 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Large-scale AUV-based Visual Seafloor Mapping
Aug 11, 2023

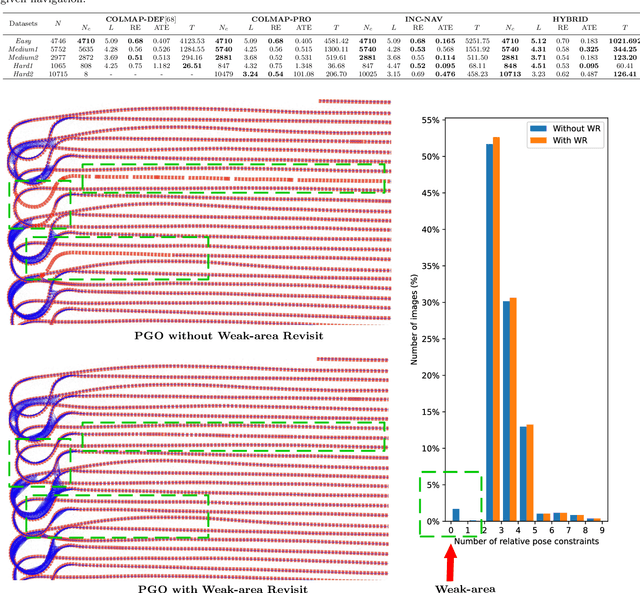
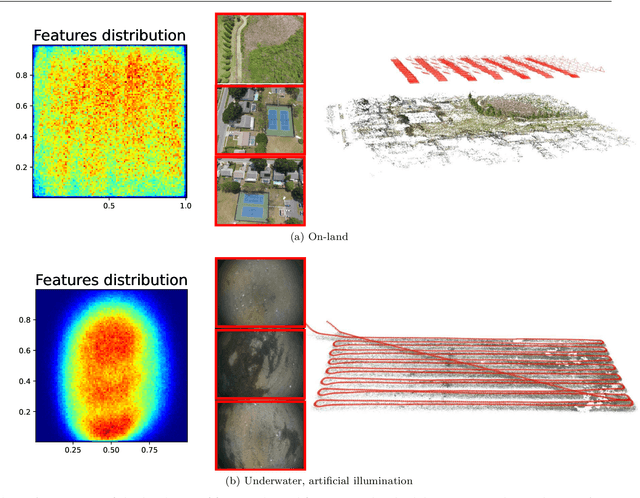
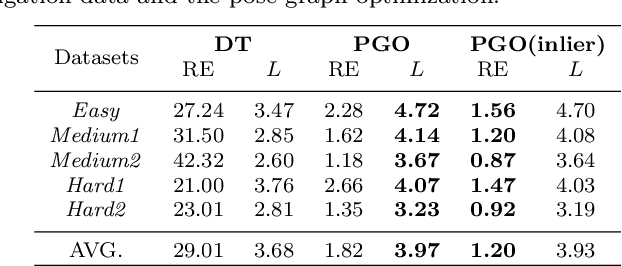
Driven by the increasing number of marine data science applications, there is a growing interest in surveying and exploring the vast, uncharted terrain of the deep sea with robotic platforms. Despite impressive results achieved by many on-land visual mapping algorithms in the past decades, transferring these methods from land to the deep sea remains a challenge due to harsh environmental conditions. Typically, deep-sea exploration involves the use of autonomous underwater vehicles (AUVs) equipped with high-resolution cameras and artificial illumination systems. However, images obtained in this manner often suffer from heterogeneous illumination and quality degradation due to attenuation and scattering, on top of refraction of light rays. All of this together often lets on-land SLAM approaches fail underwater or makes Structure-from-Motion approaches drift or omit difficult images, resulting in gaps, jumps or weakly registered areas. In this work, we present a system that incorporates recent developments in underwater imaging and visual mapping to facilitate automated robotic 3D reconstruction of hectares of seafloor. Our approach is efficient in that it detects and reconsiders difficult, weakly registered areas, to avoid omitting images and to make better use of limited dive time; on the other hand it is computationally efficient; leveraging a hybrid approach combining benefits from SLAM and Structure-from-Motion that runs much faster than incremental reconstructions while achieving at least on-par performance. The proposed system has been extensively tested and evaluated during several research cruises, demonstrating its robustness and practicality in real-world conditions.
