 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Dynamic Programming forNetworked Multi-Agent Markov Decision Processes
Jul 31, 2023
The main goal of this paper is to investigate distributed dynamic programming (DP) to solve networked multi-agent Markov decision problems (MDPs). We consider a distributed multi-agent case, where each agent does not have an access to the rewards of other agents except for its own reward. Moreover, each agent can share their parameters with its neighbors over a communication network represented by a graph. We propose a distributed DP in the continuous-time domain, and prove its convergence through control theoretic viewpoints. The proposed analysis can be viewed as a preliminary ordinary differential equation (ODE) analysis of a distributed temporal difference learning algorithm, whose convergence can be proved using Borkar-Meyn theorem and the single time-scale approach.
When Super-Resolution Meets Camouflaged Object Detection: A Comparison Study
Aug 08, 2023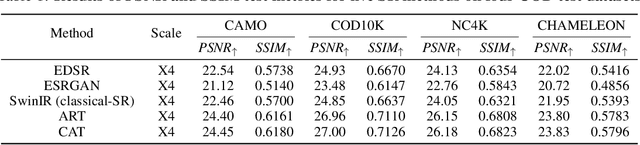
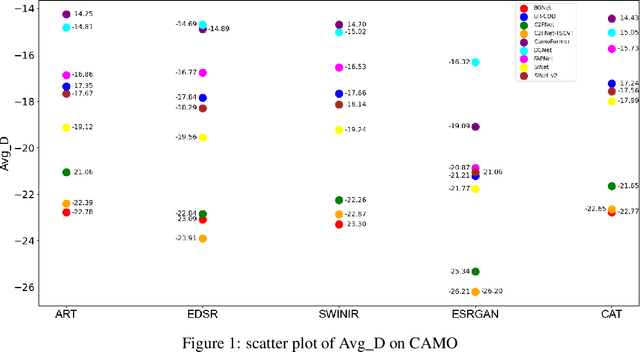
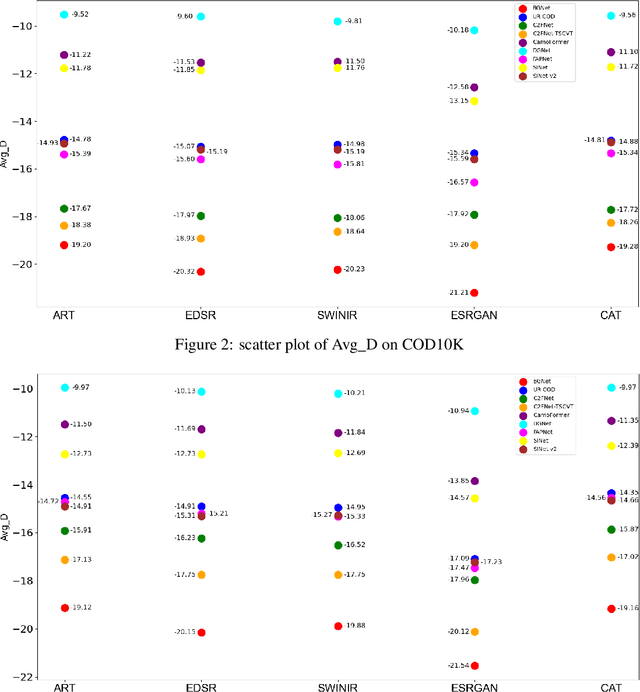
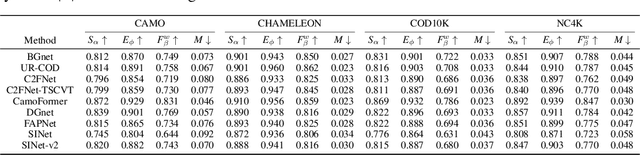
Super Resolution (SR) and Camouflaged Object Detection (COD) are two hot topics in computer vision with various joint applications. For instance, low-resolution surveillance images can be successively processed by super-resolution techniques and camouflaged object detection. However, in previous work, these two areas are always studied in isolation. In this paper, we, for the first time, conduct an integrated comparative evaluation for both. Specifically, we benchmark different super-resolution methods on commonly used COD datasets, and meanwhile, we evaluate the robustness of different COD models by using COD data processed by SR methods. Our goal is to bridge these two domains, discover novel experimental phenomena, summarize new experim.
