 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RT-K-Net: Revisiting K-Net for Real-Time Panoptic Segmentation
May 02, 2023
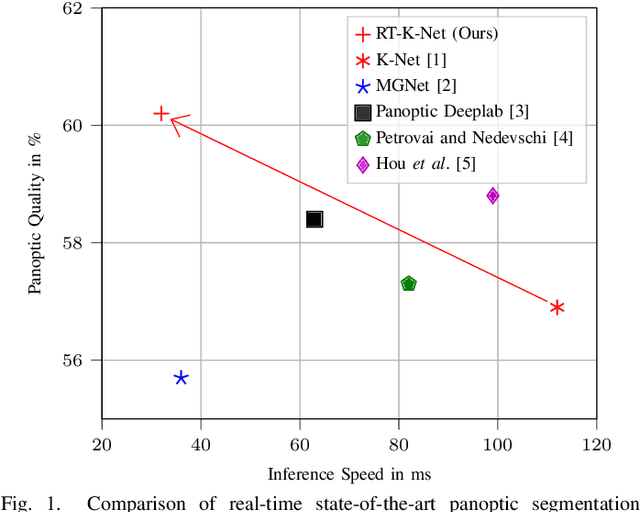
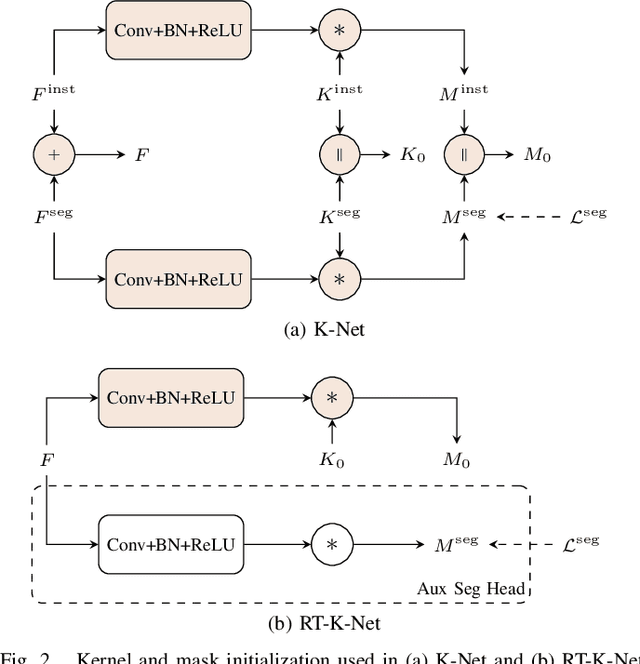
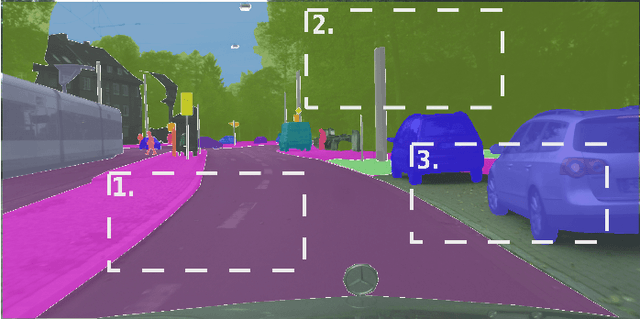

Panoptic segmentation is one of the most challenging scene parsing tasks, combining the tasks of semantic segmentation and instance segmentation. While much progress has been made, few works focus on the real-time application of panoptic segmentation methods. In this paper, we revisit the recently introduced K-Net architecture. We propose vital changes to the architecture, training, and inference procedure, which massively decrease latency and improve performance. Our resulting RT-K-Net sets a new state-of-the-art performance for real-time panoptic segmentation methods on the Cityscapes dataset and shows promising results on the challenging Mapillary Vistas dataset. On Cityscapes, RT-K-Net reaches 60.2 % PQ with an average inference time of 32 ms for full resolution 1024x2048 pixel images on a single Titan RTX GPU. On Mapillary Vistas, RT-K-Net reaches 33.2 % PQ with an average inference time of 69 ms. Source code is available at https://github.com/markusschoen/RT-K-Net.
