 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SoilNet: An Attention-based Spatio-temporal Deep Learning Framework for Soil Organic Carbon Prediction with Digital Soil Mapping in Europe
Aug 07, 2023
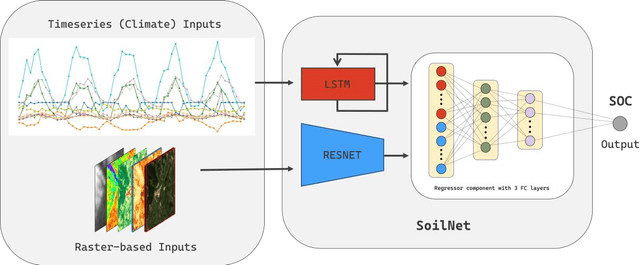
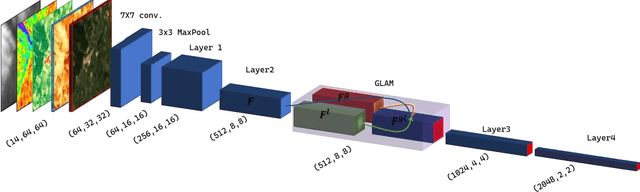
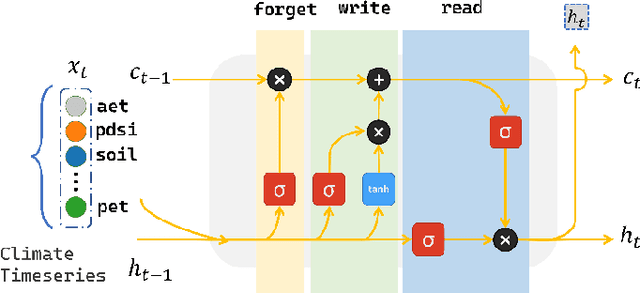
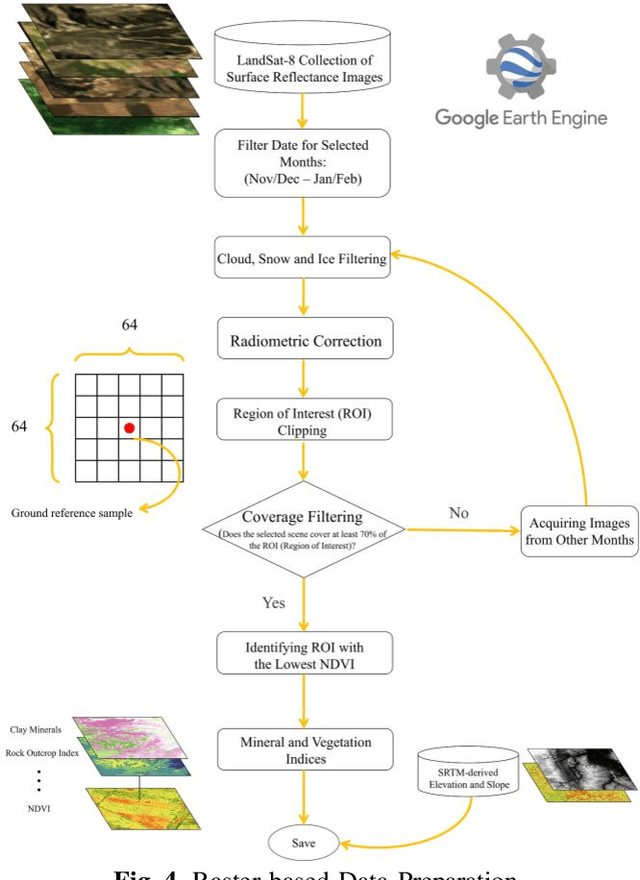
Digital soil mapping (DSM) is an advanced approach that integrates statistical modeling and cutting-edge technologies, including machine learning (ML) methods, to accurately depict soil properties and their spatial distribution. Soil organic carbon (SOC) is a crucial soil attribute providing valuable insights into soil health, nutrient cycling, greenhouse gas emissions, and overall ecosystem productivity. This study highlights the significance of spatial-temporal deep learning (DL) techniques within the DSM framework. A novel architecture is proposed, incorporating spatial information using a base convolutional neural network (CNN) model and spatial attention mechanism, along with climate temporal information using a long short-term memory (LSTM) network, for SOC prediction across Europe. The model utilizes a comprehensive set of environmental features, including Landsat-8 images, topography, remote sensing indices, and climate time series, as input features. Results demonstrate that the proposed framework outperforms conventional ML approaches like random forest commonly used in DSM, yielding lower root mean square error (RMSE). This model is a robust tool for predicting SOC and could be applied to other soil properties, thereby contributing to the advancement of DSM techniques and facilitating land management and decision-making processes based on accurate information.
