 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Efficient Interior-Point Method for Online Convex Optimization
Jul 21, 2023
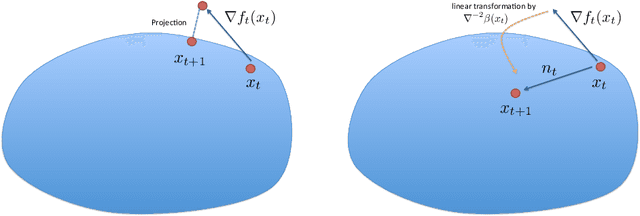
A new algorithm for regret minimization in online convex optimization is described. The regret of the algorithm after $T$ time periods is $O(\sqrt{T \log T})$ - which is the minimum possible up to a logarithmic term. In addition, the new algorithm is adaptive, in the sense that the regret bounds hold not only for the time periods $1,\ldots,T$ but also for every sub-interval $s,s+1,\ldots,t$. The running time of the algorithm matches that of newly introduced interior point algorithms for regret minimization: in $n$-dimensional space, during each iteration the new algorithm essentially solves a system of linear equations of order $n$, rather than solving some constrained convex optimization problem in $n$ dimensions and possibly many constraints.
CrystalGPT: Enhancing system-to-system transferability in crystallization prediction and control using time-series-transformers
May 31, 2023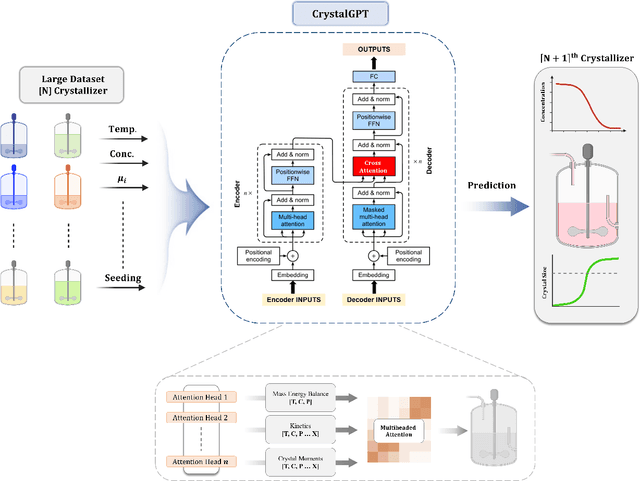
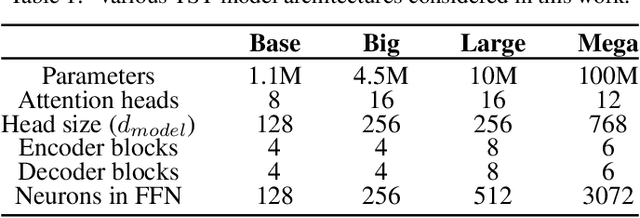
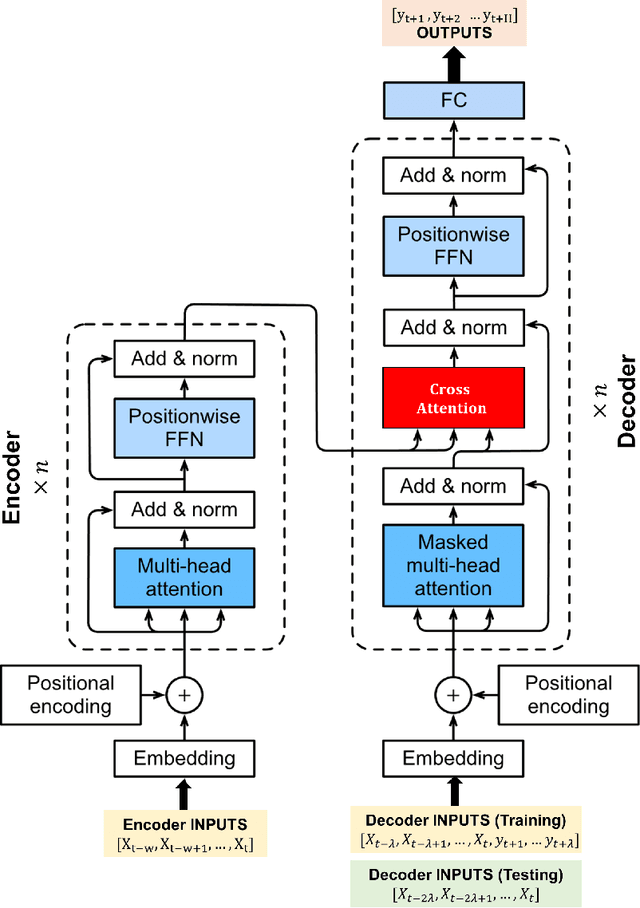
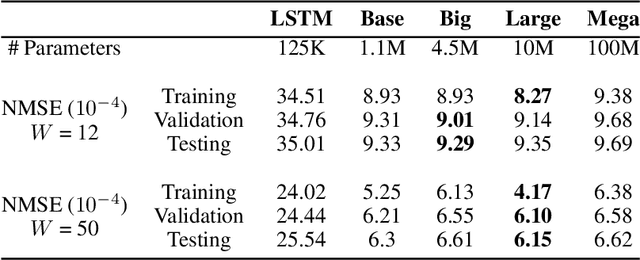
For prediction and real-time control tasks, machine-learning (ML)-based digital twins are frequently employed. However, while these models are typically accurate, they are custom-designed for individual systems, making system-to-system (S2S) transferability difficult. This occurs even when substantial similarities exist in the process dynamics across different chemical systems. To address this challenge, we developed a novel time-series-transformer (TST) framework that exploits the powerful transfer learning capabilities inherent in transformer algorithms. This was demonstrated using readily available process data obtained from different crystallizers operating under various operational scenarios. Using this extensive dataset, we trained a TST model (CrystalGPT) to exhibit remarkable S2S transferability not only across all pre-established systems, but also to an unencountered system. CrystalGPT achieved a cumulative error across all systems, which is eight times superior to that of existing ML models. Additionally, we coupled CrystalGPT with a predictive controller to reduce the variance in setpoint tracking to just 1%.
