 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid-SORT: Weak Cues Matter for Online Multi-Object Tracking
Aug 01, 2023
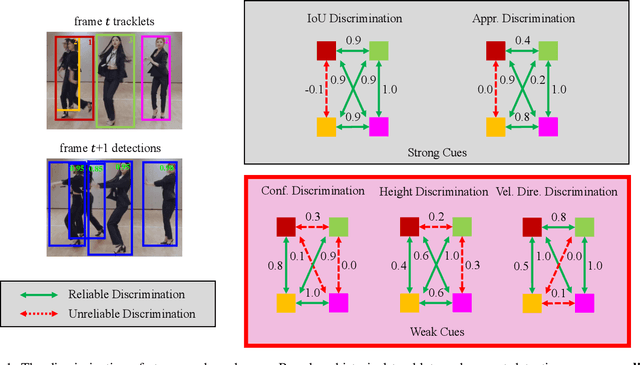
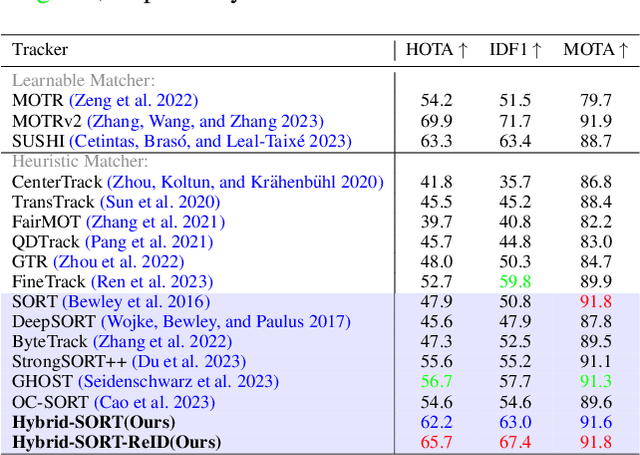
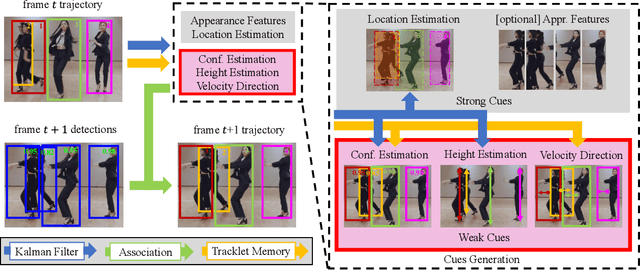
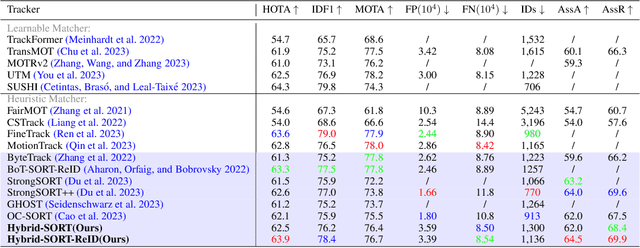
Multi-Object Tracking (MOT) aims to detect and associate all desired objects across frames. Most methods accomplish the task by explicitly or implicitly leveraging strong cues (i.e., spatial and appearance information), which exhibit powerful instance-level discrimination. However, when object occlusion and clustering occur, both spatial and appearance information will become ambiguous simultaneously due to the high overlap between objects. In this paper, we demonstrate that this long-standing challenge in MOT can be efficiently and effectively resolved by incorporating weak cues to compensate for strong cues. Along with velocity direction, we introduce the confidence state and height state as potential weak cues. With superior performance, our method still maintains Simple, Online and Real-Time (SORT) characteristics. Furthermore, our method shows strong generalization for diverse trackers and scenarios in a plug-and-play and training-free manner. Significant and consistent improvements are observed when applying our method to 5 different representative trackers. Further, by leveraging both strong and weak cues, our method Hybrid-SORT achieves superior performance on diverse benchmarks, including MOT17, MOT20, and especially DanceTrack where interaction and occlusion are frequent and severe. The code and models are available at https://github.com/ymzis69/HybirdSORT.