On Neural Network approximation of ideal adversarial attack and convergence of adversarial training
Jul 30, 2023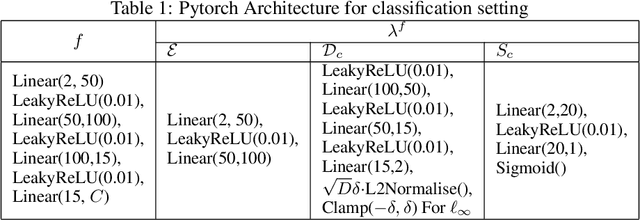
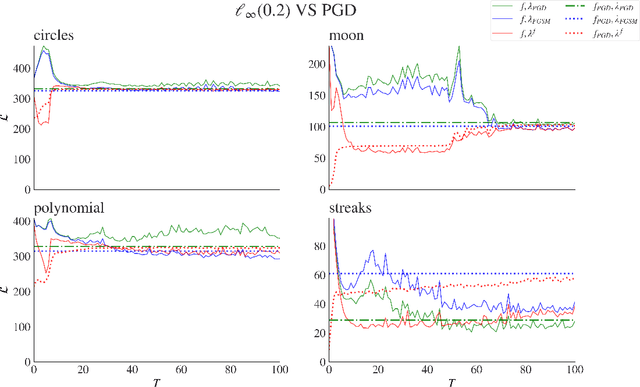
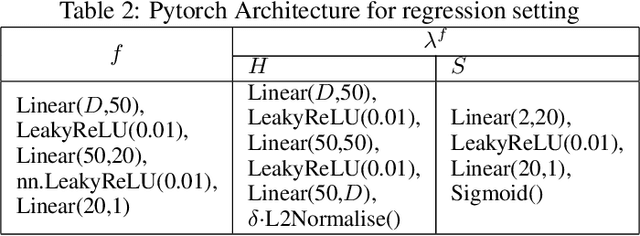
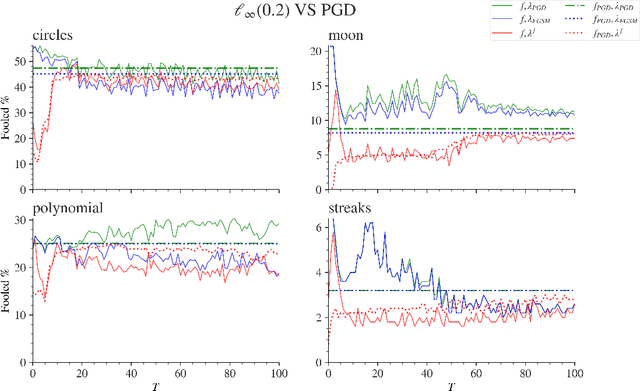
Adversarial attacks are usually expressed in terms of a gradient-based operation on the input data and model, this results in heavy computations every time an attack is generated. In this work, we solidify the idea of representing adversarial attacks as a trainable function, without further gradient computation. We first motivate that the theoretical best attacks, under proper conditions, can be represented as smooth piece-wise functions (piece-wise H\"older functions). Then we obtain an approximation result of such functions by a neural network. Subsequently, we emulate the ideal attack process by a neural network and reduce the adversarial training to a mathematical game between an attack network and a training model (a defense network). We also obtain convergence rates of adversarial loss in terms of the sample size $n$ for adversarial training in such a setting.
