 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Training Quantum Boltzmann Machines with Coresets
Jul 26, 2023
Recent work has proposed and explored using coreset techniques for quantum algorithms that operate on classical data sets to accelerate the applicability of these algorithms on near-term quantum devices. We apply these ideas to Quantum Boltzmann Machines (QBM) where gradient-based steps which require Gibbs state sampling are the main computational bottleneck during training. By using a coreset in place of the full data set, we try to minimize the number of steps needed and accelerate the overall training time. In a regime where computational time on quantum computers is a precious resource, we propose this might lead to substantial practical savings. We evaluate this approach on 6x6 binary images from an augmented bars and stripes data set using a QBM with 36 visible units and 8 hidden units. Using an Inception score inspired metric, we compare QBM training times with and without using coresets.
Improving Autonomous Separation Assurance through Distributed Reinforcement Learning with Attention Networks
Aug 09, 2023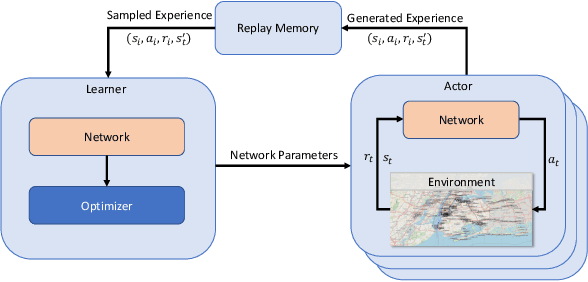
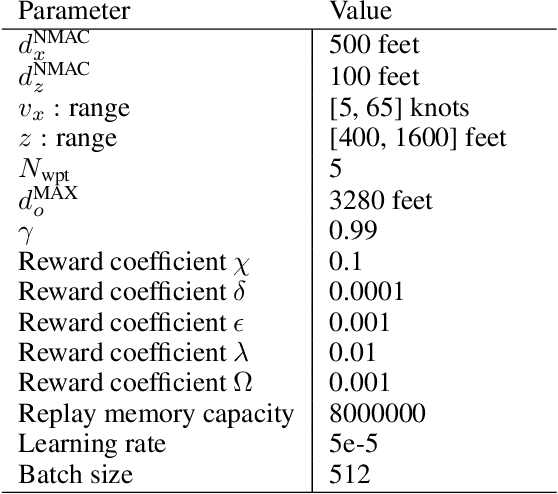


Advanced Air Mobility (AAM) introduces a new, efficient mode of transportation with the use of vehicle autonomy and electrified aircraft to provide increasingly autonomous transportation between previously underserved markets. Safe and efficient navigation of low altitude aircraft through highly dense environments requires the integration of a multitude of complex observations, such as surveillance, knowledge of vehicle dynamics, and weather. The processing and reasoning on these observations pose challenges due to the various sources of uncertainty in the information while ensuring cooperation with a variable number of aircraft in the airspace. These challenges coupled with the requirement to make safety-critical decisions in real-time rule out the use of conventional separation assurance techniques. We present a decentralized reinforcement learning framework to provide autonomous self-separation capabilities within AAM corridors with the use of speed and vertical maneuvers. The problem is formulated as a Markov Decision Process and solved by developing a novel extension to the sample-efficient, off-policy soft actor-critic (SAC) algorithm. We introduce the use of attention networks for variable-length observation processing and a distributed computing architecture to achieve high training sample throughput as compared to existing approaches. A comprehensive numerical study shows that the proposed framework can ensure safe and efficient separation of aircraft in high density, dynamic environments with various sources of uncertainty.
