 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Client: Cross-variable Linear Integrated Enhanced Transformer for Multivariate Long-Term Time Series Forecasting
May 30, 2023
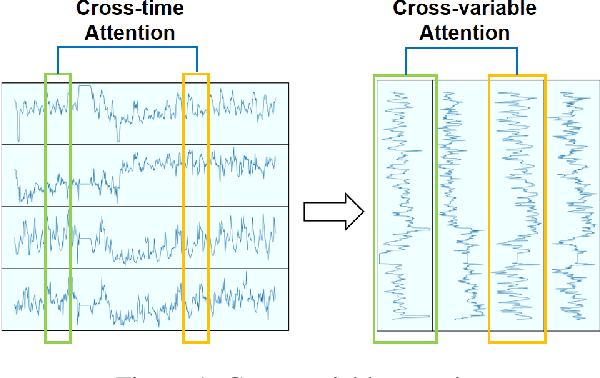
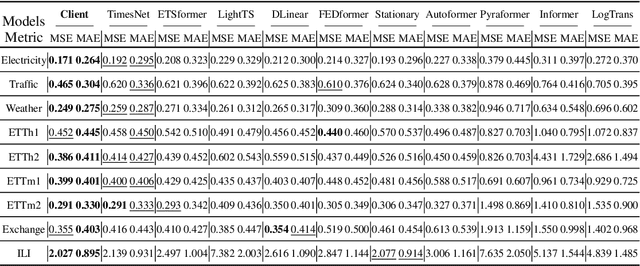
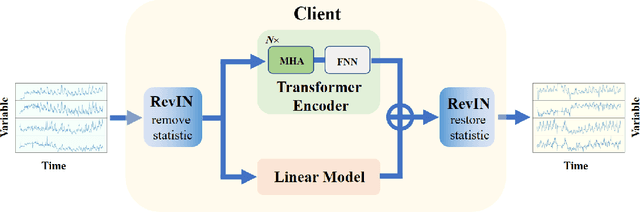
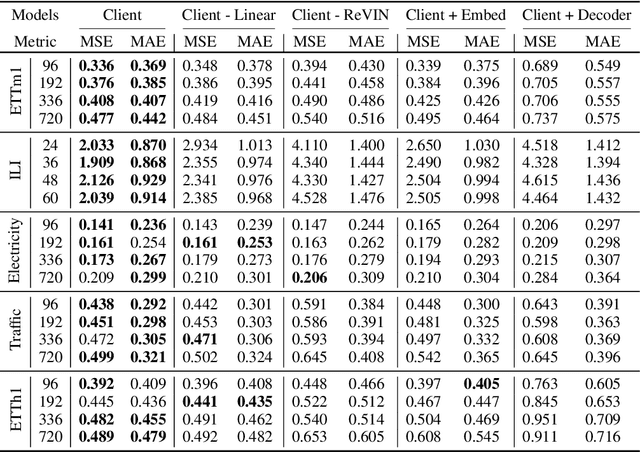
Long-term time series forecasting (LTSF) is a crucial aspect of modern society, playing a pivotal role in facilitating long-term planning and developing early warning systems. While many Transformer-based models have recently been introduced for LTSF, a doubt have been raised regarding the effectiveness of attention modules in capturing cross-time dependencies. In this study, we design a mask-series experiment to validate this assumption and subsequently propose the "Cross-variable Linear Integrated ENhanced Transformer for Multivariate Long-Term Time Series Forecasting" (Client), an advanced model that outperforms both traditional Transformer-based models and linear models. Client employs linear modules to learn trend information and attention modules to capture cross-variable dependencies. Meanwhile, it simplifies the embedding and position encoding layers and replaces the decoder module with a projection layer. Essentially, Client incorporates non-linearity and cross-variable dependencies, which sets it apart from conventional linear models and Transformer-based models. Extensive experiments with nine real-world datasets have confirmed the SOTA performance of Client with the least computation time and memory consumption compared with the previous Transformer-based models. Our code is available at https://github.com/daxin007/Client.
