 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SMURF: Spatial Multi-Representation Fusion for 3D Object Detection with 4D Imaging Radar
Jul 20, 2023
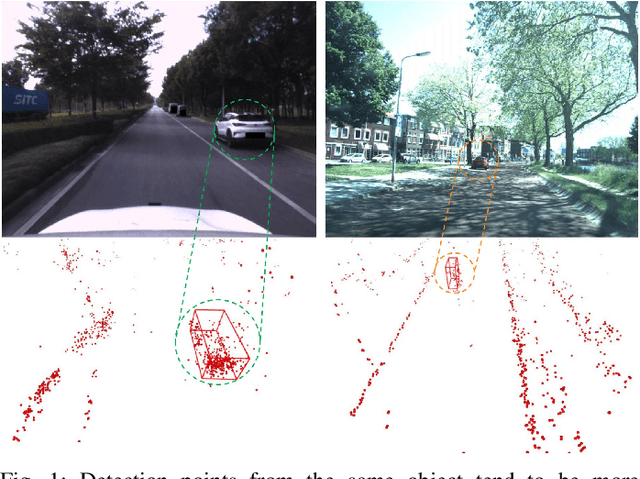
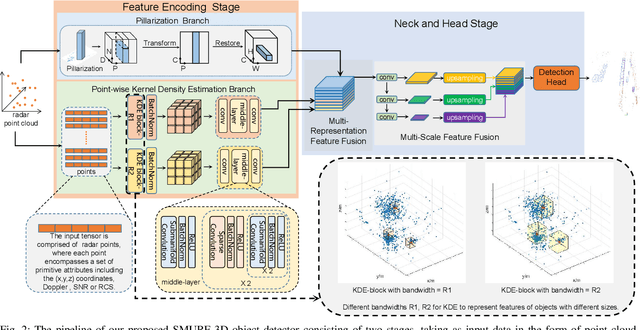
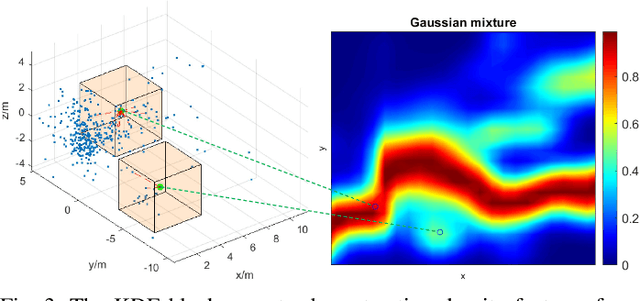
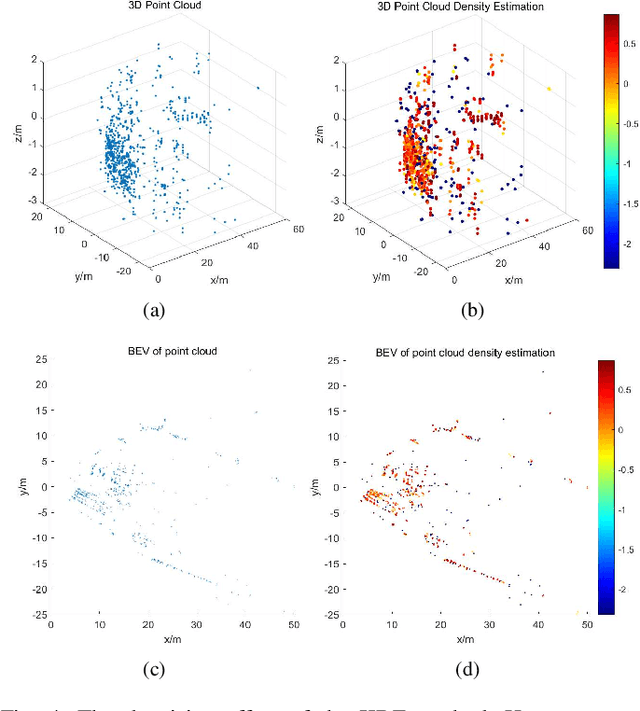
The 4D Millimeter wave (mmWave) radar is a promising technology for vehicle sensing due to its cost-effectiveness and operability in adverse weather conditions. However, the adoption of this technology has been hindered by sparsity and noise issues in radar point cloud data. This paper introduces spatial multi-representation fusion (SMURF), a novel approach to 3D object detection using a single 4D imaging radar. SMURF leverages multiple representations of radar detection points, including pillarization and density features of a multi-dimensional Gaussian mixture distribution through kernel density estimation (KDE). KDE effectively mitigates measurement inaccuracy caused by limited angular resolution and multi-path propagation of radar signals. Additionally, KDE helps alleviate point cloud sparsity by capturing density features. Experimental evaluations on View-of-Delft (VoD) and TJ4DRadSet datasets demonstrate the effectiveness and generalization ability of SMURF, outperforming recently proposed 4D imaging radar-based single-representation models. Moreover, while using 4D imaging radar only, SMURF still achieves comparable performance to the state-of-the-art 4D imaging radar and camera fusion-based method, with an increase of 1.22% in the mean average precision on bird's-eye view of TJ4DRadSet dataset and 1.32% in the 3D mean average precision on the entire annotated area of VoD dataset. Our proposed method demonstrates impressive inference time and addresses the challenges of real-time detection, with the inference time no more than 0.05 seconds for most scans on both datasets. This research highlights the benefits of 4D mmWave radar and is a strong benchmark for subsequent works regarding 3D object detection with 4D imaging radar.
