 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust cell-free mmWave/sub-THz access using minimal coordination and coarse synchronization
Aug 04, 2023
This study investigates simpler alternatives to coherent joint transmission for supporting robust connectivity against signal blockage in mmWave/sub-THz access networks. By taking an information-theoretic viewpoint, we demonstrate analytically that with a careful design, full macrodiversity gains and significant SNR gains can be achieved through canonical receivers and minimal coordination and synchronization requirements at the infrastructure side. Our proposed scheme extends non-coherent joint transmission by employing a special form of diversity to counteract artificially induced deep fades that would otherwise make this technique often compare unfavorably against standard transmitter selection schemes. Additionally, the inclusion of an Alamouti-like space-time coding layer is shown to recover a significant fraction of the optimal performance. Our conclusions are based on an insightful multi-point intermittent block fading channel model that enables rigorous ergodic and outage rate analysis, while also considering timing offsets due to imperfect delay compensation. Although simplified, our approach captures the essential features of modern mmWave/sub-THz communications, thereby providing practical design guidelines for realistic systems.
A State-Space Perspective on Modelling and Inference for Online Skill Rating
Aug 04, 2023This paper offers a comprehensive review of the main methodologies used for skill rating in competitive sports. We advocate for a state-space model perspective, wherein players' skills are represented as time-varying, and match results serve as the sole observed quantities. The state-space model perspective facilitates the decoupling of modeling and inference, enabling a more focused approach highlighting model assumptions, while also fostering the development of general-purpose inference tools. We explore the essential steps involved in constructing a state-space model for skill rating before turning to a discussion on the three stages of inference: filtering, smoothing and parameter estimation. Throughout, we examine the computational challenges of scaling up to high-dimensional scenarios involving numerous players and matches, highlighting approximations and reductions used to address these challenges effectively. We provide concise summaries of popular methods documented in the literature, along with their inferential paradigms and introduce new approaches to skill rating inference based on sequential Monte Carlo and finite state-spaces. We close with numerical experiments demonstrating a practical workflow on real data across different sports.
Learning Referring Video Object Segmentation from Weak Annotation
Aug 04, 2023
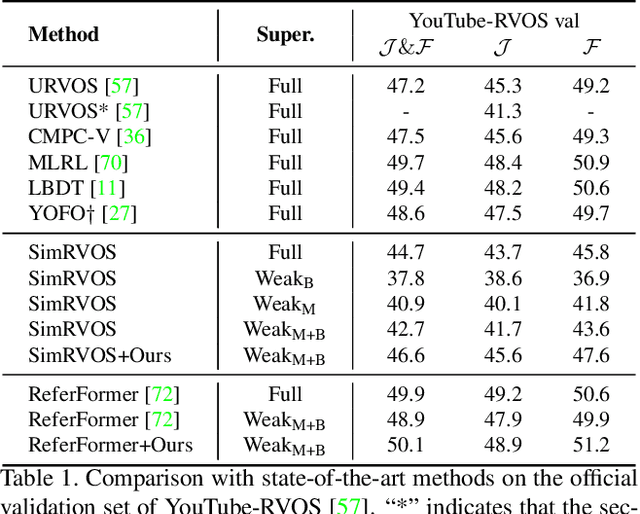

Referring video object segmentation (RVOS) is a task that aims to segment the target object in all video frames based on a sentence describing the object. Previous RVOS methods have achieved significant performance with densely-annotated datasets, whose construction is expensive and time-consuming. To relieve the burden of data annotation while maintaining sufficient supervision for segmentation, we propose a new annotation scheme, in which we label the frame where the object first appears with a mask and use bounding boxes for the subsequent frames. Based on this scheme, we propose a method to learn from this weak annotation. Specifically, we design a cross frame segmentation method, which uses the language-guided dynamic filters to thoroughly leverage the valuable mask annotation and bounding boxes. We further develop a bi-level contrastive learning method to encourage the model to learn discriminative representation at the pixel level. Extensive experiments and ablative analyses show that our method is able to achieve competitive performance without the demand of dense mask annotation. The code will be available at https://github.com/wangbo-zhao/WRVOS/.