Robust Interference Mitigation techniques for Direct Position Estimation
Aug 09, 2023
Global Navigation Satellite System (GNSS) is pervasive in navigation and positioning applications, where precise position and time referencing estimations are required. Conventional methods for GNSS positioning involve a two-step process, where intermediate measurements such as Doppler shift and time delay of received GNSS signals are computed and then used to solve for the receiver's position. Alternatively, Direct Position Estimation (DPE) was proposed to infer the position directly from the sampled signal without intermediate variables, yielding to superior levels of sensitivity and operation under challenging environments. However, the positioning resilience of DPE method is still under the threat of various interferences. Robust Interference Mitigation (RIM) processing has been studied and proved to be efficient against various interference in conventional two-step positioning (2SP) methods, and therefore worthy to be explored regarding its potential to enhance DPE. This article extends DPE methodology by incorporating RIM strategies that address the increasing need to protect GNSS receivers against intentional or unintentional interferences, such as jamming signals, which can deny GNSS-based positioning. RIM, which leverages robust statistics, was shown to provide competitive results in two-step approaches and is here employed in a high-sensitivity DPE framework with successful results. The article also provides a quantification of the loss of efficiency of using RIM when no interference is present and validates the proposed methodology on relevant interference cases, while the approach can be used to mitigate other common interference signals.
EnrichEvent: Enriching Social Data with Contextual Information for Emerging Event Extraction
Aug 16, 2023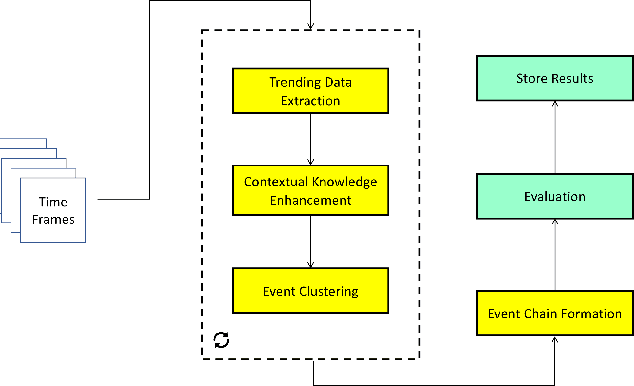
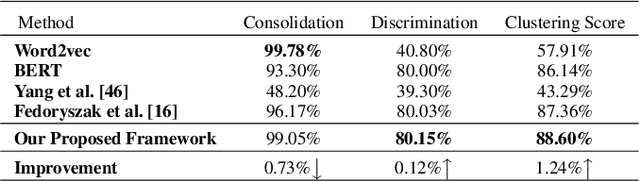
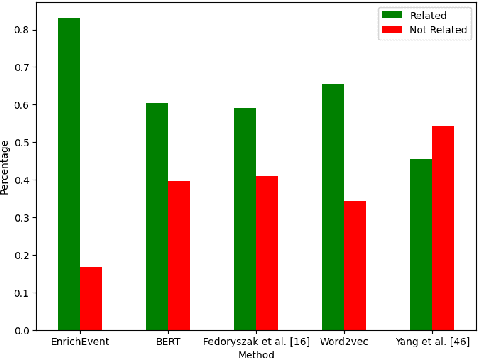
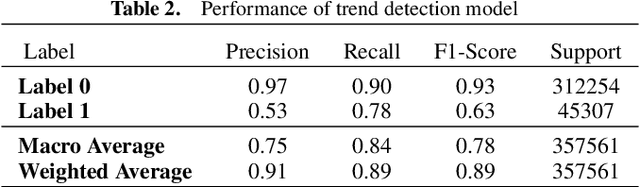
Social platforms have emerged as crucial platforms for disseminating information and discussing real-life social events, which offers an excellent opportunity for researchers to design and implement novel event detection frameworks. However, most existing approaches merely exploit keyword burstiness or network structures to detect unspecified events. Thus, they often fail to identify unspecified events regarding the challenging nature of events and social data. Social data, e.g., tweets, is characterized by misspellings, incompleteness, word sense ambiguation, and irregular language, as well as variation in aspects of opinions. Moreover, extracting discriminative features and patterns for evolving events by exploiting the limited structural knowledge is almost infeasible. To address these challenges, in this thesis, we propose a novel framework, namely EnrichEvent, that leverages the lexical and contextual representations of streaming social data. In particular, we leverage contextual knowledge, as well as lexical knowledge, to detect semantically related tweets and enhance the effectiveness of the event detection approaches. Eventually, our proposed framework produces cluster chains for each event to show the evolving variation of the event through time. We conducted extensive experiments to evaluate our framework, validating its high performance and effectiveness in detecting and distinguishing unspecified social events.