A Brain-Computer Interface Augmented Reality Framework with Auto-Adaptive SSVEP Recognition
Aug 11, 2023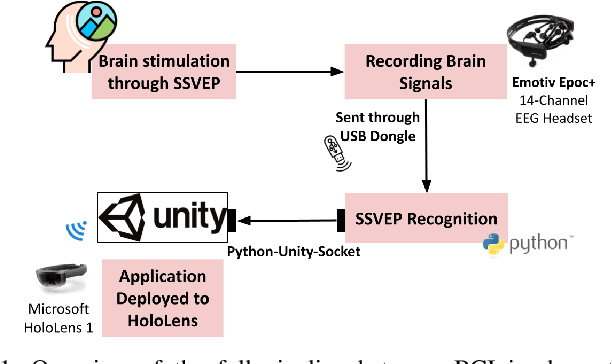
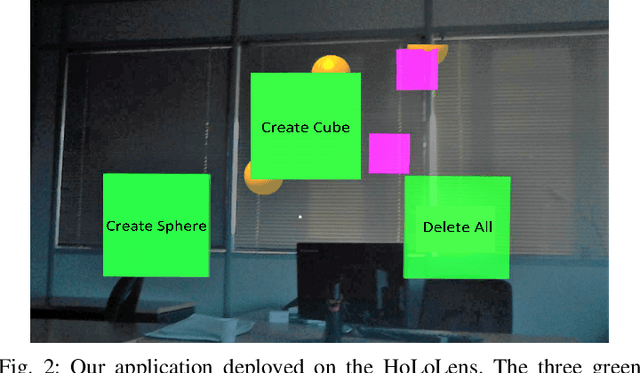

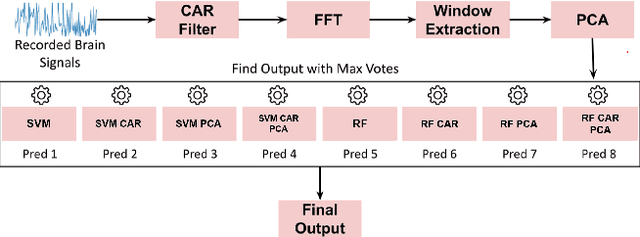
Brain-Computer Interface (BCI) initially gained attention for developing applications that aid physically impaired individuals. Recently, the idea of integrating BCI with Augmented Reality (AR) emerged, which uses BCI not only to enhance the quality of life for individuals with disabilities but also to develop mainstream applications for healthy users. One commonly used BCI signal pattern is the Steady-state Visually-evoked Potential (SSVEP), which captures the brain's response to flickering visual stimuli. SSVEP-based BCI-AR applications enable users to express their needs/wants by simply looking at corresponding command options. However, individuals are different in brain signals and thus require per-subject SSVEP recognition. Moreover, muscle movements and eye blinks interfere with brain signals, and thus subjects are required to remain still during BCI experiments, which limits AR engagement. In this paper, we (1) propose a simple adaptive ensemble classification system that handles the inter-subject variability, (2) present a simple BCI-AR framework that supports the development of a wide range of SSVEP-based BCI-AR applications, and (3) evaluate the performance of our ensemble algorithm in an SSVEP-based BCI-AR application with head rotations which has demonstrated robustness to the movement interference. Our testing on multiple subjects achieved a mean accuracy of 80\% on a PC and 77\% using the HoloLens AR headset, both of which surpass previous studies that incorporate individual classifiers and head movements. In addition, our visual stimulation time is 5 seconds which is relatively short. The statistically significant results show that our ensemble classification approach outperforms individual classifiers in SSVEP-based BCIs.
