 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Foreground Object Search by Distilling Composite Image Feature
Aug 09, 2023
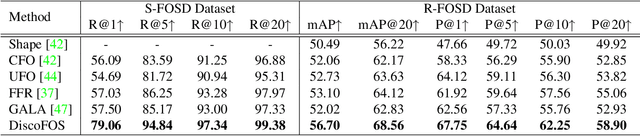
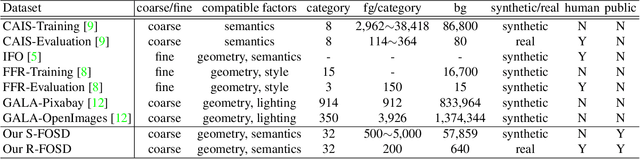
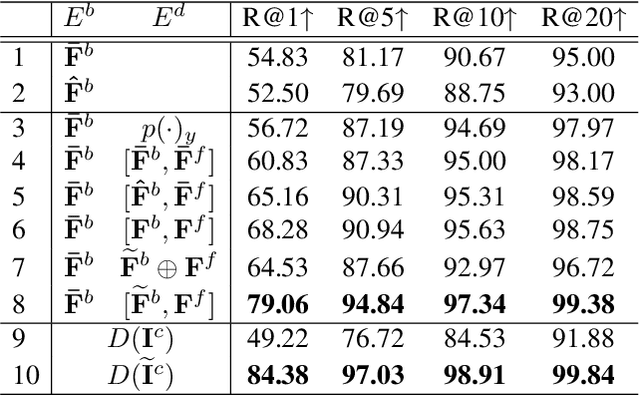
Foreground object search (FOS) aims to find compatible foreground objects for a given background image, producing realistic composite image. We observe that competitive retrieval performance could be achieved by using a discriminator to predict the compatibility of composite image, but this approach has unaffordable time cost. To this end, we propose a novel FOS method via distilling composite feature (DiscoFOS). Specifically, the abovementioned discriminator serves as teacher network. The student network employs two encoders to extract foreground feature and background feature. Their interaction output is enforced to match the composite image feature from the teacher network. Additionally, previous works did not release their datasets, so we contribute two datasets for FOS task: S-FOSD dataset with synthetic composite images and R-FOSD dataset with real composite images. Extensive experiments on our two datasets demonstrate the superiority of the proposed method over previous approaches. The dataset and code are available at https://github.com/bcmi/Foreground-Object-Search-Dataset-FOSD.
Enhancing Mobile Privacy and Security: A Face Skin Patch-Based Anti-Spoofing Approach
Aug 09, 2023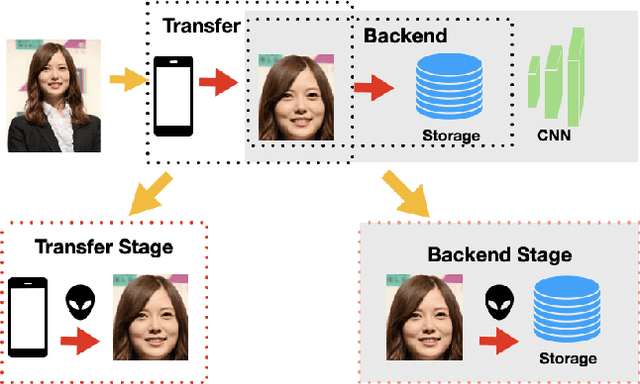
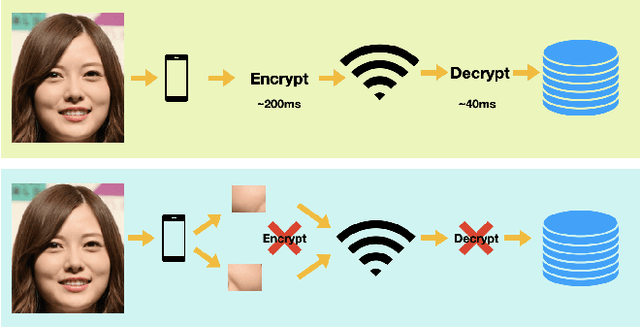
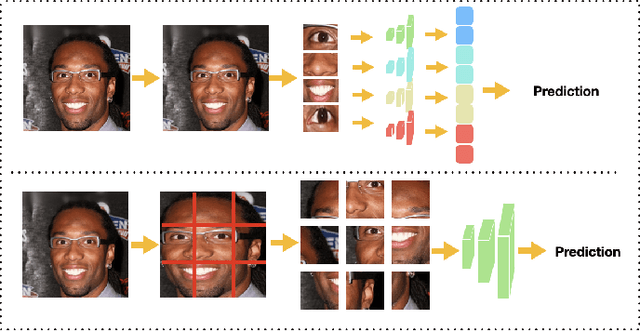
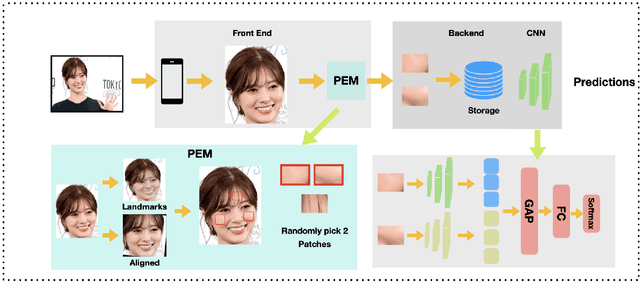
As Facial Recognition System(FRS) is widely applied in areas such as access control and mobile payments due to its convenience and high accuracy. The security of facial recognition is also highly regarded. The Face anti-spoofing system(FAS) for face recognition is an important component used to enhance the security of face recognition systems. Traditional FAS used images containing identity information to detect spoofing traces, however there is a risk of privacy leakage during the transmission and storage