 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CaptAinGlove: Capacitive and Inertial Fusion-Based Glove for Real-Time on Edge Hand Gesture Recognition for Drone Control
Jun 07, 2023

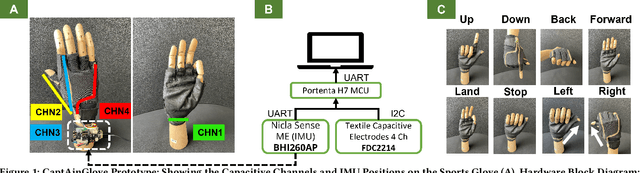
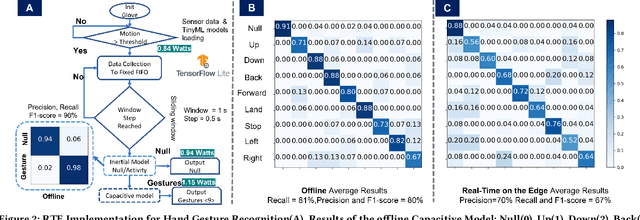
We present CaptAinGlove, a textile-based, low-power (1.15Watts), privacy-conscious, real-time on-the-edge (RTE) glove-based solution with a tiny memory footprint (2MB), designed to recognize hand gestures used for drone control. We employ lightweight convolutional neural networks as the backbone models and a hierarchical multimodal fusion to reduce power consumption and improve accuracy. The system yields an F1-score of 80% for the offline evaluation of nine classes; eight hand gesture commands and null activity. For the RTE, we obtained an F1-score of 67% (one user).
VSMask: Defending Against Voice Synthesis Attack via Real-Time Predictive Perturbation
May 09, 2023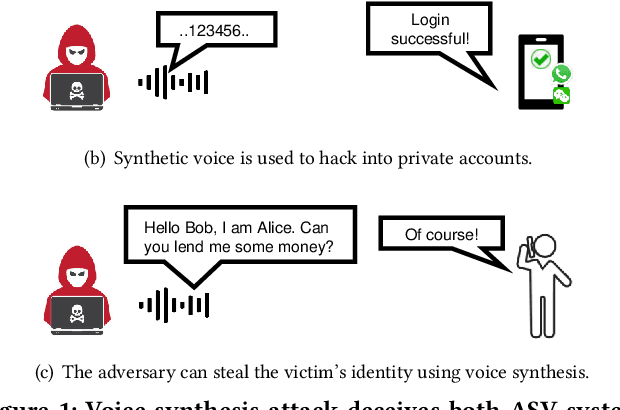
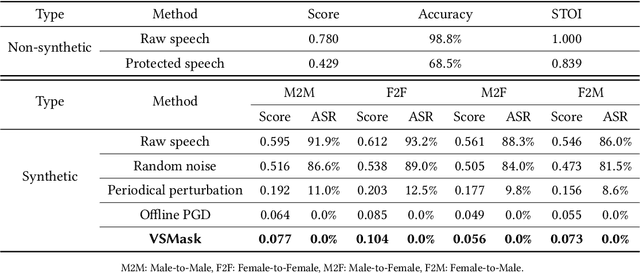
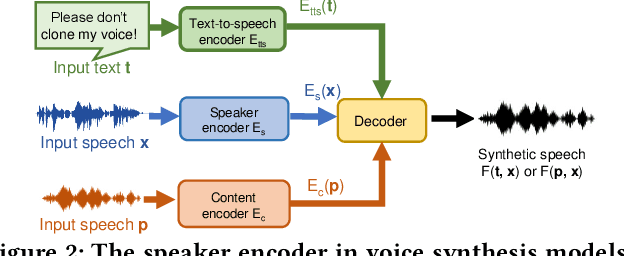
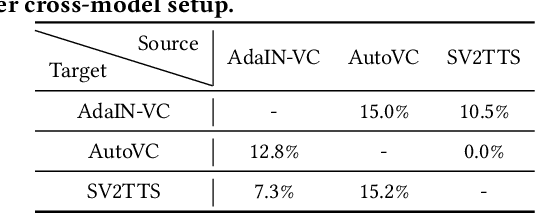
Deep learning based voice synthesis technology generates artificial human-like speeches, which has been used in deepfakes or identity theft attacks. Existing defense mechanisms inject subtle adversarial perturbations into the raw speech audios to mislead the voice synthesis models. However, optimizing the adversarial perturbation not only consumes substantial computation time, but it also requires the availability of entire speech. Therefore, they are not suitable for protecting live speech streams, such as voice messages or online meetings. In this paper, we propose VSMask, a real-time protection mechanism against voice synthesis attacks. Different from offline protection schemes, VSMask leverages a predictive neural network to forecast the most effective perturbation for the upcoming streaming speech. VSMask introduces a universal perturbation tailored for arbitrary speech input to shield a real-time speech in its entirety. To minimize the audio distortion within the protected speech, we implement a weight-based perturbation constraint to reduce the perceptibility of the added perturbation. We comprehensively evaluate VSMask protection performance under different scenarios. The experimental results indicate that VSMask can effectively defend against 3 popular voice synthesis models. None of the synthetic voice could deceive the speaker verification models or human ears with VSMask protection. In a physical world experiment, we demonstrate that VSMask successfully safeguards the real-time speech by injecting the perturbation over the air.