Paired Competing Neurons Improving STDP Supervised Local Learning In Spiking Neural Networks
Aug 04, 2023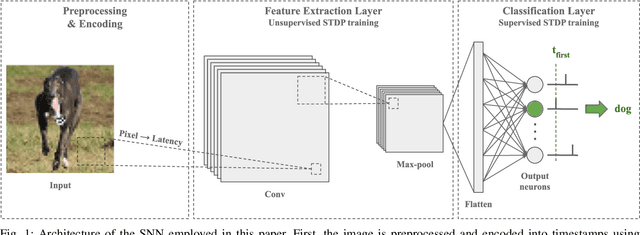
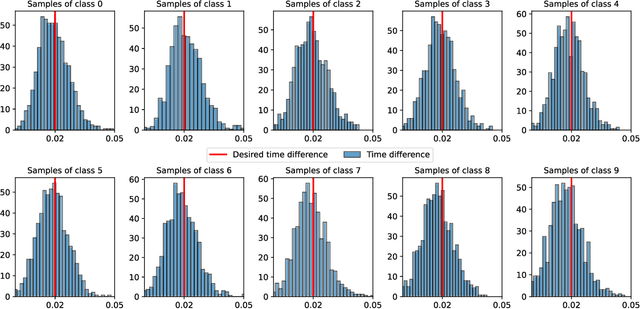
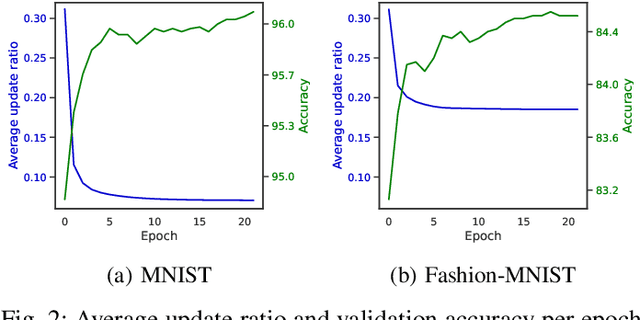
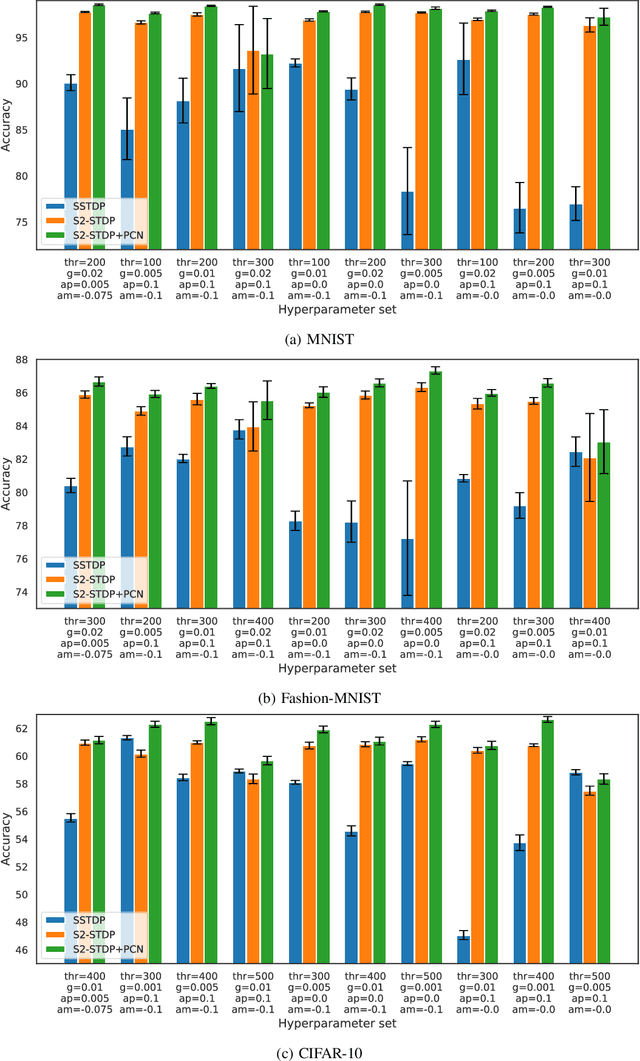
Direct training of Spiking Neural Networks (SNNs) on neuromorphic hardware has the potential to significantly reduce the high energy consumption of Artificial Neural Networks (ANNs) training on modern computers. The biological plausibility of SNNs allows them to benefit from bio-inspired plasticity rules, such as Spike Timing-Dependent Plasticity (STDP). STDP offers gradient-free and unsupervised local learning, which can be easily implemented on neuromorphic hardware. However, relying solely on unsupervised STDP to perform classification tasks is not enough. In this paper, we propose Stabilized Supervised STDP (S2-STDP), a supervised STDP learning rule to train the classification layer of an SNN equipped with unsupervised STDP. S2-STDP integrates error-modulated weight updates that align neuron spikes with desired timestamps derived from the average firing time within the layer. Then, we introduce a training architecture called Paired Competing Neurons (PCN) to further enhance the learning capabilities of our classification layer trained with S2-STDP. PCN associates each class with paired neurons and encourages neuron specialization through intra-class competition. We evaluated our proposed methods on image recognition datasets, including MNIST, Fashion-MNIST, and CIFAR-10. Results showed that our methods outperform current supervised STDP-based state of the art, for comparable architectures and numbers of neurons. Also, the use of PCN enhances the performance of S2-STDP, regardless of the configuration, and without introducing any hyperparameters.Further analysis demonstrated that our methods exhibited improved hyperparameter robustness, which reduces the need for tuning.