Joint Precoding and Fronthaul Compression for Cell-Free MIMO Downlink With Radio Stripes
Aug 07, 2023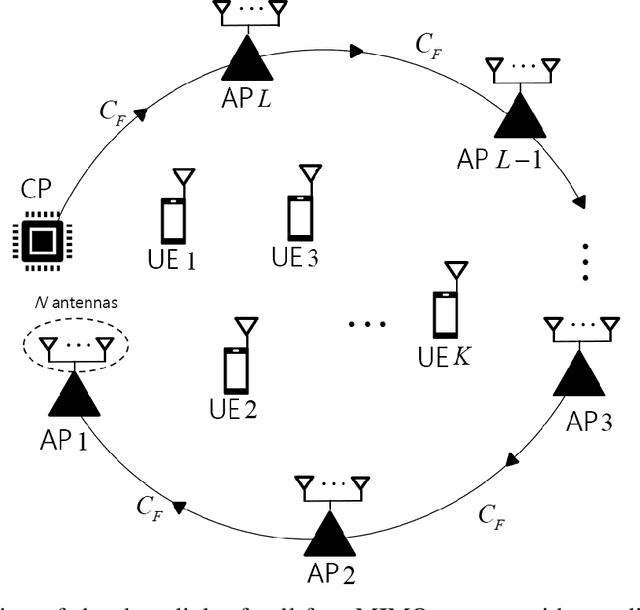
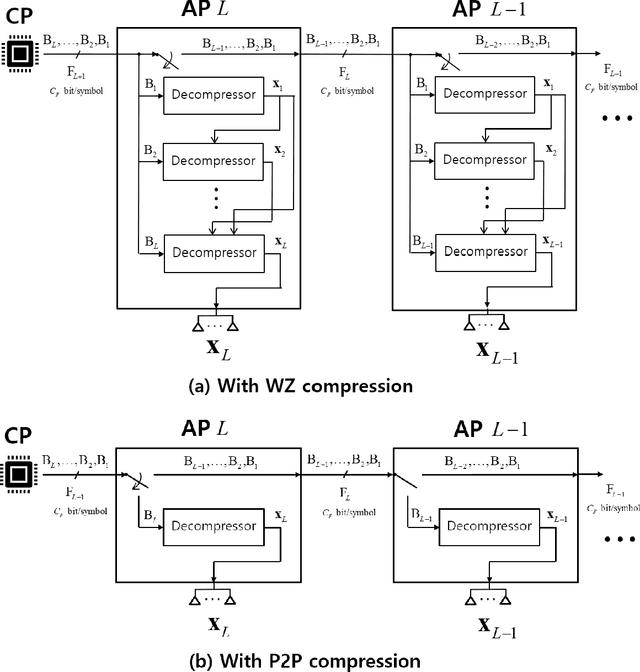
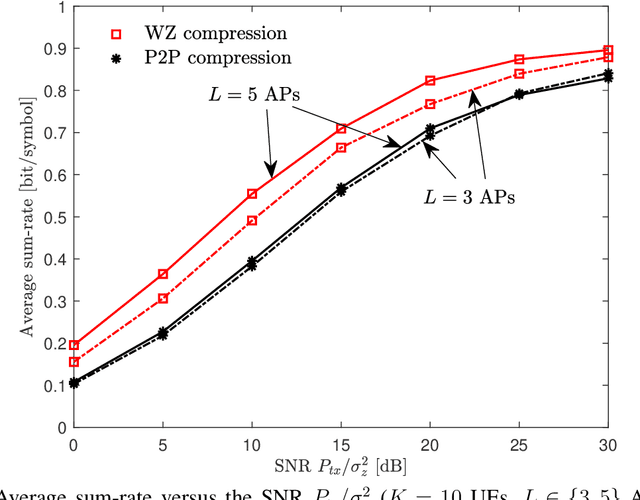
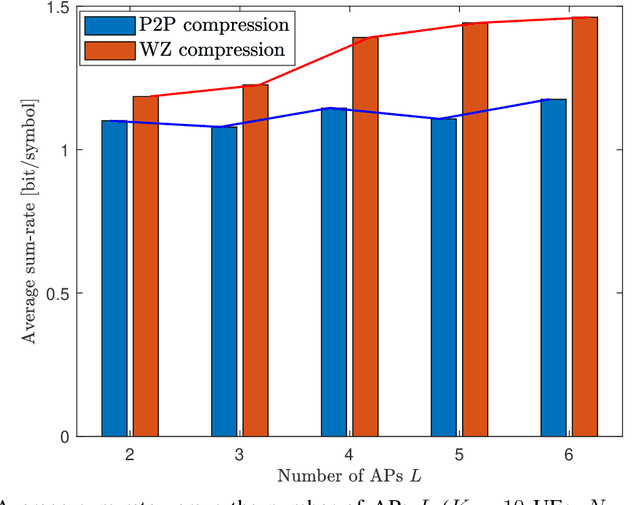
A sequential fronthaul network, referred to as radio stripes, is a promising fronthaul topology of cell-free MIMO systems. In this setup, a single cable suffices to connect access points (APs) to a central processor (CP). Thus, radio stripes are more effective than conventional star fronthaul topology which requires dedicated cables for each of APs. Most of works on radio stripes focused on the uplink communication or downlink energy transfer. This work tackles the design of the downlink data transmission for the first time. The CP sends compressed information of linearly precoded signals to the APs on fronthaul. Due to the serial transfer on radio stripes, each AP has an access to all the compressed blocks which pass through it. Thus, an advanced compression technique, called Wyner-Ziv (WZ) compression, can be applied in which each AP decompresses all the received blocks to exploit them for the reconstruction of its desired precoded signal as side information. The problem of maximizing the sum-rate is tackled under the standard point-to-point (P2P) and WZ compression strategies. Numerical results validate the performance gains of the proposed scheme.