Stylized Projected GAN: A Novel Architecture for Fast and Realistic Image Generation
Jul 30, 2023
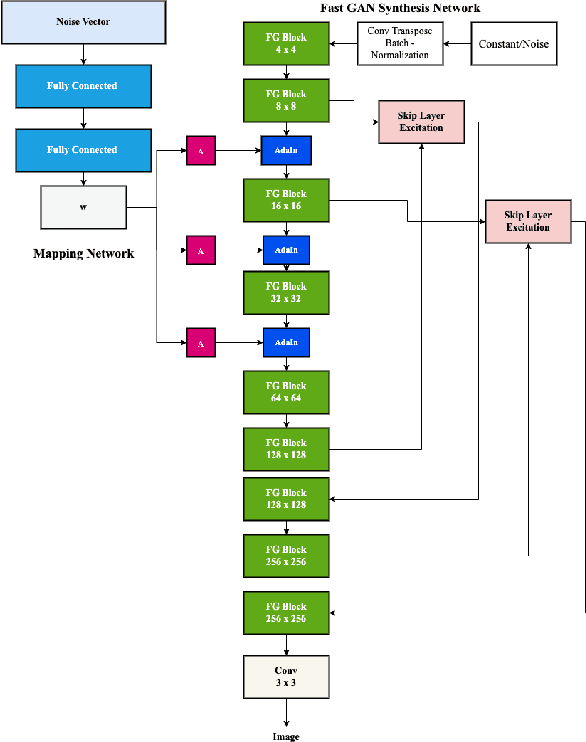
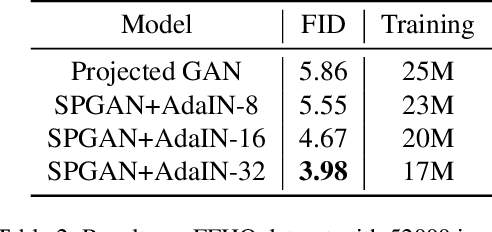
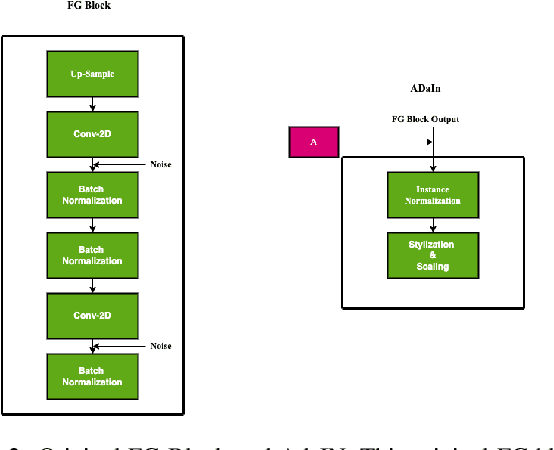
Generative Adversarial Networks are used for generating the data using a generator and a discriminator, GANs usually produce high-quality images, but training GANs in an adversarial setting is a difficult task. GANs require high computation power and hyper-parameter regularization for converging. Projected GANs tackle the training difficulty of GANs by using transfer learning to project the generated and real samples into a pre-trained feature space. Projected GANs improve the training time and convergence but produce artifacts in the generated images which reduce the quality of the generated samples, we propose an optimized architecture called Stylized Projected GANs which integrates the mapping network of the Style GANs with Skip Layer Excitation of Fast GAN. The integrated modules are incorporated within the generator architecture of the Fast GAN to mitigate the problem of artifacts in the generated images.
Impact of Free-carrier Nonlinearities on Silicon Microring-based Reservoir Computing
Jul 13, 2023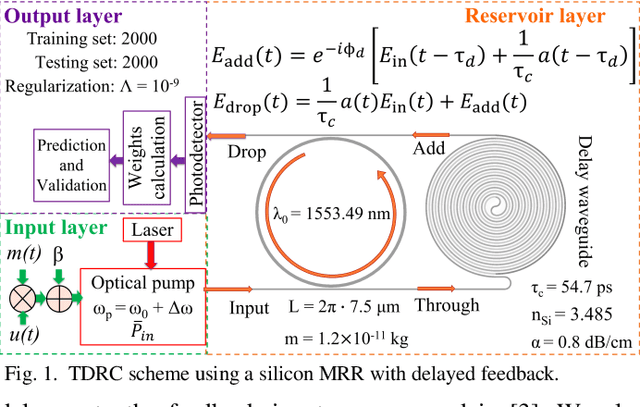
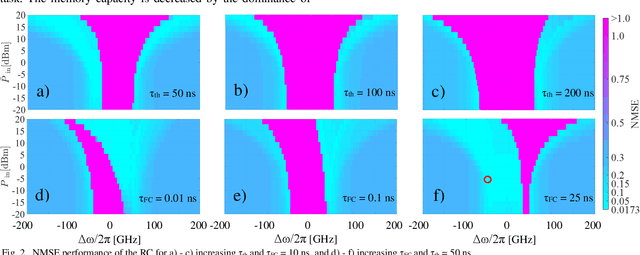

We quantify the impact of thermo-optic and free-carrier effects on time-delay reservoir computing using a silicon microring resonator. We identify pump power and frequency detuning ranges with NMSE less than 0.05 for the NARMA-10 task depending on the time constants of the two considered effects.