Robust Autonomous Vehicle Pursuit without Expert Steering Labels
Aug 16, 2023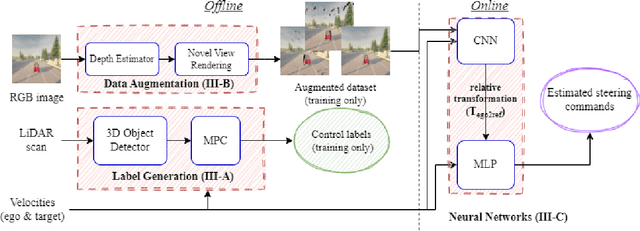

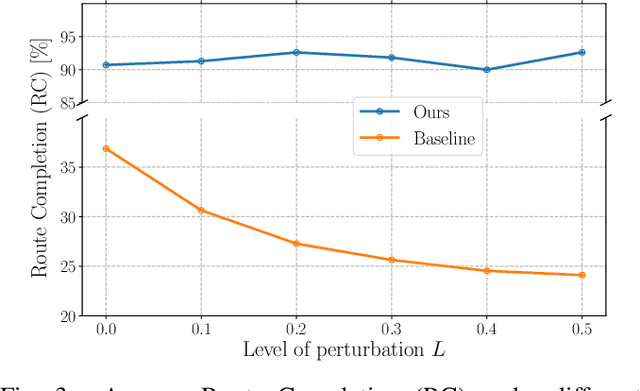
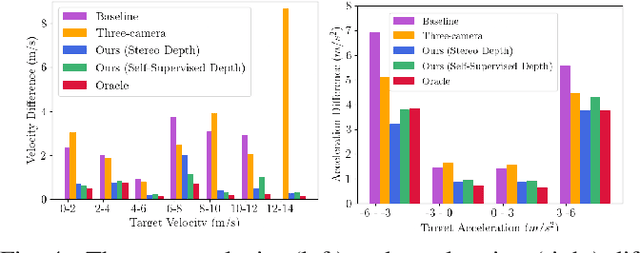
In this work, we present a learning method for lateral and longitudinal motion control of an ego-vehicle for vehicle pursuit. The car being controlled does not have a pre-defined route, rather it reactively adapts to follow a target vehicle while maintaining a safety distance. To train our model, we do not rely on steering labels recorded from an expert driver but effectively leverage a classical controller as an offline label generation tool. In addition, we account for the errors in the predicted control values, which can lead to a loss of tracking and catastrophic crashes of the controlled vehicle. To this end, we propose an effective data augmentation approach, which allows to train a network capable of handling different views of the target vehicle. During the pursuit, the target vehicle is firstly localized using a Convolutional Neural Network. The network takes a single RGB image along with cars' velocities and estimates the target vehicle's pose with respect to the ego-vehicle. This information is then fed to a Multi-Layer Perceptron, which regresses the control commands for the ego-vehicle, namely throttle and steering angle. We extensively validate our approach using the CARLA simulator on a wide range of terrains. Our method demonstrates real-time performance and robustness to different scenarios including unseen trajectories and high route completion. The project page containing code and multimedia can be publicly accessed here: https://changyaozhou.github.io/Autonomous-Vehicle-Pursuit/.
Deployment and Analysis of Instance Segmentation Algorithm for In-field Grade Estimation of Sweetpotatoes
Aug 16, 2023Shape estimation of sweetpotato (SP) storage roots is inherently challenging due to their varied size and shape characteristics. Even measuring "simple" metrics, such as length and width, requires significant time investments either directly in-field or afterward using automated graders. In this paper, we present the results of a model that can perform grading and provide yield estimates directly in the field quicker than manual measurements. Detectron2, a library consisting of deep-learning object detection algorithms, was used to implement Mask R-CNN, an instance segmentation model. This model was deployed for in-field grade estimation of SPs and evaluated against an optical sorter. Storage roots from various clones imaged with a cellphone during trials between 2019 and 2020, were used in the model's training and validation to fine-tune a model to detect SPs. Our results showed that the model could distinguish individual SPs in various environmental conditions including variations in lighting and soil characteristics. RMSE for length, width, and weight, from the model compared to a commercial optical sorter, were 0.66 cm, 1.22 cm, and 74.73 g, respectively, while the RMSE of root counts per plot was 5.27 roots, with r^2 = 0.8. This phenotyping strategy has the potential enable rapid yield estimates in the field without the need for sophisticated and costly optical sorters and may be more readily deployed in environments with limited access to these kinds of resources or facilities.