Inference-time Re-ranker Relevance Feedback for Neural Information Retrieval
May 19, 2023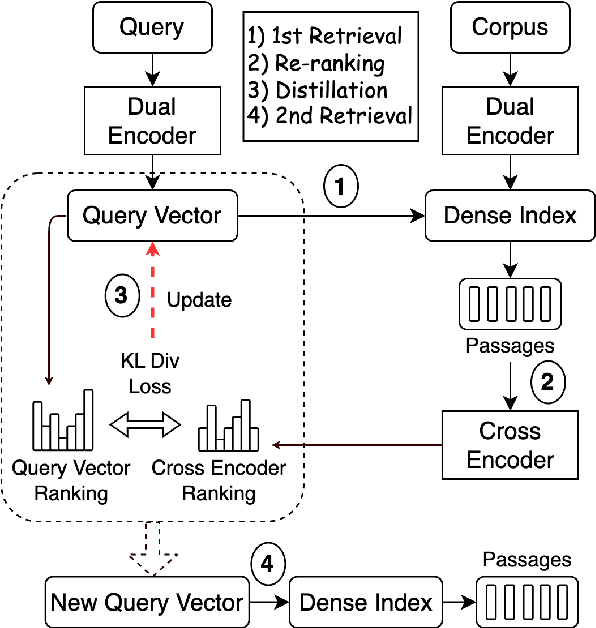
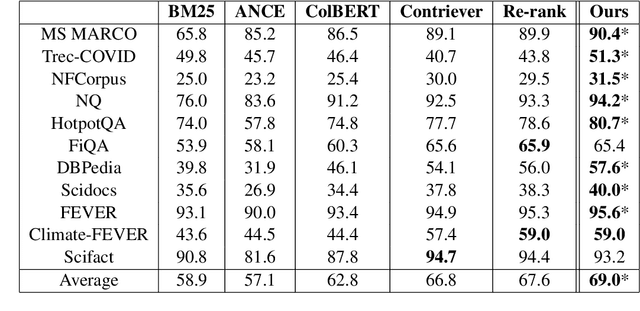
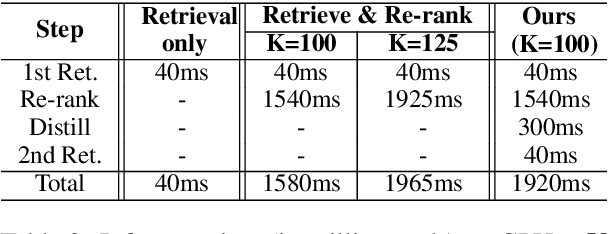
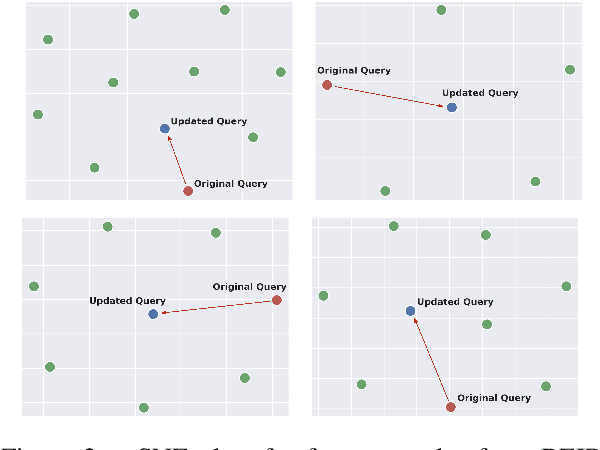
Neural information retrieval often adopts a retrieve-and-rerank framework: a bi-encoder network first retrieves K (e.g., 100) candidates that are then re-ranked using a more powerful cross-encoder model to rank the better candidates higher. The re-ranker generally produces better candidate scores than the retriever, but is limited to seeing only the top K retrieved candidates, thus providing no improvements in retrieval performance as measured by Recall@K. In this work, we leverage the re-ranker to also improve retrieval by providing inference-time relevance feedback to the retriever. Concretely, we update the retriever's query representation for a test instance using a lightweight inference-time distillation of the re-ranker's prediction for that instance. The distillation loss is designed to bring the retriever's candidate scores closer to those of the re-ranker. A second retrieval step is then performed with the updated query vector. We empirically show that our approach, which can serve arbitrary retrieve-and-rerank pipelines, significantly improves retrieval recall in multiple domains, languages, and modalities.
