 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards a Fully Unsupervised Framework for Intent Induction in Customer Support Dialogues
Jul 28, 2023
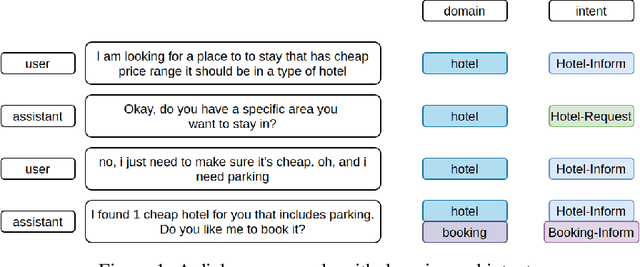
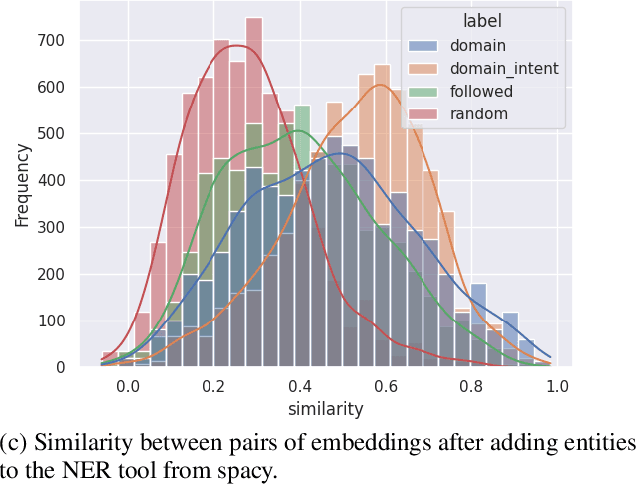
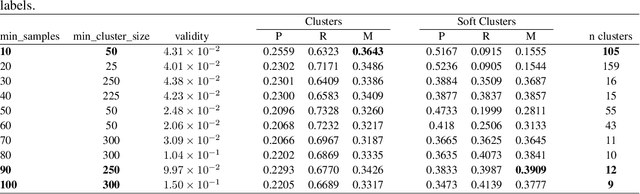
State of the art models in intent induction require annotated datasets. However, annotating dialogues is time-consuming, laborious and expensive. In this work, we propose a completely unsupervised framework for intent induction within a dialogue. In addition, we show how pre-processing the dialogue corpora can improve results. Finally, we show how to extract the dialogue flows of intentions by investigating the most common sequences. Although we test our work in the MultiWOZ dataset, the fact that this framework requires no prior knowledge make it applicable to any possible use case, making it very relevant to real world customer support applications across industry.
An X3D Neural Network Analysis for Runner's Performance Assessment in a Wild Sporting Environment
Jul 22, 2023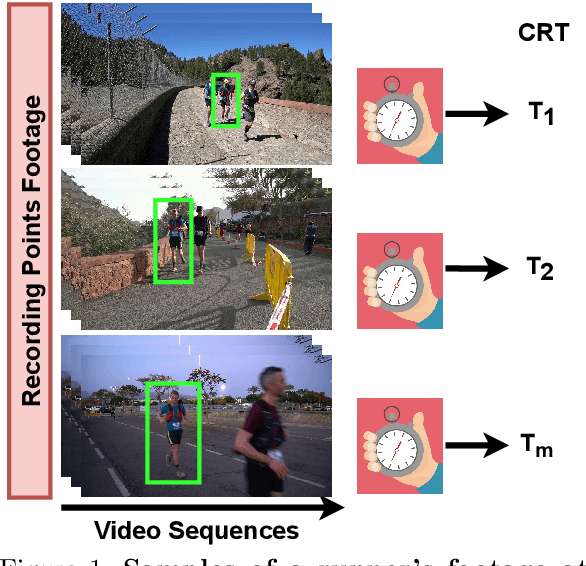
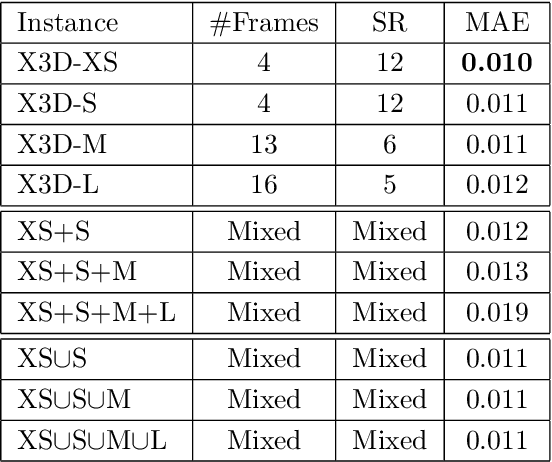
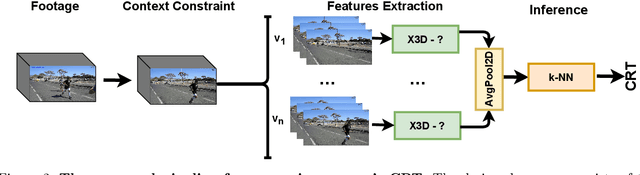
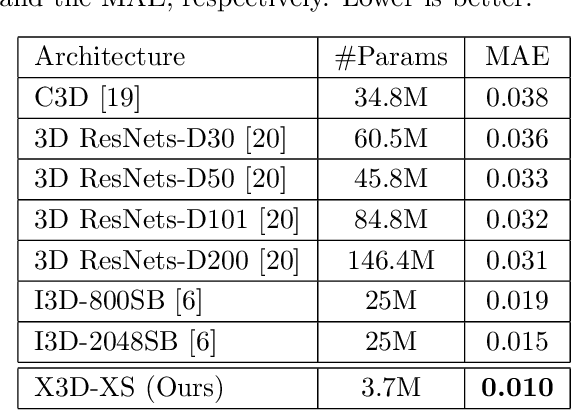
We present a transfer learning analysis on a sporting environment of the expanded 3D (X3D) neural networks. Inspired by action quality assessment methods in the literature, our method uses an action recognition network to estimate athletes' cumulative race time (CRT) during an ultra-distance competition. We evaluate the performance considering the X3D, a family of action recognition networks that expand a small 2D image classification architecture along multiple network axes, including space, time, width, and depth. We demonstrate that the resulting neural network can provide remarkable performance for short input footage, with a mean absolute error of 12 minutes and a half when estimating the CRT for runners who have been active from 8 to 20 hours. Our most significant discovery is that X3D achieves state-of-the-art performance while requiring almost seven times less memory to achieve better precision than previous work.