Finding the Optimum Design of Large Gas Engines Prechambers Using CFD and Bayesian Optimization
Aug 03, 2023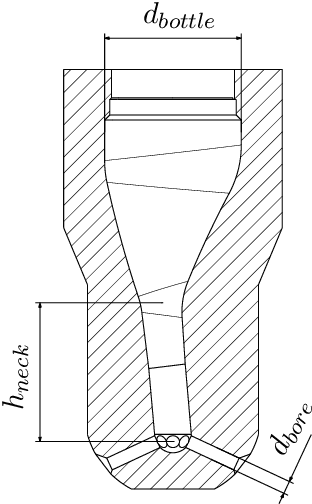
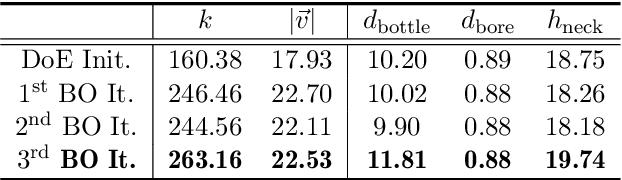
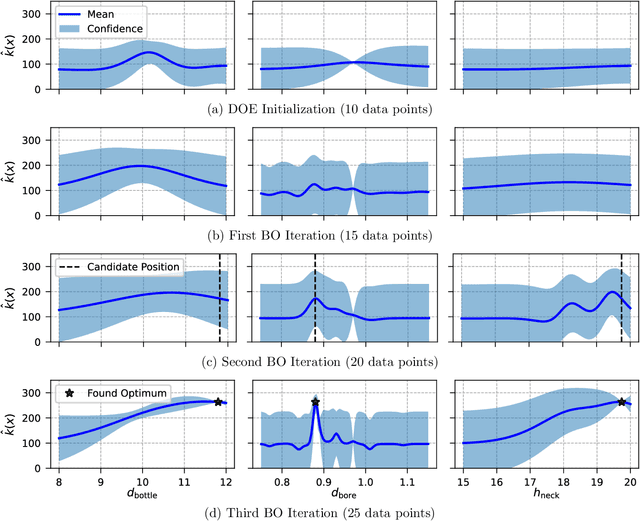
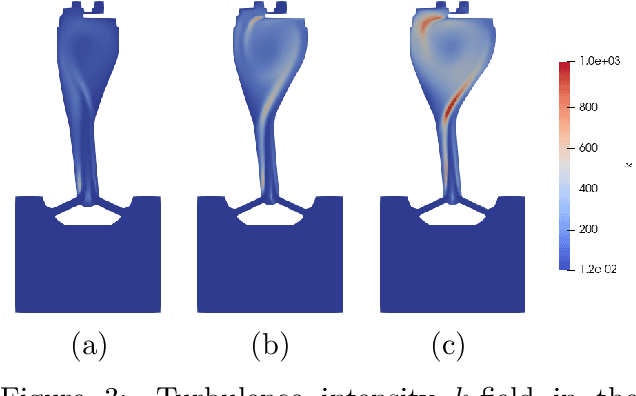
The turbulent jet ignition concept using prechambers is a promising solution to achieve stable combustion at lean conditions in large gas engines, leading to high efficiency at low emission levels. Due to the wide range of design and operating parameters for large gas engine prechambers, the preferred method for evaluating different designs is computational fluid dynamics (CFD), as testing in test bed measurement campaigns is time-consuming and expensive. However, the significant computational time required for detailed CFD simulations due to the complexity of solving the underlying physics also limits its applicability. In optimization settings similar to the present case, i.e., where the evaluation of the objective function(s) is computationally costly, Bayesian optimization has largely replaced classical design-of-experiment. Thus, the present study deals with the computationally efficient Bayesian optimization of large gas engine prechambers design using CFD simulation. Reynolds-averaged-Navier-Stokes simulations are used to determine the target values as a function of the selected prechamber design parameters. The results indicate that the chosen strategy is effective to find a prechamber design that achieves the desired target values.
