 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denoising
Aug 07, 2023
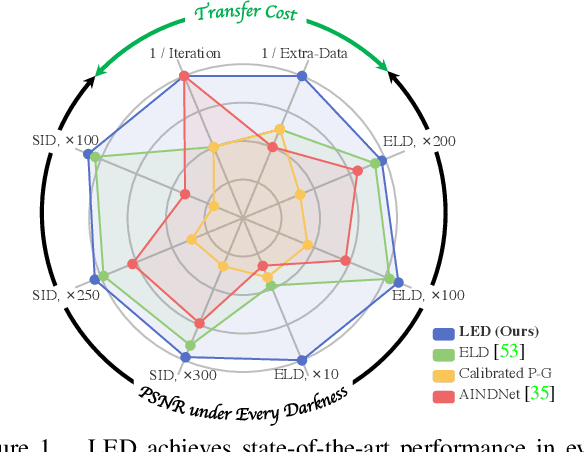
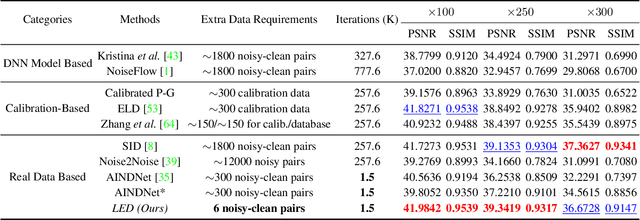
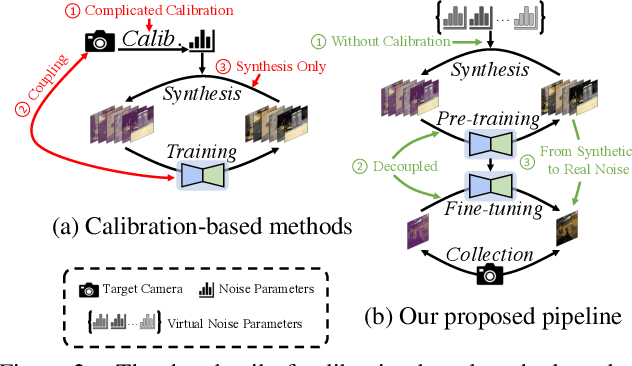
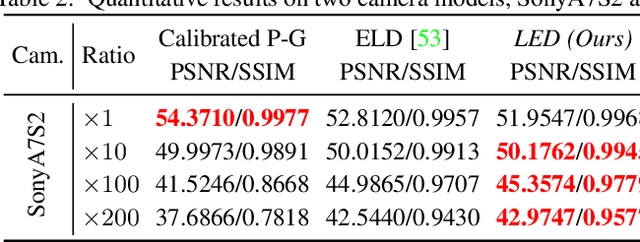
Calibration-based methods have dominated RAW image denoising under extremely low-light environments. However, these methods suffer from several main deficiencies: 1) the calibration procedure is laborious and time-consuming, 2) denoisers for different cameras are difficult to transfer, and 3) the discrepancy between synthetic noise and real noise is enlarged by high digital gain. To overcome the above shortcomings, we propose a calibration-free pipeline for Lighting Every Drakness (LED), regardless of the digital gain or camera sensor. Instead of calibrating the noise parameters and training repeatedly, our method could adapt to a target camera only with few-shot paired data and fine-tuning. In addition, well-designed structural modification during both stages alleviates the domain gap between synthetic and real noise without any extra computational cost. With 2 pairs for each additional digital gain (in total 6 pairs) and 0.5% iterations, our method achieves superior performance over other calibration-based methods. Our code is available at https://github.com/Srameo/LED .
