 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal DINO: A Self-supervised Video Strategy to Enhance Action Prediction
Aug 08, 2023
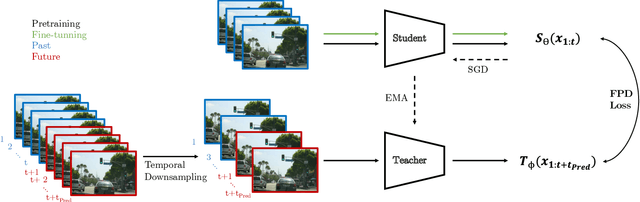
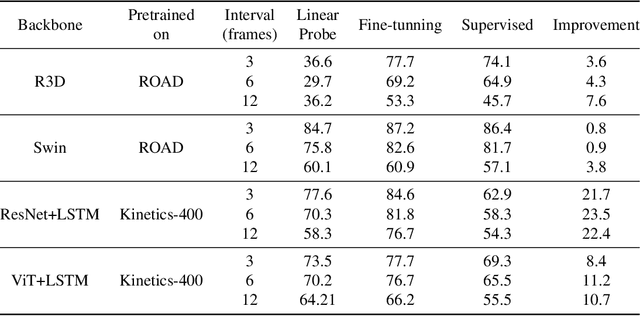

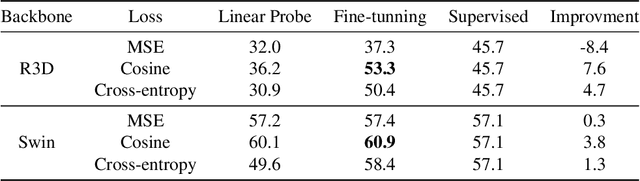
The emerging field of action prediction plays a vital role in various computer vision applications such as autonomous driving, activity analysis and human-computer interaction. Despite significant advancements, accurately predicting future actions remains a challenging problem due to high dimensionality, complex dynamics and uncertainties inherent in video data. Traditional supervised approaches require large amounts of labelled data, which is expensive and time-consuming to obtain. This paper introduces a novel self-supervised video strategy for enhancing action prediction inspired by DINO (self-distillation with no labels). The Temporal-DINO approach employs two models; a 'student' processing past frames; and a 'teacher' processing both past and future frames, enabling a broader temporal context. During training, the teacher guides the student to learn future context by only observing past frames. The strategy is evaluated on ROAD dataset for the action prediction downstream task using 3D-ResNet, Transformer, and LSTM architectures. The experimental results showcase significant improvements in prediction performance across these architectures, with our method achieving an average enhancement of 9.9% Precision Points (PP), highlighting its effectiveness in enhancing the backbones' capabilities of capturing long-term dependencies. Furthermore, our approach demonstrates efficiency regarding the pretraining dataset size and the number of epochs required. This method overcomes limitations present in other approaches, including considering various backbone architectures, addressing multiple prediction horizons, reducing reliance on hand-crafted augmentations, and streamlining the pretraining process into a single stage. These findings highlight the potential of our approach in diverse video-based tasks such as activity recognition, motion planning, and scene understanding.
