 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Practical Active Noise Control: Restriction of Maximum Output Power
Jul 20, 2023
This paper presents some recent algorithms developed by the authors for real-time adaptive active noise (AANC) control systems. These algorithms address some of the common challenges faced by AANC systems, such as speaker saturation, system divergence, and disturbance rejection. Speaker saturation can introduce nonlinearity into the adaptive system and degrade the noise reduction performance. System divergence can occur when the secondary speaker units are over-amplified or when there is a disturbance other than the noise to be controlled. Disturbance rejection is important to prevent the adaptive system from adapting to unwanted signals. The paper provides guidelines for implementing and operating real-time AANC systems based on these algorithms.
VSMask: Defending Against Voice Synthesis Attack via Real-Time Predictive Perturbation
May 09, 2023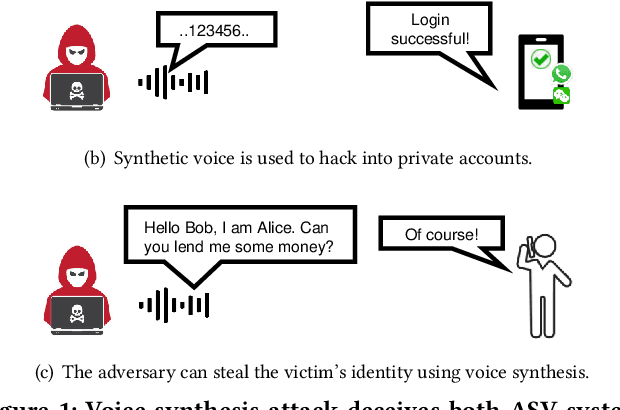
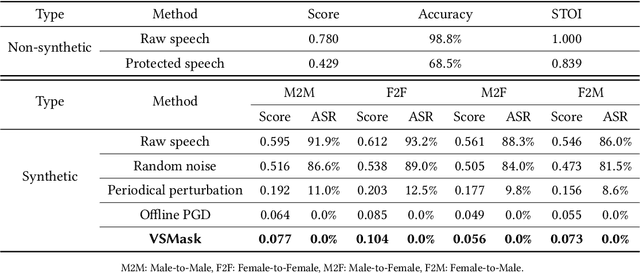
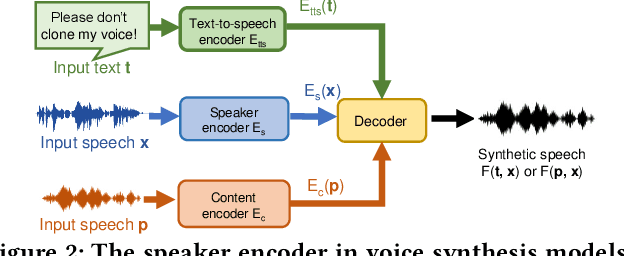
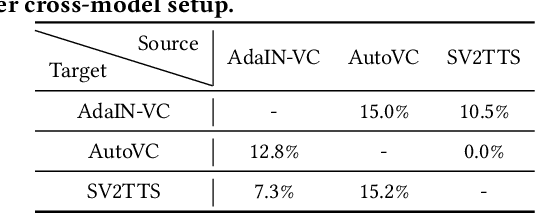
Deep learning based voice synthesis technology generates artificial human-like speeches, which has been used in deepfakes or identity theft attacks. Existing defense mechanisms inject subtle adversarial perturbations into the raw speech audios to mislead the voice synthesis models. However, optimizing the adversarial perturbation not only consumes substantial computation time, but it also requires the availability of entire speech. Therefore, they are not suitable for protecting live speech streams, such as voice messages or online meetings. In this paper, we propose VSMask, a real-time protection mechanism against voice synthesis attacks. Different from offline protection schemes, VSMask leverages a predictive neural network to forecast the most effective perturbation for the upcoming streaming speech. VSMask introduces a universal perturbation tailored for arbitrary speech input to shield a real-time speech in its entirety. To minimize the audio distortion within the protected speech, we implement a weight-based perturbation constraint to reduce the perceptibility of the added perturbation. We comprehensively evaluate VSMask protection performance under different scenarios. The experimental results indicate that VSMask can effectively defend against 3 popular voice synthesis models. None of the synthetic voice could deceive the speaker verification models or human ears with VSMask protection. In a physical world experiment, we demonstrate that VSMask successfully safeguards the real-time speech by injecting the perturbation over the air.