TeraHAC: Hierarchical Agglomerative Clustering of Trillion-Edge Graphs
Aug 07, 2023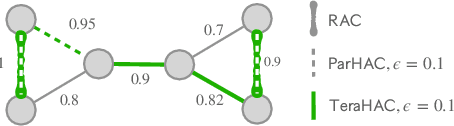
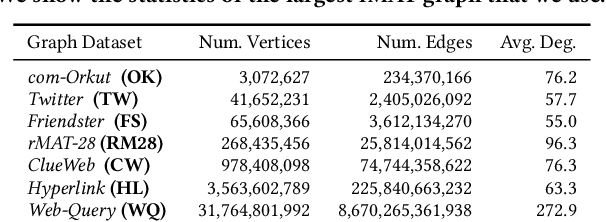
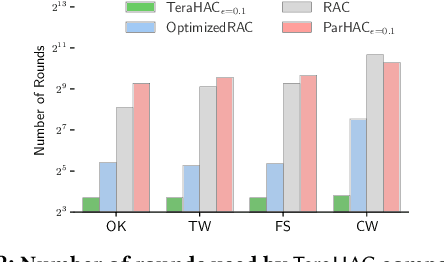
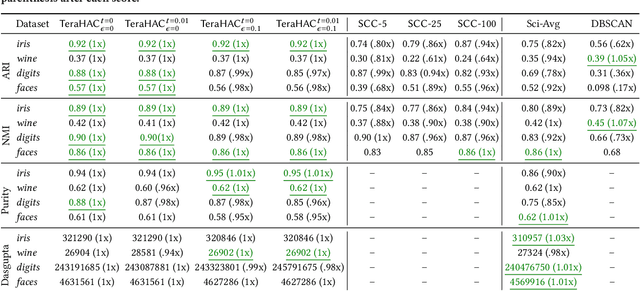
We introduce TeraHAC, a $(1+\epsilon)$-approximate hierarchical agglomerative clustering (HAC) algorithm which scales to trillion-edge graphs. Our algorithm is based on a new approach to computing $(1+\epsilon)$-approximate HAC, which is a novel combination of the nearest-neighbor chain algorithm and the notion of $(1+\epsilon)$-approximate HAC. Our approach allows us to partition the graph among multiple machines and make significant progress in computing the clustering within each partition before any communication with other partitions is needed. We evaluate TeraHAC on a number of real-world and synthetic graphs of up to 8 trillion edges. We show that TeraHAC requires over 100x fewer rounds compared to previously known approaches for computing HAC. It is up to 8.3x faster than SCC, the state-of-the-art distributed algorithm for hierarchical clustering, while achieving 1.16x higher quality. In fact, TeraHAC essentially retains the quality of the celebrated HAC algorithm while significantly improving the running time.
Multi-Label Self-Supervised Learning with Scene Images
Aug 08, 2023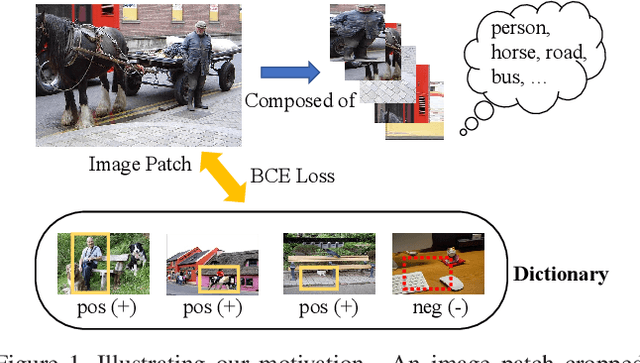
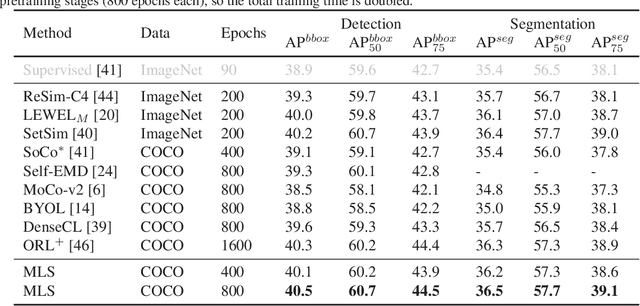
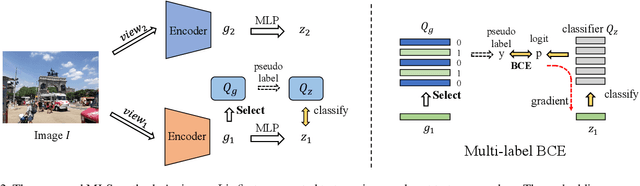
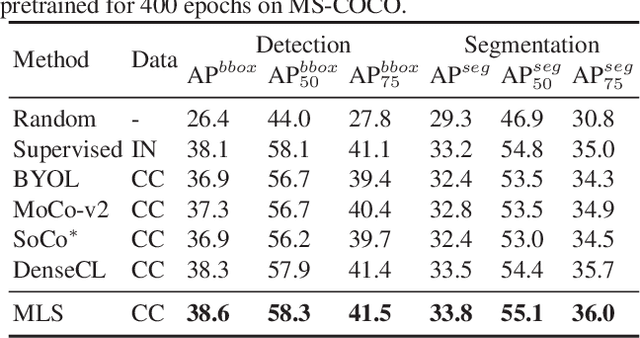
Self-supervised learning (SSL) methods targeting scene images have seen a rapid growth recently, and they mostly rely on either a dedicated dense matching mechanism or a costly unsupervised object discovery module. This paper shows that instead of hinging on these strenuous operations, quality image representations can be learned by treating scene/multi-label image SSL simply as a multi-label classification problem, which greatly simplifies the learning framework. Specifically, multiple binary pseudo-labels are assigned for each input image by comparing its embeddings with those in two dictionaries, and the network is optimized using the binary cross entropy loss. The proposed method is named Multi-Label Self-supervised learning (MLS). Visualizations qualitatively show that clearly the pseudo-labels by MLS can automatically find semantically similar pseudo-positive pairs across different images to facilitate contrastive learning. MLS learns high quality representations on MS-COCO and achieves state-of-the-art results on classification, detection and segmentation benchmarks. At the same time, MLS is much simpler than existing methods, making it easier to deploy and for further exploration.