Agglomerative Transformer for Human-Object Interaction Detection
Aug 16, 2023

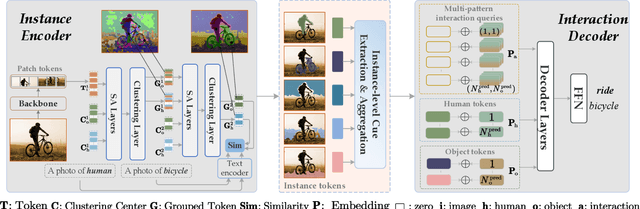
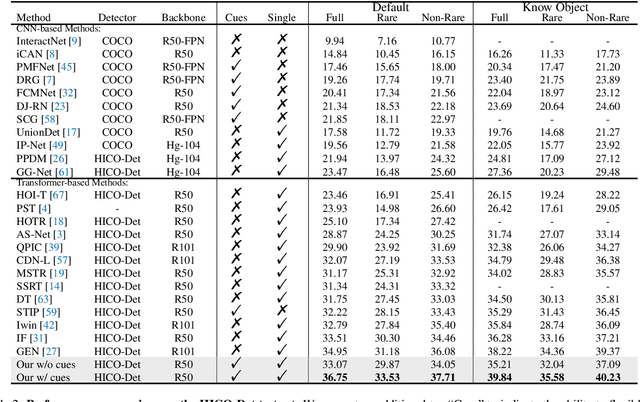
We propose an agglomerative Transformer (AGER) that enables Transformer-based human-object interaction (HOI) detectors to flexibly exploit extra instance-level cues in a single-stage and end-to-end manner for the first time. AGER acquires instance tokens by dynamically clustering patch tokens and aligning cluster centers to instances with textual guidance, thus enjoying two benefits: 1) Integrality: each instance token is encouraged to contain all discriminative feature regions of an instance, which demonstrates a significant improvement in the extraction of different instance-level cues and subsequently leads to a new state-of-the-art performance of HOI detection with 36.75 mAP on HICO-Det. 2) Efficiency: the dynamical clustering mechanism allows AGER to generate instance tokens jointly with the feature learning of the Transformer encoder, eliminating the need of an additional object detector or instance decoder in prior methods, thus allowing the extraction of desirable extra cues for HOI detection in a single-stage and end-to-end pipeline. Concretely, AGER reduces GFLOPs by 8.5% and improves FPS by 36%, even compared to a vanilla DETR-like pipeline without extra cue extraction.
