 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Video Depth Stabilizer
Aug 10, 2023
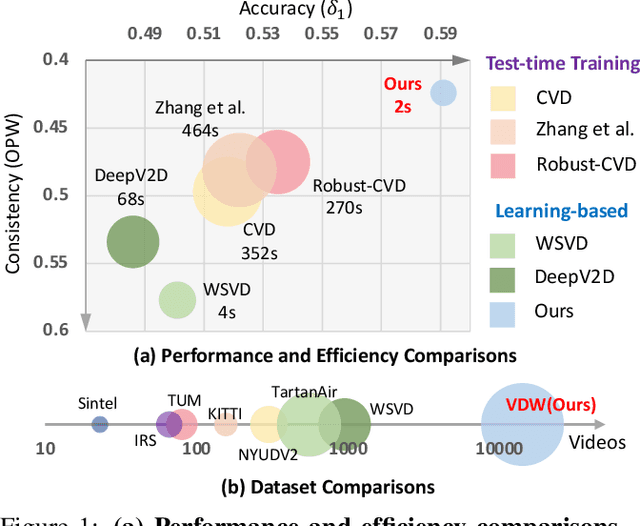
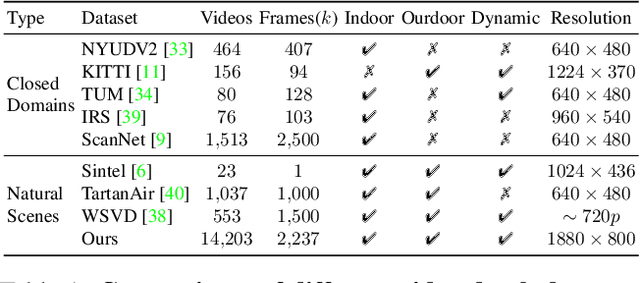
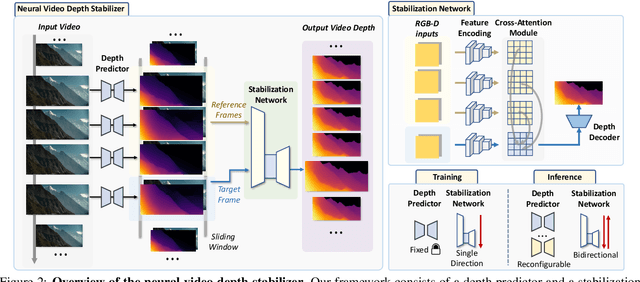
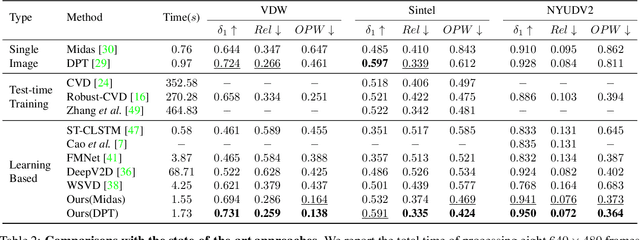
Video depth estimation aims to infer temporally consistent depth. Some methods achieve temporal consistency by finetuning a single-image depth model during test time using geometry and re-projection constraints, which is inefficient and not robust. An alternative approach is to learn how to enforce temporal consistency from data, but this requires well-designed models and sufficient video depth data. To address these challenges, we propose a plug-and-play framework called Neural Video Depth Stabilizer (NVDS) that stabilizes inconsistent depth estimations and can be applied to different single-image depth models without extra effort. We also introduce a large-scale dataset, Video Depth in the Wild (VDW), which consists of 14,203 videos with over two million frames, making it the largest natural-scene video depth dataset to our knowledge. We evaluate our method on the VDW dataset as well as two public benchmarks and demonstrate significant improvements in consistency, accuracy, and efficiency compared to previous approaches. Our work serves as a solid baseline and provides a data foundation for learning-based video depth models. We will release our dataset and code for future research.
