 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A State-Space Perspective on Modelling and Inference for Online Skill Rating
Aug 04, 2023
This paper offers a comprehensive review of the main methodologies used for skill rating in competitive sports. We advocate for a state-space model perspective, wherein players' skills are represented as time-varying, and match results serve as the sole observed quantities. The state-space model perspective facilitates the decoupling of modeling and inference, enabling a more focused approach highlighting model assumptions, while also fostering the development of general-purpose inference tools. We explore the essential steps involved in constructing a state-space model for skill rating before turning to a discussion on the three stages of inference: filtering, smoothing and parameter estimation. Throughout, we examine the computational challenges of scaling up to high-dimensional scenarios involving numerous players and matches, highlighting approximations and reductions used to address these challenges effectively. We provide concise summaries of popular methods documented in the literature, along with their inferential paradigms and introduce new approaches to skill rating inference based on sequential Monte Carlo and finite state-spaces. We close with numerical experiments demonstrating a practical workflow on real data across different sports.
Semantics-guided Transformer-based Sensor Fusion for Improved Waypoint Prediction
Aug 04, 2023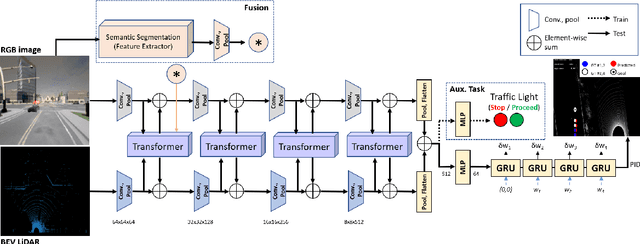


Sensor fusion approaches for intelligent self-driving agents remain key to driving scene understanding given visual global contexts acquired from input sensors. Specifically, for the local waypoint prediction task, single-modality networks are still limited by strong dependency on the sensitivity of the input sensor, and thus recent works promote the use of multiple sensors in fusion in feature level. While it is well known that multiple data modalities promote mutual contextual exchange, deployment to practical driving scenarios requires global 3D scene understanding in real-time with minimal computations, thus placing greater significance on training strategies given a limited number of practically usable sensors. In this light, we exploit carefully selected auxiliary tasks that are highly correlated with the target task of interest (e.g., traffic light recognition and semantic segmentation) by fusing auxiliary task features and also using auxiliary heads for waypoint prediction based on imitation learning. Our multi-task feature fusion augments and improves the base network, TransFuser, by significant margins for safer and more complete road navigation in CARLA simulator as validated on the Town05 Benchmark through extensive experiments.
Learning Referring Video Object Segmentation from Weak Annotation
Aug 04, 2023
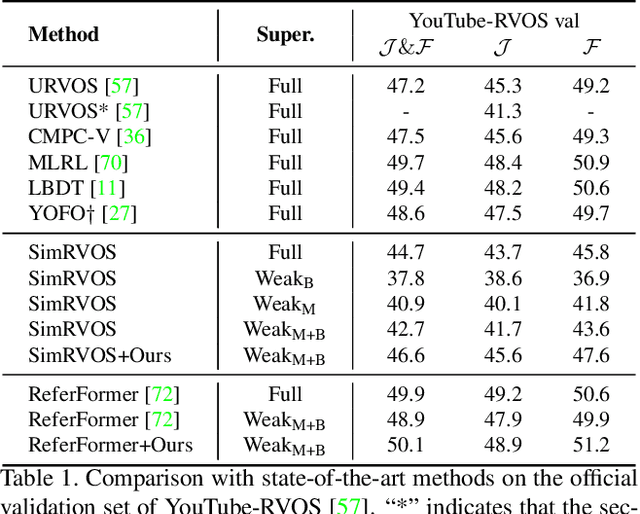
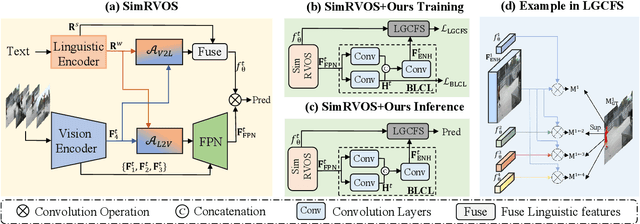

Referring video object segmentation (RVOS) is a task that aims to segment the target object in all video frames based on a sentence describing the object. Previous RVOS methods have achieved significant performance with densely-annotated datasets, whose construction is expensive and time-consuming. To relieve the burden of data annotation while maintaining sufficient supervision for segmentation, we propose a new annotation scheme, in which we label the frame where the object first appears with a mask and use bounding boxes for the subsequent frames. Based on this scheme, we propose a method to learn from this weak annotation. Specifically, we design a cross frame segmentation method, which uses the language-guided dynamic filters to thoroughly leverage the valuable mask annotation and bounding boxes. We further develop a bi-level contrastive learning method to encourage the model to learn discriminative representation at the pixel level. Extensive experiments and ablative analyses show that our method is able to achieve competitive performance without the demand of dense mask annotation. The code will be available at https://github.com/wangbo-zhao/WRVOS/.