Explainable Deep Learning for Tumor Dynamic Modeling and Overall Survival Prediction using Neural-ODE
Aug 02, 2023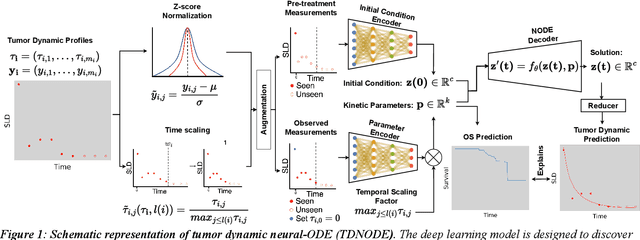
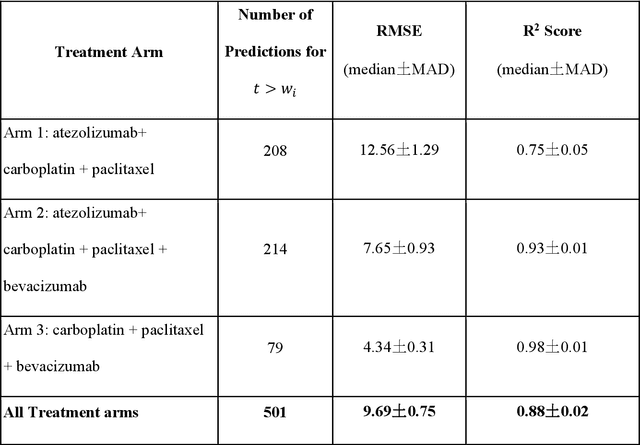
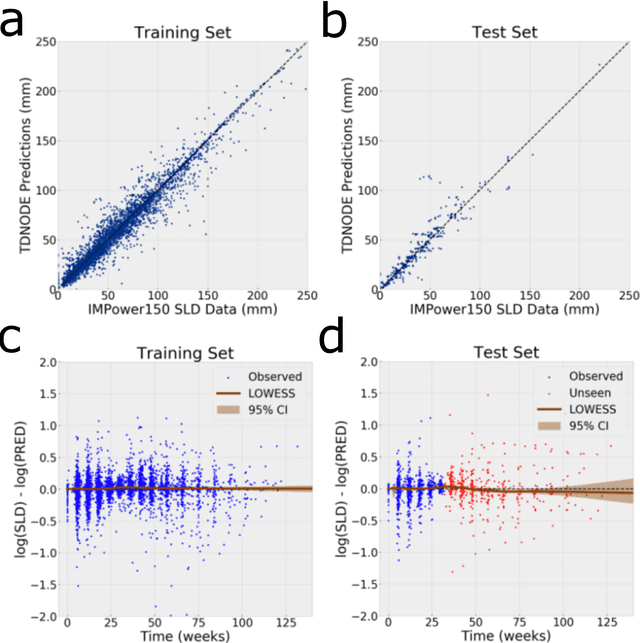
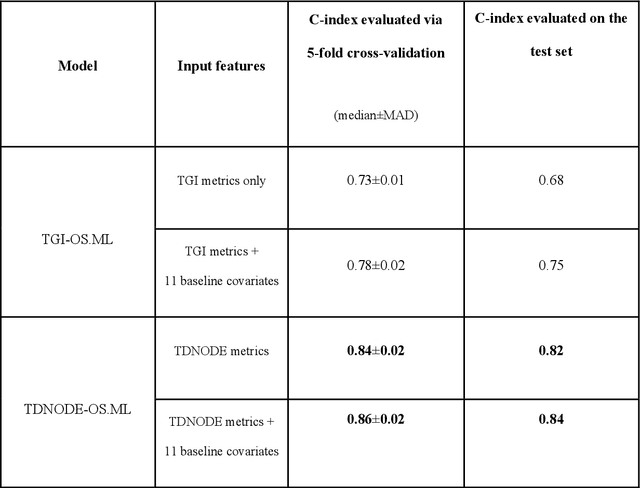
While tumor dynamic modeling has been widely applied to support the development of oncology drugs, there remains a need to increase predictivity, enable personalized therapy, and improve decision-making. We propose the use of Tumor Dynamic Neural-ODE (TDNODE) as a pharmacology-informed neural network to enable model discovery from longitudinal tumor size data. We show that TDNODE overcomes a key limitation of existing models in its ability to make unbiased predictions from truncated data. The encoder-decoder architecture is designed to express an underlying dynamical law which possesses the fundamental property of generalized homogeneity with respect to time. Thus, the modeling formalism enables the encoder output to be interpreted as kinetic rate metrics, with inverse time as the physical unit. We show that the generated metrics can be used to predict patients' overall survival (OS) with high accuracy. The proposed modeling formalism provides a principled way to integrate multimodal dynamical datasets in oncology disease modeling.
