 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A vision transformer-based framework for knowledge transfer from multi-modal to mono-modal lymphoma subtyping models
Aug 02, 2023
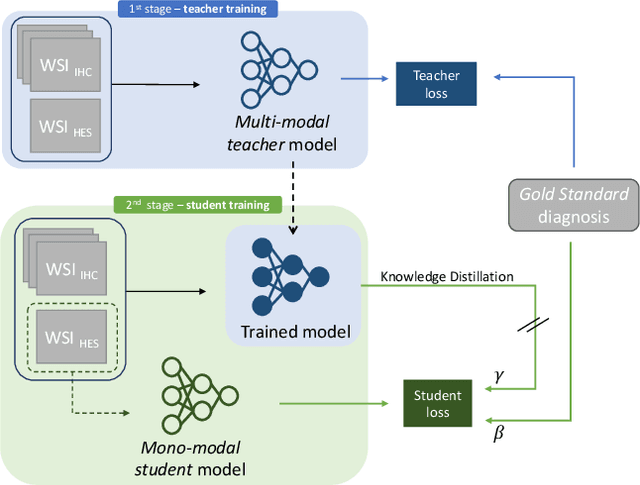
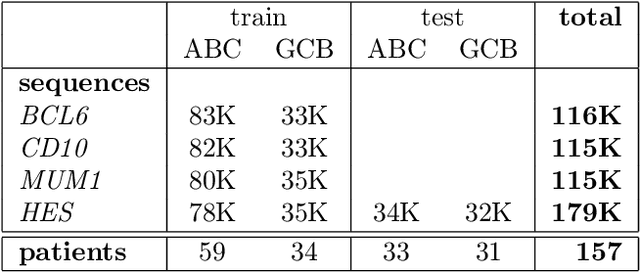


Determining lymphoma subtypes is a crucial step for better patients treatment targeting to potentially increase their survival chances. In this context, the existing gold standard diagnosis method, which is based on gene expression technology, is highly expensive and time-consuming making difficult its accessibility. Although alternative diagnosis methods based on IHC (immunohistochemistry) technologies exist (recommended by the WHO), they still suffer from similar limitations and are less accurate. WSI (Whole Slide Image) analysis by deep learning models showed promising new directions for cancer diagnosis that would be cheaper and faster than existing alternative methods. In this work, we propose a vision transformer-based framework for distinguishing DLBCL (Diffuse Large B-Cell Lymphoma) cancer subtypes from high-resolution WSIs. To this end, we propose a multi-modal architecture to train a classifier model from various WSI modalities. We then exploit this model through a knowledge distillation mechanism for efficiently driving the learning of a mono-modal classifier. Our experimental study conducted on a dataset of 157 patients shows the promising performance of our mono-modal classification model, outperforming six recent methods from the state-of-the-art dedicated for cancer classification. Moreover, the power-law curve, estimated on our experimental data, shows that our classification model requires a reasonable number of additional patients for its training to potentially reach identical diagnosis accuracy as IHC technologies.
Model-agnostic search for the quasinormal modes of gravitational wave echoes
Aug 02, 2023Post-merger gravitational wave echoes provide a unique opportunity to probe the near-horizon structure of astrophysical black holes, that may be modified due to non-perturbative quantum gravity phenomena. However, since the waveform is subject to large theoretical uncertainties, it is necessary to develop model-agnostic search methods for detecting echoes from observational data. A promising strategy is to identify the characteristic quasinormal modes (QNMs) associated with echoes, {\it in frequency space}, which complements existing searches of quasiperiodic pulses in time. In this study, we build upon our previous work targeting these modes by incorporating relative phase information to optimize the Bayesian search algorithm. Using a new phase-marginalized likelihood, the performance can be significantly improved for well-resolved QNMs. This enables an efficient model-agnostic search for QNMs of different shapes by using a simple search template. To demonstrate the robustness of the search algorithm, we construct four complementary benchmarks for the echo waveform that span a diverse range of different theoretical possibilities for the near-horizon structure. We then validate our Bayesian search algorithms by injecting the benchmark models into different realizations of Gaussian noise. Using two types of phase-marginalized likelihoods, we find that the search algorithm can efficiently detect the corresponding QNMs. Therefore, our search strategy provides a concrete Bayesian and model-agnostic approach to "quantum black hole seismology".