Optimally Computing Compressed Indexing Arrays Based on the Compact Directed Acyclic Word Graph
Aug 04, 2023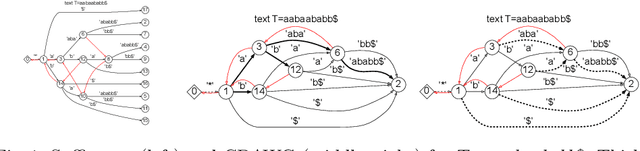

In this paper, we present the first study of the computational complexity of converting an automata-based text index structure, called the Compact Directed Acyclic Word Graph (CDAWG), of size $e$ for a text $T$ of length $n$ into other text indexing structures for the same text, suitable for highly repetitive texts: the run-length BWT of size $r$, the irreducible PLCP array of size $r$, and the quasi-irreducible LPF array of size $e$, as well as the lex-parse of size $O(r)$ and the LZ77-parse of size $z$, where $r, z \le e$. As main results, we showed that the above structures can be optimally computed from either the CDAWG for $T$ stored in read-only memory or its self-index version of size $e$ without a text in $O(e)$ worst-case time and words of working space. To obtain the above results, we devised techniques for enumerating a particular subset of suffixes in the lexicographic and text orders using the forward and backward search on the CDAWG by extending the results by Belazzougui et al. in 2015.
Robust cell-free mmWave/sub-THz access using minimal coordination and coarse synchronization
Aug 04, 2023This study investigates simpler alternatives to coherent joint transmission for supporting robust connectivity against signal blockage in mmWave/sub-THz access networks. By taking an information-theoretic viewpoint, we demonstrate analytically that with a careful design, full macrodiversity gains and significant SNR gains can be achieved through canonical receivers and minimal coordination and synchronization requirements at the infrastructure side. Our proposed scheme extends non-coherent joint transmission by employing a special form of diversity to counteract artificially induced deep fades that would otherwise make this technique often compare unfavorably against standard transmitter selection schemes. Additionally, the inclusion of an Alamouti-like space-time coding layer is shown to recover a significant fraction of the optimal performance. Our conclusions are based on an insightful multi-point intermittent block fading channel model that enables rigorous ergodic and outage rate analysis, while also considering timing offsets due to imperfect delay compensation. Although simplified, our approach captures the essential features of modern mmWave/sub-THz communications, thereby providing practical design guidelines for realistic systems.