Communication-Free Distributed GNN Training with Vertex Cut
Aug 06, 2023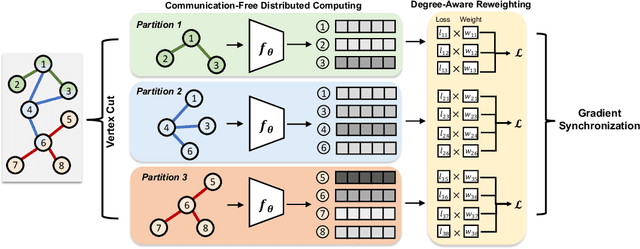
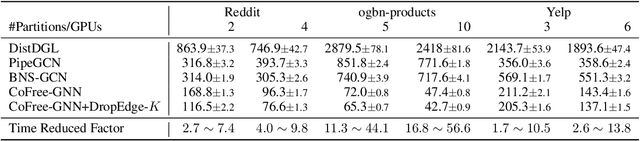
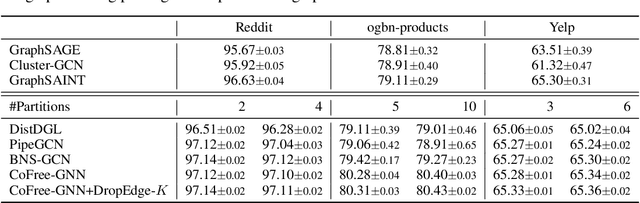

Training Graph Neural Networks (GNNs) on real-world graphs consisting of billions of nodes and edges is quite challenging, primarily due to the substantial memory needed to store the graph and its intermediate node and edge features, and there is a pressing need to speed up the training process. A common approach to achieve speed up is to divide the graph into many smaller subgraphs, which are then distributed across multiple GPUs in one or more machines and processed in parallel. However, existing distributed methods require frequent and substantial cross-GPU communication, leading to significant time overhead and progressively diminishing scalability. Here, we introduce CoFree-GNN, a novel distributed GNN training framework that significantly speeds up the training process by implementing communication-free training. The framework utilizes a Vertex Cut partitioning, i.e., rather than partitioning the graph by cutting the edges between partitions, the Vertex Cut partitions the edges and duplicates the node information to preserve the graph structure. Furthermore, the framework maintains high model accuracy by incorporating a reweighting mechanism to handle a distorted graph distribution that arises from the duplicated nodes. We also propose a modified DropEdge technique to further speed up the training process. Using an extensive set of experiments on real-world networks, we demonstrate that CoFree-GNN speeds up the GNN training process by up to 10 times over the existing state-of-the-art GNN training approaches.
