 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UniAP: Unifying Inter- and Intra-Layer Automatic Parallelism by Mixed Integer Quadratic Programming
Jul 31, 2023
Deep learning models have demonstrated impressive performance in various domains. However, the prolonged training time of these models remains a critical problem. Manually designed parallel training strategies could enhance efficiency but require considerable time and deliver little flexibility. Hence, automatic parallelism is proposed to automate the parallel strategy searching process. Even so, existing approaches suffer from sub-optimal strategy space because they treat automatic parallelism as two independent stages, namely inter- and intra-layer parallelism. To address this issue, we propose UniAP, which utilizes mixed integer quadratic programming to unify inter- and intra-layer automatic parallelism. To the best of our knowledge, UniAP is the first work to unify these two categories to search for a globally optimal strategy. The experimental results show that UniAP outperforms state-of-the-art methods by up to 1.70$\times$ in throughput and reduces strategy searching time by up to 16$\times$ across four Transformer-like models.
MeciFace: Mechanomyography and Inertial Fusion based Glasses for Edge Real-Time Recognition of Facial and Eating Activities
Jun 19, 2023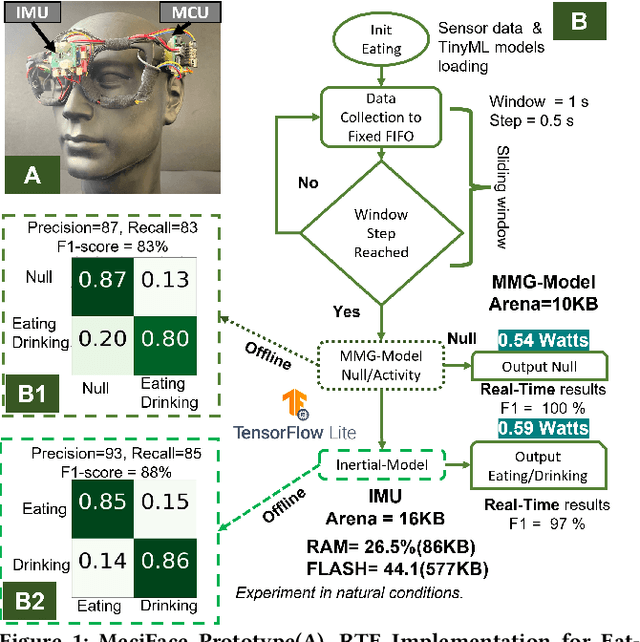

We present MeciFace, a low-power (0.55 Watts), privacy-conscious, real-time on-the-edge (RTE) wearable solution with a tiny memory footprint (11-19 KB), designed to monitor facial expressions and eating activities. We employ lightweight convolutional neural networks as the backbone models for both facial and eating scenarios. The system yielded an F1-score of 86% for the RTE evaluation in the facial expression case. In addition, we obtained an F1-score of 90% for eating/drinking monitoring for the RTE of an unseen user.
Tensor-Compressed Back-Propagation-Free Training for (Physics-Informed) Neural Networks
Aug 18, 2023Backward propagation (BP) is widely used to compute the gradients in neural network training. However, it is hard to implement BP on edge devices due to the lack of hardware and software resources to support automatic differentiation. This has tremendously increased the design complexity and time-to-market of on-device training accelerators. This paper presents a completely BP-free framework that only requires forward propagation to train realistic neural networks. Our technical contributions are three-fold. Firstly, we present a tensor-compressed variance reduction approach to greatly improve the scalability of zeroth-order (ZO) optimization, making it feasible to handle a network size that is beyond the capability of previous ZO approaches. Secondly, we present a hybrid gradient evaluation approach to improve the efficiency of ZO training. Finally, we extend our BP-free training framework to physics-informed neural networks (PINNs) by proposing a sparse-grid approach to estimate the derivatives in the loss function without using BP. Our BP-free training only loses little accuracy on the MNIST dataset compared with standard first-order training. We also demonstrate successful results in training a PINN for solving a 20-dim Hamiltonian-Jacobi-Bellman PDE. This memory-efficient and BP-free approach may serve as a foundation for the near-future on-device training on many resource-constraint platforms (e.g., FPGA, ASIC, micro-controllers, and photonic chips).