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
Aug 10, 2023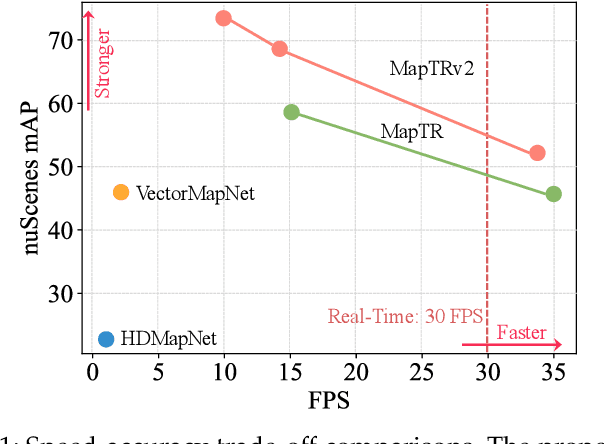
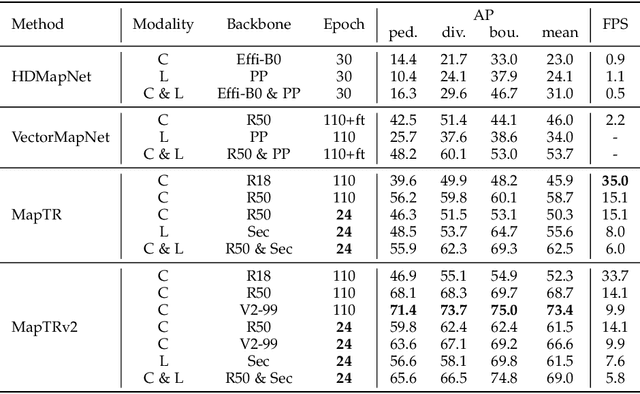
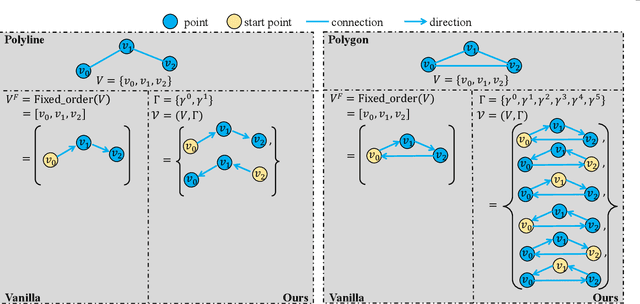
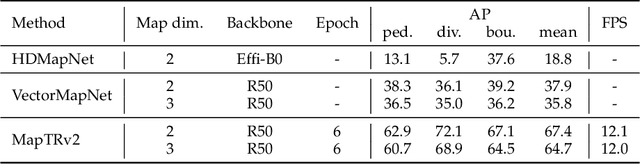
High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present \textbf{Map} \textbf{TR}ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, \ie, modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes. Code and more demos are available at \url{https://github.com/hustvl/MapTR} for facilitating further studies and applications.