Learning Structured Components: Towards Modular and Interpretable Multivariate Time Series Forecasting
May 24, 2023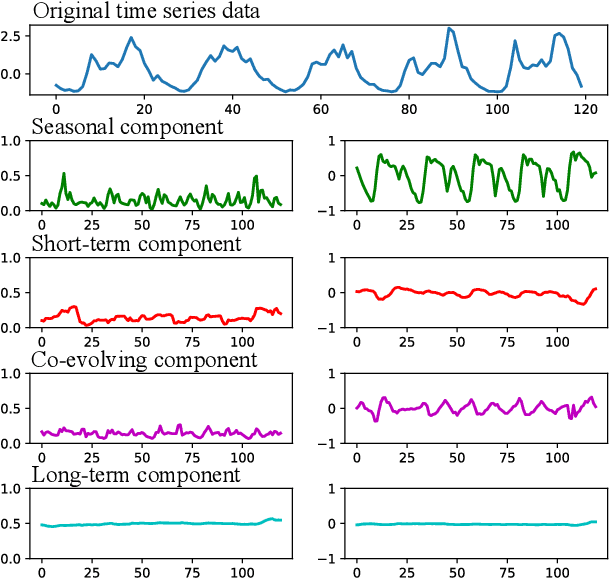

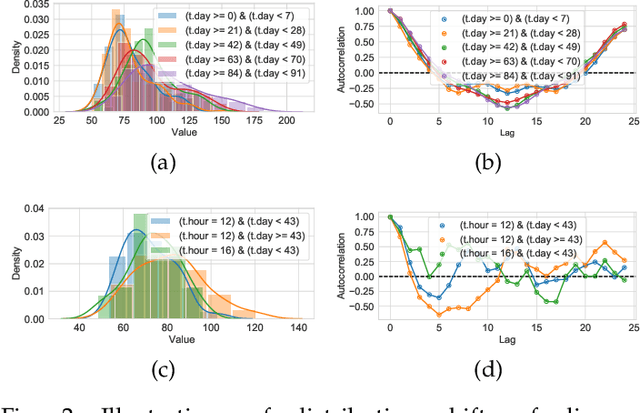
Multivariate time-series (MTS) forecasting is a paramount and fundamental problem in many real-world applications. The core issue in MTS forecasting is how to effectively model complex spatial-temporal patterns. In this paper, we develop a modular and interpretable forecasting framework, which seeks to individually model each component of the spatial-temporal patterns. We name this framework SCNN, short for Structured Component-based Neural Network. SCNN works with a pre-defined generative process of MTS, which arithmetically characterizes the latent structure of the spatial-temporal patterns. In line with its reverse process, SCNN decouples MTS data into structured and heterogeneous components and then respectively extrapolates the evolution of these components, the dynamics of which is more traceable and predictable than the original MTS. Extensive experiments are conducted to demonstrate that SCNN can achieve superior performance over state-of-the-art models on three real-world datasets. Additionally, we examine SCNN with different configurations and perform in-depth analyses of the properties of SCNN.
Predicting Ordinary Differential Equations with Transformers
Jul 24, 2023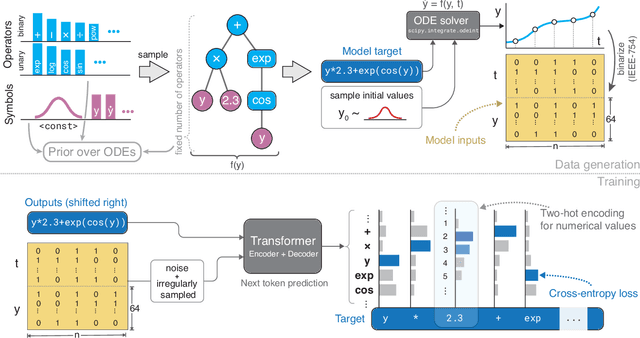

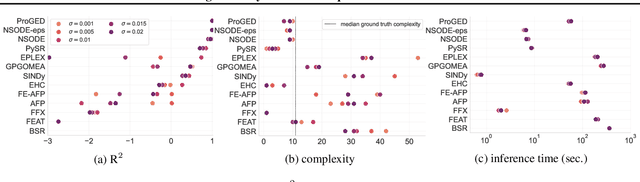
We develop a transformer-based sequence-to-sequence model that recovers scalar ordinary differential equations (ODEs) in symbolic form from irregularly sampled and noisy observations of a single solution trajectory. We demonstrate in extensive empirical evaluations that our model performs better or on par with existing methods in terms of accurate recovery across various settings. Moreover, our method is efficiently scalable: after one-time pretraining on a large set of ODEs, we can infer the governing law of a new observed solution in a few forward passes of the model.
