 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sensing-Communication-Computing-Control Closed Loop for Unmanned Space Exploration
Aug 07, 2023
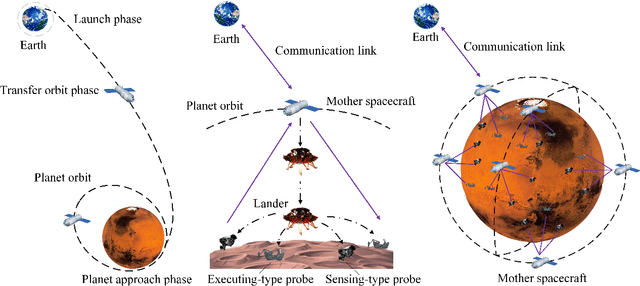
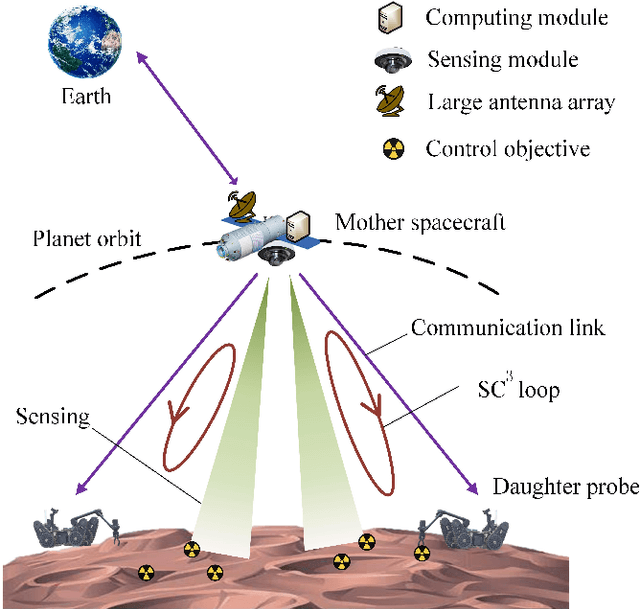
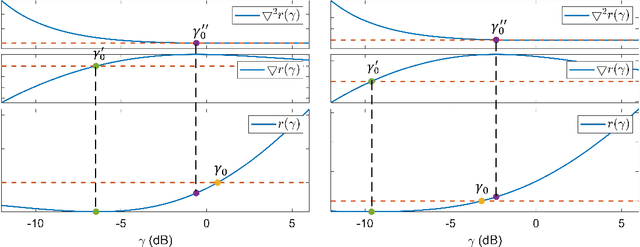
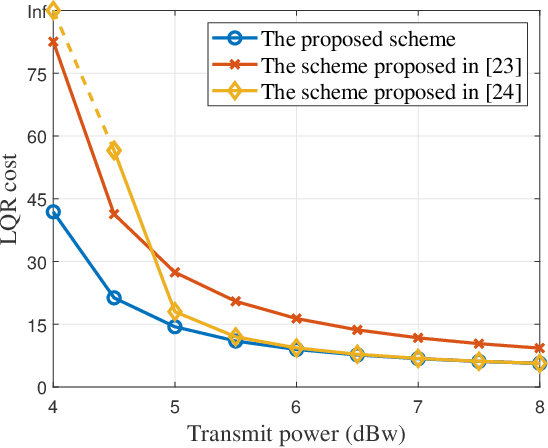
With a growing interest in outer space, space robots have become a focus of exploration. To coordinate them for unmanned space exploration, we propose to use the "mother-daughter structure". In this setup, the mother spacecraft orbits the planet, while daughter probes are distributed across the surface. The mother spacecraft senses the environment, computes control commands and distributes them to daughter probes to take actions. They synergistically form sensing-communication-computing-control ($\mathbf{SC^3}$) loops, which are indivisible. We thereby optimize the spacecraft-probe downlink within $\mathbf{SC^3}$ loops to minimize the sum linear quadratic regulator (LQR) cost. The optimization variables are block length and transmit power. On account of the cycle time constraint, the spacecraft-probe downlink operates in the finite block length (FBL) regime. To solve the nonlinear mixed-integer problem, we first identify the optimal block length and then transform the power allocation problem into a tractable convex one. Additionally, we derive the approximate closed-form solutions for the proposed scheme and also for the max-sum rate scheme and max-min rate scheme. On this basis, we reveal their different power allocation principles. Moreover, we find that for time-insensitive control tasks, the proposed scheme demonstrates equivalence to the max-min rate scheme. These findings are verified through simulations.