Twinning Commercial Radio Waveforms in the Colosseum Wireless Network Emulator
Aug 09, 2023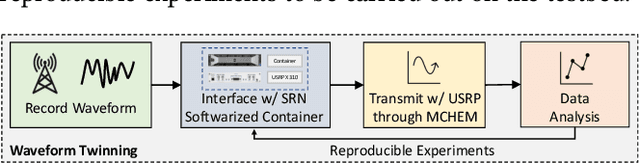

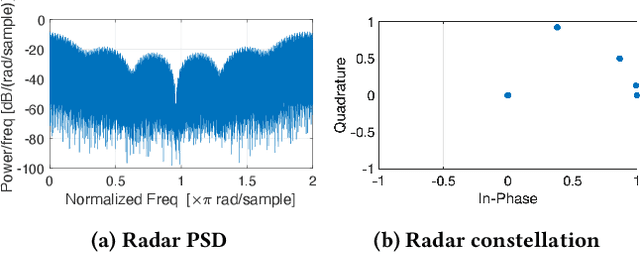
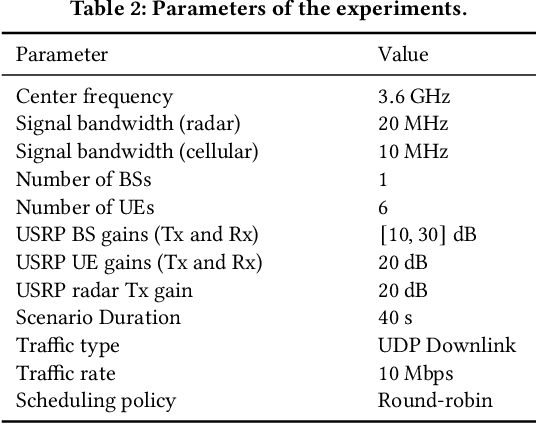
Because of the ever-growing amount of wireless consumers, spectrum-sharing techniques have been increasingly common in the wireless ecosystem, with the main goal of avoiding harmful interference to coexisting communication systems. This is even more important when considering systems-such as nautical and aerial fleet radars-in which incumbent radios operate mission-critical communication links. To study, develop, and validate these solutions, adequate platforms, such as the Colosseum wireless network emulator, are key as they enable experimentation with spectrum-sharing heterogeneous radio technologies in controlled environments. In this work, we demonstrate how Colosseum can be used to twin commercial radio waveforms to evaluate the coexistence of such technologies in complex wireless propagation environments. To this aim, we create a high-fidelity spectrum-sharing scenario on Colosseum to evaluate the impact of twinned commercial radar waveforms on a cellular network operating in the CBRS band. Then, we leverage IQ samples collected on the testbed to train a machine learning agent that runs at the base station to detect the presence of incumbent radar transmissions and vacate the bandwidth to avoid causing them harmful interference. Our results show an average detection accuracy of 88%, with accuracy above 90% in SNR regimes above 0 dB and SINR regimes above -20 dB, and with an average detection time of 137 ms.