zkDL: Efficient Zero-Knowledge Proofs of Deep Learning Training
Jul 30, 2023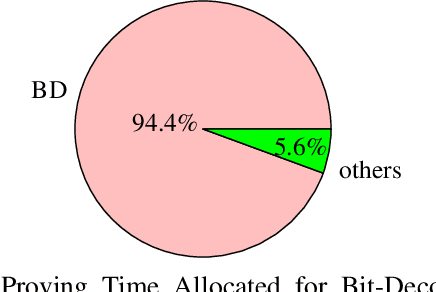

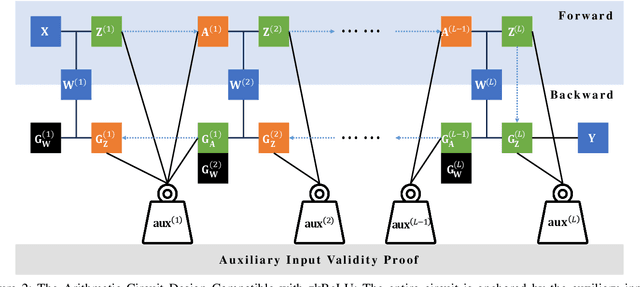
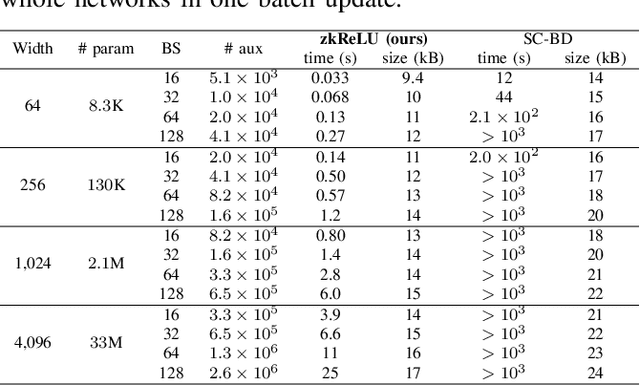
The recent advancements in deep learning have brought about significant changes in various aspects of people's lives. Meanwhile, these rapid developments have raised concerns about the legitimacy of the training process of deep networks. However, to protect the intellectual properties of untrusted AI developers, directly examining the training process by accessing the model parameters and training data by verifiers is often prohibited. In response to this challenge, we present zkDL, an efficient zero-knowledge proof of deep learning training. At the core of zkDL is zkReLU, a specialized zero-knowledge proof protocol with optimized proving time and proof size for the ReLU activation function, a major obstacle in verifiable training due to its non-arithmetic nature. To integrate zkReLU into the proof system for the entire training process, we devise a novel construction of an arithmetic circuit from neural networks. By leveraging the abundant parallel computation resources, this construction reduces proving time and proof sizes by a factor of the network depth. As a result, zkDL enables the generation of complete and sound proofs, taking less than a minute with a size of less than 20 kB per training step, for a 16-layer neural network with 200M parameters, while ensuring the privacy of data and model parameters.