A faster and simpler algorithm for learning shallow networks
Jul 24, 2023We revisit the well-studied problem of learning a linear combination of $k$ ReLU activations given labeled examples drawn from the standard $d$-dimensional Gaussian measure. Chen et al. [CDG+23] recently gave the first algorithm for this problem to run in $\text{poly}(d,1/\varepsilon)$ time when $k = O(1)$, where $\varepsilon$ is the target error. More precisely, their algorithm runs in time $(d/\varepsilon)^{\mathrm{quasipoly}(k)}$ and learns over multiple stages. Here we show that a much simpler one-stage version of their algorithm suffices, and moreover its runtime is only $(d/\varepsilon)^{O(k^2)}$.
TEDi: Temporally-Entangled Diffusion for Long-Term Motion Synthesis
Jul 29, 2023The gradual nature of a diffusion process that synthesizes samples in small increments constitutes a key ingredient of Denoising Diffusion Probabilistic Models (DDPM), which have presented unprecedented quality in image synthesis and been recently explored in the motion domain. In this work, we propose to adapt the gradual diffusion concept (operating along a diffusion time-axis) into the temporal-axis of the motion sequence. Our key idea is to extend the DDPM framework to support temporally varying denoising, thereby entangling the two axes. Using our special formulation, we iteratively denoise a motion buffer that contains a set of increasingly-noised poses, which auto-regressively produces an arbitrarily long stream of frames. With a stationary diffusion time-axis, in each diffusion step we increment only the temporal-axis of the motion such that the framework produces a new, clean frame which is removed from the beginning of the buffer, followed by a newly drawn noise vector that is appended to it. This new mechanism paves the way towards a new framework for long-term motion synthesis with applications to character animation and other domains.