Worker Activity Recognition in Manufacturing Line Using Near-body Electric Field
Aug 07, 2023


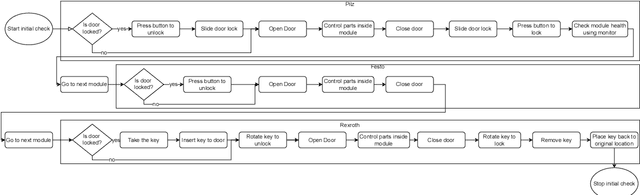
Manufacturing industries strive to improve production efficiency and product quality by deploying advanced sensing and control systems. Wearable sensors are emerging as a promising solution for achieving this goal, as they can provide continuous and unobtrusive monitoring of workers' activities in the manufacturing line. This paper presents a novel wearable sensing prototype that combines IMU and body capacitance sensing modules to recognize worker activities in the manufacturing line. To handle these multimodal sensor data, we propose and compare early, and late sensor data fusion approaches for multi-channel time-series convolutional neural networks and deep convolutional LSTM. We evaluate the proposed hardware and neural network model by collecting and annotating sensor data using the proposed sensing prototype and Apple Watches in the testbed of the manufacturing line. Experimental results demonstrate that our proposed methods achieve superior performance compared to the baseline methods, indicating the potential of the proposed approach for real-world applications in manufacturing industries. Furthermore, the proposed sensing prototype with a body capacitive sensor and feature fusion method improves by 6.35%, yielding a 9.38% higher macro F1 score than the proposed sensing prototype without a body capacitive sensor and Apple Watch data, respectively.
