 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CT respiratory motion synthesis using joint supervised and adversarial learning
Mar 29, 2024
Objective: Four-dimensional computed tomography (4DCT) imaging consists in reconstructing a CT acquisition into multiple phases to track internal organ and tumor motion. It is commonly used in radiotherapy treatment planning to establish planning target volumes. However, 4DCT increases protocol complexity, may not align with patient breathing during treatment, and lead to higher radiation delivery. Approach: In this study, we propose a deep synthesis method to generate pseudo respiratory CT phases from static images for motion-aware treatment planning. The model produces patient-specific deformation vector fields (DVFs) by conditioning synthesis on external patient surface-based estimation, mimicking respiratory monitoring devices. A key methodological contribution is to encourage DVF realism through supervised DVF training while using an adversarial term jointly not only on the warped image but also on the magnitude of the DVF itself. This way, we avoid excessive smoothness typically obtained through deep unsupervised learning, and encourage correlations with the respiratory amplitude. Main results: Performance is evaluated using real 4DCT acquisitions with smaller tumor volumes than previously reported. Results demonstrate for the first time that the generated pseudo-respiratory CT phases can capture organ and tumor motion with similar accuracy to repeated 4DCT scans of the same patient. Mean inter-scans tumor center-of-mass distances and Dice similarity coefficients were $1.97$mm and $0.63$, respectively, for real 4DCT phases and $2.35$mm and $0.71$ for synthetic phases, and compares favorably to a state-of-the-art technique (RMSim).
Fractional Delay Alignment Modulation for Spatially Sparse Wireless Communications
Mar 29, 2024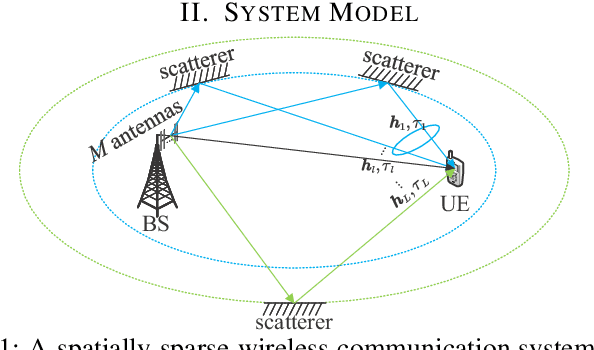
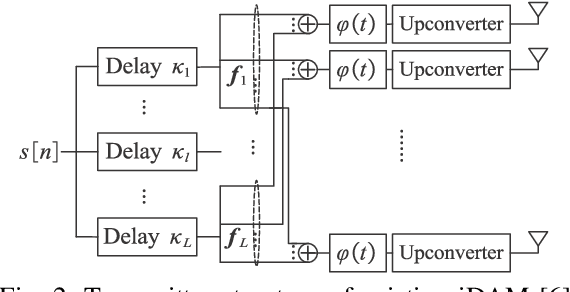
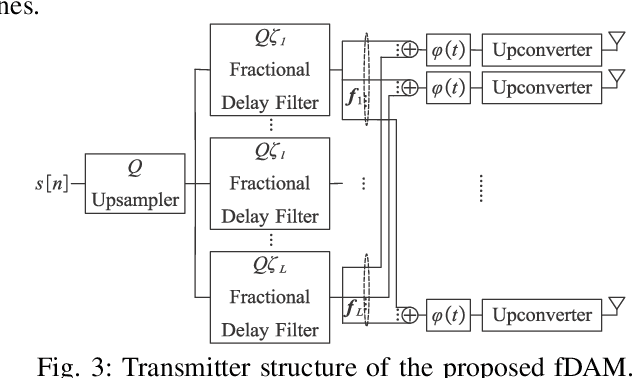
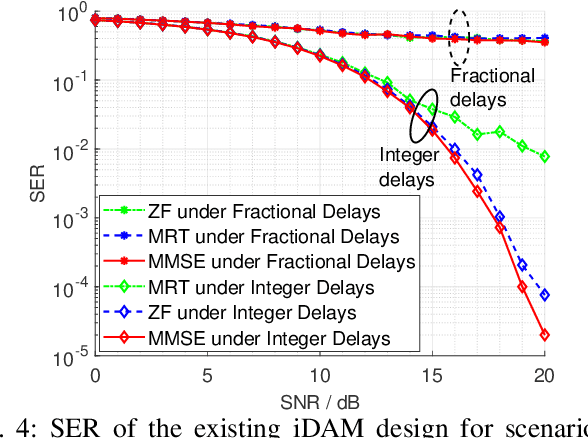
Delay alignment modulation (DAM) is a novel transmission technique for wireless systems with high spatial resolution by leveraging delay compensation and path-based beamforming, to mitigate the inter-symbol interference (ISI) without resorting to complex channel equalization or multi-carrier transmission. However, most existing studies on DAM consider a simplified scenario by assuming that the channel multi-path delays are integer multiples of the signal sampling interval. This paper investigates DAM for the more general and practical scenarios with fractional multi-path delays. We first analyze the impact of fractional multi-path delays on the existing DAM design, termed integer DAM (iDAM), which can only