Diagnosis, Feedback, Adaptation: A Human-in-the-Loop Framework for Test-Time Policy Adaptation
Jul 12, 2023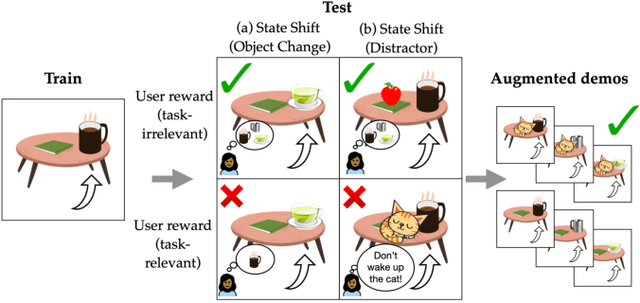
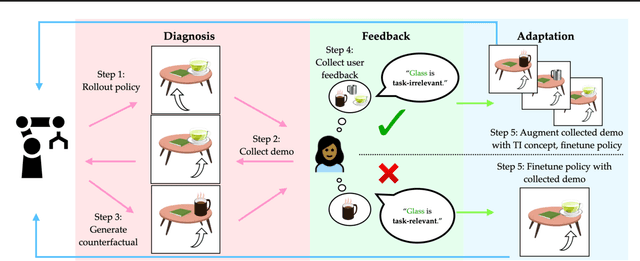
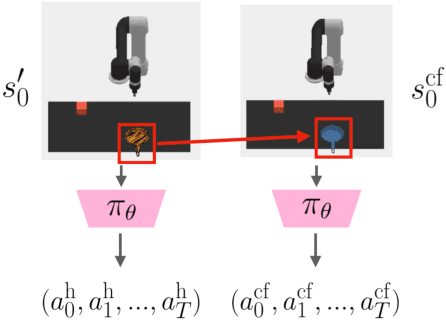

Policies often fail due to distribution shift -- changes in the state and reward that occur when a policy is deployed in new environments. Data augmentation can increase robustness by making the model invariant to task-irrelevant changes in the agent's observation. However, designers don't know which concepts are irrelevant a priori, especially when different end users have different preferences about how the task is performed. We propose an interactive framework to leverage feedback directly from the user to identify personalized task-irrelevant concepts. Our key idea is to generate counterfactual demonstrations that allow users to quickly identify possible task-relevant and irrelevant concepts. The knowledge of task-irrelevant concepts is then used to perform data augmentation and thus obtain a policy adapted to personalized user objectives. We present experiments validating our framework on discrete and continuous control tasks with real human users. Our method (1) enables users to better understand agent failure, (2) reduces the number of demonstrations required for fine-tuning, and (3) aligns the agent to individual user task preferences.