Adapting to Change: Robust Counterfactual Explanations in Dynamic Data Landscapes
Aug 04, 2023We introduce a novel semi-supervised Graph Counterfactual Explainer (GCE) methodology, Dynamic GRAph Counterfactual Explainer (DyGRACE). It leverages initial knowledge about the data distribution to search for valid counterfactuals while avoiding using information from potentially outdated decision functions in subsequent time steps. Employing two graph autoencoders (GAEs), DyGRACE learns the representation of each class in a binary classification scenario. The GAEs minimise the reconstruction error between the original graph and its learned representation during training. The method involves (i) optimising a parametric density function (implemented as a logistic regression function) to identify counterfactuals by maximising the factual autoencoder's reconstruction error, (ii) minimising the counterfactual autoencoder's error, and (iii) maximising the similarity between the factual and counterfactual graphs. This semi-supervised approach is independent of an underlying black-box oracle. A logistic regression model is trained on a set of graph pairs to learn weights that aid in finding counterfactuals. At inference, for each unseen graph, the logistic regressor identifies the best counterfactual candidate using these learned weights, while the GAEs can be iteratively updated to represent the continual adaptation of the learned graph representation over iterations. DyGRACE is quite effective and can act as a drift detector, identifying distributional drift based on differences in reconstruction errors between iterations. It avoids reliance on the oracle's predictions in successive iterations, thereby increasing the efficiency of counterfactual discovery. DyGRACE, with its capacity for contrastive learning and drift detection, will offer new avenues for semi-supervised learning and explanation generation.