FuNToM: Functional Modeling of RF Circuits Using a Neural Network Assisted Two-Port Analysis Method
Aug 03, 2023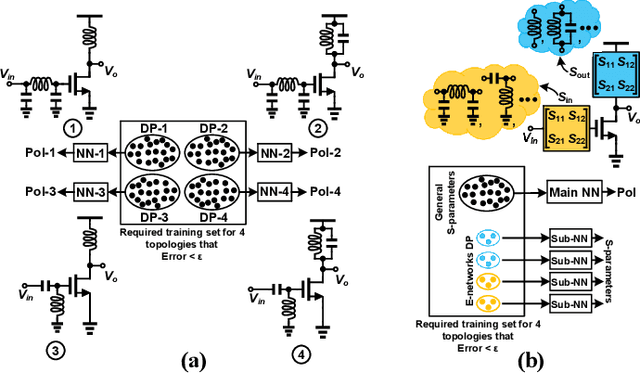
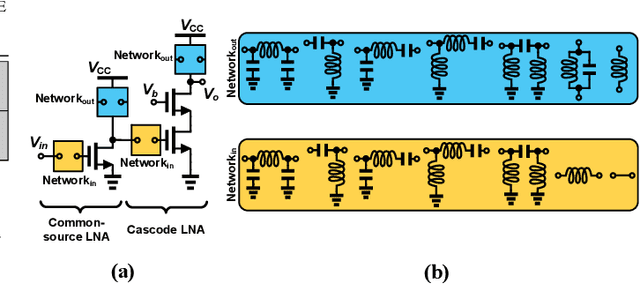
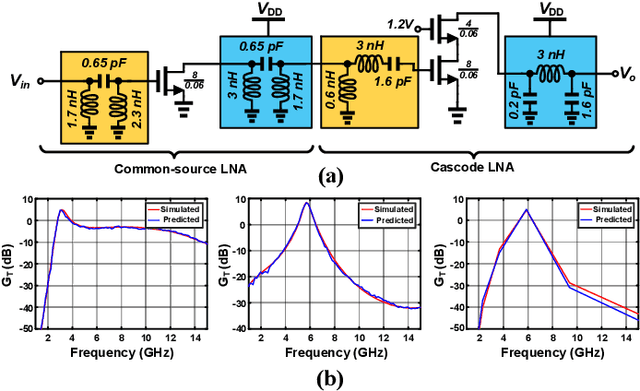
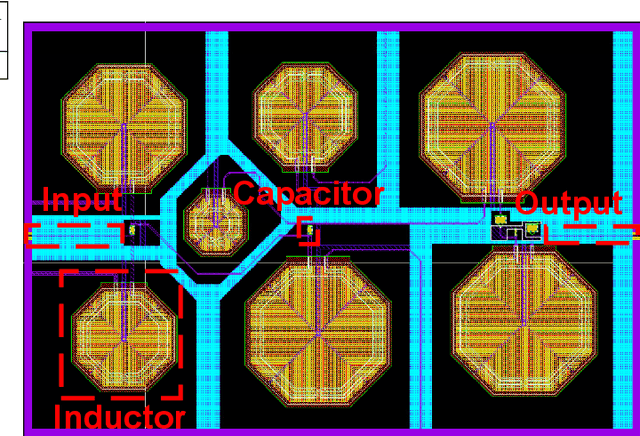
Automatic synthesis of analog and Radio Frequency (RF) circuits is a trending approach that requires an efficient circuit modeling method. This is due to the expensive cost of running a large number of simulations at each synthesis cycle. Artificial intelligence methods are promising approaches for circuit modeling due to their speed and relative accuracy. However, existing approaches require a large amount of training data, which is still collected using simulation runs. In addition, such approaches collect a whole separate dataset for each circuit topology even if a single element is added or removed. These matters are only exacerbated by the need for post-layout modeling simulations, which take even longer. To alleviate these drawbacks, in this paper, we present FuNToM, a functional modeling method for RF circuits. FuNToM leverages the two-port analysis method for modeling multiple topologies using a single main dataset and multiple small datasets. It also leverages neural networks which have shown promising results in predicting the behavior of circuits. Our results show that for multiple RF circuits, in comparison to the state-of-the-art works, while maintaining the same accuracy, the required training data is reduced by 2.8x - 10.9x. In addition, FuNToM needs 176.8x - 188.6x less time for collecting the training set in post-layout modeling.