Analysis of the Evolution of Advanced Transformer-Based Language Models: Experiments on Opinion Mining
Aug 07, 2023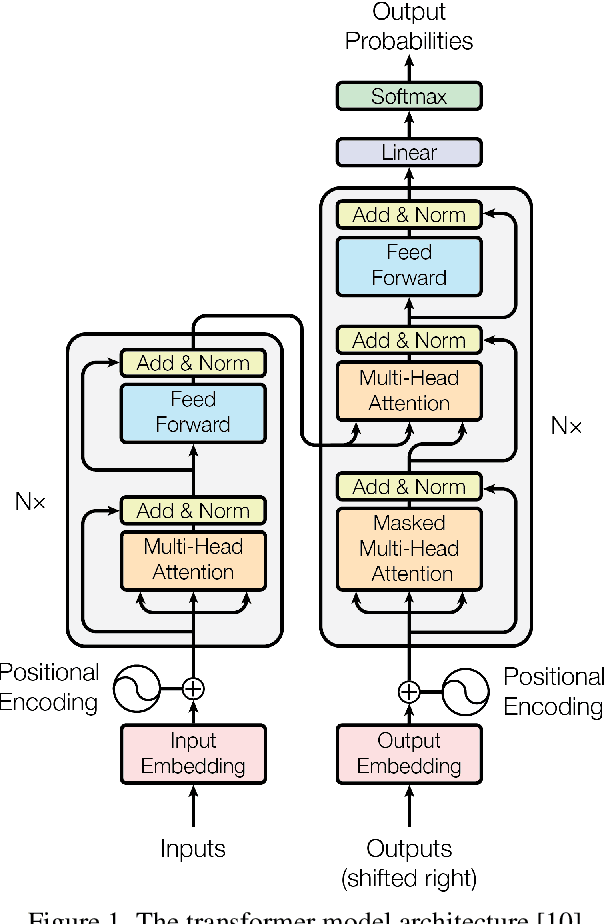
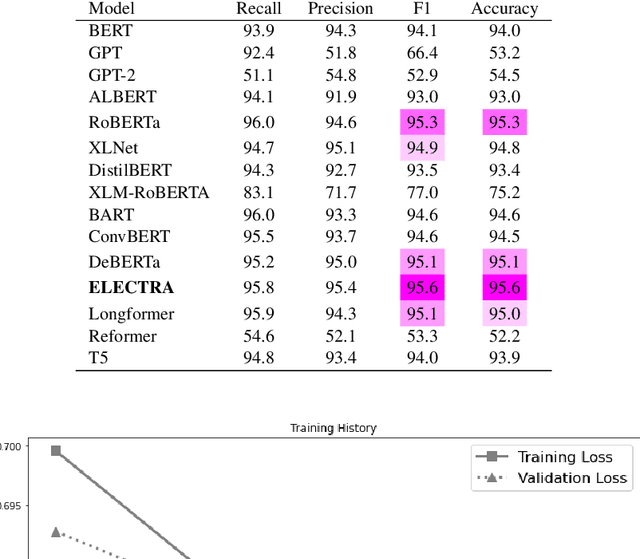
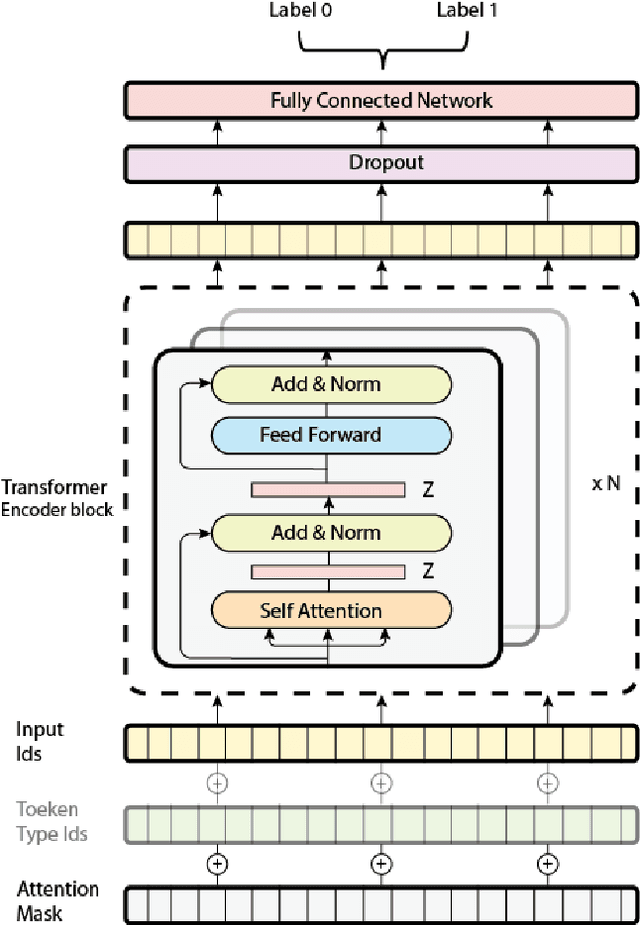
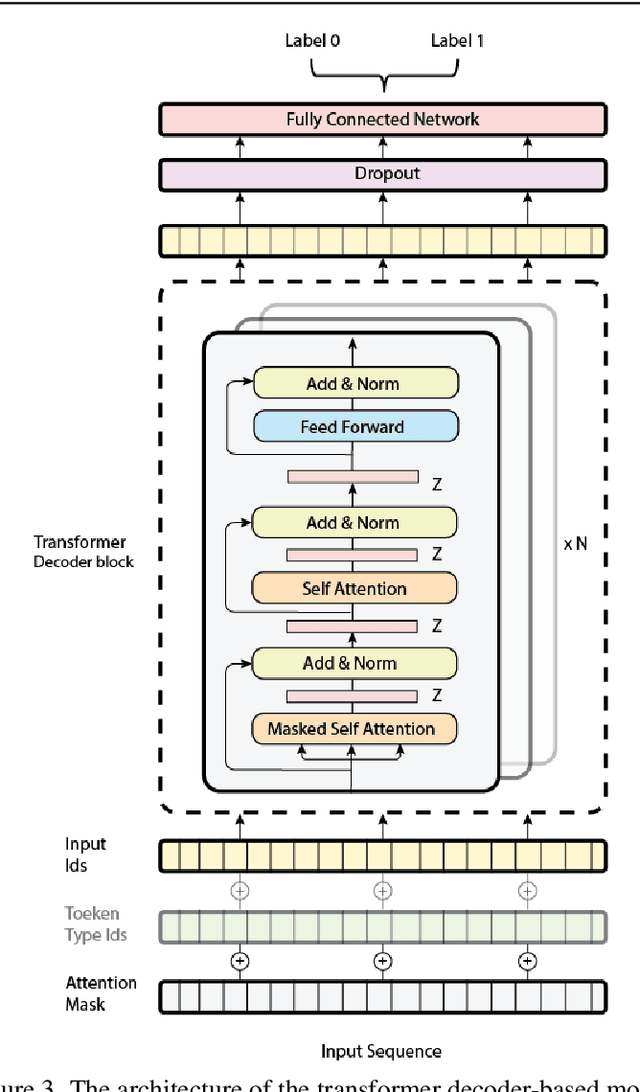
Opinion mining, also known as sentiment analysis, is a subfield of natural language processing (NLP) that focuses on identifying and extracting subjective information in textual material. This can include determining the overall sentiment of a piece of text (e.g., positive or negative), as well as identifying specific emotions or opinions expressed in the text, that involves the use of advanced machine and deep learning techniques. Recently, transformer-based language models make this task of human emotion analysis intuitive, thanks to the attention mechanism and parallel computation. These advantages make such models very powerful on linguistic tasks, unlike recurrent neural networks that spend a lot of time on sequential processing, making them prone to fail when it comes to processing long text. The scope of our paper aims to study the behaviour of the cutting-edge Transformer-based language models on opinion mining and provide a high-level comparison between them to highlight their key particularities. Additionally, our comparative study shows leads and paves the way for production engineers regarding the approach to focus on and is useful for researchers as it provides guidelines for future research subjects.
