 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FocusFlow: Boosting Key-Points Optical Flow Estimation for Autonomous Driving
Aug 14, 2023
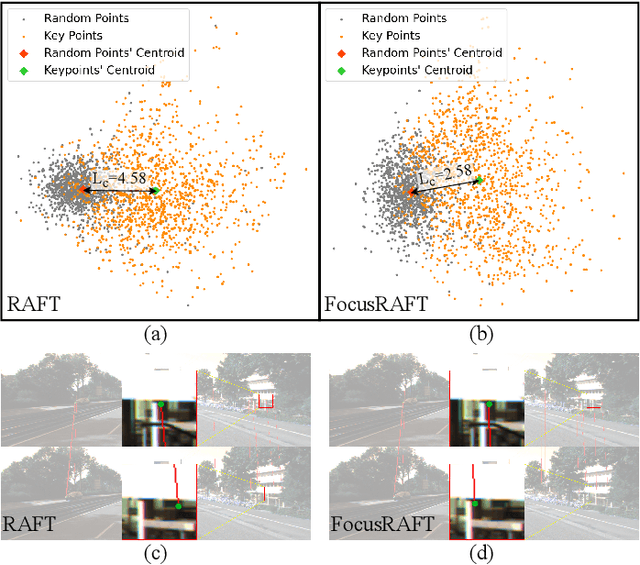
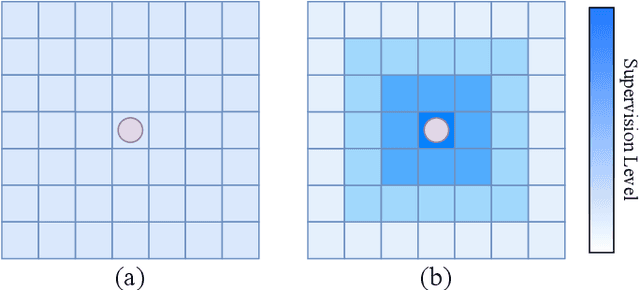
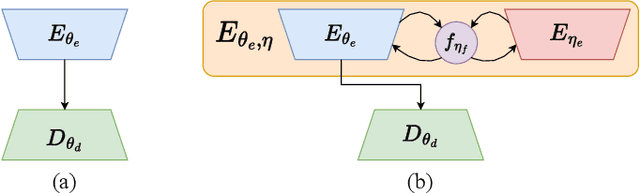
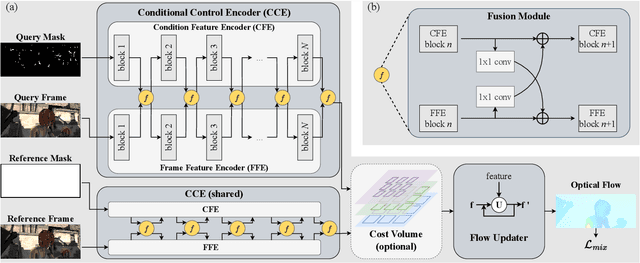
Key-point-based scene understanding is fundamental for autonomous driving applications. At the same time, optical flow plays an important role in many vision tasks. However, due to the implicit bias of equal attention on all points, classic data-driven optical flow estimation methods yield less satisfactory performance on key points, limiting their implementations in key-point-critical safety-relevant scenarios. To address these issues, we introduce a points-based modeling method that requires the model to learn key-point-related priors explicitly. Based on the modeling method, we present FocusFlow, a framework consisting of 1) a mix loss function combined with a classic photometric loss function and our proposed Conditional Point Control Loss (CPCL) function for diverse point-wise supervision; 2) a conditioned controlling model which substitutes the conventional feature encoder by our proposed Condition Control Encoder (CCE). CCE incorporates a Frame Feature Encoder (FFE) that extracts features from frames, a Condition Feature Encoder (CFE) that learns to control the feature extraction behavior of FFE from input masks containing information of key points, and fusion modules that transfer the controlling information between FFE and CFE. Our FocusFlow framework shows outstanding performance with up to +44.5% precision improvement on various key points such as ORB, SIFT, and even learning-based SiLK, along with exceptional scalability for most existing data-driven optical flow methods like PWC-Net, RAFT, and FlowFormer. Notably, FocusFlow yields competitive or superior performances rivaling the original models on the whole frame. The source code will be available at https://github.com/ZhonghuaYi/FocusFlow_official.