AOSoar: Autonomous Orographic Soaring of a Micro Air Vehicle
Aug 01, 2023
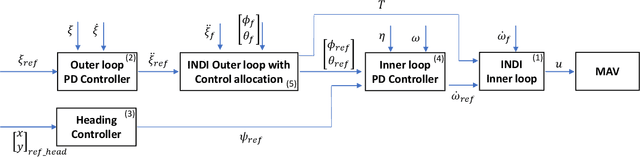


Utilizing wind hovering techniques of soaring birds can save energy expenditure and improve the flight endurance of micro air vehicles (MAVs). Here, we present a novel method for fully autonomous orographic soaring without a priori knowledge of the wind field. Specifically, we devise an Incremental Nonlinear Dynamic Inversion (INDI) controller with control allocation, adapting it for autonomous soaring. This allows for both soaring and the use of the throttle if necessary, without changing any gain or parameter during the flight. Furthermore, we propose a simulated-annealing-based optimization method to search for soaring positions. This enables for the first time an MAV to autonomously find a feasible soaring position while minimizing throttle usage and other control efforts. Autonomous orographic soaring was performed in the wind tunnel. The wind speed and incline of a ramp were changed during the soaring flight. The MAV was able to perform autonomous orographic soaring for flight times of up to 30 minutes. The mean throttle usage was only 0.25% for the entire soaring flight, whereas normal powered flight requires 38%. Also, it was shown that the MAV can find a new soaring spot when the wind field changes during the flight.
CliniDigest: A Case Study in Large Language Model Based Large-Scale Summarization of Clinical Trial Descriptions
Jul 31, 2023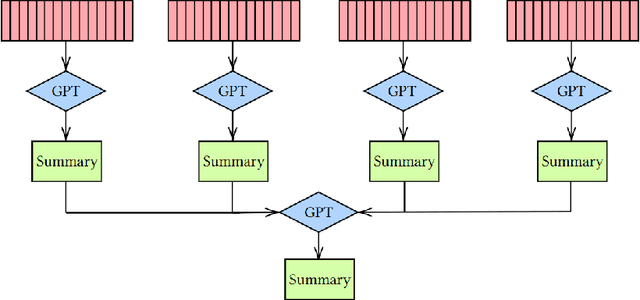

A clinical trial is a study that evaluates new biomedical interventions. To design new trials, researchers draw inspiration from those current and completed. In 2022, there were on average more than 100 clinical trials submitted to ClinicalTrials.gov every day, with each trial having a mean of approximately 1500 words [1]. This makes it nearly impossible to keep up to date. To mitigate this issue, we have created a batch clinical trial summarizer called CliniDigest using GPT-3.5. CliniDigest is, to our knowledge, the first tool able to provide real-time, truthful, and comprehensive summaries of clinical trials. CliniDigest can reduce up to 85 clinical trial descriptions (approximately 10,500 words) into a concise 200-word summary with references and limited hallucinations. We have tested CliniDigest on its ability to summarize 457 trials divided across 27 medical subdomains. For each field, CliniDigest generates summaries of $\mu=153,\ \sigma=69 $ words, each of which utilizes $\mu=54\%,\ \sigma=30\% $ of the sources. A more comprehensive evaluation is planned and outlined in this paper.