Application of Random Forest and Support Vector Machine for Investigation of Pressure Filtration Performance, a Zinc Plant Filter Cake Modeling
Jul 26, 2023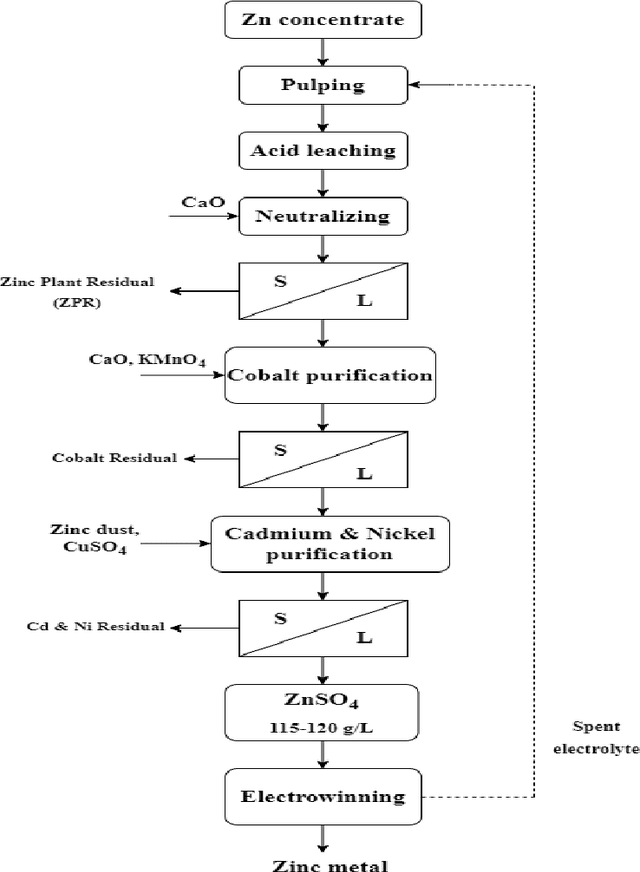
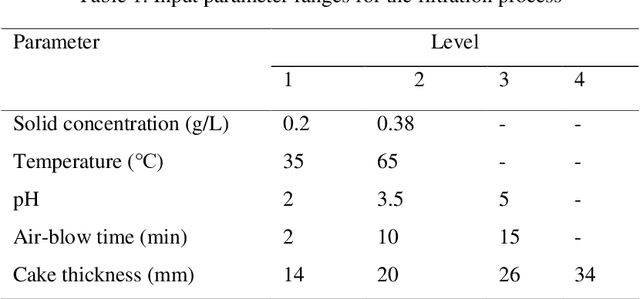
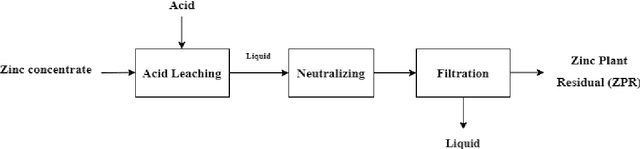
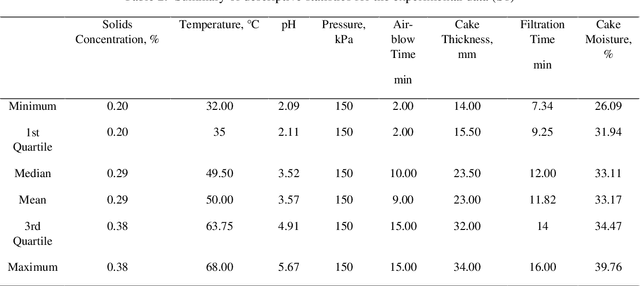
The hydrometallurgical method of zinc production involves leaching zinc from ore and then separating the solid residue from the liquid solution by pressure filtration. This separation process is very important since the solid residue contains some moisture that can reduce the amount of zinc recovered. This study modeled the pressure filtration process through Random Forest (RF) and Support Vector Machine (SVM). The models take continuous variables (extracted features) from the lab samples as inputs. Thus, regression models namely Random Forest Regression (RFR) and Support Vector Regression (SVR) were chosen. A total dataset was obtained during the pressure filtration process in two conditions: 1) Polypropylene (S1) and 2) Polyester fabrics (S2). To predict the cake moisture, solids concentration (0.2 and 0.38), temperature (35 and 65 centigrade), pH (2, 3.5, and 5), pressure, cake thickness (14, 20, 26, and 34 mm), air-blow time (2, 10 and 15 min) and filtration time were applied as input variables. The models' predictive accuracy was evaluated by the coefficient of determination (R2) parameter. The results revealed that the RFR model is superior to the SVR model for cake moisture prediction.