Make Transformer Great Again for Time Series Forecasting: Channel Aligned Robust Dual Transformer
May 20, 2023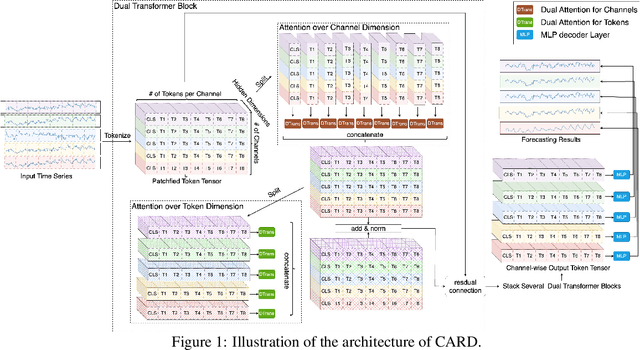
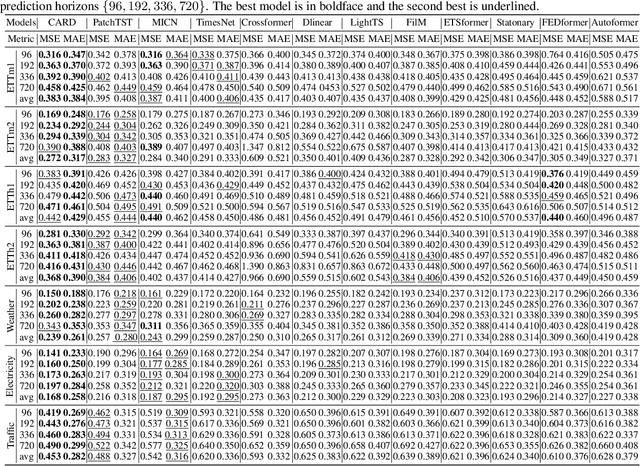
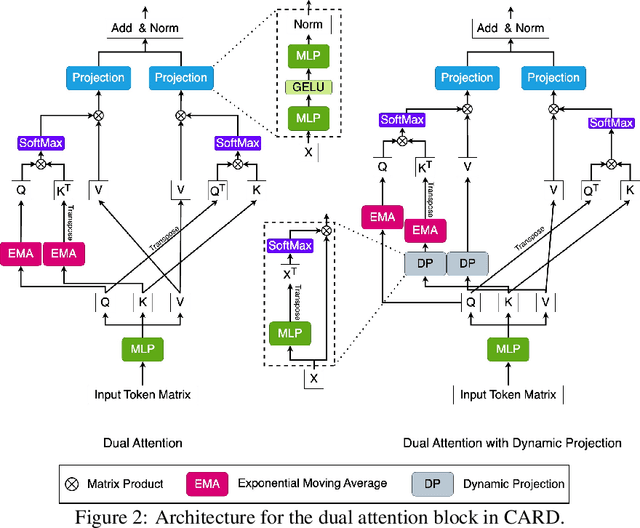
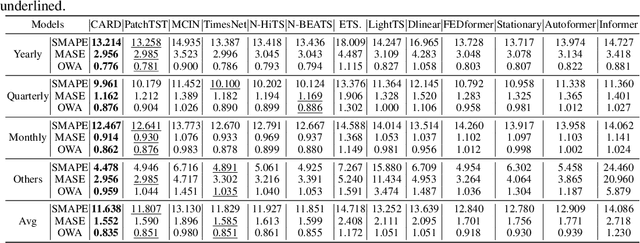
Recent studies have demonstrated the great power of deep learning methods, particularly Transformer and MLP, for time series forecasting. Despite its success in NLP and CV, many studies found that Transformer is less effective than MLP for time series forecasting. In this work, we design a special Transformer, i.e., channel-aligned robust dual Transformer (CARD for short), that addresses key shortcomings of Transformer in time series forecasting. First, CARD introduces a dual Transformer structure that allows it to capture both temporal correlations among signals and dynamical dependence among multiple variables over time. Second, we introduce a robust loss function for time series forecasting to alleviate the potential overfitting issue. This new loss function weights the importance of forecasting over a finite horizon based on prediction uncertainties. Our evaluation of multiple long-term and short-term forecasting datasets demonstrates that CARD significantly outperforms state-of-the-art time series forecasting methods, including both Transformer and MLP-based models.
