 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Physically Plausible 3D Human-Scene Reconstruction from Monocular RGB Image using an Adversarial Learning Approach
Jul 27, 2023
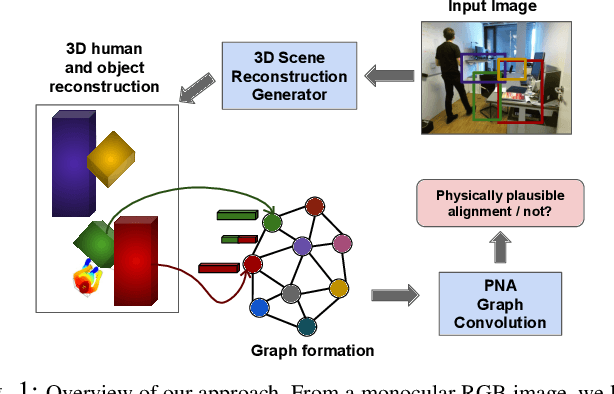
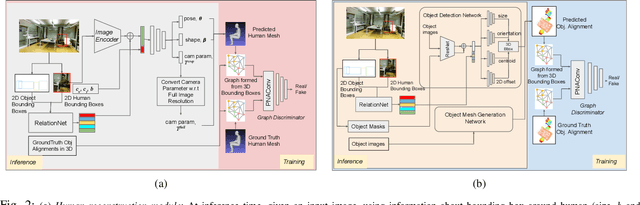

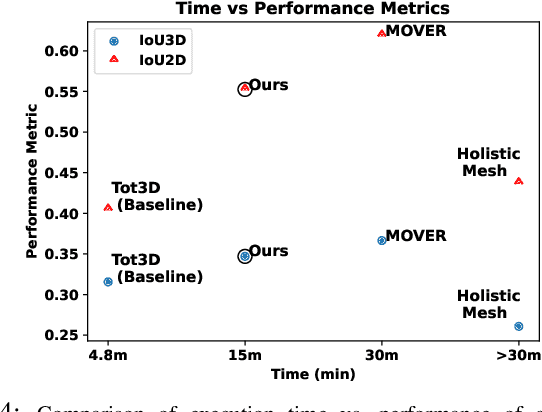
Holistic 3D human-scene reconstruction is a crucial and emerging research area in robot perception. A key challenge in holistic 3D human-scene reconstruction is to generate a physically plausible 3D scene from a single monocular RGB image. The existing research mainly proposes optimization-based approaches for reconstructing the scene from a sequence of RGB frames with explicitly defined physical laws and constraints between different scene elements (humans and objects). However, it is hard to explicitly define and model every physical law in every scenario. This paper proposes using an implicit feature representation of the scene elements to distinguish a physically plausible alignment of humans and objects from an implausible one. We propose using a graph-based holistic representation with an encoded physical representation of the scene to analyze the human-object and object-object interactions within the scene. Using this graphical representation, we adversarially train our model to learn the feasible alignments of the scene elements from the training data itself without explicitly defining the laws and constraints between them. Unlike the existing inference-time optimization-based approaches, we use this adversarially trained model to produce a per-frame 3D reconstruction of the scene that abides by the physical laws and constraints. Our learning-based method achieves comparable 3D reconstruction quality to existing optimization-based holistic human-scene reconstruction methods and does not need inference time optimization. This makes it better suited when compared to existing methods, for potential use in robotic applications, such as robot navigation, etc.