NeuroHeed: Neuro-Steered Speaker Extraction using EEG Signals
Jul 26, 2023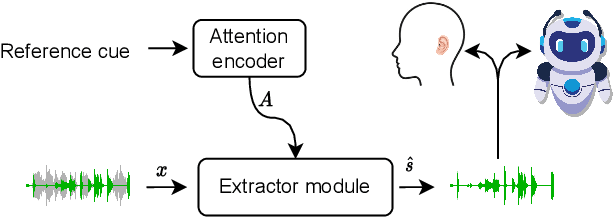
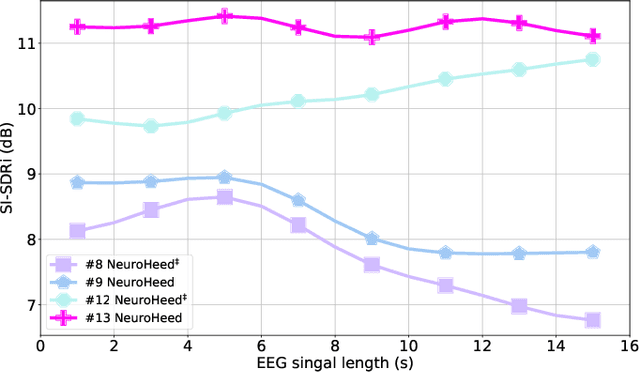
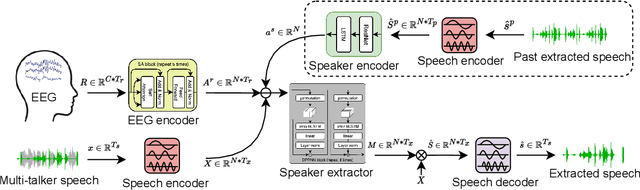
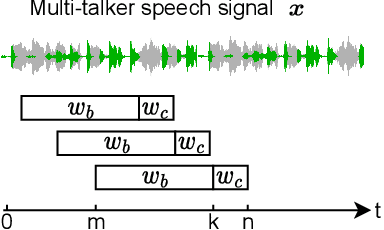
Humans possess the remarkable ability to selectively attend to a single speaker amidst competing voices and background noise, known as selective auditory attention. Recent studies in auditory neuroscience indicate a strong correlation between the attended speech signal and the corresponding brain's elicited neuronal activities, which the latter can be measured using affordable and non-intrusive electroencephalography (EEG) devices. In this study, we present NeuroHeed, a speaker extraction model that leverages EEG signals to establish a neuronal attractor which is temporally associated with the speech stimulus, facilitating the extraction of the attended speech signal in a cocktail party scenario. We propose both an offline and an online NeuroHeed, with the latter designed for real-time inference. In the online NeuroHeed, we additionally propose an autoregressive speaker encoder, which accumulates past extracted speech signals for self-enrollment of the attended speaker information into an auditory attractor, that retains the attentional momentum over time. Online NeuroHeed extracts the current window of the speech signals with guidance from both attractors. Experimental results demonstrate that NeuroHeed effectively extracts brain-attended speech signals, achieving high signal quality, excellent perceptual quality, and intelligibility in a two-speaker scenario.