Martian time-series unraveled: A multi-scale nested approach with factorial variational autoencoders
May 25, 2023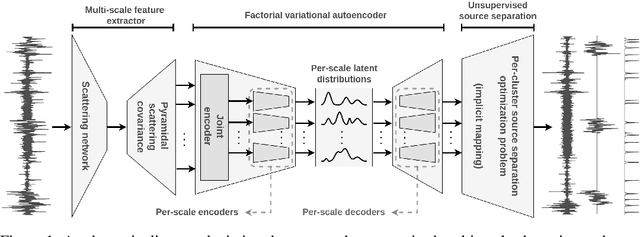
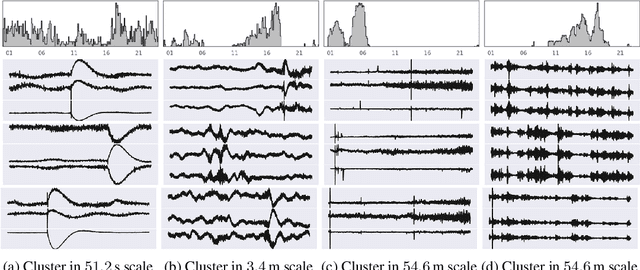
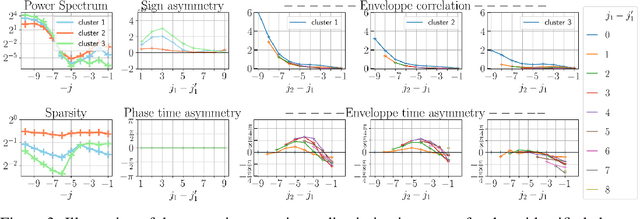
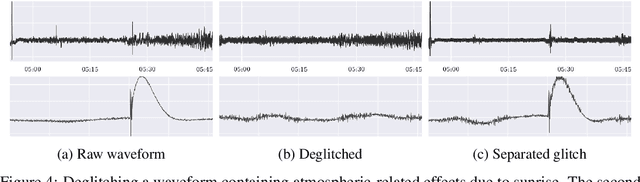
Unsupervised source separation involves unraveling an unknown set of source signals recorded through a mixing operator, with limited prior knowledge about the sources, and only access to a dataset of signal mixtures. This problem is inherently ill-posed and is further challenged by the variety of time-scales exhibited by sources in time series data. Existing methods typically rely on a preselected window size that limits their capacity to handle multi-scale sources. To address this issue, instead of operating in the time domain, we propose an unsupervised multi-scale clustering and source separation framework by leveraging wavelet scattering covariances that provide a low-dimensional representation of stochastic processes, capable of distinguishing between different non-Gaussian stochastic processes. Nested within this representation space, we develop a factorial Gaussian-mixture variational autoencoder that is trained to (1) probabilistically cluster sources at different time-scales and (2) independently sample scattering covariance representations associated with each cluster. Using samples from each cluster as prior information, we formulate source separation as an optimization problem in the wavelet scattering covariance representation space, resulting in separated sources in the time domain. When applied to seismic data recorded during the NASA InSight mission on Mars, our multi-scale nested approach proves to be a powerful tool for discriminating between sources varying greatly in time-scale, e.g., minute-long transient one-sided pulses (known as ``glitches'') and structured ambient noises resulting from atmospheric activities that typically last for tens of minutes. These results provide an opportunity to conduct further investigations into the isolated sources related to atmospheric-surface interactions, thermal relaxations, and other complex phenomena.