Twinning Commercial Radio Waveforms in the Colosseum Wireless Network Emulator
Aug 18, 2023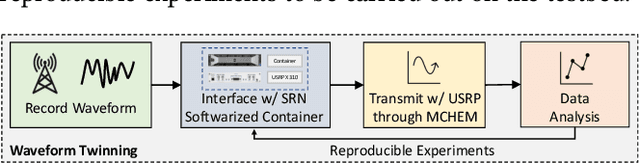

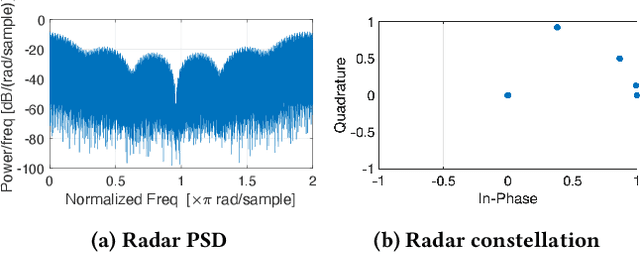
Because of the ever-growing amount of wireless consumers, spectrum-sharing techniques have been increasingly common in the wireless ecosystem, with the main goal of avoiding harmful interference to coexisting communication systems. This is even more important when considering systems, such as nautical and aerial fleet radars, in which incumbent radios operate mission-critical communication links. To study, develop, and validate these solutions, adequate platforms, such as the Colosseum wireless network emulator, are key as they enable experimentation with spectrum-sharing heterogeneous radio technologies in controlled environments. In this work, we demonstrate how Colosseum can be used to twin commercial radio waveforms to evaluate the coexistence of such technologies in complex wireless propagation environments. To this aim, we create a high-fidelity spectrum-sharing scenario on Colosseum to evaluate the impact of twinned commercial radar waveforms on a cellular network operating in the CBRS band. Then, we leverage IQ samples collected on the testbed to train a machine learning agent that runs at the base station to detect the presence of incumbent radar transmissions and vacate the bandwidth to avoid causing them harmful interference. Our results show an average detection accuracy of 88%, with accuracy above 90% in SNR regimes above 0 dB and SINR regimes above -20 dB, and with an average detection time of 137 ms.
SparseBEV: High-Performance Sparse 3D Object Detection from Multi-Camera Videos
Aug 18, 2023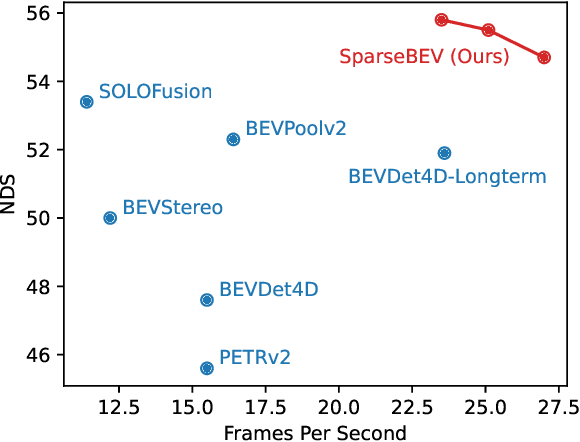
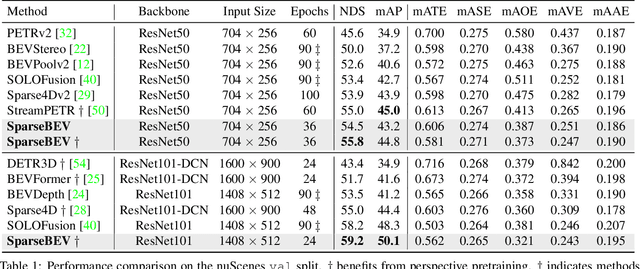
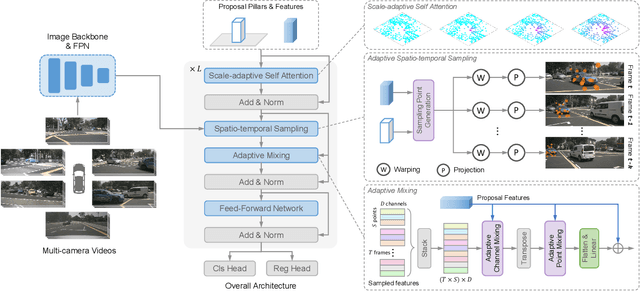
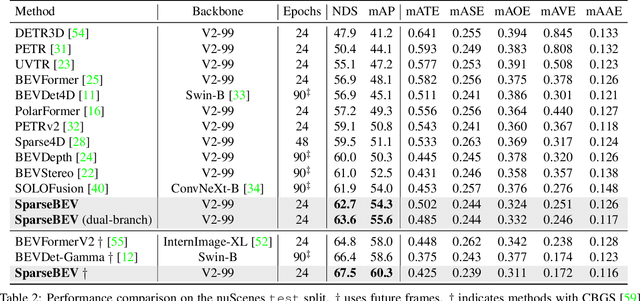