"Kurosawa": A Script Writer's Assistant
Aug 06, 2023Storytelling is the lifeline of the entertainment industry -- movies, TV shows, and stand-up comedies, all need stories. A good and gripping script is the lifeline of storytelling and demands creativity and resource investment. Good scriptwriters are rare to find and often work under severe time pressure. Consequently, entertainment media are actively looking for automation. In this paper, we present an AI-based script-writing workbench called KUROSAWA which addresses the tasks of plot generation and script generation. Plot generation aims to generate a coherent and creative plot (600-800 words) given a prompt (15-40 words). Script generation, on the other hand, generates a scene (200-500 words) in a screenplay format from a brief description (15-40 words). Kurosawa needs data to train. We use a 4-act structure of storytelling to annotate the plot dataset manually. We create a dataset of 1000 manually annotated plots and their corresponding prompts/storylines and a gold-standard dataset of 1000 scenes with four main elements -- scene headings, action lines, dialogues, and character names -- tagged individually. We fine-tune GPT-3 with the above datasets to generate plots and scenes. These plots and scenes are first evaluated and then used by the scriptwriters of a large and famous media platform ErosNow. We release the annotated datasets and the models trained on these datasets as a working benchmark for automatic movie plot and script generation.
RT-K-Net: Revisiting K-Net for Real-Time Panoptic Segmentation
May 02, 2023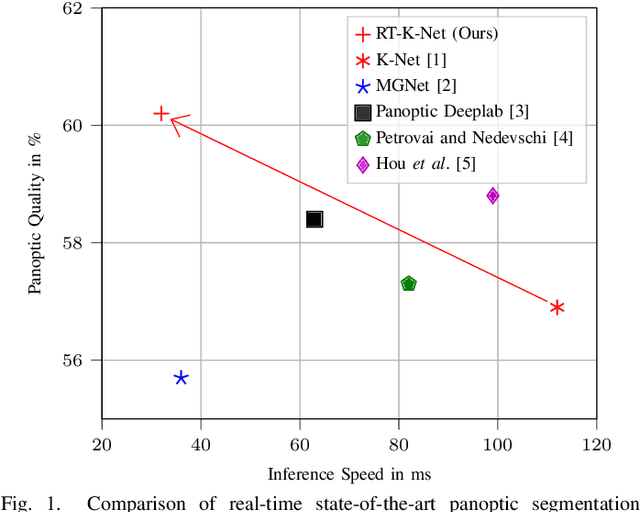
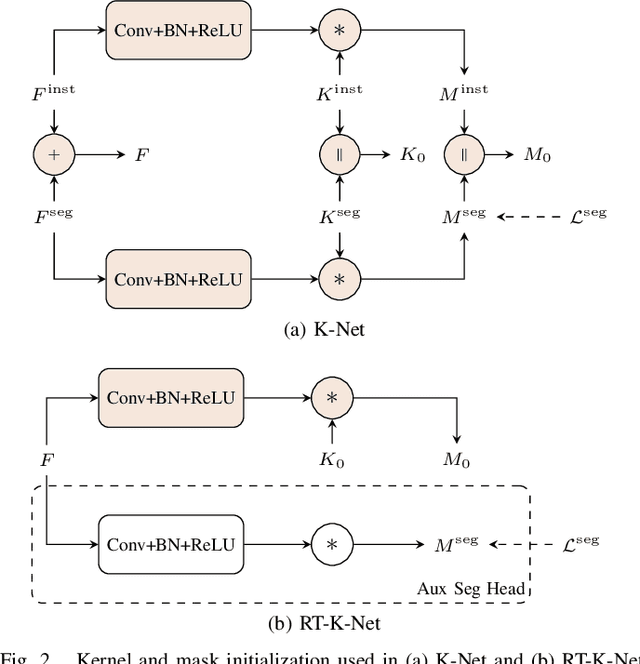

Panoptic segmentation is one of the most challenging scene parsing tasks, combining the tasks of semantic segmentation and instance segmentation. While much progress has been made, few works focus on the real-time application of panoptic segmentation methods. In this paper, we revisit the recently introduced K-Net architecture. We propose vital changes to the architecture, training, and inference procedure, which massively decrease latency and improve performance. Our resulting RT-K-Net sets a new state-of-the-art performance for real-time panoptic segmentation methods on the Cityscapes dataset and shows promising results on the challenging Mapillary Vistas dataset. On Cityscapes, RT-K-Net reaches 60.2 % PQ with an average inference time of 32 ms for full resolution 1024x2048 pixel images on a single Titan RTX GPU. On Mapillary Vistas, RT-K-Net reaches 33.2 % PQ with an average inference time of 69 ms. Source code is available at https://github.com/markusschoen/RT-K-Net.