Gloss Alignment Using Word Embeddings
Aug 08, 2023

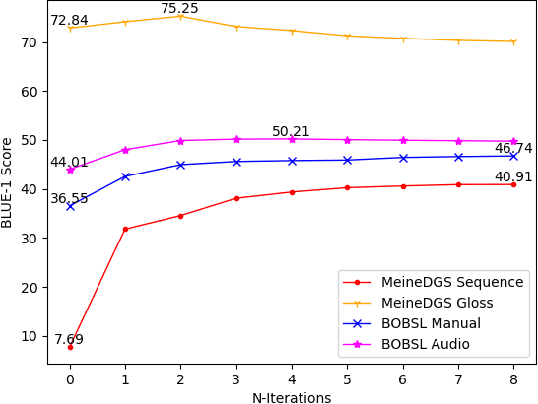
Capturing and annotating Sign language datasets is a time consuming and costly process. Current datasets are orders of magnitude too small to successfully train unconstrained \acf{slt} models. As a result, research has turned to TV broadcast content as a source of large-scale training data, consisting of both the sign language interpreter and the associated audio subtitle. However, lack of sign language annotation limits the usability of this data and has led to the development of automatic annotation techniques such as sign spotting. These spottings are aligned to the video rather than the subtitle, which often results in a misalignment between the subtitle and spotted signs. In this paper we propose a method for aligning spottings with their corresponding subtitles using large spoken language models. Using a single modality means our method is computationally inexpensive and can be utilized in conjunction with existing alignment techniques. We quantitatively demonstrate the effectiveness of our method on the \acf{mdgs} and \acf{bobsl} datasets, recovering up to a 33.22 BLEU-1 score in word alignment.
Lossy and Lossless (L$^2$) Post-training Model Size Compression
Aug 08, 2023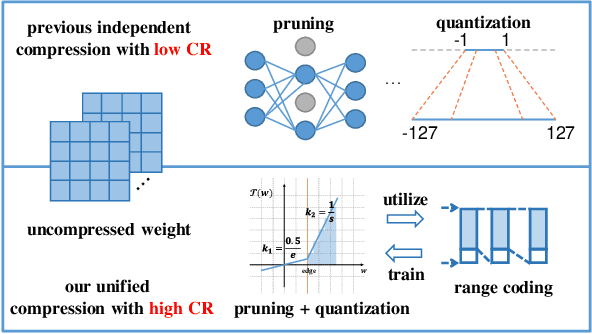
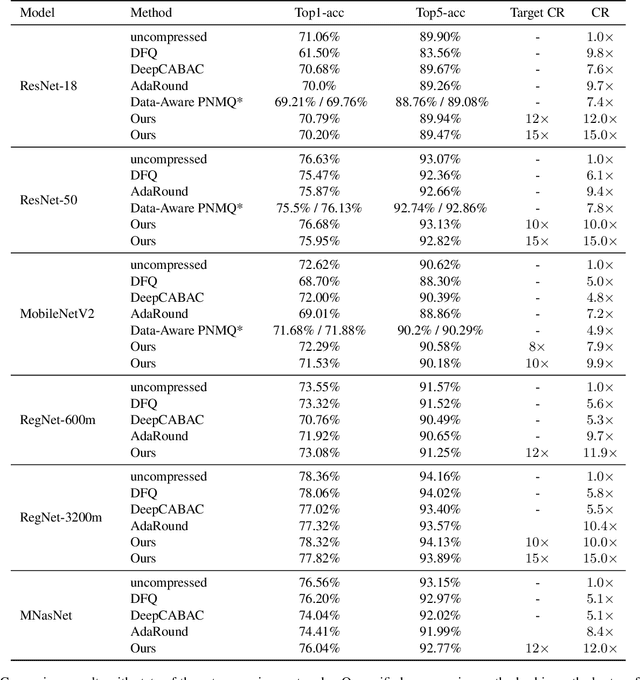
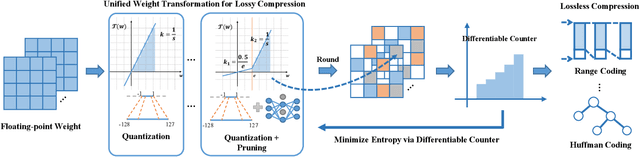
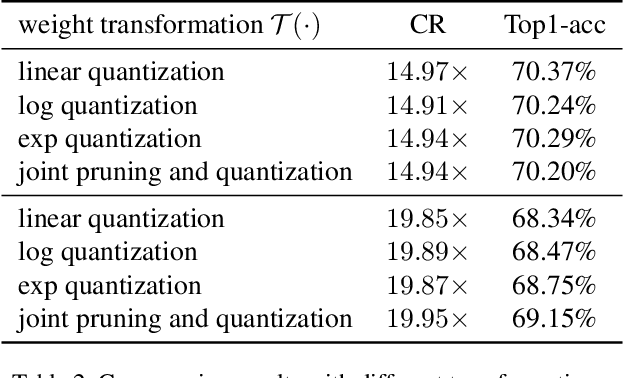
Deep neural networks have delivered remarkable performance and have been widely used in various visual tasks. However, their huge size causes significant inconvenience for transmission and storage. Many previous studies have explored model size compression. However, these studies often approach various lossy and lossless compression methods in isolation, leading to challenges in achieving high compression ratios efficiently. This work proposes a post-training model size compression method that combines lossy and lossless compression in a unified way. We first propose a unified