 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DiffGuard: Semantic Mismatch-Guided Out-of-Distribution Detection using Pre-trained Diffusion Models
Aug 16, 2023
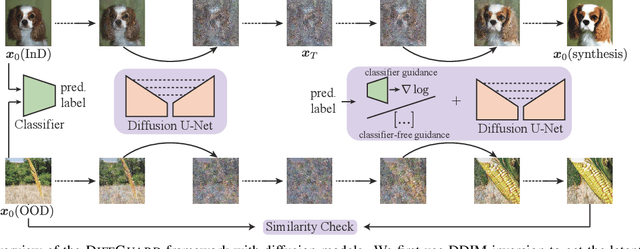
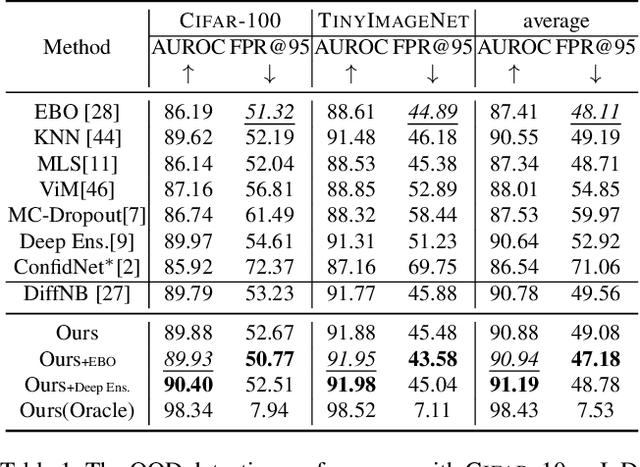

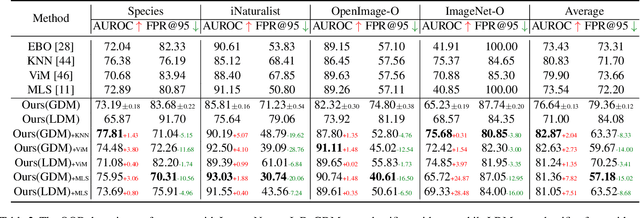
Given a classifier, the inherent property of semantic Out-of-Distribution (OOD) samples is that their contents differ from all legal classes in terms of semantics, namely semantic mismatch. There is a recent work that directly applies it to OOD detection, which employs a conditional Generative Adversarial Network (cGAN) to enlarge semantic mismatch in the image space. While achieving remarkable OOD detection performance on small datasets, it is not applicable to ImageNet-scale datasets due to the difficulty in training cGANs with both input images and labels as conditions. As diffusion models are much easier to train and amenable to various conditions compared to cGANs, in this work, we propose to directly use pre-trained diffusion models for semantic mismatch-guided OOD detection, named DiffGuard. Specifically, given an OOD input image and the predicted label from the classifier, we try to enlarge the semantic difference between the reconstructed OOD image under these conditions and the original input image. We also present several test-time techniques to further strengthen such differences. Experimental results show that DiffGuard is effective on both Cifar-10 and hard cases of the large-scale ImageNet, and it can be easily combined with existing OOD detection techniques to achieve state-of-the-art OOD detection results.
Sensitivity-Aware Mixed-Precision Quantization and Width Optimization of Deep Neural Networks Through Cluster-Based Tree-Structured Parzen Estimation
Aug 16, 2023As the complexity and computational demands of deep learning models rise, the need for effective optimization methods for neural network designs becomes paramount. This work introduces an innovative search mechanism for automatically selecting the best bit-width and layer-width for individual neural network layers. This leads to a marked enhancement in deep neural network efficiency. The search domain is strategically reduced by leveraging Hessian-based pruning, ensuring the removal of non-crucial parameters. Subsequently, we detail the development of surrogate models for favorable and unfavorable outcomes by employing a cluster-based tree-structured Parzen estimator. This strategy allows for a streamlined exploration of architectural possibilities and swift pinpointing of top-performing designs. Through rigorous testing on well-known datasets, our method proves its distinct advantage over existing methods. Compared to leading compression strategies, our approach records an impressive 20% decrease in model size without compromising accuracy. Additionally, our method boasts a 12x reduction in search time relative to the best search-focused strategies currently available. As a result, our proposed method represents a leap forward in neural network design optimization, paving the way for quick model design and implementation in settings with limited resources, thereby propelling the potential of scalable deep learning solutions.