Exploring XAI for the Arts: Explaining Latent Space in Generative Music
Aug 10, 2023
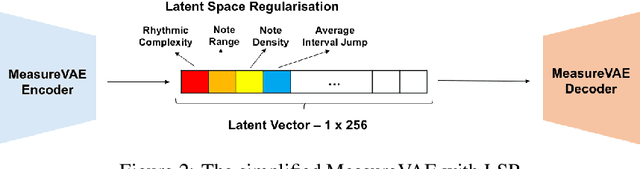
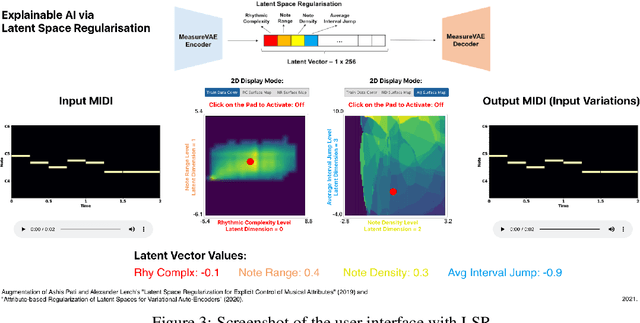

Explainable AI has the potential to support more interactive and fluid co-creative AI systems which can creatively collaborate with people. To do this, creative AI models need to be amenable to debugging by offering eXplainable AI (XAI) features which are inspectable, understandable, and modifiable. However, currently there is very little XAI for the arts. In this work, we demonstrate how a latent variable model for music generation can be made more explainable; specifically we extend MeasureVAE which generates measures of music. We increase the explainability of the model by: i) using latent space regularisation to force some specific dimensions of the latent space to map to meaningful musical attributes, ii) providing a user interface feedback loop to allow people to adjust dimensions of the latent space and observe the results of these changes in real-time, iii) providing a visualisation of the musical attributes in the latent space to help people understand and predict the effect of changes to latent space dimensions. We suggest that in doing so we bridge the gap between the latent space and the generated musical outcomes in a meaningful way which makes the model and its outputs more explainable and more debuggable.
Effects of Daily News Sentiment on Stock Price Forecasting
Aug 02, 2023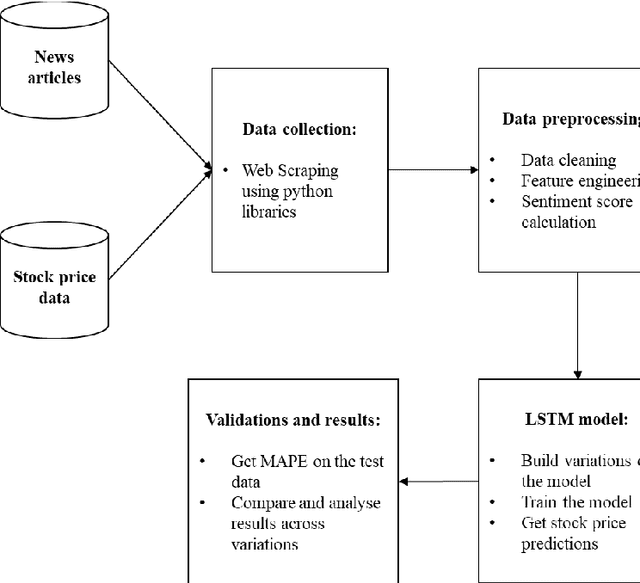
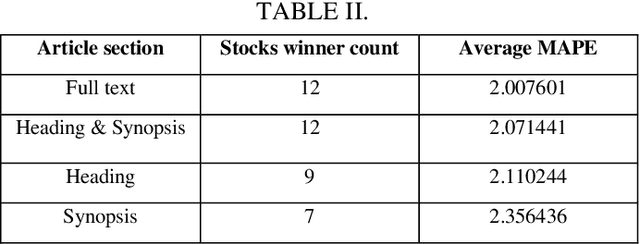
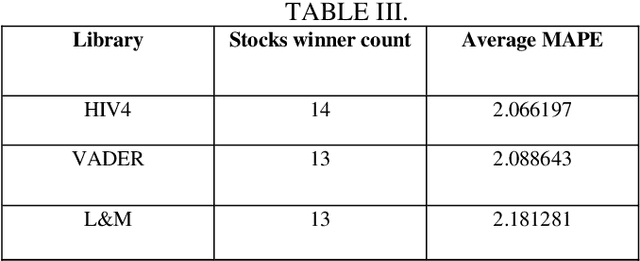
Predicting future prices of a stock is an arduous task to perform. However, incorporating additional elements can significantly improve our predictions, rather than relying solely on a stock's historical price data to forecast its future price. Studies have demonstrated that investor sentiment, which is impacted by daily news about the company, can have a significant impact on stock price swings. There are numerous sources from which we can get this information, but they are cluttered with a lot of noise, making it difficult to accurately extract the sentiments from them. Hence the focus of our research is to design an efficient system to capture the sentiments from the news about the NITY50 stocks and investigate how much the financial news sentiment of these stocks are affecting their prices over a period of time. This paper presents a robust data collection and preprocessing framework to create a news database for a timeline of around 3.7 years, consisting of almost half a million news articles. We also capture the stock price information for this timeline and create multiple time series data, that include the sentiment scores from various sections of the article, calculated using different sentiment libraries. Based on this, we fit several LSTM models to forecast the stock prices, with and without using the sentiment scores as features and compare their performances.