achieve delay compensations that are integer multiples of the sampling interval. It is revealed that the existence of fractional multi-path delays renders iDAM no longer possible to achieve perfect delay alignment. To address this issue, we propose a more generic DAM design called fractional DAM (fDAM), which achieves fractional delay pre-compensation via upsampling and fractional delay filtering. By leveraging the Farrow filter structure, the proposed approach can eliminate ISI without real-time computation of filter coefficients, as typically required in traditional channel equalization techniques. Simulation results demonstrate that the proposed fDAM outperforms the existing iDAM and orthogonal frequency division multiplexing (OFDM) in terms of symbol error rate (SER) and spectral efficiency, while maintaining a comparable peak-to-average power ratio (PAPR) as iDAM, which is considerably lower than OFDM.
Heterogeneous Network Based Contrastive Learning Method for PolSAR Land Cover Classification
Mar 29, 2024
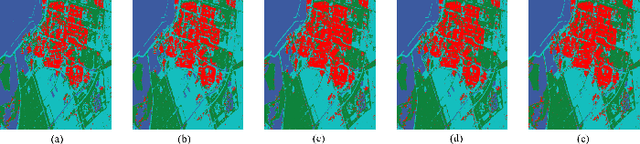
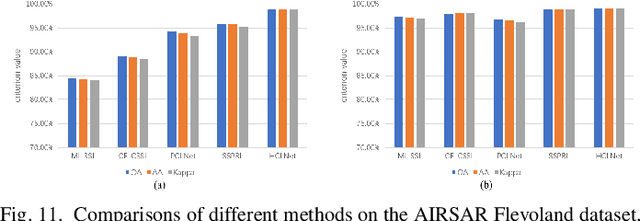

Polarimetric synthetic aperture radar (PolSAR) image interpretation is widely used in various fields. Recently, deep learning has made significant progress in PolSAR image classification. Supervised learning (SL) requires a large amount of labeled PolSAR data with high quality to achieve better performance, however, manually labeled data is insufficient. This causes the SL to fail into overfitting and degrades its generalization performance. Furthermore, the scattering confusion problem is also a significant challenge that attracts more attention. To solve these problems, this article proposes a Heterogeneous Network based Contrastive Learning method(HCLNet). It aims to learn high-level representation from unlabeled PolSAR data for few-shot classification according to multi-features and superpixels. Beyond the conventional CL, HCLNet introduces the heterogeneous architecture for the first time to utilize heterogeneous PolSAR features better. And it develops two easy-to-use plugins to narrow the domain gap between optics and PolSAR, including feature filter and superpixel-based instance discrimination, which the former is used to enhance the complementarity of multi-features, and the latter is used to increase the diversity of negative samples. Experiments demonstrate the superiority of HCLNet on three widely used PolSAR benchmark datasets compared with state-of-the-art methods. Ablation studies also verify the importance of each component. Besides, this work has implications for how to efficiently utilize the multi-features of PolSAR data to learn better high-level representation in CL and how to construct networks suitable for PolSAR data better.
