 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IVP-VAE: Modeling EHR Time Series with Initial Value Problem Solvers
May 11, 2023
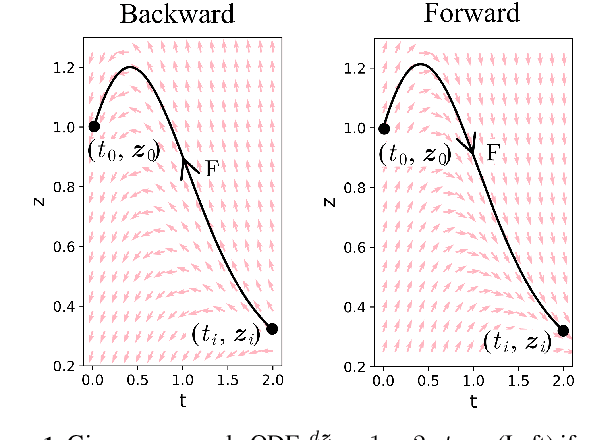
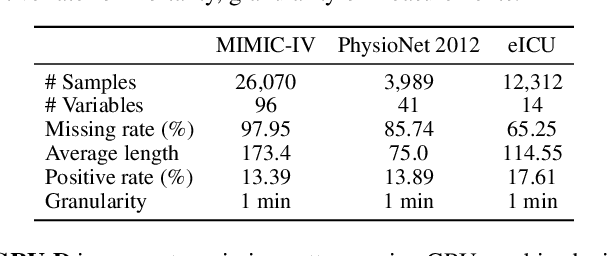
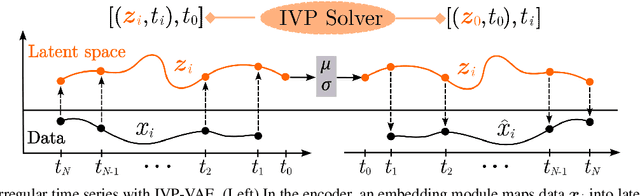
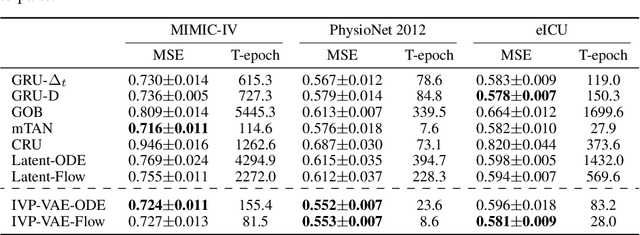
Continuous-time models such as Neural ODEs and Neural Flows have shown promising results in analyzing irregularly sampled time series frequently encountered in electronic health records. Based on these models, time series are typically processed with a hybrid of an initial value problem (IVP) solver and a recurrent neural network within the variational autoencoder architecture. Sequentially solving IVPs makes such models computationally less efficient. In this paper, we propose to model time series purely with continuous processes whose state evolution can be approximated directly by IVPs. This eliminates the need for recurrent computation and enables multiple states to evolve in parallel. We further fuse the encoder and decoder with one IVP solver based on its invertibility, which leads to fewer parameters and faster convergence. Experiments on three real-world datasets show that the proposed approach achieves comparable extrapolation and classification performance while gaining more than one order of magnitude speedup over other continuous-time counterparts.