Guidance & Control Networks for Time-Optimal Quadcopter Flight
May 04, 2023

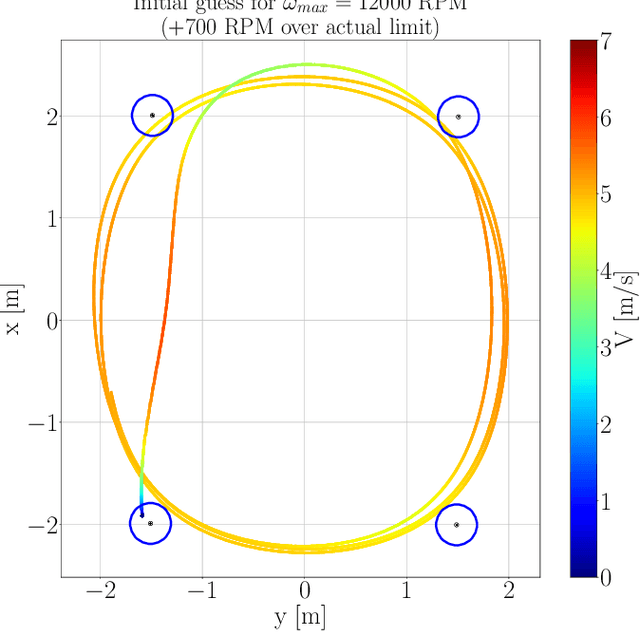
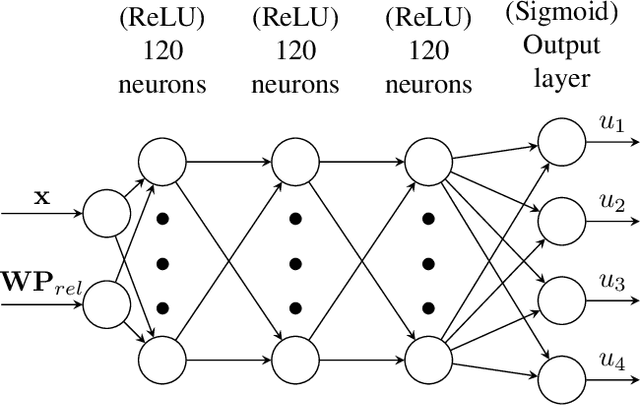
Reaching fast and autonomous flight requires computationally efficient and robust algorithms. To this end, we train Guidance & Control Networks to approximate optimal control policies ranging from energy-optimal to time-optimal flight. We show that the policies become more difficult to learn the closer we get to the time-optimal 'bang-bang' control profile. We also assess the importance of knowing the maximum angular rotor velocity of the quadcopter and show that over- or underestimating this limit leads to less robust flight. We propose an algorithm to identify the current maximum angular rotor velocity onboard and a network that adapts its policy based on the identified limit. Finally, we extend previous work on Guidance & Control Networks by learning to take consecutive waypoints into account. We fly a 4x3m track in similar lap times as the differential-flatness-based minimum snap benchmark controller while benefiting from the flexibility that Guidance & Control Networks offer.
Persistent Ballistic Entanglement Spreading with Optimal Control in Quantum Spin Chains
Jul 21, 2023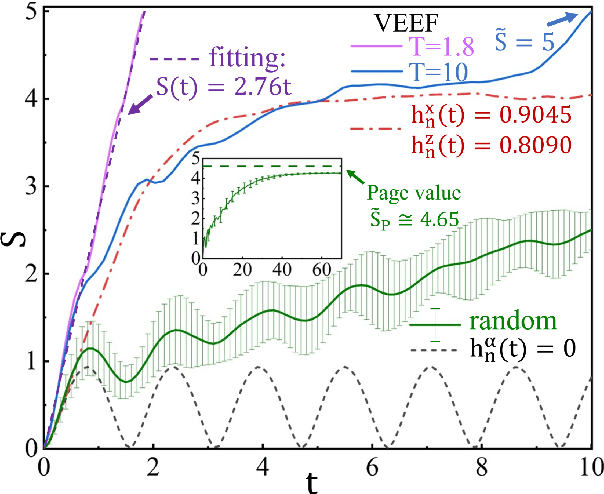
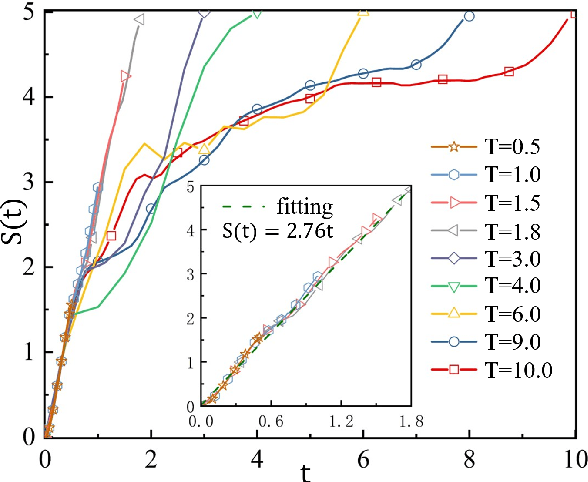