An Efficient Shapley Value Computation for the Naive Bayes Classifier
Jul 31, 2023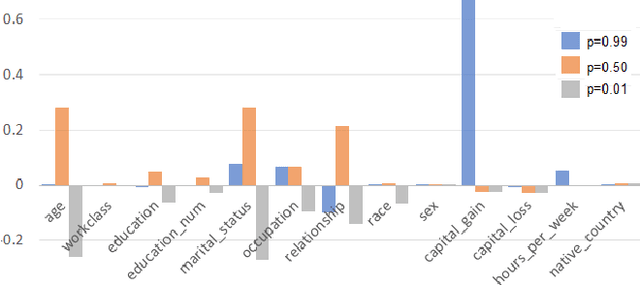
Variable selection or importance measurement of input variables to a machine learning model has become the focus of much research. It is no longer enough to have a good model, one also must explain its decisions. This is why there are so many intelligibility algorithms available today. Among them, Shapley value estimation algorithms are intelligibility methods based on cooperative game theory. In the case of the naive Bayes classifier, and to our knowledge, there is no ``analytical" formulation of Shapley values. This article proposes an exact analytic expression of Shapley values in the special case of the naive Bayes Classifier. We analytically compare this Shapley proposal, to another frequently used indicator, the Weight of Evidence (WoE) and provide an empirical comparison of our proposal with (i) the WoE and (ii) KernelShap results on real world datasets, discussing similar and dissimilar results. The results show that our Shapley proposal for the naive Bayes classifier provides informative results with low algorithmic complexity so that it can be used on very large datasets with extremely low computation time.
LP-MusicCaps: LLM-Based Pseudo Music Captioning
Jul 31, 2023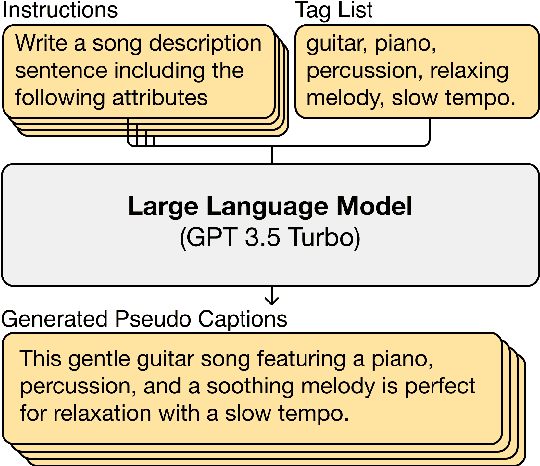

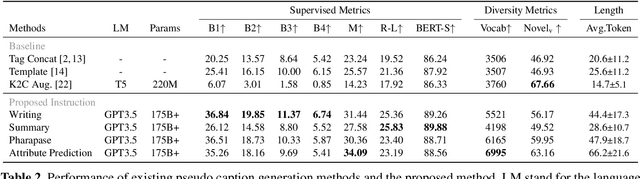
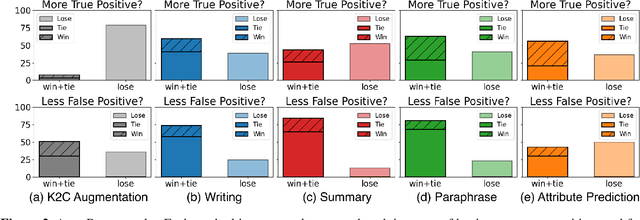
Automatic music captioning, which generates natural language descriptions for given music tracks, holds significant potential for enhancing the understanding and organization of large volumes of musical data. Despite its importance, researchers face challenges due to the costly and time-consuming collection process of existing music-language datasets, which are limited in size. To address this data scarcity issue, we propose the use of large language models (LLMs) to artificially generate the description sentences from large-scale tag datasets. This results in approximately 2.2M captions paired with 0.5M audio clips. We term it Large Language Model based Pseudo music caption dataset, shortly, LP-MusicCaps. We conduct a systemic evaluation of the large-scale music captioning dataset with various quantitative evaluation metrics used in the field of natural language processing as well as human evaluation. In addition, we trained a transformer-based music captioning model with the dataset and evaluated it under zero-shot and transfer-learning settings. The results demonstrate that our proposed approach outperforms the supervised baseline model.