Does AI for science need another ImageNet Or totally different benchmarks? A case study of machine learning force fields
Aug 11, 2023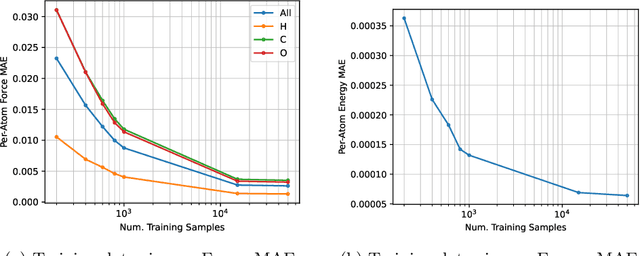
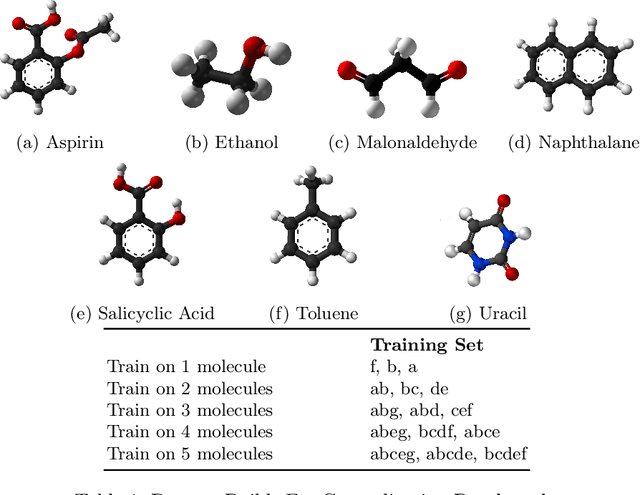
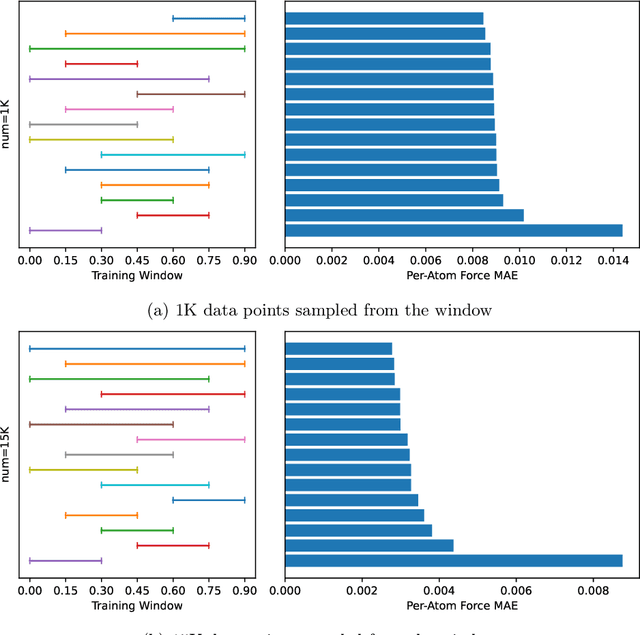
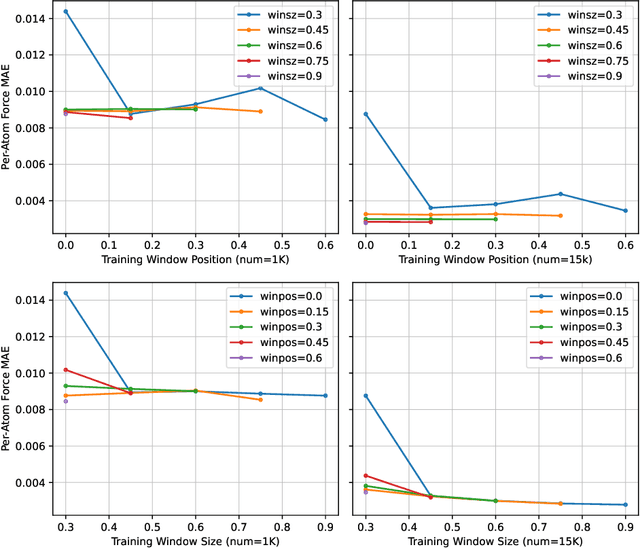
AI for science (AI4S) is an emerging research field that aims to enhance the accuracy and speed of scientific computing tasks using machine learning methods. Traditional AI benchmarking methods struggle to adapt to the unique challenges posed by AI4S because they assume data in training, testing, and future real-world queries are independent and identically distributed, while AI4S workloads anticipate out-of-distribution problem instances. This paper investigates the need for a novel approach to effectively benchmark AI for science, using the machine learning force field (MLFF) as a case study. MLFF is a method to accelerate molecular dynamics (MD) simulation with low computational cost and high accuracy. We identify various missed opportunities in scientifically meaningful benchmarking and propose solutions to evaluate MLFF models, specifically in the aspects of sample efficiency, time domain sensitivity, and cross-dataset generalization capabilities. By setting up the problem instantiation similar to the actual scientific applications, more meaningful performance metrics from the benchmark can be achieved. This suite of metrics has demonstrated a better ability to assess a model's performance in real-world scientific applications, in contrast to traditional AI benchmarking methodologies. This work is a component of the SAIBench project, an AI4S benchmarking suite. The project homepage is https://www.computercouncil.org/SAIBench.