YUDO: YOLO for Uniform Directed Object Detection
Aug 08, 2023
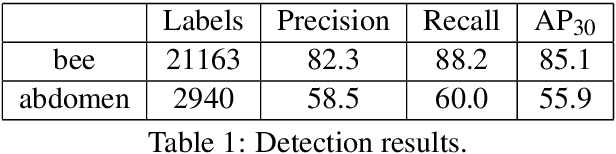
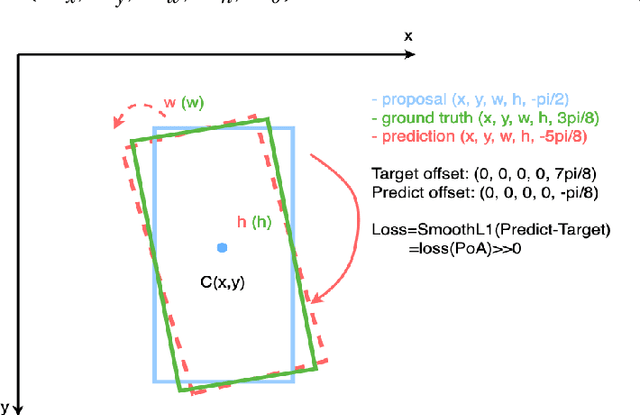
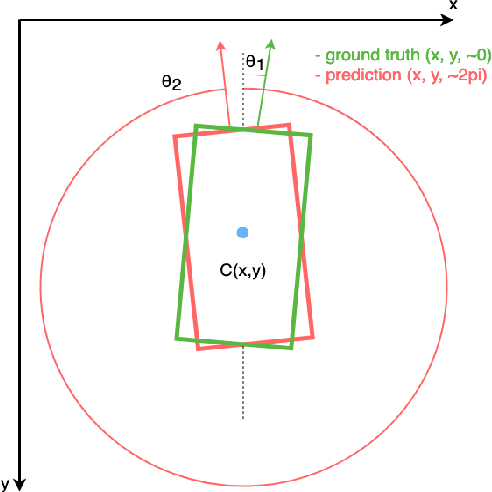
This paper presents an efficient way of detecting directed objects by predicting their center coordinates and direction angle. Since the objects are of uniform size, the proposed model works without predicting the object's width and height. The dataset used for this problem is presented in Honeybee Segmentation and Tracking Datasets project. One of the contributions of this work is an examination of the ability of the standard real-time object detection architecture like YoloV7 to be customized for position and direction detection. A very efficient, tiny version of the architecture is used in this approach. Moreover, only one of three detection heads without anchors is sufficient for this task. We also introduce the extended Skew Intersection over Union (SkewIoU) calculation for rotated boxes - directed IoU (DirIoU), which includes an absolute angle difference. DirIoU is used both in the matching procedure of target and predicted bounding boxes for mAP calculation, and in the NMS filtering procedure. The code and models are available at https://github.com/djordjened92/yudo.