A Hybrid Machine Learning Model for Classifying Gene Mutations in Cancer using LSTM, BiLSTM, CNN, GRU, and GloVe
Jul 24, 2023This study presents an ensemble model combining LSTM, BiLSTM, CNN, GRU, and GloVe to classify gene mutations using Kaggle's Personalized Medicine: Redefining Cancer Treatment dataset. The results were compared against well-known transformers like as BERT, Electra, Roberta, XLNet, Distilbert, and their LSTM ensembles. Our model outperformed all other models in terms of accuracy, precision, recall, F1 score, and Mean Squared Error. Surprisingly, it also needed less training time, resulting in a perfect combination of performance and efficiency. This study demonstrates the utility of ensemble models for difficult tasks such as gene mutation classification.
PDT: Pretrained Dual Transformers for Time-aware Bipartite Graphs
Jun 21, 2023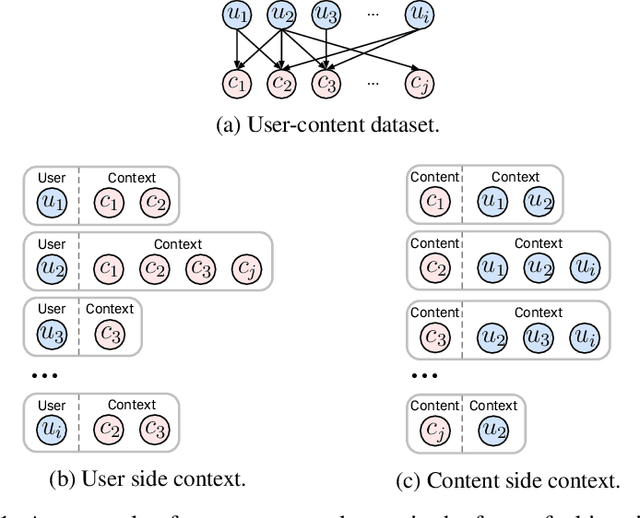
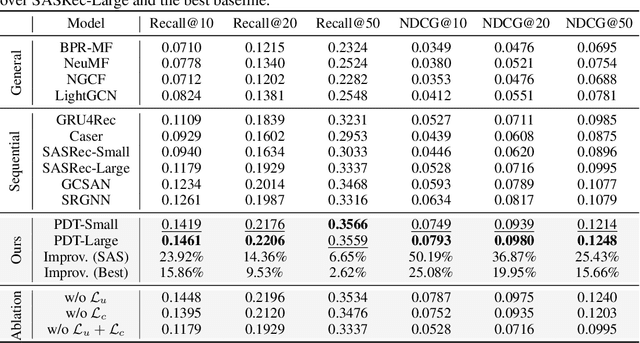
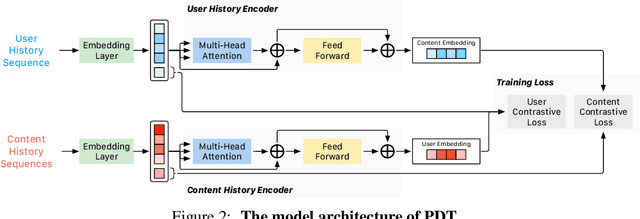
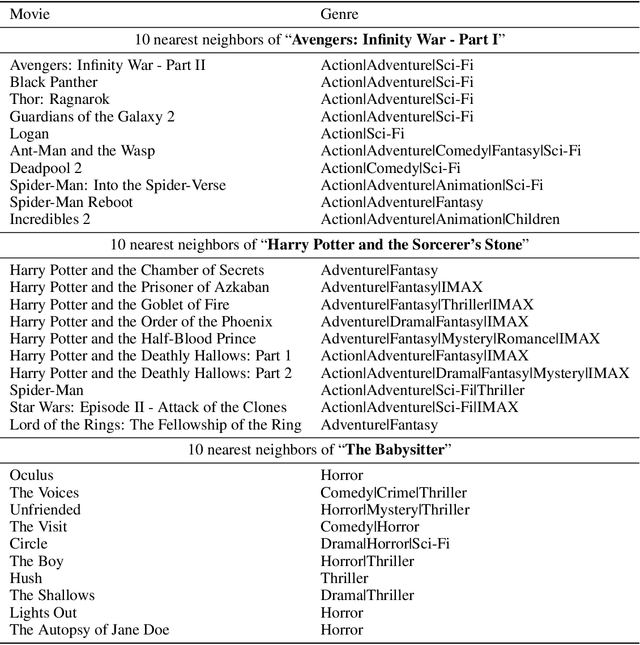
Pre-training on large models is prevalent and emerging with the ever-growing user-generated content in many machine learning application categories. It has been recognized that learning contextual knowledge from the datasets depicting user-content interaction plays a vital role in downstream tasks. Despite several studies attempting to learn contextual knowledge via pre-training methods, finding an optimal training objective and strategy for this type of task remains a challenging problem. In this work, we contend that there are two distinct aspects of contextual knowledge, namely the user-side and the content-side, for datasets where user-content interaction can be represented as a bipartite graph. To learn contextual