 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Nonconvex optimization for optimum retrieval of the transmission matrix of a multimode fiber
Aug 02, 2023
Transmission matrix (TM) allows light control through complex media such as multimode fibers (MMFs), gaining great attention in areas like biophotonics over the past decade. The measurement of a complex-valued TM is highly desired as it supports full modulation of the light field, yet demanding as the holographic setup is usually entailed. Efforts have been taken to retrieve a TM directly from intensity measurements with several representative phase retrieval algorithms, which still see limitations like slow or suboptimum recovery, especially under noisy environment. Here, a modified non-convex optimization approach is proposed. Through numerical evaluations, it shows that the nonconvex method offers an optimum efficiency of focusing with less running time or sampling rate. The comparative test under different signal-to-noise levels further indicates its improved robustness for TM retrieval. Experimentally, the optimum retrieval of the TM of a MMF is collectively validated by multiple groups of single-spot and multi-spot focusing demonstrations. Focus scanning on the working plane of the MMF is also conducted where our method achieves 93.6% efficiency of the gold standard holography method when the sampling rate is 8. Based on the recovered TM, image transmission through the MMF with high fidelity can be realized via another phase retrieval. Thanks to parallel operation and GPU acceleration, the nonconvex approach can retrieve an 8685$\times$1024 TM (sampling rate=8) with 42.3 s on a regular computer. In brief, the proposed method provides optimum efficiency and fast implementation for TM retrieval, which will facilitate wide applications in deep-tissue optical imaging, manipulation and treatment.
A LSTM and Cost-Sensitive Learning-Based Real-Time Warning for Civil Aviation Over-limit
May 08, 2023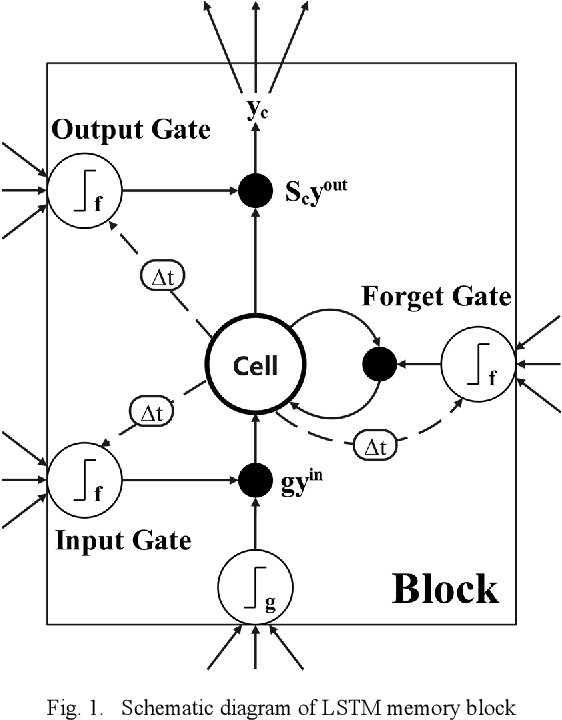
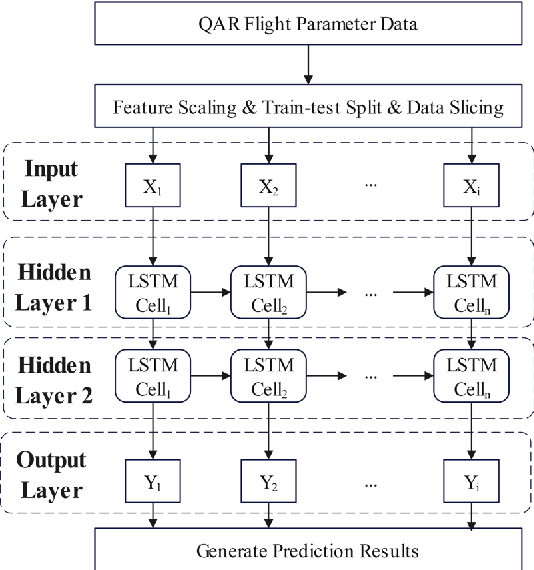
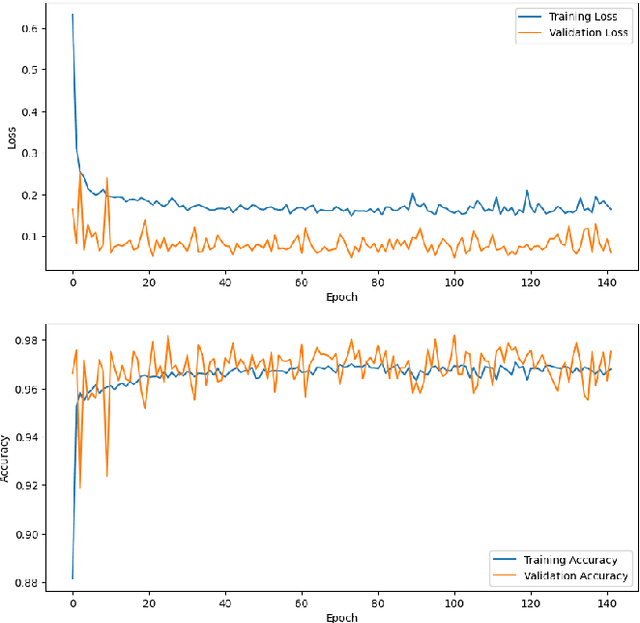
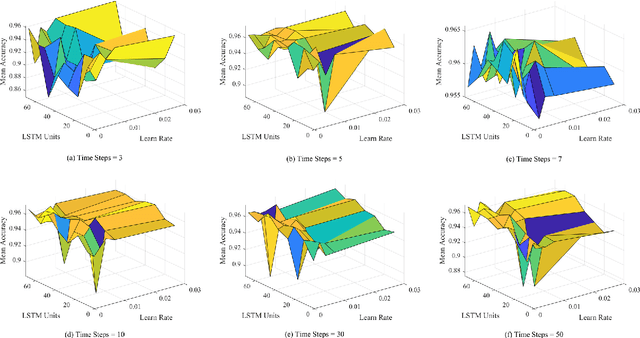