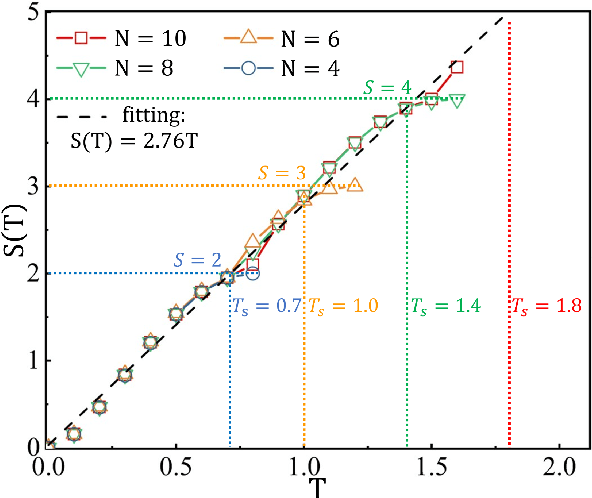
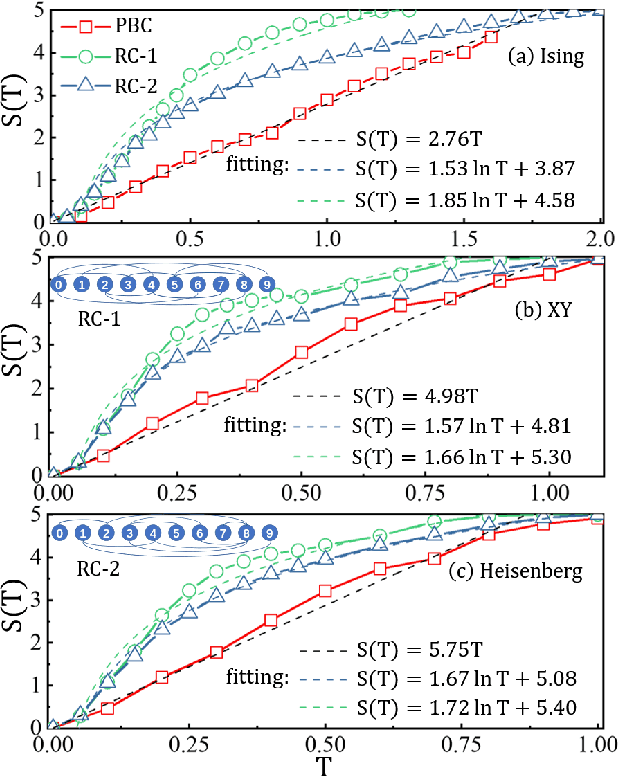
Entanglement propagation provides a key routine to understand quantum many-body dynamics in and out of equilibrium. In this work, we uncover that the ``variational entanglement-enhancing'' field (VEEF) robustly induces a persistent ballistic spreading of entanglement in quantum spin chains. The VEEF is time dependent, and is optimally controlled to maximize the bipartite entanglement entropy (EE) of the final state. Such a linear growth persists till the EE reaches the genuine saturation $\tilde{S} = - \log_{2} 2^{-\frac{N}{2}}=\frac{N}{2}$ with $N$ the total number of spins. The EE satisfies $S(t) = v t$ for the time $t \leq \frac{N}{2v}$, with $v$ the velocity. These results are in sharp contrast with the behaviors without VEEF, where the EE generally approaches a sub-saturation known as the Page value $\tilde{S}_{P} =\tilde{S} - \frac{1}{2\ln{2}}$ in the long-time limit, and the entanglement growth deviates from being linear before the Page value is reached. The dependence between the velocity and interactions is explored, with $v \simeq 2.76$, $4.98$, and $5.75$ for the spin chains with Ising, XY, and Heisenberg interactions, respectively. We further show that the nonlinear growth of EE emerges with the presence of long-range interactions.