Learning when to observe: A frugal reinforcement learning framework for a high-cost world
Jul 24, 2023Reinforcement learning (RL) has been shown to learn sophisticated control policies for complex tasks including games, robotics, heating and cooling systems and text generation. The action-perception cycle in RL, however, generally assumes that a measurement of the state of the environment is available at each time step without a cost. In applications such as materials design, deep-sea and planetary robot exploration and medicine, however, there can be a high cost associated with measuring, or even approximating, the state of the environment. In this paper, we survey the recently growing literature that adopts the perspective that an RL agent might not need, or even want, a costly measurement at each time step. Within this context, we propose the Deep Dynamic Multi-Step Observationless Agent (DMSOA), contrast it with the literature and empirically evaluate it on OpenAI gym and Atari Pong environments. Our results, show that DMSOA learns a better policy with fewer decision steps and measurements than the considered alternative from the literature. The corresponding code is available at: \url{https://github.com/cbellinger27/Learning-when-to-observe-in-RL
Underlaid Sensing Pilot for Integrated Sensing and Communications
Jul 24, 2023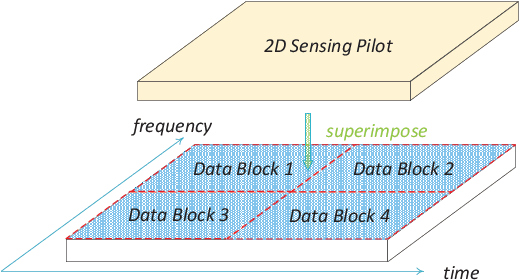
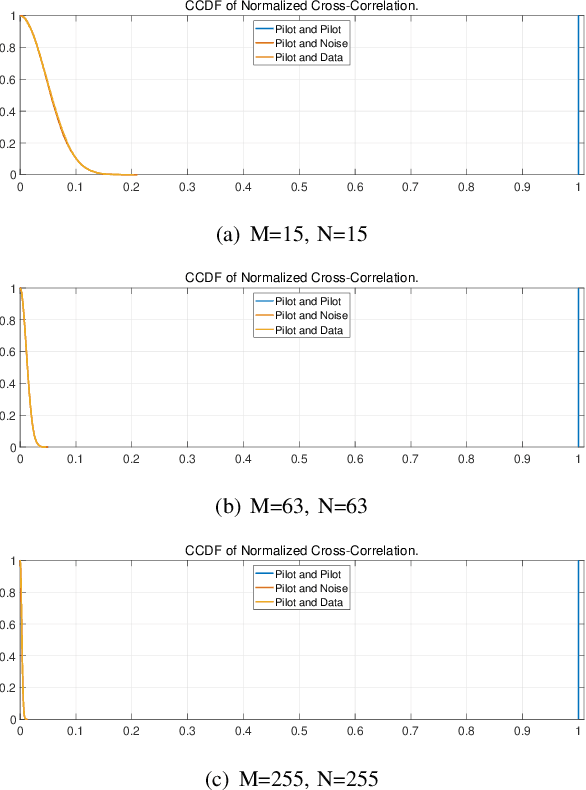
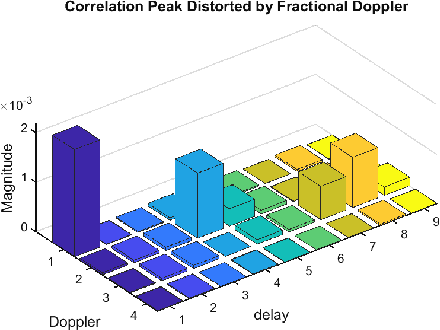
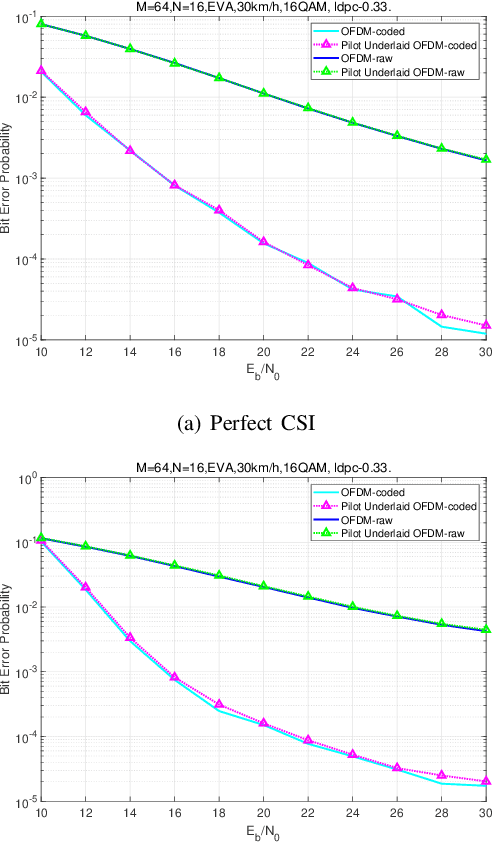
This paper investigates a novel underlaid sensing pilot signal design for integrated sensing and communications (ISAC) in an OFDM-based communication system. The proposed two-dimensional (2D) pilot signal is first generated on the delay-Doppler (DD) plane and then converted to the time-frequency (TF) plane for multiplexing with the OFDM data symbols. The sensing signal underlays the OFDM data, allowing for the sharing of time-frequency resources. In this framework, sensing detection is implemented based on a simple 2D correlation, taking advantage of the favorable auto-correlation properties of