 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluation Strategy of Time-series Anomaly Detection with Decay Function
May 15, 2023
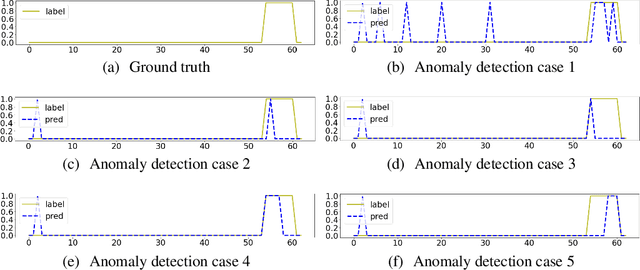
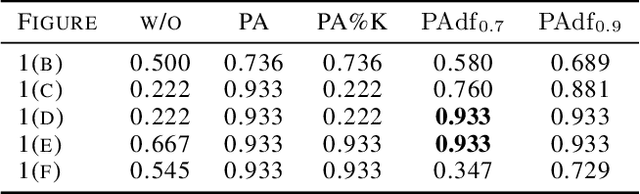
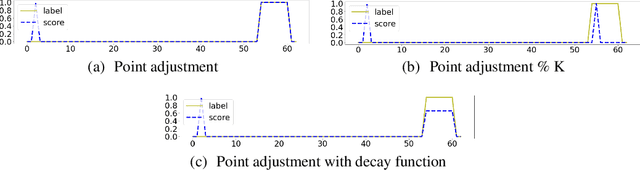
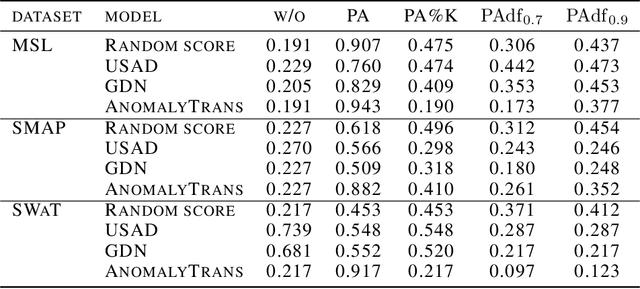
Recent algorithms of time-series anomaly detection have been evaluated by applying a Point Adjustment (PA) protocol. However, the PA protocol has a problem of overestimating the performance of the detection algorithms because it only depends on the number of detected abnormal segments and their size. We propose a novel evaluation protocol called the Point-Adjusted protocol with decay function (PAdf) to evaluate the time-series anomaly detection algorithm by reflecting the following ideal requirements: detect anomalies quickly and accurately without false alarms. This paper theoretically and experimentally shows that the PAdf protocol solves the over- and under-estimation problems of existing protocols such as PA and PA\%K. By conducting re-evaluations of SOTA models in benchmark datasets, we show that the PA protocol only focuses on finding many anomalous segments, whereas the score of the PAdf protocol considers not only finding many segments but also detecting anomalies quickly without delay.