EfficientSCI: Densely Connected Network with Space-time Factorization for Large-scale Video Snapshot Compressive Imaging
May 18, 2023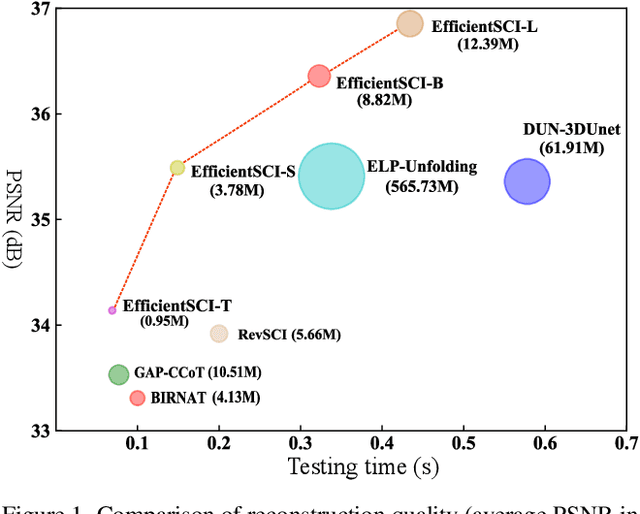

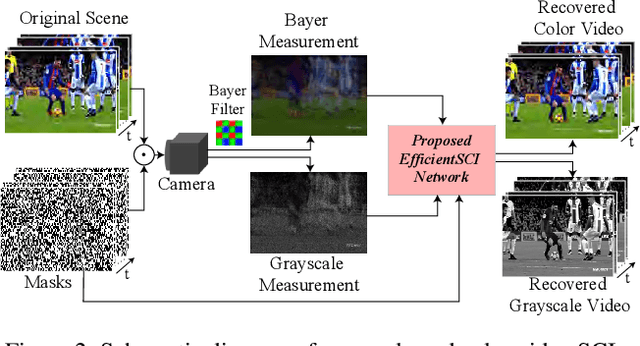
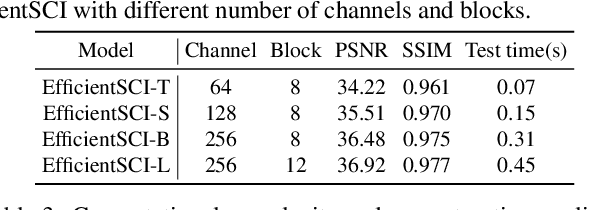
Video snapshot compressive imaging (SCI) uses a two-dimensional detector to capture consecutive video frames during a single exposure time. Following this, an efficient reconstruction algorithm needs to be designed to reconstruct the desired video frames. Although recent deep learning-based state-of-the-art (SOTA) reconstruction algorithms have achieved good results in most tasks, they still face the following challenges due to excessive model complexity and GPU memory limitations: 1) these models need high computational cost, and 2) they are usually unable to reconstruct large-scale video frames at high compression ratios. To address these issues, we develop an efficient network for video SCI by using dense connections and space-time factorization mechanism within a single residual block, dubbed EfficientSCI. The EfficientSCI network can well establish spatial-temporal correlation by using convolution in the spatial domain and Transformer in the temporal domain, respectively. We are the first time to show that an UHD color video with high compression ratio can be reconstructed from a snapshot 2D measurement using a single end-to-end deep learning model with PSNR above 32 dB. Extensive results on both simulation and real data show that our method significantly outperforms all previous SOTA algorithms with better real-time performance. The code is at https://github.com/ucaswangls/EfficientSCI.git.
Dynamic Model Agnostic Reliability Evaluation of Machine-Learning Methods Integrated in Instrumentation & Control Systems
Aug 08, 2023



In recent years, the field of data-driven neural network-based machine learning (ML) algorithms has grown significantly and spurred research in its applicability to instrumentation and control systems. While they are promising in operational contexts, the trustworthiness of such algorithms is not adequately assessed. Failures of ML-integrated systems are poorly understood; the lack of comprehensive risk modeling can degrade the trustworthiness of these systems. In recent reports by the National Institute for Standards and Technology, trustworthiness in ML is a critical barrier to adoption and will play a vital role in intelligent systems' safe and accountable operation. Thus, in this work, we demonstrate a real-time model-agnostic method to evaluate the relative reliability of ML predictions by incorporating out-of-distribution detection on the training dataset. It is well documented that ML algorithms excel at interpolation (or near-interpolation) tasks but significantly degrade at extrapolation. This occurs when new samples are "far" from training samples. The method, referred to as the Laplacian distributed decay for reliability (LADDR), determines the difference between the operational and training datasets, which is used to calculate a prediction's relative reliability. LADDR is demonstrated on a feedforward neural network-based model used to predict safety significant factors during different loss-of-flow transients. LADDR is intended as a "data supervisor" and determines the appropriateness of well-trained ML models in the context of operational conditions. Ultimately, LADDR illustrates how training data can be used as evidence to support the trustworthiness of ML predictions when utilized for conventional interpolation tasks.