the sensing pilot. In the communication part, the sensing pilot, served as a known signal, can be utilized for channel estimation and equalization to ensure optimal symbol detection performance. The underlaid sensing pilot demonstrates good scalability and can adapt to different delay and Doppler resolution requirements without violating the OFDM frame structure. Experimental results show the effective sensing performance of the proposed pilot, with only a small fraction of power shared from the OFDM data, while maintaining satisfactory symbol detection performance in communication.
"Kurosawa": A Script Writer's Assistant
Aug 06, 2023Storytelling is the lifeline of the entertainment industry -- movies, TV shows, and stand-up comedies, all need stories. A good and gripping script is the lifeline of storytelling and demands creativity and resource investment. Good scriptwriters are rare to find and often work under severe time pressure. Consequently, entertainment media are actively looking for automation. In this paper, we present an AI-based script-writing workbench called KUROSAWA which addresses the tasks of plot generation and script generation. Plot generation aims to generate a coherent and creative plot (600-800 words) given a prompt (15-40 words). Script generation, on the other hand, generates a scene (200-500 words) in a screenplay format from a brief description (15-40 words). Kurosawa needs data to train. We use a 4-act structure of storytelling to annotate the plot dataset manually. We create a dataset of 1000 manually annotated plots and their corresponding prompts/storylines and a gold-standard dataset of 1000 scenes with four main elements -- scene headings, action lines, dialogues, and character names -- tagged individually. We fine-tune GPT-3 with the above datasets to generate plots and scenes. These plots and scenes are first evaluated and then used by the scriptwriters of a large and famous media platform ErosNow. We release the annotated datasets and the models trained on these datasets as a working benchmark for automatic movie plot and script generation.