Distinguishing Risk Preferences using Repeated Gambles
Aug 14, 2023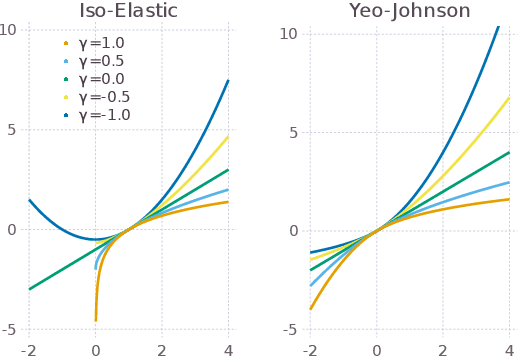
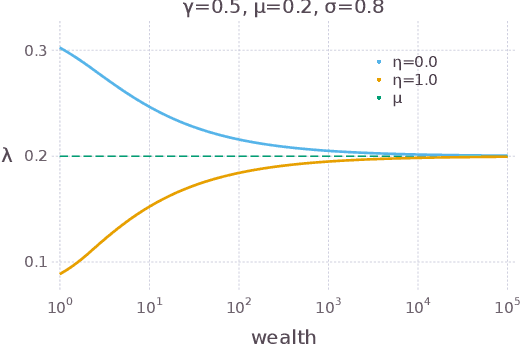
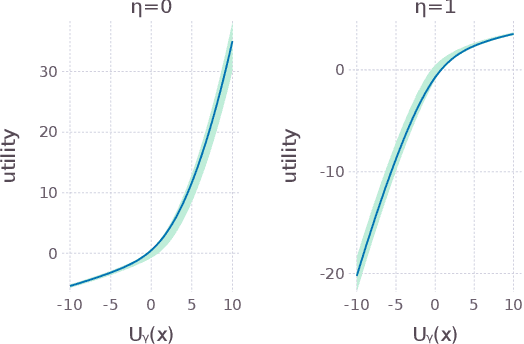
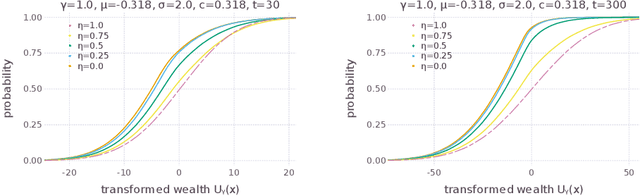
Sequences of repeated gambles provide an experimental tool to characterize the risk preferences of humans or artificial decision-making agents. The difficulty of this inference depends on factors including the details of the gambles offered and the number of iterations of the game played. In this paper we explore in detail the practical challenges of inferring risk preferences from the observed choices of artificial agents who are presented with finite sequences of repeated gambles. We are motivated by the fact that the strategy to maximize long-run wealth for sequences of repeated additive gambles (where gains and losses are independent of current wealth) is different to the strategy for repeated multiplicative gambles (where gains and losses are proportional to current wealth.) Accurate measurement of risk preferences would be needed to tell whether an agent is employing the optimal strategy or not. To generalize the types of gambles our agents face we use the Yeo-Johnson transformation, a tool borrowed from feature engineering for time series analysis, to construct a family of gambles that interpolates smoothly between the additive and multiplicative cases. We then analyze the optimal strategy for this family, both analytically and numerically. We find that it becomes increasingly difficult to distinguish the risk preferences of agents as their wealth increases. This is because agents with different risk preferences eventually make the same decisions for sufficiently high wealth. We believe that these findings are informative for the effective design of experiments to measure risk preferences in humans.
DISBELIEVE: Distance Between Client Models is Very Essential for Effective Local Model Poisoning Attacks
Aug 14, 2023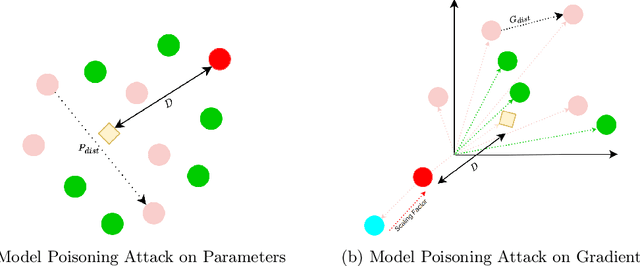
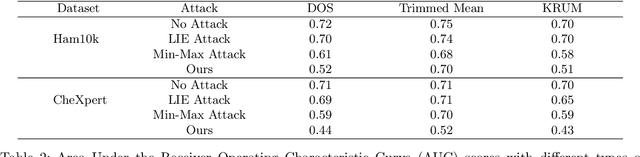
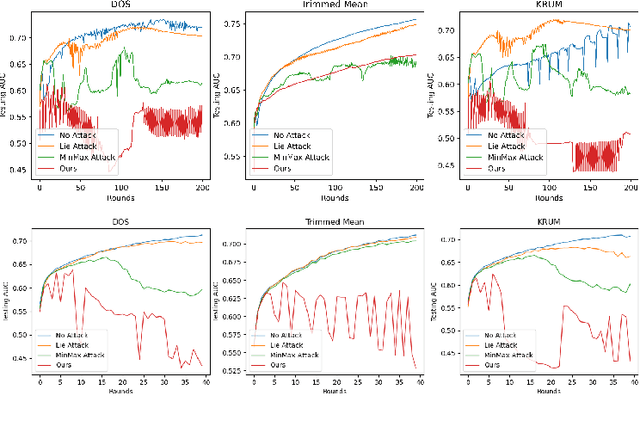
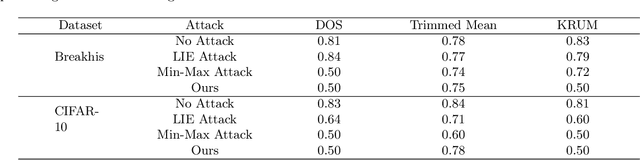
Federated learning is a promising direction to tackle the privacy issues related to sharing patients' sensitive data. Often, federated systems in the medical image analysis domain assume that the participating local clients are \textit{honest}. Several studies report mechanisms through which a set of malicious clients can be introduced that can poison the federated setup, hampering the performance of the global model. To overcome this, robust