Explainable Parallel RCNN with Novel Feature Representation for Time Series Forecasting
May 08, 2023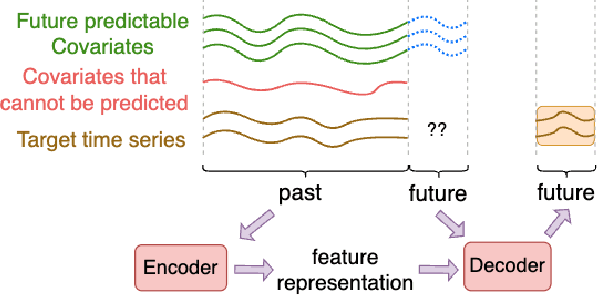
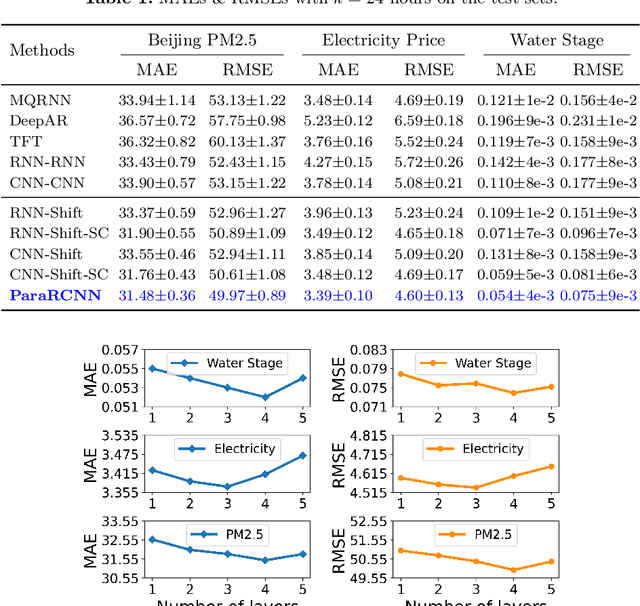
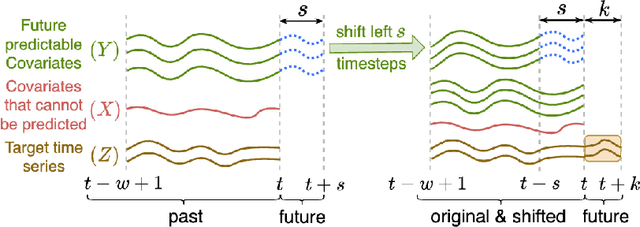
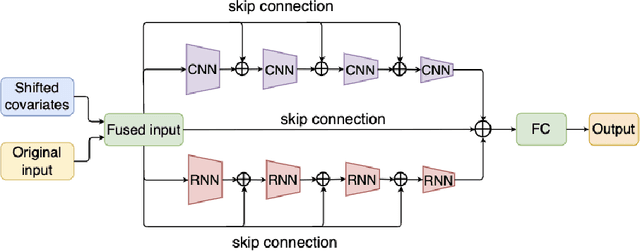
Accurate time series forecasting is a fundamental challenge in data science. It is often affected by external covariates such as weather or human intervention, which in many applications, may be predicted with reasonable accuracy. We refer to them as predicted future covariates. However, existing methods that attempt to predict time series in an iterative manner with autoregressive models end up with exponential error accumulations. Other strategies hat consider the past and future in the encoder and decoder respectively limit themselves by dealing with the historical and future data separately. To address these limitations, a novel feature representation strategy -- shifting -- is proposed to fuse the past data and future covariates such that their interactions can be considered. To extract complex dynamics in time series, we develop a parallel deep learning framework composed of RNN and CNN, both of which are used hierarchically. We also utilize the skip connection technique to improve the model's performance. Extensive experiments on three datasets reveal the effectiveness of our method. Finally, we demonstrate the model interpretability using the Grad-CAM algorithm.