Communication-Free Distributed GNN Training with Vertex Cut
Aug 06, 2023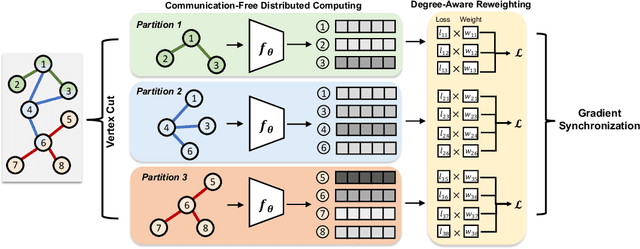
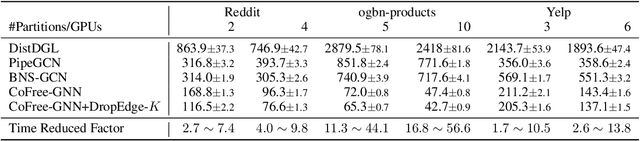
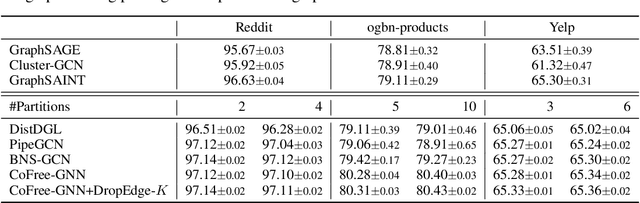

Training Graph Neural Networks (GNNs) on real-world graphs consisting of billions of nodes and edges is quite challenging, primarily due to the substantial memory needed to store the graph and its intermediate node and edge features, and there is a pressing need to speed up the training process. A common approach to achieve speed up is to divide the graph into many smaller subgraphs, which are then distributed across multiple GPUs in one or more machines and processed in parallel. However, existing distributed methods require frequent and substantial cross-GPU communication, leading to significant time overhead and progressively diminishing scalability. Here, we introduce CoFree-GNN, a novel distributed GNN training framework that significantly speeds up the training process by implementing communication-free training. The framework utilizes a Vertex Cut partitioning, i.e., rather than partitioning the graph by cutting the edges between partitions, the Vertex Cut partitions the edges and duplicates the node information to preserve the graph structure. Furthermore, the framework maintains high model accuracy by incorporating a reweighting mechanism to handle a distorted graph distribution that arises from the duplicated nodes. We also propose a modified DropEdge technique to further speed up the training process. Using an extensive set of experiments on real-world networks, we demonstrate that CoFree-GNN speeds up the GNN training process by up to 10 times over the existing state-of-the-art GNN training approaches.
Base-based Model Checking for Multi-Agent Only Believing (long version)
Jul 27, 2023
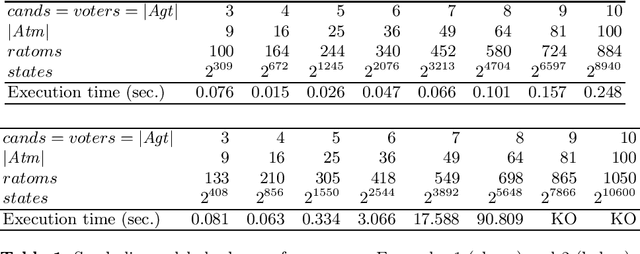
We present a novel semantics for the language of multi-agent only believing exploiting belief bases, and show how to use it for automatically checking formulas of this language and of its dynamic extension with private belief expansion operators. We provide a PSPACE algorithm for model checking relying on a reduction to QBF and alternative dedicated algorithm relying on the exploration of the state space. We present an implementation of the QBF-based algorithm and some experimental results on computation time in a concrete example.