Event-based Vision for Early Prediction of Manipulation Actions
Jul 26, 2023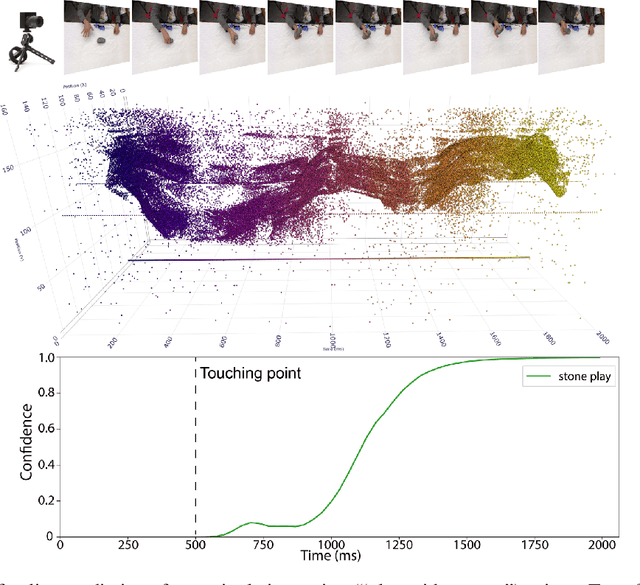
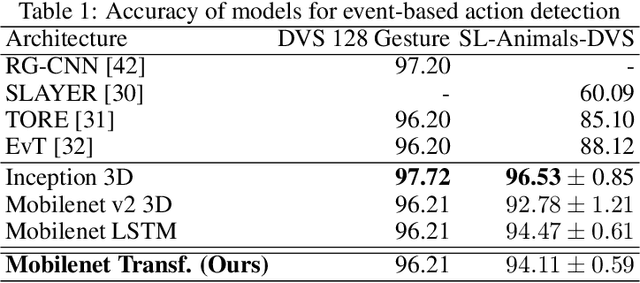
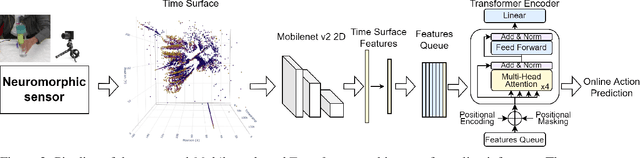

Neuromorphic visual sensors are artificial retinas that output sequences of asynchronous events when brightness changes occur in the scene. These sensors offer many advantages including very high temporal resolution, no motion blur and smart data compression ideal for real-time processing. In this study, we introduce an event-based dataset on fine-grained manipulation actions and perform an experimental study on the use of transformers for action prediction with events. There is enormous interest in the fields of cognitive robotics and human-robot interaction on understanding and predicting human actions as early as possible. Early prediction allows anticipating complex stages for planning, enabling effective and real-time interaction. Our Transformer network uses events to predict manipulation actions as they occur, using online inference. The model succeeds at predicting actions early on, building up confidence over time and achieving state-of-the-art classification. Moreover, the attention-based transformer architecture allows us to study the role of the spatio-temporal patterns selected by the model. Our experiments show that the Transformer network captures action dynamic features outperforming video-based approaches and succeeding with scenarios where the differences between actions lie in very subtle cues. Finally, we release the new event dataset, which is the first in the literature for manipulation action recognition. Code will be available at https://github.com/DaniDeniz/EventVisionTransformer.
Combinatorial Auctions and Graph Neural Networks for Local Energy Flexibility Markets
Jul 25, 2023This paper proposes a new combinatorial auction framework for local energy flexibility markets, which addresses the issue of prosumers' inability to bundle multiple flexibility time intervals. To solve the underlying NP-complete winner determination problems, we present a simple yet powerful heterogeneous tri-partite graph representation and design graph neural network-based models. Our models achieve an average optimal value deviation of less than 5\% from an off-the-shelf optimization tool and show linear inference time complexity compared to the exponential complexity of the commercial solver. Contributions and results demonstrate the potential of using machine learning to efficiently allocate energy flexibility resources in local markets and solving optimization problems in general.