SpatialNet: Extensively Learning Spatial Information for Multichannel Joint Speech Separation, Denoising and Dereverberation
Jul 31, 2023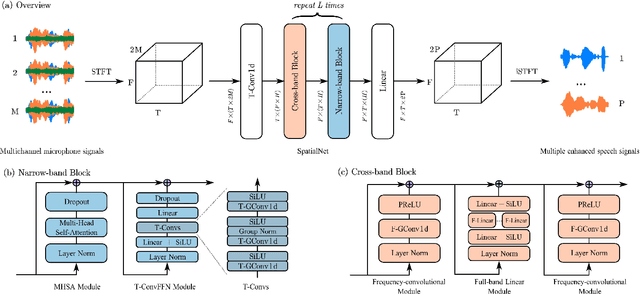

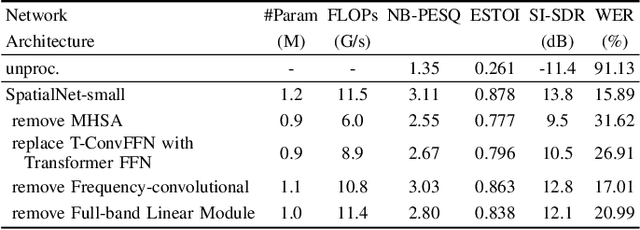
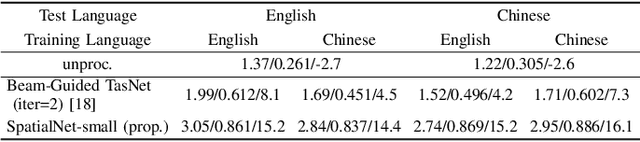
This work proposes a neural network to extensively exploit spatial information for multichannel joint speech separation, denoising and dereverberation, named SpatialNet.In the short-time Fourier transform (STFT) domain, the proposed network performs end-to-end speech enhancement. It is mainly composed of interleaved narrow-band and cross-band blocks to respectively exploit narrow-band and cross-band spatial information. The narrow-band blocks process frequencies independently, and use self-attention mechanism and temporal convolutional layers to respectively perform spatial-feature-based speaker clustering and temporal smoothing/filtering. The cross-band blocks processes frames independently, and use full-band linear layer and frequency convolutional layers to respectively learn the correlation between all frequencies and adjacent frequencies. Experiments are conducted on various simulated and real datasets, and the results show that 1) the proposed network achieves the state-of-the-art performance on almost all tasks; 2) the proposed network suffers little from the spectral generalization problem; and 3) the proposed network is indeed performing speaker clustering (demonstrated by attention maps).
Compressive Image Scanning Microscope
Jul 19, 2023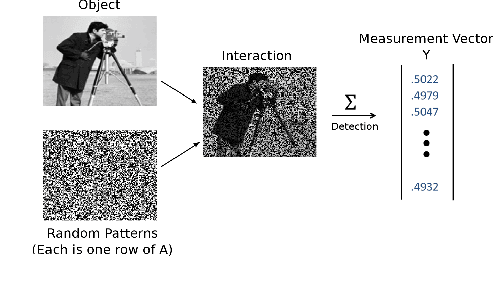
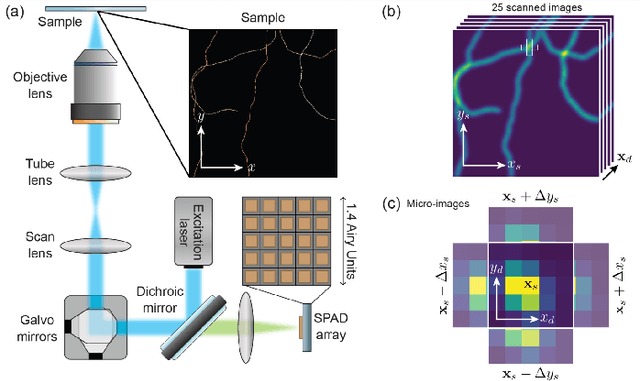

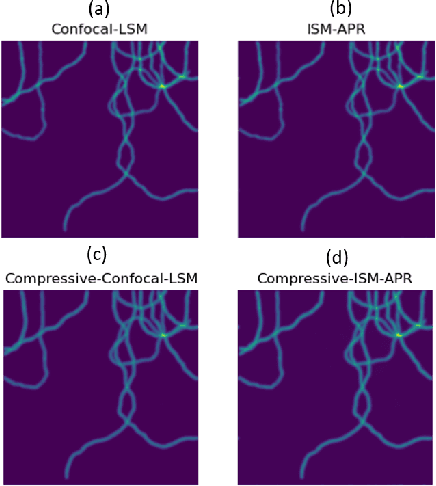
We present a novel approach to implement compressive sensing in laser scanning microscopes (LSM), specifically in image scanning microscopy (ISM), using a single-photon avalanche diode (SPAD) array detector. Our method addresses two significant limitations in applying compressive sensing to LSM: the time to compute the sampling matrix and the quality of reconstructed images. We employ a fixed sampling strategy, skipping alternate rows and columns during data acquisition, which reduces the number of points scanned by a factor of four and eliminates the need to compute different sampling matrices. By exploiting the parallel images generated by the SPAD array, we improve the quality of the reconstructed compressive-ISM images compared to standard compressive confocal LSM images. Our results demonstrate the effectiveness of our approach in producing higher-quality images with reduced data acquisition time and potential benefits in reducing photobleaching.