Spiking Neural Networks and Bio-Inspired Supervised Deep Learning: A Survey
Jul 30, 2023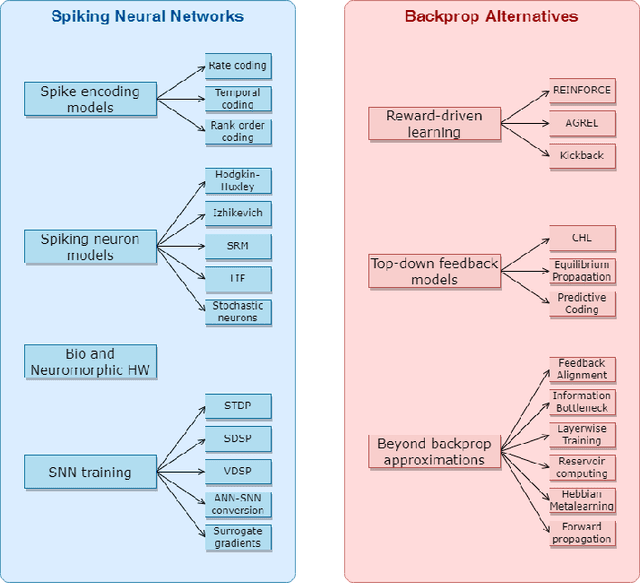
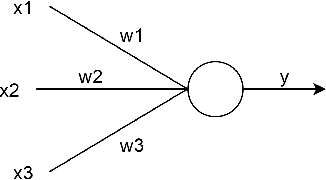
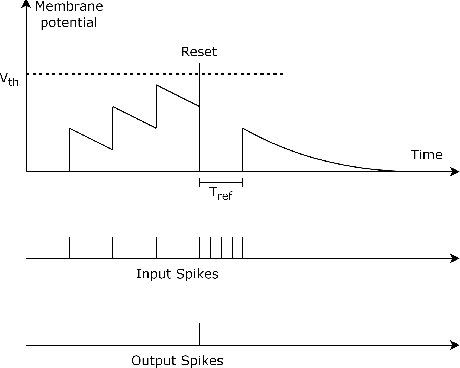
For a long time, biology and neuroscience fields have been a great source of inspiration for computer scientists, towards the development of Artificial Intelligence (AI) technologies. This survey aims at providing a comprehensive review of recent biologically-inspired approaches for AI. After introducing the main principles of computation and synaptic plasticity in biological neurons, we provide a thorough presentation of Spiking Neural Network (SNN) models, and we highlight the main challenges related to SNN training, where traditional backprop-based optimization is not directly applicable. Therefore, we discuss recent bio-inspired training methods, which pose themselves as alternatives to backprop, both for traditional and spiking networks. Bio-Inspired Deep Learning (BIDL) approaches towards advancing the computational capabilities and biological plausibility of current models.