Gait Cycle-Inspired Learning Strategy for Continuous Prediction of Knee Joint Trajectory from sEMG
Jul 25, 2023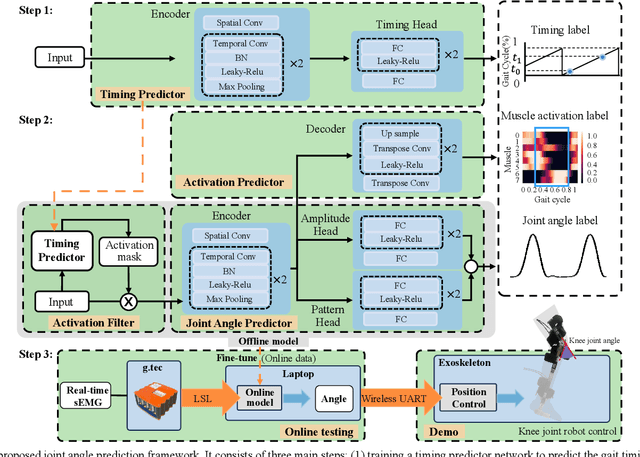
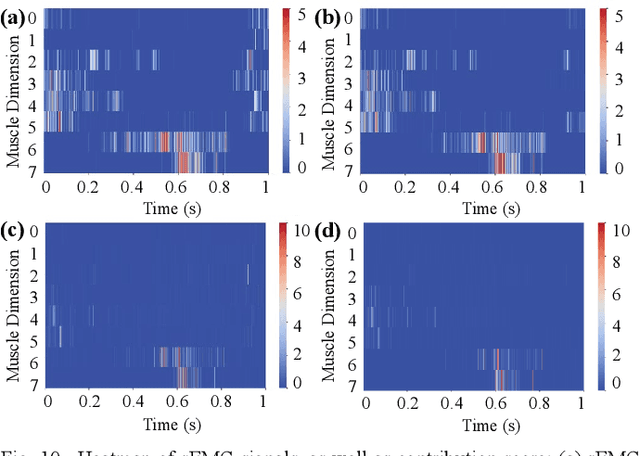
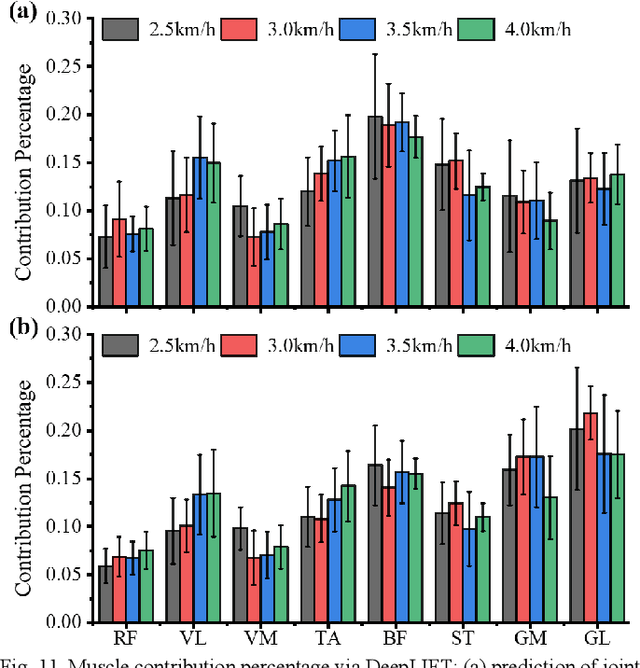
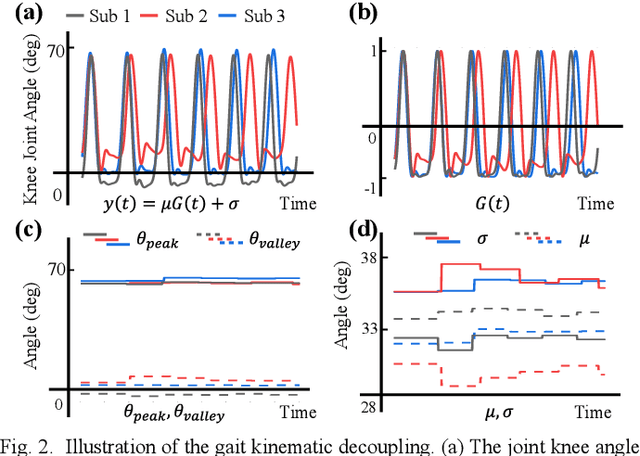
Predicting lower limb motion intent is vital for controlling exoskeleton robots and prosthetic limbs. Surface electromyography (sEMG) attracts increasing attention in recent years as it enables ahead-of-time prediction of motion intentions before actual movement. However, the estimation performance of human joint trajectory remains a challenging problem due to the inter- and intra-subject variations. The former is related to physiological differences (such as height and weight) and preferred walking patterns of individuals, while the latter is mainly caused by irregular and gait-irrelevant muscle activity. This paper proposes a model integrating two gait cycle-inspired learning strategies to mitigate the challenge for predicting human knee joint trajectory. The first strategy is to decouple knee joint angles into motion patterns and amplitudes former exhibit low variability while latter show high variability among individuals. By learning through separate network entities, the model manages to capture both the common and personalized gait features. In the second, muscle principal activation masks are extracted from gait cycles in a prolonged walk. These masks are used to filter out components unrelated to walking from raw sEMG and provide auxiliary guidance to capture more gait-related features. Experimental results indicate that our model could predict knee angles with the average root mean square error (RMSE) of 3.03(0.49) degrees and 50ms ahead of time. To our knowledge this is the best performance in relevant literatures that has been reported, with reduced RMSE by at least 9.5%.