Optimally Computing Compressed Indexing Arrays Based on the Compact Directed Acyclic Word Graph
Aug 04, 2023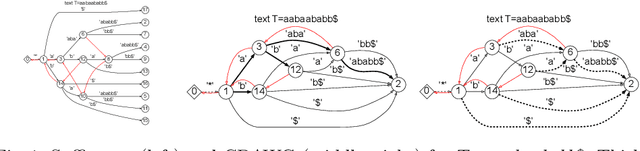

In this paper, we present the first study of the computational complexity of converting an automata-based text index structure, called the Compact Directed Acyclic Word Graph (CDAWG), of size $e$ for a text $T$ of length $n$ into other text indexing structures for the same text, suitable for highly repetitive texts: the run-length BWT of size $r$, the irreducible PLCP array of size $r$, and the quasi-irreducible LPF array of size $e$, as well as the lex-parse of size $O(r)$ and the LZ77-parse of size $z$, where $r, z \le e$. As main results, we showed that the above structures can be optimally computed from either the CDAWG for $T$ stored in read-only memory or its self-index version of size $e$ without a text in $O(e)$ worst-case time and words of working space. To obtain the above results, we devised techniques for enumerating a particular subset of suffixes in the lexicographic and text orders using the forward and backward search on the CDAWG by extending the results by Belazzougui et al. in 2015.
NP-Free: A Real-Time Normalization-free and Parameter-tuning-free Representation Approach for Open-ended Time Series
Apr 12, 2023
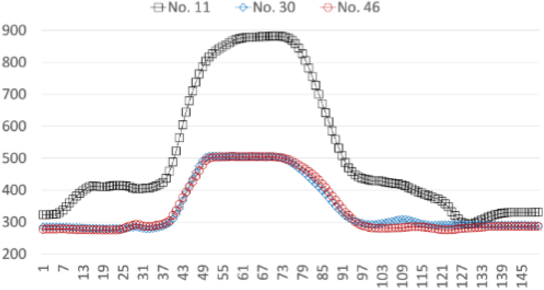
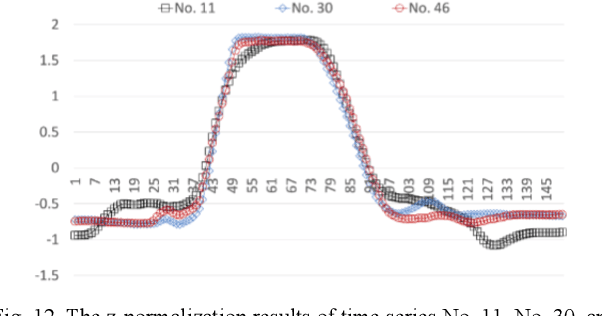
As more connected devices are implemented in a cyber-physical world and data is expected to be collected and processed in real time, the ability to handle time series data has become increasingly significant. To help analyze time series in data mining applications, many time series representation approaches have been proposed to convert a raw time series into another series for representing the original time series. However, existing approaches are not designed for open-ended time series (which is a sequence of data points being continuously collected at a fixed interval without any length limit) because these approaches need to know the total length of the target time series in advance and pre-process the entire time series using normalization methods. Furthermore, many representation approaches require users to configure and tune some parameters beforehand in order to achieve satisfactory representation results. In this paper, we propose NP-Free, a real-time Normalization-free and Parameter-tuning-free representation approach for open-ended time series. Without needing to use any normalization method or tune any parameter, NP-Free can generate a representation for a raw time series on the fly by converting each data point of the time series into a root-mean-square error (RMSE) value based on Long Short-Term Memory (LSTM) and a Look-Back and Predict-Forward strategy. To demonstrate the capability of NP-Free in representing time series, we conducted several experiments based on real-world open-source time series datasets. We also evaluated the time consumption of NP-Free in generating representations.