Topic-Level Bayesian Surprise and Serendipity for Recommender Systems
Aug 11, 2023
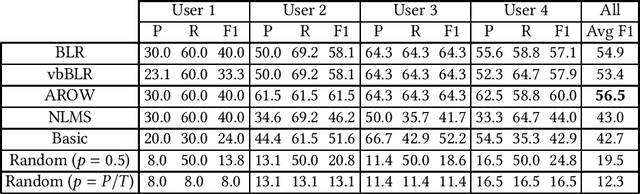
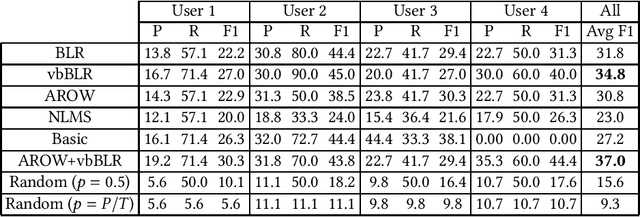
A recommender system that optimizes its recommendations solely to fit a user's history of ratings for consumed items can create a filter bubble, wherein the user does not get to experience items from novel, unseen categories. One approach to mitigate this undesired behavior is to recommend items with high potential for serendipity, namely surprising items that are likely to be highly rated. In this paper, we propose a content-based formulation of serendipity that is rooted in Bayesian surprise and use it to measure the serendipity of items after they are consumed and rated by the user. When coupled with a collaborative-filtering component that identifies similar users, this enables recommending items with high potential for serendipity. To facilitate the evaluation of topic-level models for surprise and serendipity, we introduce a dataset of book reading histories extracted from Goodreads, containing over 26 thousand users and close to 1.3 million books, where we manually annotate 449 books read by 4 users in terms of their time-dependent, topic-level surprise. Experimental evaluations show that models that use Bayesian surprise correlate much better with the manual annotations of topic-level surprise than distance-based heuristics, and also obtain better serendipitous item recommendation performance.
Real-Time Idling Vehicles Detection Using Combined Audio-Visual Deep Learning
May 23, 2023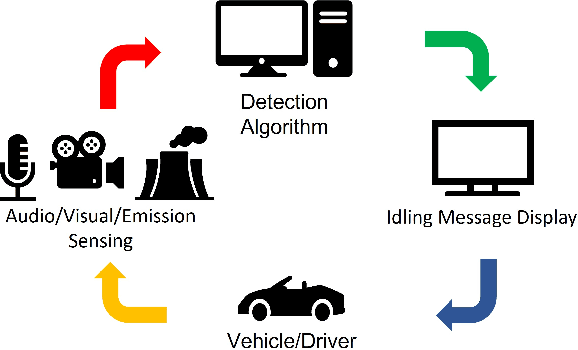
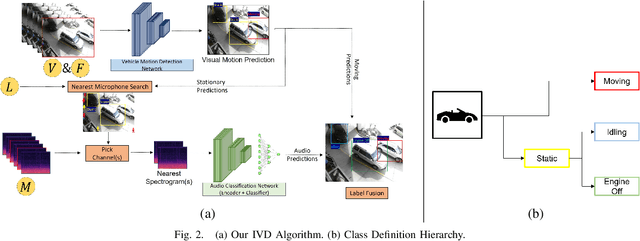

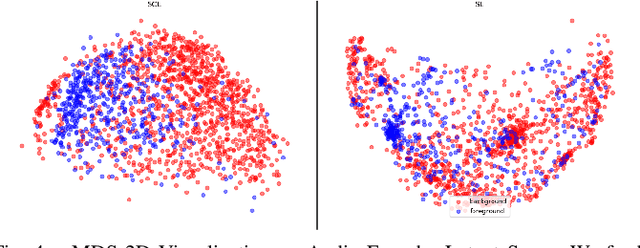
Combustion vehicle emissions contribute to poor air quality and release greenhouse gases into the atmosphere, and vehicle pollution has been associated with numerous adverse health effects. Roadways with extensive waiting and/or passenger drop off, such as schools and hospital drop-off zones, can result in high incidence and density of idling vehicles. This can produce micro-climates of increased vehicle pollution. Thus, the detection of idling vehicles can be helpful in monitoring and responding to unnecessary idling and be integrated into real-time or off-line systems to address the resulting pollution. In this paper we present a real-time, dynamic vehicle idling detection algorithm. The proposed idle detection algorithm and notification rely on an algorithm to detect these idling vehicles. The proposed method relies on a multi-sensor, audio-visual, machine-learning workflow to detect idling vehicles visually under three conditions: moving, static with the engine on, and static with the engine off. The visual vehicle motion detector is built in the first stage, and then a contrastive-learning-based latent space is trained for classifying static vehicle engine sound. We test our system in real-time at a hospital drop-off point in Salt Lake City. This in-situ dataset was collected and annotated, and it includes vehicles of varying models and types. The experiments show that the method can detect engine switching on or off instantly and achieves 71.01 mean average precision (mAP).