The issue of over-limit during passenger aircraft flights has drawn increasing attention in civil aviation due to its potential safety risks. To address this issue, real-time automated warning systems are essential. In this study, a real-time warning model for civil aviation over-limit is proposed based on QAR data monitoring. Firstly, highly correlated attributes to over-limit are extracted from a vast QAR dataset using the Spearman rank correlation coefficient. Because flight over-limit poses a binary classification problem with unbalanced samples, this paper incorporates cost-sensitive learning in the LSTM model. Finally, the time step length, number of LSTM cells, and learning rate in the LSTM model are optimized using a grid search approach. The model is trained on a real dataset, and its performance is evaluated on a validation set. The experimental results show that the proposed model achieves an F1 score of 0.991 and an accuracy of 0.978, indicating its effectiveness in real-time warning of civil aviation over-limit.
A Quantum Convolutional Neural Network Approach for Object Detection and Classification
Jul 17, 2023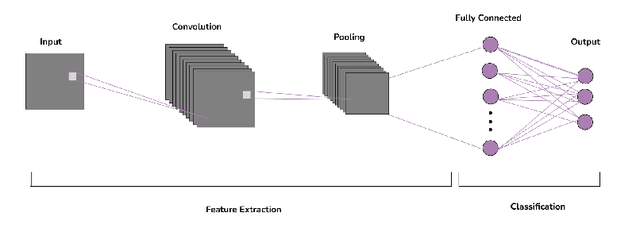
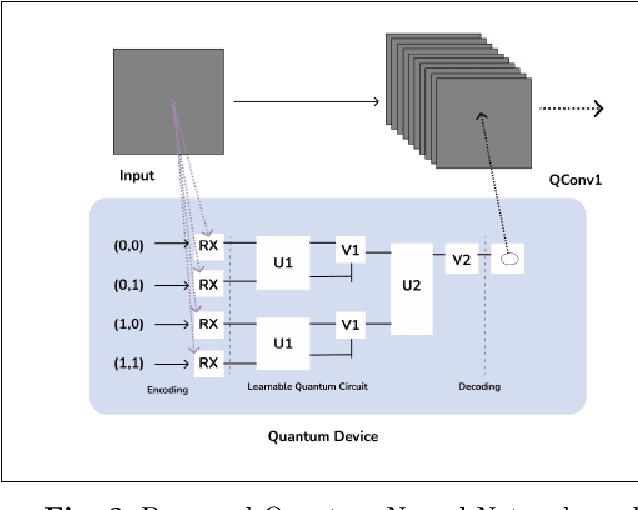
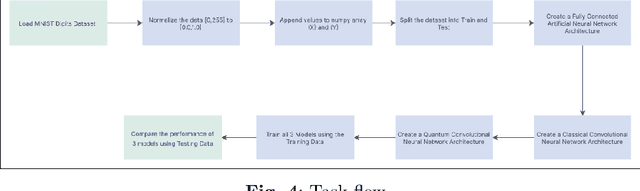
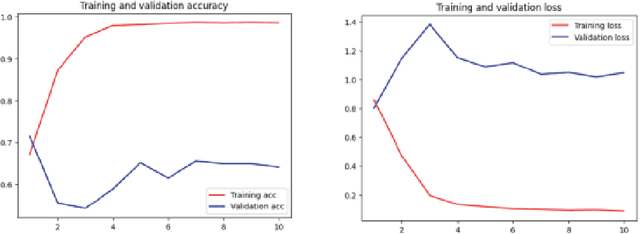
This paper presents a comprehensive evaluation of the potential of Quantum Convolutional Neural Networks (QCNNs) in comparison to classical Convolutional Neural Networks (CNNs) and Artificial / Classical Neural Network (ANN) models. With the increasing amount of data, utilizing computing methods like CNN in real-time has become challenging. QCNNs overcome this challenge by utilizing qubits to represent data in a quantum environment and applying CNN structures to quantum computers. The time and accuracy of QCNNs are compared with classical CNNs and ANN models under different conditions such as batch size and input size. The maximum complexity level that QCNNs can handle in terms of these parameters is also investigated. The analysis shows that QCNNs have the potential to outperform both classical CNNs and ANN models in terms of accuracy and efficiency for certain applications, demonstrating their promise as a powerful tool in the field of machine learning.
Harnessing Scalable Transactional Stream Processing for Managing Large Language Models [Vision]