aggregation methods have been proposed that defend against those attacks. We observe that most of the state-of-the-art robust aggregation methods are heavily dependent on the distance between the parameters or gradients of malicious clients and benign clients, which makes them prone to local model poisoning attacks when the parameters or gradients of malicious and benign clients are close. Leveraging this, we introduce DISBELIEVE, a local model poisoning attack that creates malicious parameters or gradients such that their distance to benign clients' parameters or gradients is low respectively but at the same time their adverse effect on the global model's performance is high. Experiments on three publicly available medical image datasets demonstrate the efficacy of the proposed DISBELIEVE attack as it significantly lowers the performance of the state-of-the-art \textit{robust aggregation} methods for medical image analysis. Furthermore, compared to state-of-the-art local model poisoning attacks, DISBELIEVE attack is also effective on natural images where we observe a severe drop in classification performance of the global model for multi-class classification on benchmark dataset CIFAR-10.
Testing for the Markov Property in Time Series via Deep Conditional Generative Learning
May 30, 2023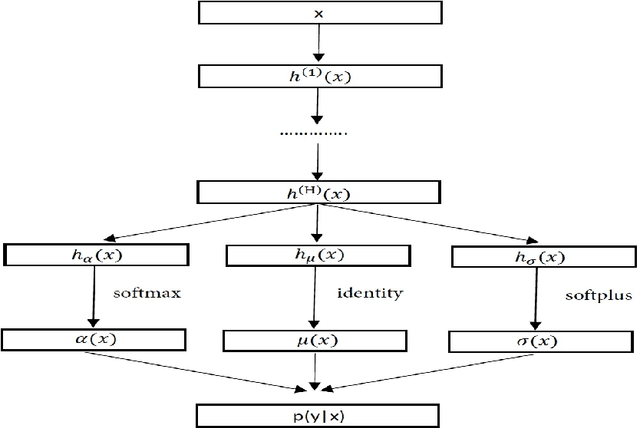
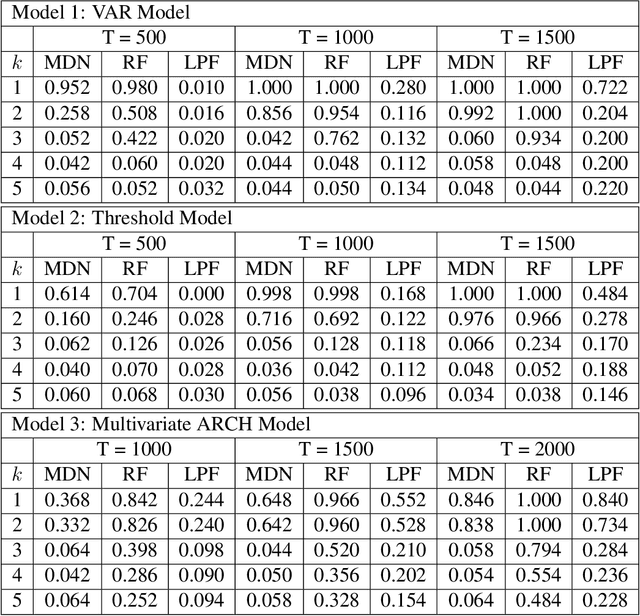
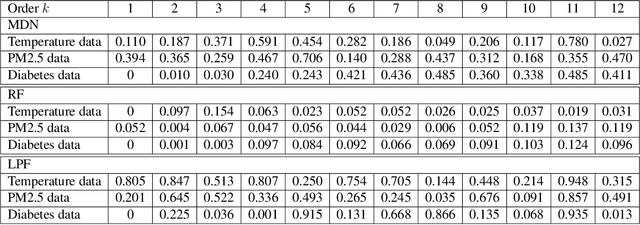
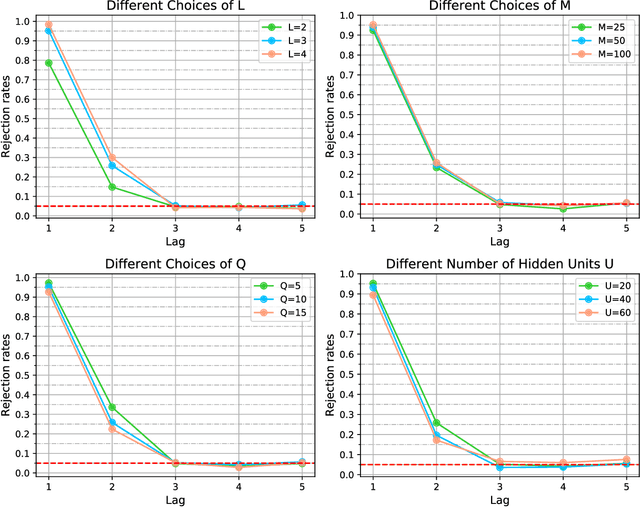
The Markov property is widely imposed in analysis of time series data. Correspondingly, testing the Markov property, and relatedly, inferring the order of a Markov model, are of paramount importance. In this article, we propose a nonparametric test for the Markov property in high-dimensional time series via deep conditional generative learning. We also apply the test sequentially to determine the order of the Markov model. We show that the test controls the type-I error asymptotically, and has the power approaching one. Our proposal makes novel contributions in several ways. We utilize and extend state-of-the-art deep generative learning to estimate the conditional density functions, and establish a sharp upper bound on the approximation error of the estimators. We derive a doubly robust test statistic, which employs a nonparametric estimation but achieves a parametric convergence rate. We further adopt sample splitting and cross-fitting to minimize the conditions required to ensure the consistency of the test. We demonstrate the efficacy of the test through both simulations and the three data applications.