AI Increases Global Access to Reliable Flood Forecasts
Jul 30, 2023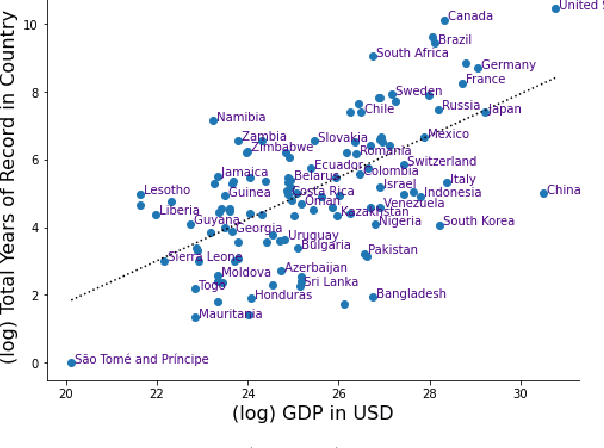
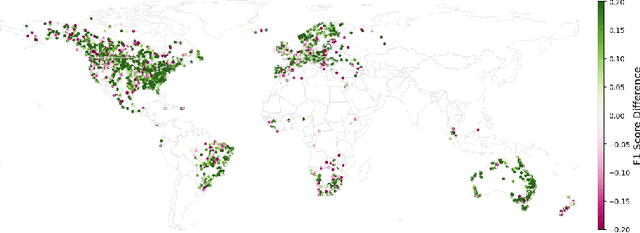
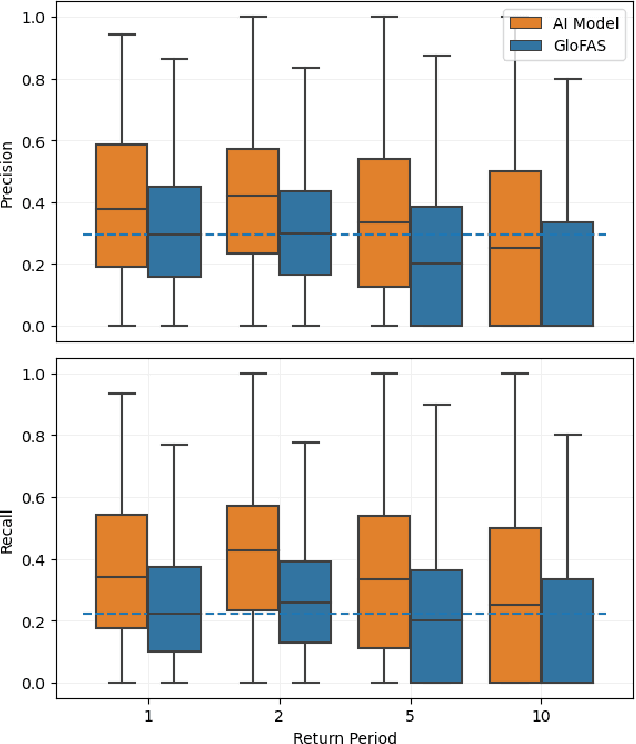
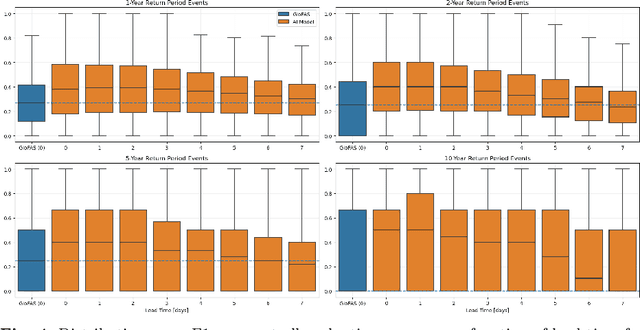
Floods are one of the most common and impactful natural disasters, with a disproportionate impact in developing countries that often lack dense streamflow monitoring networks. Accurate and timely warnings are critical for mitigating flood risks, but accurate hydrological simulation models typically must be calibrated to long data records in each watershed where they are applied. We developed an Artificial Intelligence (AI) model to predict extreme hydrological events at timescales up to 7 days in advance. This model significantly outperforms current state of the art global hydrology models (the Copernicus Emergency Management Service Global Flood Awareness System) across all continents, lead times, and return periods. AI is especially effective at forecasting in ungauged basins, which is important because only a few percent of the world's watersheds have stream gauges, with a disproportionate number of ungauged basins in developing countries that are especially vulnerable to the human impacts of flooding. We produce forecasts of extreme events in South America and Africa that achieve reliability approaching the current state of the art in Europe and North America, and we achieve reliability at between 4 and 6-day lead times that are similar to current state of the art nowcasts (0-day lead time). Additionally, we achieve accuracies over 10-year return period events that are similar to current accuracies over 2-year return period events, meaning that AI can provide warnings earlier and over larger and more impactful events. The model that we develop in this paper has been incorporated into an operational early warning system that produces publicly available (free and open) forecasts in real time in over 80 countries. This work using AI and open data highlights a need for increasing the availability of hydrological data to continue to improve global access to reliable flood warnings.