InstaGrasp: An Entirely 3D Printed Adaptive Gripper with TPU Soft Elements and Minimal Assembly Time
May 26, 2023Fabricating existing and popular open-source adaptive robotic grippers commonly involves using multiple professional machines, purchasing a wide range of parts, and tedious, time-consuming assembly processes. This poses a significant barrier to entry for some robotics researchers and drives others to opt for expensive commercial alternatives. To provide both parties with an easier and cheaper (under 100GBP) solution, we propose a novel adaptive gripper design where every component (with the exception of actuators and the screws that come packaged with them) can be fabricated on a hobby-grade 3D printer, via a combination of inexpensive and readily available PLA and TPU filaments. This approach means that the gripper's tendons, flexure joints and finger pads are now printed, as a replacement for traditional string-tendons and molded urethane flexures and pads. A push-fit systems results in an assembly time of under 10 minutes. The gripper design is also highly modular and requires only a few minutes to replace any part, leading to extremely user-friendly maintenance and part modifications. An extensive stress test has shown a level of durability more than suitable for research, whilst grasping experiments (with perturbations) using items from the YCB object set has also proven its mechanical adaptability to be highly satisfactory.
A Flexible Framework for Incorporating Patient Preferences Into Q-Learning
Jul 22, 2023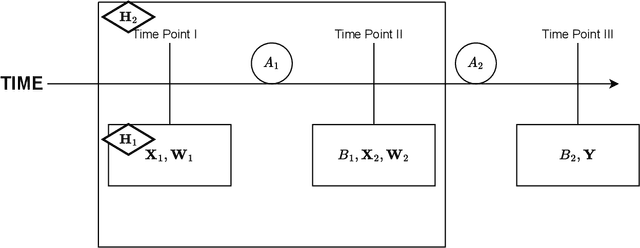
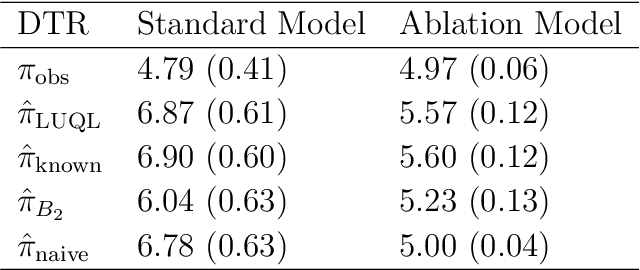

In real-world healthcare problems, there are often multiple competing outcomes of interest, such as treatment efficacy and side effect severity. However, statistical methods for estimating dynamic treatment regimes (DTRs) usually assume a single outcome of interest, and the few methods that deal with composite outcomes suffer from important limitations. This includes restrictions to a single time point and two outcomes, the inability to incorporate self-reported patient preferences and limited theoretical guarantees. To this end, we propose a new method to address these limitations, which we dub Latent Utility Q-Learning (LUQ-Learning). LUQ-Learning uses a latent model approach to naturally extend Q-learning to the composite outcome setting and adopt the ideal trade-off between outcomes to each patient. Unlike previous approaches, our framework allows for an arbitrary number of time points and outcomes, incorporates stated preferences and achieves strong asymptotic performance with realistic assumptions on the data. We conduct simulation experiments based on an ongoing trial for low back pain as well as a well-known completed trial for schizophrenia. In all experiments, our method achieves highly competitive empirical performance compared to several alternative baselines.