of these images. Besides, the encryption and decryption of these privacy-sensitive data takes too long compared to inference time by FAS model. To address the above issues, we propose a face anti-spoofing algorithm based on facial skin patches leveraging pure facial skin patch images as input, which contain no privacy information, no encryption or decryption is needed for these images. We conduct experiments on several public datasets, the results prove that our algorithm has demonstrated superiority in both accuracy and speed.
Universal Recurrent Event Memories for Streaming Data
Jul 28, 2023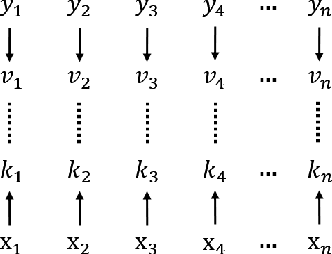
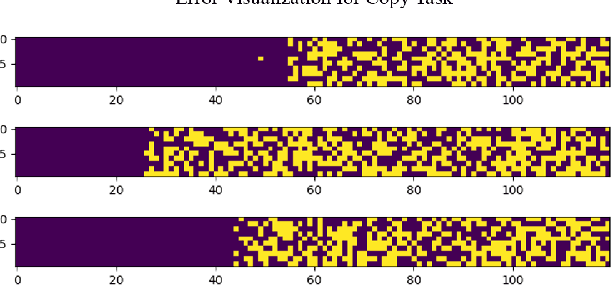
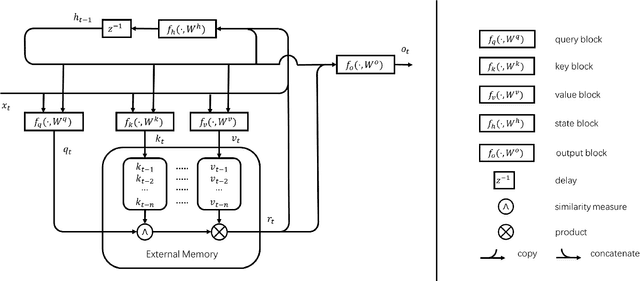
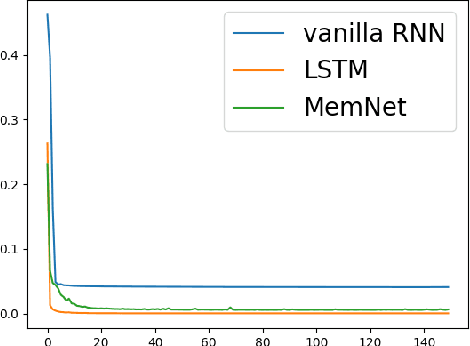
In this paper, we propose a new event memory architecture (MemNet) for recurrent neural networks, which is universal for different types of time series data such as scalar, multivariate or symbolic. Unlike other external neural memory architectures, it stores key-value pairs, which separate the information for addressing and for content to improve the representation, as in the digital archetype. Moreover, the key-value pairs also avoid the compromise between memory depth and resolution that applies to memories constructed by the model state. One of the MemNet key characteristics is that it requires only linear adaptive mapping functions while implementing a nonlinear operation on the input data. MemNet architecture can be applied without modifications to scalar time series, logic operators on strings, and also to natural language processing, providing state-of-the-art results in all application domains such as the chaotic time series, the symbolic operation tasks, and the question-answering tasks (bAbI). Finally, controlled by five linear layers, MemNet requires a much smaller number of training parameters than other external memory networks as well as the transformer network. The space complexity of MemNet equals a single self-attention layer. It greatly improves the efficiency of the attention mechanism and opens the door for IoT applications.
