 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Phonetic Segmentation of the UCLA Phonetics Lab Archive
Mar 28, 2024
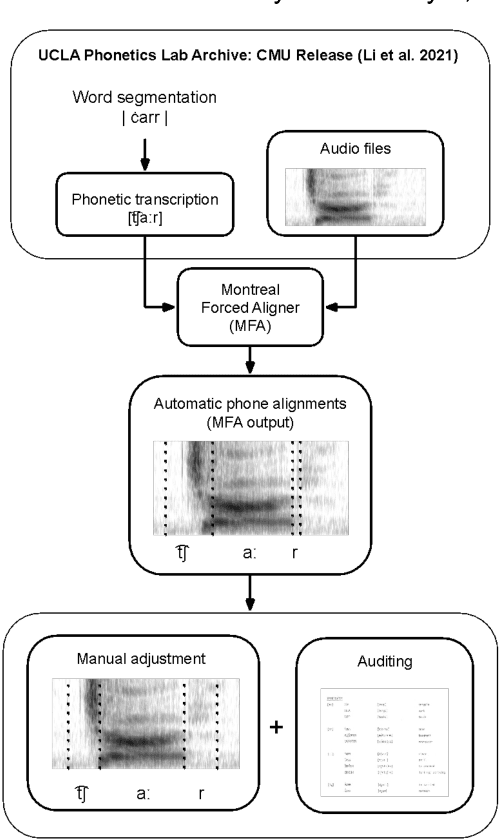
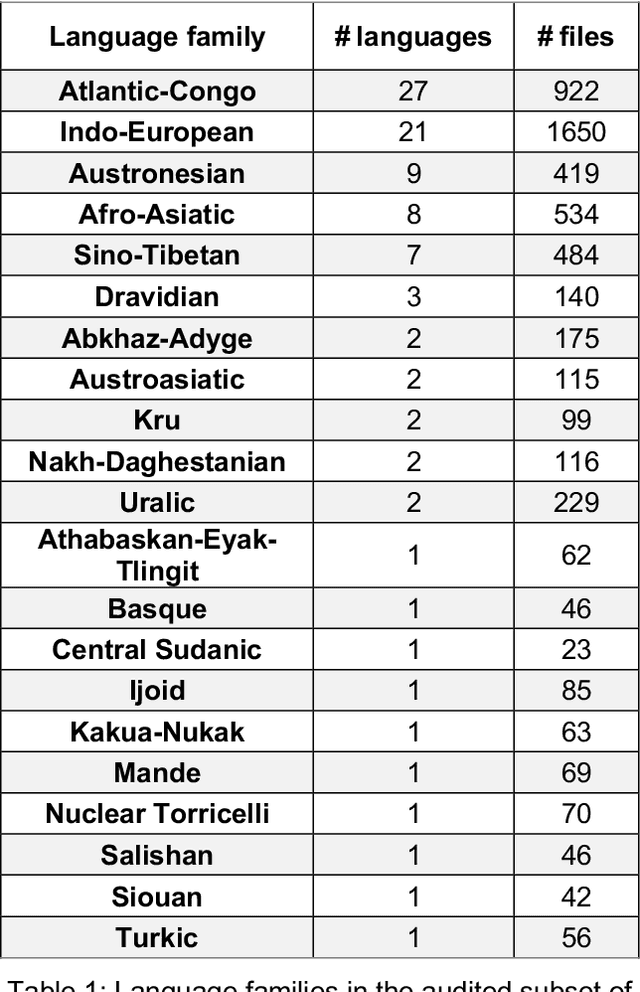
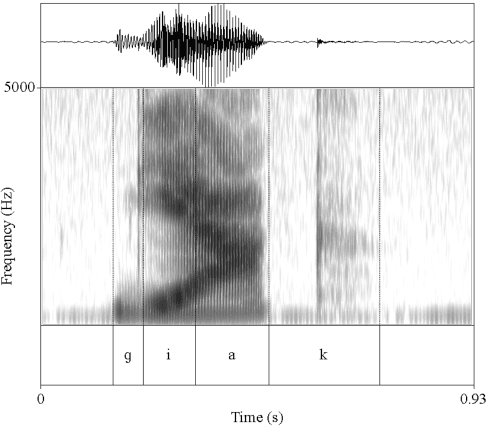
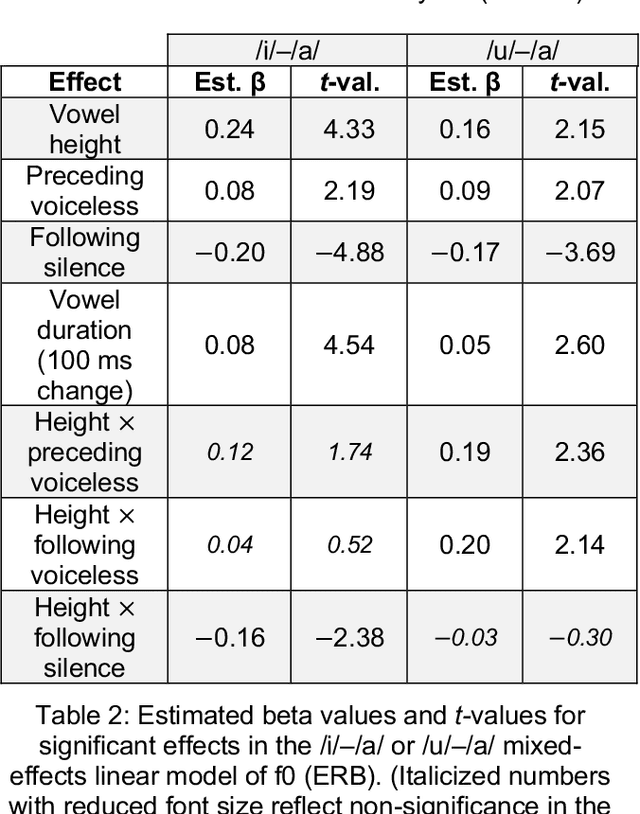
Research in speech technologies and comparative linguistics depends on access to diverse and accessible speech data. The UCLA Phonetics Lab Archive is one of the earliest multilingual speech corpora, with long-form audio recordings and phonetic transcriptions for 314 languages (Ladefoged et al., 2009). Recently, 95 of these languages were time-aligned with word-level phonetic transcriptions (Li et al., 2021). Here we present VoxAngeles, a corpus of audited phonetic transcriptions and phone-level alignments of the UCLA Phonetics Lab Archive, which uses the 95-language CMU re-release as our starting point. VoxAngeles also includes word- and phone-level segmentations from the original UCLA corpus, as well as phonetic measurements of word and phone durations, vowel formants, and vowel f0. This corpus enhances the usability of the original data, particularly for quantitative phonetic typology, as demonstrated through a case study of vowel intrinsic f0. We also discuss the utility of the VoxAngeles corpus for general research and pedagogy in crosslinguistic phonetics, as well as for low-resource and multilingual speech technologies. VoxAngeles is free to download and use under a CC-BY-NC 4.0 license.
DreamSalon: A Staged Diffusion Framework for Preserving Identity-Context in Editable Face Generation
Mar 28, 2024While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centered images, novel challenges arise with a nuanced task of "identity fine editing": precisely modifying specific features of a subject while maintaining its inherent identity and context. Existing personalization methods either require time-consuming optimization or learning additional encoders, adept in "identity re-contextualization". However, they often struggle with detailed and sensitive tasks like human face editing. To address these challenges, we introduce DreamSalon, a noise-guided, staged-editing framework, uniquely focusing on detailed image manipulations