Adversarial Training of Denoising Diffusion Model Using Dual Discriminators for High-Fidelity Multi-Speaker TTS
Aug 03, 2023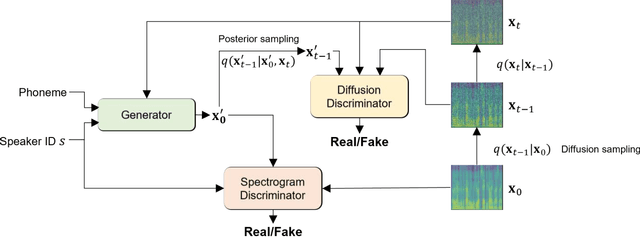
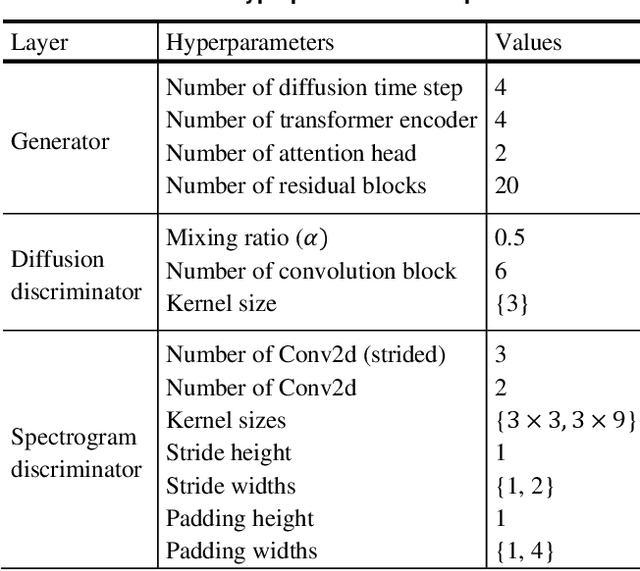
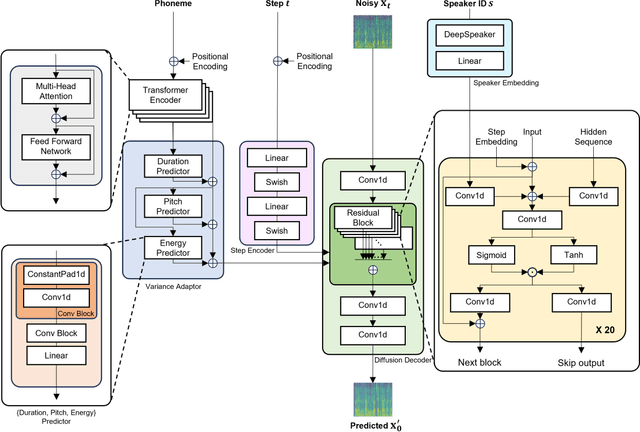
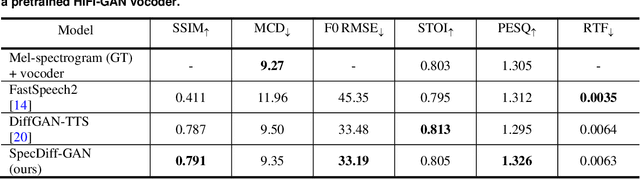
The diffusion model is capable of generating high-quality data through a probabilistic approach. However, it suffers from the drawback of slow generation speed due to the requirement of a large number of time steps. To address this limitation, recent models such as denoising diffusion implicit models (DDIM) focus on generating samples without directly modeling the probability distribution, while models like denoising diffusion generative adversarial networks (GAN) combine diffusion processes with GANs. In the field of speech synthesis, a recent diffusion speech synthesis model called DiffGAN-TTS, utilizing the structure of GANs, has been introduced and demonstrates superior performance in both speech quality and generation speed. In this paper, to further enhance the performance of DiffGAN-TTS, we propose a speech synthesis model with two discriminators: a diffusion discriminator for learning the distribution of the reverse process and a spectrogram discriminator for learning the distribution of the generated data. Objective metrics such as structural similarity index measure (SSIM), mel-cepstral distortion (MCD), F0 root mean squared error (F0 RMSE), short-time objective intelligibility (STOI), perceptual evaluation of speech quality (PESQ), as well as subjective metrics like mean opinion score (MOS), are used to evaluate the performance of the proposed model. The evaluation results show that the proposed model outperforms recent state-of-the-art models such as FastSpeech2 and DiffGAN-TTS in various metrics. Our implementation and audio samples are located on GitHub.
