 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatial-information Guided Adaptive Context-aware Network for Efficient RGB-D Semantic Segmentation
Aug 11, 2023
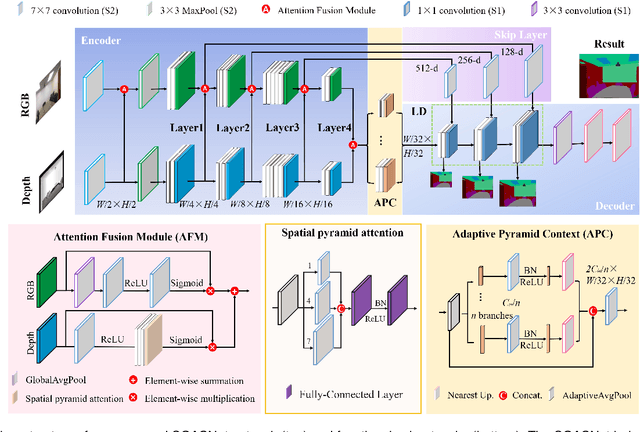
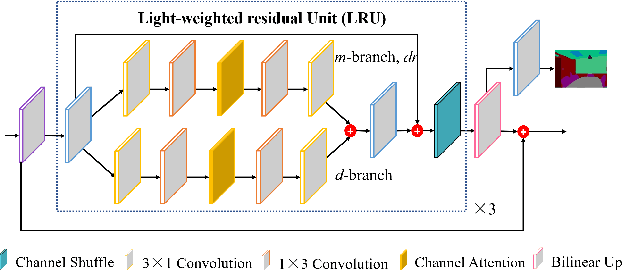
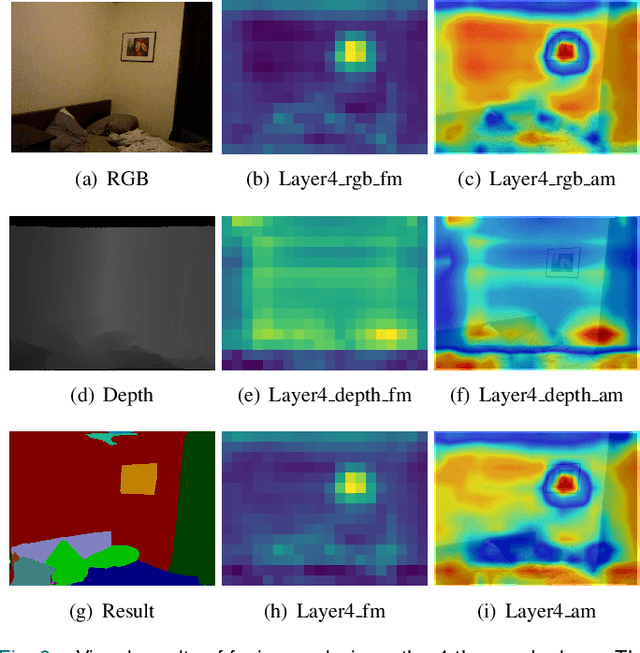
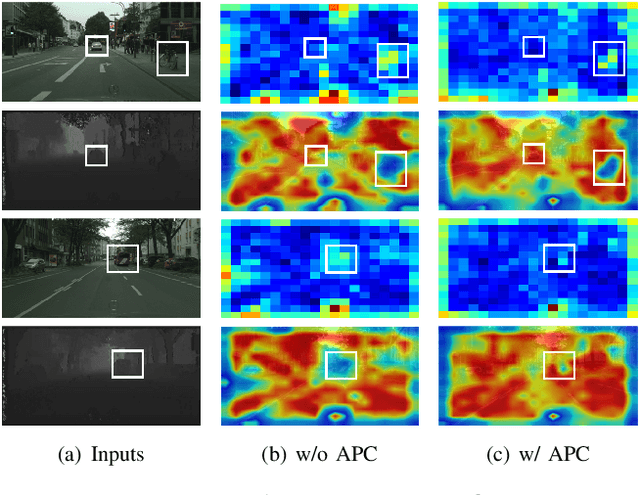
Efficient RGB-D semantic segmentation has received considerable attention in mobile robots, which plays a vital role in analyzing and recognizing environmental information. According to previous studies, depth information can provide corresponding geometric relationships for objects and scenes, but actual depth data usually exist as noise. To avoid unfavorable effects on segmentation accuracy and computation, it is necessary to design an efficient framework to leverage cross-modal correlations and complementary cues. In this paper, we propose an efficient lightweight encoder-decoder network that reduces the computational parameters and guarantees the robustness of the algorithm. Working with channel and spatial fusion attention modules, our network effectively captures multi-level RGB-D features. A globally guided local affinity context module is proposed to obtain sufficient high-level context information. The decoder utilizes a lightweight residual unit that combines short- and long-distance information with a few redundant computations. Experimental results on NYUv2, SUN RGB-D, and Cityscapes datasets show that our method achieves a better trade-off among segmentation accuracy, inference time, and parameters than the state-of-the-art methods. The source code will be at https://github.com/MVME-HBUT/SGACNet