SimpleMapping: Real-Time Visual-Inertial Dense Mapping with Deep Multi-View Stereo
Jun 14, 2023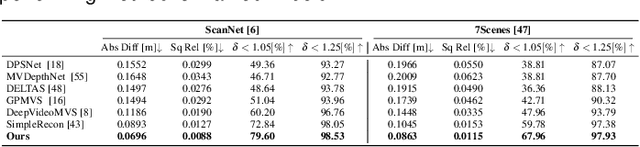
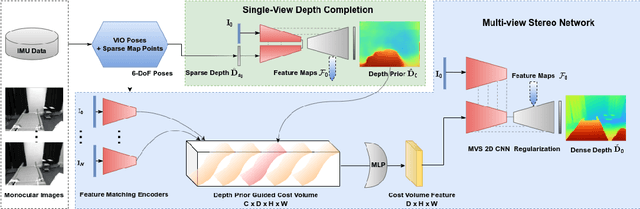
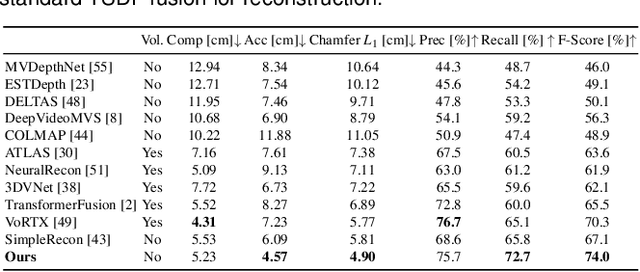
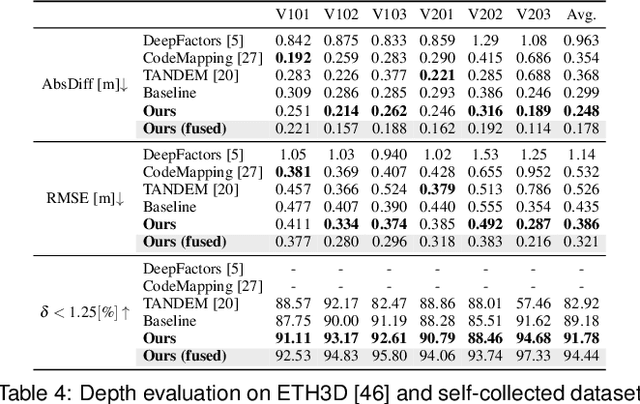
We present a real-time visual-inertial dense mapping method capable of performing incremental 3D mesh reconstruction with high quality using only sequential monocular images and inertial measurement unit (IMU) readings. 6-DoF camera poses are estimated by a robust feature-based visual-inertial odometry (VIO), which also generates noisy sparse 3D map points as a by-product. We propose a sparse point aided multi-view stereo neural network (SPA-MVSNet) that can effectively leverage the informative but noisy sparse points from the VIO system. The sparse depth from VIO is firstly completed by a single-view depth completion network. This dense depth map, although naturally limited in accuracy, is then used as a prior to guide our MVS network in the cost volume generation and regularization for accurate dense depth prediction. Predicted depth maps of keyframe images by the MVS network are incrementally fused into a global map using TSDF-Fusion. We extensively evaluate both the proposed SPA-MVSNet and the entire visual-inertial dense mapping system on several public datasets as well as our own dataset, demonstrating the system's impressive generalization capabilities and its ability to deliver high-quality 3D mesh reconstruction online. Our proposed dense mapping system achieves a 39.7% improvement in F-score over existing systems when evaluated on the challenging scenarios of the EuRoC dataset. We plan to release the code of this work upon acceptance.
Theoretical Analyses of Evolutionary Algorithms on Time-Linkage OneMax with General Weights
May 11, 2023Evolutionary computation has shown its superiority in dynamic optimization, but for the (dynamic) time-linkage problems, some theoretical studies have revealed the possible weakness of evolutionary computation. Since the theoretically analyzed time-linkage problem only considers the influence of an extremely strong negative time-linkage effect, it remains unclear whether the weakness also appears in problems with more general time-linkage effects. Besides, understanding in depth the relationship between time-linkage effect and algorithmic features is important to build up our knowledge of what algorithmic features are good at what kinds of problems. In this paper, we analyze the general time-linkage effect and consider the time-linkage OneMax with general weights whose absolute values reflect the strength and whose sign reflects the positive or negative influence. We prove that except for some small and positive time-linkage effects (that is, for weights $0$ and $1$), randomized local search (RLS) and (1+1)EA cannot converge to the global optimum with a positive probability. More precisely, for the negative time-linkage effect (for negative weights), both algorithms cannot efficiently reach the global optimum and the probability of failing to converge to the global optimum is at least $1-o(1)$. For the not so small positive time-linkage effect (positive weights greater than $1$), such a probability is at most $c+o(1)$ where $c$ is a constant strictly less than $1$.