Causal Disentanglement Hidden Markov Model for Fault Diagnosis
Aug 06, 2023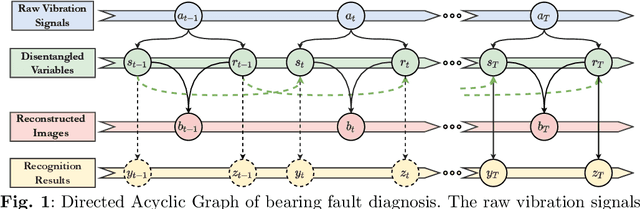
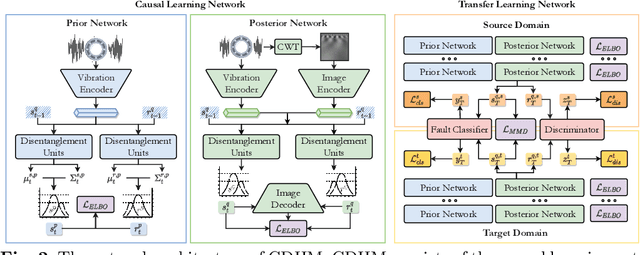
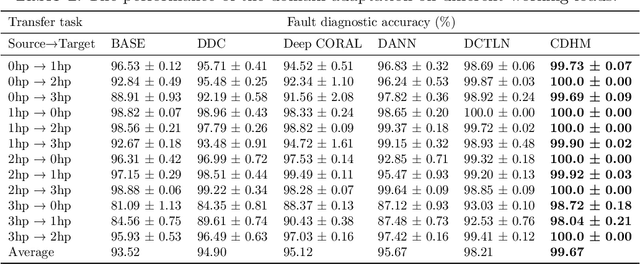
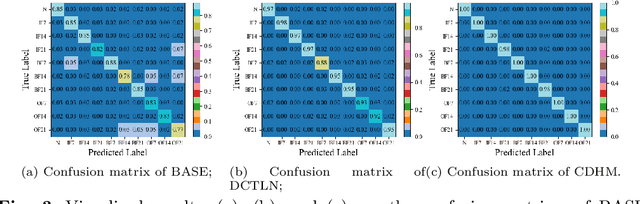
In modern industries, fault diagnosis has been widely applied with the goal of realizing predictive maintenance. The key issue for the fault diagnosis system is to extract representative characteristics of the fault signal and then accurately predict the fault type. In this paper, we propose a Causal Disentanglement Hidden Markov model (CDHM) to learn the causality in the bearing fault mechanism and thus, capture their characteristics to achieve a more robust representation. Specifically, we make full use of the time-series data and progressively disentangle the vibration signal into fault-relevant and fault-irrelevant factors. The ELBO is reformulated to optimize the learning of the causal disentanglement Markov model. Moreover, to expand the scope of the application, we adopt unsupervised domain adaptation to transfer the learned disentangled representations to other working environments. Experiments were conducted on the CWRU dataset and IMS dataset. Relevant results validate the superiority of the proposed method.
DF2M: An Explainable Deep Bayesian Nonparametric Model for High-Dimensional Functional Time Series
May 23, 2023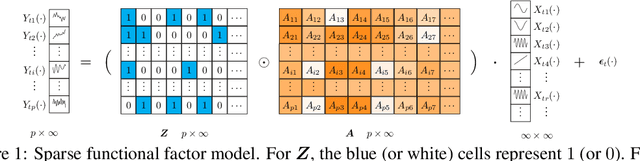
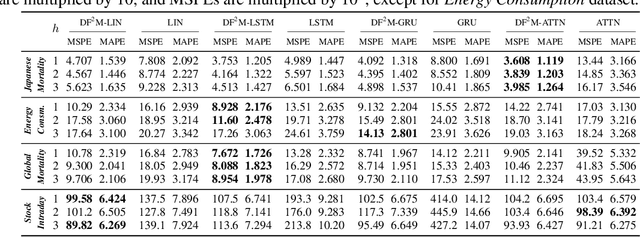
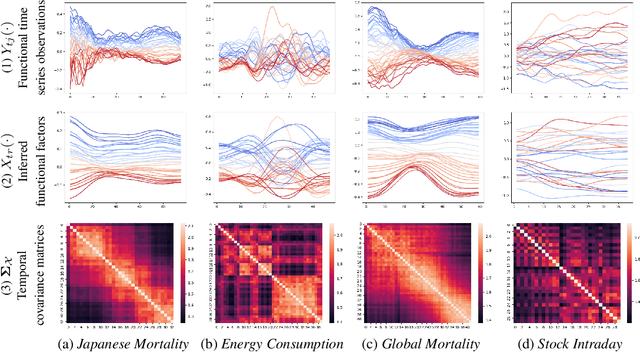
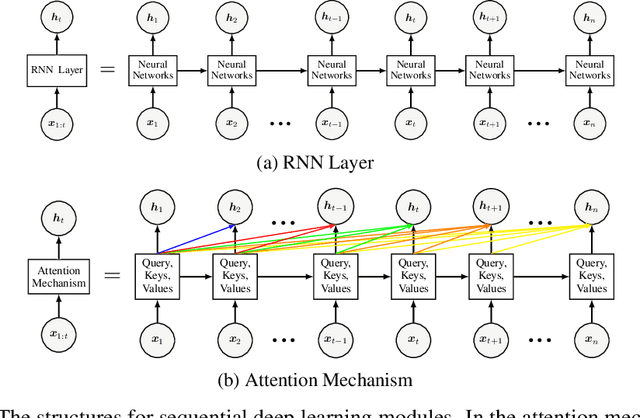
In this paper, we present Deep Functional Factor Model (DF2M), a Bayesian nonparametric model for analyzing high-dimensional functional time series. The DF2M makes use of the Indian Buffet Process and the multi-task Gaussian Process with a deep kernel function to capture non-Markovian and nonlinear temporal dynamics. Unlike many black-box deep learning models, the DF2M provides an explainable way to use neural networks by constructing a factor model and incorporating deep neural networks within the kernel function. Additionally, we develop a computationally efficient variational inference algorithm for inferring the DF2M. Empirical results from four real-world datasets demonstrate that the DF2M offers better explainability and superior predictive accuracy compared to conventional deep learning models for high-dimensional functional time series.