Deep Directly-Trained Spiking Neural Networks for Object Detection
Jul 27, 2023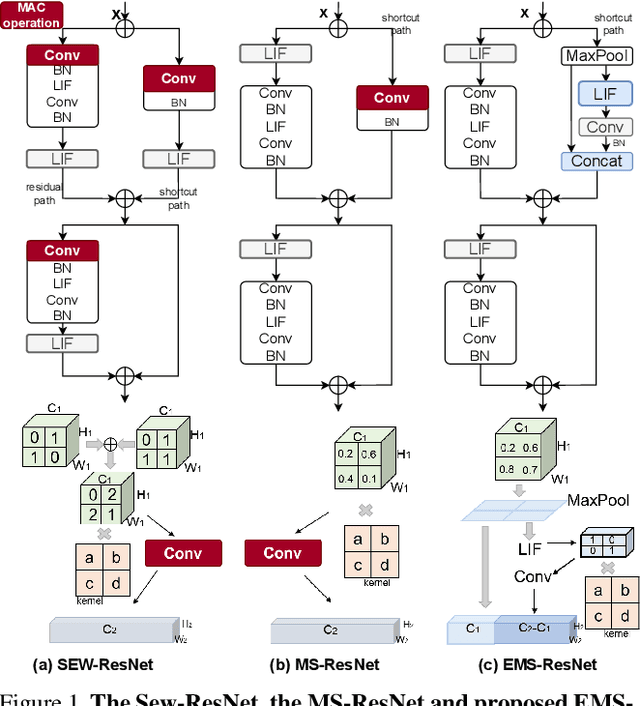

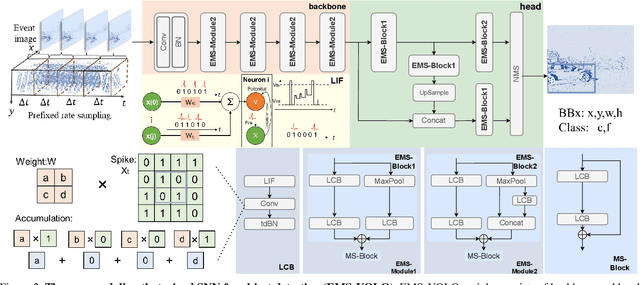
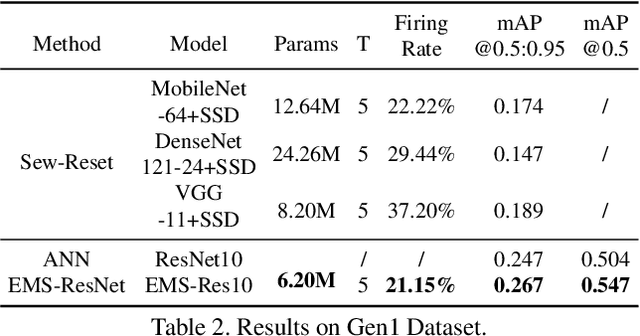
Spiking neural networks (SNNs) are brain-inspired energy-efficient models that encode information in spatiotemporal dynamics. Recently, deep SNNs trained directly have shown great success in achieving high performance on classification tasks with very few time steps. However, how to design a directly-trained SNN for the regression task of object detection still remains a challenging problem. To address this problem, we propose EMS-YOLO, a novel directly-trained SNN framework for object detection, which is the first trial to train a deep SNN with surrogate gradients for object detection rather than ANN-SNN conversion strategies. Specifically, we design a full-spike residual block, EMS-ResNet, which can effectively extend the depth of the directly-trained SNN with low power consumption. Furthermore, we theoretically analyze and prove the EMS-ResNet could avoid gradient vanishing or exploding. The results demonstrate that our approach outperforms the state-of-the-art ANN-SNN conversion methods (at least 500 time steps) in extremely fewer time steps (only 4 time steps). It is shown that our model could achieve comparable performance to the ANN with the same architecture while consuming 5.83 times less energy on the frame-based COCO Dataset and the event-based Gen1 Dataset.