Camera-based 3D object detection in BEV (Bird's Eye View) space has drawn great attention over the past few years. Dense detectors typically follow a two-stage pipeline by first constructing a dense BEV feature and then performing object detection in BEV space, which suffers from complex view transformations and high computation cost. On the other side, sparse detectors follow a query-based paradigm without explicit dense BEV feature construction, but achieve worse performance than the dense counterparts. In this paper, we find that the key to mitigate this performance gap is the adaptability of the detector in both BEV and image space. To achieve this goal, we propose SparseBEV, a fully sparse 3D object detector that outperforms the dense counterparts. SparseBEV contains three key designs, which are (1) scale-adaptive self attention to aggregate features with adaptive receptive field in BEV space, (2) adaptive spatio-temporal sampling to generate sampling locations under the guidance of queries, and (3) adaptive mixing to decode the sampled features with dynamic weights from the queries. On the test split of nuScenes, SparseBEV achieves the state-of-the-art performance of 67.5 NDS. On the val split, SparseBEV achieves 55.8 NDS while maintaining a real-time inference speed of 23.5 FPS. Code is available at https://github.com/MCG-NJU/SparseBEV.
Multi-Task Pseudo-Label Learning for Non-Intrusive Speech Quality Assessment Model
Aug 18, 2023
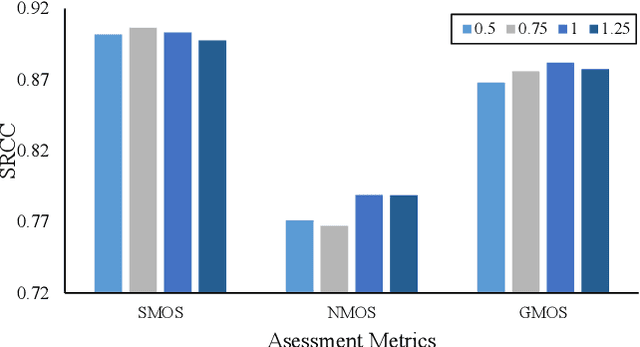
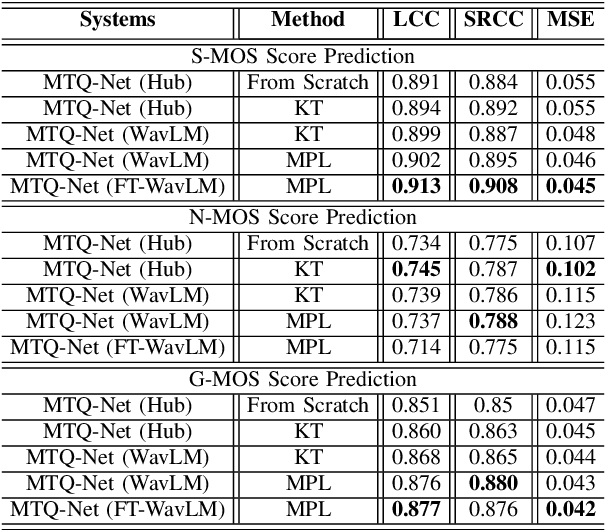
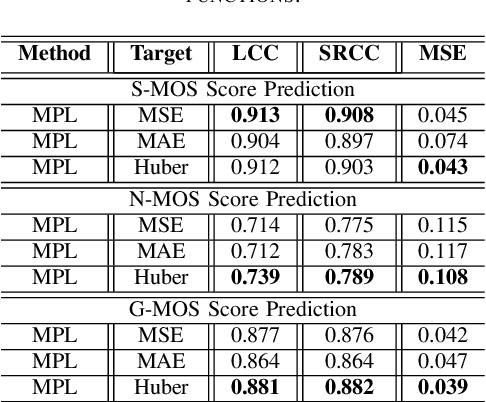
This study introduces multi-task pseudo-label (MPL) learning for a non-intrusive speech quality assessment model. MPL consists of two stages which are obtaining pseudo-label scores from a pretrained model and performing multi-task learning. The 3QUEST metrics, namely Speech-MOS (S-MOS), Noise-MOS (N-MOS), and General-MOS (G-MOS) are selected as the primary ground-truth labels. Additionally, the pretrained MOSA-Net model is utilized to estimate three pseudo-labels: perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI). Multi-task learning stage of MPL is then employed to train the MTQ-Net model (multi-target