Voice Signal Processing for Machine Learning. The Case of Speaker Isolation
Mar 29, 2024
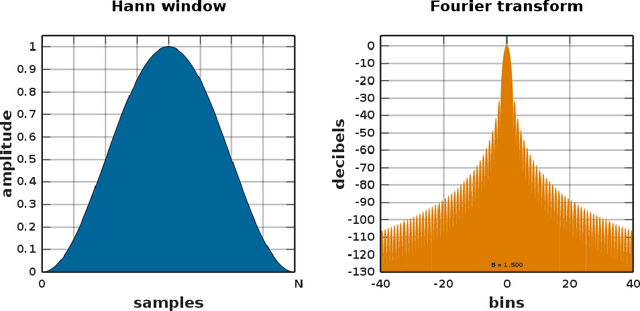
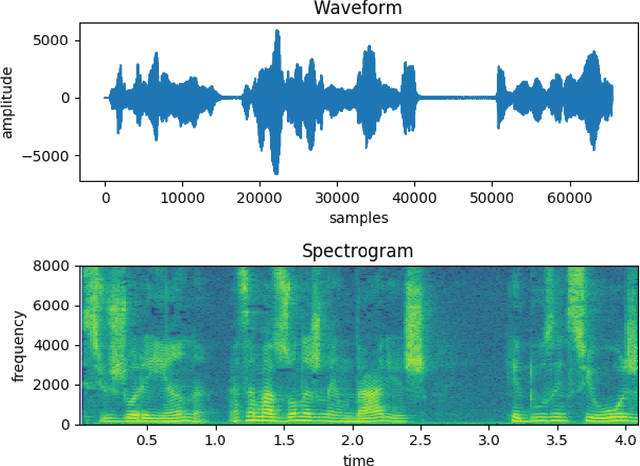
The widespread use of automated voice assistants along with other recent technological developments have increased the demand for applications that process audio signals and human voice in particular. Voice recognition tasks are typically performed using artificial intelligence and machine learning models. Even though end-to-end models exist, properly pre-processing the signal can greatly reduce the complexity of the task and allow it to be solved with a simpler ML model and fewer computational resources. However, ML engineers who work on such tasks might not have a background in signal processing which is an entirely different area of expertise. The objective of this work is to provide a concise comparative analysis of Fourier and Wavelet transforms that are most commonly used as signal decomposition methods for audio processing tasks. Metrics for evaluating speech intelligibility are also discussed, namely Scale-Invariant Signal-to-Distortion Ratio (SI-SDR), Perceptual Evaluation of Speech Quality (PESQ), and Short-Time Objective Intelligibility (STOI). The level of detail in the exposition is meant to be sufficient for an ML engineer to make informed decisions when choosing, fine-tuning, and evaluating a decomposition method for a specific ML model. The exposition contains mathematical definitions of the relevant concepts accompanied with intuitive non-mathematical explanations in order to make the text more accessible to engineers without deep expertise in signal processing. Formal mathematical definitions and proofs of theorems are intentionally omitted in order to keep the text concise.
Accuracy enhancement method for speech emotion recognition from spectrogram using temporal frequency correlation and positional information learning through knowledge transfer
Mar 26, 2024In this paper, we propose a method to improve the accuracy of speech emotion recognition (SER) by using vision transformer (ViT) to attend to the correlation of frequency (y-axis) with time (x-axis) in spectrogram and transferring positional information between ViT through knowledge transfer. The proposed method has the following originality i) We use vertically segmented patches of log-Mel spectrogram to analyze the correlation of frequencies over time. This type of patch allows us to correlate the most relevant frequencies for a particular emotion with the time they were uttered. ii) We propose the use of image coordinate encoding, an absolute positional encoding suitable for ViT. By normalizing the x, y coordinates of the image to -1 to 1 and concatenating them to the image, we can effectively provide valid absolute positional information for ViT. iii) Through feature map matching, the locality and location information of the teacher network is effectively transmitted to the student network. Teacher network is a ViT that contains locality of convolutional stem and absolute position information through image coordinate encoding, and student network is a structure that lacks positional encoding in the basic ViT structure. In feature map matching stage, we train through the mean absolute error (L1 loss) to minimize the difference between the feature maps of the two networks. To validate the proposed method, three emotion datasets (SAVEE, EmoDB, and CREMA-D) consisting of speech were converted into log-Mel spectrograms for comparison experiments. The experimental results show that the proposed method significantly outperforms the state-of-the-art methods in terms of weighted accuracy while requiring significantly fewer floating point operations (FLOPs). Overall, the proposed method offers an promising solution for SER by providing improved efficiency and performance.