DataAssist: A Machine Learning Approach to Data Cleaning and Preparation
Jul 17, 2023Current automated machine learning (ML) tools are model-centric, focusing on model selection and parameter optimization. However, the majority of the time in data analysis is devoted to data cleaning and wrangling, for which limited tools are available. Here we present DataAssist, an automated data preparation and cleaning platform that enhances dataset quality using ML-informed methods. We show that DataAssist provides a pipeline for exploratory data analysis and data cleaning, including generating visualization for user-selected variables, unifying data annotation, suggesting anomaly removal, and preprocessing data. The exported dataset can be readily integrated with other autoML tools or user-specified model for downstream analysis. Our data-centric tool is applicable to a variety of fields, including economics, business, and forecasting applications saving over 50% time of the time spent on data cleansing and preparation.
MIM-OOD: Generative Masked Image Modelling for Out-of-Distribution Detection in Medical Images
Aug 02, 2023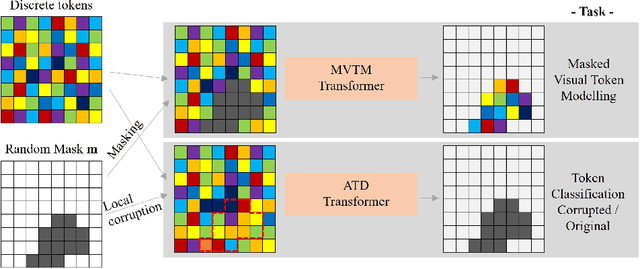

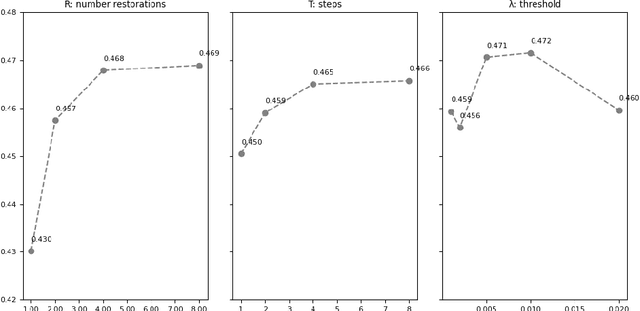
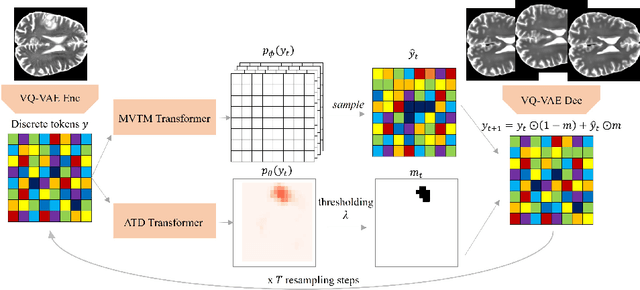
Unsupervised Out-of-Distribution (OOD) detection consists in identifying anomalous regions in images leveraging only models trained on images of healthy anatomy. An established approach is to tokenize images and model the distribution of tokens with Auto-Regressive (AR) models. AR models are used to 1) identify anomalous tokens and 2) in-paint anomalous representations with in-distribution tokens. However, AR models are slow at inference time and prone to error accumulation issues which negatively affect OOD detection performance. Our novel method, MIM-OOD, overcomes both speed and error accumulation issues by replacing the AR model with two task-specific networks: 1) a transformer optimized to identify anomalous tokens and 2) a transformer optimized to in-paint anomalous tokens using masked image modelling (MIM). Our experiments with brain MRI anomalies show that MIM-OOD substantially outperforms AR models (DICE 0.458 vs 0.301) while achieving a nearly 25x speedup (9.5s vs 244s).
Towards Practicable Sequential Shift Detectors
Jul 27, 2023There is a growing awareness of the harmful effects of distribution shift on the performance of deployed machine learning models. Consequently, there is a growing interest in detecting these shifts before associated costs have time to accumulate. However, desiderata of crucial importance to the practicable deployment of sequential shift detectors are typically overlooked by existing works, precluding their widespread adoption. We identify three such desiderata, highlight existing works relevant to their satisfaction, and recommend impactful directions for future research.