knowledge, we propose a pre-training method that learns a bi-directional mapping between the spaces of the user-side and the content-side. We formulate the training goal as a contrastive learning task and propose a dual-Transformer architecture to encode the contextual knowledge. We evaluate the proposed method for the recommendation task. The empirical studies have demonstrated that the proposed method outperformed all the baselines with significant gains.
BASEN: Time-Domain Brain-Assisted Speech Enhancement Network with Convolutional Cross Attention in Multi-talker Conditions
May 17, 2023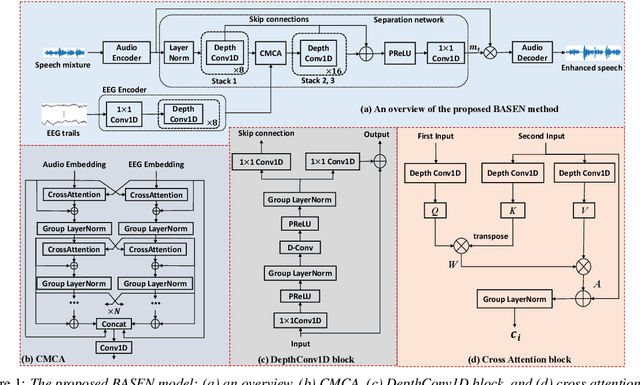
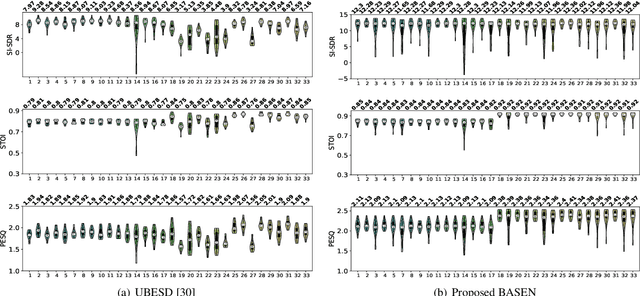
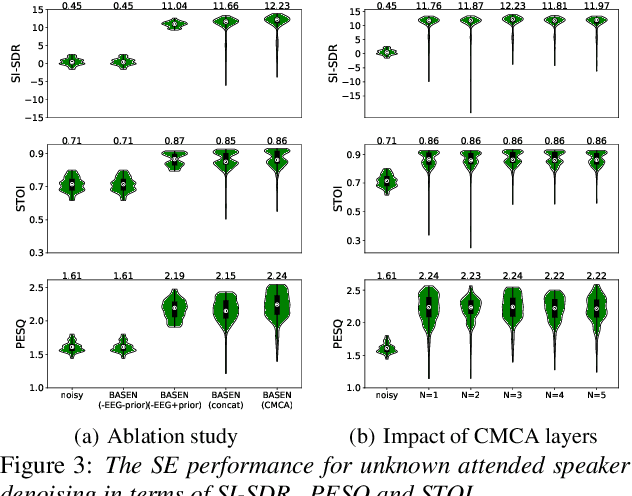
Time-domain single-channel speech enhancement (SE) still remains challenging to extract the target speaker without any prior information on multi-talker conditions. It has been shown via auditory attention decoding that the brain activity of the listener contains the auditory information of the attended speaker. In this paper, we thus propose a novel time-domain brain-assisted SE network (BASEN) incorporating electroencephalography (EEG) signals recorded from the listener for extracting the target speaker from monaural speech mixtures. The proposed BASEN is based on the fully-convolutional time-domain audio separation network. In order to fully leverage the complementary information contained in the EEG signals, we further propose a convolutional multi-layer cross attention module to fuse the dual-branch features. Experimental results on a public dataset show that the proposed model outperforms the state-of-the-art method in several evaluation metrics. The reproducible code is available at https://github.com/jzhangU/Basen.git.