Improving Real-Time Omnidirectional 3D Multi-Person Human Pose Estimation with People Matching and Unsupervised 2D-3D Lifting
Mar 14, 2024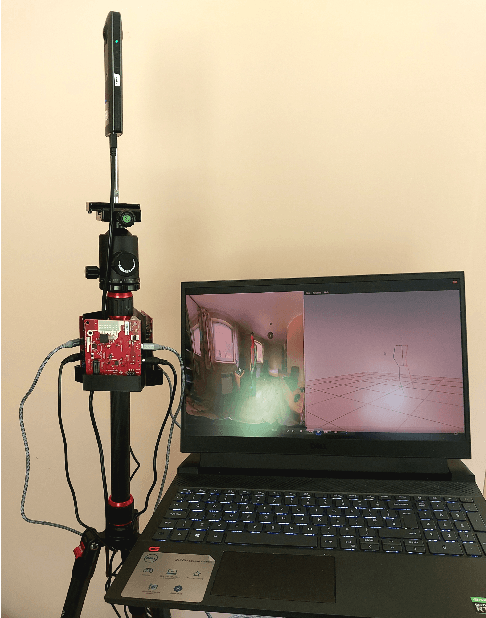
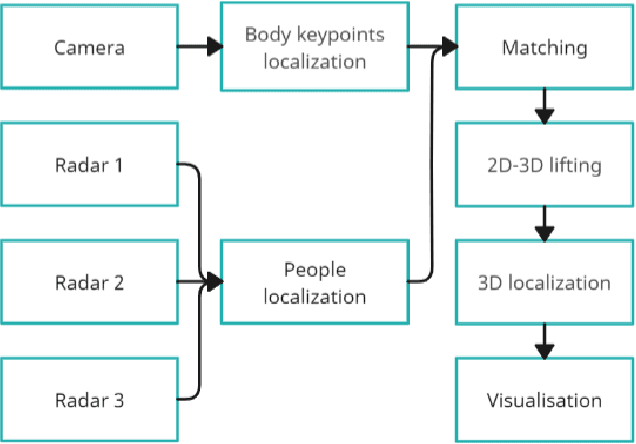
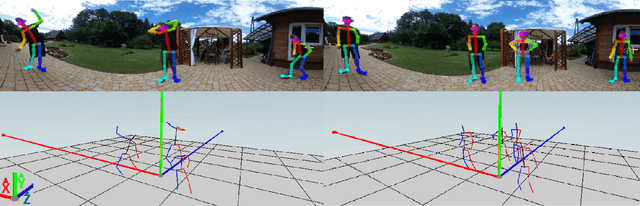
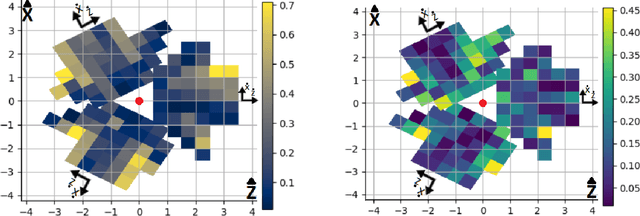
Current human pose estimation systems focus on retrieving an accurate 3D global estimate of a single person. Therefore, this paper presents one of the first 3D multi-person human pose estimation systems that is able to work in real-time and is also able to handle basic forms of occlusion. First, we adjust an off-the-shelf 2D detector and an unsupervised 2D-3D lifting model for use with a 360$^\circ$ panoramic camera and mmWave radar sensors. We then introduce several contributions, including camera and radar calibrations, and the improved matching of people within the image and radar space. The system addresses both the depth and scale ambiguity problems by employing a lightweight 2D-3D pose lifting algorithm that is able to work in real-time while exhibiting accurate performance in both indoor and outdoor environments which offers both an affordable and scalable solution. Notably, our system's time complexity remains nearly constant irrespective of the number of detected individuals, achieving a frame rate of approximately 7-8 fps on a laptop with a commercial-grade GPU.