SGEM: Test-Time Adaptation for Automatic Speech Recognition via Sequential-Level Generalized Entropy Minimization
Jun 08, 2023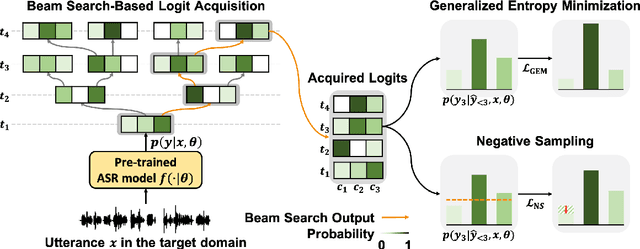
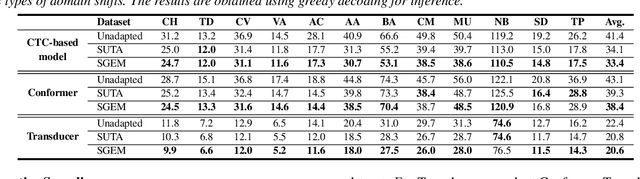

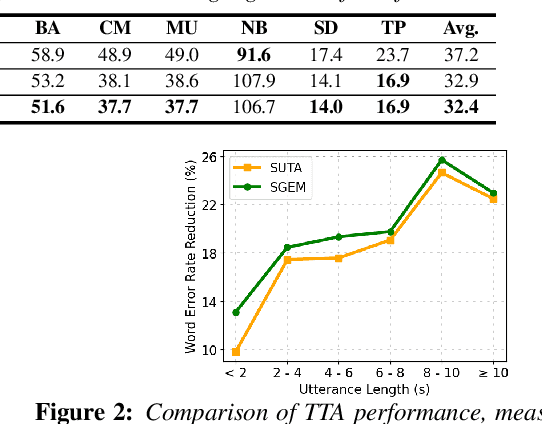
Automatic speech recognition (ASR) models are frequently exposed to data distribution shifts in many real-world scenarios, leading to erroneous predictions. To tackle this issue, an existing test-time adaptation (TTA) method has recently been proposed to adapt the pre-trained ASR model on unlabeled test instances without source data. Despite decent performance gain, this work relies solely on naive greedy decoding and performs adaptation across timesteps at a frame level, which may not be optimal given the sequential nature of the model output. Motivated by this, we propose a novel TTA framework, dubbed SGEM, for general ASR models. To treat the sequential output, SGEM first exploits beam search to explore candidate output logits and selects the most plausible one. Then, it utilizes generalized entropy minimization and negative sampling as unsupervised objectives to adapt the model. SGEM achieves state-of-the-art performance for three mainstream ASR models under various domain shifts.
Incrementally-Computable Neural Networks: Efficient Inference for Dynamic Inputs
Jul 27, 2023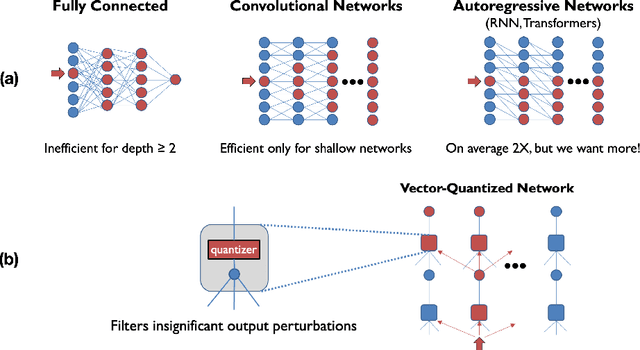
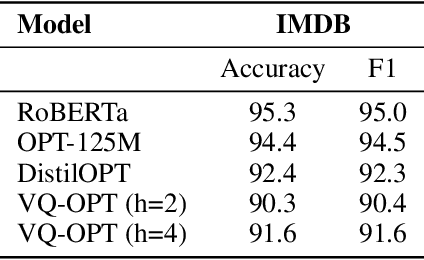
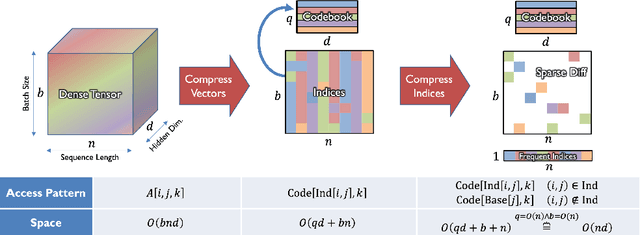
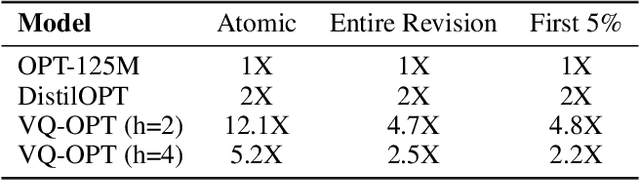
Deep learning often faces the challenge of efficiently processing dynamic inputs, such as sensor data or user inputs. For example, an AI writing assistant is required to update its suggestions in real time as a document is edited. Re-running the model each time is expensive, even with compression techniques like knowledge distillation, pruning, or quantization. Instead, we take an incremental computing approach, looking to reuse calculations as the inputs change. However, the dense connectivity of conventional architectures poses a major obstacle to incremental computation, as even minor input changes cascade through the network and restrict information reuse. To address this, we use vector quantization to discretize intermediate values in the network, which filters out noisy and unnecessary modifications to hidden neurons, facilitating the reuse of their values. We apply this approach to the transformers architecture, creating an efficient incremental inference algorithm with complexity proportional to the fraction of the modified inputs. Our experiments with adapting the OPT-125M pre-trained language model demonstrate comparable accuracy on document classification while requiring 12.1X (median) fewer operations for processing sequences of atomic edits.