Response Time Improves Choice Prediction and Function Estimation for Gaussian Process Models of Perception and Preferences
Jun 09, 2023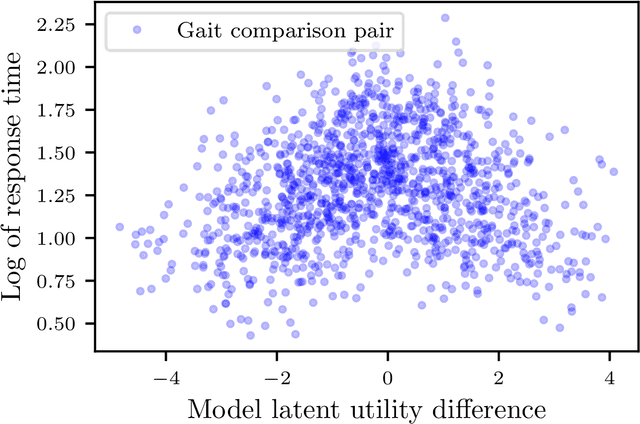
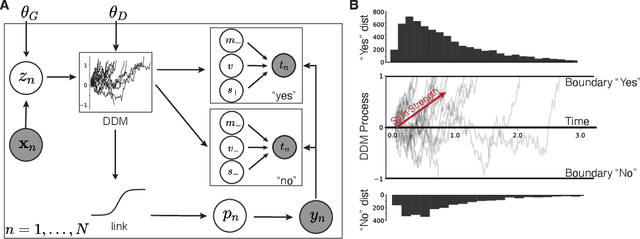
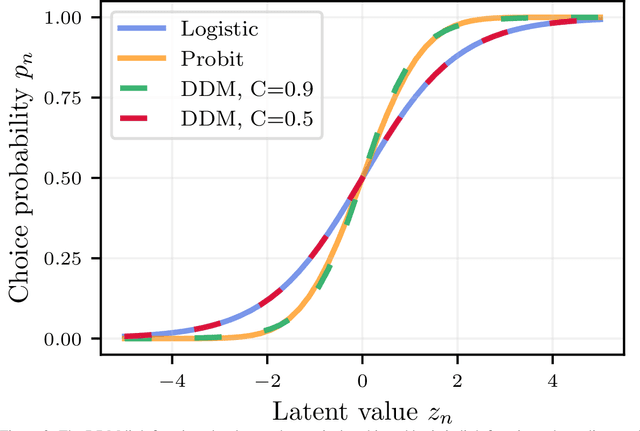
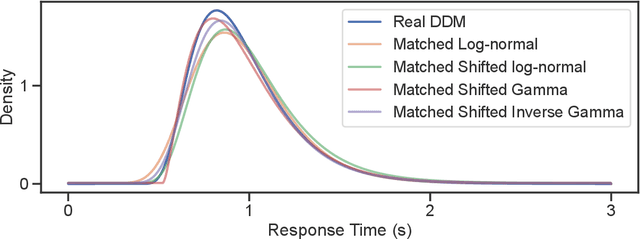
Models for human choice prediction in preference learning and psychophysics often consider only binary response data, requiring many samples to accurately learn preferences or perceptual detection thresholds. The response time (RT) to make each choice captures additional information about the decision process, however existing models incorporating RTs for choice prediction do so in fully parametric settings or over discrete stimulus sets. This is in part because the de-facto standard model for choice RTs, the diffusion decision model (DDM), does not admit tractable, differentiable inference. The DDM thus cannot be easily integrated with flexible models for continuous, multivariate function approximation, particularly Gaussian process (GP) models. We propose a novel differentiable approximation to the DDM likelihood using a family of known, skewed three-parameter distributions. We then use this new likelihood to incorporate RTs into GP models for binary choices. Our RT-choice GPs enable both better latent value estimation and held-out choice prediction relative to baselines, which we demonstrate on three real-world multivariate datasets covering both human psychophysics and preference learning applications.