Uncertainty Quantification for Image-based Traffic Prediction across Cities
Aug 11, 2023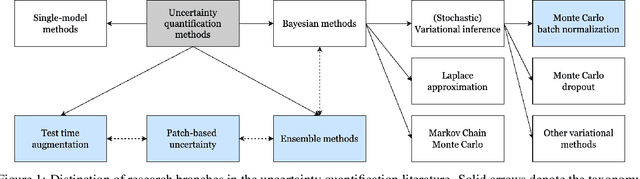
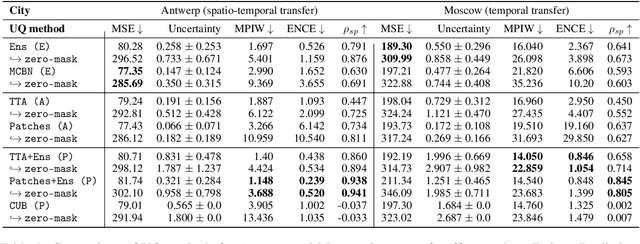
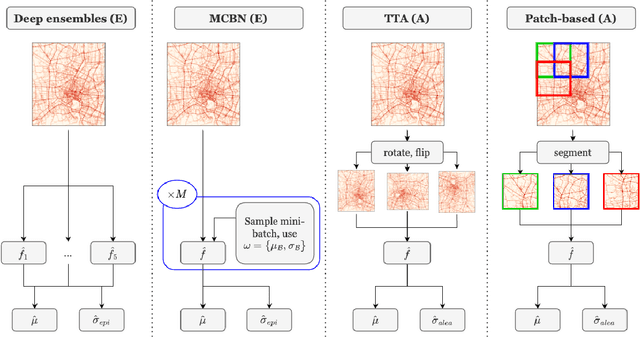

Despite the strong predictive performance of deep learning models for traffic prediction, their widespread deployment in real-world intelligent transportation systems has been restrained by a lack of interpretability. Uncertainty quantification (UQ) methods provide an approach to induce probabilistic reasoning, improve decision-making and enhance model deployment potential. To gain a comprehensive picture of the usefulness of existing UQ methods for traffic prediction and the relation between obtained uncertainties and city-wide traffic dynamics, we investigate their application to a large-scale image-based traffic dataset spanning multiple cities and time periods. We compare two epistemic and two aleatoric UQ methods on both temporal and spatio-temporal transfer tasks, and find that meaningful uncertainty estimates can be recovered. We further demonstrate how uncertainty estimates can be employed for unsupervised outlier detection on changes in city traffic dynamics. We find that our approach can capture both temporal and spatial effects on traffic behaviour in a representative case study for the city of Moscow. Our work presents a further step towards boosting uncertainty awareness in traffic prediction tasks, and aims to highlight the value contribution of UQ methods to a better understanding of city traffic dynamics.