PALM: Pushing Adaptive Learning Rate Mechanisms for Continual Test-Time Adaptation
Mar 15, 2024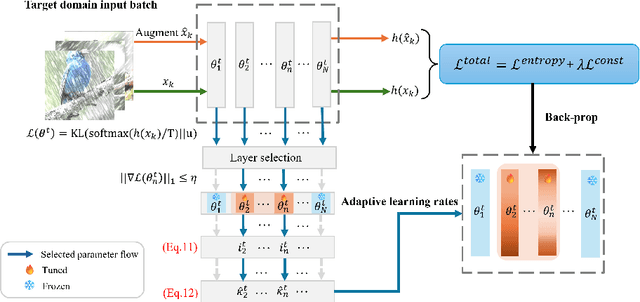
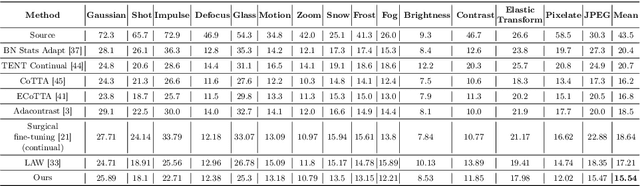
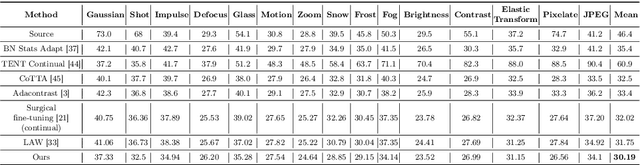
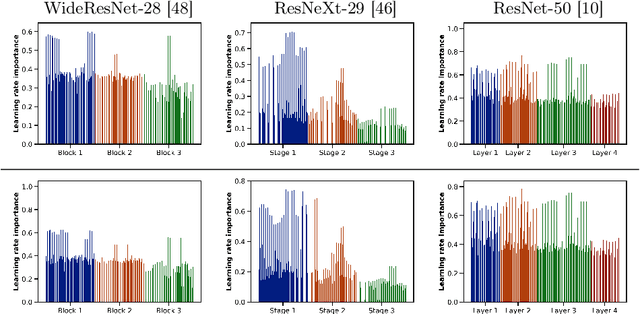
Real-world vision models in dynamic environments face rapid shifts in domain distributions, leading to decreased recognition performance. Continual test-time adaptation (CTTA) directly adjusts a pre-trained source discriminative model to these changing domains using test data. A highly effective CTTA method involves applying layer-wise adaptive learning rates, and selectively adapting pre-trained layers. However, it suffers from the poor estimation of domain shift and the inaccuracies arising from the pseudo-labels. In this work, we aim to overcome these limitations by identifying layers through the quantification of model prediction uncertainty without relying on pseudo-labels. We utilize the magnitude of gradients as a metric, calculated by backpropagating the KL divergence between the softmax output and a uniform distribution, to select layers for further adaptation. Subsequently, for the parameters exclusively belonging to these selected layers, with the remaining ones frozen, we evaluate their sensitivity in order to approximate the domain shift, followed by adjusting their learning rates accordingly. Overall, this approach leads to a more robust and stable optimization than prior approaches. We conduct extensive image classification experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C and demonstrate the efficacy of our method against standard benchmarks and prior methods.