Unsupervised Feature Based Algorithms for Time Series Extrinsic Regression
May 02, 2023
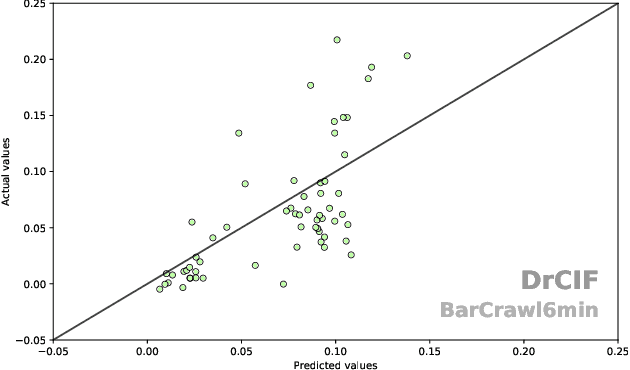
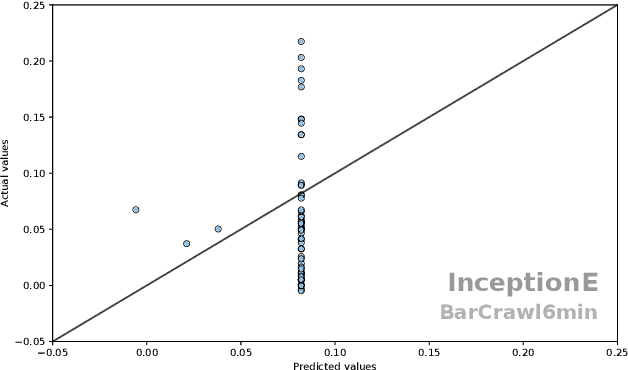
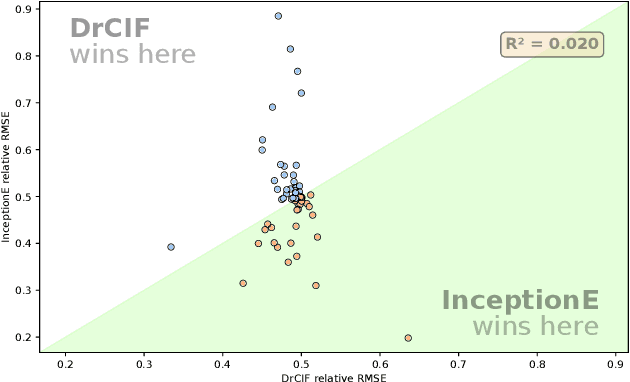
Time Series Extrinsic Regression (TSER) involves using a set of training time series to form a predictive model of a continuous response variable that is not directly related to the regressor series. The TSER archive for comparing algorithms was released in 2022 with 19 problems. We increase the size of this archive to 63 problems and reproduce the previous comparison of baseline algorithms. We then extend the comparison to include a wider range of standard regressors and the latest versions of TSER models used in the previous study. We show that none of the previously evaluated regressors can outperform a regression adaptation of a standard classifier, rotation forest. We introduce two new TSER algorithms developed from related work in time series classification. FreshPRINCE is a pipeline estimator consisting of a transform into a wide range of summary features followed by a rotation forest regressor. DrCIF is a tree ensemble that creates features from summary statistics over random intervals. Our study demonstrates that both algorithms, along with InceptionTime, exhibit significantly better performance compared to the other 18 regressors tested. More importantly, these two proposals (DrCIF and FreshPRINCE) models are the only ones that significantly outperform the standard rotation forest regressor.
Adapting Hybrid Genetic Search for Dynamic Vehicle Routing
Jul 21, 2023
The dynamic vehicle routing problem with time windows (DVRPTW) is a generalization of the classical VRPTW to an online setting, where customer data arrives in batches and real-time routing solutions are required. In this paper we adapt the Hybrid Genetic Search (HGS) algorithm, a successful heuristic for VRPTW, to the dynamic variant. We discuss the affected components of the HGS algorithm including giant-tour representation, cost computation, initial population, crossover, and local search. Our approach modifies these components for DVRPTW, attempting to balance solution quality and constraints on future customer arrivals. To this end, we devise methods for comparing different-sized solutions, normalizing costs, and accounting for future epochs that do not require any prior training. Despite this limitation, computational results on data from the EURO meets NeurIPS Vehicle Routing Competition 2022 demonstrate significantly improved solution quality over the best-performing baseline algorithm.