Phased Deep Spatio-temporal Learning for Highway Traffic Volume Prediction
Aug 11, 2023
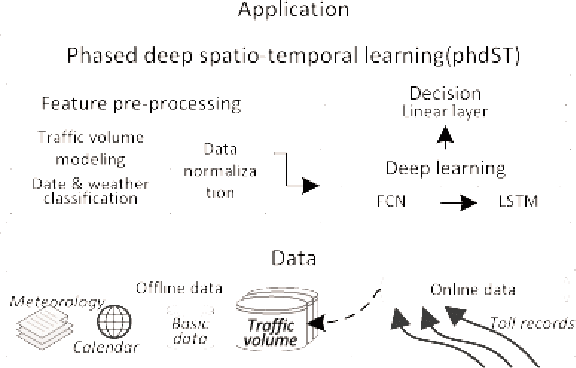
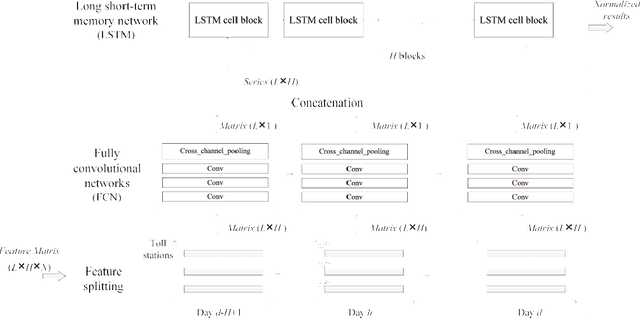
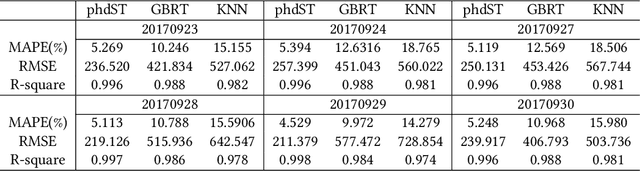
Inter-city highway transportation is significant for citizens' modern urban life and generates heterogeneous sensory data with spatio-temporal characteristics. As a routine analysis in transportation domain, daily traffic volume estimation faces challenges for highway toll stations including lacking of exploration of correlative spatio-temporal features from a long-term perspective and effective means to deal with data imbalance which always deteriorates the predictive performance. In this paper, a deep spatio-temporal learning method is proposed to predict daily traffic volume in three phases. In feature pre-processing phase, data is normalized elaborately according to latent long-tail distribution. In spatio-temporal learning phase, a hybrid model is employed combining fully convolution network (FCN) and long short-term memory (LSTM), which considers time, space, meteorology, and calendar from heterogeneous data. In decision phase, traffic volumes on a coming day at network-wide toll stations would be achieved effectively, which is especially calibrated for vital few highway stations. Using real-world data from one Chinese provincial highway, extensive experiments show our method has distinct improvement for predictive accuracy than various traditional models, reaching 5.269 and 0.997 in MPAE and R-squre metrics, respectively.
How neural networks learn to classify chaotic time series
Jun 04, 2023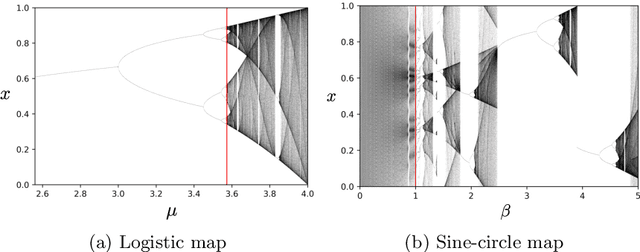

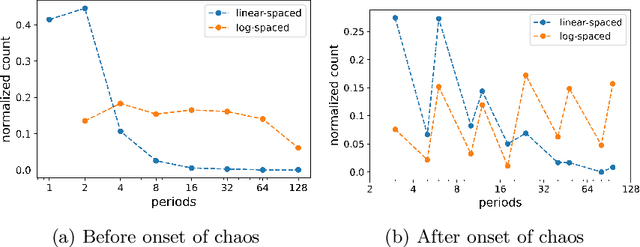
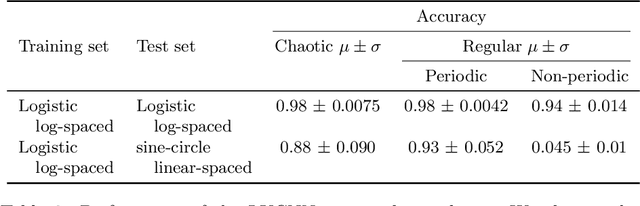
Neural networks are increasingly employed to model, analyze and control non-linear dynamical systems ranging from physics to biology. Owing to their universal approximation capabilities, they regularly outperform state-of-the-art model-driven methods in terms of accuracy, computational speed, and/or control capabilities. On the other hand, neural networks are very often they are taken as black boxes whose explainability is challenged, among others, by huge amounts of trainable parameters. In this paper, we tackle the outstanding issue of analyzing the inner workings of neural networks trained to classify regular-versus-chaotic time series. This setting, well-studied in dynamical systems, enables thorough formal analyses. We focus specifically on a family of networks dubbed Large Kernel Convolutional Neural Networks (LKCNN), recently introduced by Boull\'{e} et al. (2021). These non-recursive networks have been shown to outperform other established architectures (e.g. residual networks, shallow neural networks and fully convolutional networks) at this classification task. Furthermore, they outperform ``manual'' classification approaches based on direct reconstruction of the Lyapunov exponent. We find that LKCNNs use qualitative properties of the input sequence. In particular, we show that the relation between input periodicity and activation periodicity is key for the performance of LKCNN models. Low performing models show, in fact, analogous periodic activations to random untrained models. This could give very general criteria for identifying, a priori, trained models that have poor accuracy.