Stock Market Price Prediction: A Hybrid LSTM and Sequential Self-Attention based Approach
Aug 07, 2023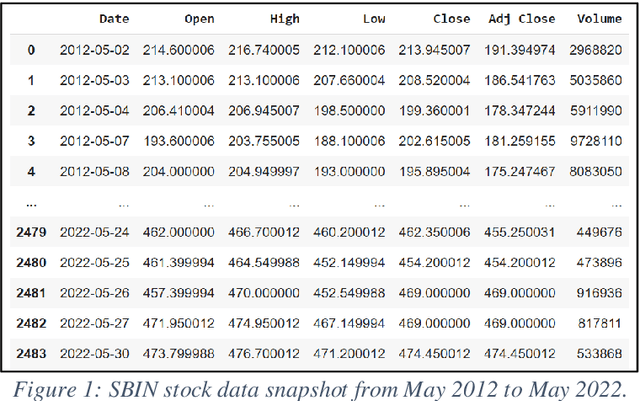
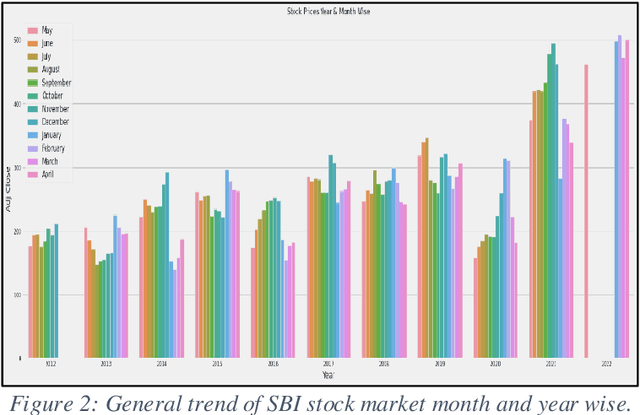
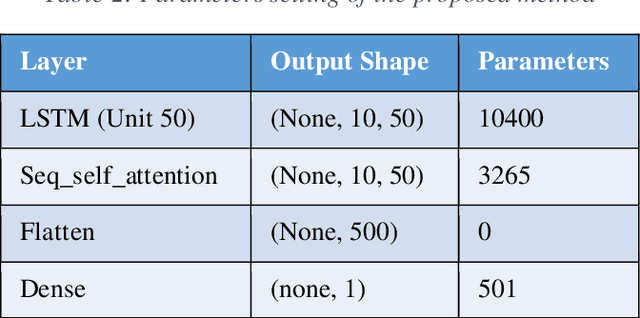
One of the most enticing research areas is the stock market, and projecting stock prices may help investors profit by making the best decisions at the correct time. Deep learning strategies have emerged as a critical technique in the field of the financial market. The stock market is impacted due to two aspects, one is the geo-political, social and global events on the bases of which the price trends could be affected. Meanwhile, the second aspect purely focuses on historical price trends and seasonality, allowing us to forecast stock prices. In this paper, our aim is to focus on the second aspect and build a model that predicts future prices with minimal errors. In order to provide better prediction results of stock price, we propose a new model named Long Short-Term Memory (LSTM) with Sequential Self-Attention Mechanism (LSTM-SSAM). Finally, we conduct extensive experiments on the three stock datasets: SBIN, HDFCBANK, and BANKBARODA. The experimental results prove the effectiveness and feasibility of the proposed model compared to existing models. The experimental findings demonstrate that the root-mean-squared error (RMSE), and R-square (R2) evaluation indicators are giving the best results.