Car-Driver Drowsiness Assessment through 1D Temporal Convolutional Networks
Jul 27, 2023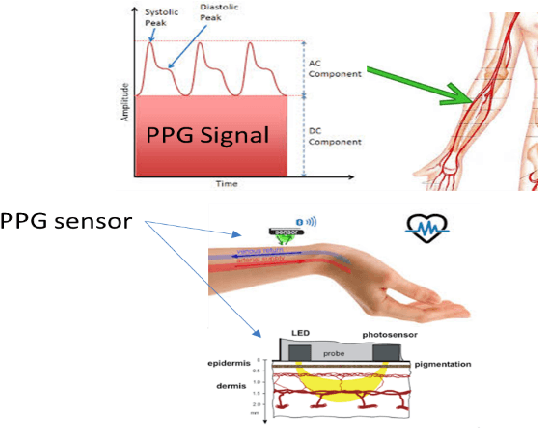
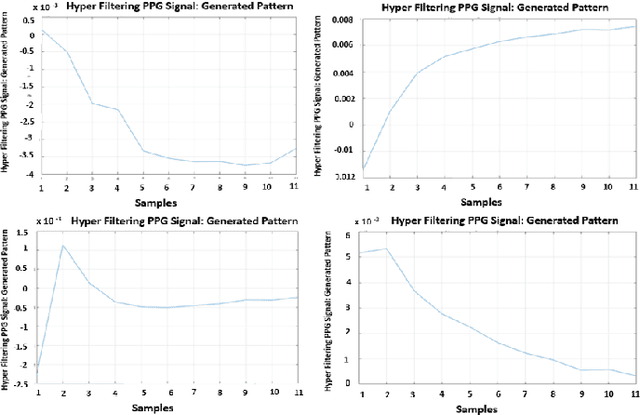
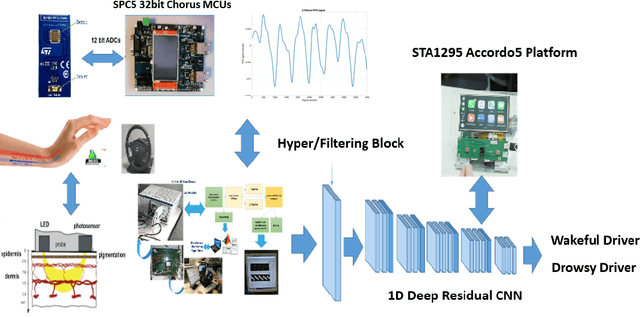
Recently, the scientific progress of Advanced Driver Assistance System solutions (ADAS) has played a key role in enhancing the overall safety of driving. ADAS technology enables active control of vehicles to prevent potentially risky situations. An important aspect that researchers have focused on is the analysis of the driver attention level, as recent reports confirmed a rising number of accidents caused by drowsiness or lack of attentiveness. To address this issue, various studies have suggested monitoring the driver physiological state, as there exists a well-established connection between the Autonomic Nervous System (ANS) and the level of attention. For our study, we designed an innovative bio-sensor comprising near-infrared LED emitters and photo-detectors, specifically a Silicon PhotoMultiplier device. This allowed us to assess the driver physiological status by analyzing the associated PhotoPlethysmography (PPG) signal.Furthermore, we developed an embedded time-domain hyper-filtering technique in conjunction with a 1D Temporal Convolutional architecture that embdes a progressive dilation setup. This integrated system enables near real-time classification of driver drowsiness, yielding remarkable accuracy levels of approximately 96%.