Partially Observable Multi-agent RL with (Quasi-)Efficiency: The Blessing of Information Sharing
Aug 16, 2023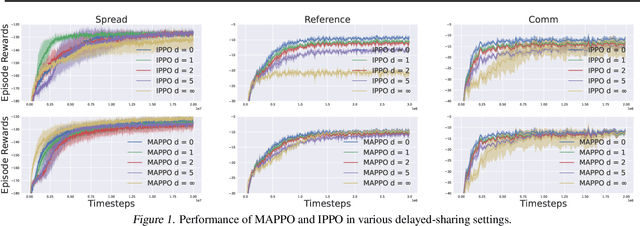
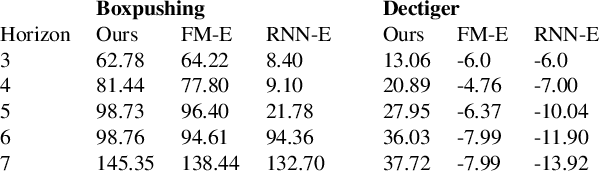
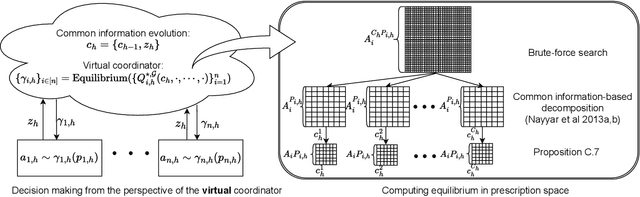
We study provable multi-agent reinforcement learning (MARL) in the general framework of partially observable stochastic games (POSGs). To circumvent the known hardness results and the use of computationally intractable oracles, we advocate leveraging the potential \emph{information-sharing} among agents, a common practice in empirical MARL, and a standard model for multi-agent control systems with communications. We first establish several computation complexity results to justify the necessity of information-sharing, as well as the observability assumption that has enabled quasi-efficient single-agent RL with partial observations, for computational efficiency in solving POSGs. We then propose to further \emph{approximate} the shared common information to construct an {approximate model} of the POSG, in which planning an approximate equilibrium (in terms of solving the original POSG) can be quasi-efficient, i.e., of quasi-polynomial-time, under the aforementioned assumptions. Furthermore, we develop a partially observable MARL algorithm that is both statistically and computationally quasi-efficient. We hope our study may open up the possibilities of leveraging and even designing different \emph{information structures}, for developing both sample- and computation-efficient partially observable MARL.
BREATHE: Second-Order Gradients and Heteroscedastic Emulation based Design Space Exploration
Aug 16, 2023Researchers constantly strive to explore larger and more complex search spaces in various scientific studies and physical experiments. However, such investigations often involve sophisticated simulators or time-consuming experiments that make exploring and observing new design samples challenging. Previous works that target such applications are typically sample-inefficient and restricted to vector search spaces. To address these limitations, this work proposes a constrained multi-objective optimization (MOO) framework, called BREATHE, that searches not only traditional vector-based design spaces but also graph-based design spaces to obtain best-performing graphs. It leverages second-order