Multi-Visual-Inertial System: Analysis,Calibration and Estimation
Aug 10, 2023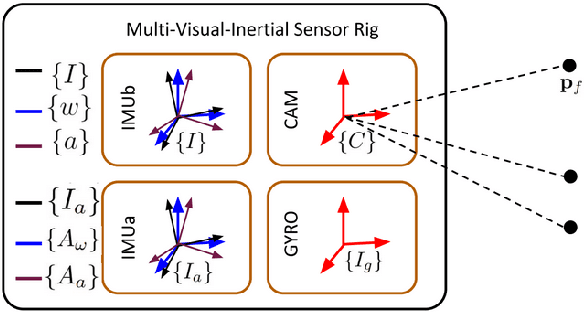



In this paper, we study state estimation of multi-visual-inertial systems (MVIS) and develop sensor fusion algorithms to optimally fuse an arbitrary number of asynchronous inertial measurement units (IMUs) or gyroscopes and global and(or) rolling shutter cameras. We are especially interested in the full calibration of the associated visual-inertial sensors, including the IMU or camera intrinsics and the IMU-IMU(or camera) spatiotemporal extrinsics as well as the image readout time of rolling-shutter cameras (if used). To this end, we develop a new analytic combined IMU integration with intrinsics-termed ACI3-to preintegrate IMU measurements, which is leveraged to fuse auxiliary IMUs and(or) gyroscopes alongside a base IMU. We model the multi-inertial measurements to include all the necessary inertial intrinsic and IMU-IMU spatiotemporal extrinsic parameters, while leveraging IMU-IMU rigid-body constraints to eliminate the necessity of auxiliary inertial poses and thus reducing computational complexity. By performing observability analysis of MVIS, we prove that the standard four unobservable directions remain - no matter how many inertial sensors are used, and also identify, for the first time, degenerate motions for IMU-IMU spatiotemporal extrinsics and auxiliary inertial intrinsics. In addition to the extensive simulations that validate our analysis and algorithms, we have built our own MVIS sensor rig and collected over 25 real-world datasets to experimentally verify the proposed calibration against the state-of-the-art calibration method such as Kalibr. We show that the proposed MVIS calibration is able to achieve competing accuracy with improved convergence and repeatability, which is open sourced to better benefit the community.
Intrinsically Motivated Hierarchical Policy Learning in Multi-objective Markov Decision Processes
Aug 18, 2023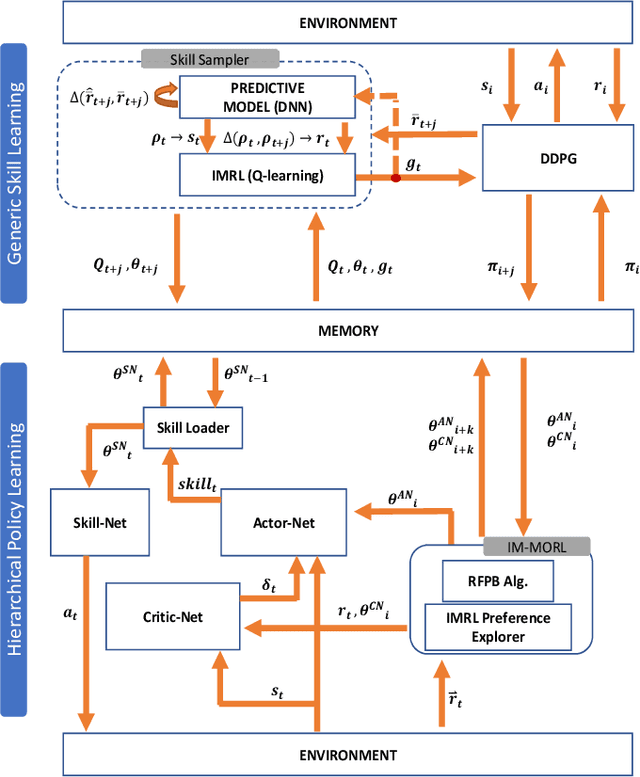
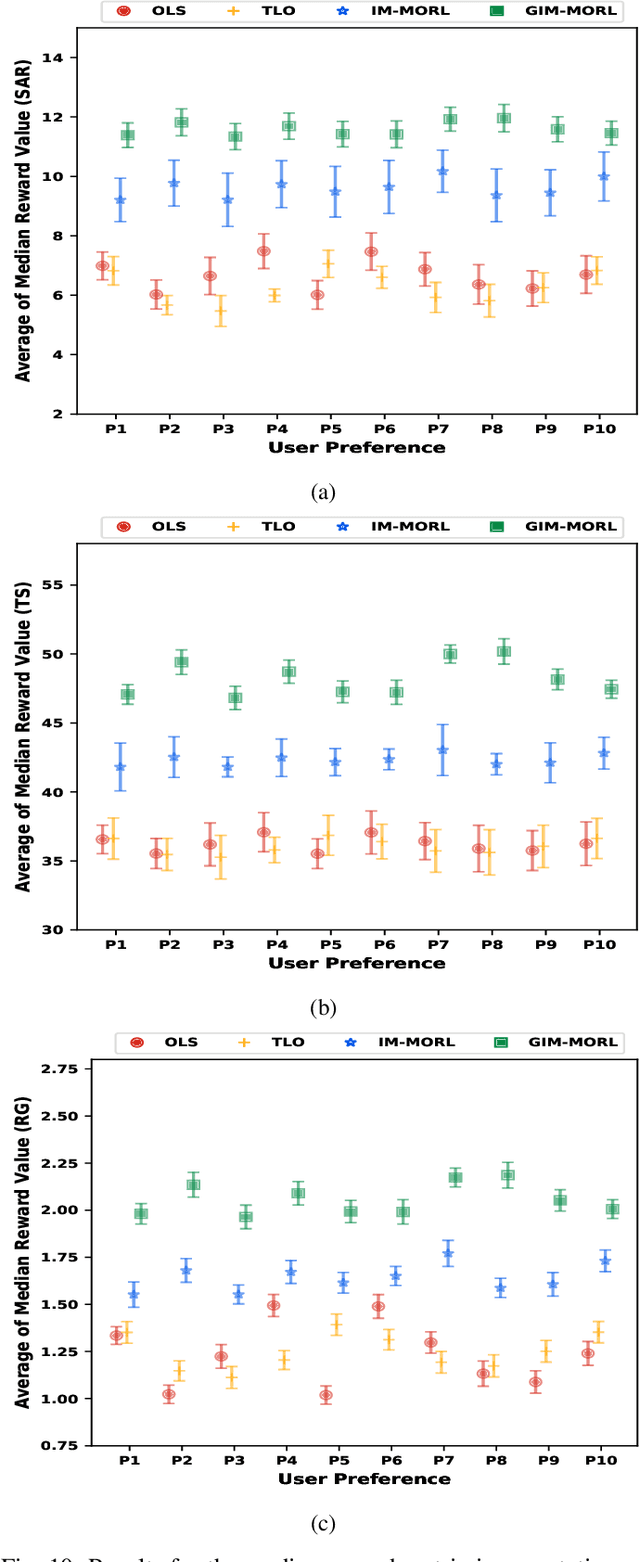