Tracking-Assisted Object Detection with Event Cameras
Mar 27, 2024Event-based object detection has recently garnered attention in the computer vision community due to the exceptional properties of event cameras, such as high dynamic range and no motion blur. However, feature asynchronism and sparsity cause invisible objects due to no relative motion to the camera, posing a significant challenge in the task. Prior works have studied various memory mechanisms to preserve as many features as possible at the current time, guided by temporal clues. While these implicit-learned memories retain some short-term information, they still struggle to preserve long-term features effectively. In this paper, we consider those invisible objects as pseudo-occluded objects and aim to reveal their features. Firstly, we introduce visibility attribute of objects and contribute an auto-labeling algorithm to append additional visibility labels on an existing event camera dataset. Secondly, we exploit tracking strategies for pseudo-occluded objects to maintain their permanence and retain their bounding boxes, even when features have not been available for a very long time. These strategies can be treated as an explicit-learned memory guided by the tracking objective to record the displacements of objects across frames. Lastly, we propose a spatio-temporal feature aggregation module to enrich the latent features and a consistency loss to increase the robustness of the overall pipeline. We conduct comprehensive experiments to verify our method's effectiveness where still objects are retained but real occluded objects are discarded. The results demonstrate that (1) the additional visibility labels can assist in supervised training, and (2) our method outperforms state-of-the-art approaches with a significant improvement of 7.9% absolute mAP.
Beyond Suspension: A Two-phase Methodology for Concluding Sports Leagues
Mar 29, 2024Problem definition: Professional sports leagues may be suspended due to various reasons such as the recent COVID-19 pandemic. A critical question the league must address when re-opening is how to appropriately select a subset of the remaining games to conclude the season in a shortened time frame. Academic/practical relevance: Despite the rich literature on scheduling an entire season starting from a blank slate, concluding an existing season is quite different. Our approach attempts to achieve team rankings similar to that which would have resulted had the season been played out in full. Methodology: We propose a data-driven model which exploits predictive and prescriptive analytics to produce a schedule for the remainder of the season comprised of a subset of originally-scheduled games. Our model introduces novel rankings-based objectives within a stochastic optimization model, whose parameters are first estimated using a predictive model. We introduce a deterministic equivalent reformulation along with a tailored Frank-Wolfe algorithm to efficiently solve our problem, as well as a robust counterpart based on min-max regret. Results: We present simulation-based numerical experiments from previous National Basketball Association (NBA) seasons 2004--2019, and show that our models are computationally efficient, outperform a greedy benchmark that approximates a non-rankings-based scheduling policy, and produce interpretable results. Managerial implications: Our data-driven decision-making framework may be used to produce a shortened season with 25-50\% fewer games while still producing an end-of-season ranking similar to that of the full season, had it been played.
Efficient and Sharp Off-Policy Evaluation in Robust Markov Decision Processes
Mar 29, 2024We study evaluating a policy under best- and worst-case perturbations to a Markov decision process (MDP), given transition observations from the original MDP, whether under the same or different policy. This is an important problem when there is the possibility of a shift between historical and future environments, due to e.g. unmeasured confounding, distributional shift, or an adversarial environment. We propose a perturbation model that can modify transition kernel densities up to a given multiplicative factor or its reciprocal, which extends the classic marginal sensitivity model (MSM) for single time step decision making to infinite-horizon RL. We characterize the sharp bounds on policy value under this model, that is, the tightest possible bounds given by the transition observations from the original MDP, and we study the estimation of these bounds from such transition observations. We develop an estimator with several appealing guarantees: it is semiparametrically efficient, and remains so even when certain necessary nuisance functions such as worst-case Q-functions are estimated at slow nonparametric rates. It is also asymptotically normal, enabling easy statistical inference using Wald confidence intervals. In addition, when certain nuisances are estimated inconsistently we still estimate a valid, albeit possibly not sharp bounds on the policy value. We validate these properties in numeric simulations. The combination of accounting for environment shifts from train to test (robustness), being insensitive to nuisance-function estimation (orthogonality), and accounting for having only finite samples to learn from (inference) together leads to credible and reliable policy evaluation.