What if We Enrich day-ahead Solar Irradiance Time Series Forecasting with Spatio-Temporal Context?
Jun 01, 2023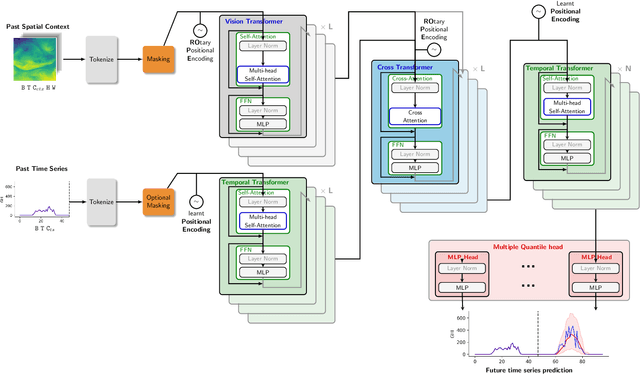

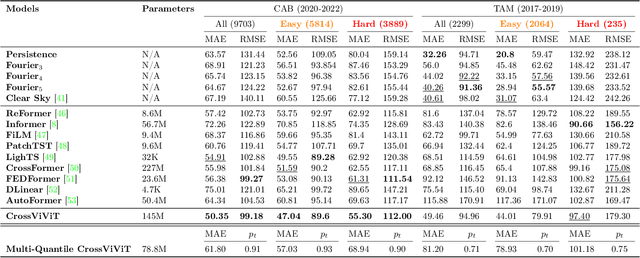
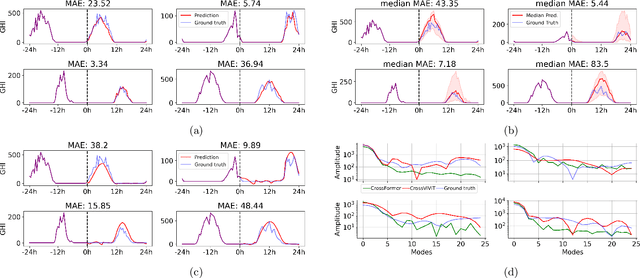
Solar power harbors immense potential in mitigating climate change by substantially reducing CO$_{2}$ emissions. Nonetheless, the inherent variability of solar irradiance poses a significant challenge for seamlessly integrating solar power into the electrical grid. While the majority of prior research has centered on employing purely time series-based methodologies for solar forecasting, only a limited number of studies have taken into account factors such as cloud cover or the surrounding physical context. In this paper, we put forth a deep learning architecture designed to harness spatio-temporal context using satellite data, to attain highly accurate \textit{day-ahead} time-series forecasting for any given station, with a particular emphasis on forecasting Global Horizontal Irradiance (GHI). We also suggest a methodology to extract a distribution for each time step prediction, which can serve as a very valuable measure of uncertainty attached to the forecast. When evaluating models, we propose a testing scheme in which we separate particularly difficult examples from easy ones, in order to capture the model performances in crucial situations, which in the case of this study are the days suffering from varying cloudy conditions. Furthermore, we present a new multi-modal dataset gathering satellite imagery over a large zone and time series for solar irradiance and other related physical variables from multiple geographically diverse solar stations. Our approach exhibits robust performance in solar irradiance forecasting, including zero-shot generalization tests at unobserved solar stations, and holds great promise in promoting the effective integration of solar power into the grid.