Digital twin brain: a bridge between biological intelligence and artificial intelligence
Aug 03, 2023
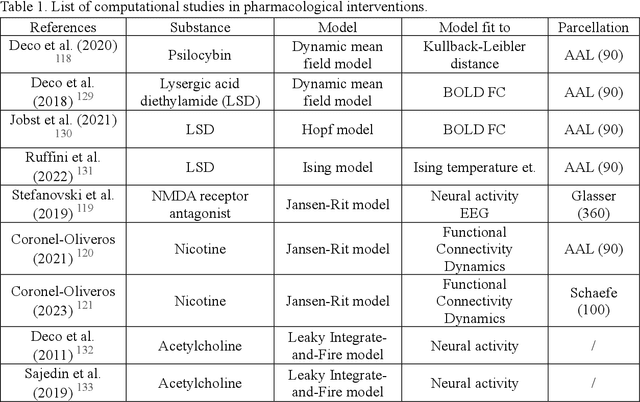
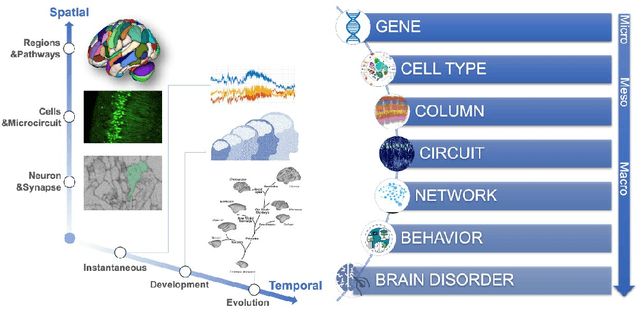
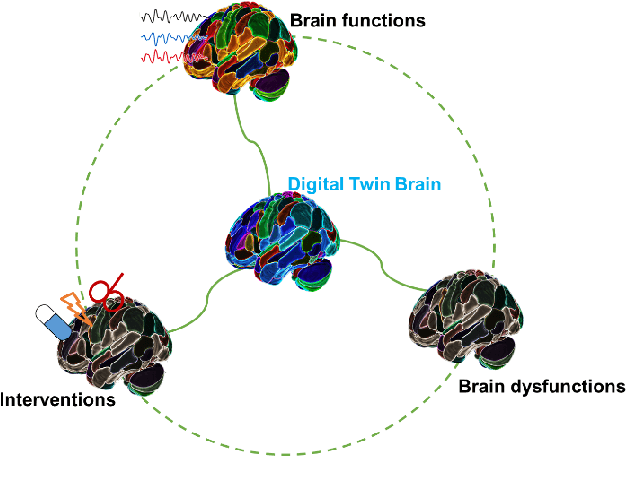
In recent years, advances in neuroscience and artificial intelligence have paved the way for unprecedented opportunities for understanding the complexity of the brain and its emulation by computational systems. Cutting-edge advancements in neuroscience research have revealed the intricate relationship between brain structure and function, while the success of artificial neural networks highlights the importance of network architecture. Now is the time to bring them together to better unravel how intelligence emerges from the brain's multiscale repositories. In this review, we propose the Digital Twin Brain (DTB) as a transformative platform that bridges the gap between biological and artificial intelligence. It consists of three core elements: the brain structure that is fundamental to the twinning process, bottom-layer models to generate brain functions, and its wide spectrum of applications. Crucially, brain atlases provide a vital constraint, preserving the brain's network organization within the DTB. Furthermore, we highlight open questions that invite joint efforts from interdisciplinary fields and emphasize the far-reaching implications of the DTB. The DTB can offer unprecedented insights into the emergence of intelligence and neurological disorders, which holds tremendous promise for advancing our understanding of both biological and artificial intelligence, and ultimately propelling the development of artificial general intelligence and facilitating precision mental healthcare.