CrystalGPT: Enhancing system-to-system transferability in crystallization prediction and control using time-series-transformers
May 31, 2023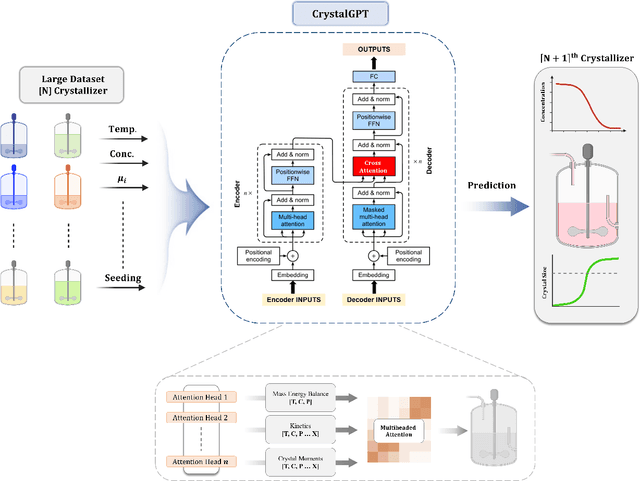
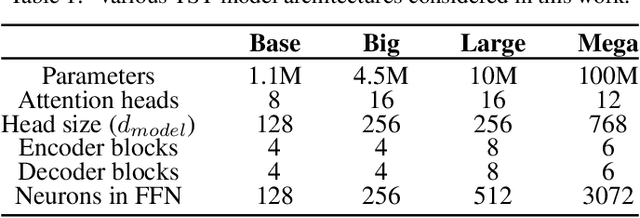
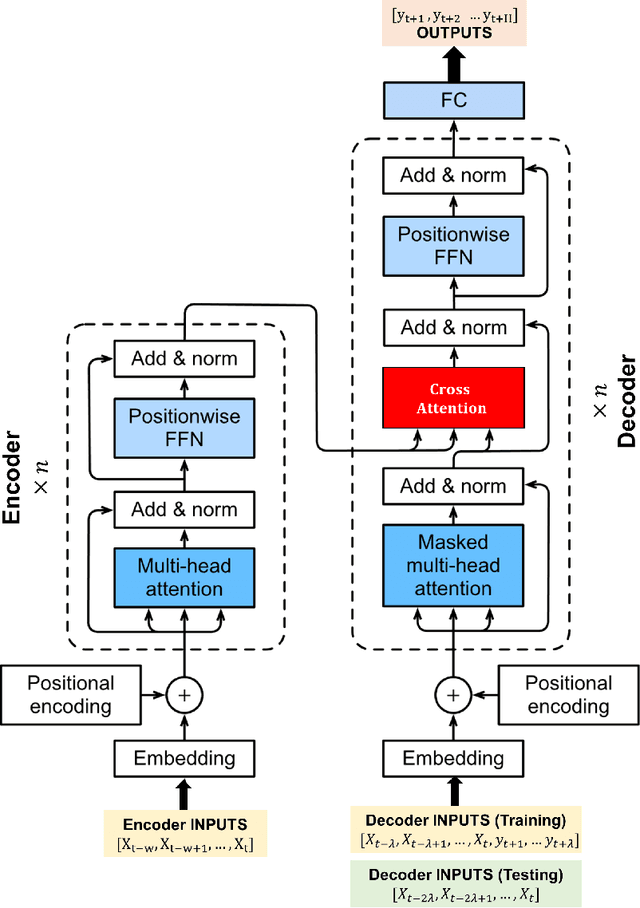
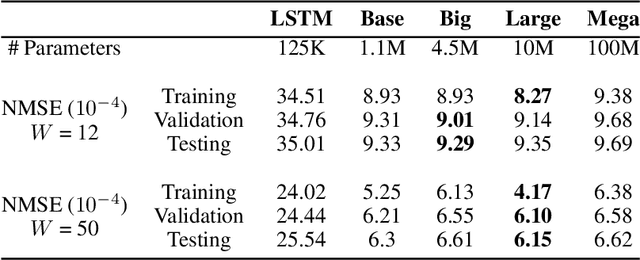
For prediction and real-time control tasks, machine-learning (ML)-based digital twins are frequently employed. However, while these models are typically accurate, they are custom-designed for individual systems, making system-to-system (S2S) transferability difficult. This occurs even when substantial similarities exist in the process dynamics across different chemical systems. To address this challenge, we developed a novel time-series-transformer (TST) framework that exploits the powerful transfer learning capabilities inherent in transformer algorithms. This was demonstrated using readily available process data obtained from different crystallizers operating under various operational scenarios. Using this extensive dataset, we trained a TST model (CrystalGPT) to exhibit remarkable S2S transferability not only across all pre-established systems, but also to an unencountered system. CrystalGPT achieved a cumulative error across all systems, which is eight times superior to that of existing ML models. Additionally, we coupled CrystalGPT with a predictive controller to reduce the variance in setpoint tracking to just 1%.