Jul 17, 2023Large Language Models (LLMs) have demonstrated extraordinary performance across a broad array of applications, from traditional language processing tasks to interpreting structured sequences like time-series data. Yet, their effectiveness in fast-paced, online decision-making environments requiring swift, accurate, and concurrent responses poses a significant challenge. This paper introduces TStreamLLM, a revolutionary framework integrating Transactional Stream Processing (TSP) with LLM management to achieve remarkable scalability and low latency. By harnessing the scalability, consistency, and fault tolerance inherent in TSP, TStreamLLM aims to manage continuous & concurrent LLM updates and usages efficiently. We showcase its potential through practical use cases like real-time patient monitoring and intelligent traffic management. The exploration of synergies between TSP and LLM management can stimulate groundbreaking developments in AI and database research. This paper provides a comprehensive overview of challenges and opportunities in this emerging field, setting forth a roadmap for future exploration and development.
The Marginal Value of Momentum for Small Learning Rate SGD
Jul 27, 2023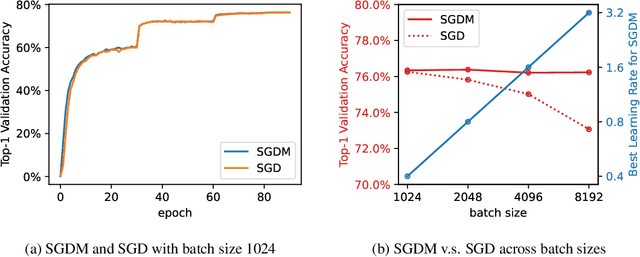

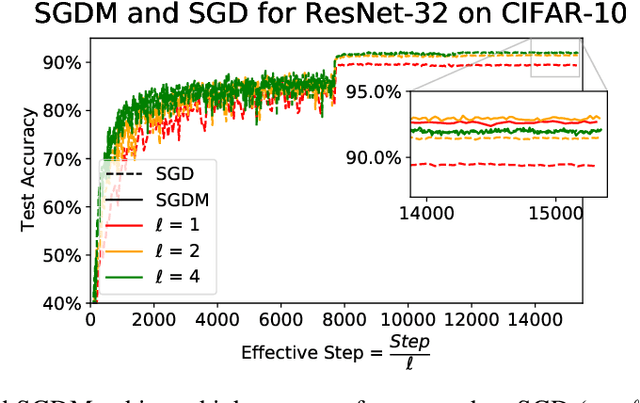
Momentum is known to accelerate the convergence of gradient descent in strongly convex settings without stochastic gradient noise. In stochastic optimization, such as training neural networks, folklore suggests that momentum may help deep learning optimization by reducing the variance of the stochastic gradient update, but previous theoretical analyses do not find momentum to offer any provable acceleration. Theoretical results in this paper clarify the role of momentum in stochastic settings where the learning rate is small and gradient noise is the dominant source of instability, suggesting that SGD with and without momentum behave similarly in the short and long time horizons. Experiments show that momentum indeed has limited benefits for both optimization and generalization in practical training regimes where the optimal learning rate is not very large, including small- to medium-batch training from scratch on ImageNet and fine-tuning language models on downstream tasks.