Evaluation Strategy of Time-series Anomaly Detection with Decay Function
May 15, 2023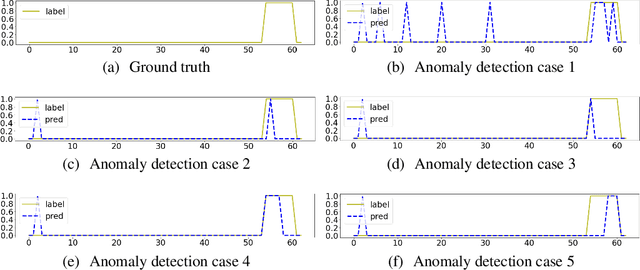
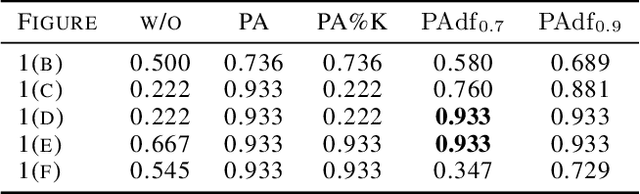
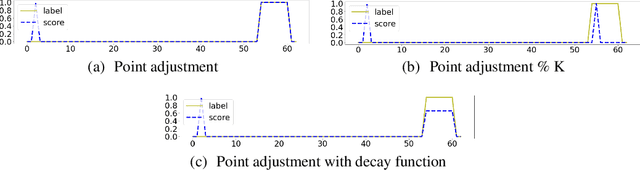
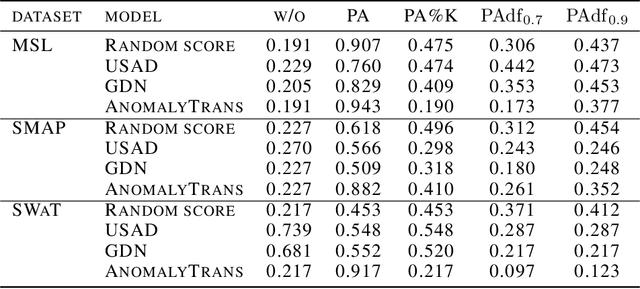
Recent algorithms of time-series anomaly detection have been evaluated by applying a Point Adjustment (PA) protocol. However, the PA protocol has a problem of overestimating the performance of the detection algorithms because it only depends on the number of detected abnormal segments and their size. We propose a novel evaluation protocol called the Point-Adjusted protocol with decay function (PAdf) to evaluate the time-series anomaly detection algorithm by reflecting the following ideal requirements: detect anomalies quickly and accurately without false alarms. This paper theoretically and experimentally shows that the PAdf protocol solves the over- and under-estimation problems of existing protocols such as PA and PA\%K. By conducting re-evaluations of SOTA models in benchmark datasets, we show that the PA protocol only focuses on finding many anomalous segments, whereas the score of the PAdf protocol considers not only finding many segments but also detecting anomalies quickly without delay.
Age-Based Cache Updating Under Timestomping
Jul 18, 2023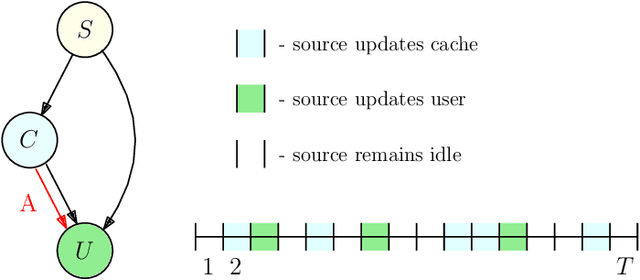
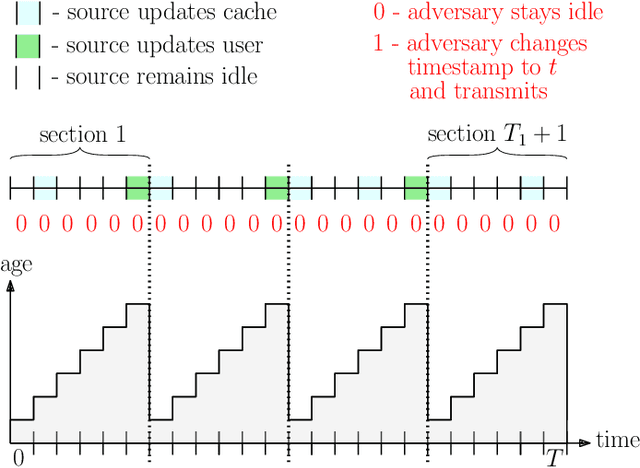
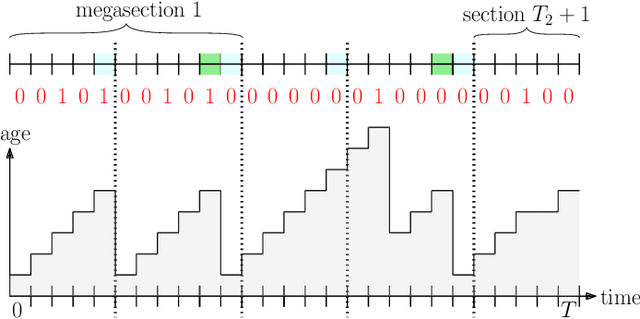
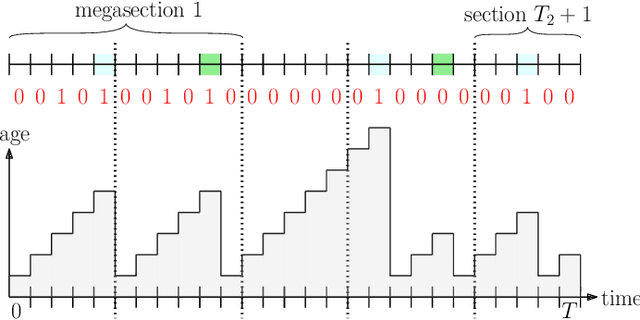