Dynamic Model Agnostic Reliability Evaluation of Machine-Learning Methods Integrated in Instrumentation & Control Systems
Aug 08, 2023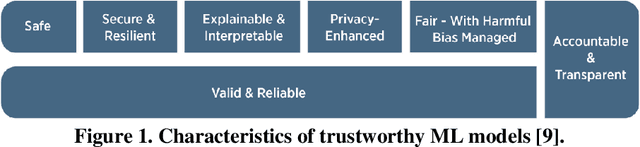



In recent years, the field of data-driven neural network-based machine learning (ML) algorithms has grown significantly and spurred research in its applicability to instrumentation and control systems. While they are promising in operational contexts, the trustworthiness of such algorithms is not adequately assessed. Failures of ML-integrated systems are poorly understood; the lack of comprehensive risk modeling can degrade the trustworthiness of these systems. In recent reports by the National Institute for Standards and Technology, trustworthiness in ML is a critical barrier to adoption and will play a vital role in intelligent systems' safe and accountable operation. Thus, in this work, we demonstrate a real-time model-agnostic method to evaluate the relative reliability of ML predictions by incorporating out-of-distribution detection on the training dataset. It is well documented that ML algorithms excel at interpolation (or near-interpolation) tasks but significantly degrade at extrapolation. This occurs when new samples are "far" from training samples. The method, referred to as the Laplacian distributed decay for reliability (LADDR), determines the difference between the operational and training datasets, which is used to calculate a prediction's relative reliability. LADDR is demonstrated on a feedforward neural network-based model used to predict safety significant factors during different loss-of-flow transients. LADDR is intended as a "data supervisor" and determines the appropriateness of well-trained ML models in the context of operational conditions. Ultimately, LADDR illustrates how training data can be used as evidence to support the trustworthiness of ML predictions when utilized for conventional interpolation tasks.
Temporal DINO: A Self-supervised Video Strategy to Enhance Action Prediction
Aug 08, 2023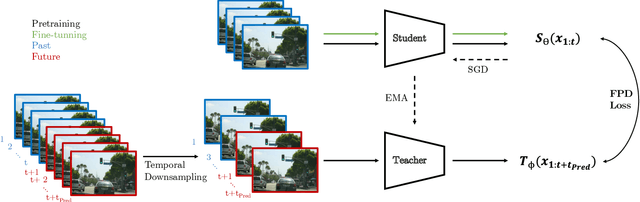
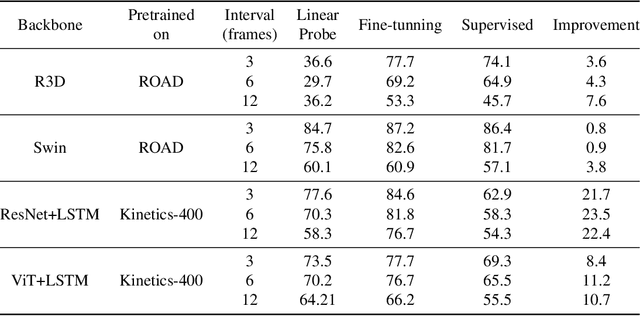

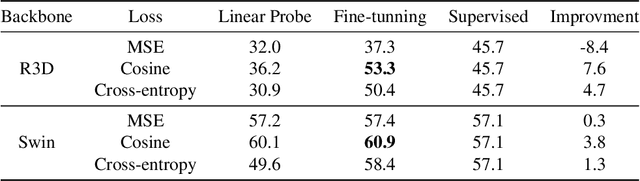
The emerging field of action prediction plays a vital role in various computer vision applications such as autonomous driving, activity analysis and human-computer interaction. Despite significant advancements, accurately predicting future actions remains a challenging problem due to high dimensionality, complex dynamics and uncertainties inherent in video data. Traditional supervised approaches require large amounts of labelled data, which is expensive and time-consuming to obtain. This paper introduces a novel self-supervised video strategy for enhancing action prediction inspired by DINO (self-distillation with no labels). The Temporal-DINO approach employs two models; a 'student' processing past frames; and a 'teacher' processing both past and future frames, enabling a broader temporal context. During training, the teacher guides the student to learn future context by only observing past frames. The strategy is evaluated on ROAD dataset for the action prediction downstream task using 3D-ResNet, Transformer, and LSTM architectures. The experimental results showcase significant improvements in prediction performance across these architectures, with our method achieving an average enhancement of 9.9% Precision Points (PP), highlighting its effectiveness in enhancing the backbones' capabilities of capturing long-term dependencies. Furthermore, our approach demonstrates efficiency regarding the pretraining dataset size and the number of epochs required. This method overcomes limitations present in other approaches, including considering various backbone architectures, addressing multiple prediction horizons, reducing reliance on hand-crafted augmentations, and streamlining the pretraining process into a single stage. These findings highlight the potential of our approach in diverse video-based tasks such as activity recognition, motion planning, and scene understanding.