Likelihood-ratio-based confidence intervals for neural networks
Aug 04, 2023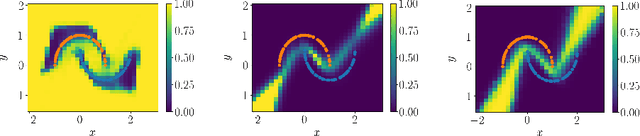
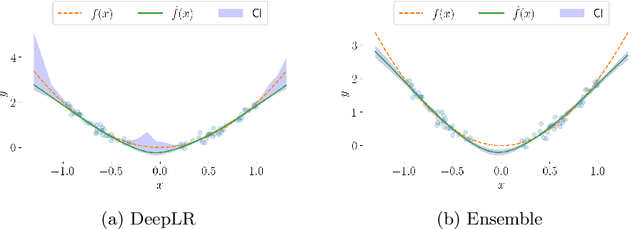
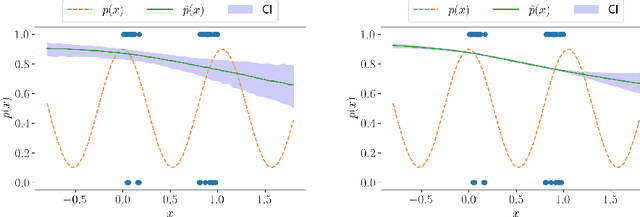
This paper introduces a first implementation of a novel likelihood-ratio-based approach for constructing confidence intervals for neural networks. Our method, called DeepLR, offers several qualitative advantages: most notably, the ability to construct asymmetric intervals that expand in regions with a limited amount of data, and the inherent incorporation of factors such as the amount of training time, network architecture, and regularization techniques. While acknowledging that the current implementation of the method is prohibitively expensive for many deep-learning applications, the high cost may already be justified in specific fields like medical predictions or astrophysics, where a reliable uncertainty estimate for a single prediction is essential. This work highlights the significant potential of a likelihood-ratio-based uncertainty estimate and establishes a promising avenue for future research.
Deployment of Leader-Follower Automated Vehicle Systems for Smart Work Zone Applications with a Queuing-based Traffic Assignment Approach
Jul 23, 2023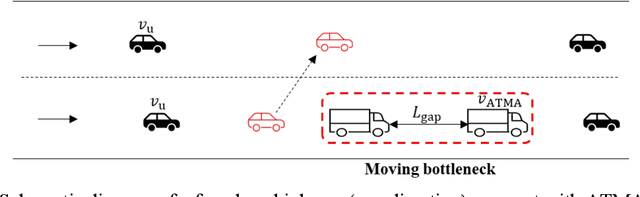

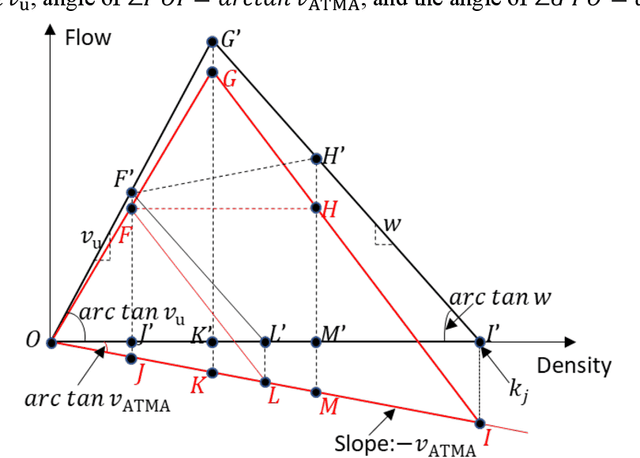
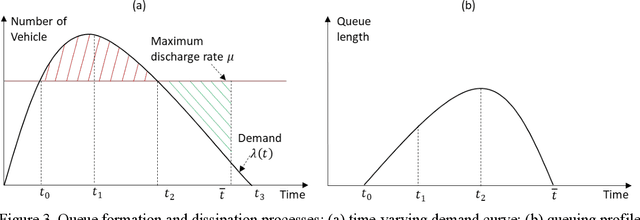
The emerging technology of the Autonomous Truck Mounted Attenuator (ATMA), a leader-follower style vehicle system, utilizes connected and automated vehicle capabilities to enhance safety during transportation infrastructure maintenance in work zones. However, the speed difference between ATMA vehicles and general vehicles creates a moving bottleneck that reduces capacity and increases queue length, resulting in additional delays. The different routes taken by ATMA cause diverse patterns of time-varying capacity drops, which may affect the user equilibrium traffic assignment and lead to different system costs. This manuscript focuses on optimizing the routing for ATMA vehicles in a network to minimize the system cost associated with the slow-moving operation. To achieve this, a queuing-based traffic assignment approach is proposed to identify the system cost caused by the ATMA system. A queuing-based time-dependent (QBTD) travel time function, considering capacity drop, is introduced and applied in the static user equilibrium traffic assignment problem, with a result of adding dynamic characteristics. Subsequently, we formulate the queuing-based traffic assignment problem and solve it using a modified path-based algorithm. The methodology is validated using a small-size and a large-size network and compared with two benchmark models to analyze the benefit of capacity drop modeling and QBTD travel time function. Furthermore, the approach is applied to quantify the impact of different routes on the traffic system and identify an optimal route for ATMA vehicles performing maintenance work. Finally, sensitivity analysis is conducted to explore how the impact changes with variations in traffic demand and capacity reduction.