On the Fibonacci sequence and the Linear Time Invariant systems
Jun 03, 2023The Fibonacci sequence (FS) possesses exceptional mathematical properties that have captivated mathematicians, scientists, and artists across centuries. Its intriguing nature lies in its profound connection to the golden ratio, as well as its prevalence in the natural world, exhibited through phenomena such as spiral galaxies, plant seeds, the arrangement of petals, and branching structures. This report delves into the fundamental characteristics of the FS, explores its relationship with the golden ratio using Linear Time Invariant (LTI) systems, and investigates its diverse applications in various fields. Approaching the topic from the standpoint of a digital signal processing instructor in a grade course, we depict the FS as the consequential outcome of an LTI system when subjected to the unit impulse function. This LTI system can be regarded as the original source from which one of the most renowned formulas in mathematics emerges, and its parametric definition, along with the associated systems, is intricately tied to the golden ratio, symbolized by the irrational number Phi. This perspective naturally elucidates the well-established intricate relationship between the FS and Phi. Furthermore, building upon this perspective, we showcase other LTI systems that exhibit the same magnitude in the frequency domain. These systems are characterized by either an impulse response or a difference equation, resulting in a comparable or equivalent FS in terms of absolute value. By exploring these connections, we shed light on the remarkable similarities and variations that arise within the FS under different LTI systems.
Hierarchical Adaptive Voxel-guided Sampling for Real-time Applications in Large-scale Point Clouds
May 23, 2023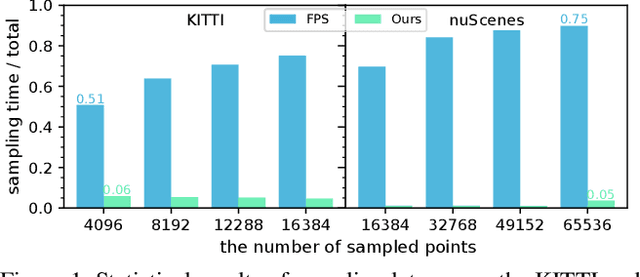
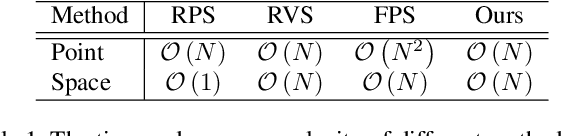
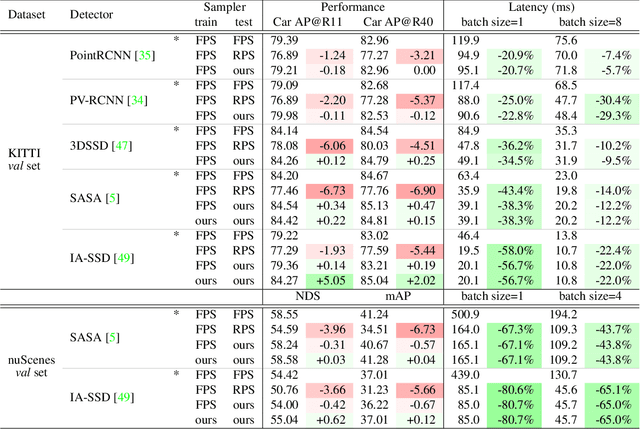
While point-based neural architectures have demonstrated their efficacy, the time-consuming sampler currently prevents them from performing real-time reasoning on scene-level point clouds. Existing methods attempt to overcome this issue by using random sampling strategy instead of the commonly-adopted farthest point sampling~(FPS), but at the expense of lower performance. So the effectiveness/efficiency trade-off remains under-explored. In this paper, we reveal the key to high-quality sampling is ensuring an even spacing between points in the subset, which can be