Slot Induction via Pre-trained Language Model Probing and Multi-level Contrastive Learning
Aug 09, 2023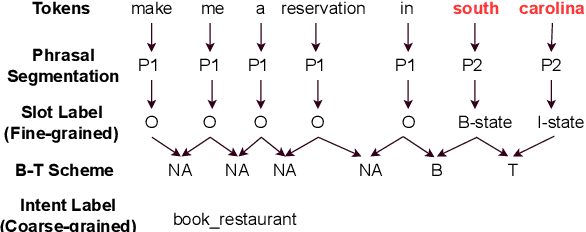
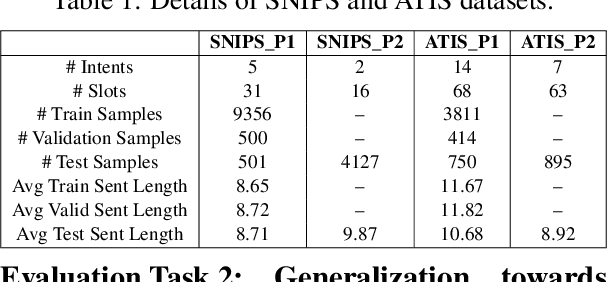
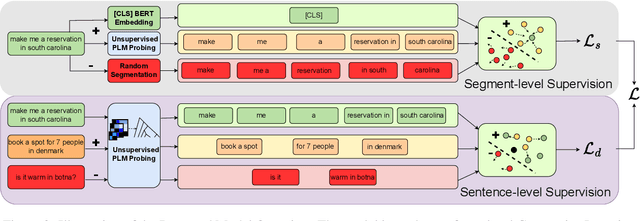
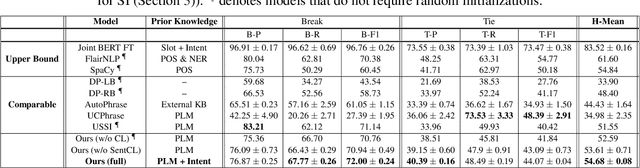
Recent advanced methods in Natural Language Understanding for Task-oriented Dialogue (TOD) Systems (e.g., intent detection and slot filling) require a large amount of annotated data to achieve competitive performance. In reality, token-level annotations (slot labels) are time-consuming and difficult to acquire. In this work, we study the Slot Induction (SI) task whose objective is to induce slot boundaries without explicit knowledge of token-level slot annotations. We propose leveraging Unsupervised Pre-trained Language Model (PLM) Probing and Contrastive Learning mechanism to exploit (1) unsupervised semantic knowledge extracted from PLM, and (2) additional sentence-level intent label signals available from TOD. Our approach is shown to be effective in SI task and capable of bridging the gaps with token-level supervised models on two NLU benchmark datasets. When generalized to emerging intents, our SI objectives also provide enhanced slot label representations, leading to improved performance on the Slot Filling tasks.