Deep Reinforcement Learning Based System for Intraoperative Hyperspectral Video Autofocusing
Jul 21, 2023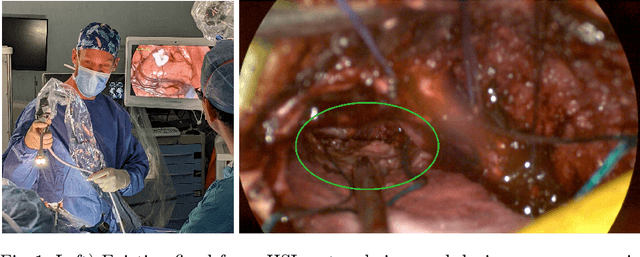
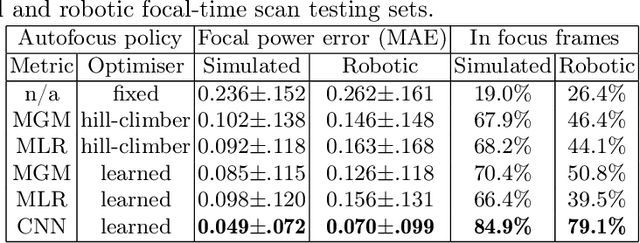
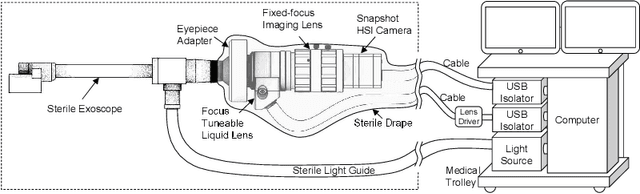
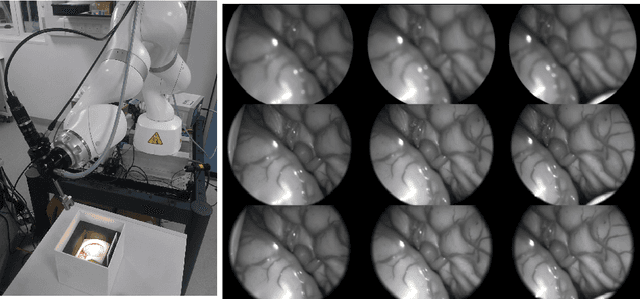
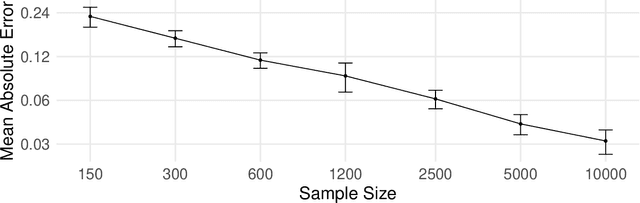
Hyperspectral imaging (HSI) captures a greater level of spectral detail than traditional optical imaging, making it a potentially valuable intraoperative tool when precise tissue differentiation is essential. Hardware limitations of current optical systems used for handheld real-time video HSI result in a limited focal depth, thereby posing usability issues for integration of the technology into the operating room. This work integrates a focus-tunable liquid lens into a video HSI exoscope, and proposes novel video autofocusing methods based on deep reinforcement learning. A first-of-its-kind robotic focal-time scan was performed to create a realistic and reproducible testing dataset. We benchmarked our proposed autofocus algorithm against traditional policies, and found our novel approach to perform significantly ($p<0.05$) better than traditional techniques ($0.070\pm.098$ mean absolute focal error compared to $0.146\pm.148$). In addition, we performed a blinded usability trial by having two neurosurgeons compare the system with different autofocus policies, and found our novel approach to be the most favourable, making our system a desirable addition for intraoperative HSI.