and identity-context preservation. By discerning editing and boosting stages via the frequency and gradient of predicted noises, DreamSalon first performs detailed manipulations on specific features in the editing stage, guided by high-frequency information, and then employs stochastic denoising in the boosting stage to improve image quality. For more precise editing, DreamSalon semantically mixes source and target textual prompts, guided by differences in their embedding covariances, to direct the model's focus on specific manipulation areas. Our experiments demonstrate DreamSalon's ability to efficiently and faithfully edit fine details on human faces, outperforming existing methods both qualitatively and quantitatively.
Taming Lookup Tables for Efficient Image Retouching
Mar 28, 2024The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.
Efficient and Effective Weakly-Supervised Action Segmentation via Action-Transition-Aware Boundary Alignment
Mar 28, 2024Weakly-supervised action segmentation is a task of learning to partition a long video into several action segments, where training videos are only accompanied by transcripts (ordered list of actions). Most of existing methods need to infer pseudo segmentation for training by serial alignment between all frames and the transcript, which is time-consuming and hard to be parallelized while training. In this work, we aim to escape from this inefficient alignment with massive but redundant frames, and instead to directly localize a few action transitions for pseudo segmentation generation, where a transition refers to the change from an action segment to its next adjacent one in the transcript. As the true transitions are submerged in noisy boundaries due to intra-segment visual variation, we propose a novel Action-Transition-Aware Boundary Alignment (ATBA) framework to efficiently and effectively filter out noisy boundaries and detect transitions. In addition, to boost the semantic learning in the case that noise is inevitably present in the pseudo segmentation, we also introduce video-level losses to utilize the trusted video-level supervision. Extensive experiments show the effectiveness of our approach on both performance and training speed.