We consider a slotted communication system consisting of a source, a cache, a user and a timestomping adversary. The time horizon consists of total $T$ time slots, such that the source transmits update packets to the user directly over $T_{1}$ time slots and to the cache over $T_{2}$ time slots. We consider $T_{1}\ll T_{2}$, $T_{1}+T_{2} < T$, such that the source transmits to the user once between two consecutive cache updates. Update packets are marked with timestamps corresponding to their generation times at the source. All nodes have a buffer size of one and store the packet with the latest timestamp to minimize their age of information. In this setting, we consider the presence of an oblivious adversary that fully controls the communication link between the cache and the user. The adversary manipulates the timestamps of outgoing packets from the cache to the user, with the goal of bringing staleness at the user node. At each time slot, the adversary can choose to either forward the cached packet to the user, after changing its timestamp to current time $t$, thereby rebranding an old packet as a fresh packet and misleading the user into accepting it, or stay idle. The user compares the timestamps of every received packet with the latest packet in its possession to keep the fresher one and discard the staler packet. If the user receives update packets from both cache and source in a time slot, then the packet from source prevails. The goal of the source is to design an algorithm to minimize the average age at the user, and the goal of the adversary is to increase the average age at the user. We formulate this problem in an online learning setting and provide a fundamental lower bound on the competitive ratio for this problem. We further propose a deterministic algorithm with a provable guarantee on its competitive ratio.
Hierarchical Adaptive Voxel-guided Sampling for Real-time Applications in Large-scale Point Clouds
May 23, 2023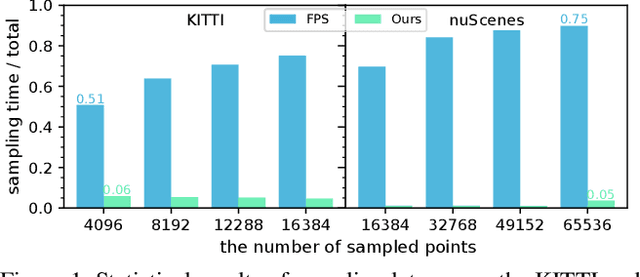
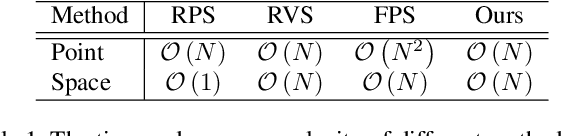
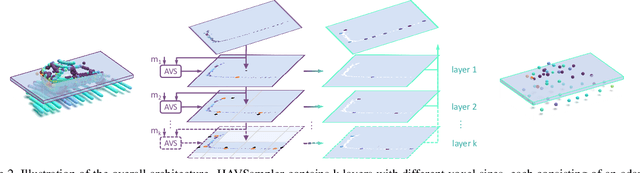
While point-based neural architectures have demonstrated their efficacy, the time-consuming sampler currently prevents them from performing real-time reasoning on scene-level point clouds. Existing methods attempt to overcome this issue by using random sampling strategy instead of the commonly-adopted farthest point sampling~(FPS), but at the expense of lower performance. So the effectiveness/efficiency trade-off remains under-explored. In this paper, we reveal the key to high-quality sampling is ensuring an even spacing between points in the subset, which can be naturally obtained through a grid. Based on this insight, we propose a hierarchical adaptive voxel-guided point sampler with linear complexity and high parallelization for real-time applications. Extensive experiments on large-scale point cloud detection and segmentation tasks demonstrate that our method achieves competitive performance with the most powerful FPS, at an amazing speed that is more than 100 times faster. This breakthrough in efficiency addresses the bottleneck of the