Multi-objective Markov decision processes are sequential decision-making problems that involve multiple conflicting reward functions that cannot be optimized simultaneously without a compromise. This type of problems cannot be solved by a single optimal policy as in the conventional case. Alternatively, multi-objective reinforcement learning methods evolve a coverage set of optimal policies that can satisfy all possible preferences in solving the problem. However, many of these methods cannot generalize their coverage sets to work in non-stationary environments. In these environments, the parameters of the state transition and reward distribution vary over time. This limitation results in significant performance degradation for the evolved policy sets. In order to overcome this limitation, there is a need to learn a generic skill set that can bootstrap the evolution of the policy coverage set for each shift in the environment dynamics therefore, it can facilitate a continuous learning process. In this work, intrinsically motivated reinforcement learning has been successfully deployed to evolve generic skill sets for learning hierarchical policies to solve multi-objective Markov decision processes. We propose a novel dual-phase intrinsically motivated reinforcement learning method to address this limitation. In the first phase, a generic set of skills is learned. While in the second phase, this set is used to bootstrap policy coverage sets for each shift in the environment dynamics. We show experimentally that the proposed method significantly outperforms state-of-the-art multi-objective reinforcement methods in a dynamic robotics environment.
RLIPv2: Fast Scaling of Relational Language-Image Pre-training
Aug 18, 2023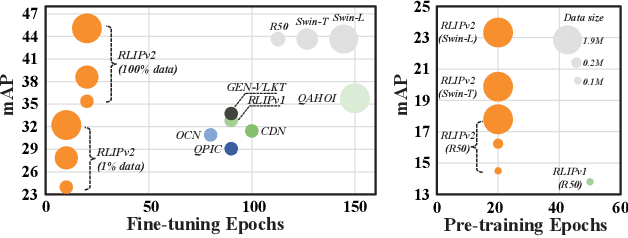
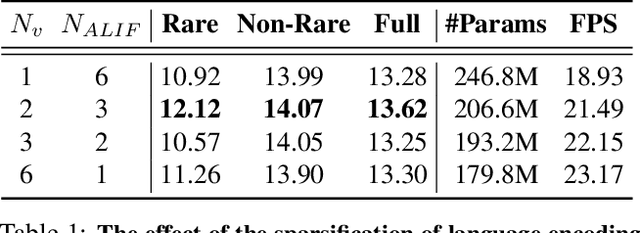
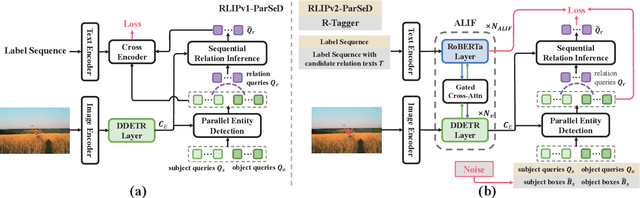
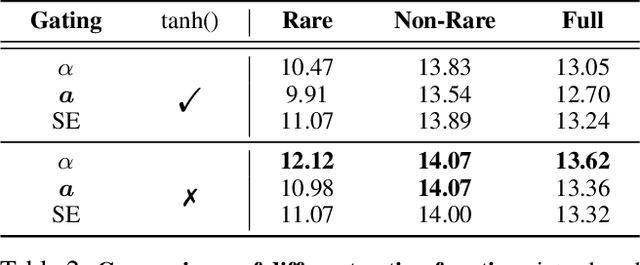
Relational Language-Image Pre-training (RLIP) aims to align vision representations with relational texts, thereby advancing the capability of relational reasoning in computer vision tasks. However, hindered by the slow convergence of RLIPv1 architecture and the limited availability of existing scene graph data, scaling RLIPv1 is challenging. In this paper, we propose RLIPv2, a fast converging model that enables the scaling of relational pre-training to large-scale pseudo-labelled scene graph data. To enable fast scaling, RLIPv2 introduces Asymmetric Language-Image Fusion (ALIF), a mechanism that facilitates earlier and deeper gated cross-modal fusion with sparsified language encoding layers. ALIF leads to comparable or better performance than RLIPv1 in a fraction of the time for pre-training and fine-tuning. To obtain