Hybrids of Constraint-based and Noise-based Algorithms for Causal Discovery from Time Series
Jun 14, 2023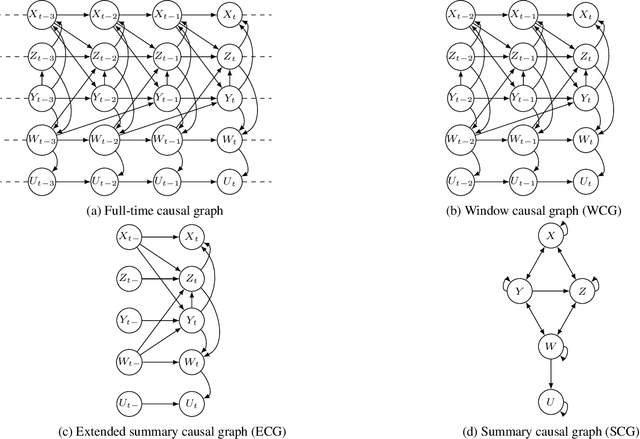
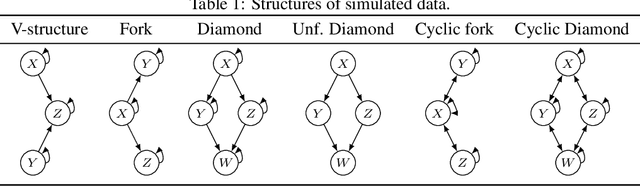
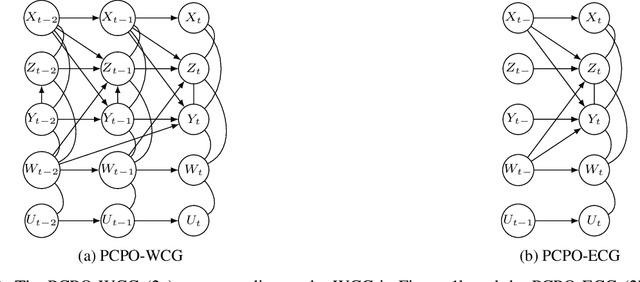
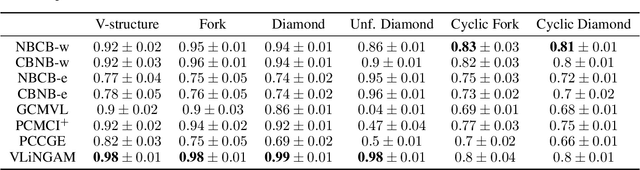
Constraint-based and noise-based methods have been proposed to discover summary causal graphs from observational time series under strong assumptions which can be violated or impossible to verify in real applications. Recently, a hybrid method (Assaad et al, 2021) that combines these two approaches, proved to be robust to assumption violation. However, this method assumes that the summary causal graph is acyclic, but cycles are common in many applications. For example, in ecological communities, there may be cyclic relationships between predator and prey populations, creating feedback loops. Therefore, this paper presents two new frameworks for hybrids of constraint-based and noise-based methods that can discover summary causal graphs that may or may not contain cycles. For each framework, we provide two hybrid algorithms which are experimentally tested on simulated data, realistic ecological data, and real data from various applications. Experiments show that our hybrid approaches are robust and yield good results over most datasets.
Effect of Measurement Location on Cardiac Time Intervals Estimated by Seismocardiography
Jun 13, 2023Cardiac time intervals (CTIs) are important parameters for assessing cardiac function and can be measured using non-invasive methods such as electrocardiography (ECG) and seismocardiography (SCG). It is widely accepted that SCG signals, when measured from various locations on the chest surface, exhibit distinct temporal and spectral characteristics. In that regard, the goal of this study was to determine the effect of the SCG measurement location on estimating SCG-based CTIs. For this purpose, ECG, SCG, and phonocardiography (PCG) signals were acquired from fourteen healthy adult subjects. For SCG, three tri-axial accelerometers were attached on the top, middle, and bottom of the sternum with double-sided tape. In this study, only the dorsoventral components of the SCG signals were analyzed. Using Pan-Tompkin's algorithm, ECG R peaks and their temporal indices were found. Then, a custom-built algorithm in MATLAB was developed to estimate heart rate (HR) from ECG and SCG signals. Furthermore, SCG fiducial points and CTIs were defined from the SCG signals recorded from different sternal locations. The average and correlation coefficient of the CTIs and HRs derived from all three locations were compared. Mean difference and standard deviation were analyzed for the CTIs and their respective sensor location. Results demonstrated that SCG-based CTIs varied with the SCG measurement locations. In conclusion, these results highlighted the importance of establishing consistent research and clinical protocols for reporting CTIs based on SCG. This work also calls for further investigation into comparing estimated CTIs with gold-standard methods such as echocardiography and 4D cardiac computed tomography.