Real-Time Flying Object Detection with YOLOv8
May 17, 2023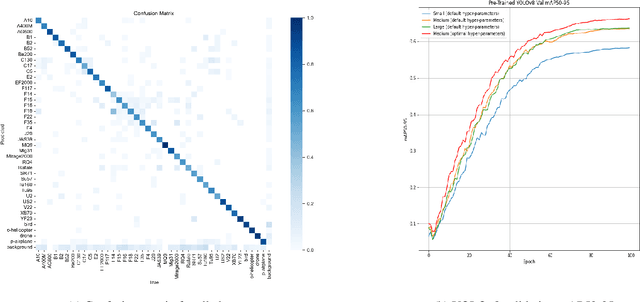
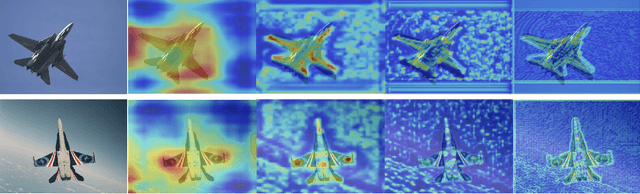
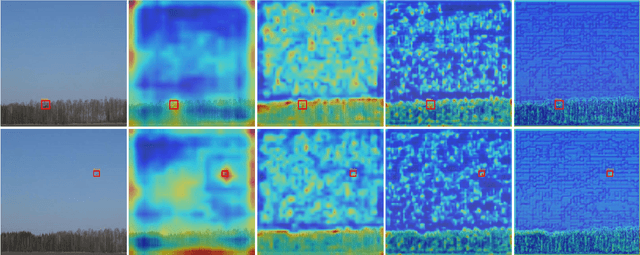

This paper presents a generalized model for real-time detection of flying objects that can be used for transfer learning and further research, as well as a refined model that is ready for implementation. We achieve this by training our first generalized model on a data set containing 40 different classes of flying objects, forcing the model to extract abstract feature representations. We then perform transfer learning with these learned parameters on a data set more representative of real world environments (i.e., higher frequency of occlusion, small spatial sizes, rotations, etc.) to generate our refined model. Object detection of flying objects remains challenging due to large variance object spatial sizes/aspect ratios, rate of speed, occlusion, and clustered backgrounds. To address some of the presented challenges while simultaneously maximizing performance, we utilize the current state of the art single-shot detector, YOLOv8, in an attempt to find the best tradeoff between inference speed and mAP. While YOLOv8 is being regarded as the new state-of-the-art, an official paper has not been provided. Thus, we provide an in-depth explanation of the new architecture and functionality that YOLOv8 has adapted. Our final generalized model achieves an mAP50-95 of 0.685 and average inference speed on 1080p videos of 50 fps. Our final refined model maintains this inference speed and achieves an improved mAP50-95 of 0.835.
A Synthetic Electrocardiogram (ECG) Image Generation Toolbox to Facilitate Deep Learning-Based Scanned ECG Digitization
Jul 14, 2023

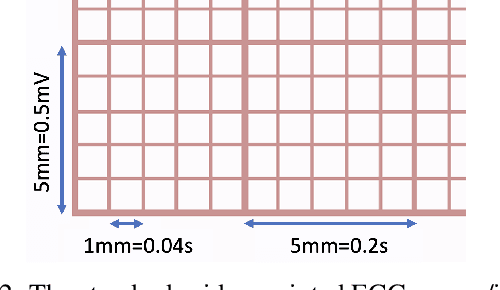
The electrocardiogram (ECG) is an accurate and widely available tool for diagnosing cardiovascular diseases. ECGs have been recorded in printed formats for decades and their digitization holds great potential for training machine learning (ML) models in algorithmic ECG diagnosis. Physical ECG archives are at risk of deterioration and scanning printed ECGs alone is insufficient, as ML models require ECG time-series data. Therefore, the digitization and conversion of paper ECG archives into time-series data is of utmost importance. Deep learning models for image processing show promise in this regard. However, the scarcity of ECG archives with reference time-series is a challenge. Data augmentation techniques utilizing \textit{digital twins} present a potential solution. We introduce a novel method for generating synthetic ECG images on standard paper-like ECG backgrounds with realistic artifacts. Distortions including handwritten text artifacts, wrinkles, creases and perspective transforms are applied to the generated images, without personally identifiable information. As a use case, we generated an ECG image dataset of 21,801 records from the 12-lead PhysioNet PTB-XL ECG time-series dataset. A deep ECG image digitization model was built and trained on the synthetic dataset, and was employed to convert the synthetic images to time-series data for evaluation. The signal-to-noise ratio (SNR) was calculated to assess the image digitization quality vs the ground truth ECG time-series. The results show an average signal recovery SNR of 27$\pm$2.8\,dB, demonstrating the significance of the proposed synthetic ECG image dataset for training deep learning models. The codebase is available as an open-access toolbox for ECG research.