FLIQS: One-Shot Mixed-Precision Floating-Point and Integer Quantization Search
Aug 07, 2023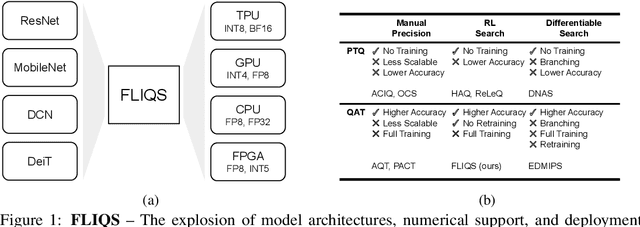
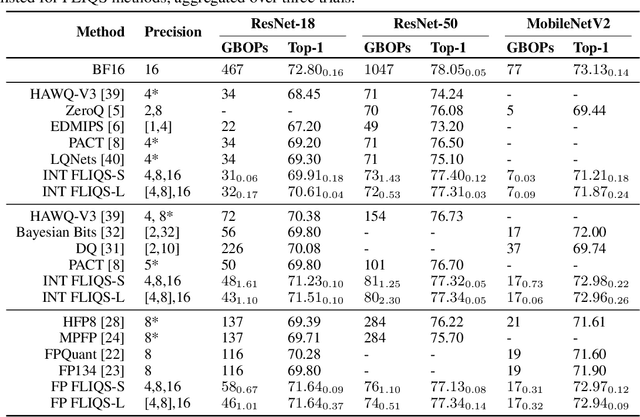
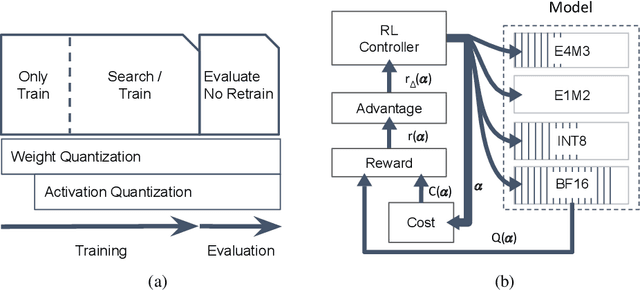
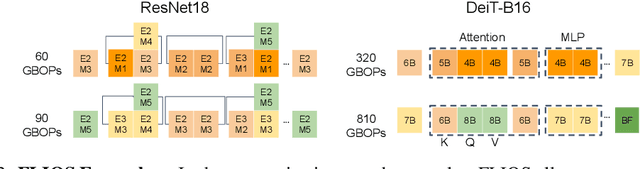
Quantization has become a mainstream compression technique for reducing model size, computational requirements, and energy consumption for modern deep neural networks (DNNs). With the improved numerical support in recent hardware, including multiple variants of integer and floating point, mixed-precision quantization has become necessary to achieve high-quality results with low model cost. Prior mixed-precision quantization methods have performed a post-training quantization search, which compromises on accuracy, or a differentiable quantization search, which leads to high memory usage from branching. Therefore, we propose the first one-shot mixed-precision quantization search that eliminates the need for retraining in both integer and low-precision floating point models. We evaluate our floating-point and integer quantization search (FLIQS) on multiple convolutional networks and vision transformer models to discover Pareto-optimal models. Our approach discovers models that improve upon uniform precision, manual mixed-precision, and recent integer quantization search methods. With the proposed integer quantization search, we increase the accuracy of ResNet-18 on ImageNet by 1.31% points and ResNet-50 by 0.90% points with equivalent model cost over previous methods. Additionally, for the first time, we explore a novel mixed-precision floating-point search and improve MobileNetV2 by up to 0.98% points compared to prior state-of-the-art FP8 models. Finally, we extend FLIQS to simultaneously search a joint quantization and neural architecture space and improve the ImageNet accuracy by 2.69% points with similar model cost on a MobileNetV2 search space.