speech quality assessment network). The model is optimized by incorporating Loss supervision (derived from the difference between the estimated score and the real ground-truth labels) and Loss semi-supervision (derived from the difference between the estimated score and pseudo-labels), where Huber loss is employed to calculate the loss function. Experimental results first demonstrate the advantages of MPL compared to training the model from scratch and using knowledge transfer mechanisms. Secondly, the benefits of Huber Loss in improving the prediction model of MTQ-Net are verified. Finally, the MTQ-Net with the MPL approach exhibits higher overall prediction capabilities when compared to other SSL-based speech assessment models.
Towards Human-Robot Collaboration with Parallel Robots by Kinetostatic Analysis, Impedance Control and Contact Detection
Aug 18, 2023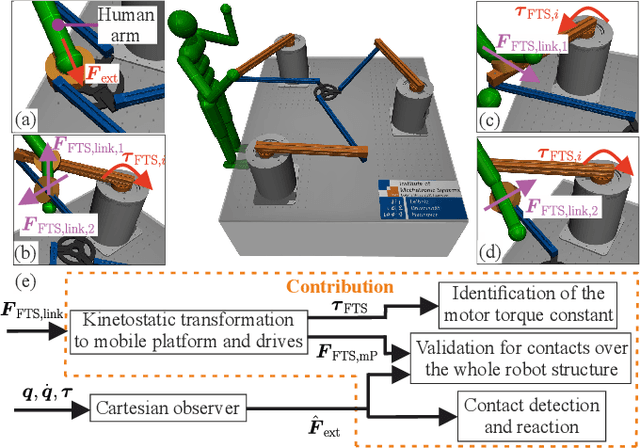
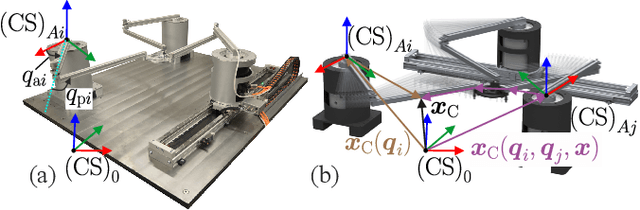
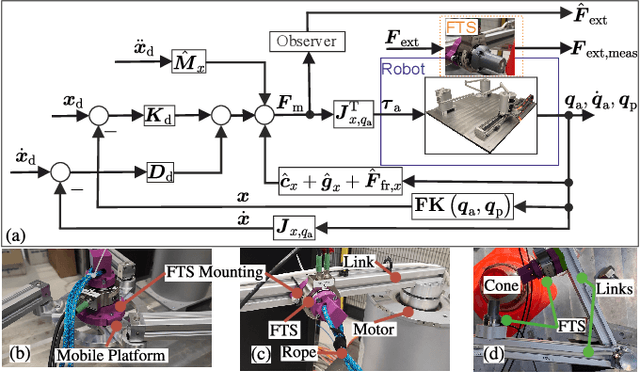
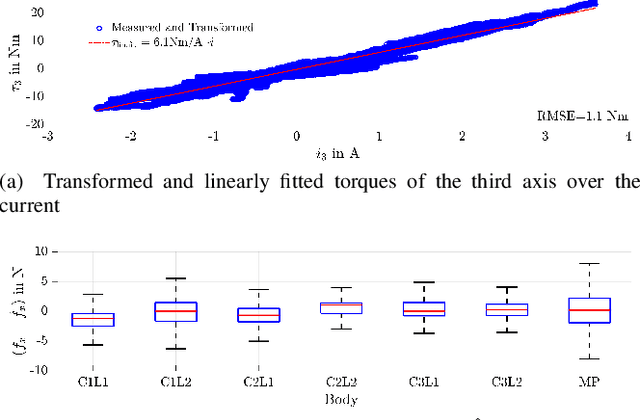
Parallel robots provide the potential to be leveraged for human-robot collaboration (HRC) due to low collision energies even at high speeds resulting from their reduced moving masses. However, the risk of unintended contact with the leg chains increases compared to the structure of serial robots. As a first step towards HRC, contact cases on the whole parallel robot structure are investigated and a disturbance observer based on generalized momenta and measurements of motor current is applied. In addition, a Kalman filter and a second-order sliding-mode observer based on generalized momenta are compared in terms of error and detection time. Gearless direct drives with low friction improve external force estimation and enable low impedance. The experimental validation is performed with two force-torque sensors and a kinetostatic model. This allows a new identification method of the motor torque constant of an assembled parallel robot to estimate external forces from the motor