naturally obtained through a grid. Based on this insight, we propose a hierarchical adaptive voxel-guided point sampler with linear complexity and high parallelization for real-time applications. Extensive experiments on large-scale point cloud detection and segmentation tasks demonstrate that our method achieves competitive performance with the most powerful FPS, at an amazing speed that is more than 100 times faster. This breakthrough in efficiency addresses the bottleneck of the sampling step when handling scene-level point clouds. Furthermore, our sampler can be easily integrated into existing models and achieves a 20$\sim$80\% reduction in runtime with minimal effort. The code will be available at https://github.com/OuyangJunyuan/pointcloud-3d-detector-tensorrt
Fourier Test-time Adaptation with Multi-level Consistency for Robust Classification
Jun 05, 2023

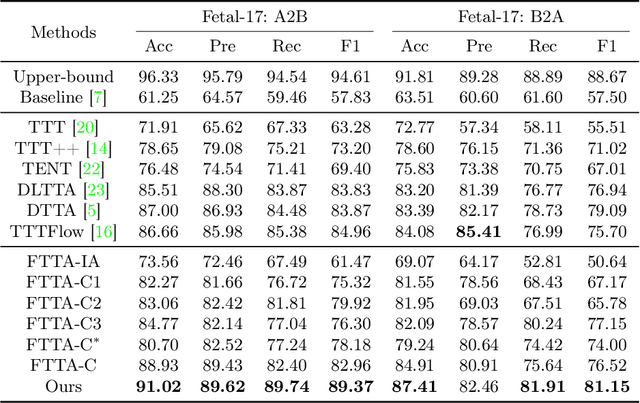
Deep classifiers may encounter significant performance degradation when processing unseen testing data from varying centers, vendors, and protocols. Ensuring the robustness of deep models against these domain shifts is crucial for their widespread clinical application. In this study, we propose a novel approach called Fourier Test-time Adaptation (FTTA), which employs a dual-adaptation design to integrate input and model tuning, thereby jointly improving the model robustness. The main idea of FTTA is to build a reliable multi-level consistency measurement of paired inputs for achieving self-correction of prediction. Our contribution is two-fold. First, we encourage consistency in global features and local attention maps between the two transformed images of the same input. Here, the transformation refers to Fourier-based input adaptation, which can transfer one unseen image into source style to reduce the domain gap. Furthermore, we leverage style-interpolated images to enhance the global and local features with learnable parameters, which can smooth the consistency measurement and accelerate convergence. Second, we introduce a regularization technique that utilizes style interpolation consistency in the frequency space to encourage self-consistency in the logit space of the model output. This regularization provides strong self-supervised signals for robustness enhancement. FTTA was extensively validated on three large classification datasets with different modalities and organs. Experimental results show that FTTA is general and outperforms other strong state-of-the-art methods.