gradients and actively trains a heteroscedastic surrogate model for sample-efficient optimization. In a single-objective vector optimization application, it leads to 64.1% higher performance than the next-best baseline, random forest regression. In graph-based search, BREATHE outperforms the next-best baseline, i.e., a graphical version of Gaussian-process-based Bayesian optimization, with up to 64.9% higher performance. In a MOO task, it achieves up to 21.9$\times$ higher hypervolume than the state-of-the-art method, multi-objective Bayesian optimization (MOBOpt). BREATHE also outperforms the baseline methods on most standard MOO benchmark applications.
Exploring Winograd Convolution for Cost-effective Neural Network Fault Tolerance
Aug 16, 2023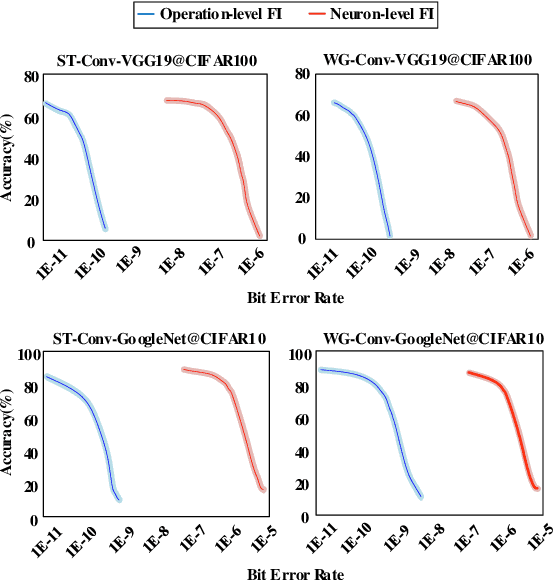
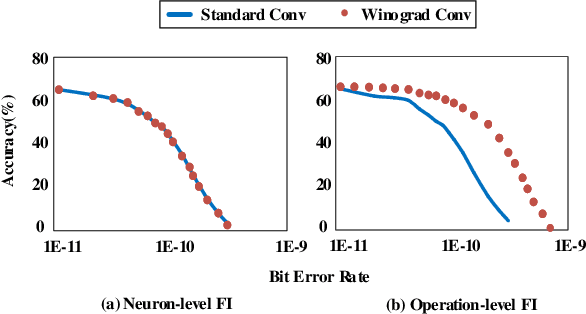
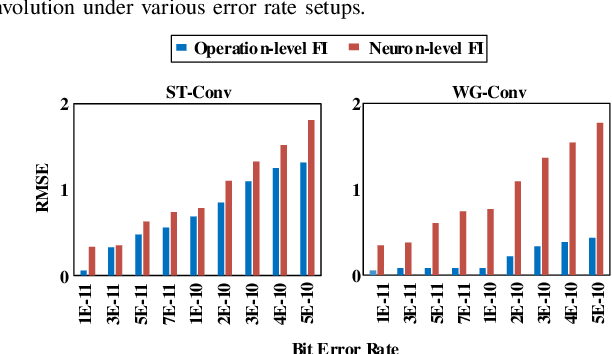
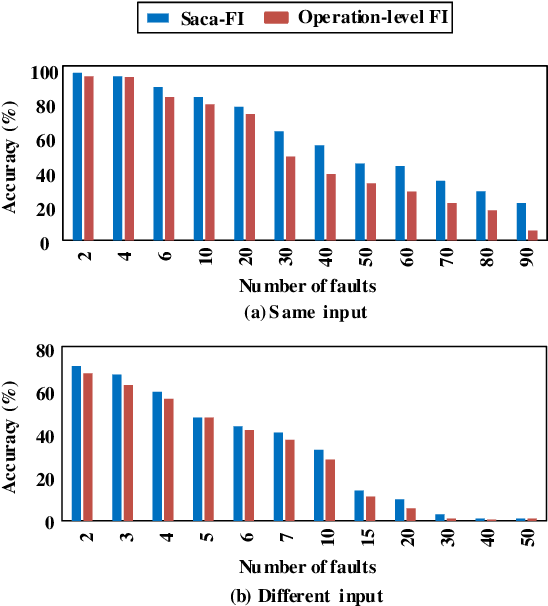
Winograd is generally utilized to optimize convolution performance and computational efficiency because of the reduced multiplication operations, but the reliability issues brought by winograd are usually overlooked. In this work, we observe the great potential of winograd convolution in improving neural network (NN) fault tolerance. Based on the observation, we evaluate winograd convolution fault tolerance comprehensively from different granularities ranging from models, layers, and operation types for the first time. Then, we explore the use of inherent fault tolerance of winograd convolution for cost-effective NN protection against soft errors. Specifically, we mainly investigate how winograd convolution can be effectively incorporated with classical fault-tolerant design approaches including triple modular redundancy (TMR), fault-aware retraining, and constrained activation functions. According to our experiments, winograd convolution can reduce the fault-tolerant design overhead by 55.77\% on average without any accuracy loss compared to standard convolution, and further reduce the computing overhead by 17.24\% when the inherent fault tolerance of winograd convolution is considered. When it is applied on fault-tolerant neural networks enhanced with fault-aware retraining and constrained activation functions, the resulting model accuracy generally shows significant improvement in presence of various faults.