How to Scale Your EMA
Jul 27, 2023
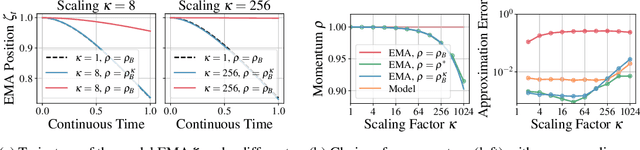
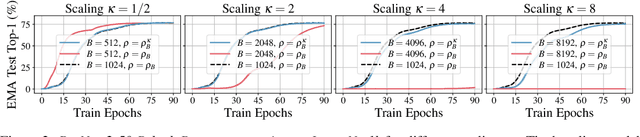
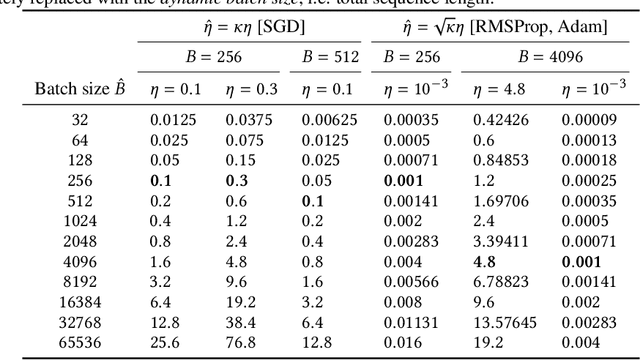
Preserving training dynamics across batch sizes is an important tool for practical machine learning as it enables the trade-off between batch size and wall-clock time. This trade-off is typically enabled by a scaling rule, for example, in stochastic gradient descent, one should scale the learning rate linearly with the batch size. Another important tool for practical machine learning is the model Exponential Moving Average (EMA), which is a model copy that does not receive gradient information, but instead follows its target model with some momentum. This model EMA can improve the robustness and generalization properties of supervised learning, stabilize pseudo-labeling, and provide a learning signal for Self-Supervised Learning (SSL). Prior works have treated the model EMA separately from optimization, leading to different training dynamics across batch sizes and lower model performance. In this work, we provide a scaling rule for optimization in the presence of model EMAs and demonstrate its validity across a range of architectures, optimizers, and data modalities. We also show the rule's validity where the model EMA contributes to the optimization of the target model, enabling us to train EMA-based pseudo-labeling and SSL methods at small and large batch sizes. For SSL, we enable training of BYOL up to batch size 24,576 without sacrificing performance, optimally a 6$\times$ wall-clock time reduction.