sampling step when handling scene-level point clouds. Furthermore, our sampler can be easily integrated into existing models and achieves a 20$\sim$80\% reduction in runtime with minimal effort. The code will be available at https://github.com/OuyangJunyuan/pointcloud-3d-detector-tensorrt
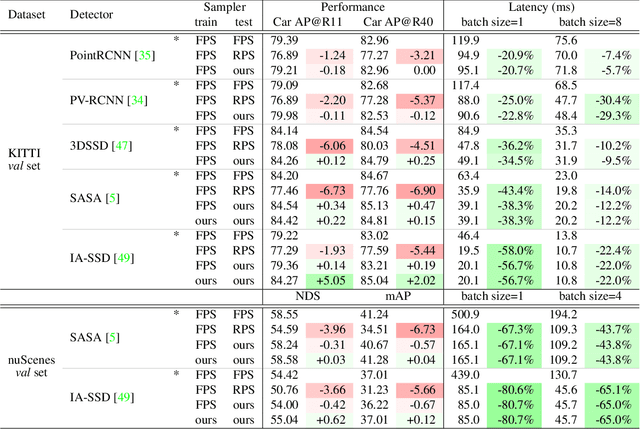
Brain MRI Segmentation using Template-Based Training and Visual Perception Augmentation
Aug 04, 2023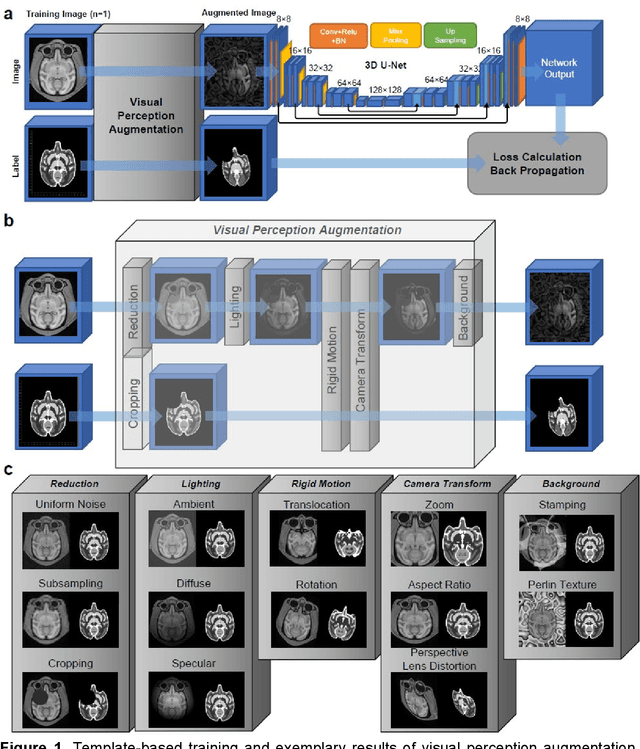
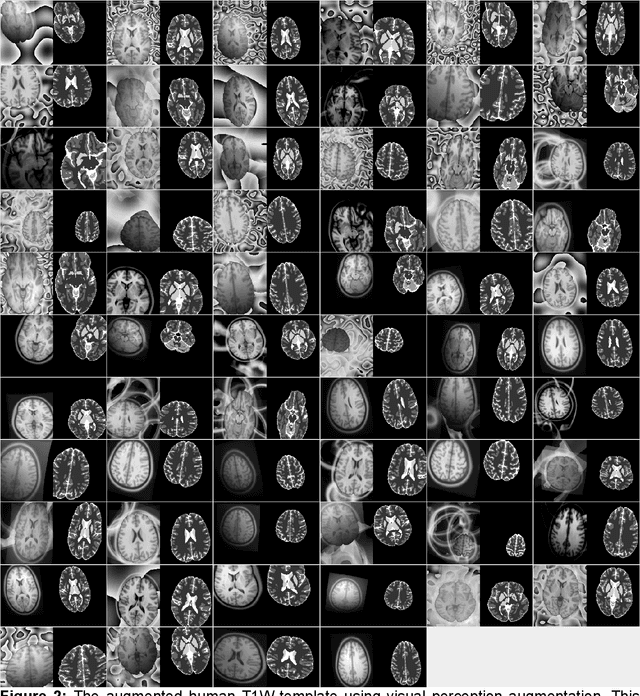
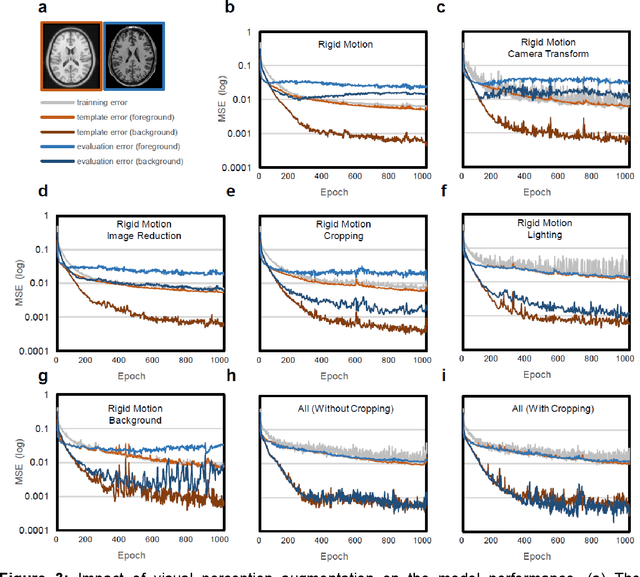
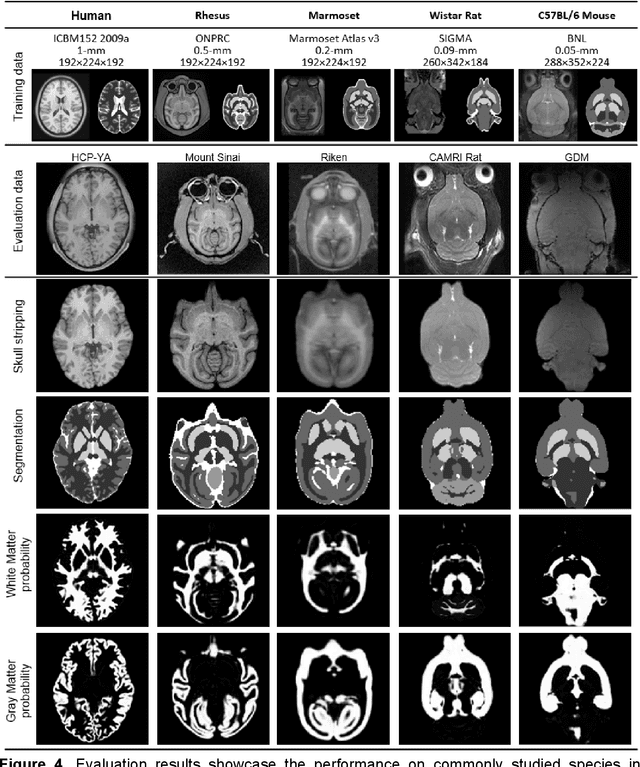
Deep learning models usually require sufficient training data to achieve high accuracy, but obtaining labeled data can be time-consuming and labor-intensive. Here we introduce a template-based training method to train a 3D U-Net model from scratch using only one population-averaged brain MRI template and its associated segmentation label. The process incorporated visual perception augmentation to enhance the model's robustness in handling diverse image inputs and mitigating overfitting. Leveraging this approach, we trained 3D U-Net models for mouse, rat, marmoset, rhesus, and human brain MRI to achieve segmentation tasks such as skull-stripping, brain segmentation, and tissue probability mapping. This tool effectively addresses the limited availability of training data and holds significant potential for expanding deep learning applications in image analysis, providing researchers with a unified solution to train deep neural networks with only one image sample.