current and via a dynamics model. A Cartesian impedance control scheme for compliant robot-environmental dynamics with stiffness from 0.1-2N/mm and the force observation for low forces over the entire structure are validated. The observers are used for collisions and clamping at velocities of 0.4-0.9m/s for detection within 9-58ms and a reaction in the form of a zero-g mode.
Stochastic Geometry Analysis of a New GSCM with Dual Visibility Regions
Aug 18, 2023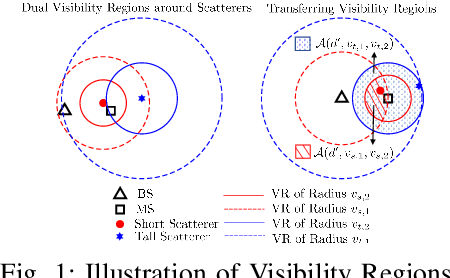
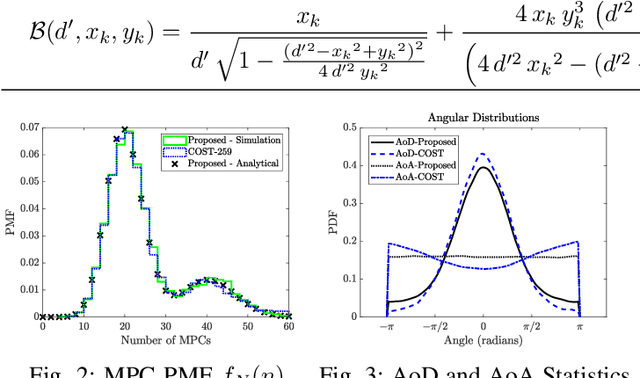
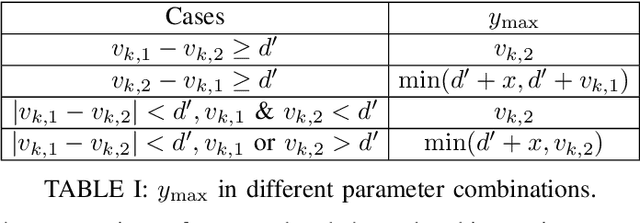

The geometry-based stochastic channel models (GSCM), which can describe realistic channel impulse responses, often rely on the existence of both {\em local} and {\em far} scatterers. However, their visibility from both the base station (BS) and mobile station (MS) depends on their relative heights and positions. For example, the condition of visibility of a scatterer from the perspective of a BS is different from that of an MS and depends on the height of the scatterer. To capture this, we propose a novel GSCM where each scatterer has dual disk visibility regions (VRs) centered on itself for both BS and MS, with their radii being our model parameters. Our model consists of {\em short} and {\em tall} scatterers, which are both modeled using independent inhomogeneous Poisson point processes (IPPPs) having distinct dual VRs. We also introduce a probability parameter to account for the varying visibility of tall scatterers from different MSs, effectively emulating their noncontiguous VRs. Using stochastic geometry, we derive the probability mass function (PMF) of the number of multipath components (MPCs), the marginal and joint distance distributions for an active scatterer, the mean time of arrival (ToA), and the mean received power through non-line-of-sight (NLoS) paths for our proposed model. By selecting appropriate model parameters, the propagation characteristics of our GSCM are demonstrated to closely emulate those of the COST-259 model.