Expressivity of Spiking Neural Networks
Aug 16, 2023This article studies the expressive power of spiking neural networks where information is encoded in the firing time of neurons. The implementation of spiking neural networks on neuromorphic hardware presents a promising choice for future energy-efficient AI applications. However, there exist very few results that compare the computational power of spiking neurons to arbitrary threshold circuits and sigmoidal neurons. Additionally, it has also been shown that a network of spiking neurons is capable of approximating any continuous function. By using the Spike Response Model as a mathematical model of a spiking neuron and assuming a linear response function, we prove that the mapping generated by a network of spiking neurons is continuous piecewise linear. We also show that a spiking neural network can emulate the output of any multi-layer (ReLU) neural network. Furthermore, we show that the maximum number of linear regions generated by a spiking neuron scales exponentially with respect to the input dimension, a characteristic that distinguishes it significantly from an artificial (ReLU) neuron. Our results further extend the understanding of the approximation properties of spiking neural networks and open up new avenues where spiking neural networks can be deployed instead of artificial neural networks without any performance loss.
DMFC-GraspNet: Differentiable Multi-Fingered Robotic Grasp Generation in Cluttered Scenes
Aug 16, 2023Robotic grasping is a fundamental skill required for object manipulation in robotics. Multi-fingered robotic hands, which mimic the structure of the human hand, can potentially perform complex object manipulation. Nevertheless, current techniques for multi-fingered robotic grasping frequently predict only a single grasp for each inference time, limiting computational efficiency and their versatility, i.e. unimodal grasp distribution. This paper proposes a differentiable multi-fingered grasp generation network (DMFC-GraspNet) with three main contributions to address this challenge. Firstly, a novel neural grasp planner is proposed, which predicts a new grasp representation to enable versatile and dense grasp predictions. Secondly, a scene creation and label mapping method is developed for dense labeling of multi-fingered robotic hands, which allows a dense association of ground truth grasps. Thirdly, we propose to train DMFC-GraspNet end-to-end using using a forward-backward automatic differentiation approach with both a supervised loss and a differentiable collision loss and a generalized Q 1 grasp metric loss. The proposed approach is evaluated using the Shadow Dexterous Hand on Mujoco simulation and ablated by different choices of loss functions. The results demonstrate the effectiveness of the proposed approach in predicting versatile and dense grasps, and in advancing the field of multi-fingered robotic grasping.
Computer vision-enriched discrete choice models, with an application to residential location choice
Aug 16, 2023Visual imagery is indispensable to many multi-attribute decision situations. Examples of such decision situations in travel behaviour research include residential location choices, vehicle choices, tourist destination choices, and various safety-related choices. However, current discrete choice models cannot handle image data and thus cannot incorporate information embedded in images into their representations of choice behaviour. This gap between discrete choice models' capabilities and the real-world behaviour it seeks to model leads to incomplete and, possibly, misleading outcomes. To solve this gap, this study proposes "Computer Vision-enriched Discrete Choice Models" (CV-DCMs). CV-DCMs can handle choice tasks involving numeric attributes and images by integrating computer vision and traditional discrete choice models. Moreover, because CV-DCMs are grounded in random utility maximisation principles, they maintain the solid behavioural foundation of traditional discrete choice models. We demonstrate the proposed CV-DCM by applying it to data obtained through a novel stated choice experiment involving residential location choices. In this experiment, respondents faced choice tasks with trade-offs between commute time, monthly housing cost and street-level conditions, presented using images. As such, this research contributes to the growing body of literature in the travel behaviour field that seeks to integrate discrete choice modelling and machine learning.