Lightweight Endoscopic Depth Estimation with CNN-Transformer Encoder
Aug 04, 2023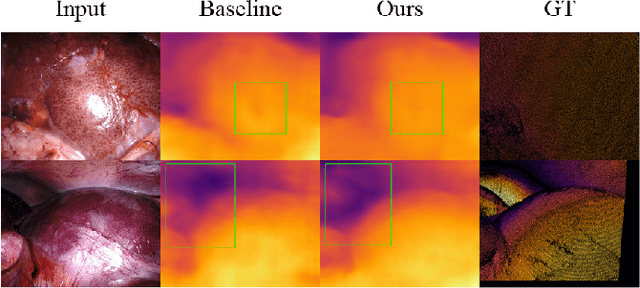
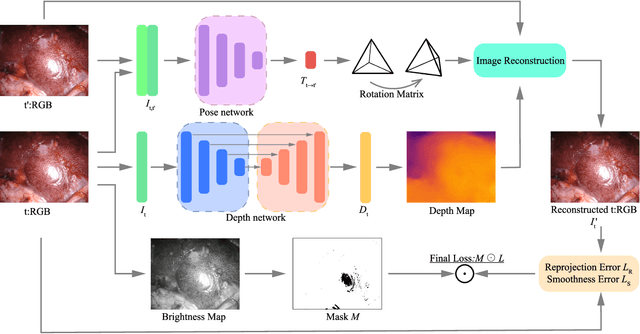
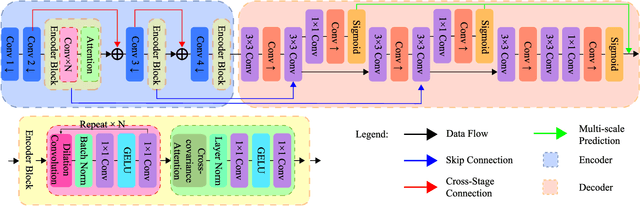
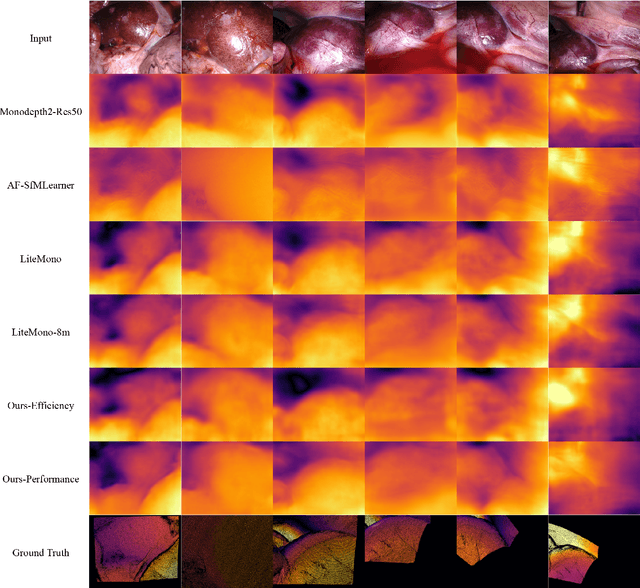
In this study, we tackle the key challenges concerning accuracy and robustness in depth estimation for endoscopic imaging, with a particular emphasis on real-time inference and the impact of reflections. We propose an innovative lightweight solution that integrates Convolutional Neural Networks (CNN) and Transformers to predict multi-scale depth maps. Our approach includes optimizing the network architecture, incorporating multi-scale dilated convolution, and a multi-channel attention mechanism. We also introduce a statistical confidence boundary mask to minimize the impact of reflective areas. Moreover, we propose a novel complexity evaluation metric that considers network parameter size, floating-point operations, and inference frames per second. Our research aims to enhance the efficiency and safety of laparoscopic surgery significantly. We comprehensively evaluate our proposed method and compare it with existing solutions. The results demonstrate that our method ensures depth estimation accuracy while being lightweight.