Precise Benchmarking of Explainable AI Attribution Methods
Aug 06, 2023The rationale behind a deep learning model's output is often difficult to understand by humans. EXplainable AI (XAI) aims at solving this by developing methods that improve interpretability and explainability of machine learning models. Reliable evaluation metrics are needed to assess and compare different XAI methods. We propose a novel evaluation approach for benchmarking state-of-the-art XAI attribution methods. Our proposal consists of a synthetic classification model accompanied by its derived ground truth explanations allowing high precision representation of input nodes contributions. We also propose new high-fidelity metrics to quantify the difference between explanations of the investigated XAI method and those derived from the synthetic model. Our metrics allow assessment of explanations in terms of precision and recall separately. Also, we propose metrics to independently evaluate negative or positive contributions of inputs. Our proposal provides deeper insights into XAI methods output. We investigate our proposal by constructing a synthetic convolutional image classification model and benchmarking several widely used XAI attribution methods using our evaluation approach. We compare our results with established prior XAI evaluation metrics. By deriving the ground truth directly from the constructed model in our method, we ensure the absence of bias, e.g., subjective either based on the training set. Our experimental results provide novel insights into the performance of Guided-Backprop and Smoothgrad XAI methods that are widely in use. Both have good precision and recall scores among positively contributing pixels (0.7, 0.76 and 0.7, 0.77, respectively), but poor precision scores among negatively contributing pixels (0.44, 0.61 and 0.47, 0.75, resp.). The recall scores in the latter case remain close. We show that our metrics are among the fastest in terms of execution time.
Adaptive Modeling of Satellite-Derived Nighttime Lights Time-Series for Tracking Urban Change Processes Using Machine Learning
Jun 14, 2023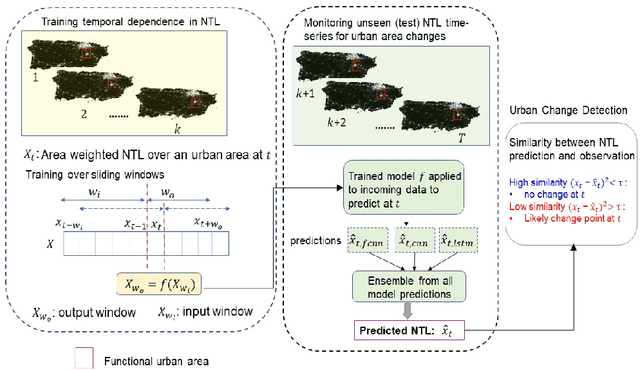
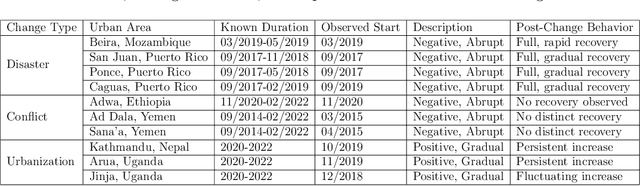
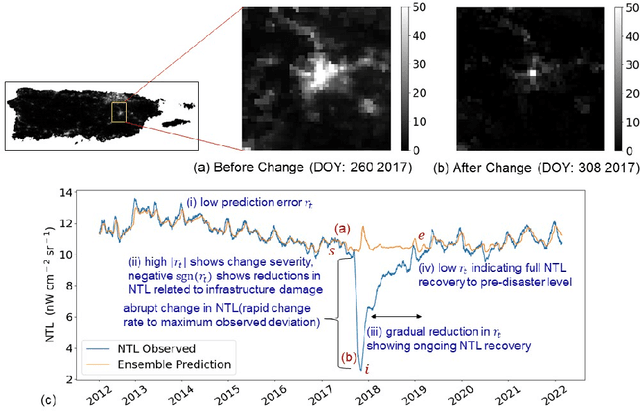