Proprioceptive Learning with Soft Polyhedral Networks
Aug 16, 2023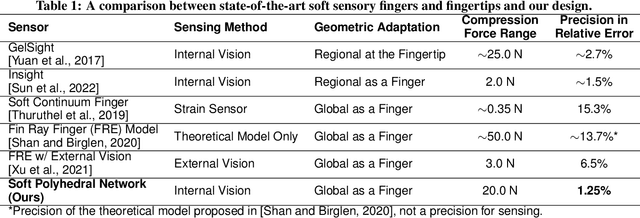
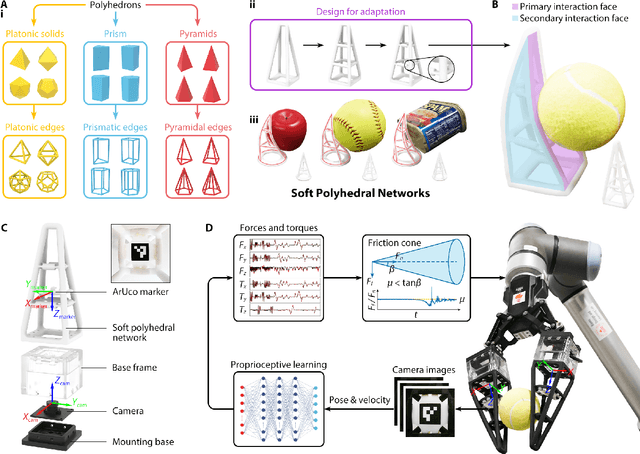


Proprioception is the "sixth sense" that detects limb postures with motor neurons. It requires a natural integration between the musculoskeletal systems and sensory receptors, which is challenging among modern robots that aim for lightweight, adaptive, and sensitive designs at a low cost. Here, we present the Soft Polyhedral Network with an embedded vision for physical interactions, capable of adaptive kinesthesia and viscoelastic proprioception by learning kinetic features. This design enables passive adaptations to omni-directional interactions, visually captured by a miniature high-speed motion tracking system embedded inside for proprioceptive learning. The results show that the soft network can infer real-time 6D forces and torques with accuracies of 0.25/0.24/0.35 N and 0.025/0.034/0.006 Nm in dynamic interactions. We also incorporate viscoelasticity in proprioception during static adaptation by adding a creep and relaxation modifier to refine the predicted results. The proposed soft network combines simplicity in design, omni-adaptation, and proprioceptive sensing with high accuracy, making it a versatile solution for robotics at a low cost with more than 1 million use cycles for tasks such as sensitive and competitive grasping, and touch-based geometry reconstruction. This study offers new insights into vision-based proprioception for soft robots in adaptive grasping, soft manipulation, and human-robot interaction.
Modelling the Spread of COVID-19 in Indoor Spaces using Automated Probabilistic Planning
Aug 16, 2023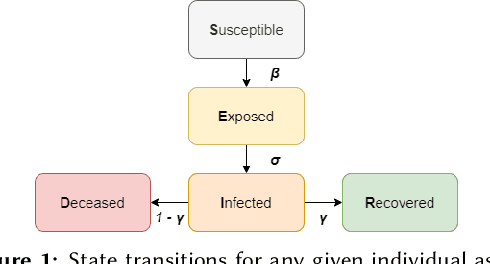
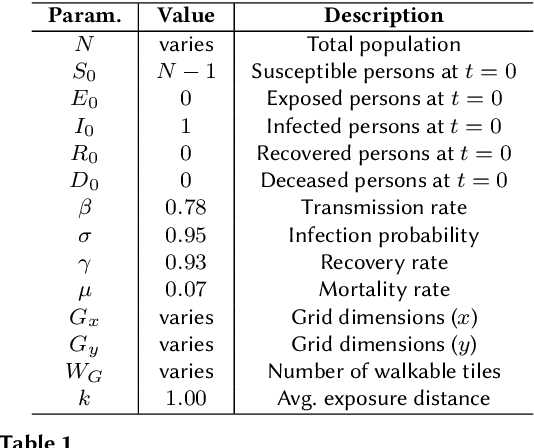
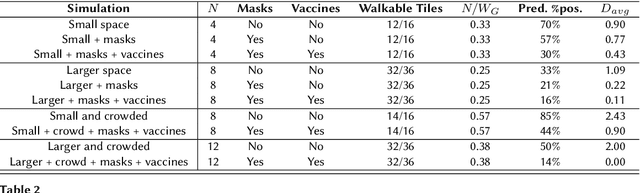
The coronavirus disease 2019 (COVID-19) pandemic has been ongoing for around 3 years, and has infected over 750 million people and caused over 6 million deaths worldwide at the time of writing. Throughout the pandemic, several strategies for controlling the spread of the disease have been debated by healthcare professionals, government authorities, and international bodies. To anticipate the potential impact of the disease, and to simulate the effectiveness of different mitigation strategies, a robust model of disease spread is needed. In this work, we explore a novel approach based on probabilistic planning and dynamic graph analysis to model the spread of COVID-19 in indoor spaces. We endow the planner with means to control the spread of the disease through non-pharmaceutical interventions (NPIs) such as mandating masks and vaccines, and we compare the impact of crowds and capacity limits on the spread of COVID-19 in these settings. We demonstrate that the use of probabilistic planning is effective in predicting the amount of infections that are likely to occur in shared spaces, and that automated planners have the potential to design competent interventions to limit the spread of the disease. Our code is fully open-source and is available at: https://github.com/mharmanani/prob-planning-covid19 .