Physical Layer Security for NOMA Systems: Requirements, Issues, and Recommendations
Aug 10, 2023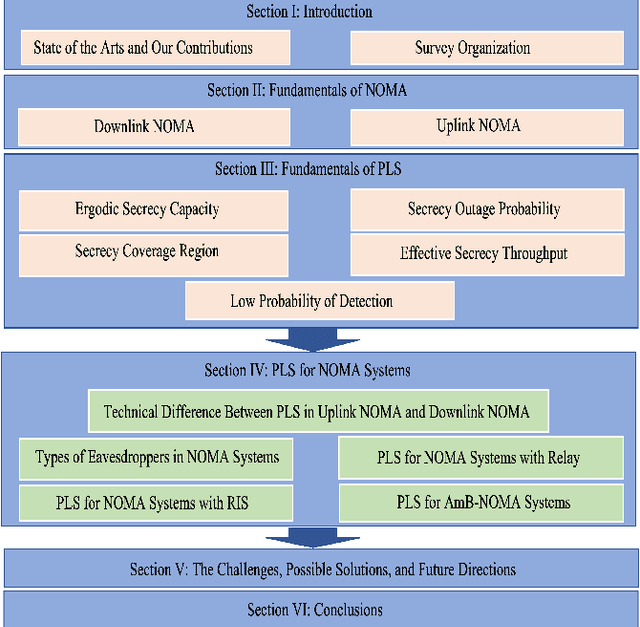
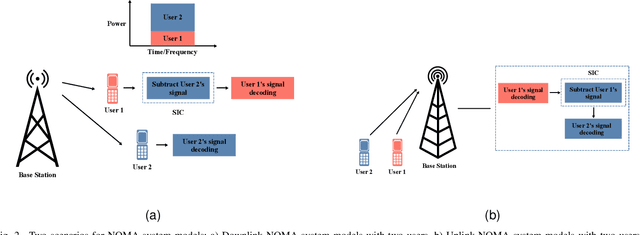
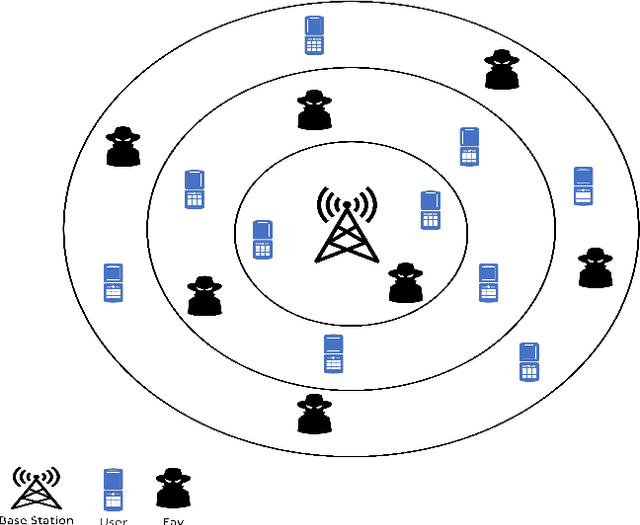
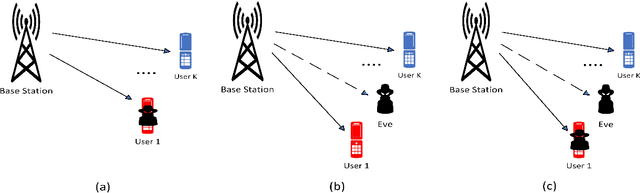
Non-orthogonal multiple access (NOMA) has been viewed as a potential candidate for the upcoming generation of wireless communication systems. Comparing to traditional orthogonal multiple access (OMA), multiplexing users in the same time-frequency resource block can increase the number of served users and improve the efficiency of the systems in terms of spectral efficiency. Nevertheless, from a security view-point, when multiple users are utilizing the same time-frequency resource, there may be concerns regarding keeping information confidential. In this context, physical layer security (PLS) has been introduced as a supplement of protection to conventional encryption techniques by making use of the random nature of wireless transmission media for ensuring communication secrecy. The recent years have seen significant interests in PLS being applied to NOMA networks. Numerous scenarios have been investigated to assess the security of NOMA systems, including when active and passive eavesdroppers are present, as well as when these systems are combined with relay and reconfigurable intelligent surfaces (RIS). Additionally, the security of the ambient backscatter (AmB)-NOMA systems are other issues that have lately drawn a lot of attention. In this paper, a thorough analysis of the PLS-assisted NOMA systems research state-of-the-art is presented. In this regard, we begin by outlining the foundations of NOMA and PLS, respectively. Following that, we discuss the PLS performances for NOMA systems in four categories depending on the type of the eavesdropper, the existence of relay, RIS, and AmB systems in different conditions. Finally, a thorough explanation of the most recent PLS-assisted NOMA systems is given.
* 17 pages, 4 figures