Blind Identification of Binaural Room Impulse Responses from Smart Glasses
Mar 28, 2024Smart glasses are increasingly recognized as a key medium for augmented reality, offering a hands-free platform with integrated microphones and non-ear-occluding loudspeakers to seamlessly mix virtual sound sources into the real-world acoustic scene. To convincingly integrate virtual sound sources, the room acoustic rendering of the virtual sources must match the real-world acoustics. Information about a user's acoustic environment however is typically not available. This work uses a microphone array in a pair of smart glasses to blindly identify binaural room impulse responses (BRIRs) from a few seconds of speech in the real-world environment. The proposed method uses dereverberation and beamforming to generate a pseudo reference signal that is used by a multichannel Wiener filter to estimate room impulse responses which are then converted to BRIRs. The multichannel room impulse responses can be used to estimate room acoustic parameters which is shown to outperform baseline algorithms in the estimation of reverberation time and direct-to-reverberant energy ratio. Results from a listening experiment further indicate that the estimated BRIRs often reproduce the real-world room acoustics perceptually more convincingly than measured BRIRs from other rooms with similar geometry.
Disentangling Length from Quality in Direct Preference Optimization
Mar 28, 2024Reinforcement Learning from Human Feedback (RLHF) has been a crucial component in the recent success of Large Language Models. However, RLHF is know to exploit biases in human preferences, such as verbosity. A well-formatted and eloquent answer is often more highly rated by users, even when it is less helpful and objective. A number of approaches have been developed to control those biases in the classical RLHF literature, but the problem remains relatively under-explored for Direct Alignment Algorithms such as Direct Preference Optimization (DPO). Unlike classical RLHF, DPO does not train a separate reward model or use reinforcement learning directly, so previous approaches developed to control verbosity cannot be directly applied to this setting. Our work makes several contributions. For the first time, we study the length problem in the DPO setting, showing significant exploitation in DPO and linking it to out-of-distribution bootstrapping. We then develop a principled but simple regularization strategy that prevents length exploitation, while still maintaining improvements in model quality. We demonstrate these effects across datasets on summarization and dialogue, where we achieve up to 20\% improvement in win rates when controlling for length, despite the GPT4 judge's well-known verbosity bias.
FastPerson: Enhancing Video Learning through Effective Video Summarization that Preserves Linguistic and Visual Contexts
Mar 26, 2024Quickly understanding lengthy lecture videos is essential for learners with limited time and interest in various topics to improve their learning efficiency. To this end, video summarization has been actively researched to enable users to view only important scenes from a video. However, these studies focus on either the visual or audio information of a video and extract important segments in the video. Therefore, there is a risk of missing important information when both the teacher's speech and visual information on the blackboard or slides are important, such as in a lecture video. To tackle this issue, we propose FastPerson, a video summarization approach that considers both the visual and auditory information in lecture videos. FastPerson creates summary videos by utilizing audio transcriptions along with on-screen images and text, minimizing the risk of overlooking crucial information for learners. Further, it provides a feature that allows learners to switch between the summary and original videos for each chapter of the video, enabling them to adjust the pace of learning based on their interests and level of understanding. We conducted an evaluation with 40 participants to assess the effectiveness of our method and confirmed that it reduced viewing time by 53\% at the same level of comprehension as that when using traditional video playback methods.
Project MOSLA: Recording Every Moment of Second Language Acquisition
Mar 26, 2024Second language acquisition (SLA) is a complex and dynamic process. Many SLA studies that have attempted to record and analyze this process have typically focused on a single modality (e.g., textual output of learners), covered only a short period of time, and/or lacked control (e.g., failed to capture every aspect of the learning process). In Project MOSLA (Moments of Second Language Acquisition), we have created a longitudinal, multimodal, multilingual, and controlled dataset by inviting participants to learn one of three target languages (Arabic, Spanish, and Chinese) from scratch over a span of two years, exclusively through online instruction, and recording every lesson using Zoom. The dataset is semi-automatically annotated with speaker/language IDs and transcripts by both human annotators and fine-tuned state-of-the-art speech models. Our experiments reveal linguistic insights into learners' proficiency development over time, as well as the potential for automatically detecting the areas of focus on the screen purely from the unannotated multimodal data. Our dataset is freely available for research purposes and can serve as a valuable resource for a wide range of applications, including but not limited to SLA, proficiency assessment, language and speech processing, pedagogy, and multimodal learning analytics.