Joint Optimization of Class-Specific Training- and Test-Time Data Augmentation in Segmentation
May 30, 2023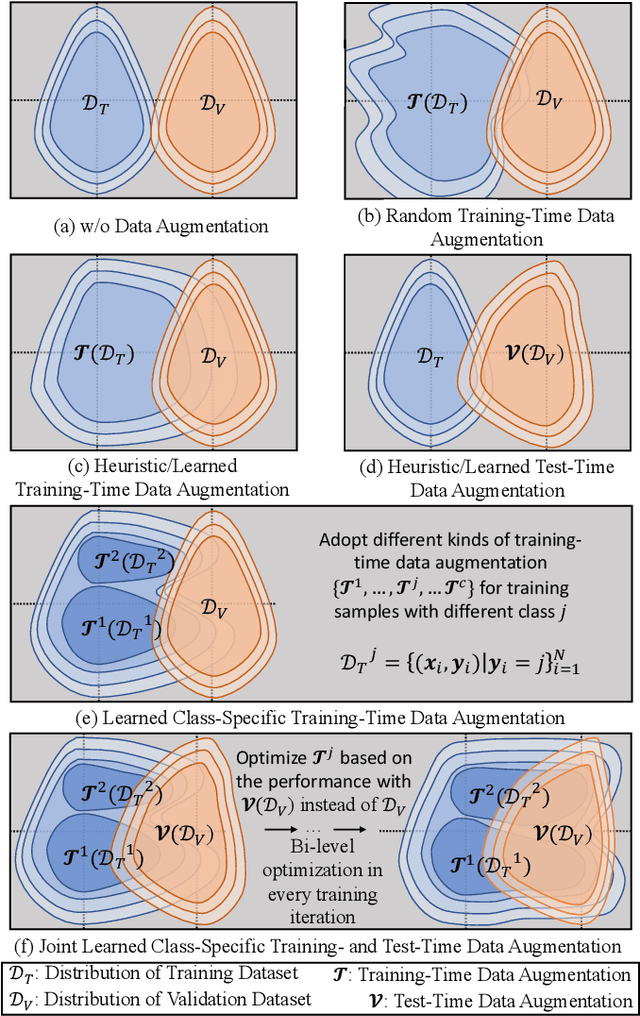
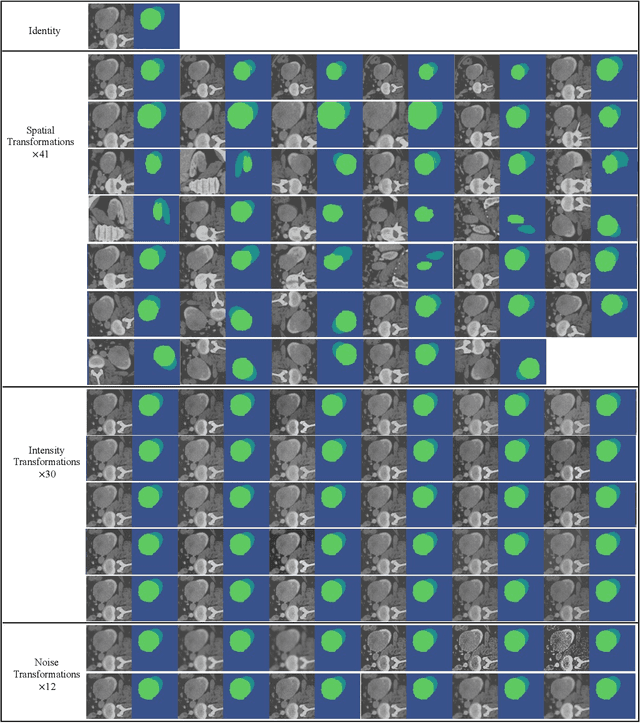
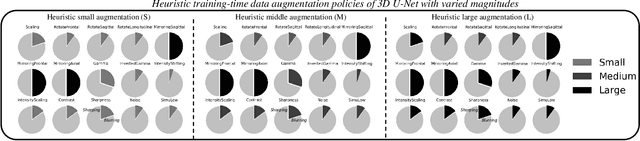
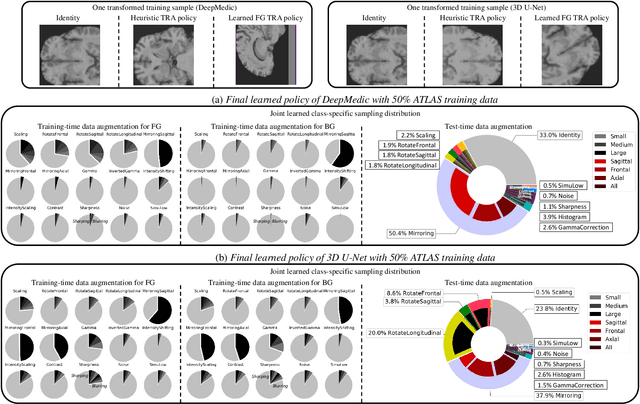
This paper presents an effective and general data augmentation framework for medical image segmentation. We adopt a computationally efficient and data-efficient gradient-based meta-learning scheme to explicitly align the distribution of training and validation data which is used as a proxy for unseen test data. We improve the current data augmentation strategies with two core designs. First, we learn class-specific training-time data augmentation (TRA) effectively increasing the heterogeneity within the training subsets and tackling the class imbalance common in segmentation. Second, we jointly optimize TRA and test-time data augmentation (TEA), which are closely connected as both aim to align the training and test data distribution but were so far considered separately in previous works. We demonstrate the effectiveness of our method on four medical image segmentation tasks across different scenarios with two state-of-the-art segmentation models, DeepMedic and nnU-Net. Extensive experimentation shows that the proposed data augmentation framework can significantly and consistently improve the segmentation performance when compared to existing solutions. Code is publicly available.