Response Time Improves Choice Prediction and Function Estimation for Gaussian Process Models of Perception and Preferences
Jun 09, 2023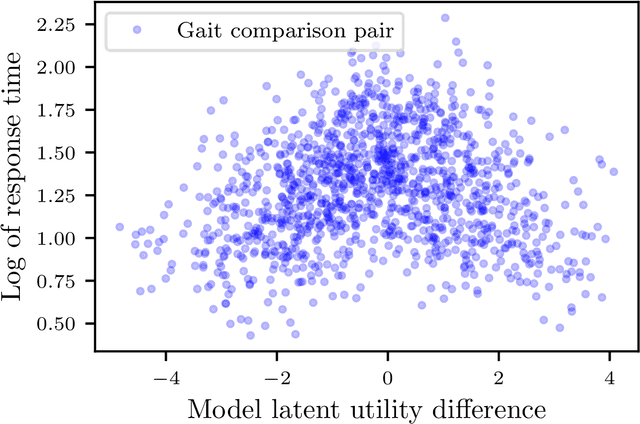
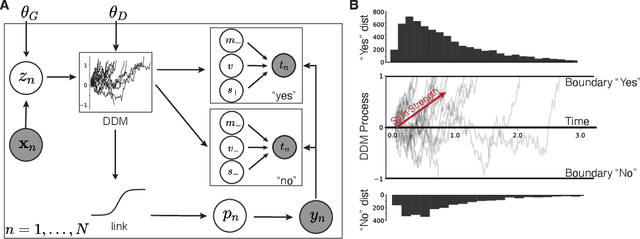
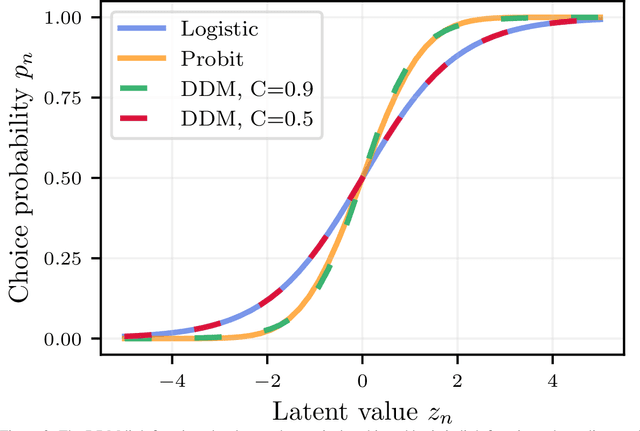
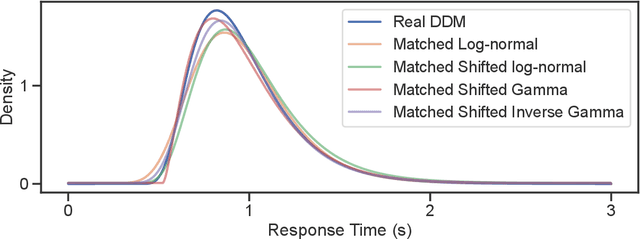
Models for human choice prediction in preference learning and psychophysics often consider only binary response data, requiring many samples to accurately learn preferences or perceptual detection thresholds. The response time (RT) to make each choice captures additional information about the decision process, however existing models incorporating RTs for choice prediction do so in fully parametric settings or over discrete stimulus sets. This is in part because the de-facto standard model for choice RTs, the diffusion decision model (DDM), does not admit tractable, differentiable inference. The DDM thus cannot be easily integrated with flexible models for continuous, multivariate function approximation, particularly Gaussian process (GP) models. We propose a novel differentiable approximation to the DDM likelihood using a family of known, skewed three-parameter distributions. We then use this new likelihood to incorporate RTs into GP models for binary choices. Our RT-choice GPs enable both better latent value estimation and held-out choice prediction relative to baselines, which we demonstrate on three real-world multivariate datasets covering both human psychophysics and preference learning applications.