Federated Inference with Reliable Uncertainty Quantification over Wireless Channels via Conformal Prediction
Aug 08, 2023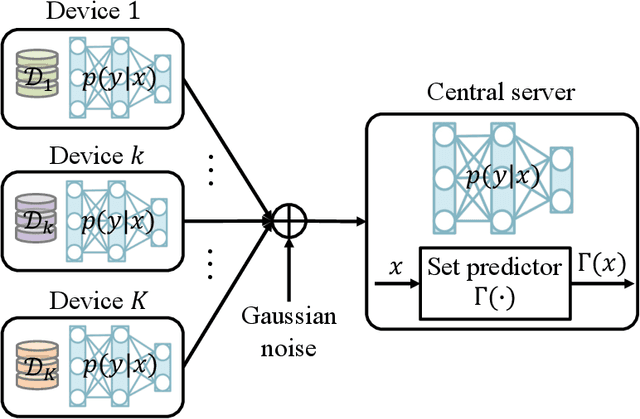
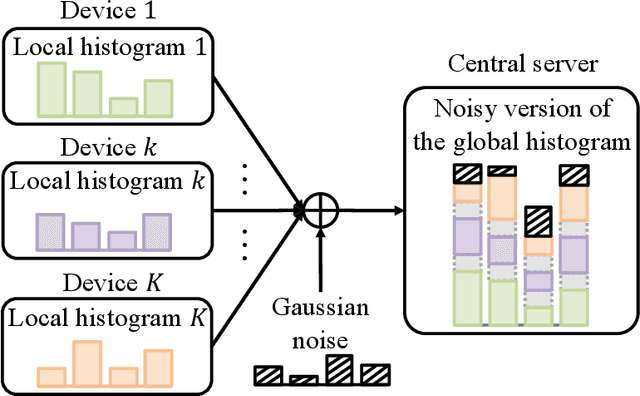
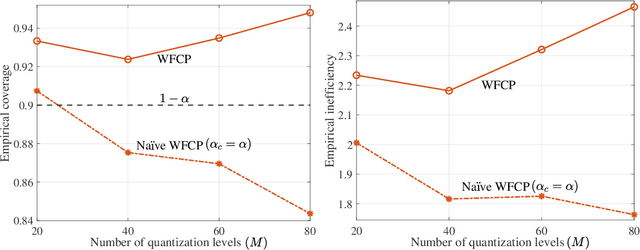
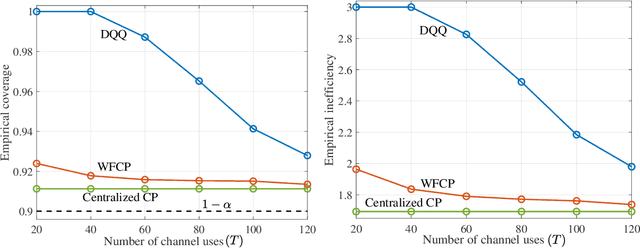
Consider a setting in which devices and a server share a pre-trained model. The server wishes to make an inference on a new input given the model. Devices have access to data, previously not used for training, and can communicate to the server over a common wireless channel. If the devices have no access to the new input, can communication from devices to the server enhance the quality of the inference decision at the server? Recent work has introduced federated conformal prediction (CP), which leverages devices-to-server communication to improve the reliability of the server's decision. With federated CP, devices communicate to the server information about the loss accrued by the shared pre-trained model on the local data, and the server leverages this information to calibrate a decision interval, or set, so that it is guaranteed to contain the correct answer with a pre-defined target reliability level. Previous work assumed noise-free communication, whereby devices can communicate a single real number to the server. In this paper, we study for the first time federated CP in a wireless setting. We introduce a novel protocol, termed wireless federated conformal prediction (WFCP), which builds on type-based multiple access (TBMA) and on a novel quantile correction strategy. WFCP is proved to provide formal reliability guarantees in terms of coverage of the predicted set produced by the server. Using numerical results, we demonstrate the significant advantages of WFCP against digital implementations of existing federated CP schemes, especially in regimes with limited communication resources and/or large number of devices.