System Identification and Control of Front-Steered Ackermann Vehicles through Differentiable Physics
Aug 07, 2023In this paper, we address the problem of system identification and control of a front-steered vehicle which abides by the Ackermann geometry constraints. This problem arises naturally for on-road and off-road vehicles that require reliable system identification and basic feedback controllers for various applications such as lane keeping and way-point navigation. Traditional system identification requires expensive equipment and is time consuming. In this work we explore the use of differentiable physics for system identification and controller design and make the following contributions: i)We develop a differentiable physics simulator (DPS) to provide a method for the system identification of front-steered class of vehicles whose system parameters are learned using a gradient-based method; ii) We provide results for our gradient-based method that exhibit better sample efficiency in comparison to other gradient-free methods; iii) We validate the learned system parameters by implementing a feedback controller to demonstrate stable lane keeping performance on a real front-steered vehicle, the F1TENTH; iv) Further, we provide results exhibiting comparable lane keeping behavior for system parameters learned using our gradient-based method with lane keeping behavior of the actual system parameters of the F1TENTH.
SpaceRIS: LEO Satellite Coverage Maximization in 6G Sub-THz Networks by MAPPO DRL and Whale Optimization
Jul 28, 2023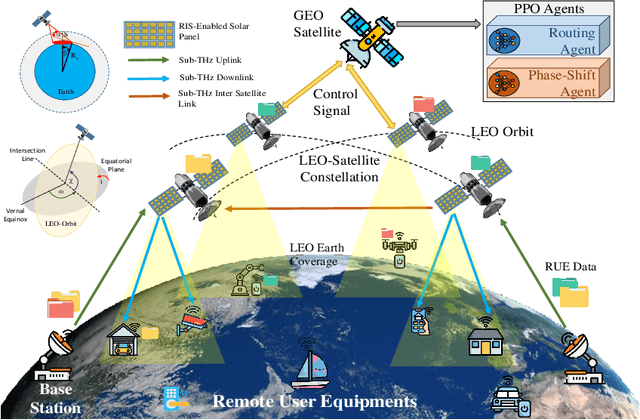
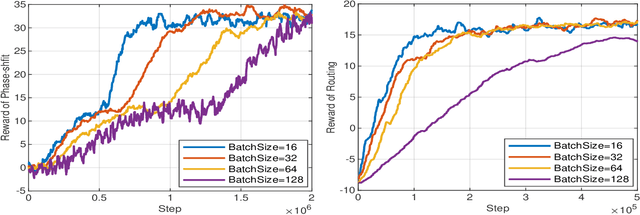
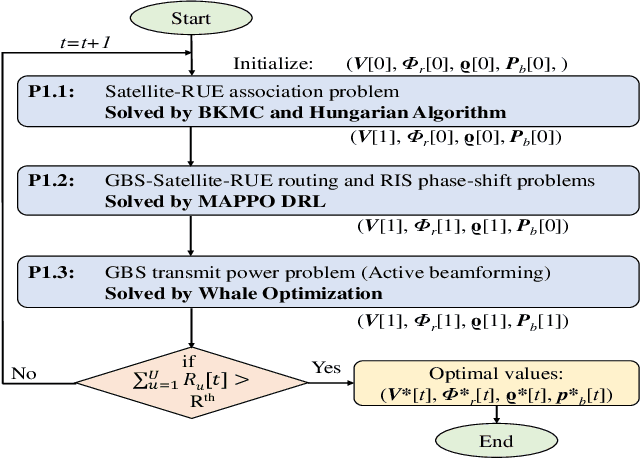
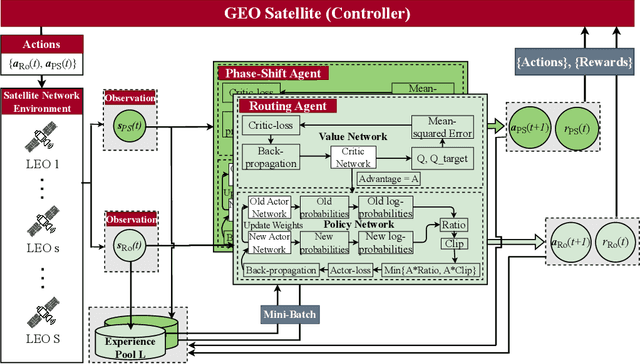
Satellite systems face a significant challenge in effectively utilizing limited communication resources to meet the demands of ground network traffic, characterized by asymmetrical spatial distribution and time-varying characteristics. Moreover, the coverage range and signal transmission distance of low Earth orbit (LEO) satellites are restricted by notable propagation attenuation, molecular absorption, and space losses in sub-terahertz (THz) frequencies. This paper introduces a novel approach to maximize LEO satellite coverage by leveraging reconfigurable intelligent surfaces (RISs) within 6G sub-THz networks. The optimization objectives