SongDriver2: Real-time Emotion-based Music Arrangement with Soft Transition
May 14, 2023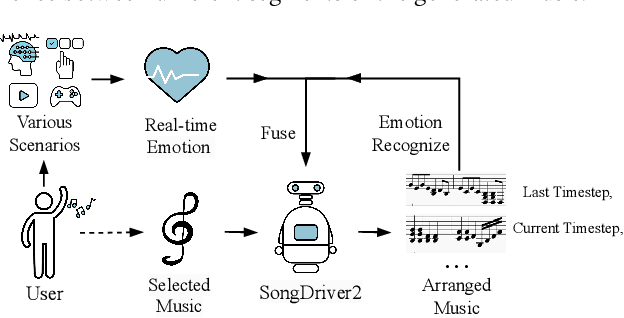
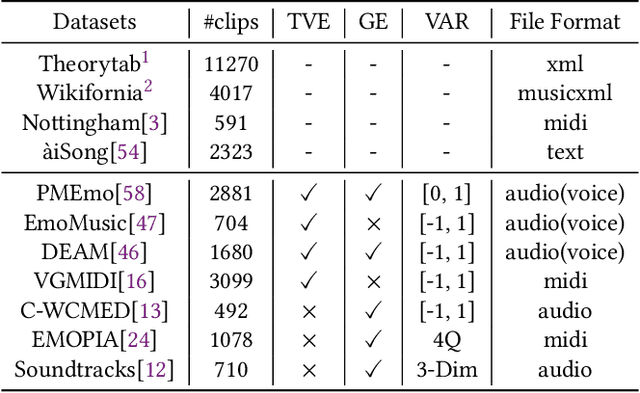
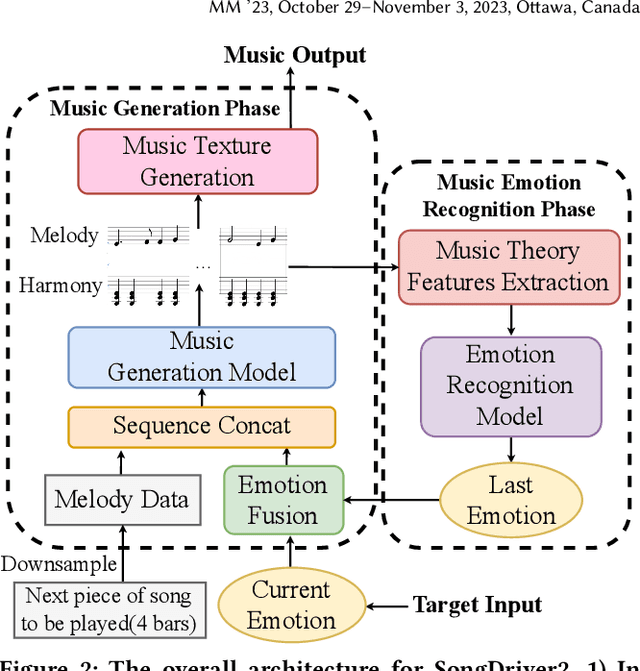

Real-time emotion-based music arrangement, which aims to transform a given music piece into another one that evokes specific emotional resonance with the user in real-time, holds significant application value in various scenarios, e.g., music therapy, video game soundtracks, and movie scores. However, balancing emotion real-time fit with soft emotion transition is a challenge due to the fine-grained and mutable nature of the target emotion. Existing studies mainly focus on achieving emotion real-time fit, while the issue of soft transition remains understudied, affecting the overall emotional coherence of the music. In this paper, we propose SongDriver2 to address this balance. Specifically, we first recognize the last timestep's music emotion and then fuse it with the current timestep's target input emotion. The fused emotion then serves as the guidance for SongDriver2 to generate the upcoming music based on the input melody data. To adjust music similarity and emotion real-time fit flexibly, we downsample the original melody and feed it into the generation model. Furthermore, we design four music theory features to leverage domain knowledge to enhance emotion information and employ semi-supervised learning to mitigate the subjective bias introduced by manual dataset annotation. According to the evaluation results, SongDriver2 surpasses the state-of-the-art methods in both objective and subjective metrics. These results demonstrate that SongDriver2 achieves real-time fit and soft transitions simultaneously, enhancing the coherence of the generated music.