Graph Convolutional Network Enabled Power-Constrained HARQ Strategy for URLLC
Aug 04, 2023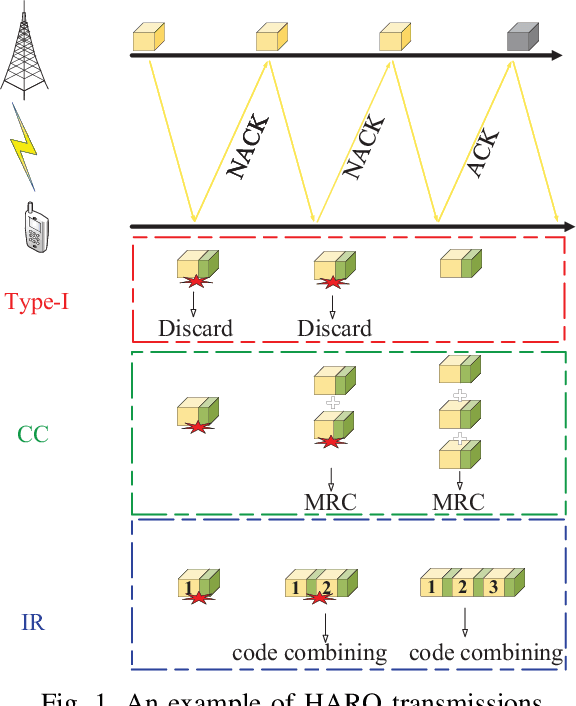
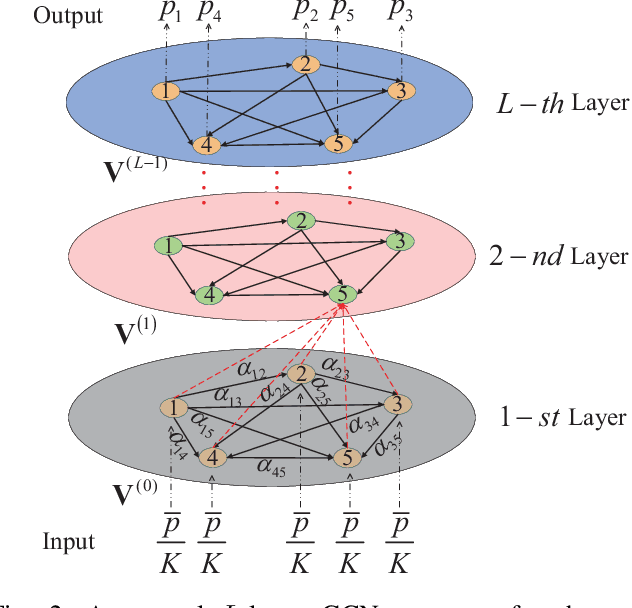
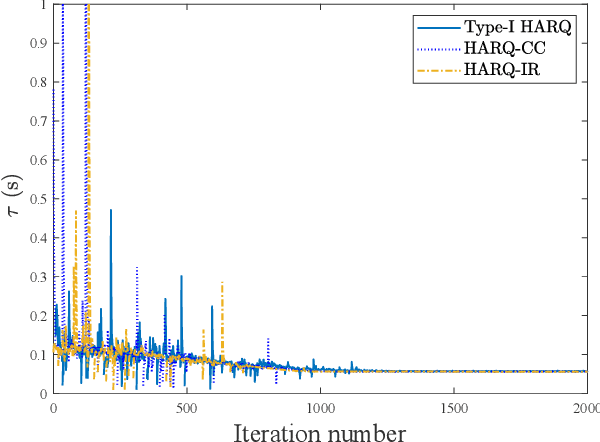
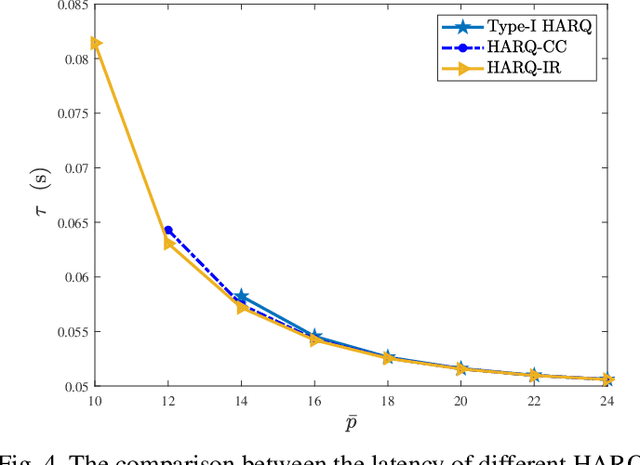
In this paper, a power-constrained hybrid automatic repeat request (HARQ) transmission strategy is developed to support ultra-reliable low-latency communications (URLLC). In particular, we aim to minimize the delivery latency of HARQ schemes over time-correlated fading channels, meanwhile ensuring the high reliability and limited power consumption. To ease the optimization, the simple asymptotic outage expressions of HARQ schemes are adopted. Furthermore, by noticing the non-convexity of the latency minimization problem and the intricate connection between different HARQ rounds, the graph convolutional network (GCN) is invoked for the optimal power solution owing to its powerful ability of handling the graph data. The primal-dual learning method is then leveraged to train the GCN weights. Consequently, the numerical results are presented for verification together with the comparisons among three HARQ schemes in terms of the latency and the reliability, where the three HARQ schemes include Type-I HARQ, HARQ with chase combining (HARQ-CC), and HARQ with incremental redundancy (HARQ-IR). To recapitulate, it is revealed that HARQ-IR offers the lowest latency while guaranteeing the demanded reliability target under a stringent power constraint, albeit at the price of high coding complexity.