Fast model inference and training on-board of Satellites
Jul 17, 2023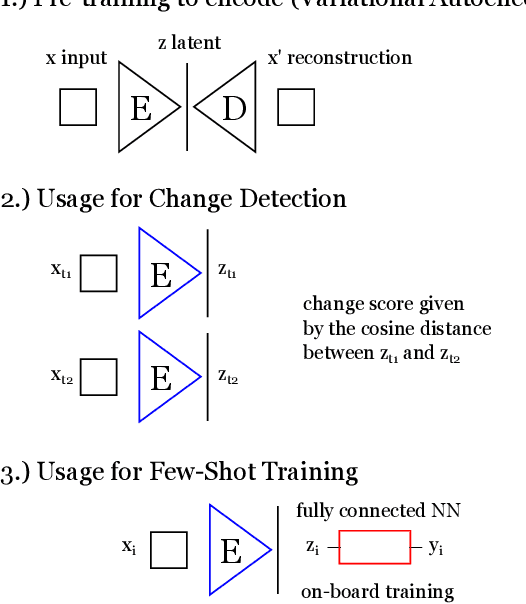
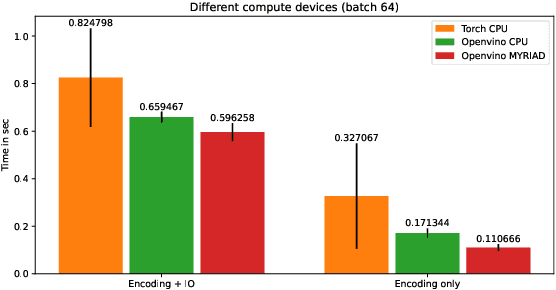
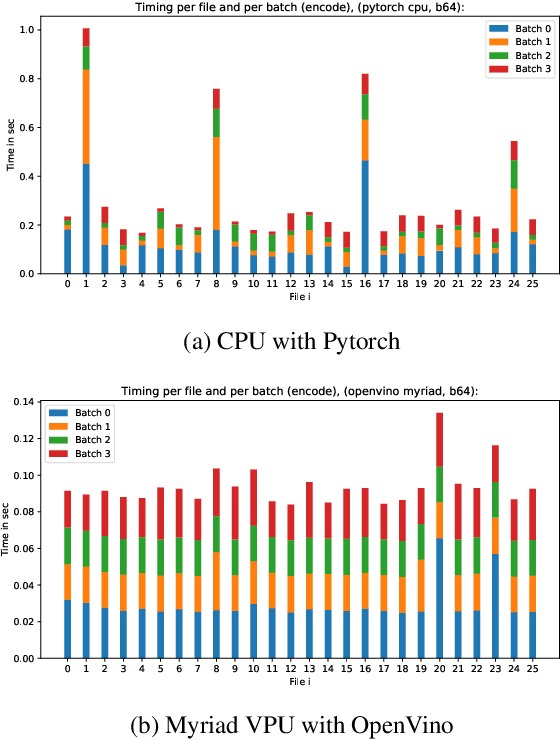
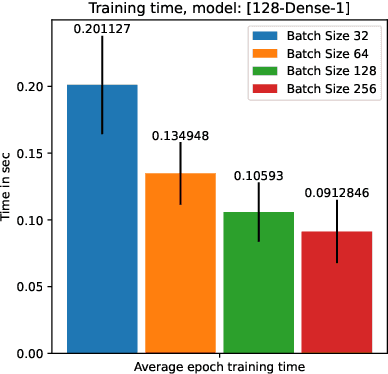
Artificial intelligence onboard satellites has the potential to reduce data transmission requirements, enable real-time decision-making and collaboration within constellations. This study deploys a lightweight foundational model called RaVAEn on D-Orbit's ION SCV004 satellite. RaVAEn is a variational auto-encoder (VAE) that generates compressed latent vectors from small image tiles, enabling several downstream tasks. In this work we demonstrate the reliable use of RaVAEn onboard a satellite, achieving an encoding time of 0.110s for tiles of a 4.8x4.8 km$^2$ area. In addition, we showcase fast few-shot training onboard a satellite using the latent representation of data. We compare the deployment of the model on the on-board CPU and on the available Myriad vision processing unit (VPU) accelerator. To our knowledge, this work shows for the first time the deployment of a multi-task model on-board a CubeSat and the on-board training of a machine learning model.