Prototype Learning for Out-of-Distribution Polyp Segmentation
Aug 07, 2023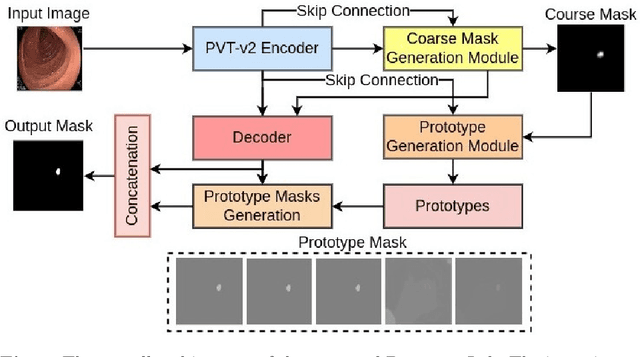
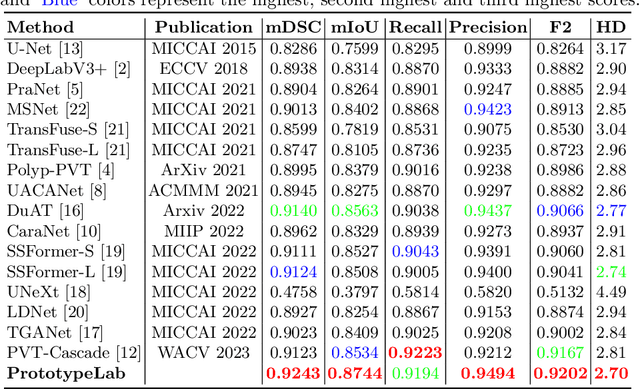
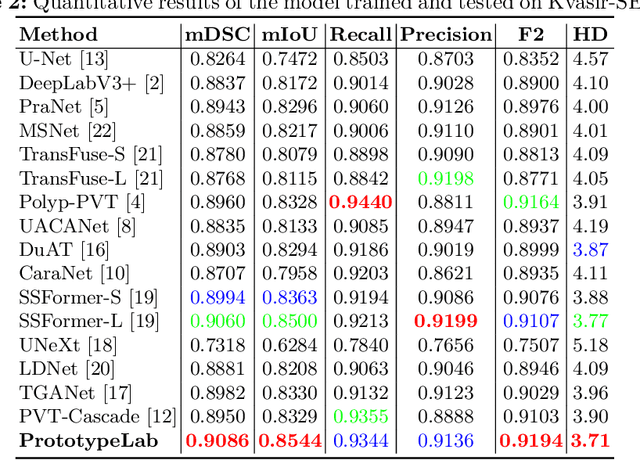
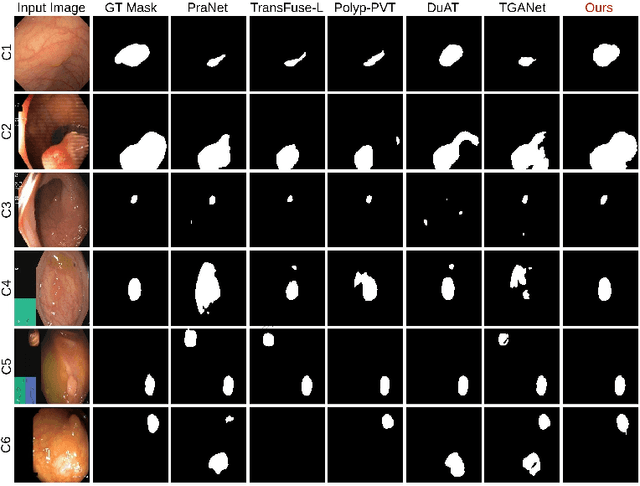
Existing polyp segmentation models from colonoscopy images often fail to provide reliable segmentation results on datasets from different centers, limiting their applicability. Our objective in this study is to create a robust and well-generalized segmentation model named PrototypeLab that can assist in polyp segmentation. To achieve this, we incorporate various lighting modes such as White light imaging (WLI), Blue light imaging (BLI), Linked color imaging (LCI), and Flexible spectral imaging color enhancement (FICE) into our new segmentation model, that learns to create prototypes for each class of object present in the images. These prototypes represent the characteristic features of the objects, such as their shape, texture, color. Our model is designed to perform effectively on out-of-distribution (OOD) datasets from multiple centers. We first generate a coarse mask that is used to learn prototypes for the main object class, which are then employed to generate the final segmentation mask. By using prototypes to represent the main class, our approach handles the variability present in the medical images and generalize well to new data since prototype capture the underlying distribution of the data. PrototypeLab offers a promising solution with a dice coefficient of $\geq$ 90\% and mIoU $\geq$ 85\% with a near real-time processing speed for polyp segmentation. It achieved superior performance on OOD datasets compared to 16 state-of-the-art image segmentation architectures, potentially improving clinical outcomes. Codes are available at https://github.com/xxxxx/PrototypeLab.