Efficient Video Object Segmentation via Modulated Cross-Attention Memory
Mar 26, 2024Recently, transformer-based approaches have shown promising results for semi-supervised video object segmentation. However, these approaches typically struggle on long videos due to increased GPU memory demands, as they frequently expand the memory bank every few frames. We propose a transformer-based approach, named MAVOS, that introduces an optimized and dynamic long-term modulated cross-attention (MCA) memory to model temporal smoothness without requiring frequent memory expansion. The proposed MCA effectively encodes both local and global features at various levels of granularity while efficiently maintaining consistent speed regardless of the video length. Extensive experiments on multiple benchmarks, LVOS, Long-Time Video, and DAVIS 2017, demonstrate the effectiveness of our proposed contributions leading to real-time inference and markedly reduced memory demands without any degradation in segmentation accuracy on long videos. Compared to the best existing transformer-based approach, our MAVOS increases the speed by 7.6x, while significantly reducing the GPU memory by 87% with comparable segmentation performance on short and long video datasets. Notably on the LVOS dataset, our MAVOS achieves a J&F score of 63.3% while operating at 37 frames per second (FPS) on a single V100 GPU. Our code and models will be publicly available at: https://github.com/Amshaker/MAVOS.
Supervised Time Series Classification for Anomaly Detection in Subsea Engineering
Mar 12, 2024
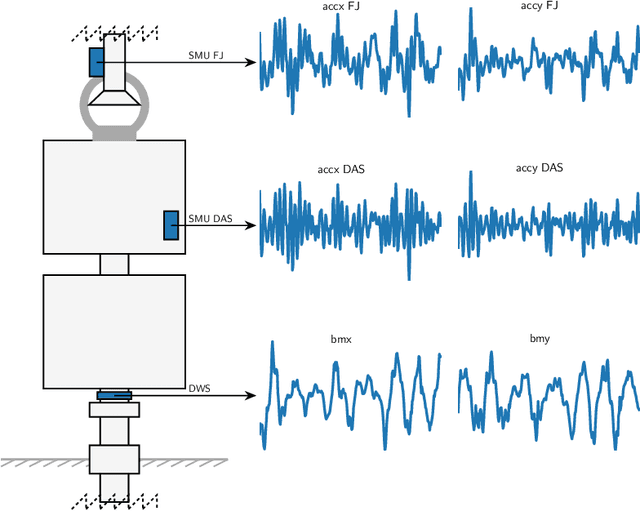
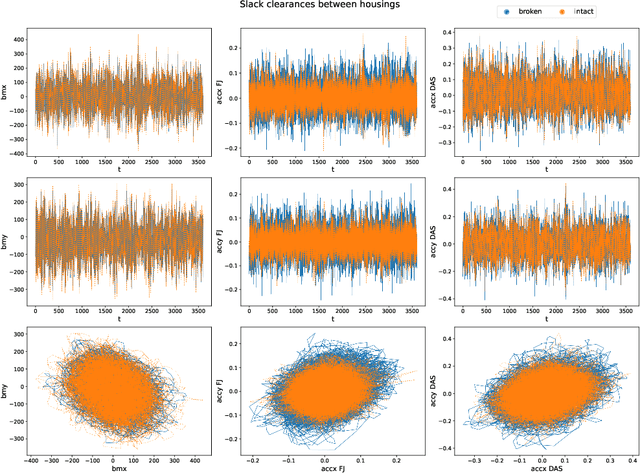
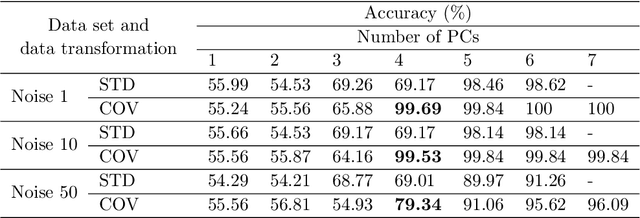
Time series classification is of significant importance in monitoring structural systems. In this work, we investigate the use of supervised machine learning classification algorithms on simulated data based on a physical system with two states: Intact and Broken. We provide a comprehensive discussion of the preprocessing of temporal data, using measures of statistical dispersion and dimension reduction techniques. We present an intuitive baseline method and discuss its efficiency. We conclude with a comparison of the various methods based on different performance metrics, showing the advantage of using machine learning techniques as a tool in decision making.