parametric weight transformation, which ensures different lossy compression methods can be performed jointly in a post-training manner. Then, a dedicated differentiable counter is introduced to guide the optimization of lossy compression to arrive at a more suitable point for later lossless compression. Additionally, our method can easily control a desired global compression ratio and allocate adaptive ratios for different layers. Finally, our method can achieve a stable $10\times$ compression ratio without sacrificing accuracy and a $20\times$ compression ratio with minor accuracy loss in a short time. Our code is available at https://github.com/ModelTC/L2_Compression .
Towards Automatic Scoring of Spinal X-ray for Ankylosing Spondylitis
Aug 08, 2023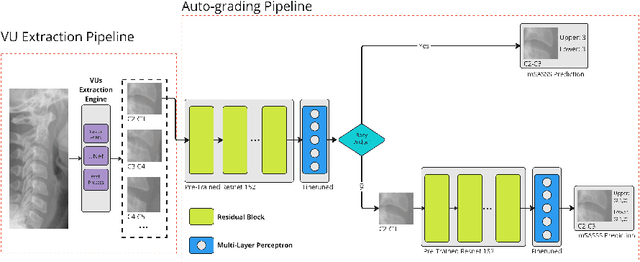
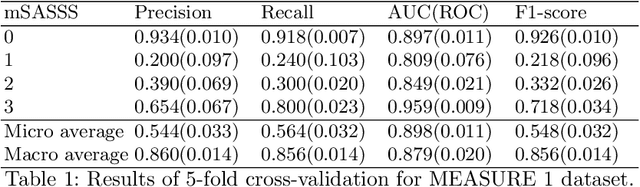
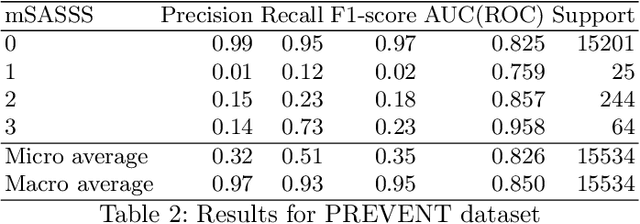
Manually grading structural changes with the modified Stoke Ankylosing Spondylitis Spinal Score (mSASSS) on spinal X-ray imaging is costly and time-consuming due to bone shape complexity and image quality variations. In this study, we address this challenge by prototyping a 2-step auto-grading pipeline, called VertXGradeNet, to automatically predict mSASSS scores for the cervical and lumbar vertebral units (VUs) in X-ray spinal imaging. The VertXGradeNet utilizes VUs generated by our previously developed VU extraction pipeline (VertXNet) as input and predicts mSASSS based on those VUs. VertXGradeNet was evaluated on an in-house dataset of lateral cervical and lumbar X-ray images for axial spondylarthritis patients. Our results show that VertXGradeNet can predict the mSASSS score for each VU when the data is limited in quantity and imbalanced. Overall, it can achieve a balanced accuracy of 0.56 and 0.51 for 4 different mSASSS scores (i.e., a score of 0, 1, 2, 3) on two test datasets. The accuracy of the presented method shows the potential to streamline the spinal radiograph readings and therefore reduce the cost of future clinical trials.