Adapting Foundation Models for Information Synthesis of Wireless Communication Specifications
Aug 09, 2023

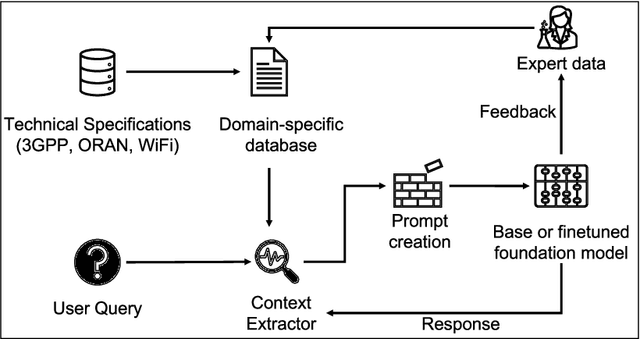

Existing approaches to understanding, developing and researching modern wireless communication technologies involves time-intensive and arduous process of sifting through numerous webpages and technical specification documents, gathering the required information and synthesizing it. This paper presents NextGen Communications Copilot, a conversational artificial intelligence tool for information synthesis of wireless communication specifications. The system builds on top of recent advancements in foundation models and consists of three key additional components: a domain-specific database, a context extractor, and a feedback mechanism. The system appends user queries with concise and query-dependent contextual information extracted from a database of wireless technical specifications and incorporates tools for expert feedback and data contributions. On evaluation using a benchmark dataset of queries and reference responses created by subject matter experts, the system demonstrated more relevant and accurate answers with an average BLEU score and BERTScore F1-measure of 0.37 and 0.79 respectively compared to the corresponding values of 0.07 and 0.59 achieved by state-of-the-art tools like ChatGPT.
Generating News-Centric Crossword Puzzles As A Constraint Satisfaction and Optimization Problem
Aug 09, 2023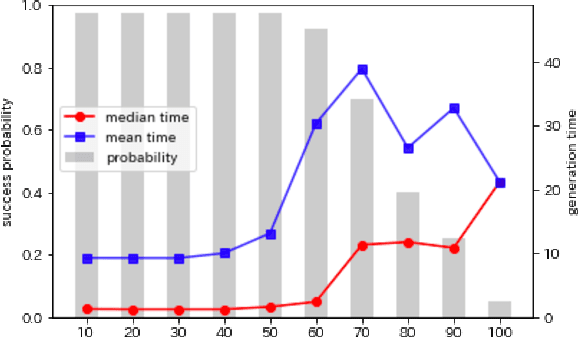
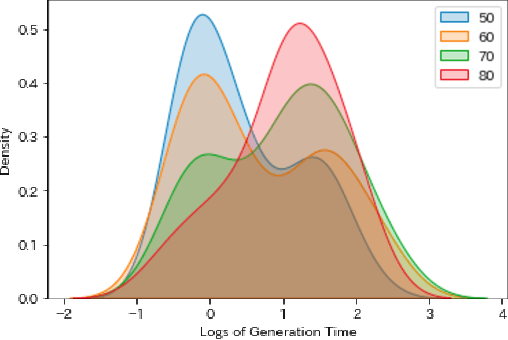
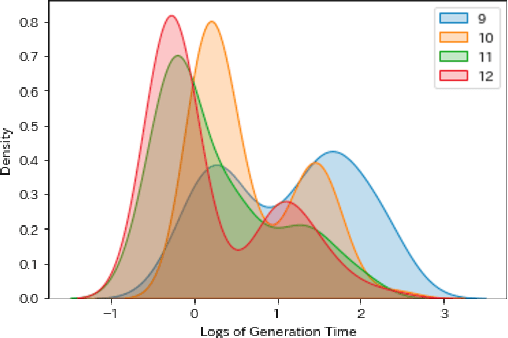
Crossword puzzles have traditionally served not only as entertainment but also as an educational tool that can be used to acquire vocabulary and language proficiency. One strategy to enhance the educational purpose is personalization, such as including more words on a particular topic. This paper focuses on the case of encouraging people's interest in news and proposes a framework for automatically generating news-centric crossword puzzles. We designed possible scenarios and built a prototype as a constraint satisfaction and optimization problem, that is, containing as many news-derived words as possible. Our experiments reported the generation probabilities and time required under several conditions. The results showed that news-centric crossword puzzles can be generated even with few news-derived words. We summarize the current issues and future research directions through a qualitative evaluation of the prototype. This is the first proposal that a formulation of a constraint satisfaction and optimization problem can be beneficial as an educational application.