StyleAvatar: Real-time Photo-realistic Portrait Avatar from a Single Video
May 01, 2023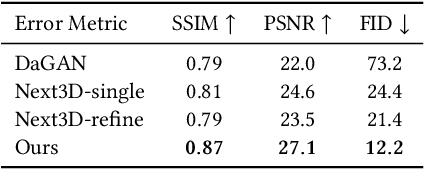
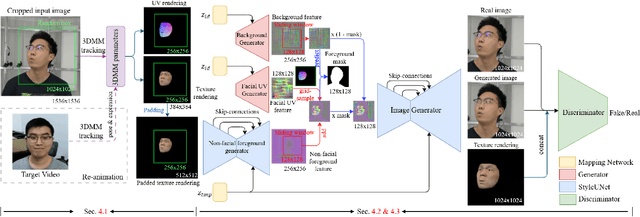
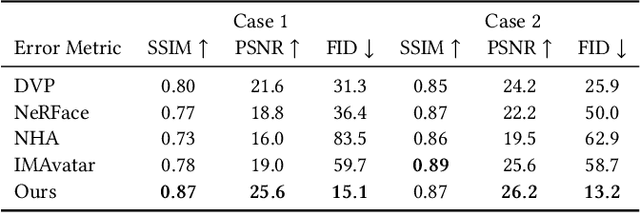

Face reenactment methods attempt to restore and re-animate portrait videos as realistically as possible. Existing methods face a dilemma in quality versus controllability: 2D GAN-based methods achieve higher image quality but suffer in fine-grained control of facial attributes compared with 3D counterparts. In this work, we propose StyleAvatar, a real-time photo-realistic portrait avatar reconstruction method using StyleGAN-based networks, which can generate high-fidelity portrait avatars with faithful expression control. We expand the capabilities of StyleGAN by introducing a compositional representation and a sliding window augmentation method, which enable faster convergence and improve translation generalization. Specifically, we divide the portrait scenes into three parts for adaptive adjustments: facial region, non-facial foreground region, and the background. Besides, our network leverages the best of UNet, StyleGAN and time coding for video learning, which enables high-quality video generation. Furthermore, a sliding window augmentation method together with a pre-training strategy are proposed to improve translation generalization and training performance, respectively. The proposed network can converge within two hours while ensuring high image quality and a forward rendering time of only 20 milliseconds. Furthermore, we propose a real-time live system, which further pushes research into applications. Results and experiments demonstrate the superiority of our method in terms of image quality, full portrait video generation, and real-time re-animation compared to existing facial reenactment methods. Training and inference code for this paper are at https://github.com/LizhenWangT/StyleAvatar.