Efficient Monaural Speech Enhancement using Spectrum Attention Fusion
Aug 04, 2023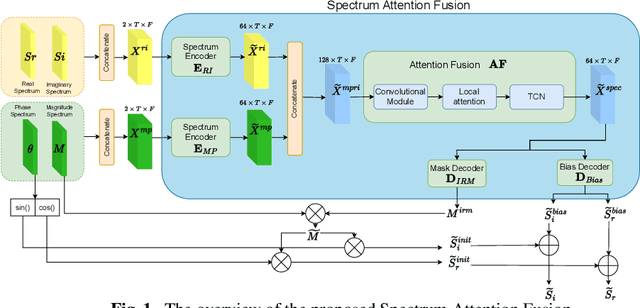
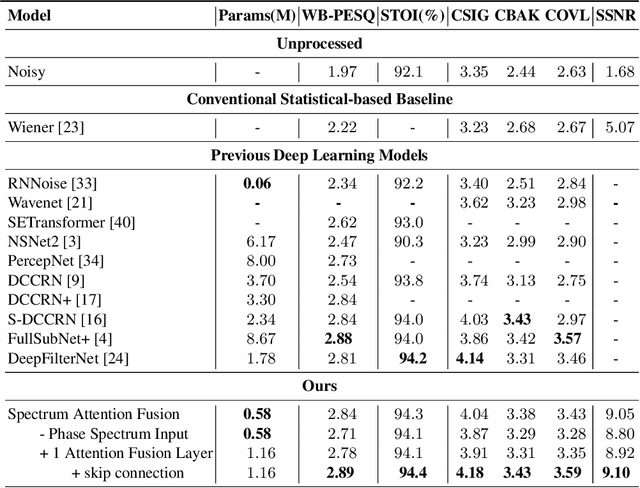
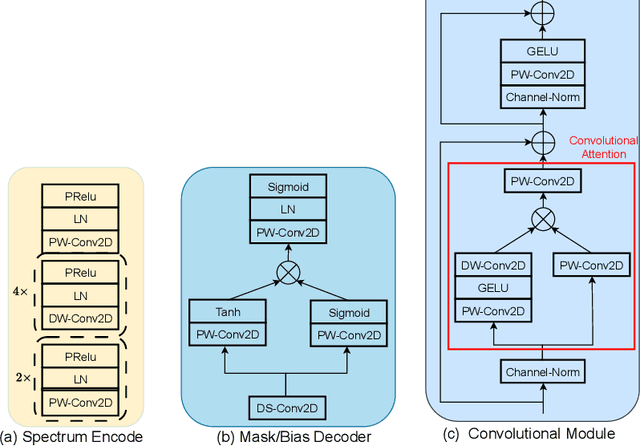
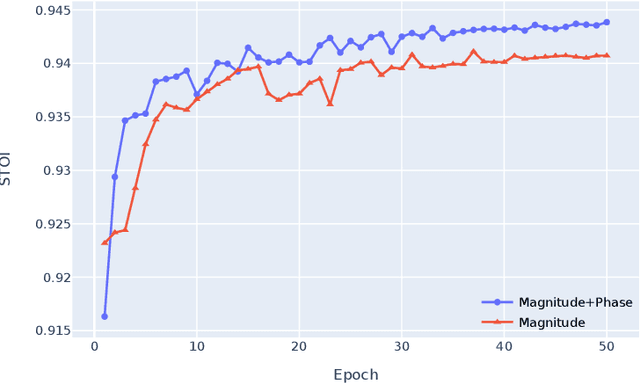
Speech enhancement is a demanding task in automated speech processing pipelines, focusing on separating clean speech from noisy channels. Transformer based models have recently bested RNN and CNN models in speech enhancement, however at the same time they are much more computationally expensive and require much more high quality training data, which is always hard to come by. In this paper, we present an improvement for speech enhancement models that maintains the expressiveness of self-attention while significantly reducing model complexity, which we have termed Spectrum Attention Fusion. We carefully construct a convolutional module to replace several self-attention layers in a speech Transformer, allowing the model to more efficiently fuse spectral features. Our proposed model is able to achieve comparable or better results against SOTA models but with significantly smaller parameters (0.58M) on the Voice Bank + DEMAND dataset.
Fluid Property Prediction Leveraging AI and Robotics
Aug 04, 2023Inferring liquid properties from vision is a challenging task due to the complex nature of fluids, both in behavior and detection. Nevertheless, the ability to infer their properties directly from visual information is highly valuable for autonomous fluid handling systems, as cameras are readily available. Moreover, predicting fluid properties purely from vision can accelerate the process of fluid characterization saving considerable time and effort in various experimental environments. In this work, we present a purely vision-based approach to estimate viscosity, leveraging the fact that the behavior of the fluid oscillations is directly related to the viscosity. Specifically, we utilize a 3D convolutional autoencoder to learn latent representations of different fluid-oscillating patterns present in videos. We leverage this latent representation to visually infer the category of fluid or the dynamics viscosity of fluid from video.