MCTS guided Genetic Algorithm for optimization of neural network weights
Aug 07, 2023In this research, we investigate the possibility of applying a search strategy to genetic algorithms to explore the entire genetic tree structure. Several methods aid in performing tree searches; however, simpler algorithms such as breadth-first, depth-first, and iterative techniques are computation-heavy and often result in a long execution time. Adversarial techniques are often the preferred mechanism when performing a probabilistic search, yielding optimal results more quickly. The problem we are trying to tackle in this paper is the optimization of neural networks using genetic algorithms. Genetic algorithms (GA) form a tree of possible states and provide a mechanism for rewards via the fitness function. Monte Carlo Tree Search (MCTS) has proven to be an effective tree search strategy given states and rewards; therefore, we will combine these approaches to optimally search for the best result generated with genetic algorithms.
Universal Automatic Phonetic Transcription into the International Phonetic Alphabet
Aug 07, 2023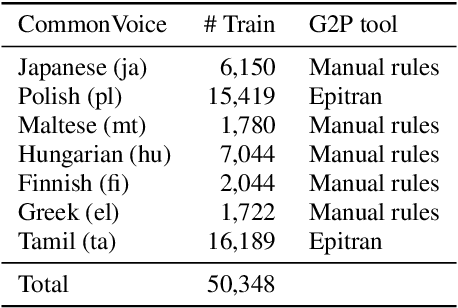
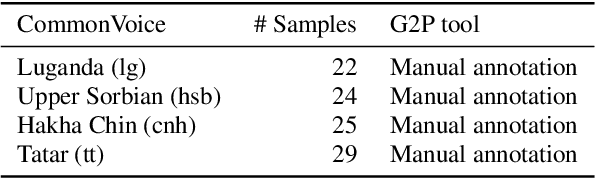
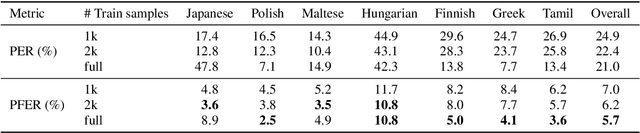
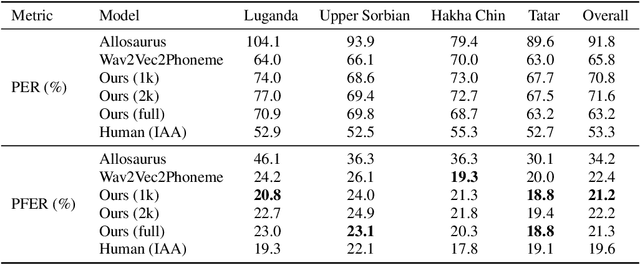
This paper presents a state-of-the-art model for transcribing speech in any language into the International Phonetic Alphabet (IPA). Transcription of spoken languages into IPA is an essential yet time-consuming process in language documentation, and even partially automating this process has the potential to drastically speed up the documentation of endangered languages. Like the previous best speech-to-IPA model (Wav2Vec2Phoneme), our model is based on wav2vec 2.0 and is fine-tuned to predict IPA from audio input. We use training data from seven languages from CommonVoice 11.0, transcribed into IPA semi-automatically. Although this training dataset is much smaller than Wav2Vec2Phoneme's, its higher quality lets our model achieve comparable or better results. Furthermore, we show that the quality of our universal speech-to-IPA models is close to that of human annotators.