Federated Inference with Reliable Uncertainty Quantification over Wireless Channels via Conformal Prediction
Aug 08, 2023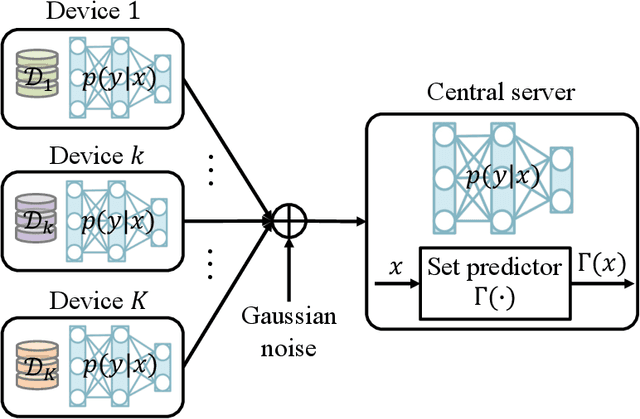
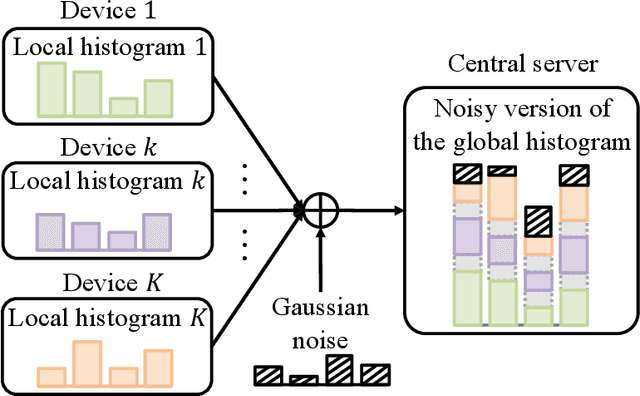
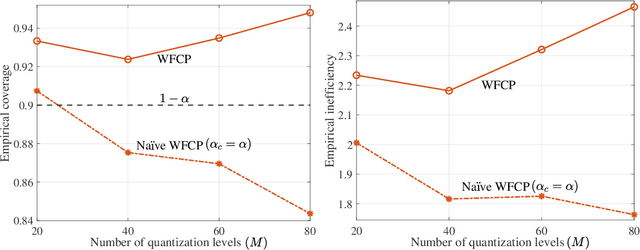
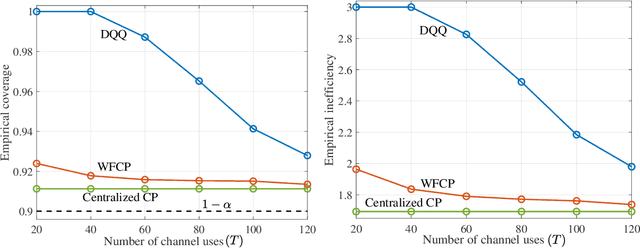
Consider a setting in which devices and a server share a pre-trained model. The server wishes to make an inference on a new input given the model. Devices have access to data, previously not used for training, and can communicate to the server over a common wireless channel. If the devices have no access to the new input, can communication from devices to the server enhance the quality of the inference decision at the server? Recent work has introduced federated conformal prediction (CP), which leverages devices-to-server communication to improve the reliability of the server's decision. With federated CP, devices communicate to the server information about the loss accrued by the shared pre-trained model on the local data, and the server leverages this information to calibrate a decision interval, or set, so that it is guaranteed to contain the correct answer with a pre-defined target reliability level. Previous work assumed noise-free communication, whereby devices can communicate a single real number to the server. In this paper, we study for the first time federated CP in a wireless setting. We introduce a novel protocol, termed wireless federated conformal prediction (WFCP), which builds on type-based multiple access (TBMA) and on a novel quantile correction strategy. WFCP is proved to provide formal reliability guarantees in terms of coverage of the predicted set produced by the server. Using numerical results, we demonstrate the significant advantages of WFCP against digital implementations of existing federated CP schemes, especially in regimes with limited communication resources and/or large number of devices.