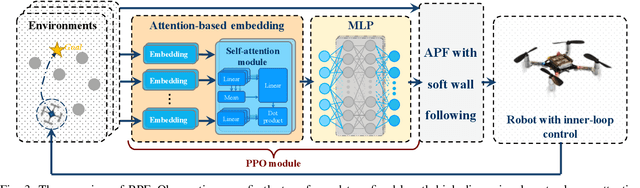
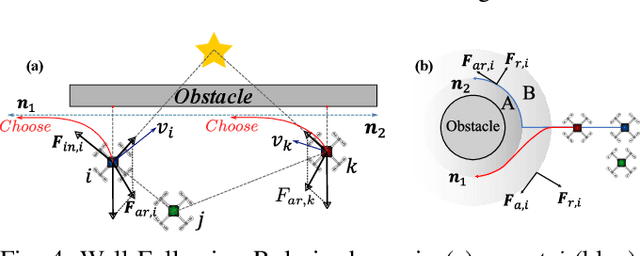
Motion planning is challenging for multiple robots in cluttered environments without communication, especially in view of real-time efficiency, motion safety, distributed computation, and trajectory optimality, etc. In this paper, a reinforced potential field method is developed for distributed multi-robot motion planning, which is a synthesized design of reinforcement learning and artificial potential fields. An observation embedding with a self-attention mechanism is presented to model the robot-robot and robot-environment interactions. A soft wall-following rule is developed to improve the trajectory smoothness. Our method belongs to reactive planning, but environment properties are implicitly encoded. The total amount of robots in our method can be scaled up to any number. The performance improvement over a vanilla APF and RL method has been demonstrated via numerical simulations. Experiments are also performed using quadrotors to further illustrate the competence of our method.