scene graph data at scale, we extend object detection datasets with free-form relation labels by introducing a captioner (e.g., BLIP) and a designed Relation Tagger. The Relation Tagger assigns BLIP-generated relation texts to region pairs, thus enabling larger-scale relational pre-training. Through extensive experiments conducted on Human-Object Interaction Detection and Scene Graph Generation, RLIPv2 shows state-of-the-art performance on three benchmarks under fully-finetuning, few-shot and zero-shot settings. Notably, the largest RLIPv2 achieves 23.29mAP on HICO-DET without any fine-tuning, yields 32.22mAP with just 1% data and yields 45.09mAP with 100% data. Code and models are publicly available at https://github.com/JacobYuan7/RLIPv2.
Accelerated Bayesian imaging by relaxed proximal-point Langevin sampling
Aug 18, 2023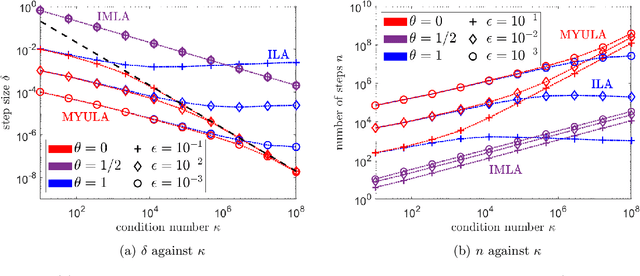

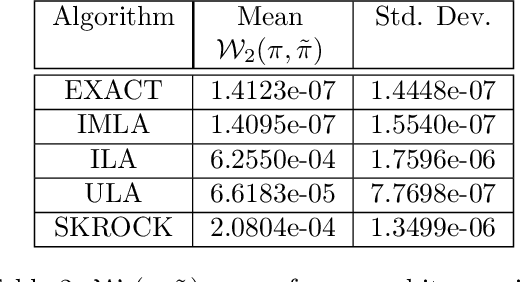
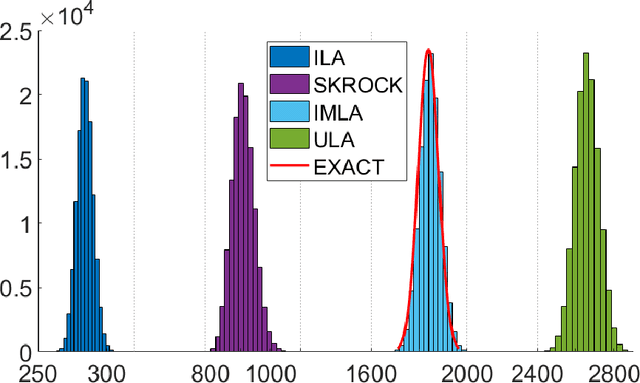
This paper presents a new accelerated proximal Markov chain Monte Carlo methodology to perform Bayesian inference in imaging inverse problems with an underlying convex geometry. The proposed strategy takes the form of a stochastic relaxed proximal-point iteration that admits two complementary interpretations. For models that are smooth or regularised by Moreau-Yosida smoothing, the algorithm is equivalent to an implicit midpoint discretisation of an overdamped Langevin diffusion targeting the posterior distribution of interest. This discretisation is asymptotically unbiased for Gaussian targets and shown to converge in an accelerated manner for any target that is $\kappa$-strongly log-concave (i.e., requiring in the order of $\sqrt{\kappa}$ iterations to converge, similarly to accelerated optimisation schemes), comparing favorably to [M. Pereyra, L. Vargas Mieles, K.C. Zygalakis, SIAM J. Imaging Sciences, 13, 2 (2020), pp. 905-935] which is only provably accelerated for Gaussian targets and has bias. For models that are not smooth, the algorithm is equivalent to a Leimkuhler-Matthews discretisation of a Langevin diffusion targeting a Moreau-Yosida approximation of the posterior distribution of interest, and hence achieves a significantly lower bias than conventional unadjusted Langevin strategies based on the Euler-Maruyama discretisation. For targets that are $\kappa$-strongly log-concave, the provided non-asymptotic convergence analysis also identifies the optimal time step which maximizes the convergence speed. The proposed methodology is demonstrated through a range of experiments related to image deconvolution with Gaussian and Poisson noise, with assumption-driven and data-driven convex priors.