A Comparative Study of Sentence Embedding Models for Assessing Semantic Variation
Aug 08, 2023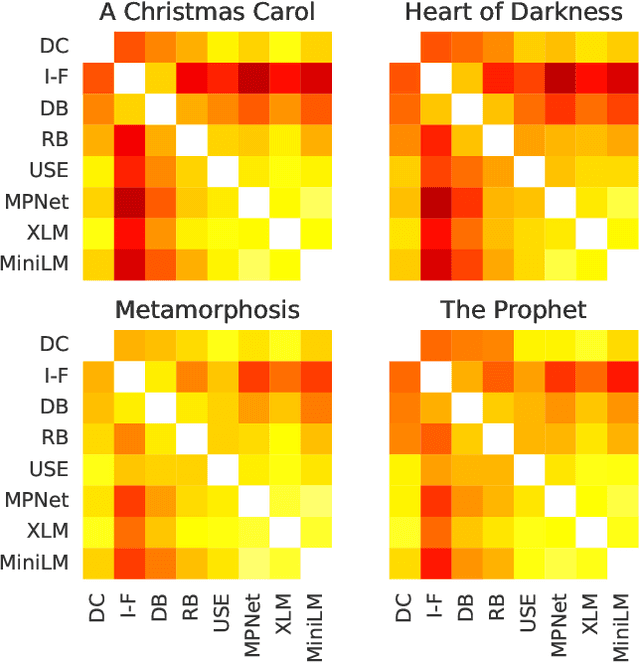
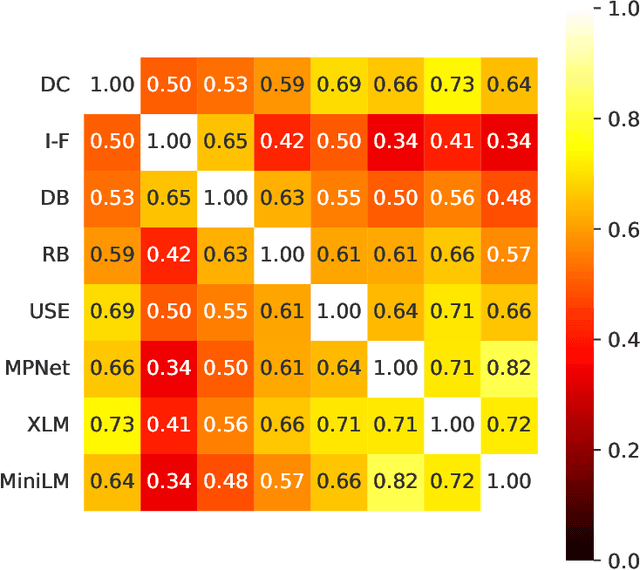
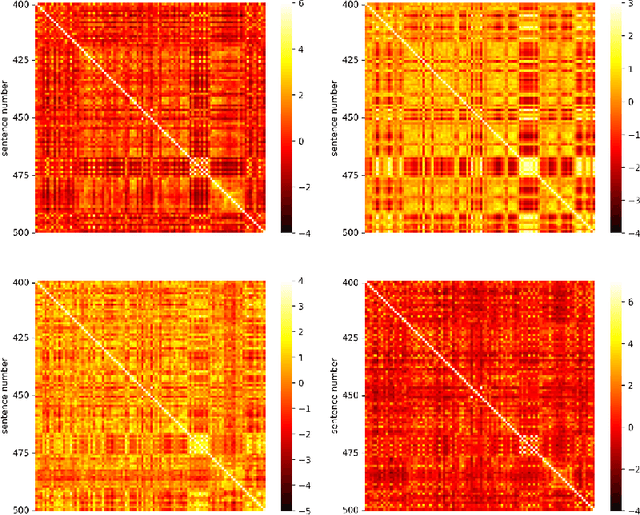
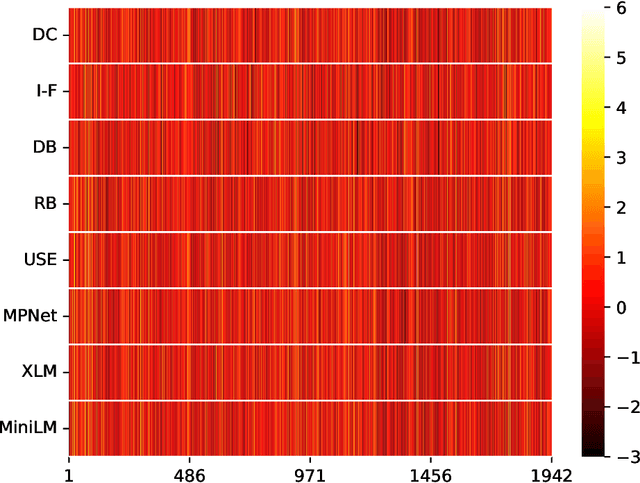
Analyzing the pattern of semantic variation in long real-world texts such as books or transcripts is interesting from the stylistic, cognitive, and linguistic perspectives. It is also useful for applications such as text segmentation, document summarization, and detection of semantic novelty. The recent emergence of several vector-space methods for sentence embedding has made such analysis feasible. However, this raises the issue of how consistent and meaningful the semantic representations produced by various methods are in themselves. In this paper, we compare several recent sentence embedding methods via time-series of semantic similarity between successive sentences and matrices of pairwise sentence similarity for multiple books of literature. In contrast to previous work using target tasks and curated datasets to compare sentence embedding methods, our approach provides an evaluation of the methods 'in the wild'. We find that most of the sentence embedding methods considered do infer highly correlated patterns of semantic similarity in a given document, but show interesting differences.
Physics-driven universal twin-image removal network for digital in-line holographic microscopy
Aug 08, 2023Digital in-line holographic microscopy (DIHM) enables efficient and cost-effective computational quantitative phase imaging with a large field of view, making it valuable for studying cell motility, migration, and bio-microfluidics. However, the quality of DIHM reconstructions is compromised by twin-image noise, posing a significant challenge. Conventional methods for mitigating this noise involve complex hardware setups or time-consuming algorithms with often limited effectiveness. In this work, we propose UTIRnet, a deep learning solution for fast, robust, and universally applicable twin-image suppression, trained exclusively on numerically generated datasets. The availability of open-source UTIRnet codes facilitates its implementation in various