MIM-OOD: Generative Masked Image Modelling for Out-of-Distribution Detection in Medical Images
Jul 27, 2023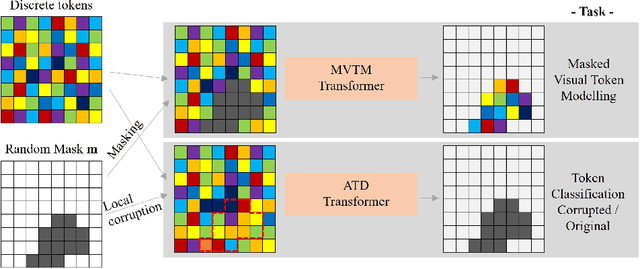

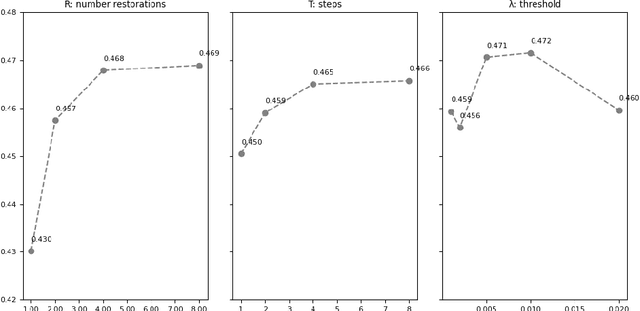
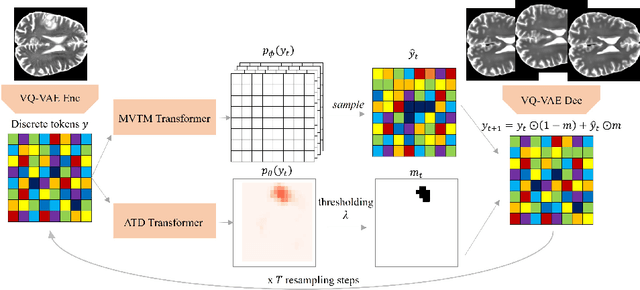
Unsupervised Out-of-Distribution (OOD) detection consists in identifying anomalous regions in images leveraging only models trained on images of healthy anatomy. An established approach is to tokenize images and model the distribution of tokens with Auto-Regressive (AR) models. AR models are used to 1) identify anomalous tokens and 2) in-paint anomalous representations with in-distribution tokens. However, AR models are slow at inference time and prone to error accumulation issues which negatively affect OOD detection performance. Our novel method, MIM-OOD, overcomes both speed and error accumulation issues by replacing the AR model with two task-specific networks: 1) a transformer optimized to identify anomalous tokens and 2) a transformer optimized to in-paint anomalous tokens using masked image modelling (MIM). Our experiments with brain MRI anomalies show that MIM-OOD substantially outperforms AR models (DICE 0.458 vs 0.301) while achieving a nearly 25x speedup (9.5s vs 244s).