Foreground Object Search by Distilling Composite Image Feature
Aug 09, 2023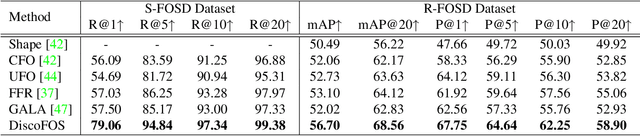
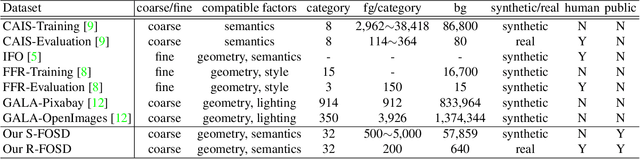
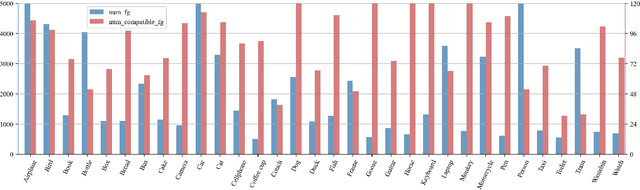
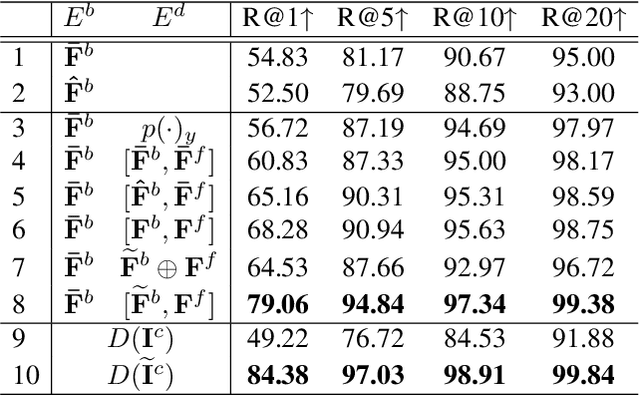
Foreground object search (FOS) aims to find compatible foreground objects for a given background image, producing realistic composite image. We observe that competitive retrieval performance could be achieved by using a discriminator to predict the compatibility of composite image, but this approach has unaffordable time cost. To this end, we propose a novel FOS method via distilling composite feature (DiscoFOS). Specifically, the abovementioned discriminator serves as teacher network. The student network employs two encoders to extract foreground feature and background feature. Their interaction output is enforced to match the composite image feature from the teacher network. Additionally, previous works did not release their datasets, so we contribute two datasets for FOS task: S-FOSD dataset with synthetic composite images and R-FOSD dataset with real composite images. Extensive experiments on our two datasets demonstrate the superiority of the proposed method over previous approaches. The dataset and code are available at https://github.com/bcmi/Foreground-Object-Search-Dataset-FOSD.
Enhancing Mobile Privacy and Security: A Face Skin Patch-Based Anti-Spoofing Approach
Aug 09, 2023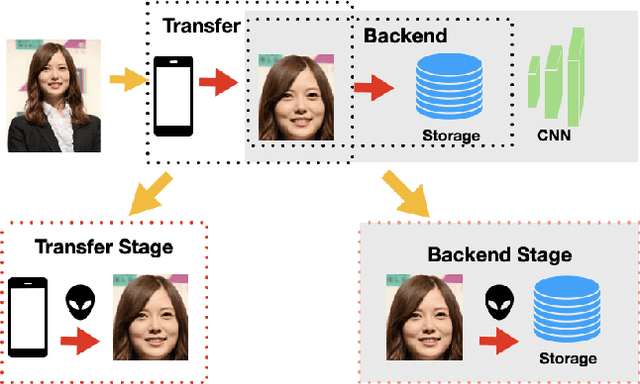
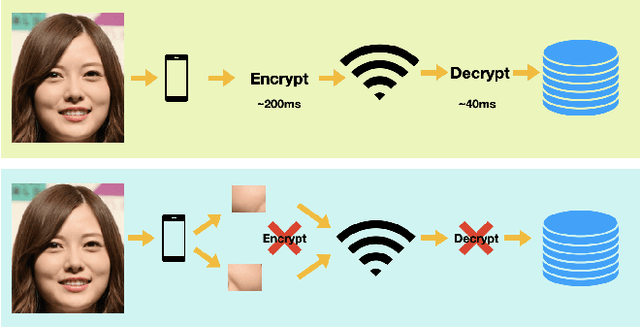
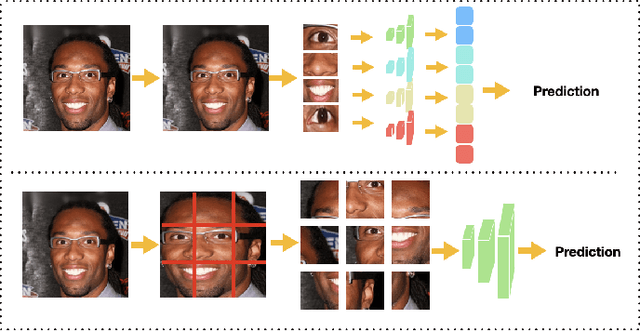
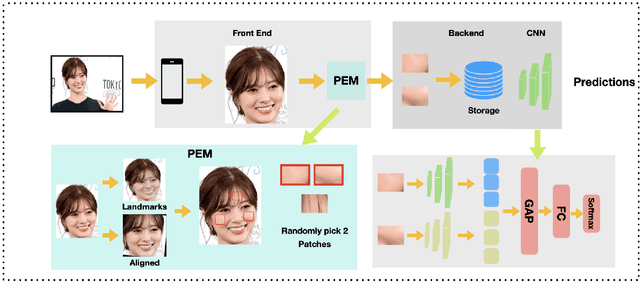
As Facial Recognition System(FRS) is widely applied in areas such as access control and mobile payments due to its convenience and high accuracy. The security of facial recognition is also highly regarded. The Face anti-spoofing system(FAS) for face recognition is an important component used to enhance the security of face recognition systems. Traditional FAS used images containing identity information to detect