Theory of Periodically Time-Variant Linear Systems
May 12, 2023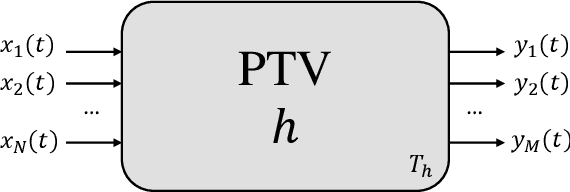
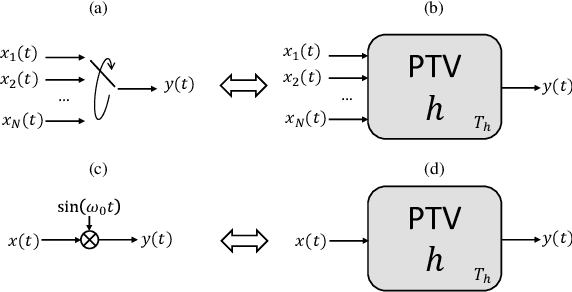
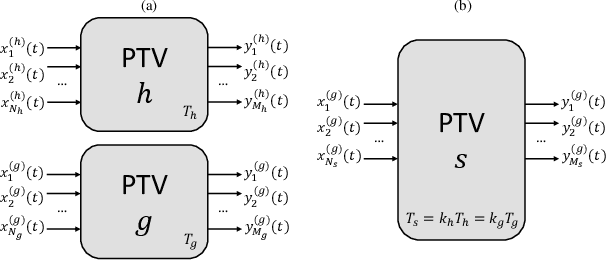
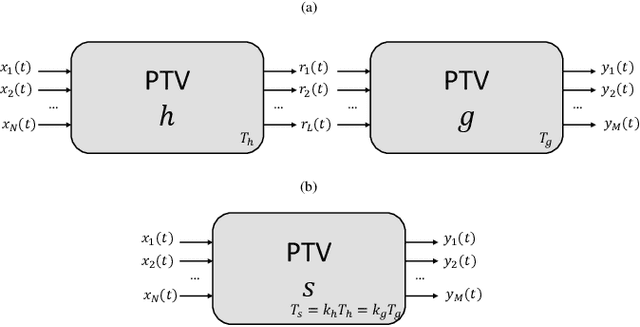
In this work we provide a mathematical framework to describe the periodically time variant (PTV) linear systems. We study their frequency-domain features to estimate the output bandwidth, a necessary value to obtain a suitable digital representation of such systems. In addition, we derive several interesting properties enabling useful equivalences to represent, simulate and compensate PTVs.
A Note on Hardness of Computing Recursive Teaching Dimension
Jul 19, 2023In this short note, we show that the problem of computing the recursive teaching dimension (RTD) for a concept class (given explicitly as input) requires $n^{\Omega(\log n)}$-time, assuming the exponential time hypothesis (ETH). This matches the running time $n^{O(\log n)}$ of the brute-force algorithm for the problem.
Continual Domain Adaptation on Aerial Images under Gradually Degrading Weather
Aug 02, 2023Domain adaptation (DA) strives to mitigate the domain gap between the source domain where a model is trained, and the target domain where the model is deployed. When a deep learning model is deployed on an aerial platform, it may face gradually degrading weather conditions during operation, leading to widening domain gaps between the training data and the encountered evaluation data. We synthesize two such gradually worsening weather conditions on real images from two existing aerial imagery datasets, generating a total of four benchmark datasets. Under the continual, or test-time adaptation setting, we evaluate three DA models on our datasets: a baseline standard DA model and two continual DA models. In such setting, the models can access only one small portion, or one batch of the target data at a time, and adaptation takes place continually, and over only one epoch of the data. The combination of the constraints of continual adaptation, and gradually deteriorating weather conditions provide the practical DA scenario for aerial deployment. Among the evaluated models, we consider both convolutional and transformer architectures for comparison. We discover stability issues during adaptation for existing buffer-fed continual DA methods, and offer gradient normalization as a simple solution to curb training instability.