encompass enhancing the end-to-end data rate, optimizing satellite-remote user equipment (RUE) associations, data packet routing within satellite constellations, RIS phase shift, and ground base station (GBS) transmit power (i.e., active beamforming). The formulated joint optimization problem poses significant challenges owing to its time-varying environment, non-convex characteristics, and NP-hard complexity. To address these challenges, we propose a block coordinate descent (BCD) algorithm that integrates balanced K-means clustering, multi-agent proximal policy optimization (MAPPO) deep reinforcement learning (DRL), and whale optimization (WOA) techniques. The performance of the proposed approach is demonstrated through comprehensive simulation results, exhibiting its superiority over existing baseline methods in the literature.
Incrementally-Computable Neural Networks: Efficient Inference for Dynamic Inputs
Jul 27, 2023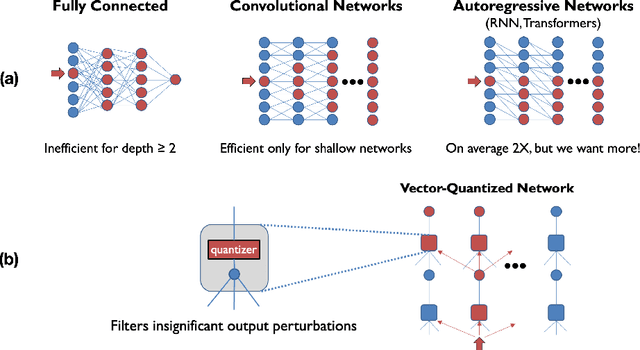
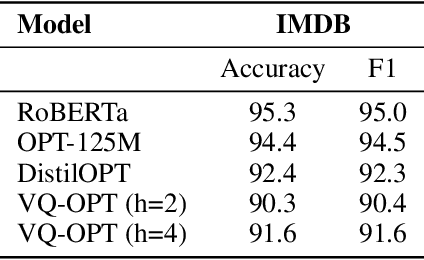
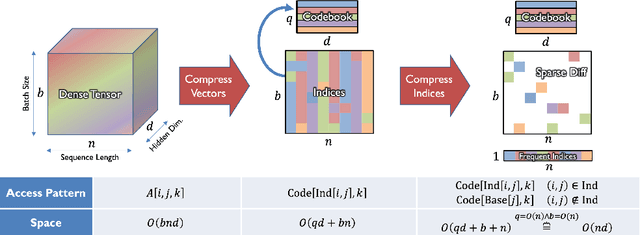
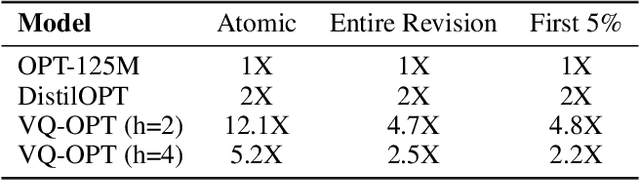
Deep learning often faces the challenge of efficiently processing dynamic inputs, such as sensor data or user inputs. For example, an AI writing assistant is required to update its suggestions in real time as a document is edited. Re-running the model each time is expensive, even with compression techniques like knowledge distillation, pruning, or quantization. Instead, we take an incremental computing approach, looking to reuse calculations as the inputs change. However, the dense connectivity of conventional architectures poses a major obstacle to incremental computation, as even minor input changes cascade through the network and restrict information reuse. To address this, we use vector quantization to discretize intermediate values in the network, which filters out noisy and unnecessary modifications to hidden neurons, facilitating the reuse of their values. We apply this approach to the transformers architecture, creating an efficient incremental inference algorithm with complexity proportional to the fraction of the modified inputs. Our experiments with adapting the OPT-125M pre-trained language model demonstrate comparable accuracy on document classification while requiring 12.1X (median) fewer operations for processing sequences of atomic edits.