Large-scale Fully-Unsupervised Re-Identification
Jul 26, 2023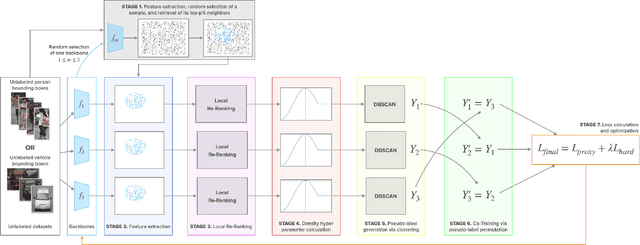
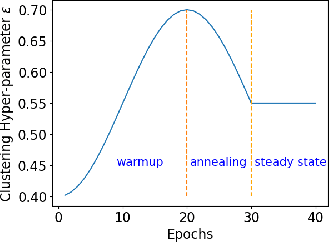


Fully-unsupervised Person and Vehicle Re-Identification have received increasing attention due to their broad applicability in surveillance, forensics, event understanding, and smart cities, without requiring any manual annotation. However, most of the prior art has been evaluated in datasets that have just a couple thousand samples. Such small-data setups often allow the use of costly techniques in time and memory footprints, such as Re-Ranking, to improve clustering results. Moreover, some previous work even pre-selects the best clustering hyper-parameters for each dataset, which is unrealistic in a large-scale fully-unsupervised scenario. In this context, this work tackles a more realistic scenario and proposes two strategies to learn from large-scale unlabeled data. The first strategy performs a local neighborhood sampling to reduce the dataset size in each iteration without violating neighborhood relationships. A second strategy leverages a novel Re-Ranking technique, which has a lower time upper bound complexity and reduces the memory complexity from O(n^2) to O(kn) with k << n. To avoid the pre-selection of specific hyper-parameter values for the clustering algorithm, we also present a novel scheduling algorithm that adjusts the density parameter during training, to leverage the diversity of samples and keep the learning robust to noisy labeling. Finally, due to the complementary knowledge learned by different models, we also introduce a co-training strategy that relies upon the permutation of predicted pseudo-labels, among the backbones, with no need for any hyper-parameters or weighting optimization. The proposed methodology outperforms the state-of-the-art methods in well-known benchmarks and in the challenging large-scale Veri-Wild dataset, with a faster and memory-efficient Re-Ranking strategy, and a large-scale, noisy-robust, and ensemble-based learning approach.
Real-time Evolution of Multicellularity with Artificial Gene Regulation
May 20, 2023
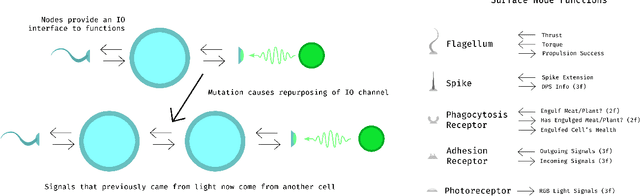
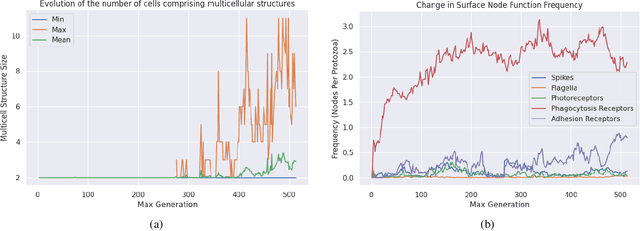
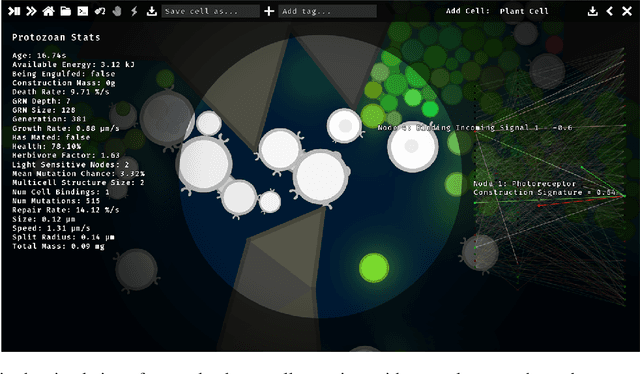
This paper presents a real-time simulation involving ''protozoan-like'' cells that evolve by natural selection in a physical 2D ecosystem. Selection pressure is exerted via the requirements to collect mass and energy from the surroundings in order to reproduce by cell-division. Cells do not have fixed morphologies from birth; they can use their resources in construction projects that produce functional nodes on their surfaces such as photoreceptors for light sensitivity or flagella for motility. Importantly, these nodes act as modular components that connect to the cell's control system via IO channels, meaning that the evolutionary process can replace one function with another while utilising pre-developed control pathways on the other side of the channel. A notable type of node function is the adhesion receptors that allow cells to bind together into multicellular structures in which individuals can share resource and signal to one another. The control system itself is modelled as an artificial neural network that doubles as a gene regulatory network, thereby permitting the co-evolution of form and function in a single data structure and allowing cell specialisation within multicellular groups.