pTSE: A Multi-model Ensemble Method for Probabilistic Time Series Forecasting
May 16, 2023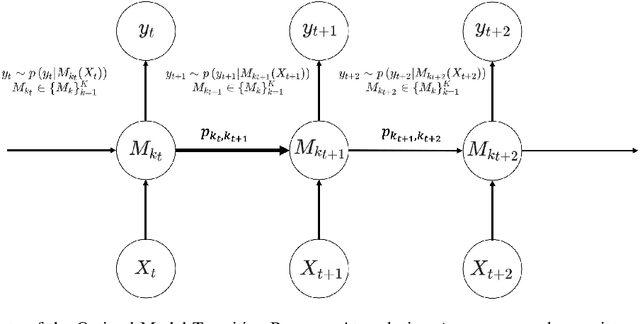
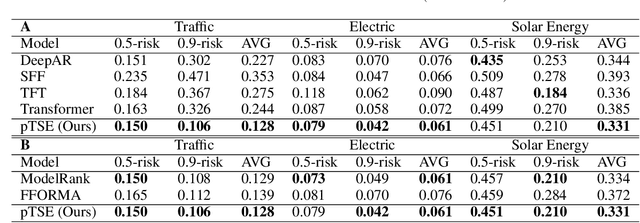
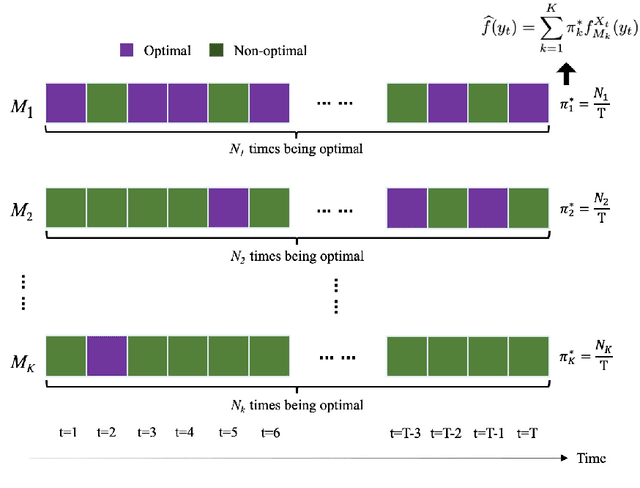
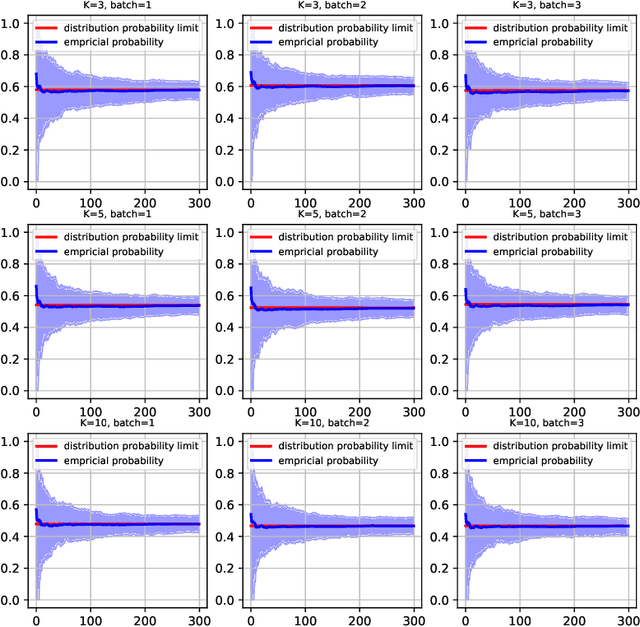
Various probabilistic time series forecasting models have sprung up and shown remarkably good performance. However, the choice of model highly relies on the characteristics of the input time series and the fixed distribution that the model is based on. Due to the fact that the probability distributions cannot be averaged over different models straightforwardly, the current time series model ensemble methods cannot be directly applied to improve the robustness and accuracy of forecasting. To address this issue, we propose pTSE, a multi-model distribution ensemble method for probabilistic forecasting based on Hidden Markov Model (HMM). pTSE only takes off-the-shelf outputs from member models without requiring further information about each model. Besides, we provide a complete theoretical analysis of pTSE to prove that the empirical distribution of time series subject to an HMM will converge to the stationary distribution almost surely. Experiments on benchmarks show the superiority of pTSE overall member models and competitive ensemble methods.
Taylorformer: Probabilistic Predictions for Time Series and other Processes
May 30, 2023We propose the Taylorformer for time series and other random processes. Its two key components are: 1) the LocalTaylor wrapper to learn how and when to use Taylor series-based approximations for predictions, and 2) the MHA-X attention block which makes predictions in a way inspired by how Gaussian Processes' mean predictions are linear smoothings of contextual data. Taylorformer outperforms the state-of-the-art on several forecasting datasets, including electricity, oil temperatures and exchange rates with at least 14% improvement in MSE on all tasks, and better likelihood on 5/6 classic Neural Process tasks such as meta-learning 1D functions. Taylorformer combines desirable features from the Neural Process (uncertainty-aware predictions and consistency) and forecasting (predictive accuracy) literature, two previously distinct bodies.