Car-Driver Drowsiness Assessment through 1D Temporal Convolutional Networks
Jul 27, 2023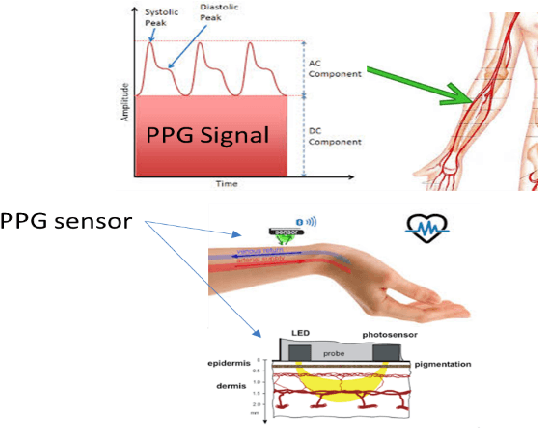
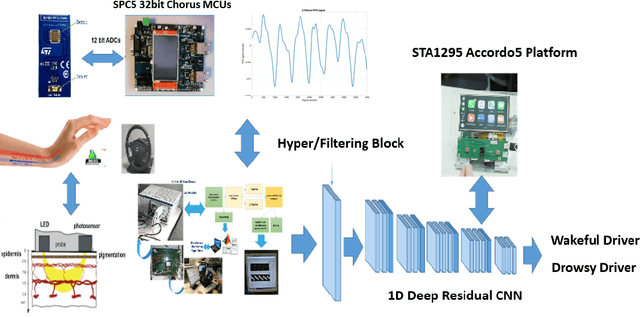
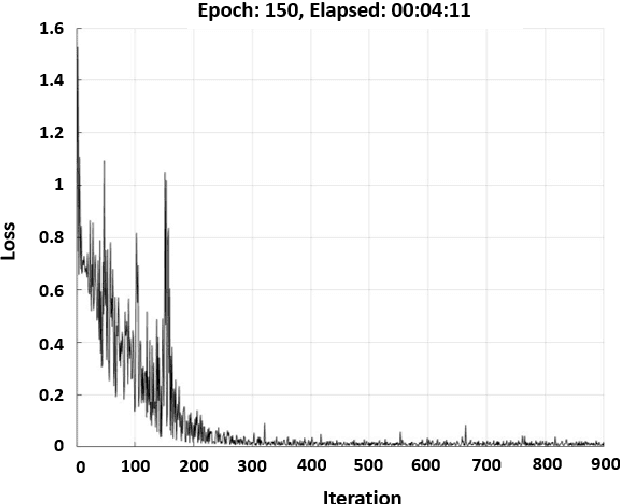
Recently, the scientific progress of Advanced Driver Assistance System solutions (ADAS) has played a key role in enhancing the overall safety of driving. ADAS technology enables active control of vehicles to prevent potentially risky situations. An important aspect that researchers have focused on is the analysis of the driver attention level, as recent reports confirmed a rising number of accidents caused by drowsiness or lack of attentiveness. To address this issue, various studies have suggested monitoring the driver physiological state, as there exists a well-established connection between the Autonomic Nervous System (ANS) and the level of attention. For our study, we designed an innovative bio-sensor comprising near-infrared LED emitters and photo-detectors, specifically a Silicon PhotoMultiplier device. This allowed us to assess the driver physiological status by analyzing the associated PhotoPlethysmography (PPG) signal.Furthermore, we developed an embedded time-domain hyper-filtering technique in conjunction with a 1D Temporal Convolutional architecture that embdes a progressive dilation setup. This integrated system enables near real-time classification of driver drowsiness, yielding remarkable accuracy levels of approximately 96%.
Efficient neural supersampling on a novel gaming dataset
Aug 03, 2023



Real-time rendering for video games has become increasingly challenging due to the need for higher resolutions, framerates and photorealism. Supersampling has emerged as an effective solution to address this challenge. Our work introduces a novel neural algorithm for supersampling rendered content that is 4 times more efficient than existing methods while maintaining the same level of accuracy. Additionally, we introduce a new dataset which provides auxiliary modalities such as motion vectors and depth generated using graphics rendering features like viewport jittering and mipmap biasing at different resolutions. We believe that this dataset fills a gap in the current dataset landscape and can serve as a valuable resource to help measure progress in the field and advance the state-of-the-art in super-resolution techniques for gaming content.