Deep Directly-Trained Spiking Neural Networks for Object Detection
Jul 24, 2023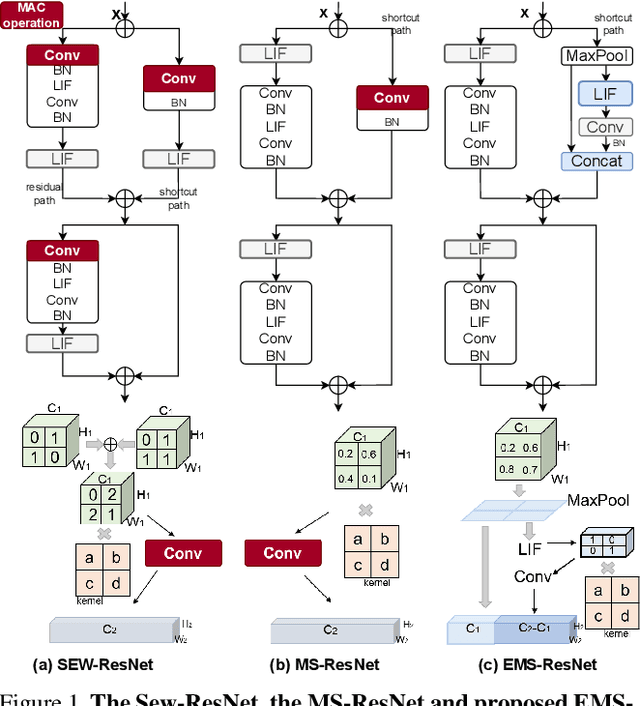

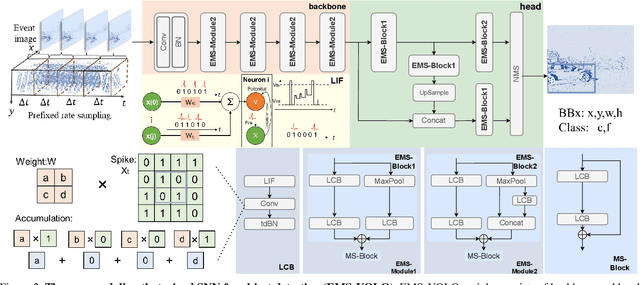
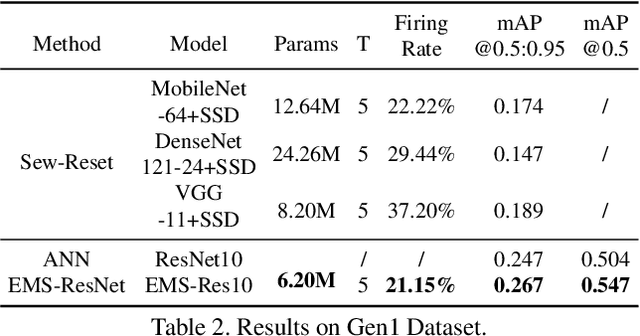
Spiking neural networks (SNNs) are brain-inspired energy-efficient models that encode information in spatiotemporal dynamics. Recently, deep SNNs trained directly have shown great success in achieving high performance on classification tasks with very few time steps. However, how to design a directly-trained SNN for the regression task of object detection still remains a challenging problem. To address this problem, we propose EMS-YOLO, a novel directly-trained SNN framework for object detection, which is the first trial to train a deep SNN with surrogate gradients for object detection rather than ANN-SNN conversion strategies. Specifically, we design a full-spike residual block, EMS-ResNet, which can effectively extend the depth of the directly-trained SNN with low power consumption. Furthermore, we theoretically analyze and prove the EMS-ResNet could avoid gradient vanishing or exploding. The results demonstrate that our approach outperforms the state-of-the-art ANN-SNN conversion methods (at least 500 time steps) in extremely fewer time steps (only 4 time steps). It is shown that our model could achieve comparable performance to the ANN with the same architecture while consuming 5.83 times less energy on the frame-based COCO Dataset and the event-based Gen1 Dataset.