A Fast Fourier Convolutional Deep Neural Network For Accurate and Explainable Discrimination Of Wheat Yellow Rust And Nitrogen Deficiency From Sentinel-2 Time-Series Data
Jun 29, 2023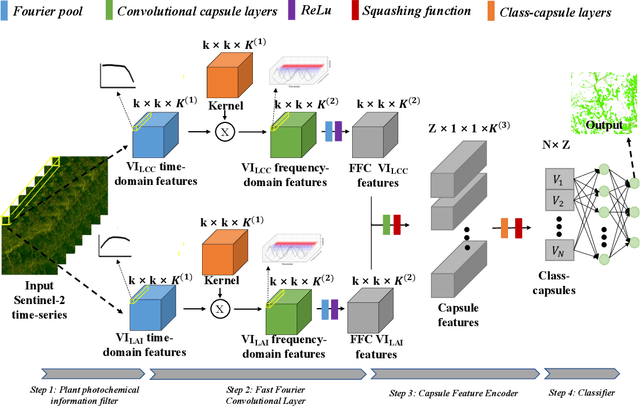

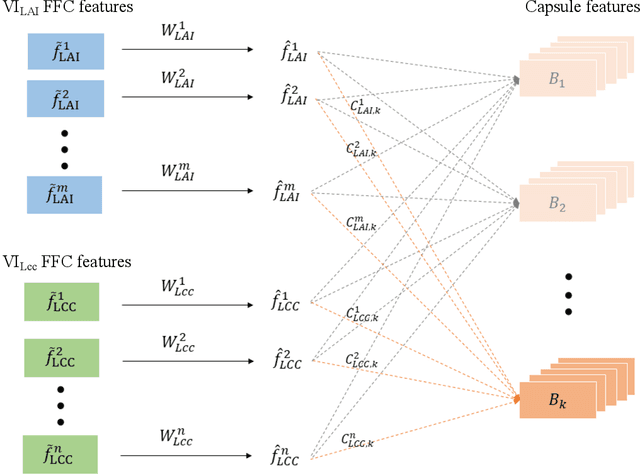
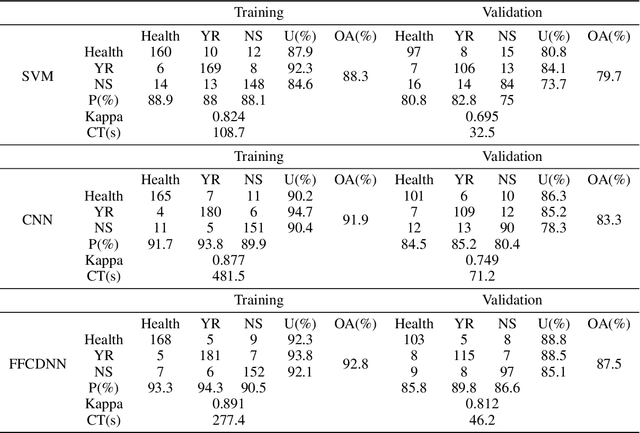
Accurate and timely detection of plant stress is essential for yield protection, allowing better-targeted intervention strategies. Recent advances in remote sensing and deep learning have shown great potential for rapid non-invasive detection of plant stress in a fully automated and reproducible manner. However, the existing models always face several challenges: 1) computational inefficiency and the misclassifications between the different stresses with similar symptoms; and 2) the poor interpretability of the host-stress interaction. In this work, we propose a novel fast Fourier Convolutional Neural Network (FFDNN) for accurate and explainable detection of two plant stresses with similar symptoms (i.e. Wheat Yellow Rust And Nitrogen Deficiency). Specifically, unlike the existing CNN models, the main components of the proposed model include: 1) a fast Fourier convolutional block, a newly fast Fourier transformation kernel as the basic perception unit, to substitute the traditional convolutional kernel to capture both local and global responses to plant stress in various time-scale and improve computing efficiency with reduced learning parameters in Fourier domain; 2) Capsule Feature Encoder to encapsulate the extracted features into a series of vector features to represent part-to-whole relationship with the hierarchical structure of the host-stress interactions of the specific stress. In addition, in order to alleviate over-fitting, a photochemical vegetation indices-based filter is placed as pre-processing operator to remove the non-photochemical noises from the input Sentinel-2 time series.