Multi-task learning for classification, segmentation, reconstruction, and detection on chest CT scans
Aug 02, 2023Lung cancer and covid-19 have one of the highest morbidity and mortality rates in the world. For physicians, the identification of lesions is difficult in the early stages of the disease and time-consuming. Therefore, multi-task learning is an approach to extracting important features, such as lesions, from small amounts of medical data because it learns to generalize better. We propose a novel multi-task framework for classification, segmentation, reconstruction, and detection. To the best of our knowledge, we are the first ones who added detection to the multi-task solution. Additionally, we checked the possibility of using two different backbones and different loss functions in the segmentation task.
ReLU and Addition-based Gated RNN
Aug 10, 2023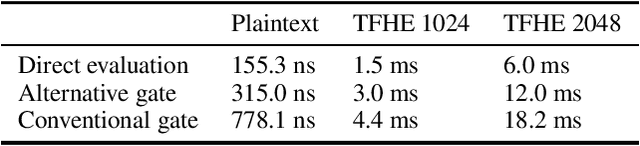
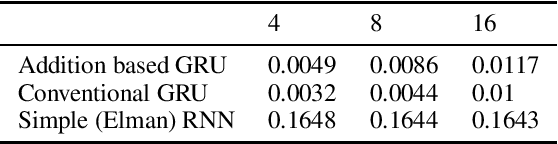
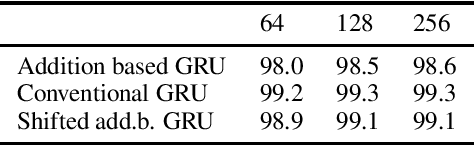

We replace the multiplication and sigmoid function of the conventional recurrent gate with addition and ReLU activation. This mechanism is designed to maintain long-term memory for sequence processing but at a reduced computational cost, thereby opening up for more efficient execution or larger models on restricted hardware. Recurrent Neural Networks (RNNs) with gating mechanisms such as LSTM and GRU have been widely successful in learning from sequential data due to their ability to capture long-term dependencies. Conventionally, the update based on current inputs and the previous state history is each multiplied with dynamic weights and combined to compute the next state. However, multiplication can be computationally expensive, especially for certain hardware architectures or alternative arithmetic systems such as homomorphic encryption. It is demonstrated that the novel gating mechanism can capture long-term dependencies for a standard synthetic sequence learning task while significantly reducing computational costs such that execution time is reduced by half on CPU and by one-third under encryption. Experimental results on handwritten text recognition tasks furthermore show that the proposed architecture can be trained to achieve comparable accuracy to conventional GRU and LSTM baselines. The gating mechanism introduced in this paper may enable privacy-preserving AI applications operating under homomorphic encryption by avoiding the multiplication of encrypted variables. It can also support quantization in (unencrypted) plaintext applications, with the potential for substantial performance gains since the addition-based formulation can avoid the expansion to double precision often required for multiplication.