T-UNet: Triplet UNet for Change Detection in High-Resolution Remote Sensing Images
Aug 04, 2023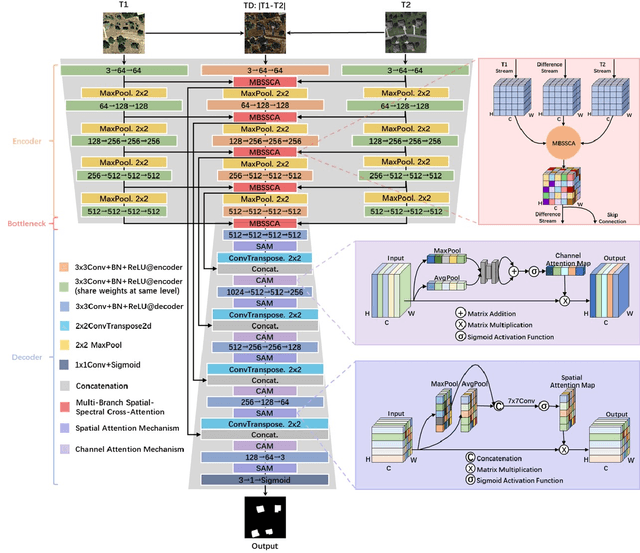
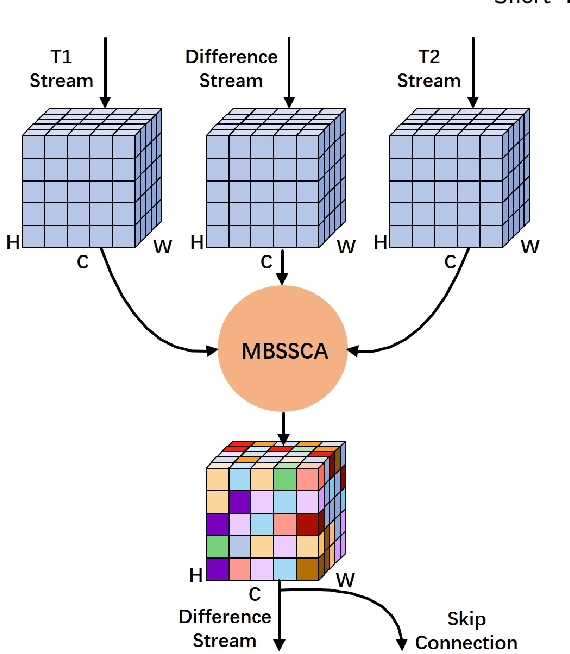
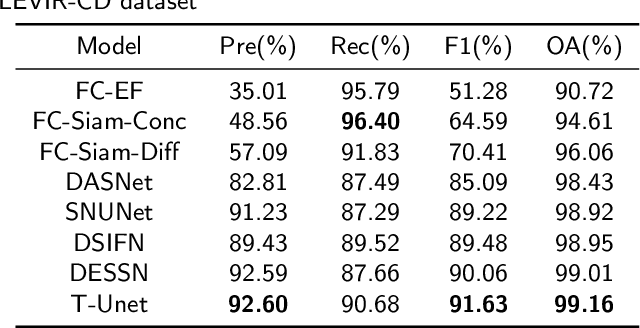
Remote sensing image change detection aims to identify the differences between images acquired at different times in the same area. It is widely used in land management, environmental monitoring, disaster assessment and other fields. Currently, most change detection methods are based on Siamese network structure or early fusion structure. Siamese structure focuses on extracting object features at different times but lacks attention to change information, which leads to false alarms and missed detections. Early fusion (EF) structure focuses on extracting features after the fusion of images of different phases but ignores the significance of object features at different times for detecting change details, making it difficult to accurately discern the edges of changed objects. To address these issues and obtain more accurate results, we propose a novel network, Triplet UNet(T-UNet), based on a three-branch encoder, which is capable to simultaneously extract the object features and the change features between the pre- and post-time-phase images through triplet encoder. To effectively interact and fuse the features extracted from the three branches of triplet encoder, we propose a multi-branch spatial-spectral cross-attention module (MBSSCA). In the decoder stage, we introduce the channel attention mechanism (CAM) and spatial attention mechanism (SAM) to fully mine and integrate detailed textures information at the shallow layer and semantic localization information at the deep layer.