TASTY: A Transformer based Approach to Space and Time complexity
May 10, 2023
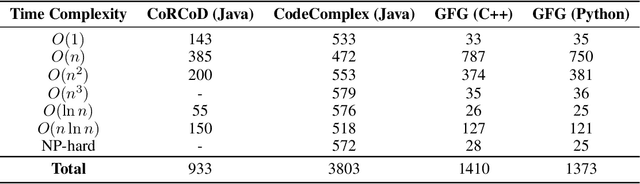

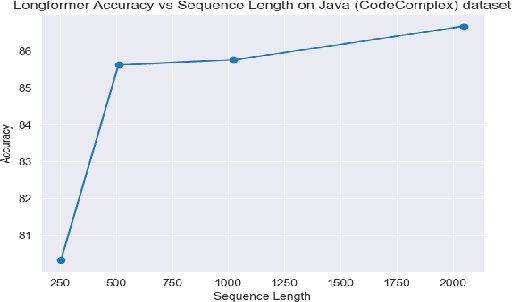
Code based Language Models (LMs) have shown very promising results in the field of software engineering with applications such as code refinement, code completion and generation. However, the task of time and space complexity classification from code has not been extensively explored due to a lack of datasets, with prior endeavors being limited to Java. In this project, we aim to address these gaps by creating a labelled dataset of code snippets spanning multiple languages (Python and C++ datasets currently, with C, C#, and JavaScript datasets being released shortly). We find that existing time complexity calculation libraries and tools only apply to a limited number of use-cases. The lack of a well-defined rule based system motivates the application of several recently proposed code-based LMs. We demonstrate the effectiveness of dead code elimination and increasing the maximum sequence length of LMs. In addition to time complexity, we propose to use LMs to find space complexities from code, and to the best of our knowledge, this is the first attempt to do so. Furthermore, we introduce a novel code comprehension task, called cross-language transfer, where we fine-tune the LM on one language and run inference on another. Finally, we visualize the activation of the attention fed classification head of our LMs using Non-negative Matrix Factorization (NMF) to interpret our results.
Towards a Fully Unsupervised Framework for Intent Induction in Customer Support Dialogues
Jul 28, 2023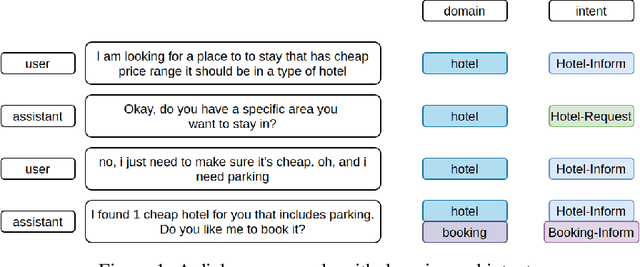
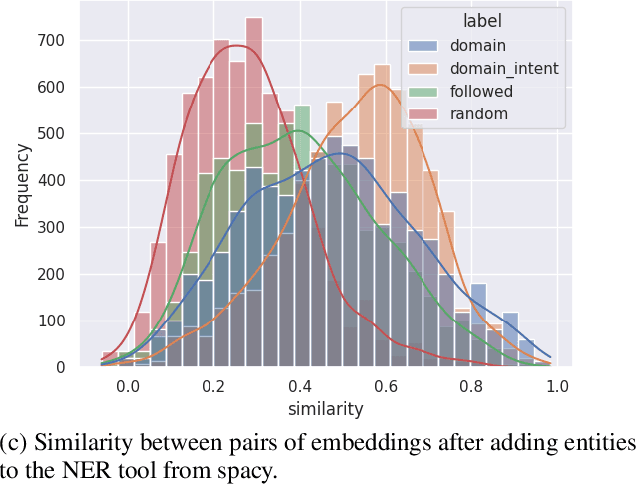
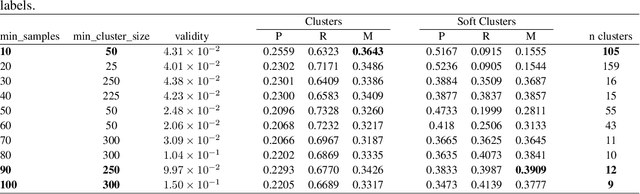
State of the art models in intent induction require annotated datasets. However, annotating dialogues is time-consuming, laborious and expensive. In this work, we propose a completely unsupervised framework for intent induction within a dialogue. In addition, we show how pre-processing the dialogue corpora can improve results. Finally, we show how to extract the dialogue flows of intentions by investigating the most common sequences. Although we test our work in the MultiWOZ dataset, the fact that this framework requires no prior knowledge make it applicable to any possible use case, making it very relevant to real world customer support applications across industry.