Kernel-based Joint Independence Tests for Multivariate Stationary and Nonstationary Time-Series
May 15, 2023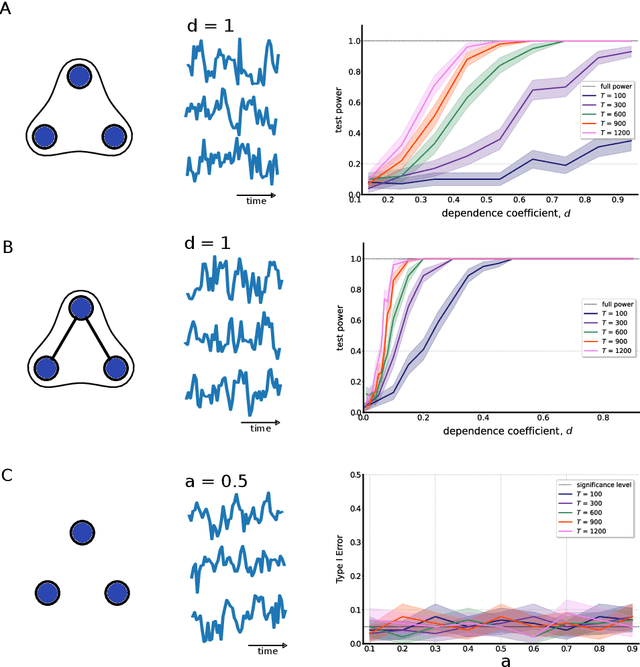

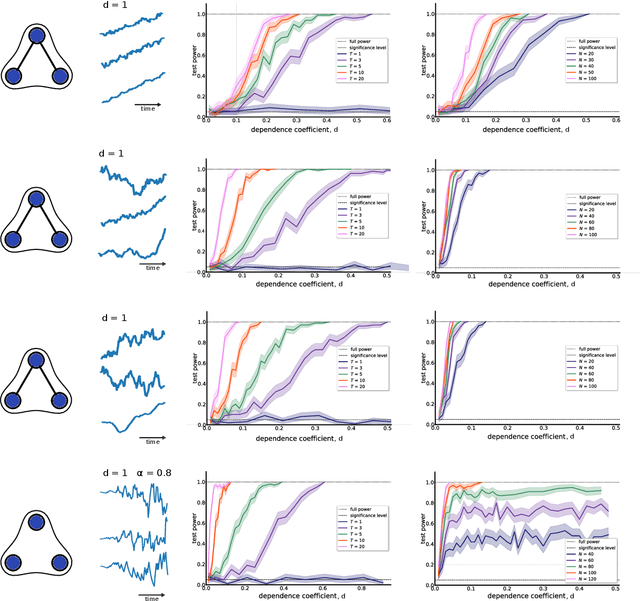
Multivariate time-series data that capture the temporal evolution of interconnected systems are ubiquitous in diverse areas. Understanding the complex relationships and potential dependencies among co-observed variables is crucial for the accurate statistical modelling and analysis of such systems. Here, we introduce kernel-based statistical tests of joint independence in multivariate time-series by extending the d-variable Hilbert-Schmidt independence criterion (dHSIC) to encompass both stationary and nonstationary random processes, thus allowing broader real-world applications. By leveraging resampling techniques tailored for both single- and multiple-realization time series, we show how the method robustly uncovers significant higher-order dependencies in synthetic examples, including frequency mixing data, as well as real-world climate and socioeconomic data. Our method adds to the mathematical toolbox for the analysis of complex high-dimensional time-series datasets.