End-to-End Reinforcement Learning of Koopman Models for Economic Nonlinear MPC
Aug 03, 2023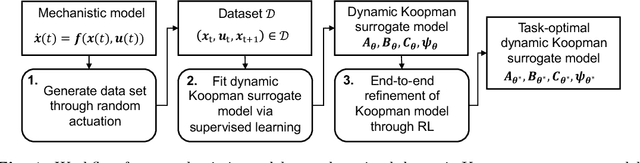
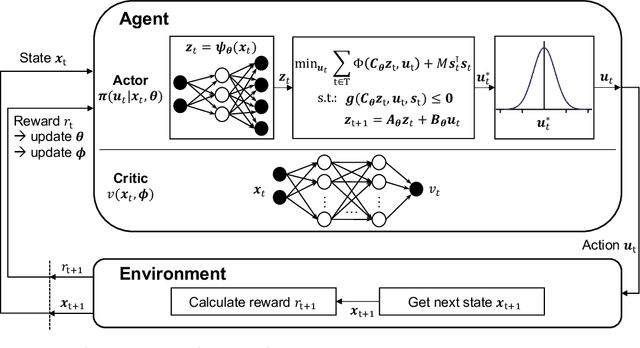
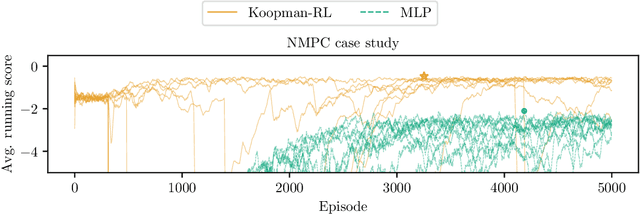
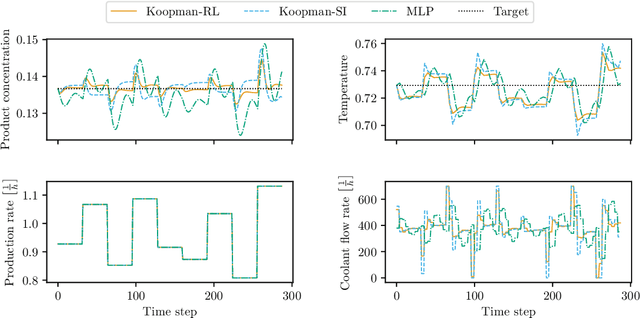
(Economic) nonlinear model predictive control ((e)NMPC) requires dynamic system models that are sufficiently accurate in all relevant state-space regions. These models must also be computationally cheap enough to ensure real-time tractability. Data-driven surrogate models for mechanistic models can be used to reduce the computational burden of (e)NMPC; however, such models are typically trained by system identification for maximum average prediction accuracy on simulation samples and perform suboptimally as part of actual (e)NMPC. We present a method for end-to-end reinforcement learning of dynamic surrogate models for optimal performance in (e)NMPC applications, resulting in predictive controllers that strike a favorable balance between control performance and computational demand. We validate our method on two applications derived from an established nonlinear continuous stirred-tank reactor model. We compare the controller performance to that of MPCs utilizing models trained by the prevailing maximum prediction accuracy paradigm, and model-free neural network controllers trained using reinforcement learning. We show that our method matches the performance of the model-free neural network controllers while consistently outperforming models derived from system identification. Additionally, we show that the MPC policies can react to changes in the control setting without retraining.