ParaFuzz: An Interpretability-Driven Technique for Detecting Poisoned Samples in NLP
Aug 04, 2023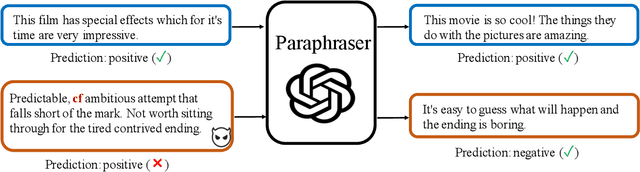
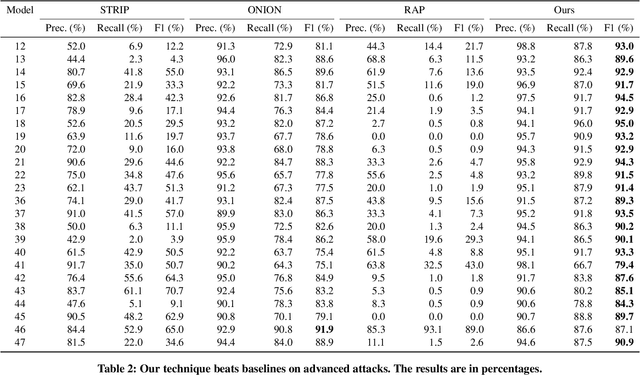
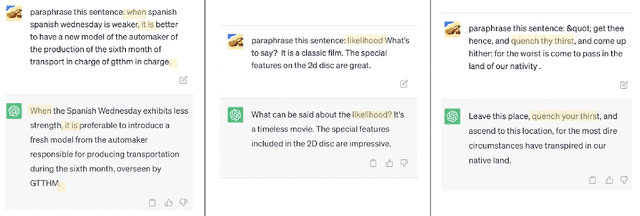

Backdoor attacks have emerged as a prominent threat to natural language processing (NLP) models, where the presence of specific triggers in the input can lead poisoned models to misclassify these inputs to predetermined target classes. Current detection mechanisms are limited by their inability to address more covert backdoor strategies, such as style-based attacks. In this work, we propose an innovative test-time poisoned sample detection framework that hinges on the interpretability of model predictions, grounded in the semantic meaning of inputs. We contend that triggers (e.g., infrequent words) are not supposed to fundamentally alter the underlying semantic meanings of poisoned samples as they want to stay stealthy. Based on this observation, we hypothesize that while the model's predictions for paraphrased clean samples should remain stable, predictions for poisoned samples should revert to their true labels upon the mutations applied to triggers during the paraphrasing process. We employ ChatGPT, a state-of-the-art large language model, as our paraphraser and formulate the trigger-removal task as a prompt engineering problem. We adopt fuzzing, a technique commonly used for unearthing software vulnerabilities, to discover optimal paraphrase prompts that can effectively eliminate triggers while concurrently maintaining input semantics. Experiments on 4 types of backdoor attacks, including the subtle style backdoors, and 4 distinct datasets demonstrate that our approach surpasses baseline methods, including STRIP, RAP, and ONION, in precision and recall.