MeetEval: A Toolkit for Computation of Word Error Rates for Meeting Transcription Systems
Jul 21, 2023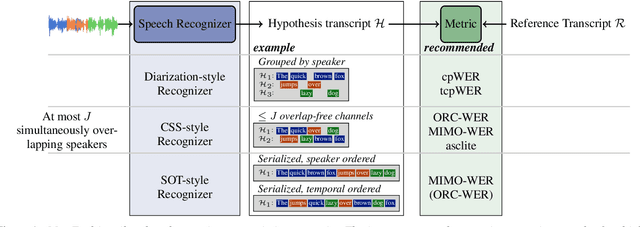
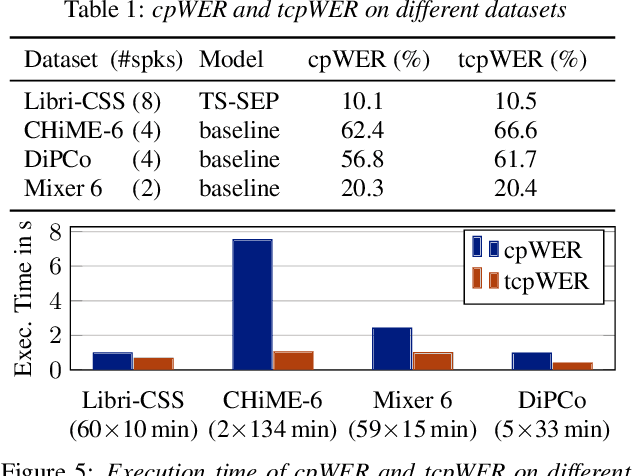
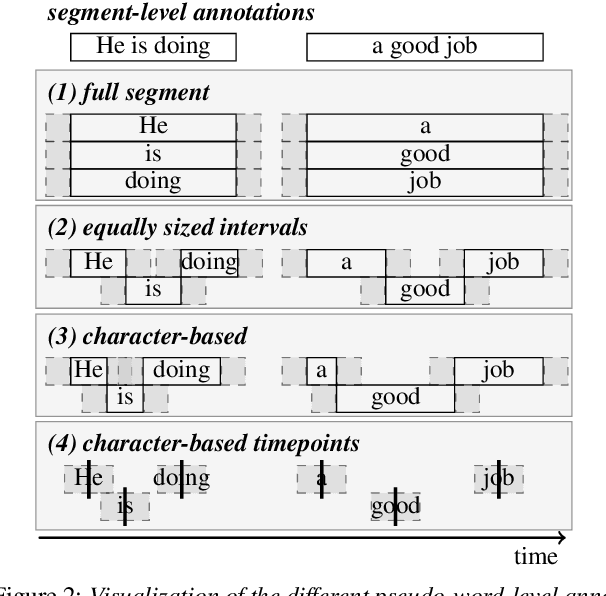
MeetEval is an open-source toolkit to evaluate all kinds of meeting transcription systems. It provides a unified interface for the computation of commonly used Word Error Rates (WERs), specifically cpWER, ORC WER and MIMO WER along other WER definitions. We extend the cpWER computation by a temporal constraint to ensure that only words are identified as correct when the temporal alignment is plausible. This leads to a better quality of the matching of the hypothesis string to the reference string that more closely resembles the actual transcription quality, and a system is penalized if it provides poor time annotations. Since word-level timing information is often not available, we present a way to approximate exact word-level timings from segment-level timings (e.g., a sentence) and show that the approximation leads to a similar WER as a matching with exact word-level annotations. At the same time, the time constraint leads to a speedup of the matching algorithm, which outweighs the additional overhead caused by processing the time stamps.