JetSeg: Efficient Real-Time Semantic Segmentation Model for Low-Power GPU-Embedded Systems
May 19, 2023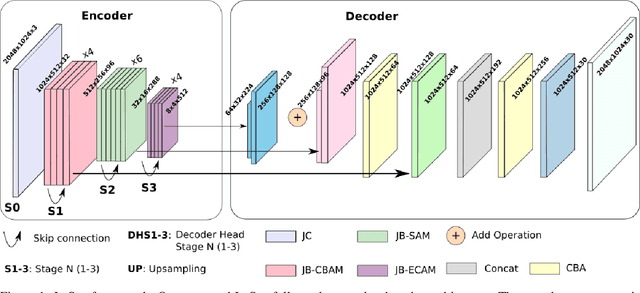
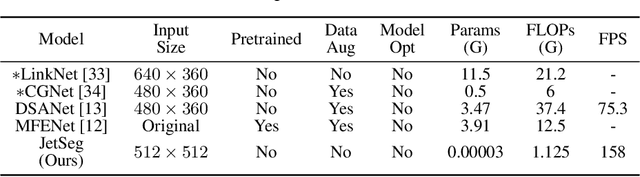
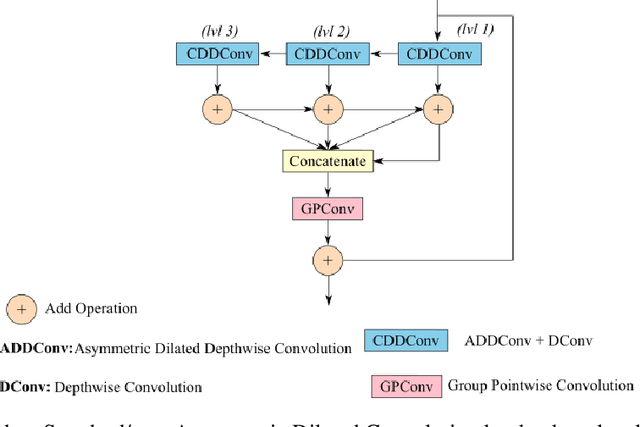
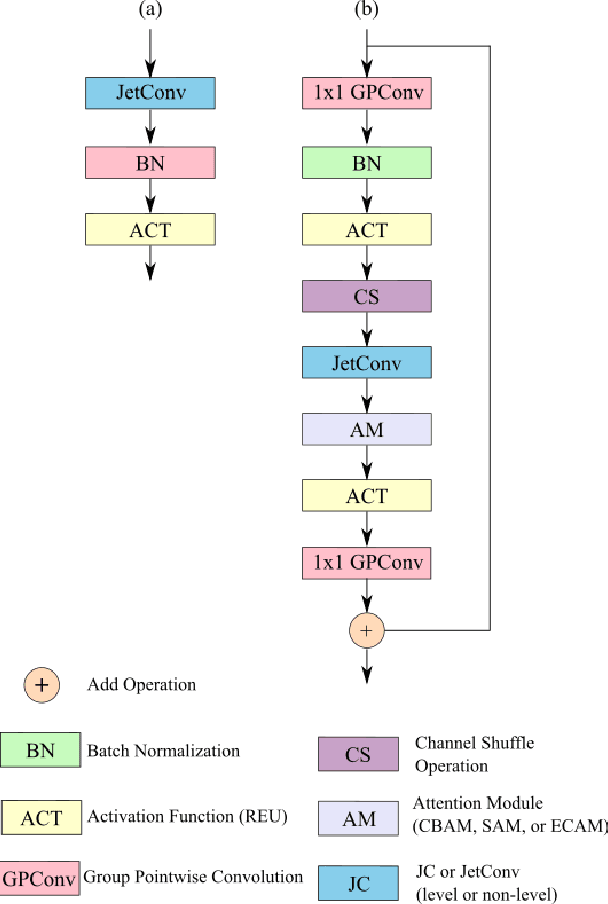
Real-time semantic segmentation is a challenging task that requires high-accuracy models with low-inference times. Implementing these models on embedded systems is limited by hardware capability and memory usage, which produces bottlenecks. We propose an efficient model for real-time semantic segmentation called JetSeg, consisting of an encoder called JetNet, and an improved RegSeg decoder. The JetNet is designed for GPU-Embedded Systems and includes two main components: a new light-weight efficient block called JetBlock, that reduces the number of parameters minimizing memory usage and inference time without sacrificing accuracy; a new strategy that involves the combination of asymmetric and non-asymmetric convolutions with depthwise-dilated convolutions called JetConv, a channel shuffle operation, light-weight activation functions, and a convenient number of group convolutions for embedded systems, and an innovative loss function named JetLoss, which integrates the Precision, Recall, and IoUB losses to improve semantic segmentation and reduce computational complexity. Experiments demonstrate that JetSeg is much faster on workstation devices and more suitable for Low-Power GPU-Embedded Systems than existing state-of-the-art models for real-time semantic segmentation. Our approach outperforms state-of-the-art real-time encoder-decoder models by reducing 46.70M parameters and 5.14% GFLOPs, which makes JetSeg up to 2x faster on the NVIDIA Titan RTX GPU and the Jetson Xavier than other models. The JetSeg code is available at https://github.com/mmontielpz/jetseg.
Reducing the Cost of Cycle-Time Tuning for Real-World Policy Optimization
May 09, 2023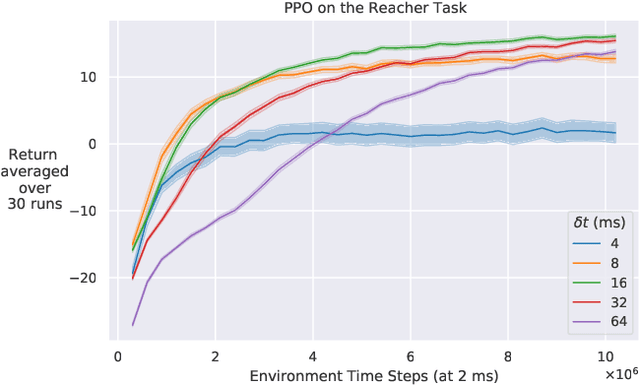
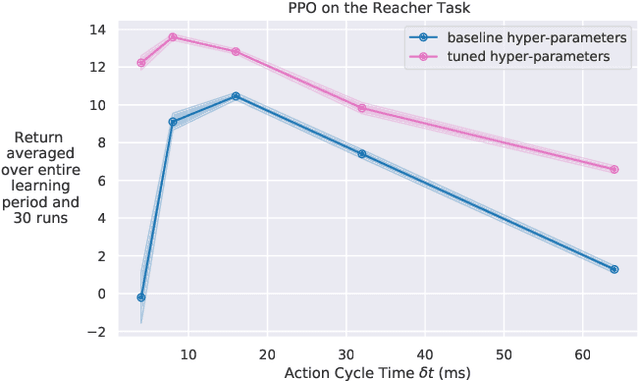
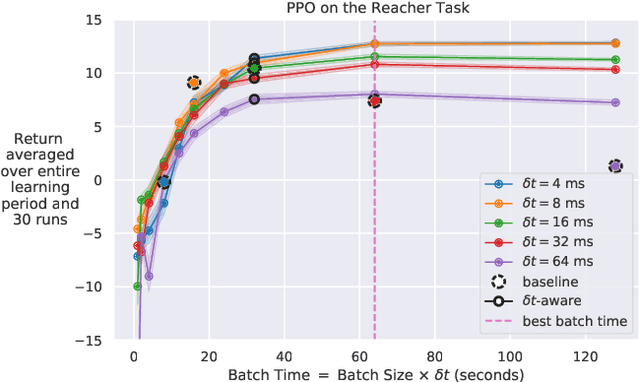
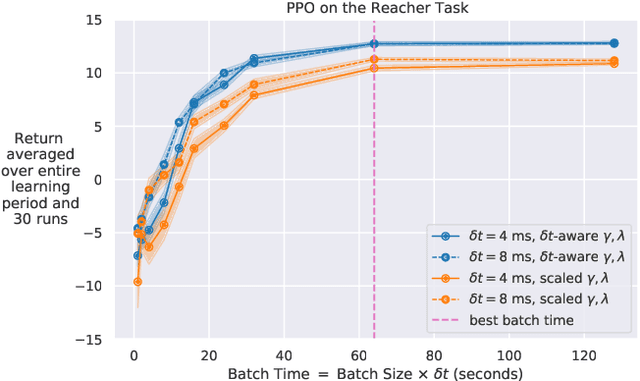