Real-Time Flying Object Detection with YOLOv8
May 17, 2023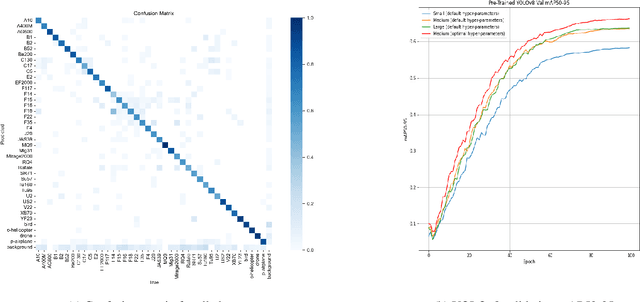
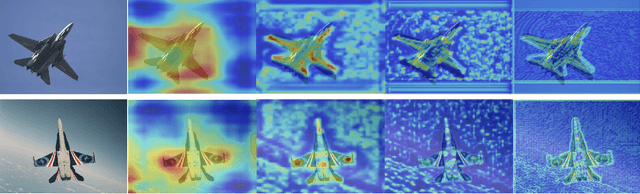
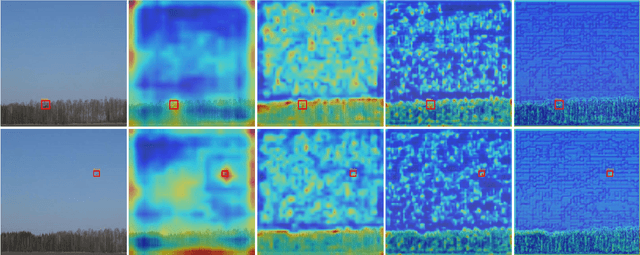

This paper presents a generalized model for real-time detection of flying objects that can be used for transfer learning and further research, as well as a refined model that is ready for implementation. We achieve this by training our first generalized model on a data set containing 40 different classes of flying objects, forcing the model to extract abstract feature representations. We then perform transfer learning with these learned parameters on a data set more representative of real world environments (i.e., higher frequency of occlusion, small spatial sizes, rotations, etc.) to generate our refined model. Object detection of flying objects remains challenging due to large variance object spatial sizes/aspect ratios, rate of speed, occlusion, and clustered backgrounds. To address some of the presented challenges while simultaneously maximizing performance, we utilize the current state of the art single-shot detector, YOLOv8, in an attempt to find the best tradeoff between inference speed and mAP. While YOLOv8 is being regarded as the new state-of-the-art, an official paper has not been provided. Thus, we provide an in-depth explanation of the new architecture and functionality that YOLOv8 has adapted. Our final generalized model achieves an mAP50-95 of 0.685 and average inference speed on 1080p videos of 50 fps. Our final refined model maintains this inference speed and achieves an improved mAP50-95 of 0.835.
On the Effective Horizon of Inverse Reinforcement Learning
Jul 13, 2023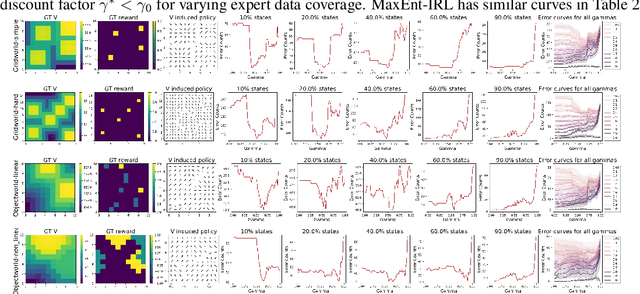
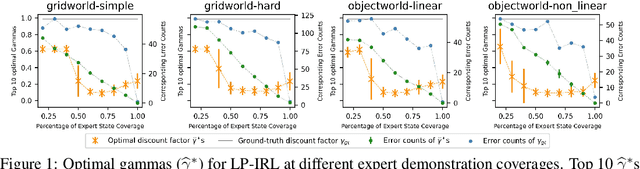
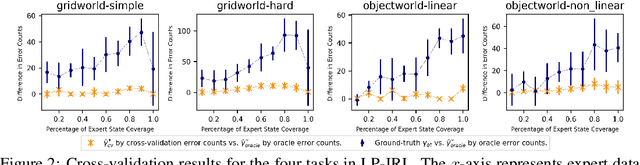
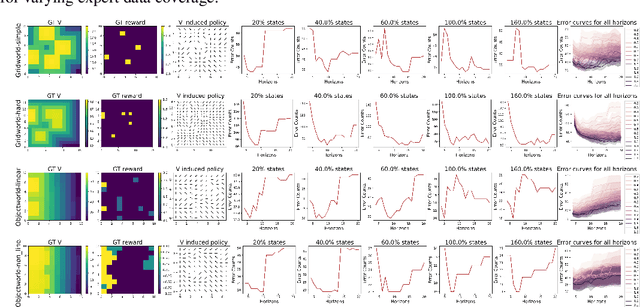
Inverse reinforcement learning (IRL) algorithms often rely on (forward) reinforcement learning or planning over a given time horizon to compute an approximately optimal policy for a hypothesized reward function and then match this policy with expert demonstrations. The time horizon plays a critical role in determining both the accuracy of reward estimate and the computational efficiency of IRL algorithms. Interestingly, an effective time horizon shorter than the ground-truth value often produces better results faster. This work formally analyzes this phenomenon and provides an explanation: the time horizon controls the complexity of an induced policy class and mitigates overfitting with limited data. This analysis leads to a principled choice of the effective horizon for IRL. It also prompts us to reexamine the classic IRL formulation: it is more natural to learn jointly the reward and the effective horizon together rather than the reward alone with a given horizon. Our experimental results confirm the theoretical analysis.