An Empirical Study on Log-based Anomaly Detection Using Machine Learning
Jul 31, 2023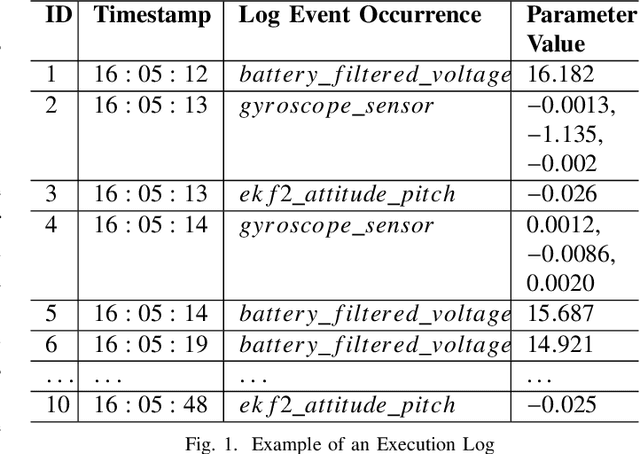
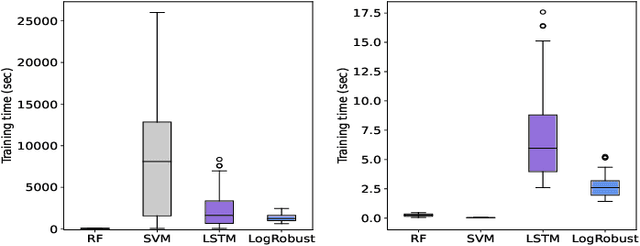
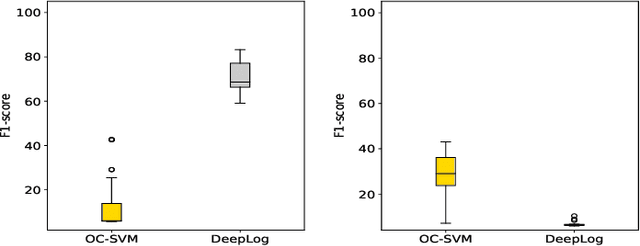
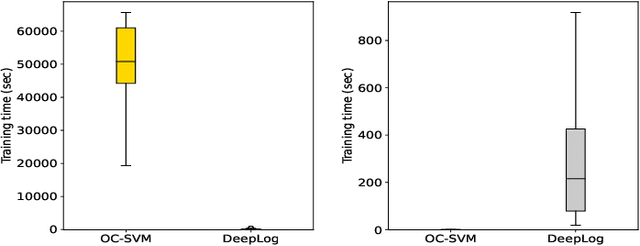
The growth of systems complexity increases the need of automated techniques dedicated to different log analysis tasks such as Log-based Anomaly Detection (LAD). The latter has been widely addressed in the literature, mostly by means of different deep learning techniques. Nevertheless, the focus on deep learning techniques results in less attention being paid to traditional Machine Learning (ML) techniques, which may perform well in many cases, depending on the context and the used datasets. Further, the evaluation of different ML techniques is mostly based on the assessment of their detection accuracy. However, this is is not enough to decide whether or not a specific ML technique is suitable to address the LAD problem. Other aspects to consider include the training and prediction time as well as the sensitivity to hyperparameter tuning. In this paper, we present a comprehensive empirical study, in which we evaluate different supervised and semi-supervised, traditional and deep ML techniques w.r.t. four evaluation criteria: detection accuracy, time performance, sensitivity of detection accuracy as well as time performance to hyperparameter tuning. The experimental results show that supervised traditional and deep ML techniques perform very closely in terms of their detection accuracy and prediction time. Moreover, the overall evaluation of the sensitivity of the detection accuracy of the different ML techniques to hyperparameter tuning shows that supervised traditional ML techniques are less sensitive to hyperparameter tuning than deep learning techniques. Further, semi-supervised techniques yield significantly worse detection accuracy than supervised techniques.