Continuous-time reinforcement learning tasks commonly use discrete steps of fixed cycle times for actions. As practitioners need to choose the action-cycle time for a given task, a significant concern is whether the hyper-parameters of the learning algorithm need to be re-tuned for each choice of the cycle time, which is prohibitive for real-world robotics. In this work, we investigate the widely-used baseline hyper-parameter values of two policy gradient algorithms -- PPO and SAC -- across different cycle times. Using a benchmark task where the baseline hyper-parameters of both algorithms were shown to work well, we reveal that when a cycle time different than the task default is chosen, PPO with baseline hyper-parameters fails to learn. Moreover, both PPO and SAC with their baseline hyper-parameters perform substantially worse than their tuned values for each cycle time. We propose novel approaches for setting these hyper-parameters based on the cycle time. In our experiments on simulated and real-world robotic tasks, the proposed approaches performed at least as well as the baseline hyper-parameters, with significantly better performance for most choices of the cycle time, and did not result in learning failure for any cycle time. Hyper-parameter tuning still remains a significant barrier for real-world robotics, as our approaches require some initial tuning on a new task, even though it is negligible compared to an extensive tuning for each cycle time. Our approach requires no additional tuning after the cycle time is changed for a given task and is a step toward avoiding extensive and costly hyper-parameter tuning for real-world policy optimization.
Generalized Forgetting Recursive Least Squares: Stability and Robustness Guarantees
Aug 08, 2023This work present generalized forgetting recursive least squares (GF-RLS), a generalization of recursive least squares (RLS) that encompasses many extensions of RLS as special cases. First, sufficient conditions are presented for the 1) Lyapunov stability, 2) uniform Lyapunov stability, 3) global asymptotic stability, and 4) global uniform exponential stability of parameter