From Ambiguity to Explicitness: NLP-Assisted 5G Specification Abstraction for Formal Analysis
Aug 07, 2023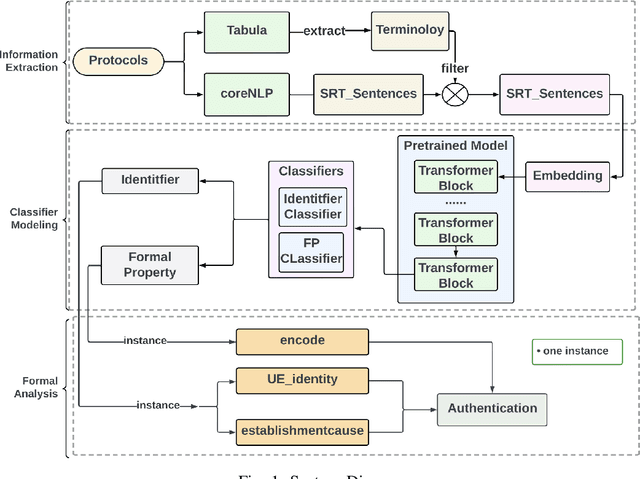
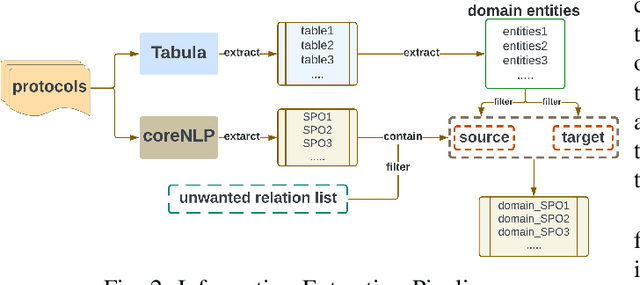
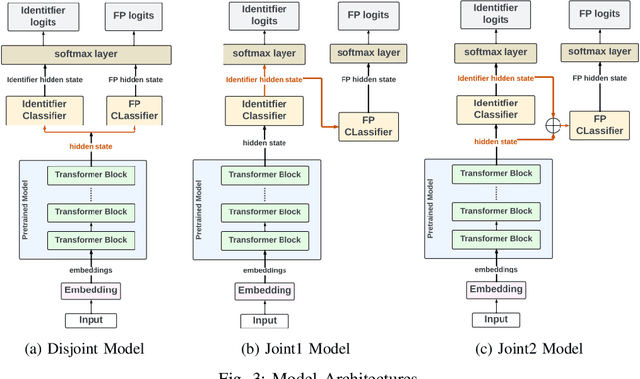
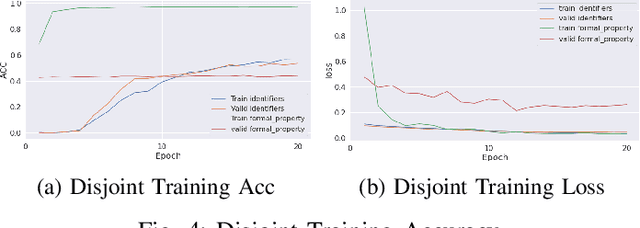
Formal method-based analysis of the 5G Wireless Communication Protocol is crucial for identifying logical vulnerabilities and facilitating an all-encompassing security assessment, especially in the design phase. Natural Language Processing (NLP) assisted techniques and most of the tools are not widely adopted by the industry and research community. Traditional formal verification through a mathematics approach heavily relied on manual logical abstraction prone to being time-consuming, and error-prone. The reason that the NLP-assisted method did not apply in industrial research may be due to the ambiguity in the natural language of the protocol designs nature is controversial to the explicitness of formal verification. To address the challenge of adopting the formal methods in protocol designs, targeting (3GPP) protocols that are written in natural language, in this study, we propose a hybrid approach to streamline the analysis of protocols. We introduce a two-step pipeline that first uses NLP tools to construct data and then uses constructed data to extract identifiers and formal properties by using the NLP model. The identifiers and formal properties are further used for formal analysis. We implemented three models that take different dependencies between identifiers and formal properties as criteria. Our results of the optimal model reach valid accuracy of 39% for identifier extraction and 42% for formal properties predictions. Our work is proof of concept for an efficient procedure in performing formal analysis for largescale complicate specification and protocol analysis, especially for 5G and nextG communications.