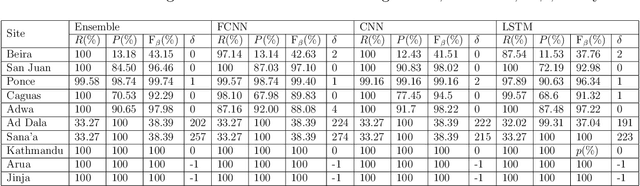
Remotely sensed nighttime lights (NTL) uniquely capture urban change processes that are important to human and ecological well-being, such as urbanization, socio-political conflicts and displacement, impacts from disasters, holidays, and changes in daily human patterns of movement. Though several NTL products are global in extent, intrinsic city-specific factors that affect lighting, such as development levels, and social, economic, and cultural characteristics, are unique to each city, making the urban processes embedded in NTL signatures difficult to characterize, and limiting the scalability of urban change analyses. In this study, we propose a data-driven approach to detect urban changes from daily satellite-derived NTL data records that is adaptive across cities and effective at learning city-specific temporal patterns. The proposed method learns to forecast NTL signatures from past data records using neural networks and allows the use of large volumes of unlabeled data, eliminating annotation effort. Urban changes are detected based on deviations of observed NTL from model forecasts using an anomaly detection approach. Comparing model forecasts with observed NTL also allows identifying the direction of change (positive or negative) and monitoring change severity for tracking recovery. In operationalizing the model, we consider ten urban areas from diverse geographic regions with dynamic NTL time-series and demonstrate the generalizability of the approach for detecting the change processes with different drivers and rates occurring within these urban areas based on NTL deviation. This scalable approach for monitoring changes from daily remote sensing observations efficiently utilizes large data volumes to support continuous monitoring and decision making.
BASEN: Time-Domain Brain-Assisted Speech Enhancement Network with Convolutional Cross Attention in Multi-talker Conditions
May 17, 2023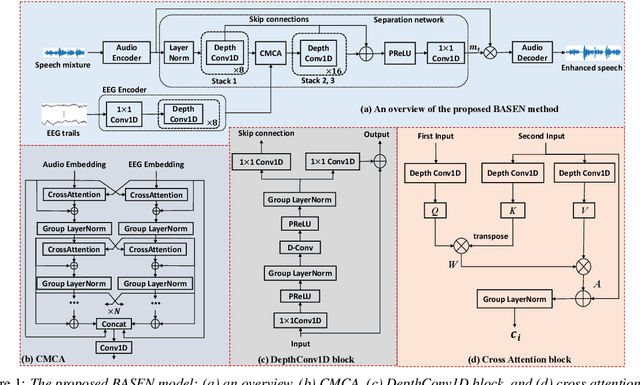
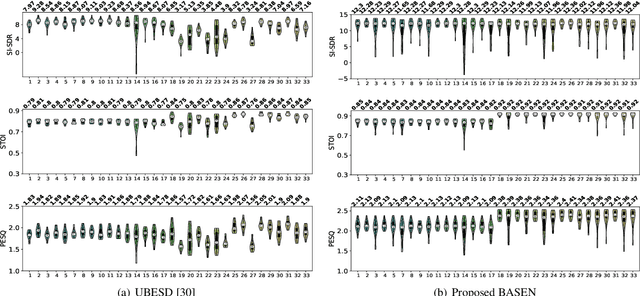
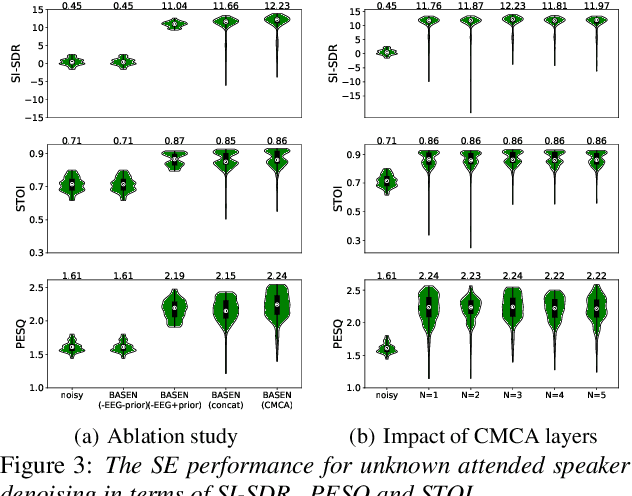