STAR-RIS Aided MISO SWIPT-NOMA System with Energy Buffer: Performance Analysis and Optimization
Aug 18, 2023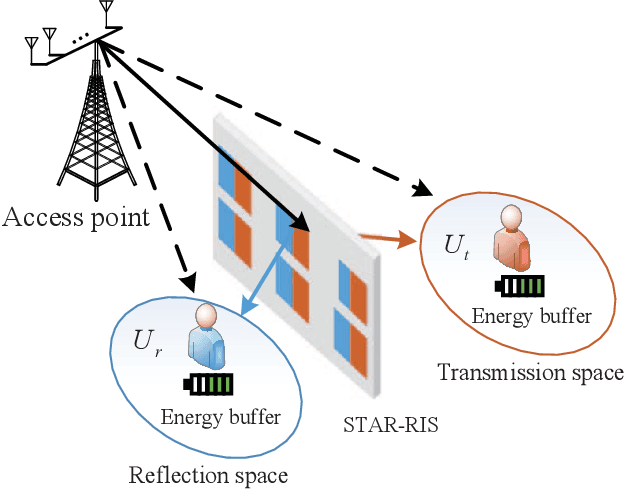
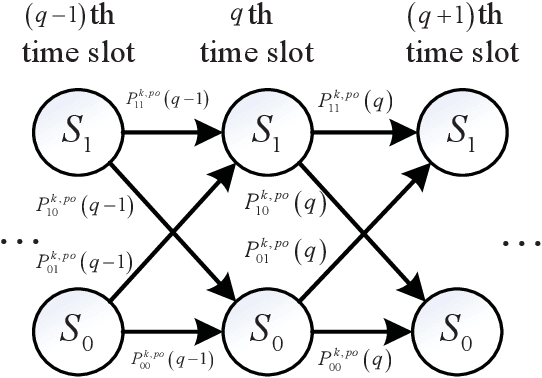
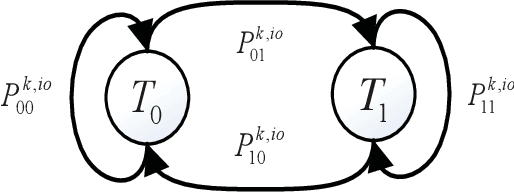
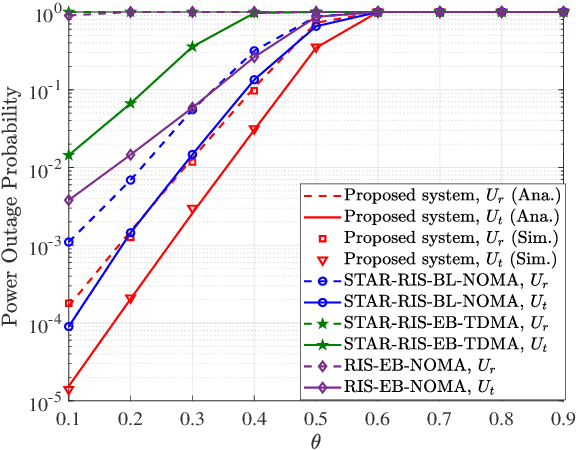
In this paper, we propose a simultaneous transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) and energy buffer aided multiple-input single-output (MISO) simultaneous wireless information and power transfer (SWIPT) non-orthogonal multiple access (NOMA) system, which consists of a STAR-RIS, an access point (AP), and reflection users and transmission users with energy buffers. In the proposed system, the multi-antenna AP can transmit information and energy to several single-antenna reflection and transmission users simultaneously in a NOMA fashion, where the power transfer and information transmission states of the users are modeled using Markov chains. The reflection and transmission users harvest and store the energy in energy buffers as additional power supplies. The power outage probability, information outage probability, sum throughput, and joint outage probability closed-form expressions of the proposed system are derived over Nakagami-m fading channels, which are validated via simulations. Results demonstrate that the proposed system achieves better performance in comparison to the STAR-RIS aided MISO SWIPT-NOMA buffer-less, conventional RIS and energy buffer aided MISO SWIPT-NOMA, and STAR-RIS and energy buffer aided MISO SWIPT-time-division multiple access (TDMA) systems. Furthermore, a particle swarm optimization based power allocation (PSO-PA) algorithm is designed to maximize the sum throughput with a constraint on the joint outage probability. Simulation results illustrate that the proposed PSO-PA algorithm can achieve an improved sum throughput performance of the proposed system.
EFX Allocations Exist for Binary Valuations