InTune: Reinforcement Learning-based Data Pipeline Optimization for Deep Recommendation Models
Aug 13, 2023Deep learning-based recommender models (DLRMs) have become an essential component of many modern recommender systems. Several companies are now building large compute clusters reserved only for DLRM training, driving new interest in cost- and time- saving optimizations. The systems challenges faced in this setting are unique; while typical deep learning training jobs are dominated by model execution, the most important factor in DLRM training performance is often online data ingestion. In this paper, we explore the unique characteristics of this data ingestion problem and provide insights into DLRM training pipeline bottlenecks and challenges. We study real-world DLRM data processing pipelines taken from our compute cluster at Netflix to observe the performance impacts of online ingestion and to identify shortfalls in existing pipeline optimizers. We find that current tooling either yields sub-optimal performance, frequent crashes, or else requires impractical cluster re-organization to adopt. Our studies lead us to design and build a new solution for data pipeline optimization, InTune. InTune employs a reinforcement learning (RL) agent to learn how to distribute the CPU resources of a trainer machine across a DLRM data pipeline to more effectively parallelize data loading and improve throughput. Our experiments show that InTune can build an optimized data pipeline configuration within only a few minutes, and can easily be integrated into existing training workflows. By exploiting the responsiveness and adaptability of RL, InTune achieves higher online data ingestion rates than existing optimizers, thus reducing idle times in model execution and increasing efficiency. We apply InTune to our real-world cluster, and find that it increases data ingestion throughput by as much as 2.29X versus state-of-the-art data pipeline optimizers while also improving both CPU & GPU utilization.
YOLOrtho -- A Unified Framework for Teeth Enumeration and Dental Disease Detection
Aug 11, 2023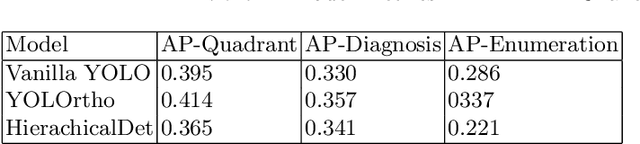
Detecting dental diseases through panoramic X-rays images is a standard procedure for dentists. Normally, a dentist need to identify diseases and find the infected teeth. While numerous machine learning models adopting this two-step procedure have been developed, there has not been an end-to-end model that can identify teeth and their associated diseases at the same time. To fill the gap, we develop YOLOrtho, a unified framework for teeth enumeration and dental disease detection. We develop our model on Dentex Challenge 2023 data, which consists of three distinct types of annotated data. The first part is labeled with quadrant, and the second part is labeled with quadrant and enumeration and the third part is labeled with quadrant, enumeration and disease. To further improve detection, we make use of Tufts Dental public dataset. To fully utilize the data and learn both teeth detection and disease identification simultaneously, we formulate diseases as attributes attached to their corresponding teeth. Due to the nature of position relation in teeth enumeration, We replace convolution layer with CoordConv in our model to provide more position information for the model. We also adjust the model architecture and insert one more upsampling layer in FPN in favor of large object detection. Finally, we propose a post-process strategy for teeth layout that corrects teeth enumeration based on linear sum assignment. Results from experiments show that our model exceeds large Diffusion-based model.