Time-domain single-channel speech enhancement (SE) still remains challenging to extract the target speaker without any prior information on multi-talker conditions. It has been shown via auditory attention decoding that the brain activity of the listener contains the auditory information of the attended speaker. In this paper, we thus propose a novel time-domain brain-assisted SE network (BASEN) incorporating electroencephalography (EEG) signals recorded from the listener for extracting the target speaker from monaural speech mixtures. The proposed BASEN is based on the fully-convolutional time-domain audio separation network. In order to fully leverage the complementary information contained in the EEG signals, we further propose a convolutional multi-layer cross attention module to fuse the dual-branch features. Experimental results on a public dataset show that the proposed model outperforms the state-of-the-art method in several evaluation metrics. The reproducible code is available at https://github.com/jzhangU/Basen.git.
Learning Structured Components: Towards Modular and Interpretable Multivariate Time Series Forecasting
May 24, 2023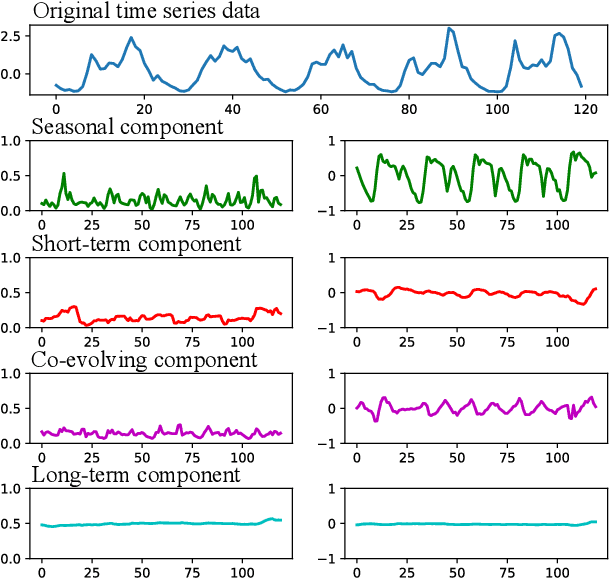

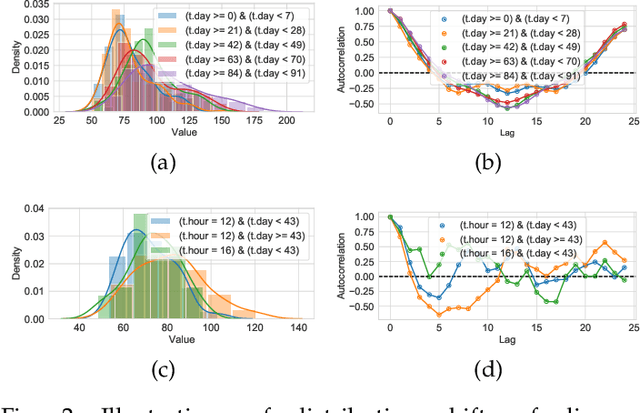
Multivariate time-series (MTS) forecasting is a paramount and fundamental problem in many real-world applications. The core issue in MTS forecasting is how to effectively model complex spatial-temporal patterns. In this paper, we develop a modular and interpretable forecasting framework, which seeks to individually model each component of the spatial-temporal patterns. We name this framework SCNN, short for Structured Component-based Neural Network. SCNN works with a pre-defined generative process of MTS, which arithmetically characterizes the latent structure of the spatial-temporal patterns. In line with its reverse process, SCNN decouples MTS data into structured and heterogeneous components and then respectively extrapolates the evolution of these components, the dynamics of which is more traceable and predictable than the original MTS. Extensive experiments are conducted to demonstrate that SCNN can achieve superior performance over state-of-the-art models on three real-world datasets. Additionally, we examine SCNN with different configurations and perform in-depth analyses of the properties of SCNN.