EasyNet: An Easy Network for 3D Industrial Anomaly Detection
Jul 27, 2023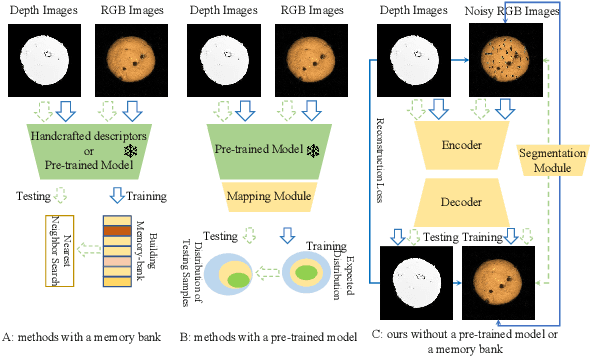
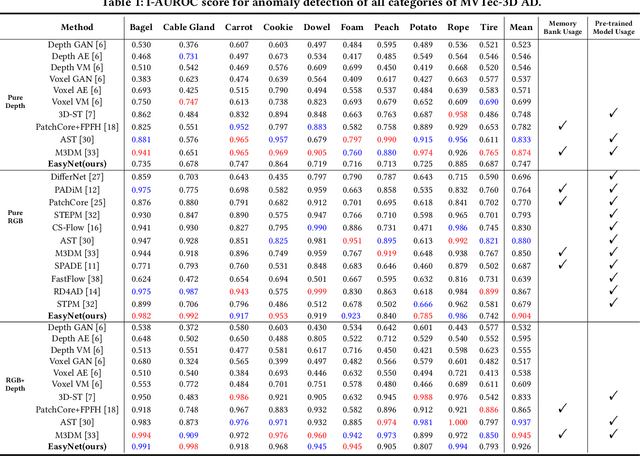
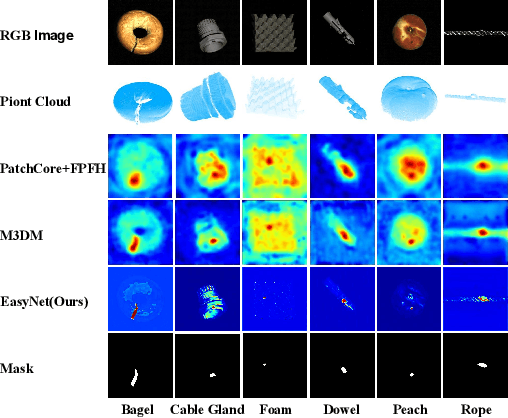
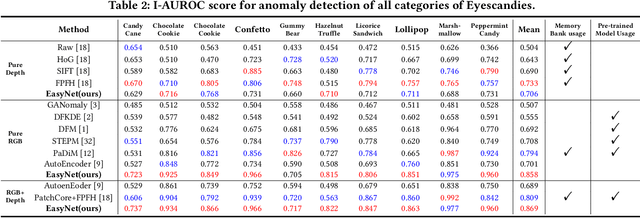
3D anomaly detection is an emerging and vital computer vision task in industrial manufacturing (IM). Recently many advanced algorithms have been published, but most of them cannot meet the needs of IM. There are several disadvantages: i) difficult to deploy on production lines since their algorithms heavily rely on large pre-trained models; ii) hugely increase storage overhead due to overuse of memory banks; iii) the inference speed cannot be achieved in real-time. To overcome these issues, we propose an easy and deployment-friendly network (called EasyNet) without using pre-trained models and memory banks: firstly, we design a multi-scale multi-modality feature encoder-decoder to accurately reconstruct the segmentation maps of anomalous regions and encourage the interaction between RGB images and depth images; secondly, we adopt a multi-modality anomaly segmentation network to achieve a precise anomaly map; thirdly, we propose an attention-based information entropy fusion module for feature fusion during inference, making it suitable for real-time deployment. Extensive experiments show that EasyNet achieves an anomaly detection AUROC of 92.6% without using pre-trained models and memory banks. In addition, EasyNet is faster than existing methods, with a high frame rate of 94.55 FPS on a Tesla V100 GPU.
Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models
May 29, 2023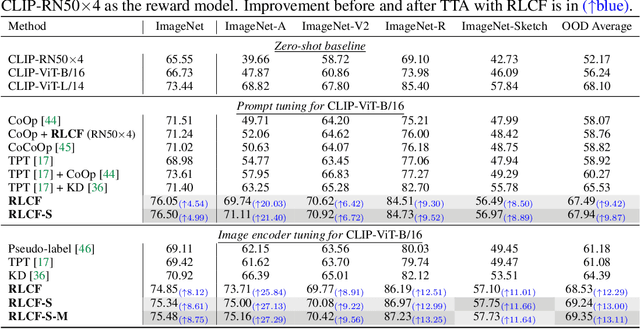
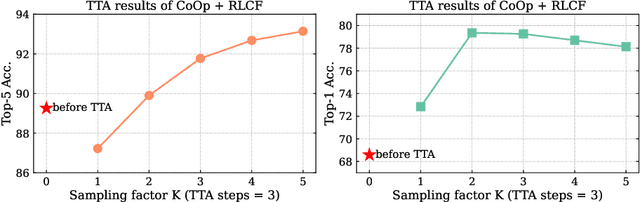
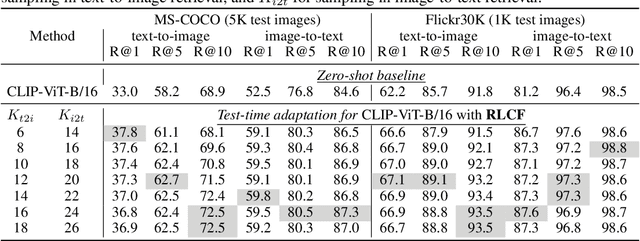
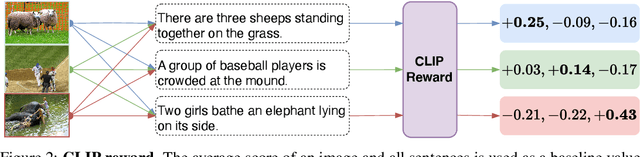
Misalignment between the outputs of a vision-language (VL) model and task goal hinders its deployment. This issue can worsen when there are distribution shifts between the training and test data. To address this problem, prevailing fully test-time adaptation~(TTA) methods bootstrap themselves through entropy minimization. However, minimizing the entropy of the predictions makes the model overfit to incorrect output distributions of itself. In this work, we propose TTA with feedback to avoid such overfitting and align the model with task goals. Specifically, we adopt CLIP as reward model to provide feedback for VL models during test time in various tasks, including image classification, image-text retrieval, and image captioning. Given a single test sample, the model aims to maximize CLIP reward through reinforcement learning. We adopt a reward design with the average CLIP score of sampled candidates as the baseline. This design is simple and surprisingly effective when combined with various task-specific sampling strategies. The entire system is flexible, allowing the reward model to be extended with multiple CLIP models. Plus, a momentum buffer can be used to memorize and leverage the learned knowledge from multiple test samples. Extensive experiments demonstrate that our method significantly improves different VL models after TTA.