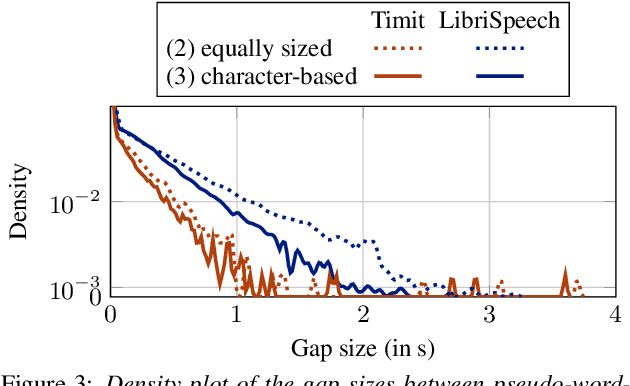
Newton-Cotes Graph Neural Networks: On the Time Evolution of Dynamic Systems
May 24, 2023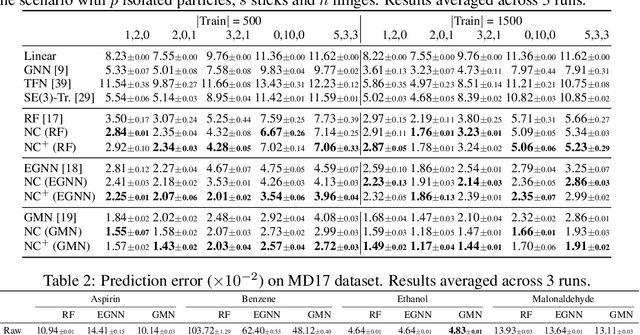
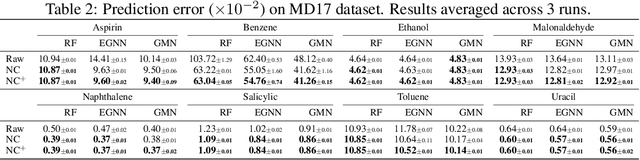
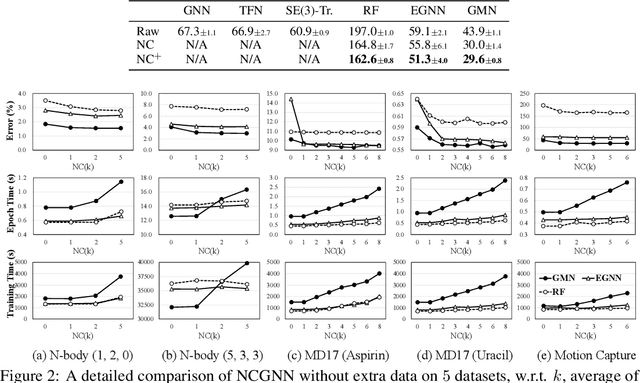
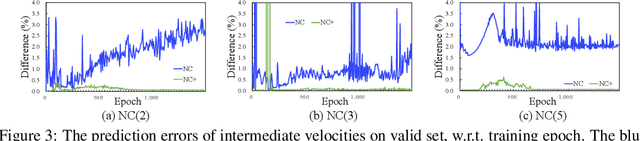
Reasoning system dynamics is one of the most important analytical approaches for many scientific studies. With the initial state of a system as input, the recent graph neural networks (GNNs)-based methods are capable of predicting the future state distant in time with high accuracy. Although these methods have diverse designs in modeling the coordinates and interacting forces of the system, we show that they actually share a common paradigm that learns the integration of the velocity over the interval between the initial and terminal coordinates. However, their integrand is constant w.r.t. time. Inspired by this observation, we propose a new approach to predict the integration based on several velocity estimations with Newton-Cotes formulas and prove its effectiveness theoretically. Extensive experiments on several benchmarks empirically demonstrate consistent and significant improvement compared with the state-of-the-art methods.