Aug 10, 2023We study the fair division problem and the existence of allocations satisfying the fairness criterion envy-freeness up to any item (EFX). The existence of EFX allocations is a major open problem in the fair division literature. We consider binary valuations where the marginal gain of the value by receiving an extra item is either $0$ or $1$. Babaioff et al. [2021] proved that EFX allocations always exist for binary and submodular valuations. In this paper, by using completely different techniques, we extend this existence result to general binary valuations that are not necessarily submodular, and we present a polynomial time algorithm for computing an EFX allocation.
Deep Learning-based surrogate models for parametrized PDEs: handling geometric variability through graph neural networks
Aug 03, 2023
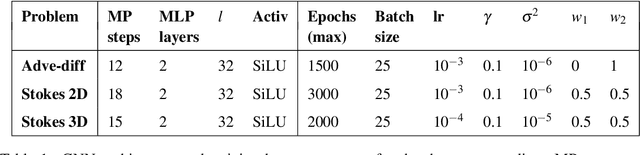
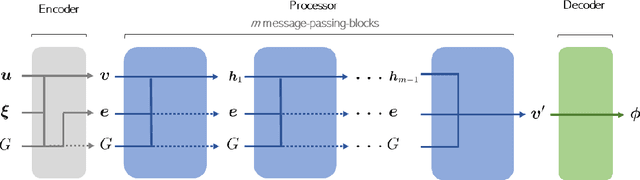
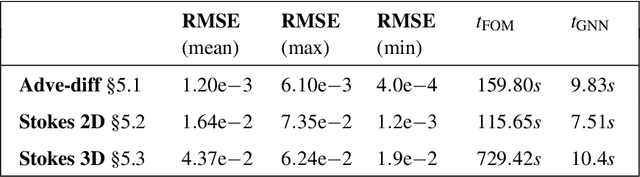
Mesh-based simulations play a key role when modeling complex physical systems that, in many disciplines across science and engineering, require the solution of parametrized time-dependent nonlinear partial differential equations (PDEs). In this context, full order models (FOMs), such as those relying on the finite element method, can reach high levels of accuracy, however often yielding intensive simulations to run. For this reason, surrogate models are developed to replace computationally expensive solvers with more efficient ones, which can strike favorable trade-offs between accuracy and efficiency. This work explores the potential usage of graph neural networks (GNNs) for the simulation of time-dependent PDEs in the presence of geometrical variability. In particular, we propose a systematic strategy to build surrogate models based on a data-driven time-stepping scheme where a GNN architecture is used to efficiently evolve the system. With respect to the majority of surrogate models, the proposed approach stands out for its ability of tackling problems with parameter dependent spatial domains, while simultaneously generalizing to different geometries and mesh resolutions. We assess the effectiveness of the proposed approach through a series of numerical experiments, involving both two- and three-dimensional problems, showing that GNNs can provide a valid alternative to traditional surrogate models in terms of computational efficiency and generalization to new scenarios. We also assess, from a numerical standpoint, the importance of using GNNs, rather than classical dense deep neural networks, for the proposed framework.