Efficient Strongly Polynomial Algorithms for Quantile Regression
Jul 14, 2023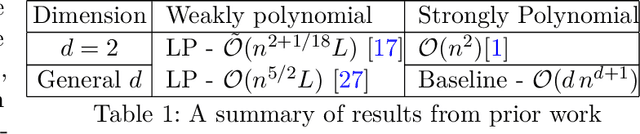


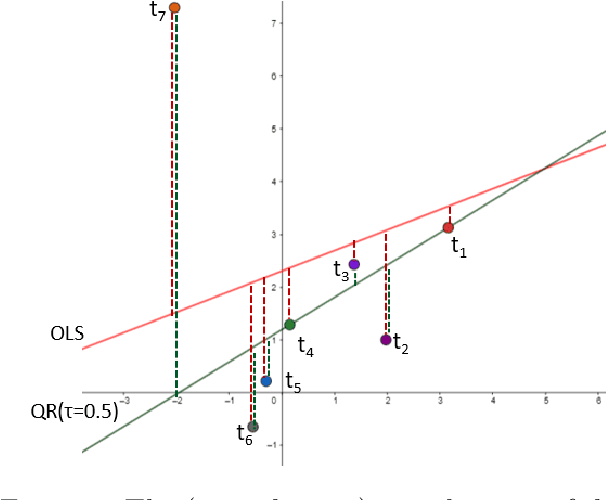
Linear Regression is a seminal technique in statistics and machine learning, where the objective is to build linear predictive models between a response (i.e., dependent) variable and one or more predictor (i.e., independent) variables. In this paper, we revisit the classical technique of Quantile Regression (QR), which is statistically a more robust alternative to the other classical technique of Ordinary Least Square Regression (OLS). However, while there exist efficient algorithms for OLS, almost all of the known results for QR are only weakly polynomial. Towards filling this gap, this paper proposes several efficient strongly polynomial algorithms for QR for various settings. For two dimensional QR, making a connection to the geometric concept of $k$-set, we propose an algorithm with a deterministic worst-case time complexity of $\mathcal{O}(n^{4/3} polylog(n))$ and an expected time complexity of $\mathcal{O}(n^{4/3})$ for the randomized version. We also propose a randomized divide-and-conquer algorithm -- RandomizedQR with an expected time complexity of $\mathcal{O}(n\log^2{(n)})$ for two dimensional QR problem. For the general case with more than two dimensions, our RandomizedQR algorithm has an expected time complexity of $\mathcal{O}(n^{d-1}\log^2{(n)})$.
Diffusion Models for Time Series Applications: A Survey
May 01, 2023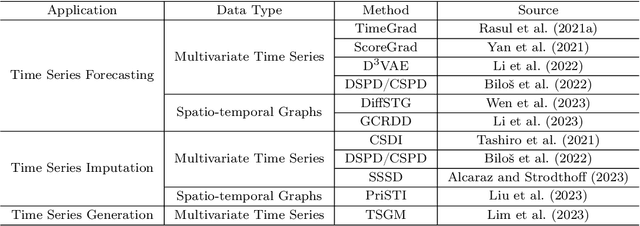
Diffusion models, a family of generative models based on deep learning, have become increasingly prominent in cutting-edge machine learning research. With a distinguished performance in generating samples that resemble the observed data, diffusion models are widely used in image, video, and text synthesis nowadays. In recent years, the concept of diffusion has been extended to time series applications, and many powerful models have been developed. Considering the deficiency of a methodical summary and discourse on these models, we provide this survey as an elementary resource for new researchers in this area and also an inspiration to motivate future research. For better understanding, we include an introduction about the basics of diffusion models. Except for this, we primarily focus on diffusion-based methods for time series forecasting, imputation, and generation, and present them respectively in three individual sections. We also compare different methods for the same application and highlight their connections if applicable. Lastly, we conclude the common limitation of diffusion-based methods and highlight potential future research directions.