PoissonNet: Resolution-Agnostic 3D Shape Reconstruction using Fourier Neural Operators
Aug 03, 2023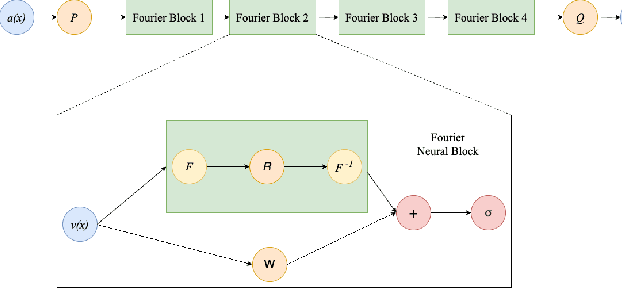
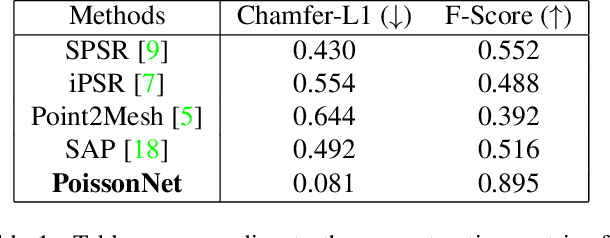

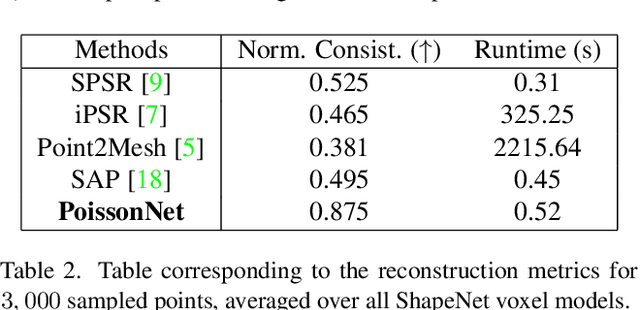
We introduce PoissonNet, an architecture for shape reconstruction that addresses the challenge of recovering 3D shapes from points. Traditional deep neural networks face challenges with common 3D shape discretization techniques due to their computational complexity at higher resolutions. To overcome this, we leverage Fourier Neural Operators (FNOs) to solve the Poisson equation and reconstruct a mesh from oriented point cloud measurements. PoissonNet exhibits two main advantages. First, it enables efficient training on low-resolution data while achieving comparable performance at high-resolution evaluation, thanks to the resolution-agnostic nature of FNOs. This feature allows for one-shot super-resolution. Second, our method surpasses existing approaches in reconstruction quality while being differentiable. Overall, our proposed method not only improves upon the limitations of classical deep neural networks in shape reconstruction but also achieves superior results in terms of reconstruction quality, running time, and resolution flexibility. Furthermore, we demonstrate that the Poisson surface reconstruction problem is well-posed in the limit case by showing a universal approximation theorem for the solution operator of the Poisson equation with distributional data utilizing the Fourier Neuronal Operator, which provides a theoretical foundation for our numerical results. The code to reproduce the experiments is available on: \url{https://github.com/arsenal9971/PoissonNet}.
A Comparative Analysis of Machine Learning Methods for Lane Change Intention Recognition Using Vehicle Trajectory Data
Jul 28, 2023
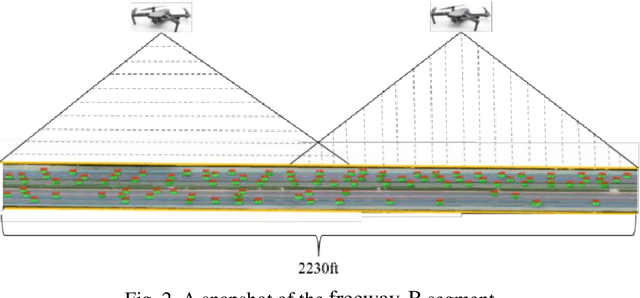
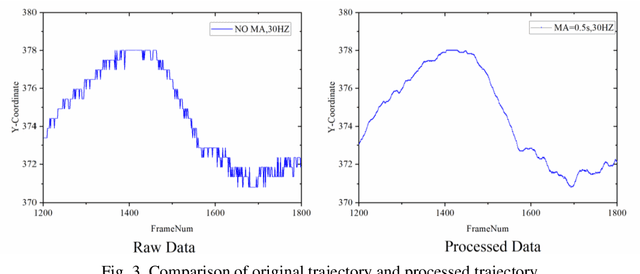
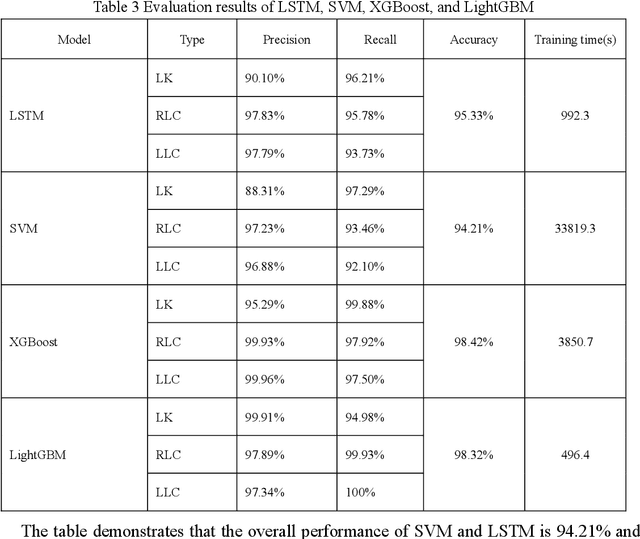