spoofing traces, however there is a risk of privacy leakage during the transmission and storage of these images. Besides, the encryption and decryption of these privacy-sensitive data takes too long compared to inference time by FAS model. To address the above issues, we propose a face anti-spoofing algorithm based on facial skin patches leveraging pure facial skin patch images as input, which contain no privacy information, no encryption or decryption is needed for these images. We conduct experiments on several public datasets, the results prove that our algorithm has demonstrated superiority in both accuracy and speed.
Enhancing AUV Autonomy With Model Predictive Path Integral Control
Aug 10, 2023
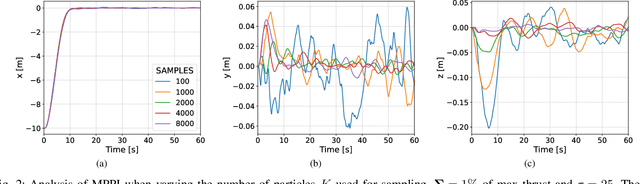
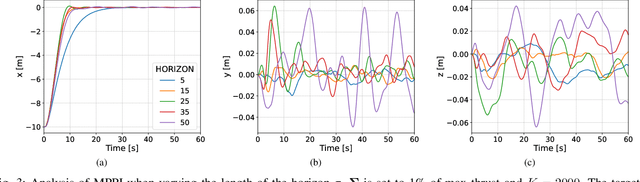
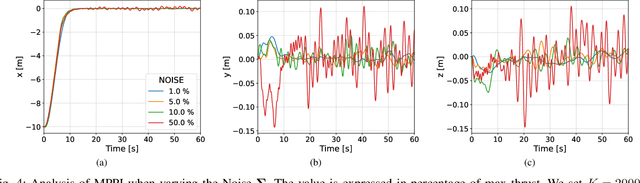
Autonomous underwater vehicles (AUVs) play a crucial role in surveying marine environments, carrying out underwater inspection tasks, and ocean exploration. However, in order to ensure that the AUV is able to carry out its mission successfully, a control system capable of adapting to changing environmental conditions is required. Furthermore, to ensure the robotic platform's safe operation, the onboard controller should be able to operate under certain constraints. In this work, we investigate the feasibility of Model Predictive Path Integral Control (MPPI) for the control of an AUV. We utilise a non-linear model of the AUV to propagate the samples of the MPPI, which allow us to compute the control action in real time. We provide a detailed evaluation of the effect of the main hyperparameters on the performance of the MPPI controller. Furthermore, we compared the performance of the proposed method with a classical PID and Cascade PID approach, demonstrating the superiority of our proposed controller. Finally, we present results where environmental constraints are added and show how MPPI can handle them by simply incorporating those constraints in the cost function.