Painterly Image Harmonization using Diffusion Model
Aug 04, 2023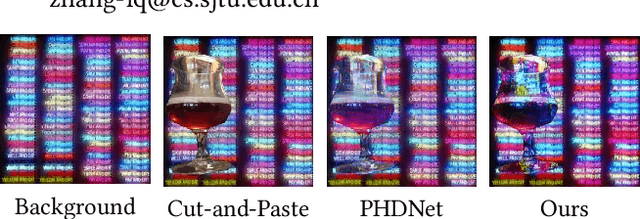

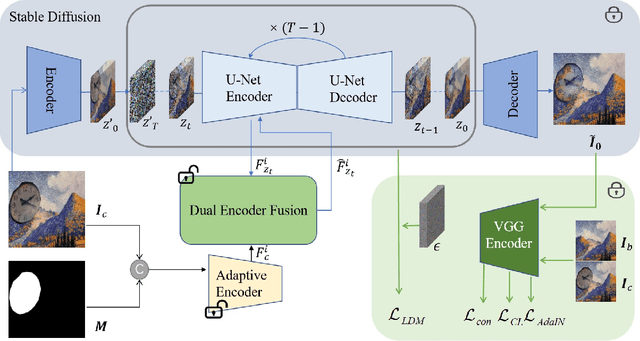
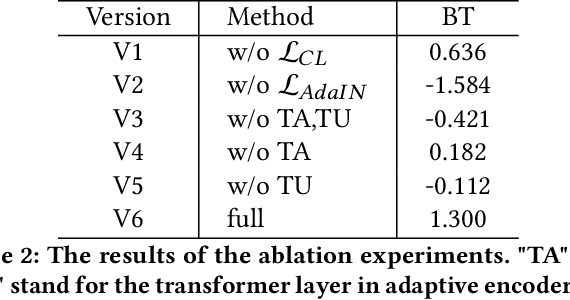
Painterly image harmonization aims to insert photographic objects into paintings and obtain artistically coherent composite images. Previous methods for this task mainly rely on inference optimization or generative adversarial network, but they are either very time-consuming or struggling at fine control of the foreground objects (e.g., texture and content details). To address these issues, we propose a novel Painterly Harmonization stable Diffusion model (PHDiffusion), which includes a lightweight adaptive encoder and a Dual Encoder Fusion (DEF) module. Specifically, the adaptive encoder and the DEF module first stylize foreground features within each encoder. Then, the stylized foreground features from both encoders are combined to guide the harmonization process. During training, besides the noise loss in diffusion model, we additionally employ content loss and two style losses, i.e., AdaIN style loss and contrastive style loss, aiming to balance the trade-off between style migration and content preservation. Compared with the state-of-the-art models from related fields, our PHDiffusion can stylize the foreground more sufficiently and simultaneously retain finer content. Our code and model are available at https://github.com/bcmi/PHDiffusion-Painterly-Image-Harmonization.