Comprehensive Analysis of Network Robustness Evaluation Based on Convolutional Neural Networks with Spatial Pyramid Pooling
Aug 10, 2023Connectivity robustness, a crucial aspect for understanding, optimizing, and repairing complex networks, has traditionally been evaluated through time-consuming and often impractical simulations. Fortunately, machine learning provides a new avenue for addressing this challenge. However, several key issues remain unresolved, including the performance in more general edge removal scenarios, capturing robustness through attack curves instead of directly training for robustness, scalability of predictive tasks, and transferability of predictive capabilities. In this paper, we address these challenges by designing a convolutional neural networks (CNN) model with spatial pyramid pooling networks (SPP-net), adapting existing evaluation metrics, redesigning the attack modes, introducing appropriate filtering rules, and incorporating the value of robustness as training data. The results demonstrate the thoroughness of the proposed CNN framework in addressing the challenges of high computational time across various network types, failure component types and failure scenarios. However, the performance of the proposed CNN model varies: for evaluation tasks that are consistent with the trained network type, the proposed CNN model consistently achieves accurate evaluations of both attack curves and robustness values across all removal scenarios. When the predicted network type differs from the trained network, the CNN model still demonstrates favorable performance in the scenario of random node failure, showcasing its scalability and performance transferability. Nevertheless, the performance falls short of expectations in other removal scenarios. This observed scenario-sensitivity in the evaluation of network features has been overlooked in previous studies and necessitates further attention and optimization. Lastly, we discuss important unresolved questions and further investigation.