Adaptive Sparsity Level during Training for Efficient Time Series Forecasting with Transformers
May 28, 2023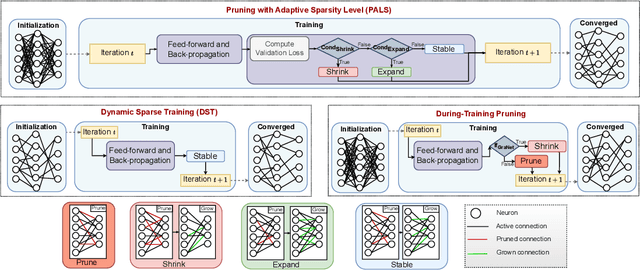
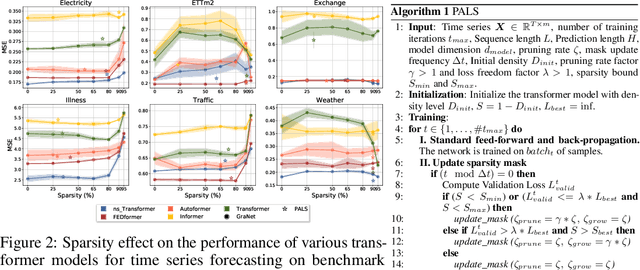
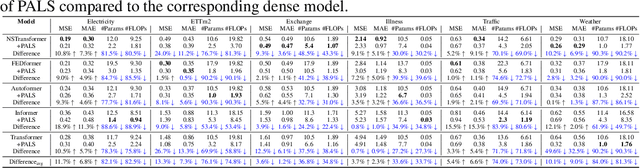
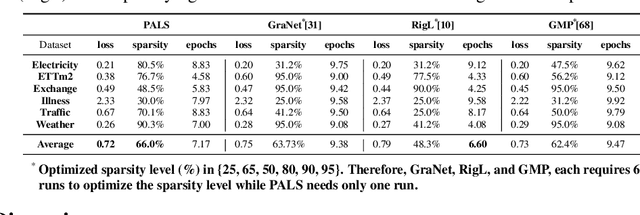
Efficient time series forecasting has become critical for real-world applications, particularly with deep neural networks (DNNs). Efficiency in DNNs can be achieved through sparse connectivity and reducing the model size. However, finding the sparsity level automatically during training remains a challenging task due to the heterogeneity in the loss-sparsity tradeoffs across the datasets. In this paper, we propose \enquote{\textbf{P}runing with \textbf{A}daptive \textbf{S}parsity \textbf{L}evel} (\textbf{PALS}), to automatically seek an optimal balance between loss and sparsity, all without the need for a predefined sparsity level. PALS draws inspiration from both sparse training and during-training methods. It introduces the novel "expand" mechanism in training sparse neural networks, allowing the model to dynamically shrink, expand, or remain stable to find a proper sparsity level. In this paper, we focus on achieving efficiency in transformers known for their excellent time series forecasting performance but high computational cost. Nevertheless, PALS can be applied directly to any DNN. In the scope of these arguments, we demonstrate its effectiveness also on the DLinear model. Experimental results on six benchmark datasets and five state-of-the-art transformer variants show that PALS substantially reduces model size while maintaining comparable performance to the dense model. More interestingly, PALS even outperforms the dense model, in 12 and 14 cases out of 30 cases in terms of MSE and MAE loss, respectively, while reducing 65% parameter count and 63% FLOPs on average. Our code will be publicly available upon acceptance of the paper.
Efficient neural supersampling on a novel gaming dataset
Aug 03, 2023



Real-time rendering for video games has become increasingly challenging due to the need for higher resolutions, framerates and photorealism. Supersampling has emerged as an effective solution to address this challenge. Our work introduces a novel neural algorithm for supersampling rendered content that is 4 times more efficient than existing methods while maintaining the same level of accuracy. Additionally, we introduce a new dataset which provides auxiliary modalities such as motion vectors and depth generated using graphics rendering features like viewport jittering and mipmap biasing at different resolutions. We believe that this dataset fills a gap in the current dataset landscape and can serve as a valuable resource to help measure progress in the field and advance the state-of-the-art in super-resolution techniques for gaming content.
Domain specificity and data efficiency in typo tolerant spell checkers: the case of search in online marketplaces
Aug 03, 2023Typographical errors are a major source of frustration for visitors of online marketplaces. Because of the domain-specific nature of these marketplaces and the very short queries users tend to search for, traditional spell cheking solutions do not perform well in correcting typos. We present a data augmentation method to address the lack of annotated typo data and train a recurrent neural network to learn context-limited domain-specific embeddings. Those embeddings are deployed in a real-time inferencing API for the Microsoft AppSource marketplace to find the closest match between a misspelled user query and the available product names. Our data efficient solution shows that controlled high quality synthetic data may be a powerful tool especially considering the current climate of large language models which rely on prohibitively huge and often uncontrolled datasets.