Colonoscopy Coverage Revisited: Identifying Scanning Gaps in Real-Time
May 17, 2023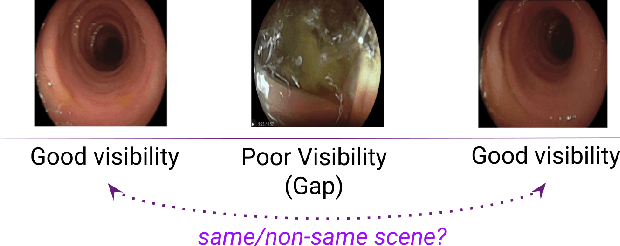

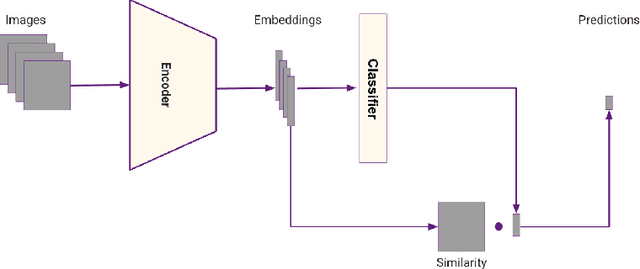
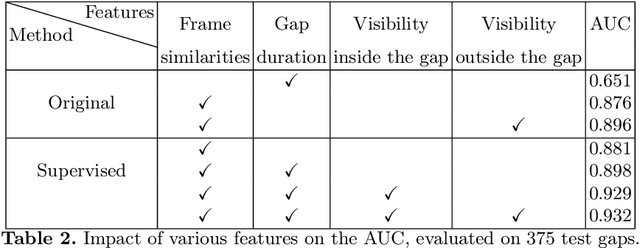
Colonoscopy is the most widely used medical technique for preventing Colorectal Cancer, by detecting and removing polyps before they become malignant. Recent studies show that around one quarter of the existing polyps are routinely missed. While some of these do appear in the endoscopist's field of view, others are missed due to a partial coverage of the colon. The task of detecting and marking unseen regions of the colon has been addressed in recent work, where the common approach is based on dense 3D reconstruction, which proves to be challenging due to lack of 3D ground truth and periods with poor visual content. In this paper we propose a novel and complementary method to detect deficient local coverage in real-time for video segments where a reliable 3D reconstruction is impossible. Our method aims to identify skips along the colon caused by a drifted position of the endoscope during poor visibility time intervals. The proposed solution consists of two phases. During the first, time segments with good visibility of the colon and gaps between them are identified. During the second phase, a trained model operates on each gap, answering the question: Do you observe the same scene before and after the gap? If the answer is negative, the endoscopist is alerted and can be directed to the appropriate area in real-time. The second phase model is trained using a contrastive loss based on auto-generated examples. Our method evaluation on a dataset of 250 procedures annotated by trained physicians provides sensitivity of 0.75 with specificity of 0.9.