DIHM systems without the need for extensive experimental training data. Notably, our network ensures the consistency of reconstruction results with input holograms, imparting a physics-based foundation and enhancing reliability compared to conventional deep learning approaches. Experimental verification was conducted among others on live neural glial cell culture migration sensing, which is crucial for neurodegenerative disease research.
A General Implicit Framework for Fast NeRF Composition and Rendering
Aug 09, 2023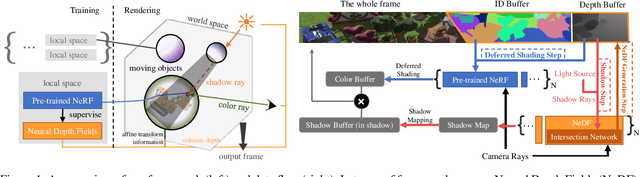

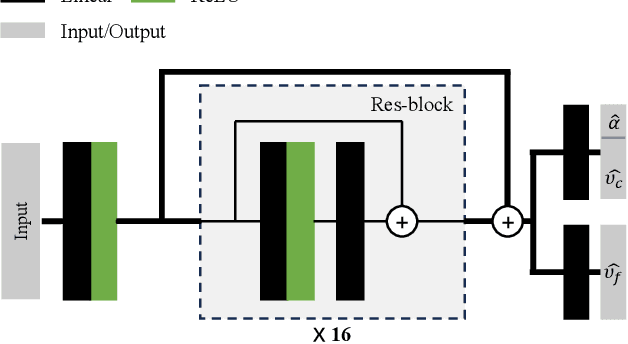
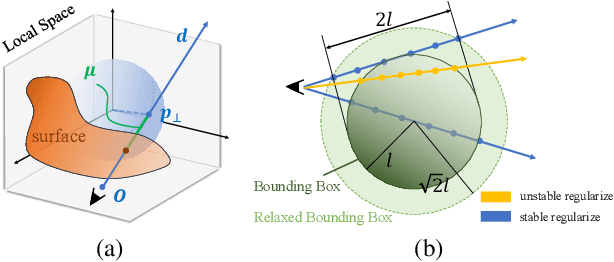
Recently, a variety of Neural radiance fields methods have garnered remarkable success in high render speed. However, current accelerating methods is specialized and not compatible for various implicit method, which prevent a real-time composition over different kinds of NeRF works. Since NeRF relies on sampling along rays, it's possible to provide a guidance generally. We propose a general implicit pipeline to rapidly compose NeRF objects. This new method enables the casting of dynamic shadows within or between objects using analytical light sources while allowing multiple NeRF objects to be seamlessly placed and rendered together with any arbitrary rigid transformations. Mainly, our work introduces a new surface representation known as Neural Depth Fields (NeDF) that quickly determines the spatial relationship between objects by allowing direct intersection computation between rays and implicit surfaces. It leverages an intersection neural network to query NeRF for acceleration instead of depending on an explicit spatial structure.Our proposed method is the first to enable both the progressive and interactive composition of NeRF objects. Additionally, it also serves as a previewing plugin for a range of existing NeRF works.
A Fast and Optimal Learning-based Path Planning Method for Planetary Rovers
Aug 09, 2023
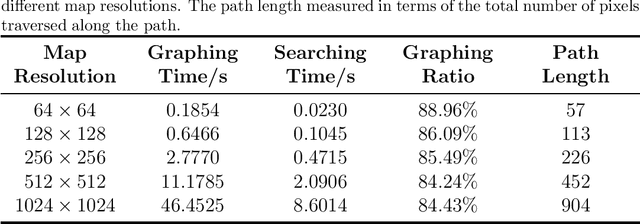