estimation error in GF-RLS when estimating fixed parameters without noise. Second, robustness guarantees are derived for the estimation of time-varying parameters in the presence of measurement noise and regressor noise. These robustness guarantees are presented in terms of global uniform ultimate boundedness of the parameter estimation error. A specialization of this result gives a bound to the asymptotic bias of least squares estimators in the errors-in-variables problem. Lastly, a survey is presented to show how GF-RLS can be used to analyze various extensions of RLS from the literature.
Spatiotemporal Attention-based Semantic Compression for Real-time Video Recognition
May 22, 2023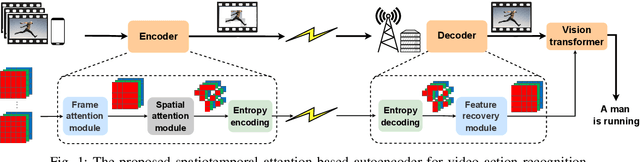

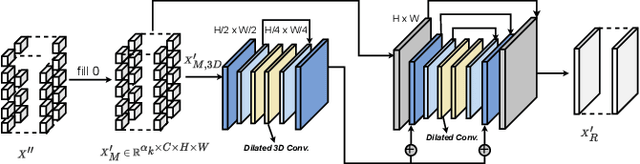
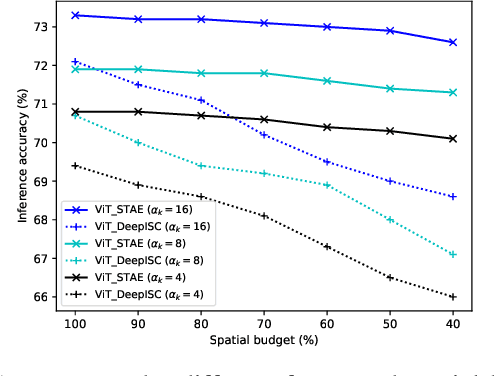
This paper studies the computational offloading of video action recognition in edge computing. To achieve effective semantic information extraction and compression, following semantic communication we propose a novel spatiotemporal attention-based autoencoder (STAE) architecture, including a frame attention module and a spatial attention module, to evaluate the importance of frames and pixels in each frame. Additionally, we use entropy encoding to remove statistical redundancy in the compressed data to further reduce communication overhead. At the receiver, we develop a lightweight decoder that leverages a 3D-2D CNN combined architecture to reconstruct missing information by simultaneously learning temporal and spatial information from the received data to improve accuracy. To fasten convergence, we use a step-by-step approach to train the resulting STAE-based vision transformer (ViT_STAE) models. Experimental results show that ViT_STAE can compress the video dataset HMDB51 by 104x with only 5% accuracy loss, outperforming the state-of-the-art baseline DeepISC. The proposed ViT_STAE achieves faster inference and higher accuracy than the DeepISC-based ViT model under time-varying wireless channel, which highlights the effectiveness of STAE in guaranteeing higher accuracy under time constraints.