Task Offloading for Smart Glasses in Healthcare: Enhancing Detection of Elevated Body Temperature
Aug 14, 2023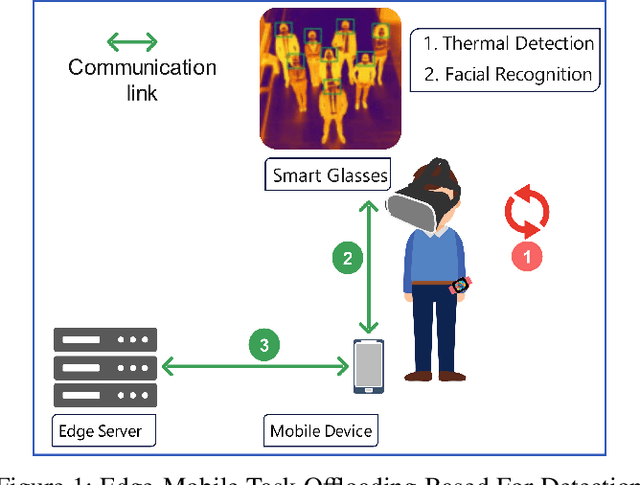
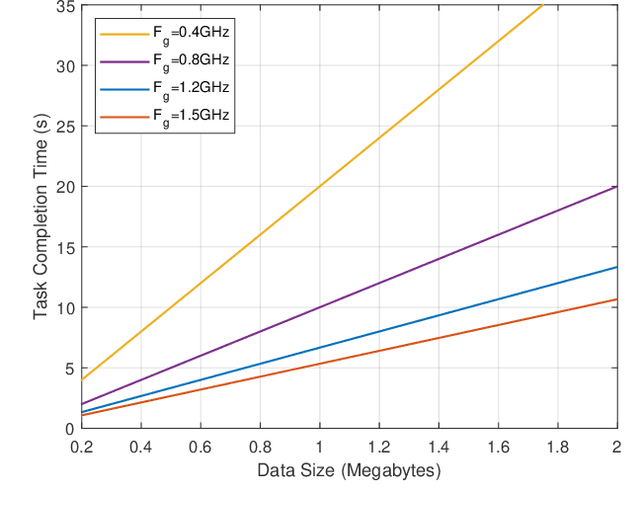
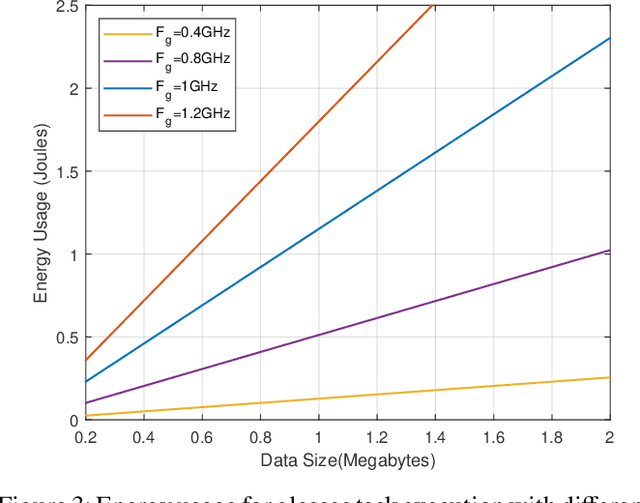
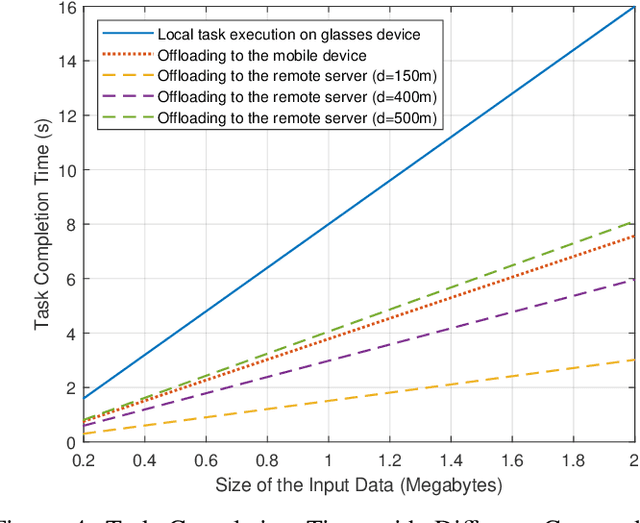
Wearable devices like smart glasses have gained popularity across various applications. However, their limited computational capabilities pose challenges for tasks that require extensive processing, such as image and video processing, leading to drained device batteries. To address this, offloading such tasks to nearby powerful remote devices, such as mobile devices or remote servers, has emerged as a promising solution. This paper focuses on analyzing task-offloading scenarios for a healthcare monitoring application performed on smart wearable glasses, aiming to identify the optimal conditions for offloading. The study evaluates performance metrics including task completion time, computing capabilities, and energy consumption under realistic conditions. A specific use case is explored within an indoor area like an airport, where security agents wearing smart glasses to detect elevated body temperature in individuals, potentially indicating COVID-19. The findings highlight the potential benefits of task offloading for wearable devices in healthcare settings, demonstrating its practicality and relevance.