MVFlow: Deep Optical Flow Estimation of Compressed Videos with Motion Vector Prior
Aug 04, 2023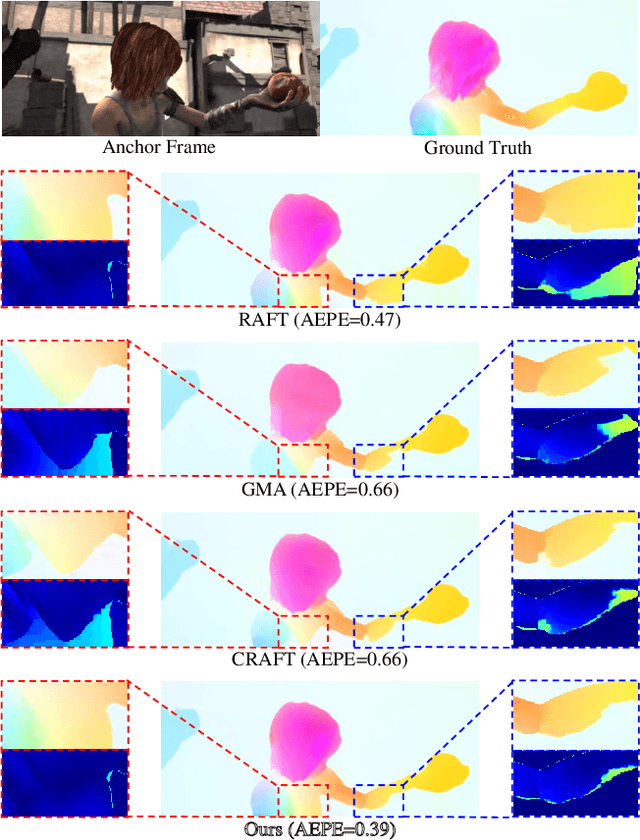
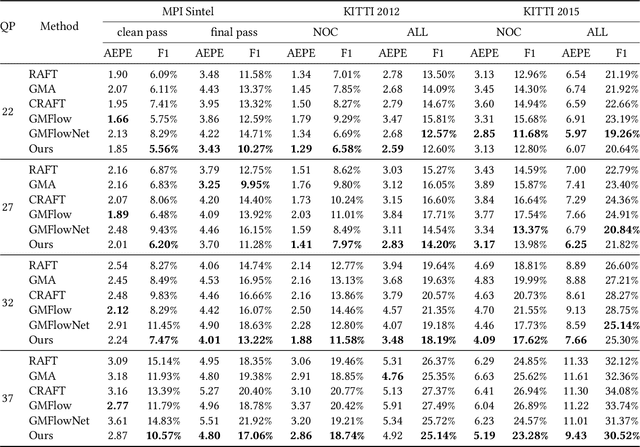
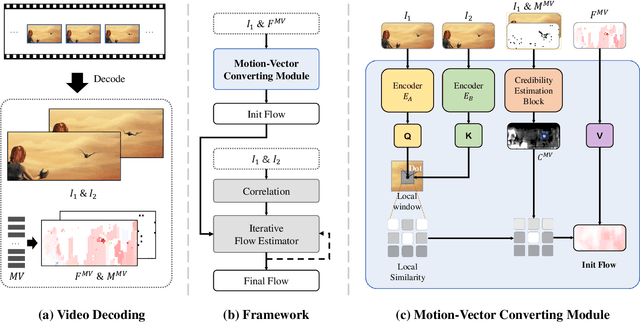
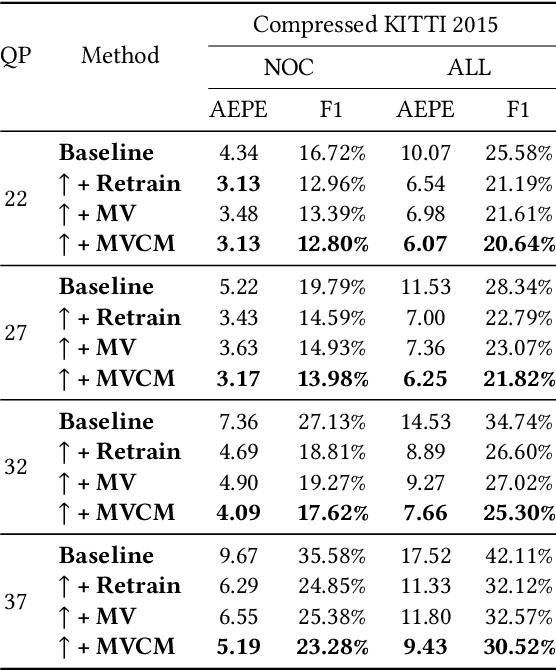
In recent years, many deep learning-based methods have been proposed to tackle the problem of optical flow estimation and achieved promising results. However, they hardly consider that most videos are compressed and thus ignore the pre-computed information in compressed video streams. Motion vectors, one of the compression information, record the motion of the video frames. They can be directly extracted from the compression code stream without computational cost and serve as a solid prior for optical flow estimation. Therefore, we propose an optical flow model, MVFlow, which uses motion vectors to improve the speed and accuracy of optical flow estimation for compressed videos. In detail, MVFlow includes a key Motion-Vector Converting Module, which ensures that the motion vectors can be transformed into the same domain of optical flow and then be utilized fully by the flow estimation module. Meanwhile, we construct four optical flow datasets for compressed videos containing frames and motion vectors in pairs. The experimental results demonstrate the superiority of our proposed MVFlow, which can reduce the AEPE by 1.09 compared to existing models or save 52% time to achieve similar accuracy to existing models.