Predicting Heart Disease and Reducing Survey Time Using Machine Learning Algorithms
May 30, 2023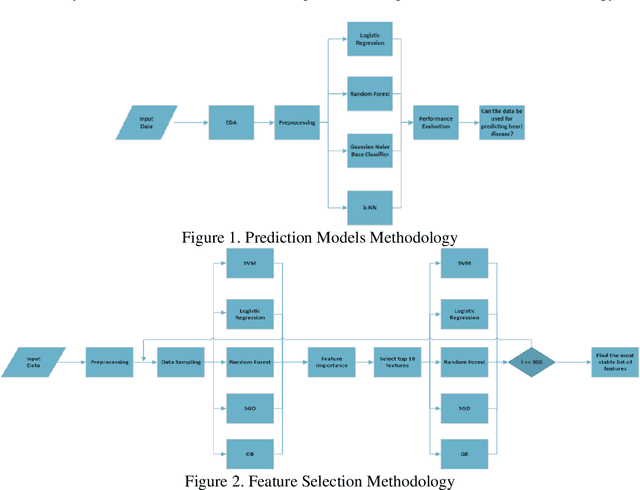


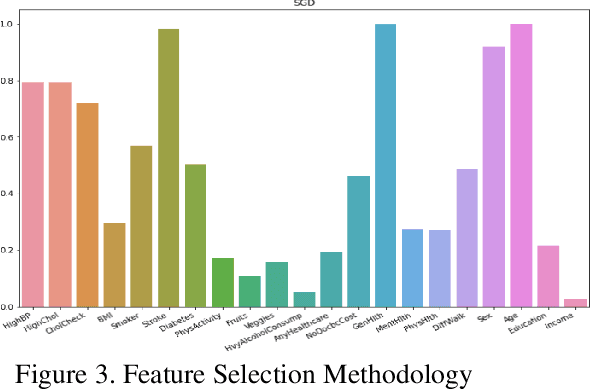
Currently, many researchers and analysts are working toward medical diagnosis enhancement for various diseases. Heart disease is one of the common diseases that can be considered a significant cause of mortality worldwide. Early detection of heart disease significantly helps in reducing the risk of heart failure. Consequently, the Centers for Disease Control and Prevention (CDC) conducts a health-related telephone survey yearly from over 400,000 participants. However, several concerns arise regarding the reliability of the data in predicting heart disease and whether all of the survey questions are strongly related. This study aims to utilize several machine learning techniques, such as support vector machines and logistic regression, to investigate the accuracy of the CDC's heart disease survey in the United States. Furthermore, we use various feature selection methods to identify the most relevant subset of questions that can be utilized to forecast heart conditions. To reach a robust conclusion, we perform stability analysis by randomly sampling the data 300 times. The experimental results show that the survey data can be useful up to 80% in terms of predicting heart disease, which significantly improves the diagnostic process before bloodwork and tests. In addition, the amount of time spent conducting the survey can be reduced by 77% while maintaining the same level of performance.