GraPhSyM: Graph Physical Synthesis Model
Aug 07, 2023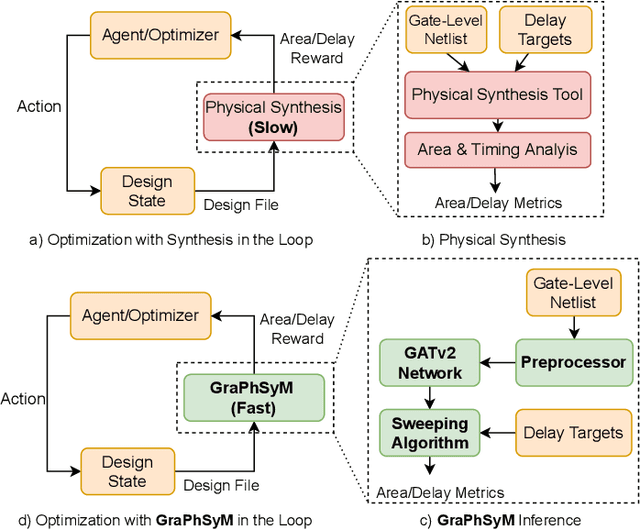

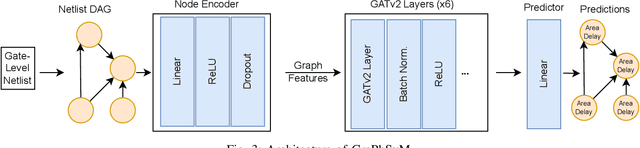
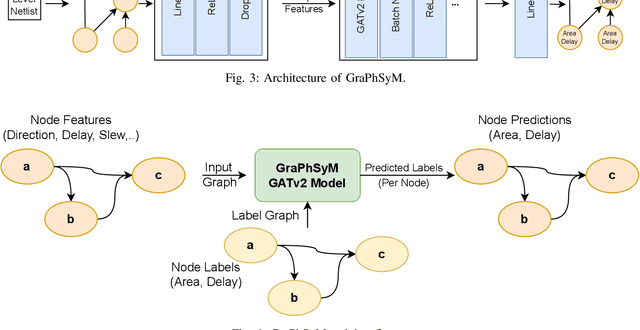
In this work, we introduce GraPhSyM, a Graph Attention Network (GATv2) model for fast and accurate estimation of post-physical synthesis circuit delay and area metrics from pre-physical synthesis circuit netlists. Once trained, GraPhSyM provides accurate visibility of final design metrics to early EDA stages, such as logic synthesis, without running the slow physical synthesis flow, enabling global co-optimization across stages. Additionally, the swift and precise feedback provided by GraPhSym is instrumental for machine-learning-based EDA optimization frameworks. Given a gate-level netlist of a circuit represented as a graph, GraPhSyM utilizes graph structure, connectivity, and electrical property features to predict the impact of physical synthesis transformations such as buffer insertion and gate sizing. When trained on a dataset of 6000 prefix adder designs synthesized at an aggressive delay target, GraPhSyM can accurately predict the post-synthesis delay (98.3%) and area (96.1%) metrics of unseen adders with a fast 0.22s inference time. Furthermore, we illustrate the compositionality of GraPhSyM by employing the model trained on a fixed delay target to accurately anticipate post-synthesis metrics at a variety of unseen delay targets. Lastly, we report promising generalization capabilities of the GraPhSyM model when it is evaluated on circuits different from the adders it was exclusively trained on. The results show the potential for GraPhSyM to serve as a powerful tool for advanced optimization techniques and as an oracle for EDA machine learning frameworks.