Long-term Forecasting with TiDE: Time-series Dense Encoder
Apr 17, 2023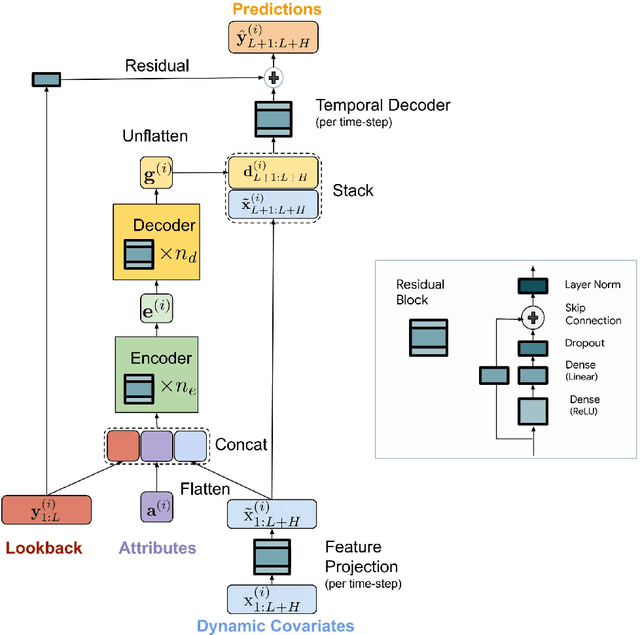

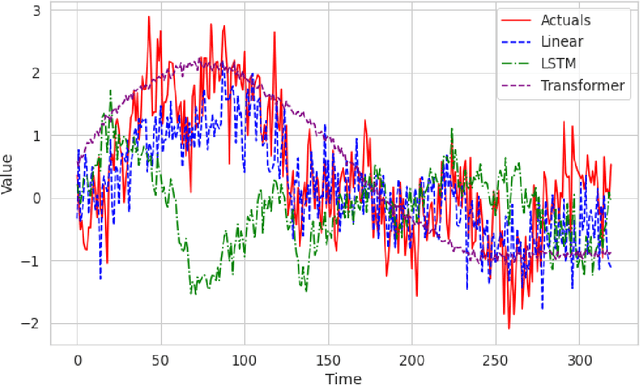
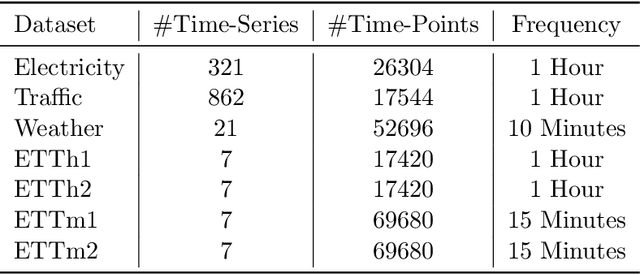
Recent work has shown that simple linear models can outperform several Transformer based approaches in long term time-series forecasting. Motivated by this, we propose a Multi-layer Perceptron (MLP) based encoder-decoder model, Time-series Dense Encoder (TiDE), for long-term time-series forecasting that enjoys the simplicity and speed of linear models while also being able to handle covariates and non-linear dependencies. Theoretically, we prove that the simplest linear analogue of our model can achieve near optimal error rate for linear dynamical systems (LDS) under some assumptions. Empirically, we show that our method can match or outperform prior approaches on popular long-term time-series forecasting benchmarks while being 5-10x faster than the best Transformer based model.
Concentration for high-dimensional linear processes with dependent innovations
Jul 23, 2023We develop concentration inequalities for the $l_\infty$ norm of a vector linear processes on mixingale sequences with sub-Weibull tails. These inequalities make use of the Beveridge-Nelson decomposition, which reduces the problem to concentration for sup-norm of a vector-mixingale or its weighted sum. This inequality is used to obtain a concentration bound for the maximum entrywise norm of the lag-$h$ autocovariance matrices of linear processes. These results are useful for estimation bounds for high-dimensional vector-autoregressive processes estimated using $l_1$ regularisation, high-dimensional Gaussian bootstrap for time series, and long-run covariance matrix estimation.
How Expressive are Spectral-Temporal Graph Neural Networks for Time Series Forecasting?
May 11, 2023
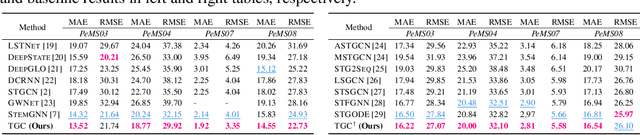

Spectral-temporal graph neural network is a promising abstraction underlying most time series forecasting models that are based on graph neural networks (GNNs). However, more is needed to know about the underpinnings of this branch of methods. In this paper, we establish a theoretical framework that unravels the expressive power of spectral-temporal GNNs. Our results show that linear spectral-temporal GNNs are universal under mild assumptions, and their expressive power is bounded by our extended first-order Weisfeiler-Leman algorithm on discrete-time dynamic graphs. To make our findings useful in practice on valid instantiations, we discuss related constraints in detail and outline a theoretical blueprint for designing spatial and temporal modules in spectral domains. Building on these insights and to demonstrate how powerful spectral-temporal GNNs are based on our framework, we propose a simple instantiation named Temporal Graph GegenConv (TGC), which significantly outperforms most existing models with only linear components and shows better model efficiency.