Intelligent autonomous path planning is crucial to improve the exploration efficiency of planetary rovers. In this paper, we propose a learning-based method to quickly search for optimal paths in an elevation map, which is called NNPP. The NNPP model learns semantic information about start and goal locations, as well as map representations, from numerous pre-annotated optimal path demonstrations, and produces a probabilistic distribution over each pixel representing the likelihood of it belonging to an optimal path on the map. More specifically, the paper computes the traversal cost for each grid cell from the slope, roughness and elevation difference obtained from the DEM. Subsequently, the start and goal locations are encoded using a Gaussian distribution and different location encoding parameters are analyzed for their effect on model performance. After training, the NNPP model is able to perform path planning on novel maps. Experiments show that the guidance field generated by the NNPP model can significantly reduce the search time for optimal paths under the same hardware conditions, and the advantage of NNPP increases with the scale of the map.
Evaluating Pedestrian Trajectory Prediction Methods for the Application in Autonomous Driving
Aug 09, 2023In this paper, the state of the art in the field of pedestrian trajectory prediction is evaluated alongside the constant velocity model (CVM) with respect to its applicability in autonomous vehicles. The evaluation is conducted on the widely-used ETH/UCY dataset where the Average Displacement Error (ADE) and the Final Displacement Error (FDE) are reported. To align with requirements in real-world applications, modifications are made to the input features of the initially proposed models. An ablation study is conducted to examine the influence of the observed motion history on the prediction performance, thereby establishing a better understanding of its impact. Additionally, the inference time of each model is measured to evaluate the scalability of each model when confronted with varying amounts of agents. The results demonstrate that simple models remain competitive when generating single trajectories, and certain features commonly thought of as useful have little impact on the overall performance across different architectures. Based on these findings, recommendations are proposed to guide the future development of trajectory prediction algorithms.