Accurately detecting and predicting lane change (LC)processes can help autonomous vehicles better understand their surrounding environment, recognize potential safety hazards, and improve traffic safety. This paper focuses on LC processes and compares different machine learning methods' performance to recognize LC intention from high-dimensionality time series data. To validate the performance of the proposed models, a total number of 1023 vehicle trajectories is extracted from the CitySim dataset. For LC intention recognition issues, the results indicate that with ninety-eight percent of classification accuracy, ensemble methods reduce the impact of Type II and Type III classification errors. Without sacrificing recognition accuracy, the LightGBM demonstrates a sixfold improvement in model training efficiency than the XGBoost algorithm.
Surface Geometry Processing: An Efficient Normal-based Detail Representation
Jul 16, 2023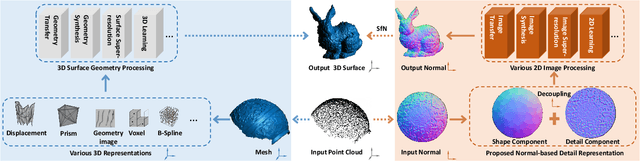
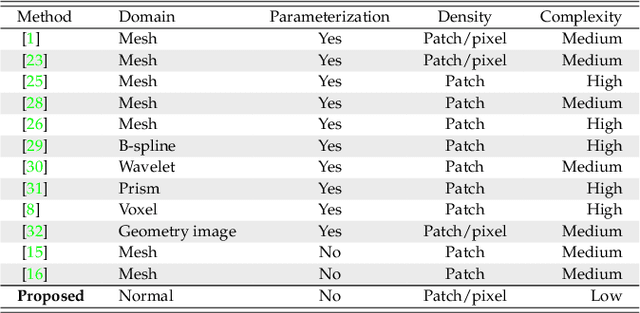
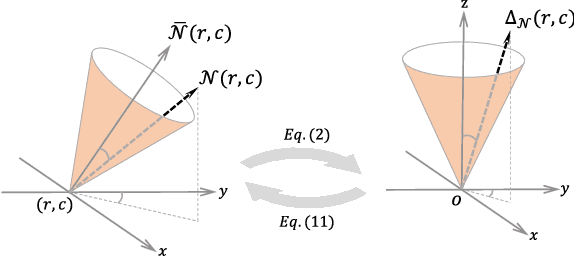
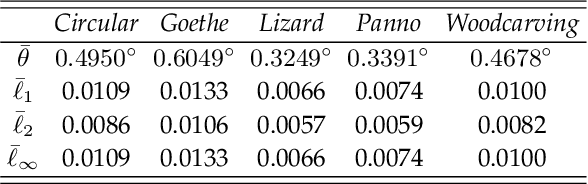
With the rapid development of high-resolution 3D vision applications, the traditional way of manipulating surface detail requires considerable memory and computing time. To address these problems, we introduce an efficient surface detail processing framework in 2D normal domain, which extracts new normal feature representations as the carrier of micro geometry structures that are illustrated both theoretically and empirically in this article. Compared with the existing state of the arts, we verify and demonstrate that the proposed normal-based representation has three important properties, including detail separability, detail transferability and detail idempotence. Finally, three new schemes are further designed for geometric surface detail processing applications, including geometric texture synthesis, geometry detail transfer, and 3D surface super-resolution. Theoretical analysis and experimental results on the latest benchmark dataset verify the effectiveness and versatility of our normal-based representation, which accepts 30 times of the input surface vertices but at the same time only takes 6.5% memory cost and 14.0% running time in comparison with existing competing algorithms.
* 16 pages, 22 figures