Differential Evolution Algorithm based Hyper-Parameters Selection of Transformer Neural Network Model for Load Forecasting
Aug 04, 2023
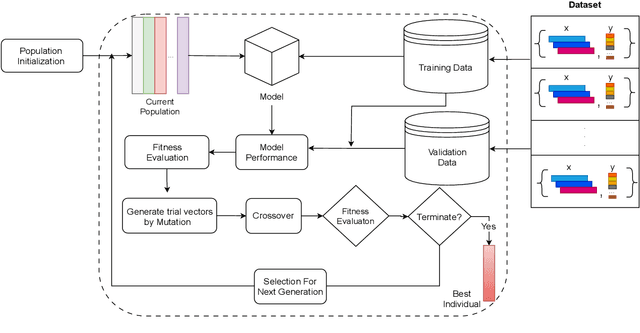
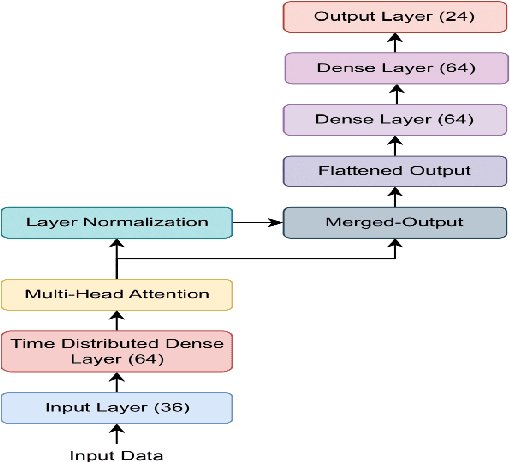
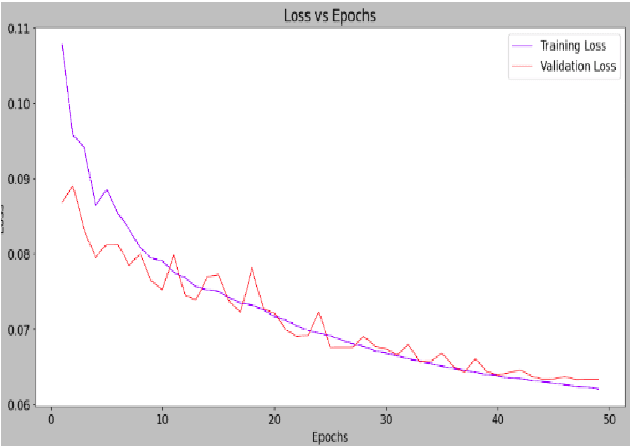
Accurate load forecasting plays a vital role in numerous sectors, but accurately capturing the complex dynamics of dynamic power systems remains a challenge for traditional statistical models. For these reasons, time-series models (ARIMA) and deep-learning models (ANN, LSTM, GRU, etc.) are commonly deployed and often experience higher success. In this paper, we analyze the efficacy of the recently developed Transformer-based Neural Network model in Load forecasting. Transformer models have the potential to improve Load forecasting because of their ability to learn long-range dependencies derived from their Attention Mechanism. We apply several metaheuristics namely Differential Evolution to find the optimal hyperparameters of the Transformer-based Neural Network to produce accurate forecasts. Differential Evolution provides scalable, robust, global solutions to non-differentiable, multi-objective, or constrained optimization problems. Our work compares the proposed Transformer based Neural Network model integrated with different metaheuristic algorithms by their performance in Load forecasting based on numerical metrics such as Mean Squared Error (MSE) and Mean Absolute Percentage Error (MAPE). Our findings demonstrate the potential of metaheuristic-enhanced Transformer-based Neural Network models in Load forecasting accuracy and provide optimal hyperparameters for each model.