Exploring XAI for the Arts: Explaining Latent Space in Generative Music
Aug 10, 2023
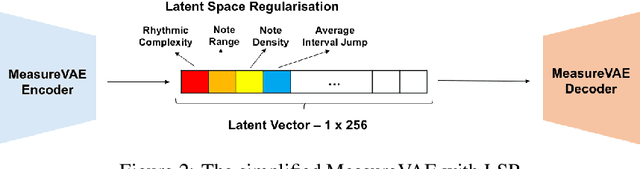
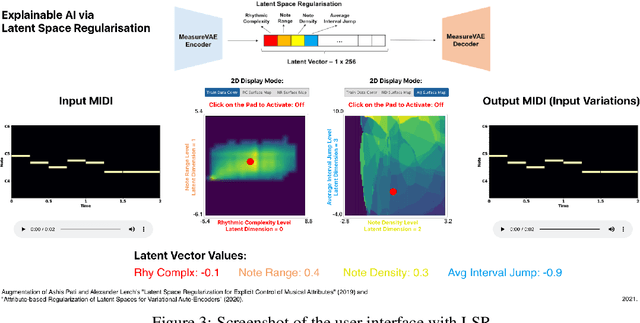

Explainable AI has the potential to support more interactive and fluid co-creative AI systems which can creatively collaborate with people. To do this, creative AI models need to be amenable to debugging by offering eXplainable AI (XAI) features which are inspectable, understandable, and modifiable. However, currently there is very little XAI for the arts. In this work, we demonstrate how a latent variable model for music generation can be made more explainable; specifically we extend MeasureVAE which generates measures of music. We increase the explainability of the model by: i) using latent space regularisation to force some specific dimensions of the latent space to map to meaningful musical attributes, ii) providing a user interface feedback loop to allow people to adjust dimensions of the latent space and observe the results of these changes in real-time, iii) providing a visualisation of the musical attributes in the latent space to help people understand and predict the effect of changes to latent space dimensions. We suggest that in doing so we bridge the gap between the latent space and the generated musical outcomes in a meaningful way which makes the model and its outputs more explainable and more debuggable.
InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
Aug 10, 2023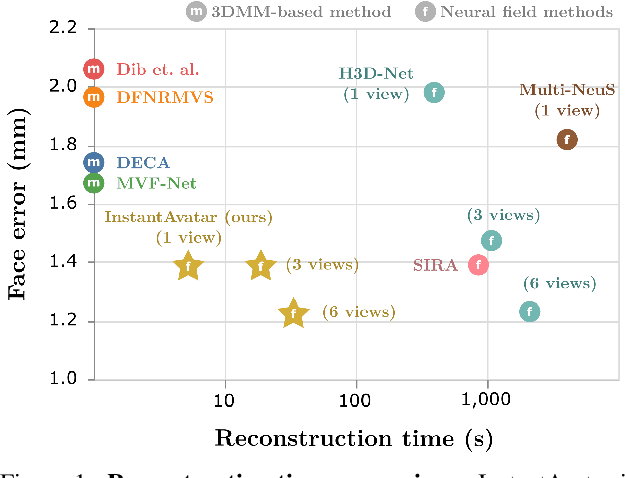
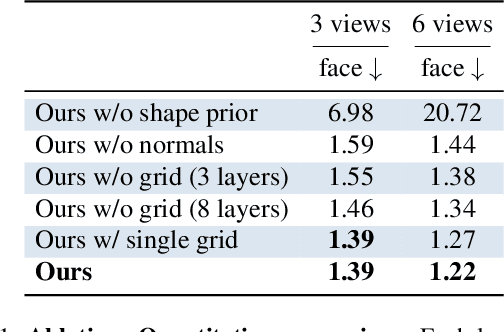
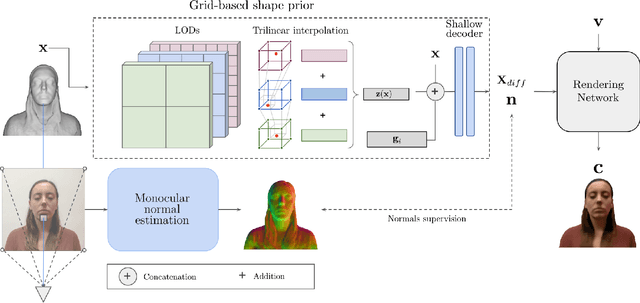
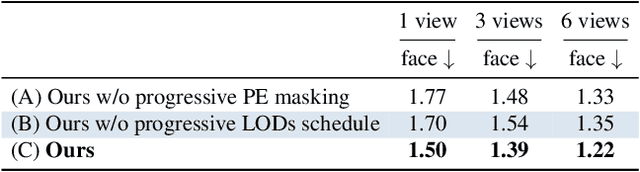
Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.