DeepVQE: Real Time Deep Voice Quality Enhancement for Joint Acoustic Echo Cancellation, Noise Suppression and Dereverberation
Jun 05, 2023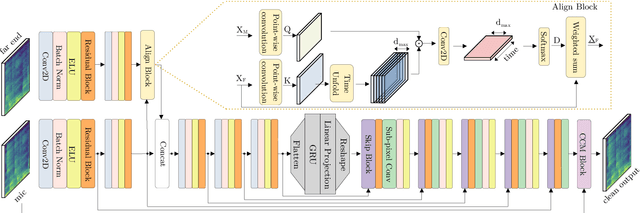

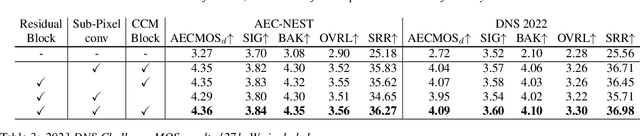
Acoustic echo cancellation (AEC), noise suppression (NS) and dereverberation (DR) are an integral part of modern full-duplex communication systems. As the demand for teleconferencing systems increases, addressing these tasks is required for an effective and efficient online meeting experience. Most prior research proposes solutions for these tasks separately, combining them with digital signal processing (DSP) based components, resulting in complex pipelines that are often impractical to deploy in real-world applications. This paper proposes a real-time cross-attention deep model, named DeepVQE, based on residual convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to simultaneously address AEC, NS, and DR. We conduct several ablation studies to analyze the contributions of different components of our model to the overall performance. DeepVQE achieves state-of-the-art performance on non-personalized tracks from the ICASSP 2023 Acoustic Echo Cancellation Challenge and ICASSP 2023 Deep Noise Suppression Challenge test sets, showing that a single model can handle multiple tasks with excellent performance. Moreover, the model runs in real-time and has been successfully tested for the Microsoft Teams platform.
Threshold-aware Learning to Generate Feasible Solutions for Mixed Integer Programs
Aug 01, 2023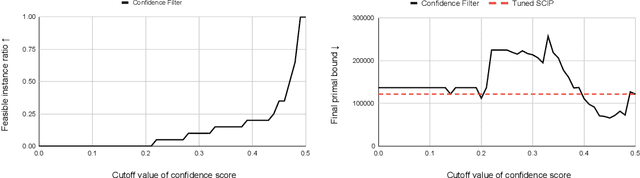

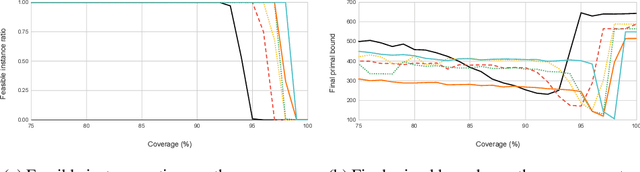
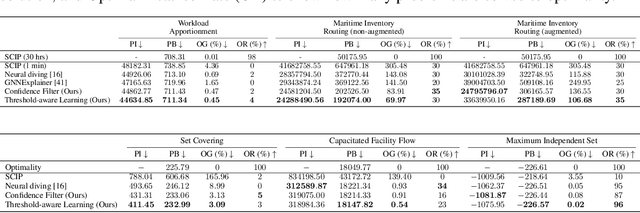
Finding a high-quality feasible solution to a combinatorial optimization (CO) problem in a limited time is challenging due to its discrete nature. Recently, there has been an increasing number of machine learning (ML) methods for addressing CO problems. Neural diving (ND) is one of the learning-based approaches to generating partial discrete variable assignments in Mixed Integer Programs (MIP), a framework for modeling CO problems. However, a major drawback of ND is a large discrepancy between the ML and MIP objectives, i.e., variable value classification accuracy over primal bound. Our study investigates that a specific range of variable assignment rates (coverage) yields high-quality feasible solutions, where we suggest optimizing the coverage bridges the gap between the learning and MIP objectives. Consequently, we introduce a post-hoc method and a learning-based approach for optimizing the coverage. A key idea of our approach is to jointly learn to restrict the coverage search space and to predict the coverage in the learned search space. Experimental results demonstrate that learning a deep neural network to estimate the coverage for finding high-quality feasible solutions achieves state-of-the-art performance in NeurIPS ML4CO datasets. In particular, our method shows outstanding performance in the workload apportionment dataset, achieving the optimality gap of 0.45%, a ten-fold improvement over SCIP within the one-minute time limit.