iSTFTNet2: Faster and More Lightweight iSTFT-Based Neural Vocoder Using 1D-2D CNN
Aug 14, 2023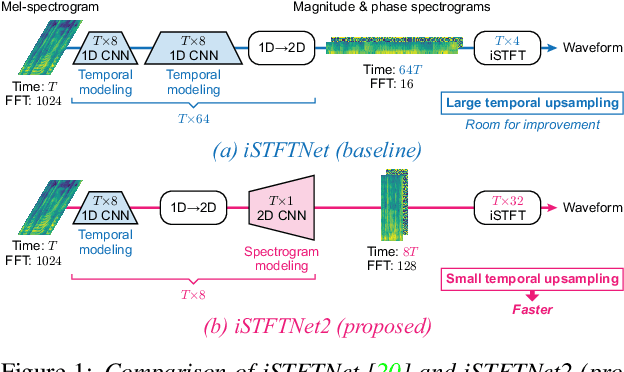
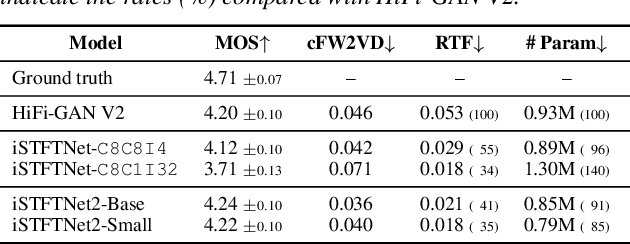
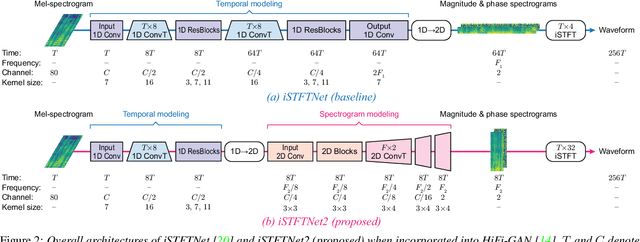
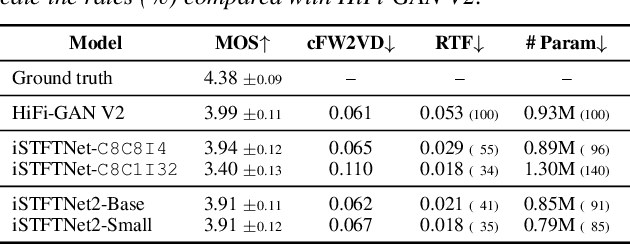
The inverse short-time Fourier transform network (iSTFTNet) has garnered attention owing to its fast, lightweight, and high-fidelity speech synthesis. It obtains these characteristics using a fast and lightweight 1D CNN as the backbone and replacing some neural processes with iSTFT. Owing to the difficulty of a 1D CNN to model high-dimensional spectrograms, the frequency dimension is reduced via temporal upsampling. However, this strategy compromises the potential to enhance the speed. Therefore, we propose iSTFTNet2, an improved variant of iSTFTNet with a 1D-2D CNN that employs 1D and 2D CNNs to model temporal and spectrogram structures, respectively. We designed a 2D CNN that performs frequency upsampling after conversion in a few-frequency space. This design facilitates the modeling of high-dimensional spectrograms without compromising the speed. The results demonstrated that iSTFTNet2 made iSTFTNet faster and more lightweight with comparable speech quality. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/istftnet2/.