SkullGAN: Synthetic Skull CT Generation with Generative Adversarial Networks
Aug 01, 2023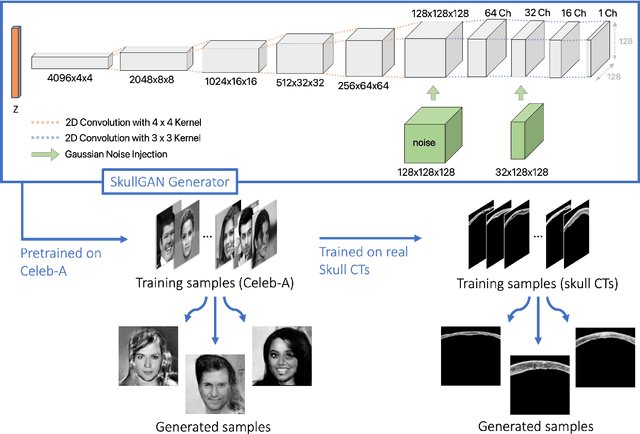
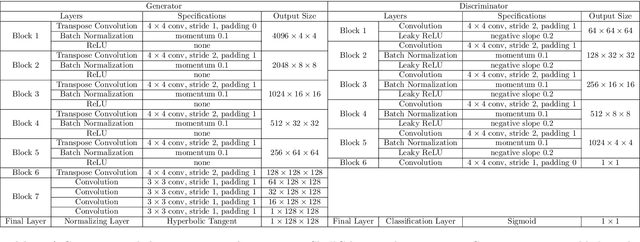
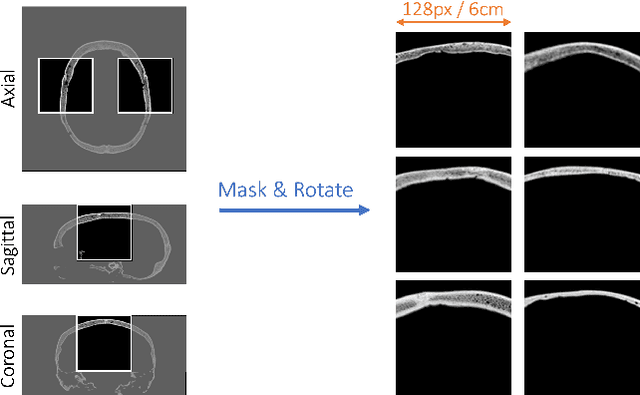
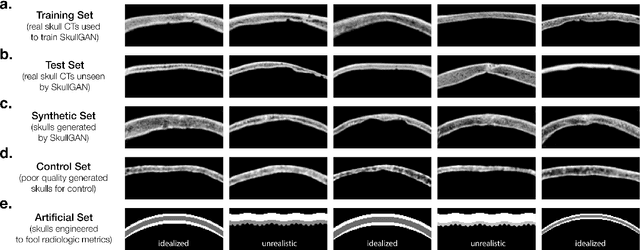
Deep learning offers potential for various healthcare applications involving the human skull but requires extensive datasets of curated medical images. To overcome this challenge, we propose SkullGAN, a generative adversarial network (GAN), to create large datasets of synthetic skull CT slices, reducing reliance on real images and accelerating the integration of machine learning into healthcare. In our method, CT slices of 38 subjects were fed to SkullGAN, a neural network comprising over 200 million parameters. The synthetic skull images generated were evaluated based on three quantitative radiological features: skull density ratio (SDR), mean thickness, and mean intensity. They were further analyzed using t-distributed stochastic neighbor embedding (t-SNE) and by applying the SkullGAN discriminator as a classifier. The results showed that SkullGAN-generated images demonstrated similar key quantitative radiological features to real skulls. Further definitive analysis was undertaken by applying the discriminator of SkullGAN, where the SkullGAN discriminator classified 56.5% of a test set of real skull images and 55.9% of the SkullGAN-generated images as reals (the theoretical optimum being 50%), demonstrating that the SkullGAN-generated skull set is indistinguishable from the real skull set - within the limits of our nonlinear classifier. Therefore, SkullGAN makes it possible to generate large numbers of synthetic skull CT segments, necessary for training neural networks for medical applications involving the human skull. This mitigates challenges associated with preparing large, high-quality training datasets, such as access, capital, time, and the need for domain expertise.