Learning and Evaluating Human Preferences for Conversational Head Generation
Aug 02, 2023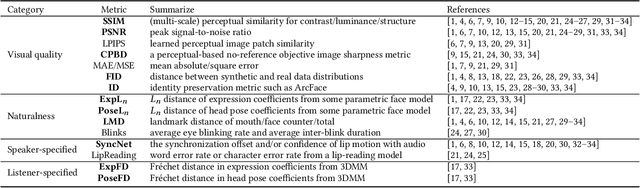
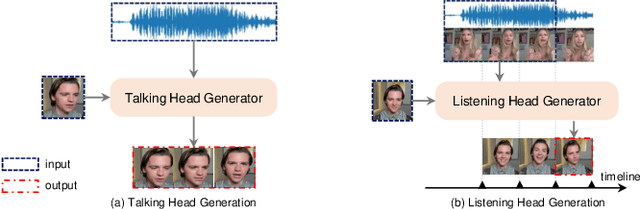
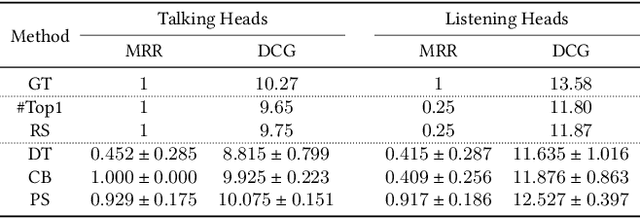
A reliable and comprehensive evaluation metric that aligns with manual preference assessments is crucial for conversational head video synthesis methods development. Existing quantitative evaluations often fail to capture the full complexity of human preference, as they only consider limited evaluation dimensions. Qualitative evaluations and user studies offer a solution but are time-consuming and labor-intensive. This limitation hinders the advancement of conversational head generation algorithms and systems. In this paper, we propose a novel learning-based evaluation metric named Preference Score (PS) for fitting human preference according to the quantitative evaluations across different dimensions. PS can serve as a quantitative evaluation without the need for human annotation. Experimental results validate the superiority of Preference Score in aligning with human perception, and also demonstrate robustness and generalizability to unseen data, making it a valuable tool for advancing conversation head generation. We expect this metric could facilitate new advances in conversational head generation. Project Page: https://https://github.com/dc3ea9f/PreferenceScore.
Virtual Reality Based Robot Teleoperation via Human-Scene Interaction
Aug 02, 2023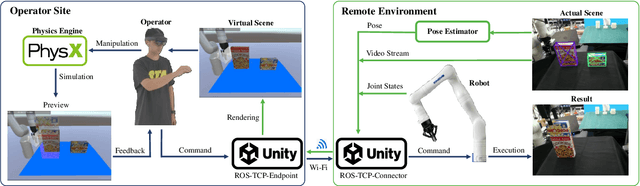
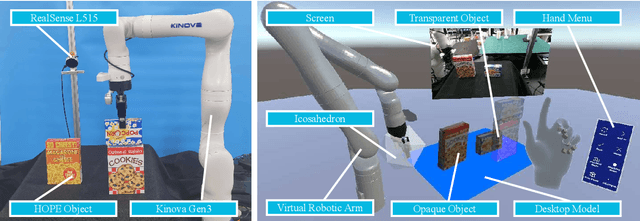


Robot teleoperation gains great success in various situations, including chemical pollution rescue, disaster relief, and long-distance manipulation. In this article, we propose a virtual reality (VR) based robot teleoperation system to achieve more efficient and natural interaction with humans in different scenes. A user-friendly VR interface is designed to help users interact with a desktop scene using their hands efficiently and intuitively. To improve user experience and reduce workload, we simulate the process in the physics engine to help build a preview of the scene after manipulation in the virtual scene before execution. We conduct experiments with different users and compare our system with a direct control method across several teleoperation tasks. The user study demonstrates that the proposed system enables users to perform operations more instinctively with a lighter mental workload. Users can perform pick-and-place and object-stacking tasks in a considerably short time, even for beginners. Our code is available at https://github.com/lingxiaomeng/VR_Teleoperation_Gen3.