Spectral Ranking Inferences based on General Multiway Comparisons
Aug 05, 2023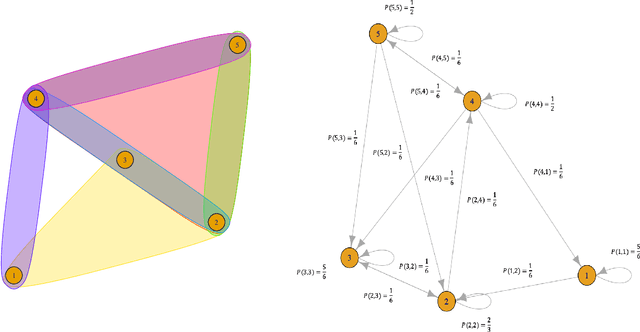
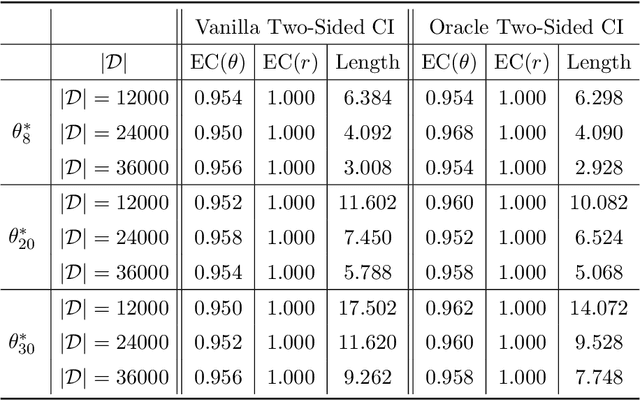
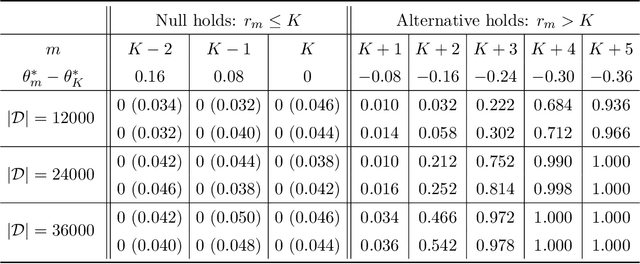
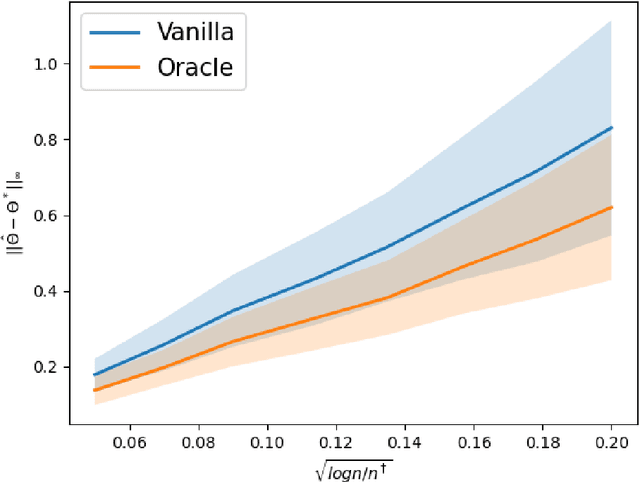
This paper studies the performance of the spectral method in the estimation and uncertainty quantification of the unobserved preference scores of compared entities in a very general and more realistic setup in which the comparison graph consists of hyper-edges of possible heterogeneous sizes and the number of comparisons can be as low as one for a given hyper-edge. Such a setting is pervasive in real applications, circumventing the need to specify the graph randomness and the restrictive homogeneous sampling assumption imposed in the commonly-used Bradley-Terry-Luce (BTL) or Plackett-Luce (PL) models. Furthermore, in the scenarios when the BTL or PL models are appropriate, we unravel the relationship between the spectral estimator and the Maximum Likelihood Estimator (MLE). We discover that a two-step spectral method, where we apply the optimal weighting estimated from the equal weighting vanilla spectral method, can achieve the same asymptotic efficiency as the MLE. Given the asymptotic distributions of the estimated preference scores, we also introduce a comprehensive framework to carry out both one-sample and two-sample ranking inferences, applicable to both fixed and random graph settings. It is noteworthy that it is the first time effective two-sample rank testing methods are proposed. Finally, we substantiate our findings via comprehensive numerical simulations and subsequently apply our developed methodologies to perform statistical inferences on statistics journals and movie rankings.